Kelly Betting as Bayesian Model Evaluation: A Framework for Time-Updating Probabilistic Forecasts
Abstract: This paper proposes a new way of evaluating the accuracy and validity of probabilistic forecasts that change over time (such as an in-game win probability model, or an election forecast). Under this approach, each model to be evaluated is treated as a canonical Kelly bettor, and the models are pitted against each other in an iterative betting contest. The growth or decline of each model's bankroll serves as the evaluation metric. Under this approach, market consensus probabilities and implied model credibilities can be updated real time as each model updates, and do not require one to wait for the final outcome. Using a simulation model, it will be shown that this method is in general more accurate than traditional average log-loss and Brier score methods at distinguishing a correct model from an incorrect model. This Kelly approach is shown to have a direct mathematical and conceptual analogue to Bayesian inference, with bankroll serving as a proxy for Bayesian credibility.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper suggests a new, easy-to-understand way to judge how good changing predictions are over time—like during a sports game or an election campaign. Instead of using traditional scores, the paper treats each prediction model like a smart bettor using the Kelly rule (a famous method for sizing bets). As the models “bet” against each other, the amount of money (bankroll) each one grows or shrinks becomes a measure of how trustworthy that model is. The paper shows this betting approach connects directly to Bayesian thinking, which is a way to update beliefs as new evidence comes in.
Goals of the Paper
This paper aims to answer simple questions people often have about forecasts that change over time:
- How can we fairly compare models when their predictions update at different times?
- Can we judge models before the final result is known?
- Is there a method that rewards models that are early, steady, and right (and penalizes those that swing wildly)?
- Can we connect this to the idea of updating beliefs (Bayes’ theorem) in a clear way?
Methods and Ideas (Explained Simply)
Think of each prediction model as a player in a friendly betting game:
- Each model has a “bankroll,” which you can think of as its trust score.
- When a new prediction is made—say the home team has a 65% chance to win—that creates “odds” everyone can use.
- The Kelly rule tells each model how much to “bet” based on how confident it is. If a model strongly believes something, it bets more; if it’s unsure, it bets less.
- “Win shares” are the amounts a model stands to win if a specific outcome happens. These let us track positions across time.
- “Marked to market” means we can value a model’s current bets immediately using the latest market odds—so we don’t need to wait for the game or election to end to see who’s doing well.
Two key ideas make this work:
- Market consensus: When models have different probabilities, there’s a math way to find a fair “market” odds that lets everyone place or accept bets. This is kind of like finding a price where buyers and sellers agree. If everyone later agrees on the same probability, it’s as if all bets settle and we can see who’s ahead.
- Bayesian link: A model’s bankroll acts like its credibility (how much we believe in it). After an outcome happens, models that were more accurate get their credibility boosted; those that were off lose credibility. This mirrors Bayes’ theorem: new evidence changes how much we trust each model.
A simple example
Bob and Alice predict a game at the start of each quarter:
- Q1: Bob says 80% chance the home team wins; Alice says 50%.
- Later, they both adjust their numbers (sometimes switching who’s more confident).
- Using the Kelly rule, they “bet” at each point. By the end, one model’s bankroll grows and the other’s shrinks.
- In the example from the paper, Alice ends up with a larger bankroll because she was earlier and steadier in her updates. Bob loses some credibility for being late and more swingy.
Main Findings and Why They Matter
The author ran many computer simulations (think thousands of pretend games) to test how well this method spots the better model. Here’s what they found:
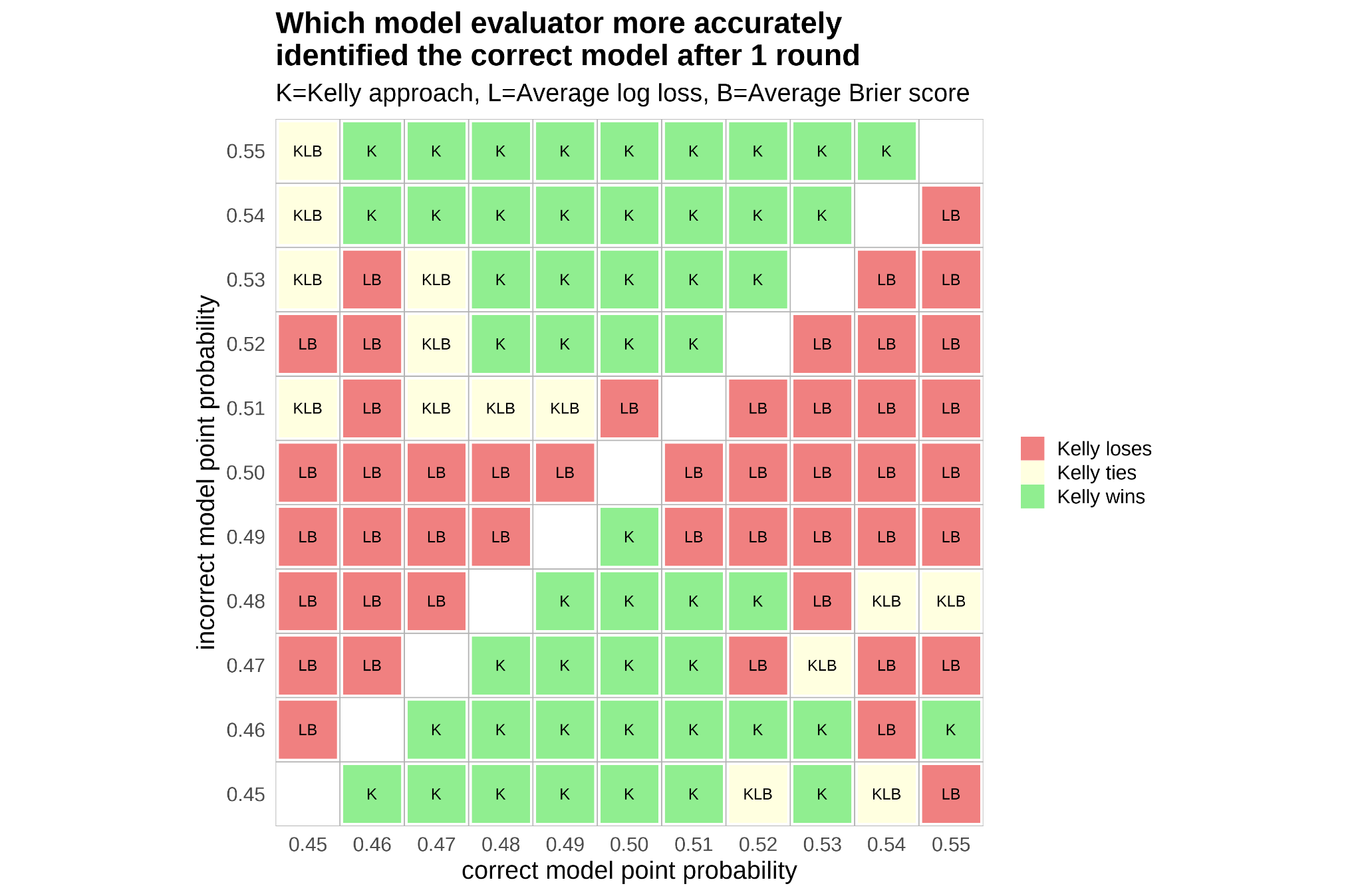
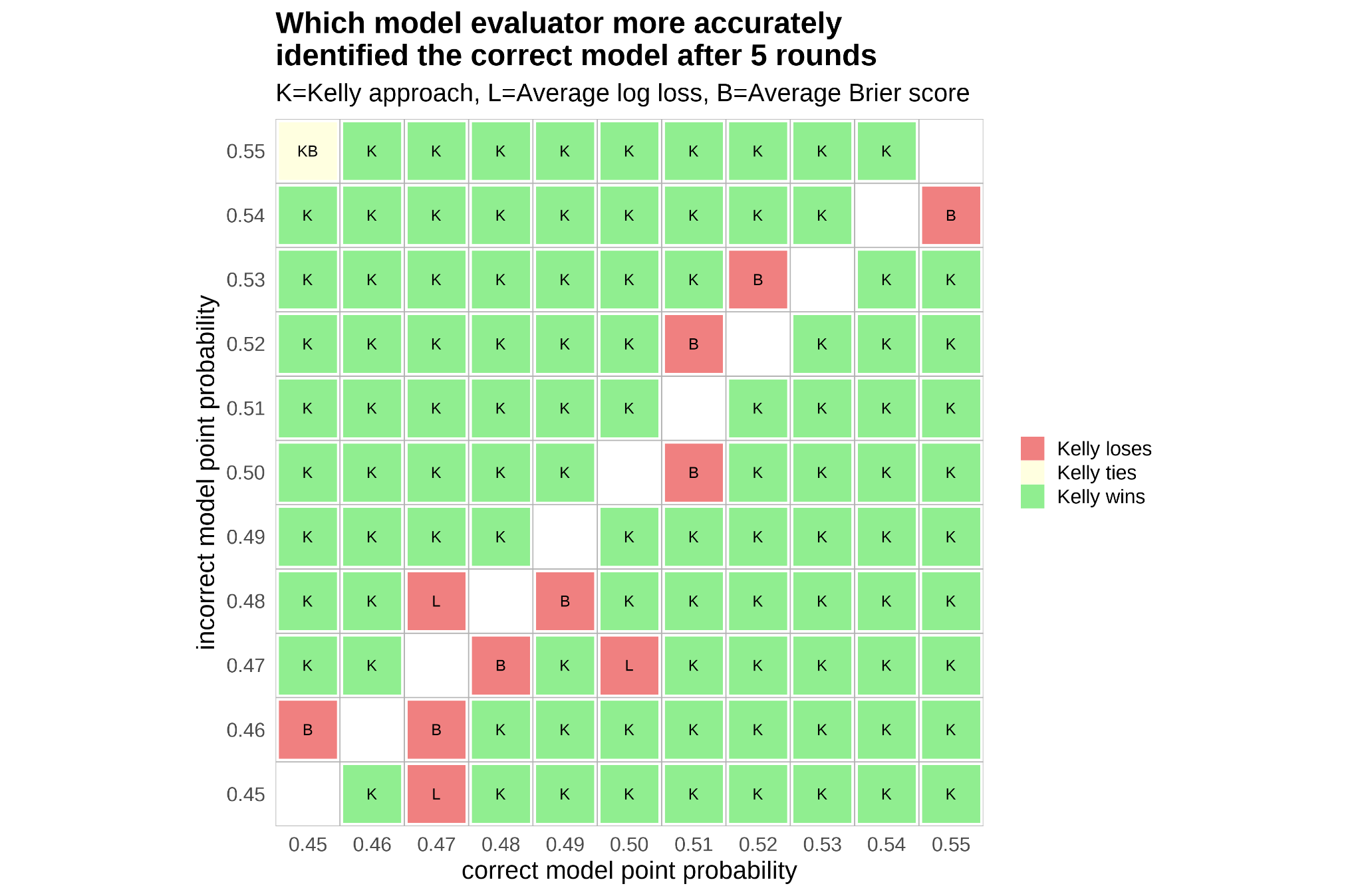
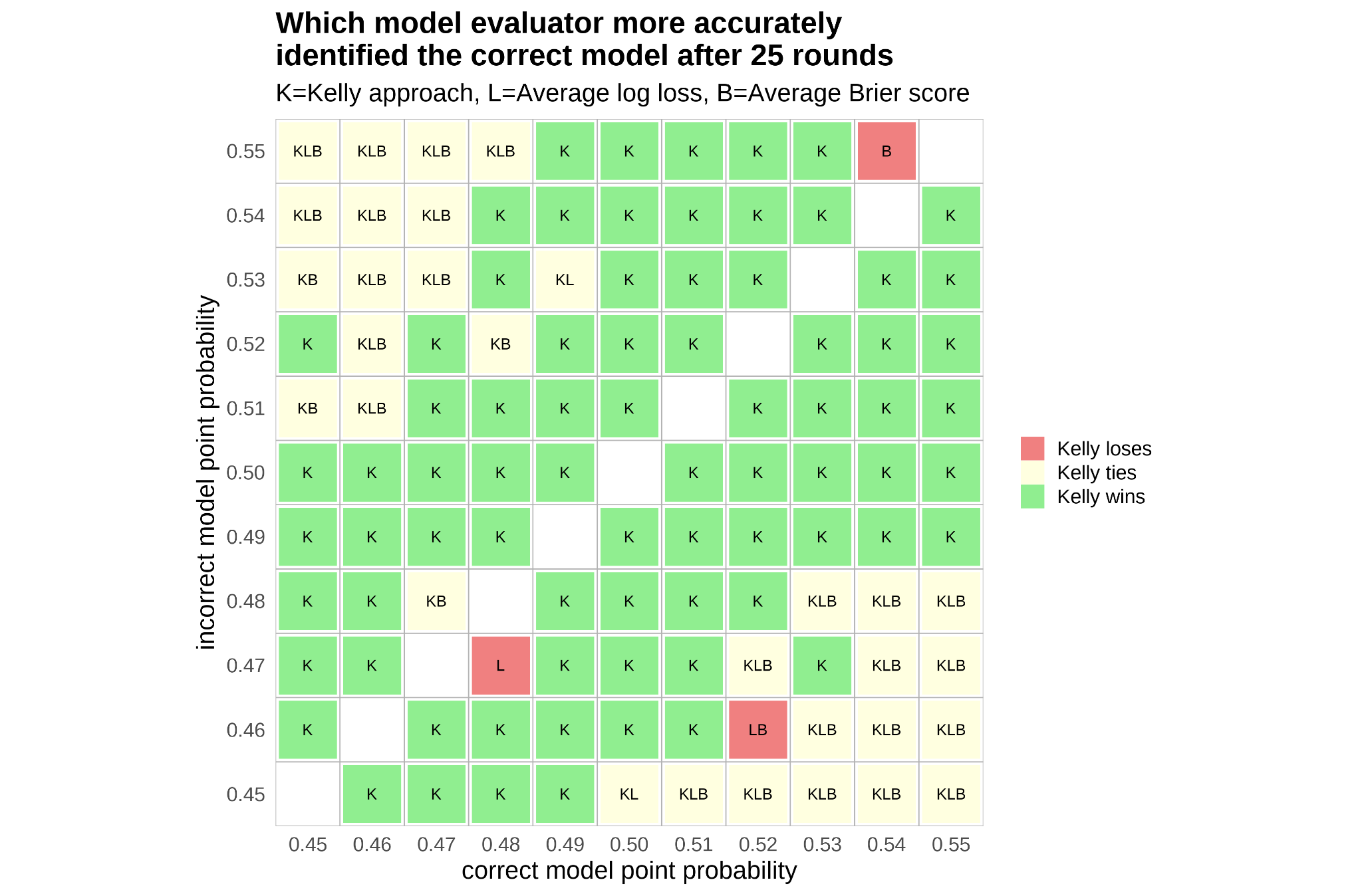
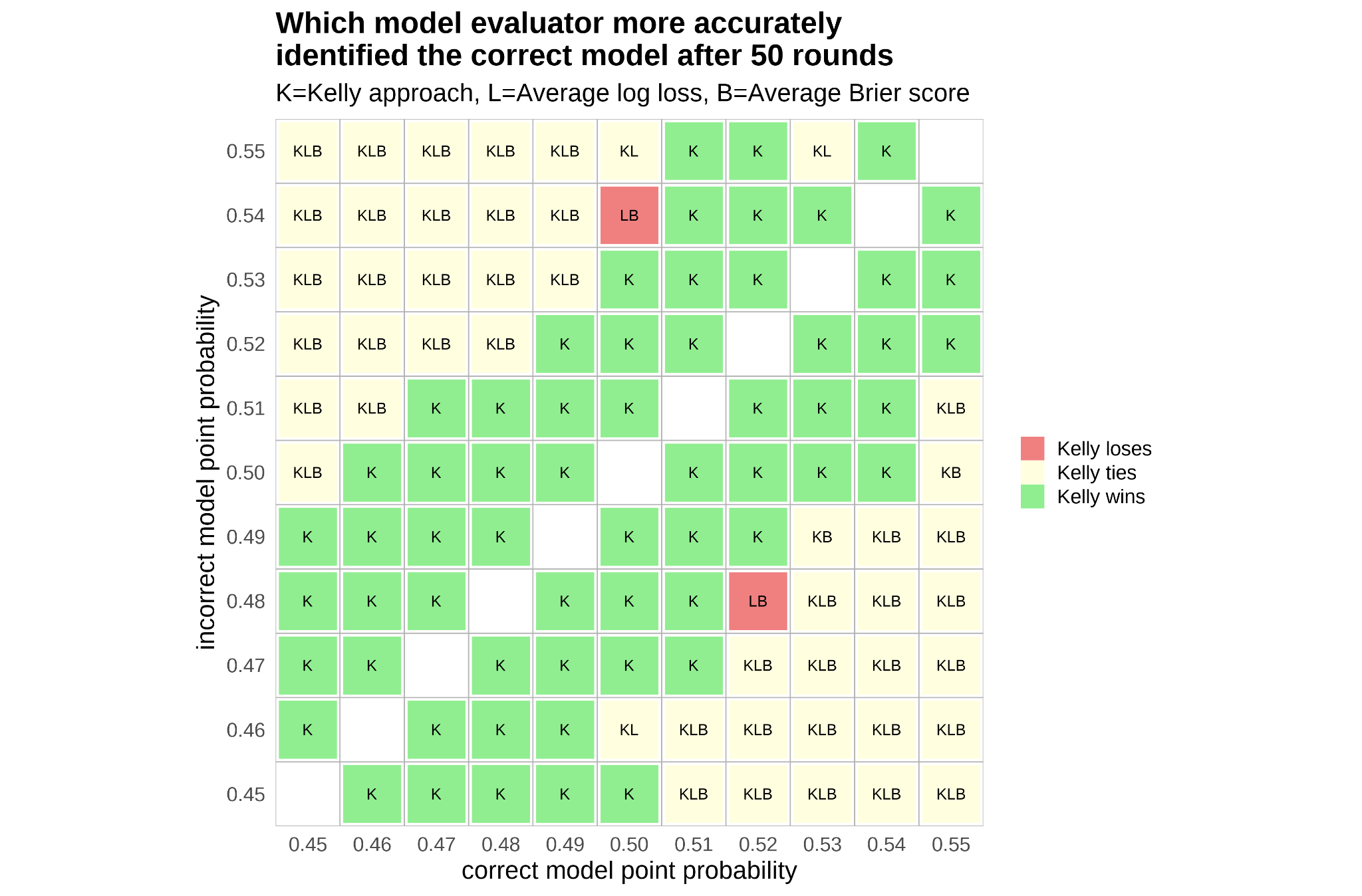
- When the wrong model is overly reactive—like changing its point-by-point prediction too much just because of recent events—the Kelly method is much better at spotting the correct model. It penalizes unnecessary swings.
- When the wrong model uses random, non-predictive information (so its probabilities drift randomly), the Kelly method also does better in telling it apart from the correct model.
- In some single-game cases where one model’s fixed probability is slightly off, traditional methods (like average log loss or Brier score) can perform similarly or a bit better. But:
- Over multiple games (carrying forward each model’s bankroll like a memory), the Kelly approach wins decisively across most scenarios. It’s especially strong when used sequentially—like season after season, or multiple election cycles—because credibility builds or erodes over time.
- This method can evaluate models in real time, before the final outcome. The credibility (bankroll) starts tilting toward the better model early in the contest, which is useful for fast-moving events.
Why this matters:
- It respects time order: Getting to the right answer early is rewarded.
- It reduces the impact of tiny, frequent, low-confidence updates: Small changes lead to small bets, so they don’t muddy the scoring.
- It has a plain-language meaning: “Would this model make money if you followed it?” That’s easier to grasp than abstract scores.
- It’s naturally Bayesian: Your trust in a model updates as evidence arrives.
Implications and Impact
This approach can improve how we judge forecasts in places where probabilities change over time:
- Sports analytics (in-game win probabilities)
- Elections (daily-updating chances of winning)
- Prediction markets (like Polymarket or Kalshi)
By turning model evaluation into a sensible betting competition, we get:
- A fair, real-time trust score for each model (the bankroll)
- A way to reward models that are early, steady, and right
- A Bayesian backbone: credibility updates as outcomes happen
- A method that can carry forward credibility from event to event
Overall, this framework helps people understand, compare, and trust dynamic forecasts—using a process that’s both mathematically sound and intuitively clear.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of unresolved issues and research opportunities suggested by the paper. Each item is framed to be actionable for future work.
- Empirical validation beyond simulation: Benchmark the Kelly-based evaluation against log loss, Brier, and prequential scoring on real, time-updating datasets (e.g., in-game sports win probabilities, election nowcasts, weather forecasts), including multiple domains and rare-event settings.
- Conditions for superiority: Derive formal conditions (theorems) under which the Kelly evaluation is provably more discriminative than proper scoring rules for sequential forecasts (e.g., as a function of volatility, miscalibration magnitude, update timing, or model error structure).
- Properness and truthfulness: Assess whether the proposed mechanism is a strictly proper evaluation rule when odds are endogenous (determined by participants’ and ). Analyze incentives for truthful probability reporting vs. strategic manipulation of .
- Sensitivity to priors: Quantify how initial bankroll allocations (priors) influence outcomes, convergence speed, and fairness. Propose principled methods for setting priors (e.g., based on historical performance with uncertainty quantification).
- Fractional Kelly and risk control: Investigate the impact of fractional Kelly (and other risk-averse variants) on evaluation accuracy, variance, and robustness to finite-horizon path dependence and risk of ruin.
- Liquidity and frictions: Extend the framework to non-ideal markets with overround/vigorish, transaction costs, bet size caps, discrete odds, and limited liquidity; characterize how these frictions affect , , and evaluation reliability.
- Asynchronous and heterogeneous update frequencies: Study fairness and bias when models update at different cadences or latencies, or when only some participants update at a given step. Propose normalization or batching schemes.
- Correlated models and shared information: Analyze how dependence among models (e.g., shared features, similar architectures) affects credibility updates, market clearing, and concentration of bankroll. Consider debiasing or de-duplication strategies.
- Generalization beyond multinomial outcomes: Develop a continuous-outcome analogue (e.g., density betting) and compare to continuous proper scores such as CRPS. Address computational and market-clearing challenges for infinite state spaces.
- Eigenvector uniqueness and stability: For the multinomial case, characterize conditions guaranteeing existence, uniqueness, and numerical stability of as the eigenvector solution of (e.g., Perron–Frobenius assumptions). Provide convergence diagnostics and fallback methods when multiple eigenvectors or near-degeneracies occur.
- Dynamic system properties: Analyze the dynamical system induced by repeated updates of , including fixed points, convergence rates, and stability under noisy or adversarial updates.
- Statistical significance in real time: Develop uncertainty quantification for “credibility” (bankroll) during live evaluation—e.g., confidence intervals, credible intervals, or sequential tests to gauge when a model’s advantage is statistically meaningful.
- Penalizing volatility vs. responsiveness: Quantify the trade-off between penalizing unnecessary volatility and allowing legitimate responsiveness to new information. Identify regimes where the method might unduly penalize truly adaptive models.
- Rare events and extreme probabilities: Examine behavior when models issue near-0 or near-1 probabilities (e.g., bankruptcy risk, numerical instability). Propose smoothing or guardrails (e.g., probability floors/ceilings) and assess their impact on fairness.
- Robustness to misspecified Kelly assumption: Evaluate performance when the “models as Kelly bettors” abstraction is violated (e.g., models that are not calibrated to Kelly-optimal stakes, or do not intend to maximize log-wealth).
- Market-clearing feasibility at scale: Provide algorithms for computing market-clearing odds and matched stakes in large systems with many models and outcomes, including incremental/online updates and guaranteed feasibility under constraints.
- Relationship to market scoring rules: Compare theoretically and empirically to market scoring rule mechanisms (e.g., LMSR) and prequential analysis (Dawid). Identify equivalences, differences, and hybrid designs that combine advantages.
- Collusion and strategic behavior: Analyze how coordinated reporting (collusion) or adversarial strategies could manipulate or siphon bankroll from others. Propose game-theoretic safeguards or auditing.
- Path dependence and horizon effects: Quantify how early misestimates (or lucky runs) affect long-horizon credibility due to compounding, and design debiasing or reset mechanisms (e.g., damped carryover, rolling windows).
- Multi-event portfolios and dependency across events: Extend the framework to evaluate models across correlated events (e.g., multiple electoral races), accounting for joint distributions and portfolio constraints.
- Fair treatment of missing or delayed updates: Specify how to handle skipped updates, data outages, or model downtime without biasing evaluation (e.g., hold positions, impose penalties, or interpolate probabilities).
- Computational reproducibility: Provide open-source code and protocols for replication (data, seeds, numerical tolerances), and report sensitivity to implementation details (e.g., matrix normalization, rounding).
- Calibration and sharpness diagnostics: Integrate calibration and sharpness analyses alongside bankroll-based evaluation to provide a fuller picture of model quality and understand when the metrics disagree.
- Convergence to the true model: Establish Bayesian consistency-like results (if a true data-generating model is in the set, does bankroll concentrate on it almost surely?), and characterize convergence rates under various noise regimes.
- Handling outcome-dependent utility: Explore evaluation when the stakeholder’s utility is asymmetric or task-specific (e.g., cost-sensitive decisions), and whether Kelly-based evaluation can be adapted accordingly.
- Impact of partial observability and delayed labels: Address cases where the true outcome is revealed long after predictions (e.g., economic indicators), including how to mark-to-market credibly during long lags.
- Choice of evaluation granularity: Formalize how to define the “time steps” for wagering (every tick vs. coarser intervals), and analyze the sensitivity of outcomes to step granularity.
- Robust baselines and ablations: Compare against a broader suite of sequential/proper scoring baselines (e.g., Ignorance score, sequential log score with discounting, online learning regret metrics) across many settings.
- Practical guidance for priors and governance: Provide protocols for initializing bankrolls, admitting/removing models, preventing overfitting to the evaluation mechanism, and communicating results to non-technical stakeholders.
- Extensions to partial Kelly matching and capital constraints: Incorporate budget limits and partial matching (not all desired stakes filled) and assess how incomplete markets affect fairness and inference.
- Theoretical link to Bayesian posteriors: Clarify and formalize the conditions under which bankroll equals posterior credibility exactly vs. approximately (given that is endogenous), and address potential circularity in ’s definition.
Practical Applications
Immediate Applications
The following use cases can be deployed with current data pipelines and forecasting workflows, drawing directly on the paper’s Kelly-as-Bayesian evaluation, market-clearing odds, and mark-to-market credibility tracking.
Software, MLOps, and Data Science
- Real-time evaluator for time-updating probabilistic models
- Workflow: Treat each candidate model as a Kelly bettor; compute market-clearing probabilities (binary or multinomial via eigenvector of p·wᵀ), update bankroll/credibility and mark-to-market continuously.
- Tools/products:
- “KellyEval” Python/R library (binary and multinomial; power-iteration for eigenvector).
- MLflow/Weights & Biases plugin for streaming model evaluation.
- Kafka/Flink microservice that ingests model updates and publishes consensus probabilities and credibilities.
- Assumptions/dependencies: Models output calibrated probabilities; log-utility (Kelly) risk preference or fractional-Kelly; unique/robust market-clearing solution; synchronized update cadence.
- Online ensemble model weighting for streaming predictions
- Workflow: Use model credibilities (bankrolls) as dynamic weights to produce consensus forecasts (m = p·c).
- Tools/products: “CredEnsemble” combiner for time-series classification/forecasting.
- Assumptions/dependencies: Stable numerical solution for multinomial case; safeguards against overfitting volatility (fractional Kelly).
- Experimentation and A/B/n testing under drift
- Workflow: Allocate exposure to variants in proportion to credibility; down-weight overly volatile or recency-biased variants.
- Tools/products: Feature-flag platforms with Kelly-weighting module.
- Assumptions/dependencies: Clear mapping from outcomes to payoffs; guardrails for early-stage variance.
Sports Analytics and Betting
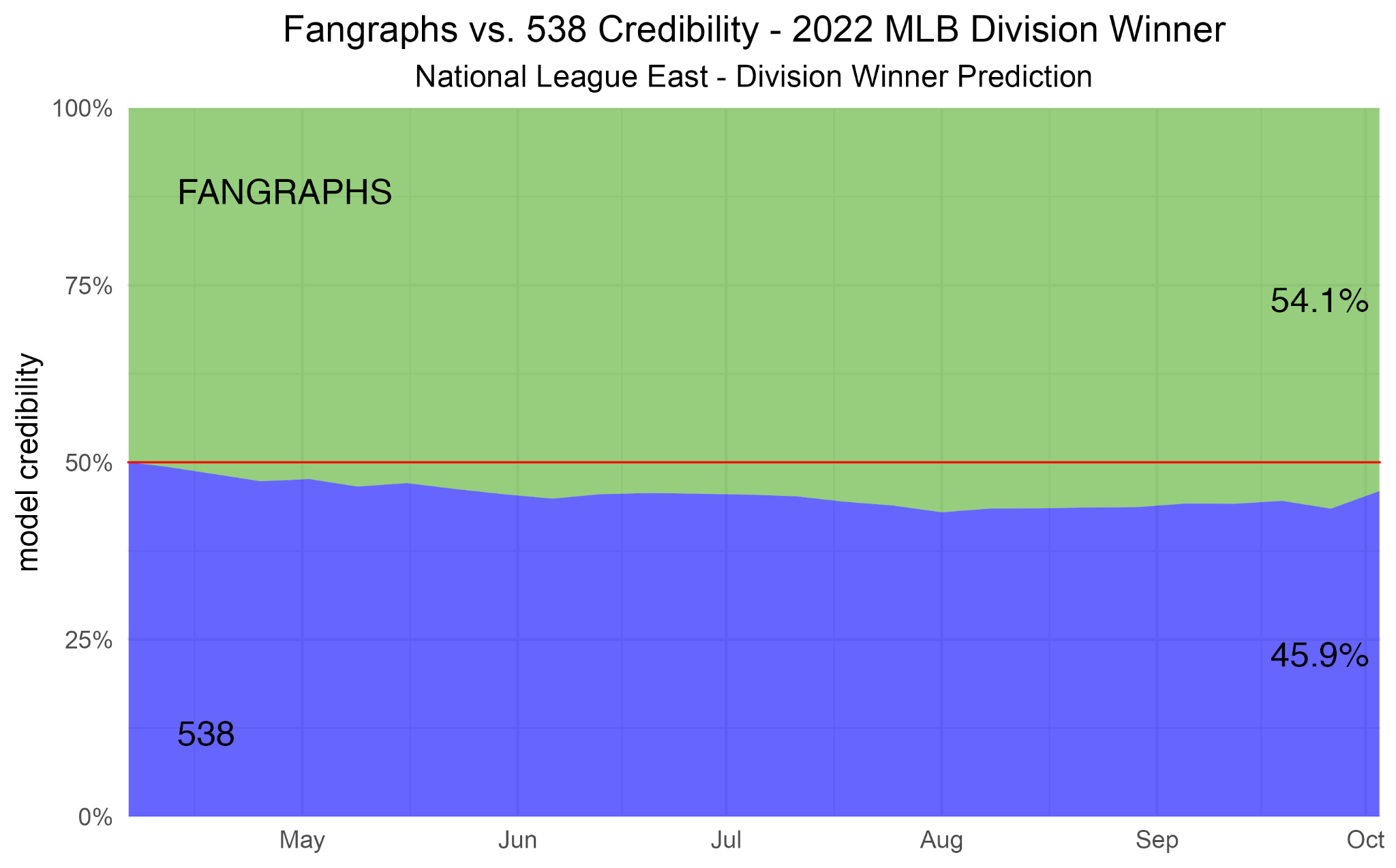
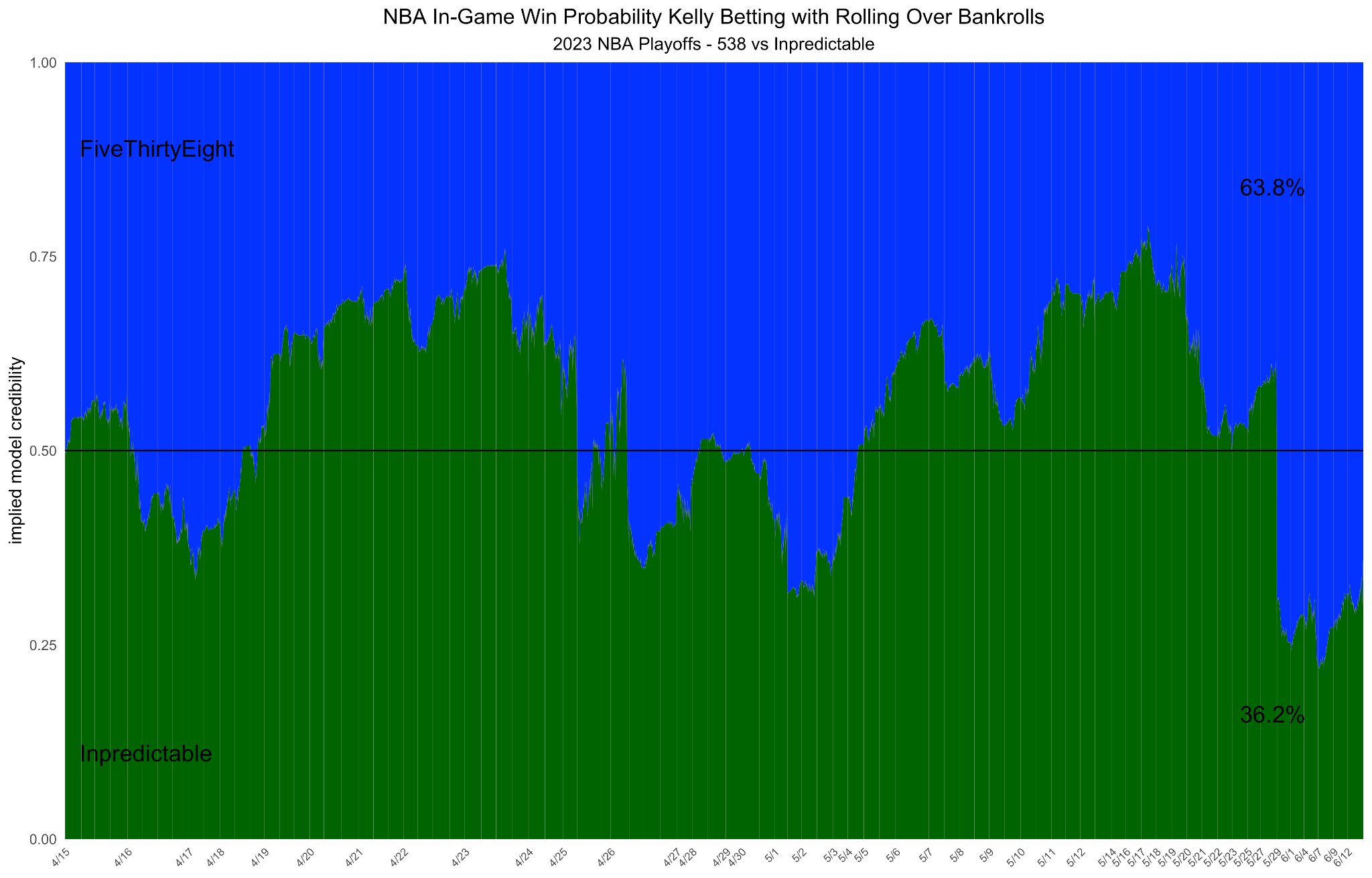
- In-game win-probability model benchmarking and vendor selection
- Workflow: Run “model leagues” during games; display market consensus and per-model credibility; select production model based on bankroll over a season.
- Tools/products: Team/league dashboards; broadcast overlays (credibility bars).
- Assumptions/dependencies: Access to synchronized model updates; regulator- and league-compliant usage.
- Sportsbook risk management
- Workflow: Internal model tournament to identify overconfident/volatile models; set in-play odds near market-clearing probability from internal models.
- Assumptions/dependencies: Internal compliance; fractional Kelly to manage drawdown risk.
Elections and Policy Forecasting
- Live aggregation of election forecasts with credibility shares
- Workflow: Publish consensus probabilities and evolving model credibilities ahead of final outcomes; reduce focus on last-day snapshot.
- Tools/products: Newsroom widgets; API for forecast aggregators.
- Assumptions/dependencies: Access to historical/update feeds; transparency standards.
Finance (Quant, Trading, and Risk)
- Meta-allocation across strategies/signals
- Workflow: Treat signals as bettors; allocate capital proportional to Kelly-derived credibility; mark-to-market using realized P&L or event outcomes.
- Tools/products: Portfolio “Allocator-as-Contest” module; OMS/Risk dashboards.
- Assumptions/dependencies: Correlation-aware fractional Kelly; transaction costs; limits and regulatory constraints.
- Real-time model selection for market microstructure forecasts
- Workflow: Choose among multiple microstructure models using bankroll trajectory under tick-level outcomes.
- Assumptions/dependencies: Fast computation; robust probability calibration.
Energy and Weather
- Grid operations and demand/renewable nowcasting
- Workflow: Compete vendor/ensemble models; use credibility-weighted consensus for dispatch decisions.
- Tools/products: “Grid-Kelly” aggregator integrated with SCADA forecasting layers.
- Assumptions/dependencies: Continuous probability feeds; latency tolerance; safety margins.
- Weather and hurricane track forecast aggregation
- Workflow: Real-time credibility re-weighting of ensemble members; communicate consensus and uncertainty.
- Assumptions/dependencies: Consistent probabilistic outputs; public risk communication protocols.
Healthcare and Clinical Operations
- Dynamic evaluation of patient-deterioration or readmission risk models
- Workflow: Compete multiple bedside or EHR models; credibility-weighted triage risk score; early identification of overreactive models.
- Tools/products: “TriageCred” dashboard for hospital command centers.
- Assumptions/dependencies: IRB/ethics oversight; rigorous validation; clear outcome definition and timing.
Education and Training
- Teaching Bayesian updating and model calibration
- Workflow: Classroom competitions using Kelly bankrolls; interpret bankroll as posterior credibility.
- Tools/products: Jupyter labs with sports/election simulations.
Prediction Markets and Platforms
- Non-crypto “model tournament” scoring without relying on external odds
- Workflow: Use market-clearing odds from participant models; bankroll-based scoring replaces Brier/log-loss leaderboards.
- Tools/products: “Model League” SaaS with anti-collusion checks.
- Assumptions/dependencies: Participation rules; adjudication of outcomes; fairness guarantees.
Media and Consumer Apps
- Sports and weather apps that show “trust meters” for models
- Workflow: Display model credibilities alongside probabilities; highlight stability vs volatility.
- Assumptions/dependencies: UX for probabilistic literacy; data-sharing agreements.
Long-Term Applications
These use cases require further research, scaling, validation, or regulatory/standardization work.
Autonomous Systems and Robotics
- Kelly-Bayesian arbitration among perception/planning modules
- Concept: Sensors/models place “belief bets”; resource allocation (compute/attention) follows credibility; down-weight noisy modules.
- Dependencies: Real-time mapping from probabilities to utility under safety constraints; latency guarantees; formal verification.
Public Risk Communication and Government Standards
- Agency-wide standard for evaluating time-updating forecasts (e.g., NOAA, CDC, emergency management)
- Concept: Replace or complement log-loss/Brier with Kelly-credibility for live events (outbreaks, storms, wildfires).
- Dependencies: Inter-agency standardization; public transparency; training materials.
Financial Infrastructure and Regulation
- Brokerages/funds using Kelly-credibility as a regulated meta-allocator across client algos
- Concept: “Credence-weighted fund-of-algos” with dynamic capacity allocation.
- Dependencies: Regulatory approval; capital and drawdown controls; robust correlation-adjusted fractional Kelly.
Clinical Decision Support and Trial Platforms
- Hospital-wide ensemble triage and adaptive trials
- Concept: Allocate enrollment or monitoring intensity based on model credibility; continually re-weight model influence on care pathways.
- Dependencies: Clinical validation; safety and fairness constraints; auditability and bias monitoring.
Energy Market Operations and Incentive Design
- System operators running forecast competitions that set operational consensus
- Concept: Market-clearing odds form operational guidance; payouts/incentives aligned with bankroll growth.
- Dependencies: Market rules; settlement mechanisms; anti-gaming design.
AI Agent Ecosystems
- Multi-agent AI systems that “bet” beliefs and reallocate compute/budgets to outperforming agents
- Concept: Kelly-based belief markets inside agent collectives; credence drives tool-use and planning authority.
- Dependencies: Mechanism design; collusion and sybil resistance; alignment and safety oversight.
Standards and Benchmarks for Time-Updating Forecasts
- ISO-like metric and benchmark suites
- Concept: Publish standardized live-evaluation tasks (sports, elections, streaming classification) with Kelly-credibility scoring.
- Dependencies: Community adoption; open datasets; reproducibility frameworks.
Product and Tooling Roadmap (Ecosystem Build-Out)
- Comprehensive platform for Kelly-based evaluation and aggregation
- Components:
- Open-source core (binary/multinomial, eigenvector solver, fractional Kelly).
- Cloud service with APIs for model updates, consensus probabilities, and credibility time series.
- Visualization (credibility timelines, volatility flags, mark-to-market P&L).
- Integrations: MLflow, Airflow, Kafka, Spark/Flink, major EHRs, grid control interfaces, broker OMS/RMS.
- Dependencies: Numerical stability; uniqueness of market-clearing solution; privacy/security; governance and anti-collusion checks.
Key Cross-Cutting Assumptions and Dependencies
- Risk preference and Kelly sizing
- Kelly assumes log-utility; in practice, use fractional Kelly to limit volatility and drawdowns.
- Fair “odds” abstraction and zero-sum constraint
- The framework assumes fair odds (no vig) and zero-sum win shares; when mapping to real markets or operations, adjust for fees, frictions, or asymmetric utilities.
- Probability calibration and comparability
- All models must produce comparable, time-stamped probabilistic forecasts; multinomial cases require consistent support across outcomes.
- Numerical and identifiability conditions
- Multinomial market-clearing requires solving an eigenvector problem; ensure existence/uniqueness and numerical stability.
- Governance and integrity
- Prevent collusion, sybil attacks, or coordinated volatility; define outcome adjudication; maintain audit logs.
- Regulatory and ethical compliance
- Finance and healthcare deployments require regulatory approval and ethical oversight; ensure fairness, transparency, and safety.
Glossary
- Bankroll: The total funds a bettor or model has available for wagering; in this framework, it also serves as a proxy for a model’s credibility. "The growth or decline of each model's bankroll serves as the evaluation metric."
- Bayes' theorem: A rule for updating probabilities of hypotheses given evidence. "Then, according to Bayes' theorem, can be calculated as:"
- Bayesian credibility: Interpreting a model’s standing (e.g., bankroll) as its credibility in a Bayesian sense. "This Kelly approach is shown to have a direct mathematical and conceptual analogue to Bayesian inference, with bankroll serving as a proxy for Bayesian credibility."
- Bayesian prior: The initial belief about a model’s correctness before observing new data; here, often represented by starting bankroll. "our Bayesian prior that Bob and Alice were equally probable to have the correct model, has now been updated to Bob being 45\% likely to have the correct model, and Alice upgraded to 55\%."
- Bookmaker: The counterparty who accepts bets and pays out according to odds. "Bob has become the bookmaker and is accepting \$16.48 from Alice, the bettor."
- Brier score: A proper scoring rule that measures the mean squared error of probabilistic forecasts. "A common approach in this situation would be to calculate a Brier score or log loss for each forecast made, and then average that number."
- Calibration tests: Statistical tests assessing whether predicted probabilities match observed frequencies. "such as log loss, Brier score, and calibration tests."
- Eigenvalue: A scalar such that multiplying a matrix by its eigenvector scales the vector by this amount; here, 1 characterizes equilibrium conditions. "Our credibility vector is an eigenvector of , with an eigenvalue of 1."
- Eigenvector: A non-zero vector whose direction is unchanged by a matrix transformation, scaled by an eigenvalue; used here to identify market-clearing probabilities and credibilities. "Written this way, we see that the market clearing probability is an eigenvector of the matrix with eigenvalue 1."
- Implied probability: The probability implied by the betting odds. "they would agree to a bet at 7/13 odds, or an implied probability of 65\%."
- Kelly bettor: A bettor who sizes wagers according to the Kelly criterion to maximize long-term log wealth. "each model to be evaluated is treated as a canonical Kelly bettor"
- Kelly criterion: A bet-sizing strategy that maximizes the expected logarithm of wealth based on estimated probability and odds. "The Kelly criterion is a bet-sizing strategy that prescribes the percentage of bankroll one should wager on an outcome, given the odds offered and the estimated true probability of the outcome."
- Left-stochastic matrix: A matrix whose columns each sum to 1; such matrices guarantee an eigenvector with eigenvalue 1. "The matrix is also a left-stochastic matrix and thus the eigenvector with eigenvalue of 1 is guaranteed to exist."
- Likelihood: The probability of observed data under a model; used here to reinterpret bankroll as model likelihood. "we will interpret it instead as a likelihood of a model being the correct model."
- Log loss: A proper scoring rule based on the negative logarithm of assigned probabilities to outcomes; penalizes overconfidence. "A common approach in this situation would be to calculate a Brier score or log loss for each forecast made, and then average that number."
- Marked to market: Valuing a portfolio or position using current market prices or probabilities. "each model's portfolio of bets can be marked to market."
- Market clearing odds: The odds at which all bettors’ desired bets are balanced given their beliefs and existing positions. "we will now calculate the implied market clearing odds as a function of each bettor's existing positions and current probability estimates."
- Market clearing price: The equilibrium price (probability) where the aggregate demand for bets equals the aggregate supply from bookmakers. "One can establish a formula for the market clearing price where, in aggregate, all bets are matched up with willing bookmakers among the bettors."
- Market consensus probabilities: Collective probability estimates derived from aggregating participants’ views via market odds. "Under this approach, market consensus probabilities and implied model credibilities can be updated real time as each model updates,"
- Market odds: The odds offered by the market reflecting consensus beliefs and pricing. "This can only be achieved by making and/or accepting bets at the given market odds."
- Market probability: The probability implied by the market odds, often the equilibrium estimate across participants. "market probability = \frac{\sum p_i b_i}{1-\sum p_i w_i}"
- Multinomial outcomes: Situations with more than two mutually exclusive outcomes (e.g., win/loss/draw). "To best model multinomial outcomes, we will dispense with the bankroll/bet distinction of the previous section"
- Posterior probability: The updated probability of an outcome after considering new evidence. "the th element tells you the posterior probability of outcome , in the event that outcome has occurred."
- Prediction markets: Markets where securities pay based on event outcomes, aggregating information into prices. "prediction markets such as Polymarket and Kalshi,"
- Recency bias: The tendency to overweight recent observations when updating predictions. "When the incorrect model has faulty recency bias"
- Self-evaluating market: A matrix-based representation (S = wT p) capturing how models assess each other, yielding an endogenous credibility vector. "We will define the matrix as (where stands for self-evaluating market)."
- Sum product: The sum of elementwise products across vectors; used here to define matrix elements and expected values. " is an matrix in which the th element is the sum product of the probability estimates for outcome times the win shares held on outcome , summed over all market participants."
- Track take: The commission or fee extracted by the house in parimutuel markets. "assume that the market odds are 'fair', in that there is no 'track take' or 'vigorish' baked into the odds."
- Vigorish: The bookmaker’s margin or fee embedded in betting odds. "assume that the market odds are 'fair', in that there is no 'track take' or 'vigorish' baked into the odds."
- Win shares: The amount a bettor stands to win or lose conditional on a specific outcome; a position measure in this framework. "Denote as a bettor's win shares, and define it as the money a bettor would stand to win (or lose, if is negative) if the outcome in question occurred."
Collections
Sign up for free to add this paper to one or more collections.