- The paper introduces a novel, model-free quantile-based method for assessing simulator fidelity using observable outputs.
- It demonstrates the method’s practical application by calibrating empirical quantile curves for LLM-driven survey simulators with finite-sample guarantees.
- The approach enables statistically validated comparisons of simulators, supporting risk-aware decisions in simulator selection.
Model-Free Quantile-Based Simulator Fidelity Assessment
Introduction and Context
The widespread use of simulators—including LLM-driven digital twins, agent-based social models, and AI-powered survey emulators—has amplified demands for robust fidelity assessment: determining how closely simulators replicate real-world behavior. Classical approaches for uncertainty quantification (UQ) generally distinguish input uncertainty (uncertain inputs to accurate simulators) from output uncertainty (errors in the simulator’s output, including bias and variance relative to ground truth). The latter is predominant for complex ML-based simulators, especially when simulator internals are inaccessible or computationally prohibitive to calibrate.
The paper "Model-Free Assessment of Simulator Fidelity via Quantile Curves" (2512.05024) develops a new, computationally tractable, model-free procedure to estimate the entire quantile curve of discrepancies between black-box simulators and ground-truth outcome distributions. The approach is broadly applicable (no parametric assumptions), supports UQ for user-chosen discrepancy measures (KL, Wasserstein, squared error, etc.), and comes with finite-sample guarantees, unlike much of the asymptotic literature.
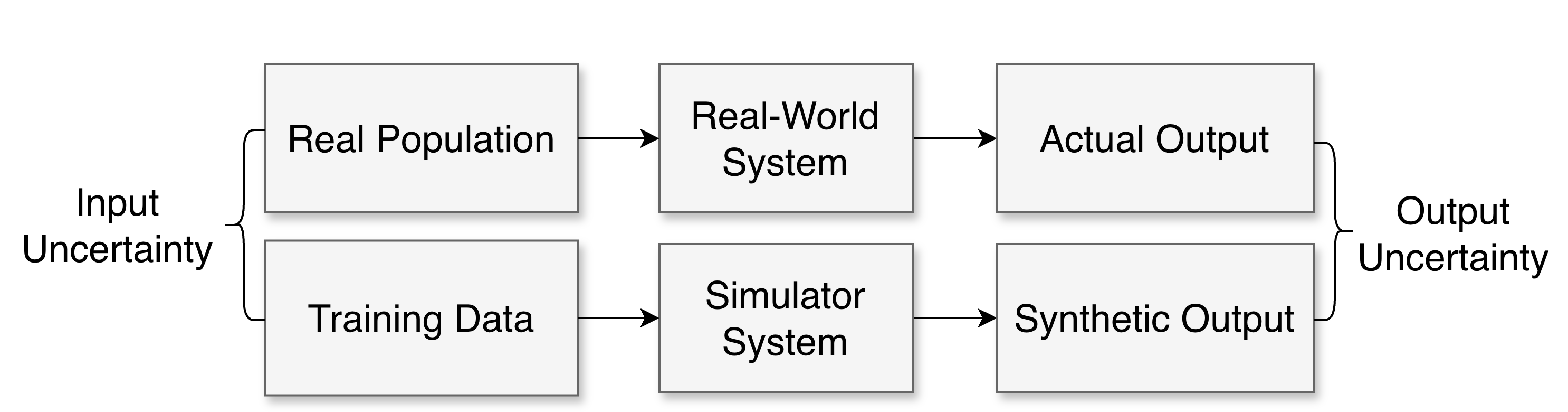
Figure 1: Simulation Uncertainty Quantification.
Methodological Framework
The methodology targets estimating the quantile function V(α) of the scenario-wise discrepancy Δψ between real and simulated outcomes, under a user-defined loss L(⋅,⋅). Simulators are treated as black boxes; only samples of real and simulated outcomes are observable, often with heterogeneous per-scenario sample sizes. The framework is general across outcome types, parameter spaces, and loss functions.
Calibration Protocol:
- For each scenario j, construct a confidence set Cj for the real-world parameter pj (e.g., mean, categorical distribution), using concentration bounds tailored to the outcome type (e.g., Chernoff-Hoeffding for Bernoulli or multinomial, Wasserstein for general outputs).
- Compute a pseudo-discrepancy per scenario: Δ^j=u∈CjsupL(u,q^j) (worst-case plausible gap).
- Aggregate across scenarios: the calibrated empirical quantile curve V^(α) is formed from {Δ^j}j=1m.
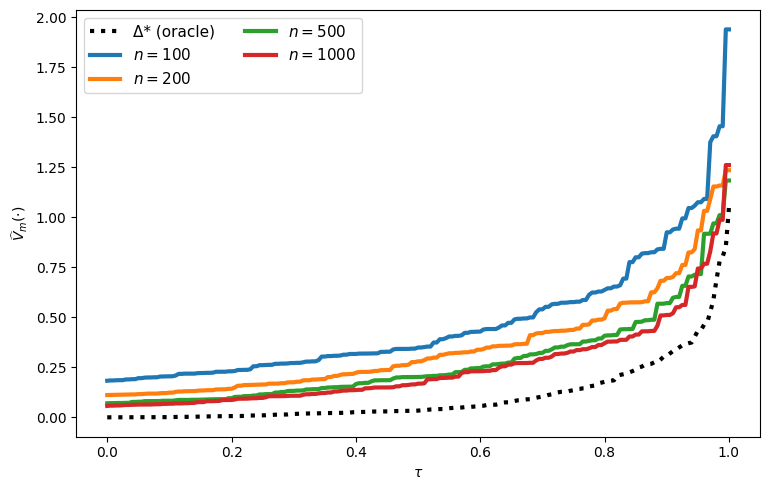
This yields a tight empirical upper envelope for the true quantile function under finite samples. The approach sharply controls both scenario uncertainty (finite number of scenarios) and finite-sample uncertainty (limited observations per scenario).
Theoretical Guarantees:
- For any α, with high probability over the calibration data, P(Δψ≤V^((1+α)/2)∣D)≥α−om(1), where m is the scenario count.
- Finite-sample coverage guarantees (tightening as m increases) are ensured by leveraging DKW and Chernoff-type inequalities adapted to the setting.
Extension: Model Comparison
The method naturally extends to pairwise comparison of black-box simulators. For two simulators S1 and S2, differences in scenario-wise pseudo-discrepancies are analyzed using the same quantile calibration machinery:
- The (1−αˉ)-quantile of pseudo-difference {δ^j} supports certified statements such as "With high probability, S1 is at least as close as S2 to the ground-truth on at least 1−αˉ fraction of scenarios (up to a vanishing correction)."
This lends strong inferential validity to claims of simulator superiority beyond mere aggregate statistics.
Empirical Evaluation: LLM Simulation Fidelity on Survey Data
The methodology is applied to world-scale social simulation: quantifying how well LLMs simulate human survey responses on the WorldValueBench dataset, extracted from the World Values Survey.
Experimental pipeline:
- 235 diverse survey questions, each mapped to [−1,1], with nj≈450–$500$ real responses per question.
- Four LLMs evaluated: GPT-4o, GPT-5-mini, Llama 3.3 70B, Qwen 3 235B, plus a uniform random baseline.
- For each question, LLMs generate k=500 synthetic predictions matched to real respondent demographics.
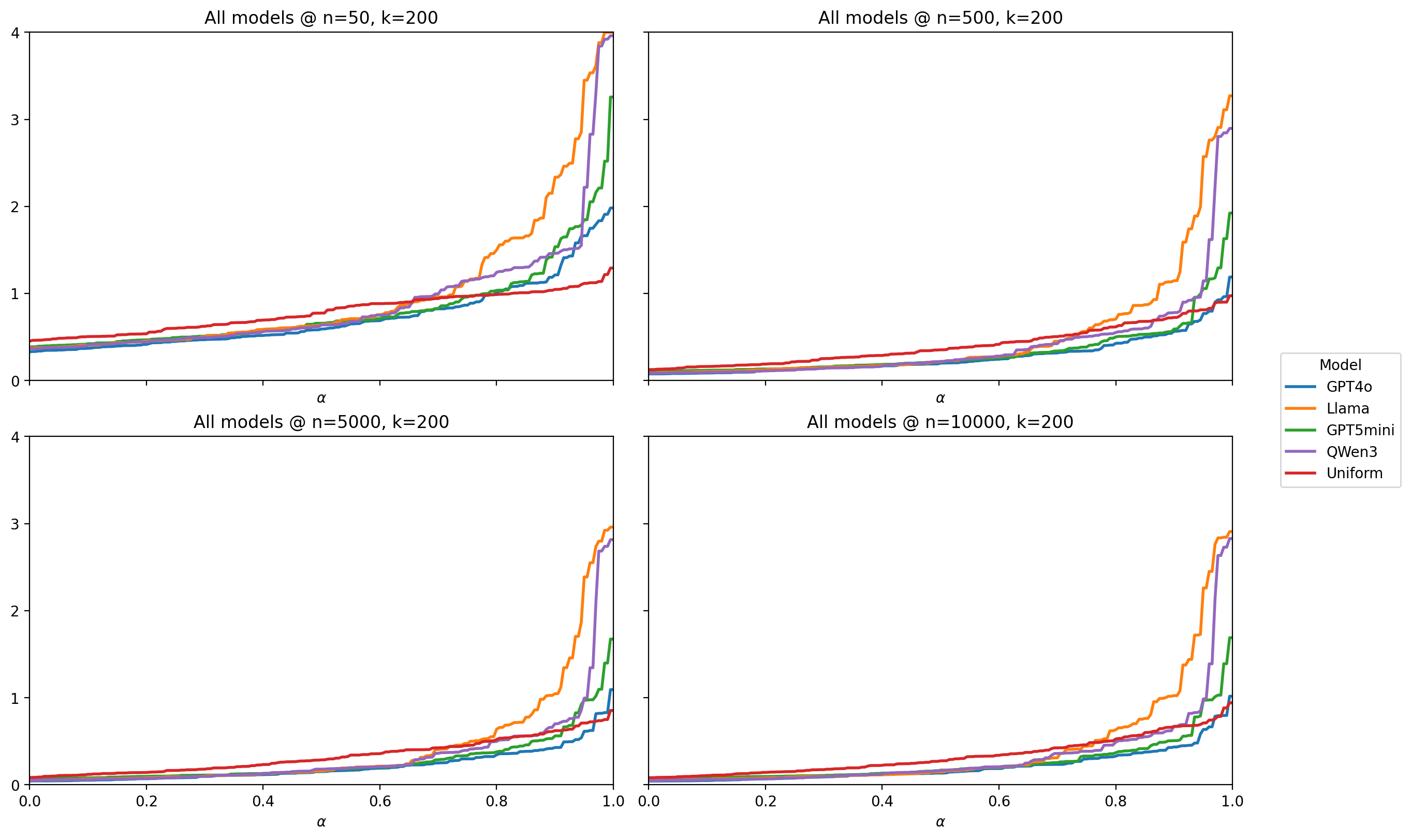
Quantile fidelity profiles are plotted using squared-error discrepancies and per-question confidence sets, yielding tight, calibrated curves.

Figure 2: Example of World Value Questions. Retrieved from WVS_Wave7_2020.
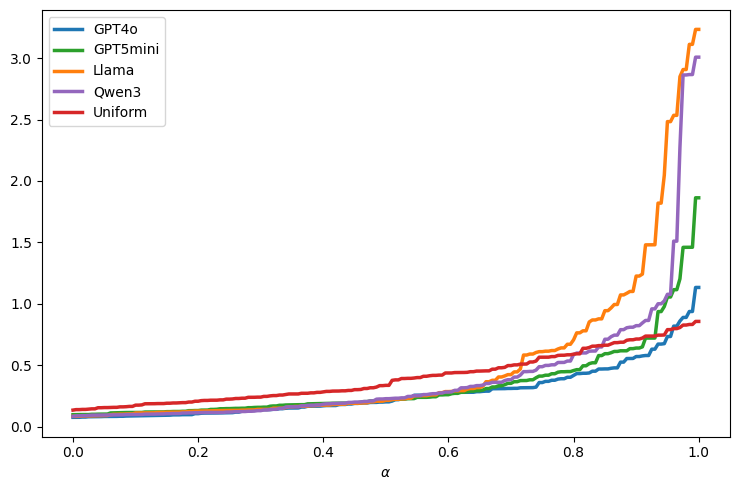
Figure 3: Calibrated V(α) across LLMs.
Key empirical findings:
Robustness checks show stability of comparisons across a range of real data sample sizes (nj from $50$ to $10,000$).
Tightness and Confidence Bands
A central concern is whether the quantile calibration is excessively conservative in finite data. Analysis establishes that:
Additional Application Results
The methodology generalizes to additional simulation types (e.g., educational MCQ settings with Bernoulli outputs, public opinion simulation with multinomial outcomes) and alternative discrepancy measures (absolute error, total variation). Consistent trends are observed: the calibrated approach reveals robust relative rankings and exposes both average and worst-case discrepancies.
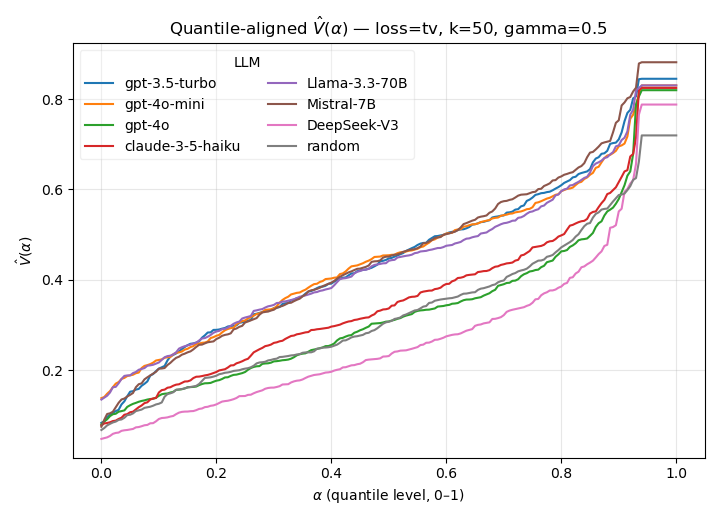
Figure 6: Quantile fidelity profiles V^(α) across LLMs (Discrepancy: Absolute loss, k=50, β=0.5, δ=0.1).
Implications and Outlook
The proposed quantile calibration framework significantly advances robust simulator evaluation:
- Guarantees distributional control of simulator-to-reality discrepancies under minimal assumptions, for any discrepancy of interest.
- Enables risk-aware summaries such as calibrated AUC and CVaR for both mean and tail-fidelity assessment.
- Permits rigorous, statistically-validated pairwise comparisons of black-box ML simulators.
Practical implications include informed simulator selection, precise reporting of alignment confidence for downstream applications (e.g., digital twins, AI social science), and judicious risk management for system designs reliant on high-fidelity simulation.
On the theoretical side, the method's finite-sample nonparametric guarantees (avoiding asymptotics and model assumptions) mark a substantive enhancement relative to both input-uncertainty and pointwise conformal inference literature.
Opportunities for future extension include:
- Tightening constants for small scenario counts,
- Extending from static to dynamic simulation settings,
- Conditioning on non-i.i.d. scenarios to address distribution shift,
- Integrating tighter, instance-adaptive concentration schemes.
Conclusion
This work formalizes and operationalizes quantile-based, model-free fidelity assessment for black-box simulators using only observable outputs. The framework is broadly applicable, theoretically grounded with finite-sample guarantees, and empirically validated across challenging ML simulation tasks. It provides a foundation for rigorous fidelity auditing, risk-sensitive system design, and robust comparative evaluation of ever more complex simulation engines in science and industry.