Revisiting [CLS] and Patch Token Interaction in Vision Transformers
Abstract: Vision Transformers have emerged as powerful, scalable and versatile representation learners. To capture both global and local features, a learnable [CLS] class token is typically prepended to the input sequence of patch tokens. Despite their distinct nature, both token types are processed identically throughout the model. In this work, we investigate the friction between global and local feature learning under different pre-training strategies by analyzing the interactions between class and patch tokens. Our analysis reveals that standard normalization layers introduce an implicit differentiation between these token types. Building on this insight, we propose specialized processing paths that selectively disentangle the computational flow of class and patch tokens, particularly within normalization layers and early query-key-value projections. This targeted specialization leads to significantly improved patch representation quality for dense prediction tasks. Our experiments demonstrate segmentation performance gains of over 2 mIoU points on standard benchmarks, while maintaining strong classification accuracy. The proposed modifications introduce only an 8% increase in parameters, with no additional computational overhead. Through comprehensive ablations, we provide insights into which architectural components benefit most from specialization and how our approach generalizes across model scales and learning frameworks.




















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of the paper
What is this paper about?
This paper looks at how Vision Transformers (ViTs)—a kind of AI model that understands images—handle two kinds of information:
- a special “class” token that summarizes the whole image, and
- many “patch” tokens that each look at a small part of the image.
The authors show that treating these two token types exactly the same is not ideal. They propose small changes so the model processes them a bit differently. This makes the model much better at “dense” tasks that need detailed, pixel-level understanding (like drawing outlines of objects in a picture), while keeping overall image classification strong.
What questions were the researchers trying to answer?
The paper focuses on questions like:
- Are the class token (the image summarizer) and patch tokens (the small parts) interfering with each other when they are processed in exactly the same way?
- Do current models already try to separate these two token types on their own?
- If we explicitly give the class token and patch tokens slightly different processing steps, does the model get better—especially for tasks that need detailed local information?
How did they study it? (Think of it like a classroom)
First, a quick picture of how a Vision Transformer works:
- The image is chopped into small squares called “patches.” Each patch becomes a “patch token.”
- A special “class token” is added to represent the whole image.
- All tokens go through many layers that include:
- Attention: like a class discussion where each token decides who to listen to.
- Normalization: like turning everyone’s microphone to a similar volume so no one is too loud or too quiet.
- Projections (Q, K, V): think of them as the notes each student prepares—questions (Q), what they know (K), and what they’ll share (V)—to help the discussion go smoothly.
What the authors did:
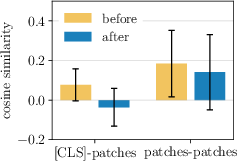
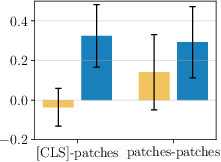
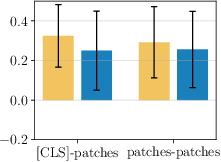
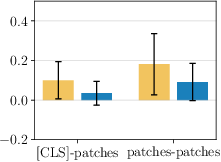
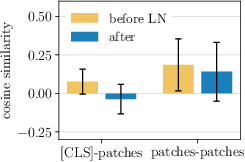
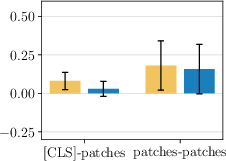
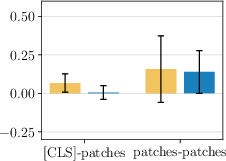
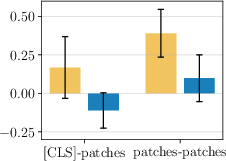
- They measured how similar the class token and patch tokens are before and after each layer. Surprise: the normalization step right before attention makes the class token and patch tokens more different from each other. That means the model is already trying to separate their roles, even though it uses the same settings for both.
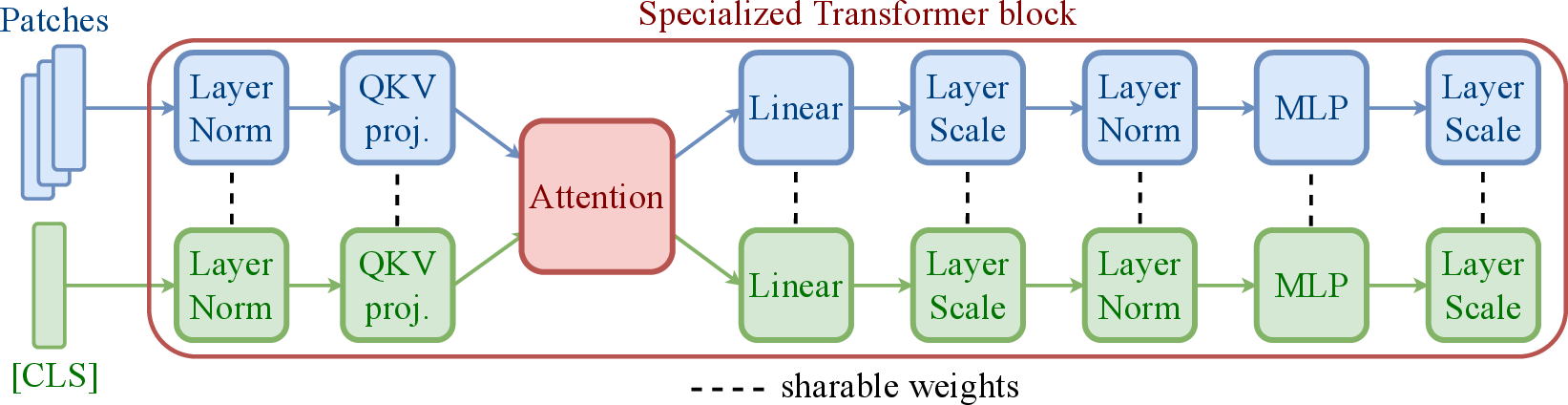
- Based on this, they proposed a change: give the class token and patch tokens their own versions of certain layers (like having slightly different instructions for the “class leader” versus the “group members”), while still letting them talk to each other in attention. This is called “specialization.”
- They tested different choices:
- Which layers to specialize (normalization, the early Q/K/V projections, etc.)
- Which parts (early, middle, or late layers) of the model to specialize
- Different model sizes and training styles
Importantly, these changes add only about 8% more parameters and do not add extra computation at inference time (so it doesn’t run slower).
What did they find, and why is it important?
Main results:
- Better local features for dense tasks:
- The model gets notably better at segmentation (drawing correct shapes of objects). On standard benchmarks, scores go up by more than 2 mIoU points (that’s a meaningful boost).
- Depth estimation (guessing how far things are) also improves.
- Classification stays strong:
- The ability to recognize what’s in an image remains about the same.
- What matters most:
- Specializing the normalization layers already helps.
- Specializing the early Q/K/V projections (the “who to listen to / what I know / what I share” notes) helps even more.
- Specializing too late in the model or specializing the MLP layers doesn’t help much and can sometimes hurt.
- Works broadly:
- The gains show up across different model sizes and training methods (self-supervised DINOv2 and supervised DeiT-III).
- Improvements appear early in training and keep growing, suggesting more stable learning.
Why this matters:
- Many real-world problems need detailed, pixel-level understanding: self-driving cars (finding roads, lanes, and pedestrians), medical imaging (spotting regions in scans), and robotics (understanding object shapes). Better patch features make these tasks more accurate.
- The trick is simple and efficient: small changes, no extra slowdown, and steady gains.
What does this mean for the future?
- Design insight: Class tokens and patch tokens play different roles. Giving them slightly different processing paths—especially in normalization and early attention projections—helps them cooperate better.
- Practical impact: You can get significantly better dense predictions without paying more in compute at run time. That’s valuable for deploying AI in devices and services where speed matters.
- Next steps: The authors hint at even lighter ways to add specialization (like low-rank adaptations) to keep the parameter increase small while preserving the gains.
In short, the paper shows that treating the “summary” token and the “patch” tokens differently in the right places makes Vision Transformers noticeably better at understanding image details, with almost no downside.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Based on the provided research paper, here is a list of knowledge gaps, limitations, and open questions that future researchers could explore:
- Token Specialization Across Different Models: The paper focuses on Vision Transformers (ViTs). How would the proposed token specialization approach apply to other transformer architectures or hybrid models that integrate convolutional layers?
- Impact on Training Efficiency: The paper suggests that specialization has no additional computational overhead during inference. What is its impact on the training time or resource consumption, especially for very large datasets like ImageNet-$22$K?
- Broader Applicability Across Tasks: While improvements in specific tasks like segmentation, depth estimation, and classification are reported, how generalizable are these improvements to other tasks, such as video processing or cross-modal tasks (e.g., vision-language tasks)?
- Granular Analysis of Layer Specialization: The paper explores layer specialization broadly but does not deeply examine the granularity of such specialization within individual components of attention and MLP layers. Can further granularity in specialization yield additional performance gains?
- Impact on Model Robustness: There is no discussion on how the specialization strategy affects model robustness to adversarial attacks or noisy data. Can specialized models retain robustness compared to non-specialized counterparts?
- Scaling Laws with Specialization: The effect of model size on the success of the specialization strategy is not fully explored. How do the proposed modifications interact with known scaling laws in transformer architectures?
- Trade-offs Between Global and Local Features: The research mentions slightly detrimental effects on classification tasks. An analysis is needed to understand the trade-offs between enhancing dense features and possibly sacrificing global feature representation quality.
- Impact on Interpretability and Explainability: Introducing specialized pathways could affect model interpretability. How do these architectural changes influence the ability to interpret the decisions made by the model?
- Potential of Low-Rank Approximation Approaches: The paper mentions preliminary results with Low Rank Adaptation (LoRA) for memory cost mitigation. Could more in-depth exploration of this approach lead to better efficiency gains?
- Long-term Effects and Saturation Point: Over longer training durations or iterations, what are the limits or saturation points of the performance benefits gained through the proposed specialization technique?
By addressing these gaps and questions, future research can further advance the understanding and application of specialized token processing in Vision Transformers and related architectures.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s findings (token-type specialization in ViTs—separate normalization and early QKV projections, especially in the first third of the network) to improve dense prediction performance without adding inference FLOPs and with a modest (~8%) parameter increase.
- Semantic segmentation upgrades in production vision stacks
- Sector: Automotive/Robotics, Smart Cities, Geospatial, Manufacturing
- What: Swap in a specialized-ViT backbone (norms specialized across all blocks + QKV specialized in the first third) to gain +1–2.2 mIoU on standard segmentation benchmarks at the same compute cost.
- Tools/Workflows:
- A “SpecViT” backbone variant in PyTorch/timm with SpecializedLayerNorm and SpecializedQKV modules; checkpoint converter to initialize specialized weights from existing ViT backbones and fine-tune.
- Training recipe: DINOv2-style pretraining (or DeiT-III supervised) + attention bias + normalization specialization in all blocks + QKV specialization in first 1/3 of blocks.
- Assumptions/Dependencies: Requires fine-tuning or pretraining with the specialized layers (cannot be a purely inference-time patch); benefits demonstrated on ViT-style models with a [CLS] token; domain shift may change gains.
- Depth estimation improvements for navigation and mapping
- Sector: Robotics, AR/VR, Construction, Drones
- What: Use specialized-ViT features to reduce RMSE on KITTI/NYU/SUN (paper shows consistent ↓RMSE) for better SLAM, obstacle avoidance, and scene reconstruction.
- Tools/Workflows: Replace standard ViT features in depth heads with specialized features; keep same inference budget.
- Assumptions/Dependencies: Gains reported via linear probing; end-to-end training may further change outcomes; requires ViT backbones.
- Better detection and scene understanding with foundation backbones
- Sector: Retail analytics, Warehousing, Smart factories, Media safety
- What: Stronger local features (patch tokens) improve detectors/segmenters plugged into a shared backbone (COCO AP gain indicated).
- Tools/Workflows: Fine-tune detect/segment heads (e.g., Mask R-CNN/DETR variants) on top of specialized ViT features; no change to inference FLOPs.
- Assumptions/Dependencies: Detector compatibility; small memory headroom for +8% params; retraining/fine-tuning needed.
- Medical and scientific image segmentation with minimally invasive changes
- Sector: Healthcare, Life Sciences
- What: Improved patch locality benefits organ/tissue/cell segmentation under constrained compute budgets.
- Tools/Workflows: Fine-tune specialized ViT backbones on domain datasets (e.g., histopathology, microscopy) with linear probes or lightweight heads.
- Assumptions/Dependencies: Regulatory/validation processes; data-specific pretraining may be needed; [CLS]-token–based ViTs preferred.
- Remote sensing and agriculture segmentation at scale
- Sector: Energy, Climate/Environment, Agriculture
- What: Land-cover/land-use mapping gains via stronger dense features without higher inference cost; good for large-scale tiling/streaming pipelines.
- Tools/Workflows: Integrate SpecViT into geospatial toolchains; batch inference unchanged; retrain head only.
- Assumptions/Dependencies: Satellite/airborne domain shift; may need domain-adaptive pretraining.
- On-device AR background/foreground matting and object masking
- Sector: Consumer software, Mobile, AR/VR
- What: Better segmentation quality for live effects, portrait mode, and virtual try-on at the same energy profile.
- Tools/Workflows: Replace ViT backbone in mobile segmentation models with specialized variant; keep input resolutions and latency identical.
- Assumptions/Dependencies: Mobile frameworks must support the slightly larger checkpoint; same FLOPs but memory ~+8%.
- Industrial inspection and defect localization
- Sector: Manufacturing, Quality Control
- What: Enhanced patch locality raises sensitivity to fine defects (scratches, cracks) without increasing runtime costs on production lines.
- Tools/Workflows: Plug specialized ViT backbone into existing anomaly/defect segmentation heads.
- Assumptions/Dependencies: Retraining/fine-tuning necessary; lighting/domain specifics.
- Data-centric annotation acceleration
- Sector: Data Ops, MLOps
- What: Higher-quality patch features improve interactive segmentation and pseudo-label generation, reducing annotation time/cost.
- Tools/Workflows: Use specialized backbones in labeling tools (e.g., auto-seg proposals); human-in-the-loop QA.
- Assumptions/Dependencies: Tooling integration; performance measured on target domains.
- Academic reproducibility and model analysis
- Sector: Academia/Research
- What: Adopt the paper’s similarity analysis (pre/post-LN), token-wise dimension diagnostics, and ablations to study token roles.
- Tools/Workflows: Release of analysis scripts to compute [CLS]-patch vs patch-patch cosine similarity across blocks; LayerNorm/QKV specialization toggles for controlled studies.
- Assumptions/Dependencies: Access to checkpoints/logs; standard ViT blocks.
- Cost/performance optimization for vision services
- Sector: Cloud/Platforms
- What: Achieve higher dense-task accuracy at fixed FLOPs, avoiding model scaling or expensive multi-pass inference.
- Tools/Workflows: A/B rollout of specialized backbones; same autoscaling targets; SLA unchanged.
- Assumptions/Dependencies: Memory budget allows +8% parameters; observability for head-to-head evaluations.
Long-Term Applications
These opportunities require further research, scaling, or engineering—e.g., broader architectures, multimodal extension, or standardization.
- Generalized token-type specialization across modalities
- Sector: Multimodal AI (Vision–Language, Vision–Audio)
- What: Extend token specialization to separate global vs local (and cross-modal) tokens in CLIP/SigLIP/LLM-vision stacks for improved grounding and dense captioning.
- Tools/Products: Specialized QKV and normalization for modality-specific token streams; multi-head “role-aware” attention.
- Dependencies: Evidence across multimodal benchmarks; rethinking models that lack a [CLS] token.
- Hierarchical and non-standard ViTs (e.g., Swin, ConvNeXt-Transformer hybrids)
- Sector: Software/Frameworks
- What: Port specialization to hierarchical transformers (windowed attention) and hybrid backbones; study where to specialize given different block designs.
- Tools/Products: Auto-search (NAS/AutoML) for “which layers/blocks to specialize” under varying architectures.
- Dependencies: Architectural differences (no explicit class token, pooled global tokens); benchmarking across tasks.
- Auto-specialization policies learned during training
- Sector: MLOps/AutoML
- What: Learn the optimal subset of blocks/layers to specialize (e.g., policy gradients or differentiable masks), balancing memory budget and gains.
- Tools/Products: Budget-aware training schedulers; constraint-driven specialization (e.g., edge vs cloud).
- Dependencies: Stability of training with dynamic specialization; interpretability.
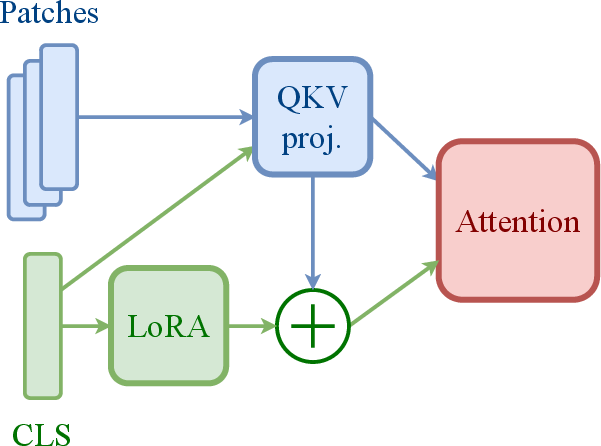
- Low-Rank Adaptation (LoRA) for specialization at fine-tuning time
- Sector: Enterprise AI, Edge AI
- What: Replace full QKV duplication with LoRA-based specialization for minimal parameter growth, enabling quick domain adaptation.
- Tools/Products: “LoRA-SpecViT” adapters; task-specific adapters for segmentation/depth/detection.
- Dependencies: Rank selection trade-offs (paper’s preliminary results suggest promise); robustness under distribution shift.
- Token-role–aware distillation for dense tasks
- Sector: Education/Research, Model Compression
- What: Distill specialized teacher backbones into smaller student models while preserving dense-feature quality (locality).
- Tools/Products: Role-consistent distillation losses (separate for [CLS] vs patches).
- Dependencies: Student architectures may lack explicit [CLS]; alignment losses need tuning.
- Standards and evaluation protocols for dense-feature quality
- Sector: Policy/Standards, Procurement
- What: Define procurement/evaluation checklists (e.g., per-class mIoU at fixed FLOPs; locality diagnostics; artifact detection).
- Tools/Products: Public leaderboards tracking “quality-at-FLOPs” for dense tasks; artifact metrics (e.g., high-norm anomalies).
- Dependencies: Community buy-in; domain-specific benchmarks (medical, geospatial).
- Safer autonomy via improved spatial understanding
- Sector: Autonomous Driving, Drones
- What: Use specialized backbones as a validated component in safety cases (ISO 26262-like), demonstrating better scene parsing at fixed compute.
- Tools/Products: Safety case libraries, formalized performance envelopes under corner cases.
- Dependencies: Extensive validation, scenario coverage, certification processes.
- Privacy-preserving and on-device dense perception
- Sector: Mobile, IoT
- What: Run higher-quality segmentation/depth locally without cloud offload due to unchanged FLOPs; reduce data transmission.
- Tools/Products: Optimized kernels and quantization-aware training for specialized backbones; mobile inference runtimes with memory-aware loading.
- Dependencies: Memory (+8% parameters) and quantization behavior; on-device benchmarking.
- Interactive content creation and video editing
- Sector: Media/Entertainment, Creator Tools
- What: High-fidelity, frame-consistent masks for object/actor editing and effects at constant compute budgets.
- Tools/Products: Video segmentation plug-ins with SpecViT backbones; timeline-aware propagation with stronger patch features.
- Dependencies: Temporal consistency training; long-video efficiency.
- Environmental monitoring and infrastructure inspection at scale
- Sector: Energy/Utilities, Climate Tech
- What: Deploy specialized segmentation for vegetation encroachment, corrosion detection, road asset mapping without increasing fleet compute.
- Tools/Products: Edge-deployable models for drones/vehicles; multi-sensor fusion with specialized visual backbones.
- Dependencies: Domain adaptation, sensor variation, regulatory approvals.
Cross-cutting assumptions and dependencies
- Architectural scope: Benefits rely on ViT-like models with distinct [CLS] and patch tokens; adaptations are needed for architectures without [CLS] or with pooled global tokens.
- Training requirement: Specialization changes weights; gains require (re)training or at least fine-tuning. Paper’s best results come from pretraining recipes (e.g., DINOv2 with attention bias).
- Where to specialize: Most gains come from specializing normalization in all blocks and QKV in the first ~1/3 of blocks; over-specialization (e.g., late MLPs) can be neutral or negative.
- Compute/memory: No inference FLOPs increase; parameter count rises modestly (~8%)—ensure memory budget on edge/mobile.
- Generalization: Improvements reported on IN22k/IN1k pretraining and standard benchmarks (ADE20k, Cityscapes, VOC, KITTI, NYU, SUN, COCO). Domain shifts may require additional pretraining/fine-tuning and validation.
- Interplay with prior fixes: Compatible with registers and attention bias; attention bias used throughout in the strongest results.
- Evaluation nuance: Many gains shown via linear probing. Full end-to-end fine-tuning may change absolute deltas; validate per deployment scenario.
Glossary
- Affine transformation: A linear mapping that preserves points, straight lines, and planes; in LayerNorm, the scale and shift applied per dimension. "it performs a point-wise normalization and a dimension-wise affine transformation."
- Attention bias: A modification to the attention mechanism that adds learned or fixed biases to attention scores to influence token interactions. "we integrate the attention bias strategy, which mitigates high-norm anomalies"
- Attention maps: Visualizations or matrices indicating how strongly tokens attend to each other in self-attention. "the noisy attention maps produced by models trained at scale during longer training periods."
- Average Precision (AP): A detection metric summarizing precision across recall levels; commonly used on COCO. "For detection, we use COCO \citep{lin2014microsoft}, reporting AP."
- Class token ([CLS]): A special learnable token prepended to the sequence to aggregate global information for classification. "averaged over patches and [CLS]—at the output of different blocks."
- Cosine similarity: A measure of similarity between vectors based on the cosine of the angle between them. "We show mean and standard deviation of cosine similarity between [ and all patches, and between all patches."
- Dense prediction tasks: Vision tasks producing per-pixel or per-patch outputs (e.g., segmentation, depth). "gains on dense prediction tasks."
- Depth estimation: Predicting a depth map indicating distance for each pixel in an image. "tasks such as object detection, semantic segmentation or depth estimation."
- Foundation models: Large, general-purpose models pretrained on broad data and transferable to many downstream tasks. "developing vision foundation models capable of generating rich and highly generalizable visual representations"
- Gram anchoring mechanism: A regularization approach that encourages patch feature similarity patterns via Gram matrix constraints. "recovering patch similarity with Gram anchoring mechanism \citep{simeoni2025dinov3}."
- High-norm anomalies: Undesirable tokens with unusually large norms that can destabilize attention and degrade locality. "which mitigates high-norm anomalies \citep{darcet2023vision} without introducing additional tokens,"
- LayerNorm: A normalization technique applied per sample across feature dimensions to stabilize training. "the LayerNorm applied before attention drastically reduces the similarity between [ and patch tokens"
- LayerScale: A learned per-block scaling of residual connections to stabilize deep transformer training. "While certain operations—such as the LayerScale applied post-attention—have little effect"
- Linear probing: Evaluating representations by training a simple linear classifier on frozen features. "we assess model representations via linear probing on global, with ImageNet-1k"
- Low Rank Adaptation (LoRA): A parameter-efficient method that injects low-rank updates into weight matrices to reduce overhead. "Note that we could ease this 8\% memory cost overhead with Low Rank Adaptation used when specializing the QKV projection."
- Masked image modeling: A pretraining objective where patches are masked and the model predicts their content to learn representations. "iBoT \citep{zhou2021ibot} augments DINO with masked image modeling \citep{he2022masked} to optimize both global and local representation."
- Mean Intersection over Union (mIoU): A segmentation metric averaging IoU across classes. "reporting mIoU."
- Multi-head self-attention: The transformer mechanism where multiple attention heads compute token interactions in parallel. "most notably the multi-head self-attention operator"
- Patch embedder: The component that splits an image into patches and maps each to a token embedding. "A typical ViT model consists of a patch embedder and a stack of transformer blocks."
- Patch tokens: Tokens representing local image regions (patches) used by the transformer. "transforms them into patch tokens that represent local information in the image."
- Principal Component Analysis (PCA): A dimensionality reduction technique; here used to visualize feature components. "We display the first PCA components of model outputs in RGB."
- Query–Key–Value (QKV) projections: Linear projections that produce queries, keys, and values for attention computations. "early query-key-value projections."
- Rank collapse: A degeneracy where features lose diversity and occupy a low-dimensional subspace. "prevents rank collapse and promotes a more uniform distribution of tokens on the unit sphere,"
- Registers: Additional storage tokens introduced to the input sequence to stabilize attention and preserve locality. "namely registers (`regs')"
- Semantic segmentation: Assigning a class label to each pixel in an image. "For semantic segmentation, we use ADE20K~\citep{zhou2017scene}, Cityscapes~\citep{cordts2016cityscapes} and PASCAL VOC~\citep{everingham2010pascal}, reporting mIoU."
- Sinkhorn–Knopp centering: A normalization technique using Sinkhorn–Knopp to stabilize and balance features or assignments. "introduces new technical components such as Sinkhorn-Knopp centering and untying heads"
- Transformer blocks: The repeated units in a transformer consisting of attention, MLP, and normalization layers. "a stack of transformer blocks."
- Vision Transformer (ViT): A transformer architecture applied to images by operating on patch embeddings. "Vision Transformer has become an architecture of choice when building vision models."
Collections
Sign up for free to add this paper to one or more collections.

