Accelerating Vision Transformers with Adaptive Patch Sizes
Abstract: Vision Transformers (ViTs) partition input images into uniformly sized patches regardless of their content, resulting in long input sequence lengths for high-resolution images. We present Adaptive Patch Transformers (APT), which addresses this by using multiple different patch sizes within the same image. APT reduces the total number of input tokens by allocating larger patch sizes in more homogeneous areas and smaller patches in more complex ones. APT achieves a drastic speedup in ViT inference and training, increasing throughput by 40% on ViT-L and 50% on ViT-H while maintaining downstream performance, and can be applied to a previously fine-tuned ViT, converging in as little as 1 epoch. It also significantly reduces training and inference time without loss of performance in high-resolution dense visual tasks, achieving up to 30\% faster training and inference in visual QA, object detection, and semantic segmentation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a faster way to run Vision Transformers (ViTs), a popular kind of AI that looks at images. Normally, ViTs split every image into equal-sized squares (called “patches”) and process each patch as a token. That means big, detailed images turn into lots of tokens and take a long time to compute. The authors propose Adaptive Patch Transformers (APT), which uses bigger patches in simple parts of an image (like clear sky) and smaller patches in complex parts (like faces or textures). This keeps the important details while using fewer tokens overall, making ViTs run much faster without losing accuracy.
What questions were the researchers trying to answer?
They wanted to find out:
- Can we make ViTs faster by giving different parts of an image different patch sizes?
- Can this speed-up work on many kinds of tasks (like classification, object detection, and visual question answering) without hurting accuracy?
- Can we add this to existing models and get good results quickly?
How did they do it?
The basic problem with Vision Transformers
ViTs split images into same-sized patches (like a checkerboard). For high-resolution images, this creates a huge number of tokens. Transformers compare tokens with each other, and this gets much slower as the number of tokens grows.
The APT idea: adaptive patch sizes
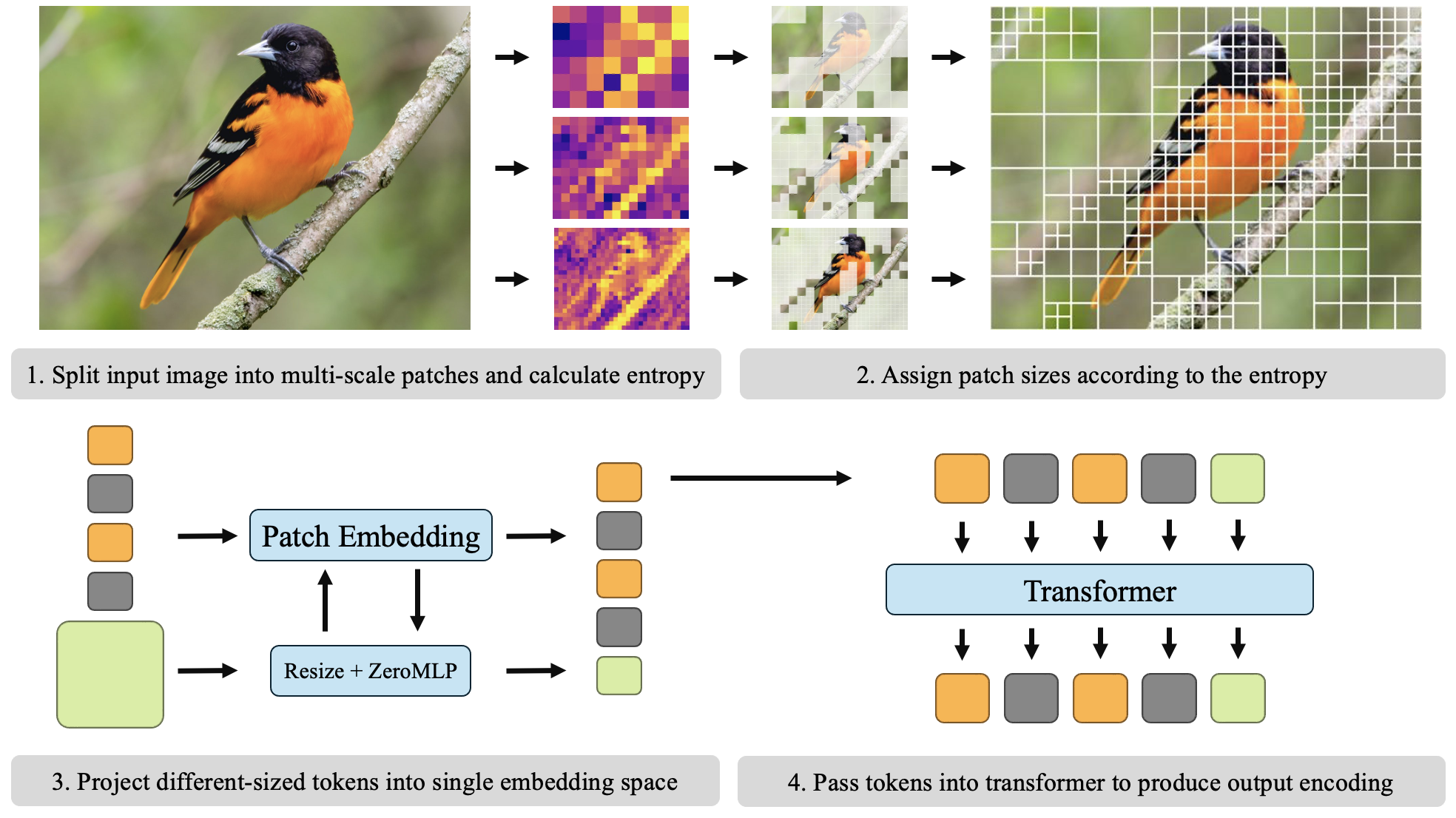
APT splits each image into patches of different sizes based on how “complicated” each region is:
- Simple areas (flat colors, blurry backgrounds) get larger patches (fewer tokens).
- Complex areas (sharp edges, detailed textures) get smaller patches (more tokens where needed).
Think of building a mosaic: you use big tiles for the blue sky and small tiles for a face.
Deciding patch sizes (measuring “complexity” with entropy)
APT measures a patch’s “entropy,” which is a way of saying how unpredictable or detailed its pixel values are:
- Low entropy = simple, predictable (good for big patches).
- High entropy = complex, detailed (needs small patches).
APT checks entropy at multiple scales (big patches, medium patches, small patches) using set thresholds. It keeps big patches where entropy is low and splits the rest into smaller patches. This creates a quadtree-like layout: big squares where it’s simple, small squares where it’s complex.
Turning patches into tokens (patch aggregation)
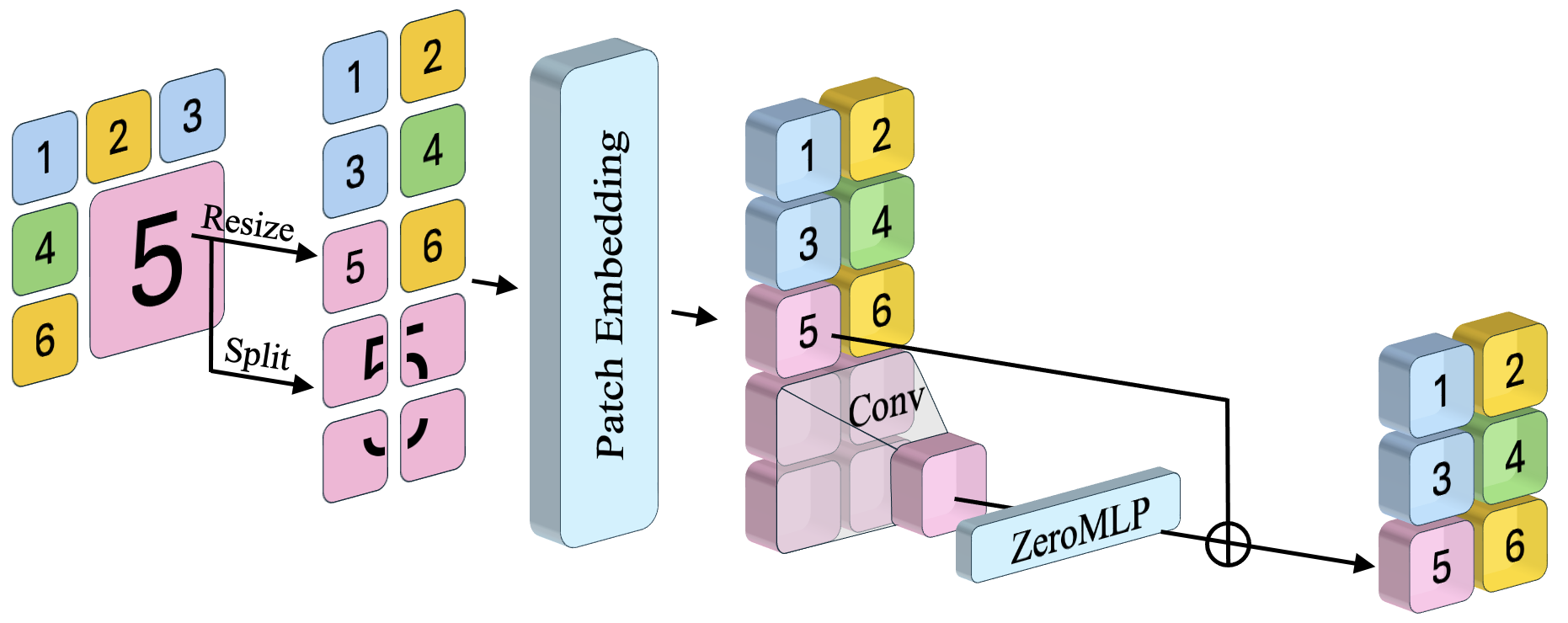
All tokens need to have the same size to fit into a ViT. For big patches, APT does two things:
- Resizes the big patch down to the base size (like shrinking it).
- Also splits the big patch into smaller sub-patches, embeds those, and combines them using a small layer (a convolution followed by a tiny neural network).
That tiny network starts with zero weights (“ZeroMLP”), meaning at first it does nothing—so the model behaves safely like a simple resize. Then, with a little fine-tuning, it learns to add useful high-resolution details without messing up the original model’s behavior.
Handling different numbers of tokens (sequence packing)
Since each image now has a different number of tokens, APT packs tokens from multiple images together into one sequence and uses attention masks so tokens only look at tokens from their own image. This lets the model process variable-length inputs efficiently, using existing fast attention libraries.
Using APT for other tasks (dense visual tasks)
Tasks like object detection and segmentation need feature maps that match the image shape. APT repeats tokens from big patches to rebuild a rectangular feature map, keeping everything differentiable and compatible with common methods (including windowed attention used in fast detectors).
What did they find?
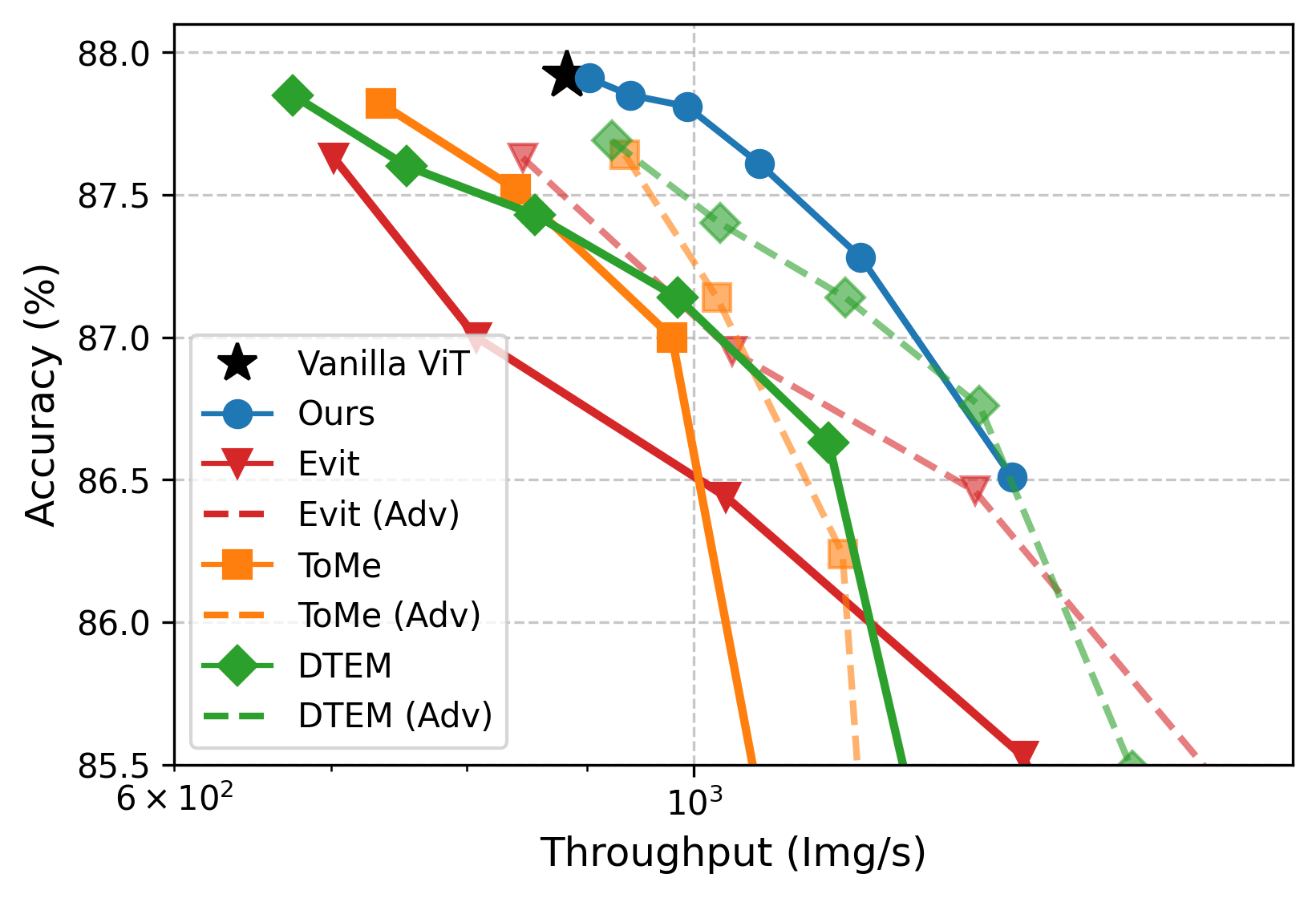
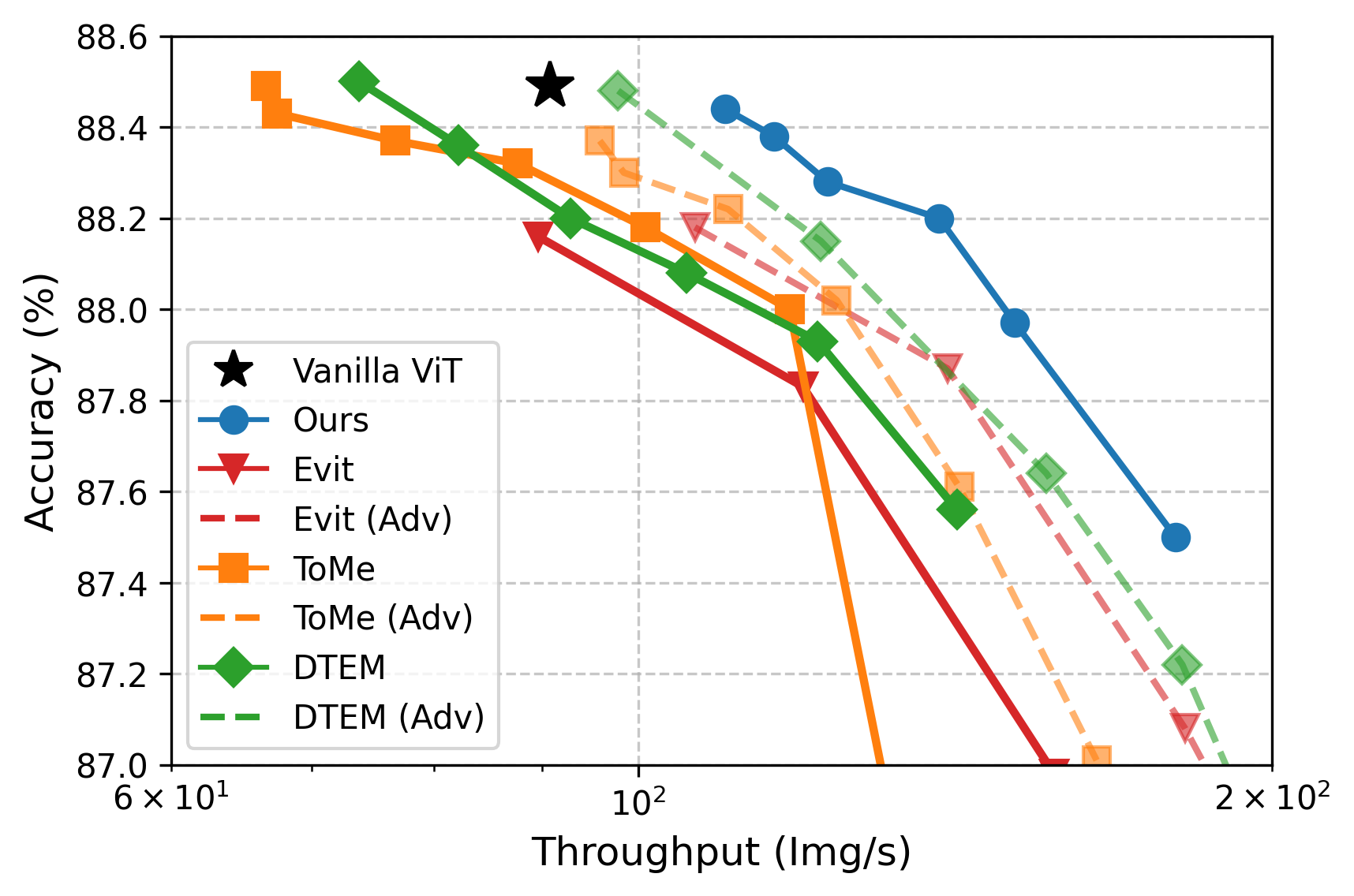
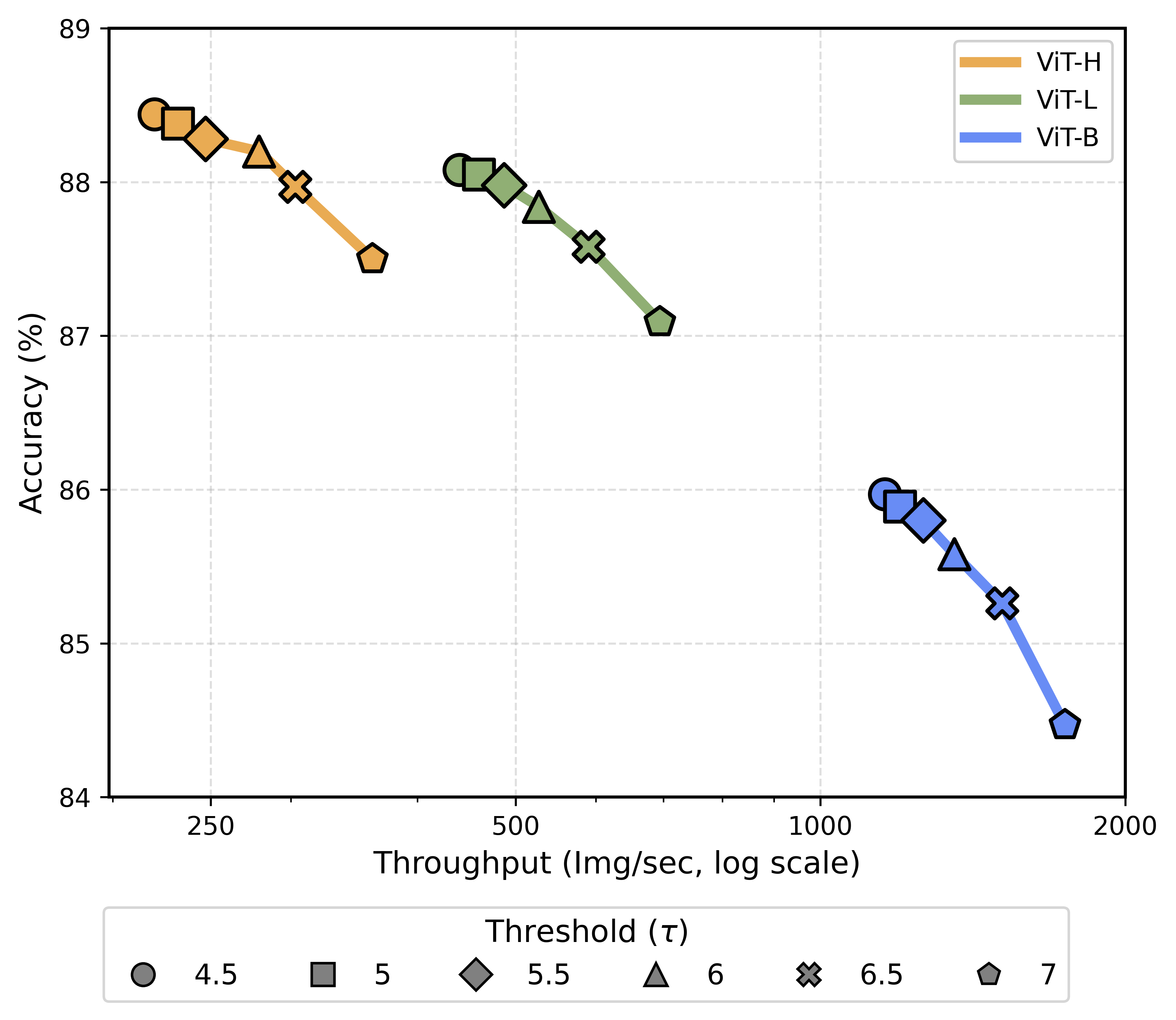
APT speeds up ViTs a lot while keeping accuracy:
- Image classification (ImageNet):
- ViT-L: About 40% faster training/inference at higher resolutions, with matching accuracy.
- ViT-H: Up to ~50% faster while preserving accuracy.
- If you already have a fine-tuned model, APT can match the original accuracy after just 1 extra epoch of fine-tuning.
- Visual Question Answering (LLaVA models):
- Around 22–26% faster throughput and equal or slightly better scores on multiple benchmarks.
- Object detection (COCO) and semantic segmentation (ADE20K):
- Up to ~30% faster training/inference on high-resolution inputs, with matching mean Average Precision (mAP) and mean Intersection-over-Union (mIoU).
Why this matters: These are real speedups in wall-clock time (the actual time it takes to run), not just theoretical savings. And they hold across big models and high-resolution inputs—exactly where ViTs are slowest.
Why does this matter?
- Faster models: APT cuts down the number of tokens by spending less effort on simple regions and more on complex ones, speeding up both training and inference.
- Lower cost and energy: Less compute means cheaper and greener AI.
- Plug-and-play: You can apply APT to existing ViTs and recover accuracy in as little as one epoch.
- Works across tasks: It helps classification, vision-LLMs, detection, and segmentation without sacrificing quality.
- Inspired by language tokenizers: Just like text models use variable-length tokens (e.g., Byte Pair Encoding) to be efficient, APT brings that smart idea to images.
Any limitations?
- Hand-crafted thresholds: APT uses a rule-based measure (entropy) and thresholds to choose patch sizes. That may not always match what a user cares about (for example, a simple background might still be semantically important).
- Focused on understanding, not generation: The paper doesn’t cover image generation tasks.
- Best for large models and high-res images: That’s where the biggest wins show up.
Overall, APT shows a practical, content-aware way to make Vision Transformers faster by adapting patch sizes to the image, unlocking big speedups while keeping accuracy across many important tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and unresolved questions to guide future research.
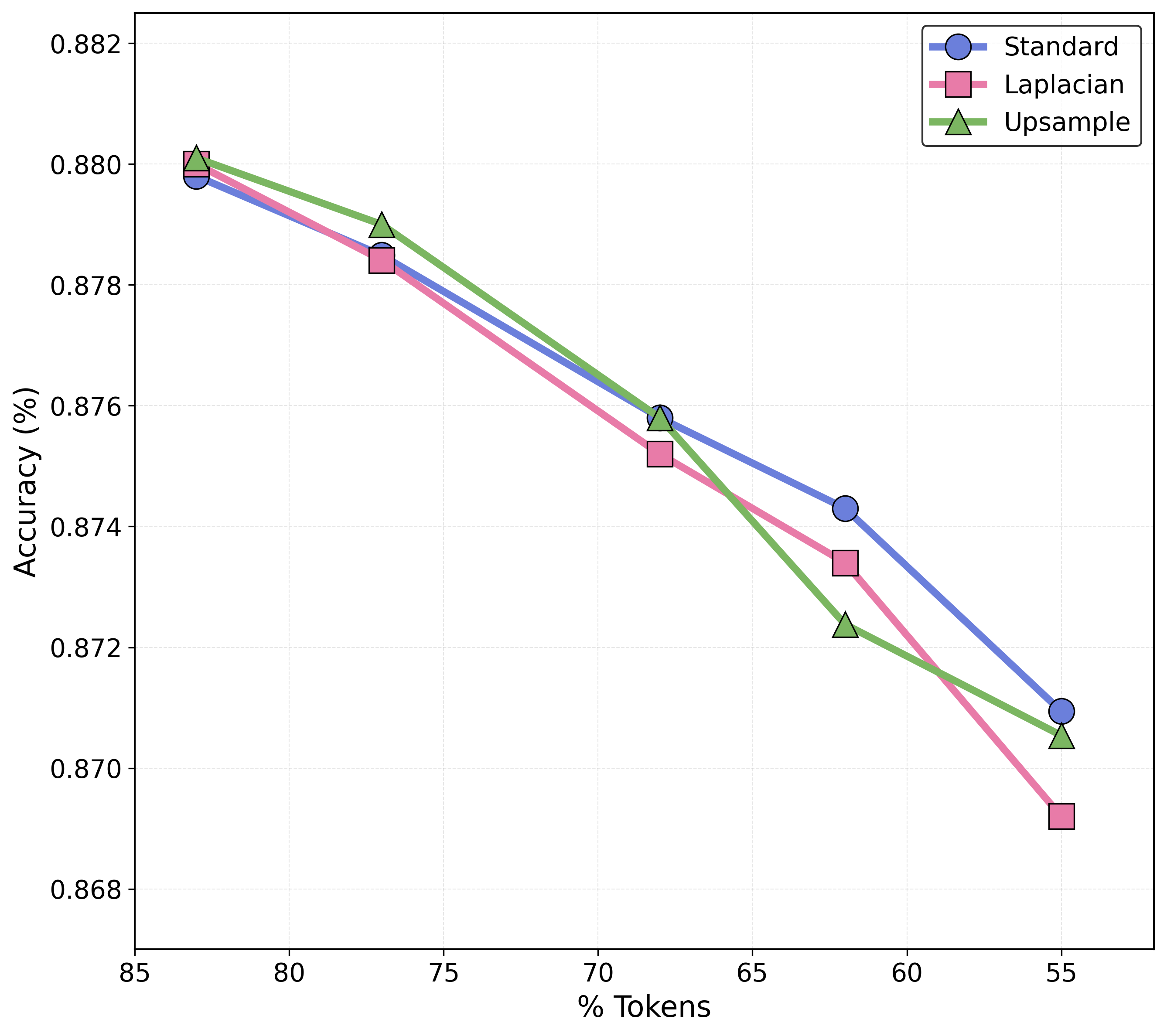
- Patch-size selection relies on hand-crafted entropy thresholds per scale; there is no principled or learned mechanism to set or adapt these thresholds to the dataset, task, or individual image, nor any procedure to optimize them jointly with the backbone.
- The entropy measure is based on binned pixel intensities, but the paper does not specify the color-space, channel handling, or robustness to photometric changes (e.g., gamma, white balance, JPEG artifacts). How do alternative complexity metrics (e.g., local variance, gradient magnitude, texture descriptors, learned saliency, task-conditioned importance) affect speed–accuracy trade-offs?
- APT uses a quadtree-like regular grid constraint for patch layouts; the impact of this constraint on representing thin structures, diagonals, or semantically coherent but non-axis-aligned regions is untested.
- The zero-initialized MLP plus Conv2d aggregator is chosen heuristically; there is no comparison to attention-based multi-scale aggregation, gating, or dynamic weighting schemes, nor analysis of when resizing versus sub-patch aggregation dominates performance.
- No theoretical analysis relates patch entropy thresholds to bounds on information loss or task error; can we derive guarantees on accuracy preservation as a function of token reduction?
- Token repetition for dense tasks (replicating large-patch tokens to form rectangular feature maps) may introduce block artifacts or bias boundary localization; a quantitative analysis of boundary quality, small-object recall, and per-class impacts is missing.
- Small-object detection and segmentation breakdowns (e.g., APs by object size, mIoU near thin boundaries) are not reported; does APT disproportionately affect small or high-frequency content?
- Effects on model calibration, uncertainty estimates, and worst-case behaviors (e.g., adversarial textures, moiré patterns, adversarial patch placement) are not studied.
- APT’s patch allocation is task-agnostic; for VQA and other conditional tasks, the allocation is not question-aware. Can we condition patch sizes on downstream queries or attention signals without sacrificing speed?
- Robustness to domain shift is untested: how do thresholds and entropy-based allocation generalize to medical, satellite, night-time, or heavily compressed images?
- The number of scales S and base patch size p are not systematically ablated; what are optimal configurations by task, model scale, and resolution?
- APT is evaluated primarily on MAE-pretrained ViTs; there is no study of pretraining with APT from scratch (self-supervised or supervised), nor of how token reduction interacts with masking-based pretext tasks.
- The sequence packing approach is validated with FlashAttention/xFormers but lacks evaluation across diverse hardware stacks (e.g., TPU, mobile GPUs, CPU inference), distributed training settings, and mixed-precision regimes that may suffer from variable-length batching overheads or memory fragmentation.
- Overhead analyses are limited to throughput comparisons; a detailed breakdown of (1) entropy computation cost, (2) patch packing/masking cost, and (3) memory footprint/peak VRAM under various batch-size/token-length distributions is missing.
- Interactions with common data augmentations (RandAugment, MixUp, CutMix, random cropping/resizing) are not analyzed; does adaptive patchification before/after augmentation change outcomes or introduce biases?
- APT shows modest gains at low resolution/small models; guidelines for when APT is beneficial (resolution/model-size thresholds, expected speedups vs. accuracy risk) are not formalized.
- Window attention integration is demonstrated but not extensively characterized; how do window sizes, overlaps, and hierarchical backbones (e.g., Swin-like pyramids) interact with variable token layouts and packing masks?
- Baseline re-implementations required disabling weighted attention to enable FlashAttention; a comprehensive apples-to-apples comparison with baselines in their native optimized settings (including kernel fusion and custom CUDA) is missing.
- The method does not support image generation; how could adaptive patch sizes integrate with DiT, VQ-VAEs, or latent tokenizers while preserving training stability and generation quality?
- APT is evaluated on images; extension to video (spatiotemporal tokenization, motion-aware allocation, temporal consistency across frames) is left open.
- Energy efficiency and carbon footprint are not reported; do speedups translate to power savings across hardware, and what is the overhead of entropy computation relative to these gains?
- Fairness and demographic bias implications are not explored; does content-aware token reduction disproportionately simplify backgrounds in ways that affect answers or detections for certain groups or contexts?
- The paper does not evaluate failure modes where images are extremely complex everywhere (minimal token reduction) or deceptively homogeneous (over-aggressive reduction); a stress-test suite and adaptive fallback strategies are needed.
- There is no exploration of learning patch-size policies end-to-end (e.g., via reinforcement learning, differentiable gating, or meta-learning) while maintaining inference-time regularity and speed.
- Determinism and reproducibility under variable-length tokenization are not discussed; how do randomness in thresholding, packing order, or non-deterministic kernels affect exact reproducibility in training and inference?
- Integration with caching in multimodal LMs (e.g., reusing visual tokens across turns) and the effect of reduced visual tokens on cross-attention latency and memory reuse are not measured.
- Security implications are unaddressed; can an attacker manipulate patch allocation (e.g., by injecting textures) to degrade performance or cause targeted errors?
- Guidance for practitioners on threshold tuning (automatic calibration, validation-time search, per-dataset presets) is missing; a plug-and-play recipe for robust deployment is needed.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating APT’s adaptive patchification (entropy-based multi-scale patches + zero-initialized MLP aggregation) and sequence packing into existing Vision Transformer pipelines. Reported speedups: 20–50% throughput on classification/VLMs and up to ~30% on detection/segmentation without accuracy loss after ≤1 epoch fine-tuning.
- Cloud-scale vision services (software, media, retail)
- Use cases: image moderation, product search/recommendation, similarity retrieval, ad creative QA, catalog deduplication, visual A/B testing.
- Tools/workflows: swap standard ViT patchify() with APT preprocessor; enable FlashAttention/xFormers; tune per-scale entropy thresholds to target SLA; 1-epoch fine-tune to recover baseline accuracy; deploy with sequence packing to maximize GPU utilization for variable token lengths.
- Dependencies/assumptions: pretrained ViT backbones; attention backend supporting block-diagonal masks; ops engineered for variable-length sequences; modest engineering to pack sequences end-to-end.
- Vision–language assistants (education, customer support, enterprise knowledge)
- Use cases: faster visual Q&A in LLaVA-style systems; product troubleshooting via uploaded images; educational tutoring with diagrams.
- Tools/workflows: insert APT before vision encoder; keep LLM unchanged; benefit carries through cross-attention due to fewer visual tokens.
- Dependencies/assumptions: VLM architecture exposes vision encoder; brief fine-tune of zero-MLP; prompt-time variability in token counts handled by batching/packing.
- Industrial inspection and manufacturing QA (manufacturing)
- Use cases: high-resolution defect detection on PCBs, textiles, wafers; line-speed visual QA.
- Tools/workflows: integrate APT into ViTDet/Detectron2/MMDetection backbones; for dense heads, use APT’s token-to-feature-map repetition to preserve spatial topology; window attention remains compatible.
- Dependencies/assumptions: high-res inputs (where APT yields largest gains); threshold calibration to avoid missing fine defects; real-time constraints require profiling.
- Remote sensing and geospatial analytics (energy, agriculture, climate, public sector)
- Use cases: land-cover segmentation, change detection, asset monitoring, disaster assessment at large scales.
- Tools/workflows: apply APT to segmentation/detection backbones (UperNet, ViTDet) with window attention; target large tiling sizes (e.g., 1024–2048).
- Dependencies/assumptions: entropy thresholds may need per-sensor calibration; geospatial pre-processing pipeline must preserve patch grid alignment.
- Medical imaging research and tooling (healthcare; non-clinical immediate use)
- Use cases: faster training/inference for segmentation in histopathology, retinal fundus, or CT slice selection; accelerating annotation tools.
- Tools/workflows: plug APT into ViT backbones for research segmentation frameworks; enable sequence packing on multi-resolution slides.
- Dependencies/assumptions: research setting only (clinical deployment requires validation/regulatory approval); ensure thresholds preserve small lesions; handle very high-res WSIs with tiling.
- Autonomous robotics, drones, and warehouse perception (robotics, logistics)
- Use cases: on-edge high-res detection/segmentation to increase FPS or reduce power; mixed-complexity scenes benefit from adaptive tokens.
- Tools/workflows: APT with window attention; quantization + APT for edge accelerators; profile entropy thresholds under motion blur/lighting changes.
- Dependencies/assumptions: edge runtimes must support attention masks/packing; memory fragmentation control for variable sequences; robust tuning under domain shifts.
- Document AI and eKYC (finance, public sector, enterprise)
- Use cases: OCR layout analysis, ID/passport verification, form understanding at high DPI; faster processing of scans.
- Tools/workflows: integrate APT into ViT-based document models; lean on large patches for homogeneous backgrounds while preserving small text with small patches.
- Dependencies/assumptions: careful thresholds to protect tiny fonts/security microprint; pipeline must accept variable token counts.
- AR/VR scene understanding (consumer electronics, gaming)
- Use cases: on-device segmentation/detection for overlays; faster environment understanding at higher resolution budgets.
- Tools/workflows: APT in ViT backbones with tiling/windows; dynamic thresholds linked to device thermals or battery.
- Dependencies/assumptions: mobile frameworks (e.g., Metal/NNAPI) need support for variable-length attention; export through ONNX/TensorRT with dynamic shapes.
- Sustainability and cost optimization (cross-sector, policy-adjacent)
- Use cases: immediate GPU-hour and energy savings for ViT training/inference; greener AI reporting.
- Tools/workflows: MLOps “efficiency toggle” exposing APT thresholds to choose speed–accuracy tradeoffs; dashboards tracking tokens-per-image and energy per inference.
- Dependencies/assumptions: organizational willingness to adjust SLAs; monitoring to prevent accuracy regressions on complex inputs.
- Academic acceleration and democratization (academia, education)
- Use cases: faster reproduction of ViT baselines; larger-batch, higher-resolution experiments on modest budgets; teaching labs on adaptive tokenization.
- Tools/workflows: open-source APT integration for timm/Transformers; recipes for 1-epoch convergence; ablation kits for entropy thresholds and zero-MLP.
- Dependencies/assumptions: availability of FlashAttention/xFormers; basic GPU memory headroom for sequence packing.
- Consumer/daily-life apps
- Use cases: faster on-device photo categorization and search; smart home camera analytics with lower latency; accessibility apps answering questions about images.
- Tools/workflows: bundle APT-enabled ViT encoders in mobile apps; adaptive thresholds driven by device performance.
- Dependencies/assumptions: mobile backends with dynamic-shape attention; privacy constraints for on-device processing.
Long-Term Applications
These opportunities require further research, engineering, or ecosystem support (compilers, hardware, standards), or domain-specific validation.
- Learned patch policies and task-aware tokenization (software, academia)
- Concept: replace hand-tuned entropy thresholds with learned gates or RL to optimize speed–accuracy per task/user intent.
- Potential products: Auto-APT calibrators; task-aware adaptive tokenizers akin to BPE for vision.
- Dependencies/assumptions: stable training for gating; avoiding train-time overhead; robustness to distribution shift.
- Video and spatiotemporal adaptive tokenization (media, robotics, autonomous driving)
- Concept: extend APT to time with motion-aware entropy, reusing tokens for static regions; adaptive streaming perception.
- Potential products: real-time AV perception with content-aware compute; video analytics platforms with token budgets.
- Dependencies/assumptions: efficient temporal packing and caching; compatibility with video attention/backbones; rigorous safety validation.
- Hardware/compiler co-design for adaptive sequences (semiconductors, cloud)
- Concept: inference engines optimized for variable-length attention, block-diagonal masks, and quadtree patch flows.
- Potential products: TensorRT/TVM passes for APT; GPU schedulers minimizing fragmentation; memory-planning for dynamic batches.
- Dependencies/assumptions: vendor support for dynamic-shape kernels; standardized mask formats; profiling-guided compilers.
- Foundation and multimodal models with adaptive vision tokens (software, education, enterprise)
- Concept: APT as default vision front-end in VLMs to reduce visual tokens entering cross-attention; early-fusion multi-scale encoders.
- Potential products: Efficient multimodal assistants (education, enterprise search) with lower latency and cost.
- Dependencies/assumptions: retraining or careful adaptation of alignment layers; evaluation on broad multimodal benchmarks.
- High-stakes domains: clinical imaging and regulated industries (healthcare, aerospace)
- Concept: production-grade APT for diagnostic support (e.g., pathology WSI triage), satellite/aerial safety monitoring.
- Potential products: FDA/CE-cleared modules; certified geospatial analytics with adaptive compute.
- Dependencies/assumptions: exhaustive validation to ensure small critical features aren’t lost; regulatory approvals; robust fail-safes (e.g., fallback to fine patches).
- Automotive ADAS/AV efficiency (mobility, energy)
- Concept: content-aware compute allocation reduces power draw and increases FPS; dynamic patch budgets tied to scene complexity.
- Potential products: perception stacks with energy-aware APT controllers; eco modes for EVs.
- Dependencies/assumptions: real-time deterministic latency; safety cases; integration with sensor fusion.
- Privacy-preserving adaptive vision (policy, security)
- Concept: systematically coarsen background regions while preserving foreground detail, reducing exposure of bystanders.
- Potential products: privacy filters in cameras and body-worn devices; compliance toolkits.
- Dependencies/assumptions: formal privacy guarantees; task-specific policies; user/legislative acceptance.
- Standards, benchmarks, and green AI policy (policy, academia, industry consortia)
- Concept: benchmarks reporting tokens-per-image and energy/inference; procurement guidelines encouraging adaptive compute.
- Potential products: “Adaptive Tokenization Scorecards”; sustainability certifications for CV systems.
- Dependencies/assumptions: community consensus on metrics; third-party auditing.
- APT-as-a-Service and MLOps controllers (software, cloud)
- Concept: managed service that instruments models, auto-tunes thresholds to meet latency/accuracy SLOs, and performs canary rollouts.
- Potential products: drop-in SDKs for PyTorch/ONNX; cost-aware schedulers that mix APT and standard ViT per request.
- Dependencies/assumptions: robust observability; tenant isolation; dynamic routing overhead doesn’t offset gains.
- Consumer-grade camera pipelines (mobile, AR)
- Concept: system camera frameworks with adaptive patch front-ends for on-device understanding (scene categorization, segmentation for effects).
- Potential products: OS-level APIs exposing variable-resolution compute; battery-aware visual processing.
- Dependencies/assumptions: OEM adoption; mobile accelerators with dynamic-shape attention; UX studies on quality trade-offs.
Notes on feasibility across all items:
- APT benefits grow with resolution/model size; low-res scenarios may see smaller gains.
- Requires attention backends that support packed variable-length sequences and stable mask semantics.
- Thresholds are the main tuning knob; miscalibration can harm small-object fidelity—include guardrails/fallback to smaller patches where uncertainty is high.
- Current method targets vision understanding; generation models need separate adaptation.
- Engineering for dynamic shapes (compilers, batching, memory) is critical to realize wall-clock gains in production.
Glossary
- Adaptive Patch Transformer (APT): A content-aware method that varies patch sizes within an image to reduce tokens and accelerate ViT training and inference. "We introduce the Adaptive Patch Transformer (APT), which addresses this mismatch by varying patch sizes within a single image."
- AP50: Average precision at a 50% intersection-over-union threshold, a common detection metric. "while matching the final performance on mAP and AP50."
- Block-diagonal mask: An attention mask structured so tokens only attend within their own example when sequences are packed together. "construct a block-diagonal mask that ensures tokens only attend to tokens from the same example."
- Byte-Pair Encoding (BPE): A subword tokenization algorithm that merges frequent byte pairs to form tokens of variable length. "LLMs rely on adaptive tokenizers such as Byte-Pair Encoding \citep{sennrich-etal-2016-neural} and SentencePiece \cite{kudo-richardson-2018-sentencepiece}"
- Class token: A special token used by ViTs to aggregate image information for classification. "After running the network, we split the resulting sequence into its constituent subsequences and either extract the class token or compute a pooled representation for each subsequence."
- ControlNet: A generative modeling technique that adds conditioning via zero-initialized layers to avoid harming pre-trained behavior. "The \text{ZeroMLP}, a single linear layer initialized with zero weights inspired by ControlNet~\citep{zhang2023controlnet}, allows the model to gradually incorporate high-resolution details..."
- Convolutional downsampling layer: A convolutional operation applied repeatedly to reduce spatial resolution while aggregating features. "applying a convolutional downsampling layer times, aggregating embeddings from sub-patches back to size ."
- Cross attention: An attention mechanism that relates tokens across modalities (e.g., vision and language) in VLMs. "it accelerates both the vision backbone and cross attention layers."
- Dense visual tasks: Vision problems requiring per-pixel or region-level predictions, such as detection and segmentation. "Standard methods for dense visual tasks like object detection or semantic segmentation often rely on a feature map that has the same aspect ratio as the image."
- Entropy: A measure of unpredictability in pixel intensity distributions used to assess patch compressibility. "We use entropy as a measure of a patch's compressibility, given by:"
- Entropy threshold: A tunable cutoff determining which patches are treated as low-entropy (compressible) at each scale. "The main tunable parameter in APT is the entropy threshold, which can differ per scale and controls how compressible a region must be in order to be retained."
- FlashAttention: A fast, memory-efficient attention kernel optimized for GPUs. "This is natively implemented in commonly available attention backends such as FlashAttention \citep{dao2022flashattention, dao2023flashattention2} or xFormers \citep{xFormers2022}"
- FLOPs: Theoretical count of floating-point operations used to estimate computational cost. "While these reduce theoretical FLOPs, they face two drawbacks."
- Gating network: A learned module that decides which patches or sizes to use dynamically. "which, like DynamicViT \citep{rao2021dynamicvit} learns a gating network to determine patch sizes and defines separate patch embedding networks for each size."
- Latent space: A compressed representation space where images are mapped by tokenizers or autoencoders. "to project images into a compressed latent space, reducing the input size significantly."
- Masked Autoencoders (MAE): A self-supervised training approach that reconstructs masked portions of the input. "We use the MAE~\citep{MaskedAutoencoders2021} training recipe for all cases."
- mAP: Mean Average Precision, a standard metric summarizing detection performance across IoU thresholds. "while matching the final performance on mAP and AP50."
- mIoU: Mean Intersection-over-Union, a segmentation metric averaging IoU over classes. "aAcc & mIoU \"
- Patch embedding: The linear projection that converts image patches into token embeddings for the transformer. "train separate patch embedding layers for each possible patch size"
- Patchification: The process of partitioning an image into patches that become tokens. "This content-aware patchification preserves important information where it matters while reducing redundancy elsewhere."
- Pooled representation: An aggregated feature vector computed from tokens to represent an image or subsequence. "either extract the class token or compute a pooled representation for each subsequence."
- Quadtree-like structure: A hierarchical grid constraint in which patches are organized by recursively subdividing squares. "we also impose the constraint that all patches follow a quadtree-like structure, following a regular grid."
- Sequence packing: Concatenating variable-length token sequences in a batch and masking cross-example attention. "We follow these methods and employ sequence packing."
- SentencePiece: A subword tokenizer that segments text into pieces based on statistical models. "LLMs rely on adaptive tokenizers such as Byte-Pair Encoding \citep{sennrich-etal-2016-neural} and SentencePiece \cite{kudo-richardson-2018-sentencepiece}"
- Transposed convolutions: Convolution-like operations used for upsampling feature maps in dense prediction. "can be upsampled by transposed convolutions and seamlessly applied to downstream tasks."
- Throughput: The rate of processing (e.g., images per second) during training or inference. "increasing throughput by 40\% on ViT-L and 50\% on ViT-H while maintaining downstream performance."
- UperNet: A segmentation architecture that builds on backbone features to produce dense predictions. "using it as a backbone with a UperNet~\citep{xiao2018upernet} segmentation model on top."
- ViTDet: An object detection framework built on Vision Transformers. "with a ViTDet~\citep{li2022vitdet} style detection head."
- Vision LLM (VLM): A model combining a vision encoder with a LLM for multimodal understanding. "LLaVA is a vision LLM (VLM) that combines a vision transformer backbone with a language backbone via a projection layer."
- Vision Transformers (ViTs): Transformer-based architectures that process images by tokenizing fixed-size patches. "Vision Transformers (ViTs) partition input images into uniformly sized patches regardless of their content, resulting in long input sequence lengths for high-resolution images."
- Wall-clock time: Actual elapsed time required to train or fine-tune a model end-to-end. "APT significantly reduces the wall-clock time to fine-tune a pre-trained backbone on ImageNet with no degradation in accuracy."
- Window attention: An attention strategy that restricts computation to local windows for efficiency. "tasks requiring high-resolution dense predictions such as object detection often rely on window attention~\citep{liu2021swin, yuan2021hrformer, fang2024eva}"
- xFormers: A modular library providing efficient transformer components and attention kernels. "such as FlashAttention \citep{dao2022flashattention, dao2023flashattention2} or xFormers \citep{xFormers2022}"
- Zero-initialized MLP: An MLP whose weights start at zero to safely inject new information without disrupting pre-trained behavior. "using a zero-initialized MLP, allowing APT to converge without harming the network."
- ZeroMLP: A specific zero-initialized linear layer used to integrate high-resolution details from sub-patches. "The \text{ZeroMLP}, a single linear layer initialized with zero weights inspired by ControlNet~\citep{zhang2023controlnet}, allows the model to gradually incorporate high-resolution details..."
Collections
Sign up for free to add this paper to one or more collections.

