- The paper demonstrates that mid-sized Vision Transformers (ViT-B/16) achieve optimal representational geometry through a distinct Cliff-Plateau-Climb phase transition.
- It introduces the Information Scrambling Index to quantify global communication, showing that controlled mixing is key to efficient performance.
- Findings suggest that calibrating network depth and enabling distributed consensus can serve as practical diagnostics for future transformer architecture design.
Introduction
This paper presents a comprehensive empirical characterization of vision transformer (ViT) scaling behavior with a focus on layerwise representational phase transitions, geometric structure, and attention dynamics in ViT-S, ViT-B, and ViT-L models trained on ImageNet (2511.21635). Contrary to standard scaling heuristics, evidence is provided showing that deeper ViTs do not necessarily yield improved representational geometry or classification performance. Instead, mid-sized models (notably ViT-B/16) exhibit more optimal geometric structures than their larger (ViT-L/16) or smaller (ViT-S/16) counterparts, challenging the assumption that scaling model depth is universally beneficial.
The Cliff-Plateau-Climb Pattern in Representation Dynamics
Layerwise tracking across all three ViT variants reveals a consistent Cliff-Plateau-Climb pattern in the evolution of patch token representations. At initialization, the addition of strong positional encodings (PE) induces a sharp drop in centered token similarity (the "Cliff"). This is followed by an extended phase of low-similarity, decorrelated representation (the "Plateau"), and concludes with a rapid re-correlation and geometric consolidation in the final layers (the "Climb"). The duration of the Plateau phase is strongly coupled to model depth.
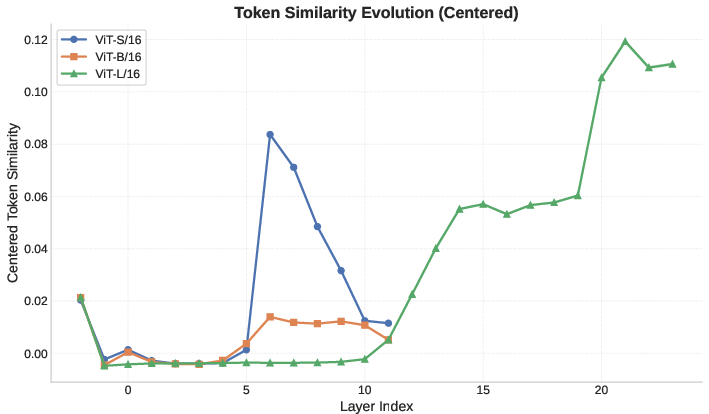
Figure 1: Layer-wise evolution of centered token similarity in Vision Transformers, illustrating the Cliff-Plateau-Climb pattern across model scales.
Parametric manipulation of the PE scaling factor demonstrates that task performance is highly sensitive to this initial decorrelation. Accuracy peaks at the default decorrelation value (α=1.0), and performance degrades when PE strength either falls below or rises above this optimal point.
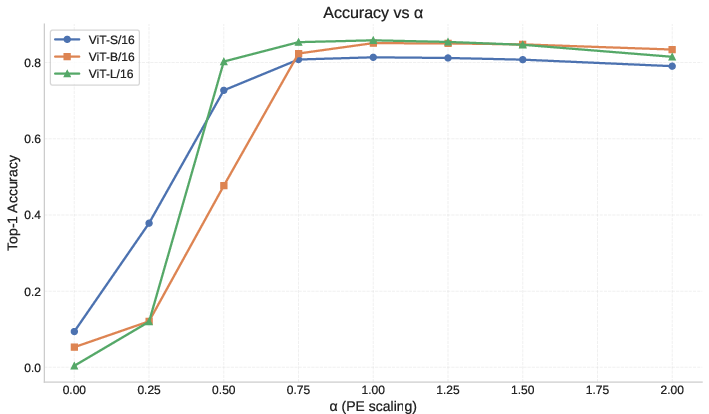
Figure 2: ImageNet top-1 accuracy versus PE scaling factor α for different ViT models; all models maximize performance near α=1.0.
The Emergence of Neural Collapse and Non-Monotonic Scaling
A salient finding is the emergence of Neural Collapse geometry during the final "Climb" phase. As ViT layers approach the final representation, within-class variance drops, class means form a simplex ETF-like structure, classifier alignment improves, and decision margins increase sharply. Significantly, ViT-B/16 achieves more favorable NC2 (ETF gap) measures than either the more shallow ViT-S/16 or the much deeper ViT-L/16, emphasizing the non-monotonicity of geometric quality with respect to model depth.
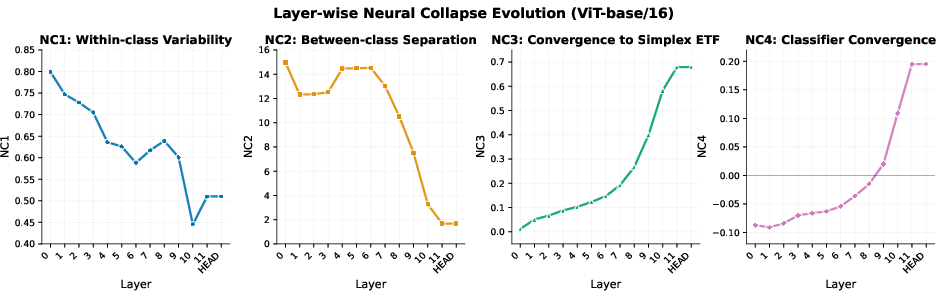
Figure 3: Layerwise metrics showing Neural Collapse emergence in ViT-Base, illustrating geometric consolidation in the final layers.
To mechanistically dissect information flow, the authors introduce the Information Scrambling Index, measuring the value of all-to-all versus self-only patch reconstruction as a proxy for quantifying the benefit (or cost) of global communication. Three regimes are identified:
- ViT-S/16 (Local Processing): Communication collapse, with nearly zero or negative scrambling, leading to predominantly local processing and only partially optimal geometry.
- ViT-B/16 (Controlled Consensus): Stable, low-positive scrambling throughout depth (approx. 0.004–0.009), enabling efficient distributed consensus and the best observed geometric structure.
- ViT-L/16 (Chaotic Diffusion): Monotonic increase in scrambling to high values (up to 0.031), indicating over-mixing and inefficient use of depth.
These regimes correspond to distinct trajectories in the information-task tradeoff: ViT-B/16 reaches high probe accuracy with minimal information loss and computational overhead, while ViT-L/16 expends significant additional depth on redundant re-mixing that fails to improve outcome geometry.
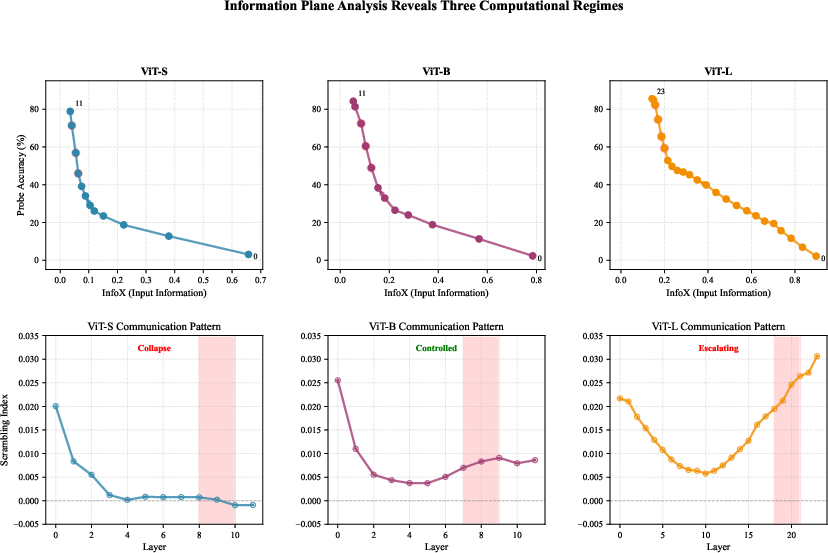
Figure 4: Information Plane Analysis showing InfoX and Scrambling Index dynamics across models, revealing divergent communication regimes and pivot zones.
Topological Reorganization: Hub Marginalization and Distributed Consensus
Attention graph analysis demonstrates that ViTs progressively marginalize the [CLS] token—originally intended as a centralized global aggregator—through depth, shifting toward distributed decision-making via patch token consensus. In ViT-B/16, a sharp transition occurs in layers 8–10 ("information pivot"), where rapid hub marginalization (CCC decrease), increased consensus (ACI increase), and geometric improvement (NC2, NC4) all coincide.
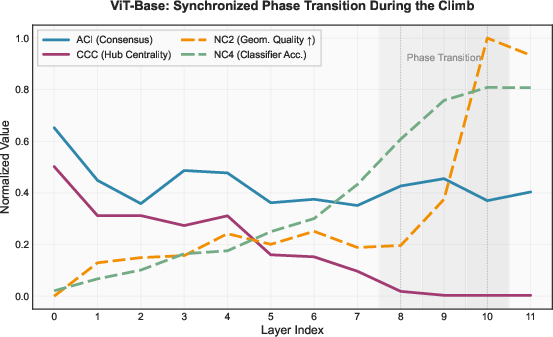
Figure 5: ViT-Base coordinated reorganization during the information pivot; hub marginalization and consensus formation are concurrent with improved geometry and accuracy.
ViT-L/16, by contrast, requires almost twice as many layers to achieve a similar degree of hub marginalization, and does so unstably, often exhibiting late-stage spikes in centrality and persistently high scrambling. This further emphasizes the inefficiency and performance ceiling induced by excessive depth without coordinated communication.
The analysis suggests that maximizing model depth and parameter count in ViTs does not ensure optimal geometric or task performance. Instead, depth should be calibrated to allow efficient phase transitions, with controlled global mixing and early, stable hub marginalization. The Information Scrambling Index and hub centrality metrics can serve as operational diagnostics to guide model architecture search or as potential regularization targets during optimization.
Practical implications include:
- Preferential allocation of compute to models with controlled consensus communication regimes.
- Early identification of inefficient architectures by monitoring hub marginalization and scrambling dynamics during training.
- Architectural innovations supporting explicit distributed consensus rather than reliance on a single aggregation hub.
- Potential application of these metrics as tuning signals for other modalities (e.g., NLP or multimodal transformers), encouraging further empirical and theoretical exploration.
Conclusion
This work demonstrates that Vision Transformers benefit from calibrated, not maximal, depth, and that non-monotonic scaling phenomena are underpinned by representational phase structure, information dynamics, and attention topology. The most effective architectures execute controlled transitions between decorrelation, computation, and consolidation, achieving distributed consensus rapidly without over-mixing or reliance on fragile architectural hubs. These findings have direct consequences for the development of depth-efficient transformer architectures and inform the mechanistic understanding of generalization and geometric organization in modern deep models.
(2511.21635)

