- The paper shows that SFT and RL updates occur in nearly orthogonal subspaces, justifying the modular extraction of reasoning skills.
- It introduces the PaST framework which linearly injects RL-derived skill vectors into SFT-trained models for improved performance.
- Empirical results on SQuAD, LooGLE, and ToolBench demonstrate significant accuracy gains and enhanced cross-domain generalization.
Injecting RL-Derived Reasoning Skills for Efficient LLM Knowledge Adaptation
Introduction and Motivation
The paper "Knowledge is Not Enough: Injecting RL Skills for Continual Adaptation" (2601.11258) addresses the problem of functional disconnect between knowledge and reasoning capacity in LLMs during continual adaptation. Standard Supervised Fine-Tuning (SFT) updates models to incorporate new factual data but results in a brittle system unable to robustly manipulate or act on newly acquired information. Reinforcement Learning (RL) confers the necessary reasoning and decision-making abilities but remains impractically costly for online adaptation in every new context. The authors argue that knowledge acquisition (SFT) alone is insufficient for operational proficiency, positioning RL-driven skill injection as essential for robust downstream performance.
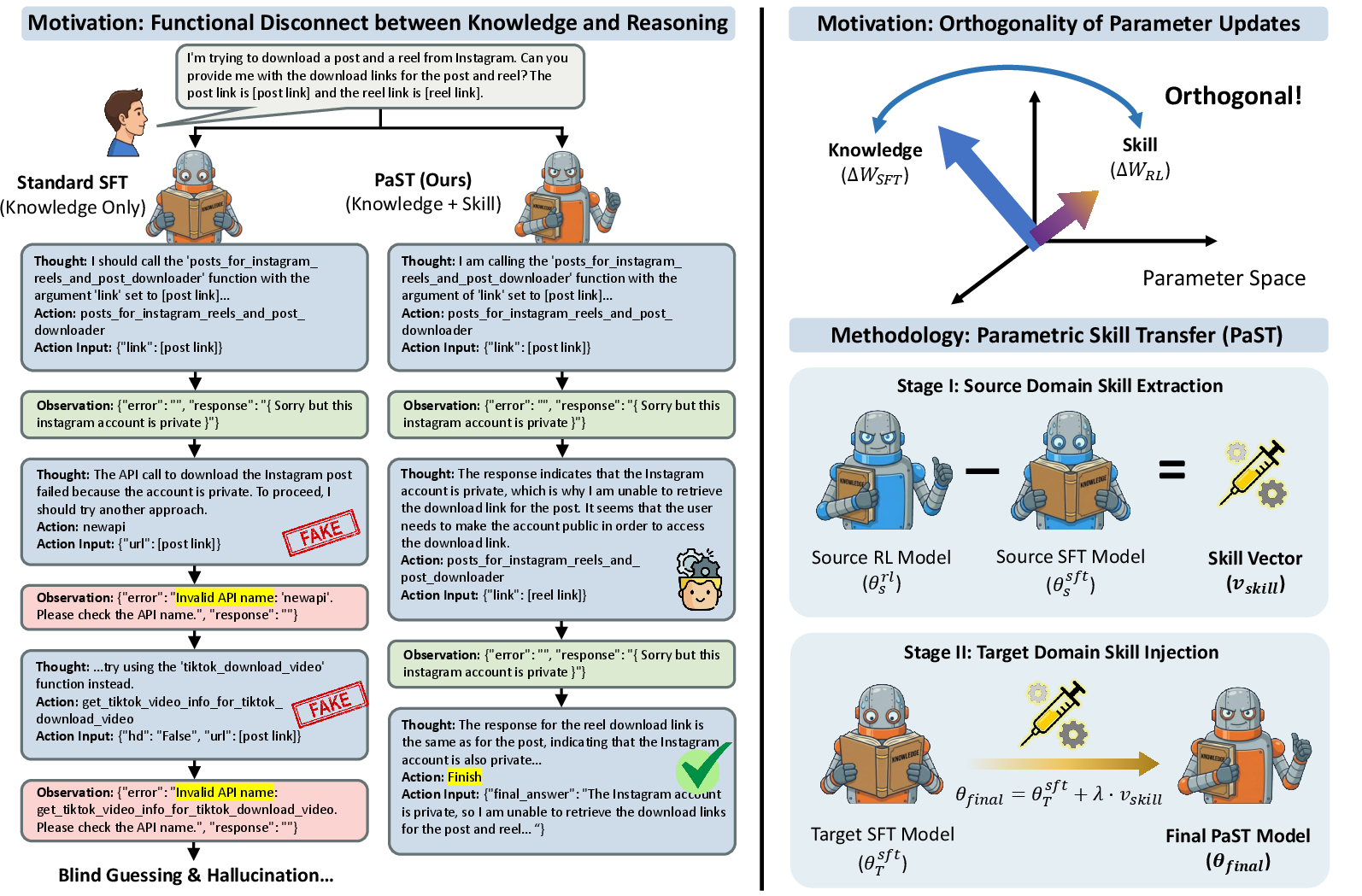
Figure 1: Overview of Parametric Skill Transfer (PaST) illustrating how SFT fails to handle errors while PaST injects RL-derived reasoning skills; parameter updates for knowledge (ΔWSFT) and skill (ΔWRL) reside in orthogonal subspaces.
Empirical Discovery: Orthogonality of SFT and RL Parameter Updates
The central technical finding is that SFT and RL induce nearly orthogonal parameter updates across model layers, as visualized via layer-wise cosine similarity analysis. This orthogonality indicates that knowledge (acquired via SFT) and procedural manipulation logic (acquired via RL) inhabit statistically disentangled subspaces in the parameter landscape. The practical implication: RL-learned skills can be extracted as a domain-agnostic vector and linearly injected into a model updated with SFT—enabling modular reasoning transfer without costly target-domain RL.
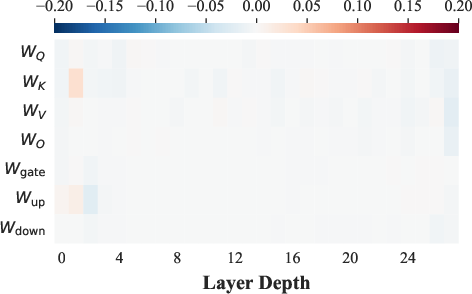
Figure 2: Layer-wise cosine similarity between SFT- and RL-induced weight changes on LooGLE demonstrates dominant near-zero values, evidencing orthogonality.
The authors provide theoretical justification grounded in high-dimensional statistics: orthogonality at the parameter level assures signal-level functional disentanglement through input-layer norm and concentration-of-measure arguments, ensuring that injected skill components do not destructively interfere with base knowledge.
Parametric Skill Transfer (PaST) Framework
PaST is a modular two-stage procedure:
- Skill Extraction: In a source domain, SFT adapts the base model to new documents. RL subsequently induces reasoning proficiency via trajectory-based interaction. The skill vector vskill=θSrl−θSsft captures RL-induced procedural policy, isolated from domain-specific facts.
- Target Domain Adaptation: Lightweight SFT internalizes target domain knowledge. The skill vector is then injected via θfinal=θTsft+λvskill, linearly integrating robust skill to enable zero-shot reasoning and tool-use in the target domain without RL-phase cost.
The framework is extensible through iterative skill refinement, partitioning source data and repeatedly distilling the skill vector for increased domain invariance and generalization.
Experimental Evaluation
Knowledge-Based QA: SQuAD and LooGLE
SQuAD
On closed-book SQuAD, PaST achieves decisive absolute gains in mean accuracy, outperforming both SFT+synthetic baselines and the state-of-the-art SEAL meta-training method by up to +9.9 points. Injection of the skill vector on top of already-strong SFT+synthetic configurations yields further improvement (+17.2%), supporting the claim that skill transfer—not just improved data generation—is the bottleneck in practical knowledge adaptation.
LooGLE
In long-context scenarios (LooGLE, average context length >21k tokens), skill vector injection delivers an accuracy gain of +8.0% over strong SFT baselines, demonstrating scalable benefit for real-world adaptation tasks characterized by massive memory and complex retrieval logic.
Cross-Domain Agentic Tool Use: ToolBench
In StableToolBench zero-shot transfer, PaST substantially improves average success rates from 21.9% (Target SFT baseline) to 32.2%, a +10.3% absolute increase. Crucially, it achieves success in categories where SFT-only adaptation fails completely (e.g., Advertising, SMS), and consistently outperforms the baseline across all 20 RL-unseen categories—establishing robust cross-domain generalization from a skill vector distilled solely in the Movies domain.
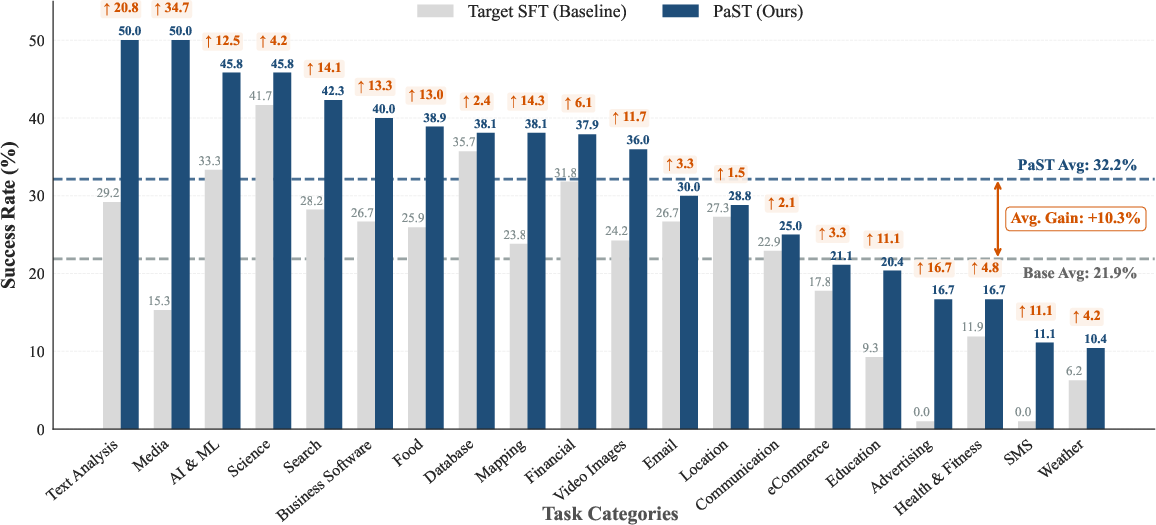
Figure 3: Zero-shot cross-domain generalization in ToolBench, PaST increases average success rate by +10.3% on RL-unseen categories.
Ablations: Iterative Refinement and Vector Injection Timing
Iterative skill refinement yields superior results over single-round training, validating the hypothesis that reasoning logic must be repeatedly purged of content-specific patterns to achieve domain-agnostic procedural generality.
Alternative transfer strategies—sequential fine-tuning or pre-injection before SFT—result in optimization conflicts or misalignment with the knowledge base, whereas post-hoc composition ensures maximal synergy between factual anchoring and skill grafting.
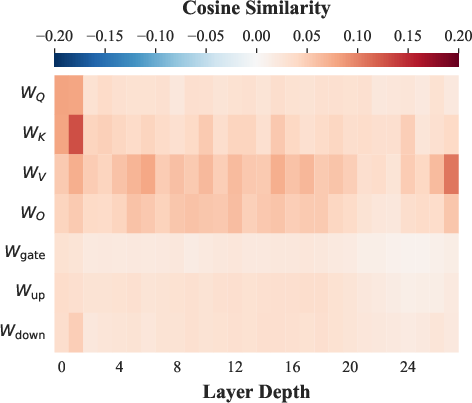
Figure 4: Similarity between two SFT updates reveals strong positive correlation, confirming only SFT-RL update orthogonality as functionally unique.
Control Experiments: Nontriviality of Orthogonality
Direct comparison of two independent SFT steps displays strong positive update correlation, confirming that shared-task adaptation occupies aligned subspaces. The pronounced orthogonality between SFT and RL updates is thus not a trivial outcome of parameter dimensionality, but a consequence of the fundamental mechanistic divide between memorization (SFT) and skill generalization (RL).
Practical and Theoretical Implications
From a practical perspective, PaST enables efficient, scalable adaptation to rapidly-changing domains without incurring the prohibitive cost of RL rollouts for every update. It supports robust knowledge manipulation and tool orchestration in previously unseen scenarios, empowering LLM-based agents for continual deployment. Theoretically, this work substantiates a model of modular cognitive transfer, where parametric skill vectors operate as reusable reasoning circuits decoupled from factual memory—potentially inspiring new architectures for continual learning, modular agent design, and efficient skill transfer across tasks and models.
Future research may explore auto-tuned scaling coefficients λ, broader architectural generalization, and recursive transfer across multi-hop knowledge/skill manifolds. Questions remain as to the universality and potential for hierarchical composition of skill vectors across base models and larger scales.
Conclusion
The paper establishes a strong empirical and theoretical foundation for modular reasoning transfer in LLMs via PaST, demonstrating that RL-derived skills and SFT-acquired knowledge inhabit decomposable, orthogonal subspaces. By distilling and injecting domain-invariant RL skill vectors, models achieve robust, efficient adaptation—raising both practical performance and conceptual understanding of continual learning in agentic language systems.