From $f(x)$ and $g(x)$ to $f(g(x))$: LLMs Learn New Skills in RL by Composing Old Ones
Abstract: Does RL teach LLMs genuinely new skills, or does it merely activate existing ones? This question lies at the core of ongoing debates about the role of RL in LLM post-training. On one side, strong empirical results can be achieved with RL even without preceding supervised finetuning; on the other, critics argue that RL contributes little beyond reweighting existing reasoning strategies. This work provides concrete evidence that LLMs can acquire genuinely new skills during RL by composing existing ones, mirroring one of the central mechanisms by which humans acquire new cognitive skills. To mitigate data contamination and other confounding factors, and to allow precise control over task complexity, we develop a synthetic framework for our investigation. Specifically, we define a skill as the ability to infer the output of a string transformation function f(x) given x. When an LLM has already learned f and g prior to RL, our experiments reveal that RL enables it to learn unseen compositions of them h(x)=g(f(x)). Further, this compositional ability generalizes to more difficult problems such as compositions of >2 functions unseen during RL training. Surprisingly, our experiments show that compositional skill acquired on a source task transfers to a different target task. This transfer happens even without compositional training on the target, requiring only prior knowledge of the target's atomic skills. Our qualitative analysis shows that RL fundamentally changes the reasoning behaviors of the models. In contrast, next-token training with the same data yields none of these findings. Our systematic experiments provide fresh insights into LLM learning, suggesting the value of first building base models with basic skills, then using RL to incentivize advanced, generalizable skills for complex problems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: When we train LLMs with reinforcement learning (RL), do they learn truly new skills, or do they just use the skills they already have in a slightly better way? The authors show evidence that LLMs can learn new skills by combining old ones—kind of like building bigger creations out of Lego pieces you already know how to use.
Key Objectives
The paper focuses on three easy-to-understand questions:
- Does RL teach LLMs new skills?
- What kind of training or “incentives” does RL need to teach those skills?
- Do the new skills work on harder problems or even in different types of tasks?
Methods and Approach
To test these questions fairly, the authors built a clean, fake world of puzzles so the model couldn’t cheat by remembering the internet. Here’s how it worked:
- Imagine you have simple “atomic skills” (basic actions) like “reverse the string,” “remove vowels,” or “take every other character.” These are small functions like f(x) that each do one clear thing.
- Then you make “compositional skills” by combining them, like g(f(x))—first do f, then do g. For example: reverse the string and then remove vowels.
To keep it scientific:
- Each function had a meaningless name (like func_16) so the model couldn’t guess what it did from its name.
- The team controlled difficulty by how many functions were chained together:
- Level 1: one function (f(x))
- Level 2: two functions (g(f(x)))
- Higher levels: longer chains (more functions in a row)
Training happened in two stages:
- Stage 1 (learn the basics): The model learned atomic skills using a method called rejection fine-tuning (RFT). Think of RFT like practicing with worked examples and copying the correct steps.
- Stage 2 (learn to combine): The model tried compositional problems either with:
- RL: It got a reward when its final answer was correct, without being shown the steps. This is like playing a game and getting points for winning.
- RFT: It saw correct examples and tried to imitate them, like studying from solutions.
The authors tested the models on:
- Held-out functions (skills not used during training)
- Harder difficulty levels (longer chains than seen during training)
- A totally different task: Countdown (a math puzzle where you combine given numbers to reach a target), to see if the “combining skills” transfer across domains
Helpful translations:
- “Atomic skills” = basic building blocks
- “Compositional skills” = putting blocks together in the right order
- “RL (Reinforcement Learning)” = learn by getting rewards for correct outcomes
- “RFT (Rejection Fine-Tuning)” = learn by imitating correct solutions
- “Held-out” = not seen during training
- “pass@k” = if a model can try k different answers, how often does at least one answer work?
Main Findings
Here are the most important results, explained simply:
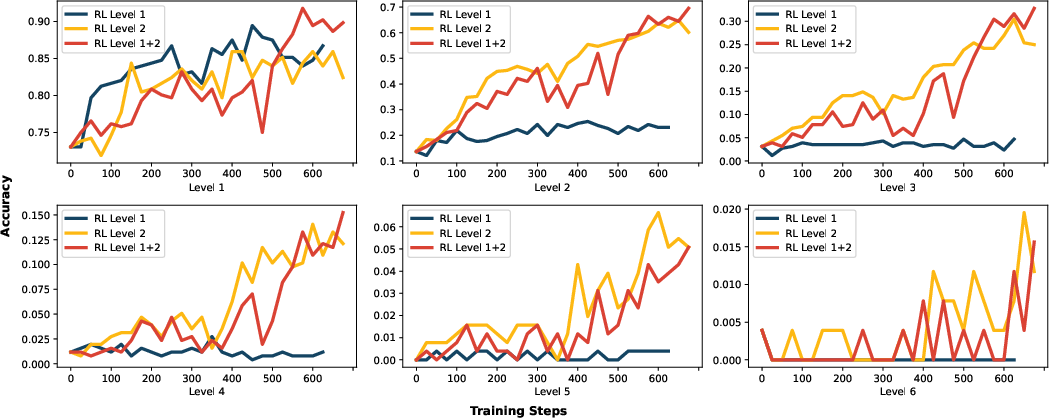
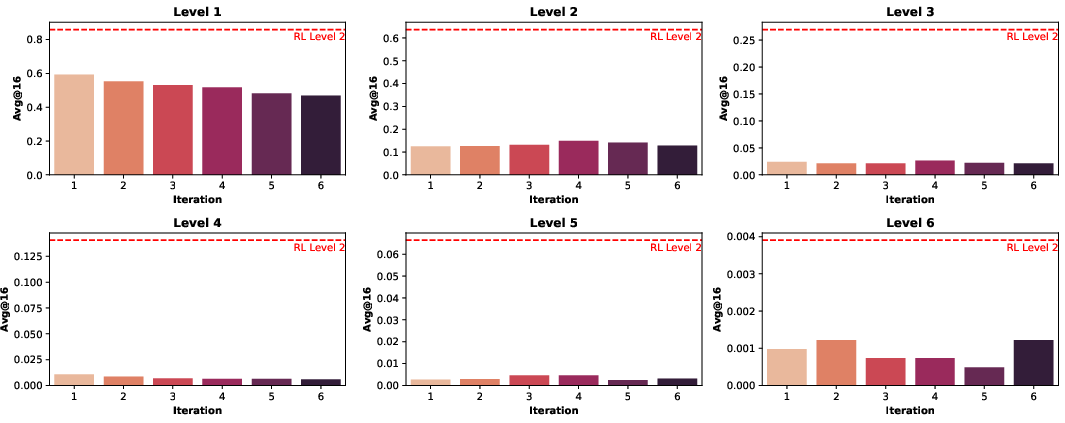
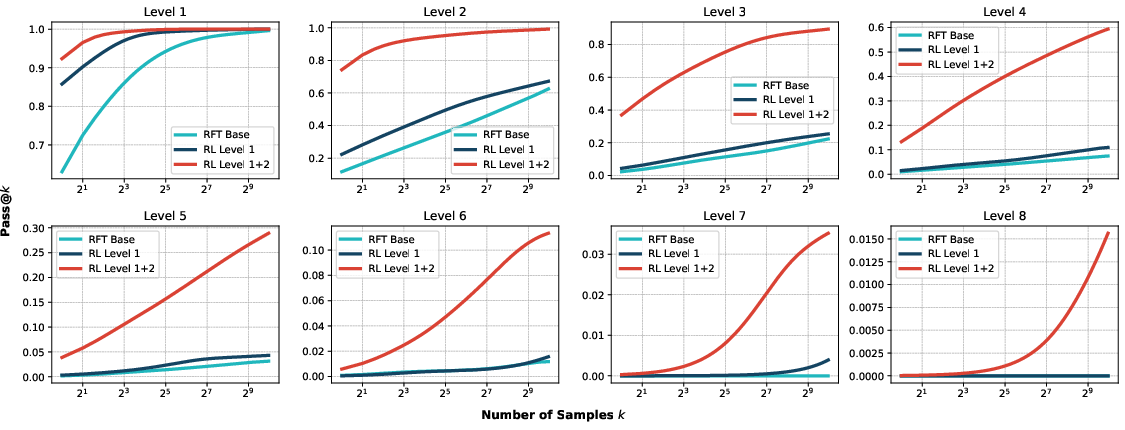
- RL on compositional problems teaches new skills
- When the model trained with RL on Level 2 (two-step) problems, it learned to solve harder problems it had never seen before, like Level 3 and Level 4.
- Accuracy jumped from almost 0% to around 30% on Level 3 and 15% on Level 4. That’s a big improvement.
- RL needs the right incentives
- RL on only Level 1 (single-step) problems didn’t help the model learn to combine skills.
- Doing RFT (studying examples) on Level 2 compositional data wasn’t enough either. Just seeing examples didn’t teach the model the deeper “how to combine” idea.
- The new skill transfers to other tasks—but only if the model knows the basics there
- A model trained to “combine skills” on string puzzles did better on Countdown math puzzles (even though it never saw Countdown during RL), but only when it already knew the math basics for Countdown.
- This suggests the “skill of combining” is a meta-skill: once learned, it helps in other areas—if the model already understands the atomic pieces in that area.
- RL changes how the model thinks, not just how often it’s right
- Before RL on compositional tasks, the model often ignored the composition or mixed up the order.
- After RL on Level 2, the model’s errors were mostly about getting one basic step wrong, not misunderstanding the chain. This shows it learned the idea of “do step A, then step B,” and its mistakes moved to more detailed places.
- Why some studies think RL only “reranks” answers
- Some evaluations say RL doesn’t really make models smarter, just better at picking their best answer from many tries (this is the “reranking” idea).
- The authors argue that this happens when the test problems are too easy or too similar to what the base model already knows. On truly hard compositional problems, RL clearly pushes performance much higher—even when the model tries many answers.
Why This Matters
This research suggests a better recipe for building strong LLMs:
- First, teach the model good atomic skills (the basics in each domain).
- Then, use RL with the right incentives—specifically, train on problems that require combining those basics.
- This can lead to skills that generalize to harder problems and even transfer across tasks.
In short, RL can teach LLMs genuinely new abilities, especially the powerful skill of composition. That’s important because many real-world problems are solved by combining small steps into bigger plans—just like how people learn and think.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or left unexplored, phrased to guide follow-up research.
- External validity beyond synthetic composition:
- Does the RL-induced compositional skill transfer to diverse real-world tasks (e.g., multi-step math beyond Countdown, code synthesis/refactoring, tool-use workflows, program synthesis, logic/graph reasoning), and how does domain distance affect transfer?
- How does performance change when function names/descriptions are expressed in natural language (ambiguous, paraphrased, or noisy) rather than meaningless identifiers?
- Breadth of transfer:
- Transfer is only shown from strings to Countdown; test additional targets (e.g., GSM8K/Math, Codeforces/code benchmarks, logical entailment, planning tasks) and the reverse direction (e.g., Countdown→strings).
- Characterize necessary and sufficient atomic-skill coverage for transfer: How partial/approximate atomic knowledge affects the benefits of compositional RL.
- Limits of compositional generalization:
- What is the maximal composition depth achievable when trained only at Level-2? Does training on Level-3 (or curriculum schedules) yield longer-horizon generalization (e.g., Level ≥ 8–10)?
- How robust is generalization to non-sequential composition (branching, conditionals, loops, recursion) rather than simple nesting?
- RL algorithm and reward design:
- Effects of different RL algorithms (PPO/TRPO, RLAIF, DPO variants, policy-gradient baselines) versus GRPO on compositional skill acquisition.
- Reward shaping ablations (process/intermediate rewards, partial credit, stepwise execution feedback) vs. outcome-only correctness rewards; which structures best incentivize composition?
- Impact of exploration controls (entropy bonuses, temperature schedules, KL penalties) on learning and avoiding entropy collapse in this setting.
- Can RL learn atomic skills de novo?
- The study assumes atomic skills are pretrained via RFT; test whether RL alone (with hidden function definitions) can discover atomic skills, and what reward signals/environments are necessary to make that feasible.
- Stronger non-RL baselines:
- Compare RL to more competitive supervised/offline methods: process-supervised SFT (with CoT), chain-of-verification, search-augmented training, off-policy preference learning, reranking with learned verifiers, and curriculum-based RFT—with matched compute and data budgets.
- Evaluate whether sophisticated test-time search (e.g., ToT/MCTS/self-consistency) can close the gap without parameter updates.
- Compute and data efficiency:
- Quantify sample efficiency and compute costs for achieving compositional generalization; provide scaling laws over model size, data volume, RL steps, and composition depth.
- Model generality and scaling:
- Replicate across model sizes and families (e.g., non-instruct base models, larger/smaller parameter regimes, multilingual models) to assess robustness and scaling behavior.
- Assess sensitivity to initialization and random seeds; report variance across runs.
- Robustness and distribution shifts:
- Test robustness to input perturbations (typos, distractors, length variations), adversarial prompts, and noisy/ambiguous function descriptions.
- Evaluate OOD function families (different algebraic properties, non-commutative/ non-associative/ non-invertible operations), and stochastic or noisy transformations.
- Fairness and reproducibility of comparisons:
- Ensure compute- and data-matched comparisons between RL and RFT (online RL can generate more diverse trajectories); report token counts, updates, and wall-clock compute.
- Release full hyperparameters, seeds, and detailed training/evaluation scripts; standardize evaluation harnesses to avoid hidden confounders.
- Behavioral analysis validity:
- The failure-mode analysis relies on an external LLM classifier (Gemini) without human validation; assess inter-rater reliability, calibration, and bias; cross-validate with human annotations.
- Pass@k and “reranking illusion” generality:
- Test the reranking vs. skill-acquisition narrative on standard, mixed-difficulty public benchmarks (math, coding, logic) to validate that the observed pass@k dynamics generalize beyond the synthetic setting.
- Catastrophic forgetting and interference:
- Measure retention of atomic skills after compositional RL; analyze negative transfer when alternating RL across tasks; study regularization methods to preserve prior skills.
- Mechanistic understanding:
- Use interpretability tools to probe whether RL induces structured representations/circuits for composition; track entropy and representation shifts over training; relate changes to error-type transitions.
- Environment and interaction design:
- Compare purely textual RL to interactive function-calling environments (with execution feedback or tool APIs); test whether tool-grounded, stepwise feedback accelerates compositional learning.
- Task and dataset design choices:
- Analyze how the number/diversity of atomic functions and their algebraic structure affect learnability and generalization.
- Investigate curriculum strategies (e.g., progressive depth, mixture proportions) that optimize easy-to-hard generalization.
- Contamination and prior exposure:
- While the string task is synthesized, Countdown may appear in pretraining; quantify pretraining exposure and its effect on atomic skill formation and cross-task transfer claims.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s findings that reinforcement learning (RL) with compositional incentives teaches LLMs genuinely new skills that generalize and transfer.
- Post-training pipeline upgrade for AI model vendors (software/AI)
- Application: Add a compositional RL stage after atomic skill acquisition (via NTP/RFT) to unlock multi-step reasoning that generalizes to higher difficulty and unseen compositions.
- Tools/workflows: GRPO or similar RLVR with binary correctness rewards; synthetic compositional curricula (e.g., function-composition datasets); held-out compositions; level-stratified evaluation.
- Assumptions/dependencies: Base model has already internalized domain-specific atomic skills; availability of verifiable tasks and reliable evaluation harnesses; compute budget for online RL.
- Level-stratified evaluation and error taxonomy in research and product QA (academia, policy, AI evaluation platforms)
- Application: Replace aggregate pass@k metrics with difficulty-stratified pass@k and behavior analysis to avoid the “reranking illusion”—detecting genuine skill acquisition vs. response reranking.
- Tools/workflows: Clean, decontaminated compositional testbeds; neutral identifiers; automated failure-mode classification (e.g., composition vs. atomic errors).
- Assumptions/dependencies: Access to controlled, verifiable datasets; buy-in to update evaluation protocols; benchmark governance.
- Agent tool-chaining reliability improvements (software/devops/data engineering)
- Application: Train agents with RL on simple tool/function compositions (Level-2) to improve generalization to longer tool chains (e.g., ETL pipelines, shell workflows, RAG multi-hop steps).
- Tools/workflows: Programmatic environments with auto-checkers for correctness; synthetic tasks composed from atomic tools; reward shaping via correctness-only outcomes.
- Assumptions/dependencies: Good coverage of atomic tool skills in the base model; deterministic or reliably verifiable outcomes; safe sandboxes.
- Math/code assistants with stronger multi-step compositional reasoning (productivity software, finance analytics, software engineering)
- Application: Enhance solvers and copilots to handle complex tasks (e.g., multi-step spreadsheet modeling, chained API calls, refactoring sequences) by RL on compositional tasks.
- Tools/products: Spreadsheet/function-composition datasets; API chaining simulators; correctness verifiers; pass@k at difficulty levels.
- Assumptions/dependencies: Clear atomic primitives (functions/APIs) in the target domain; robust unit/integration tests to serve as reward signals.
- Cross-domain bootstrapping where atomic skills already exist (education, coding, quantitative reasoning)
- Application: RL on compositional tasks in one domain (e.g., strings/logic puzzles) to lift performance in a second domain (e.g., Countdown/math/coding) if the base model already has the target’s atomic skills.
- Tools/workflows: Synthetic compositional curricula; transfer evaluation on held-out tasks; temperature-controlled sampling to assess Avg@k.
- Assumptions/dependencies: Target domain atomic skills must be present pre-RL; verifiable rewards for training source tasks; domain similarity in compositional structure.
- EdTech curriculum design and tutoring (education)
- Application: Use Level-2 compositions to teach and assess the compositional meta-skill; deploy LLM tutors trained with compositional RL for stepwise problem solving (math/programming).
- Tools/workflows: Skill graphs separating atomic from composite skills; auto-generated problem sets with nesting depth controls; correctness-driven RL loops.
- Assumptions/dependencies: Tutoring models must master atomic skills first; safe instructional deployments; alignment with learning standards.
- Safety and reliability gating for complex instructions (AI safety)
- Application: Use the paper’s behavioral analysis to gate deployments: ensure models “understand composition” (fewer composition-ignorance errors) before serving high-stakes multi-step tasks.
- Tools/workflows: Failure-mode dashboards; compositional checks in eval pipelines; rollout gating or guardrails based on error-type distributions.
- Assumptions/dependencies: Representative compositional evals; robust labeling/auto-classification of failure modes; domain-specific safety criteria.
- Data contamination mitigation in evaluation datasets (academia, model testing)
- Application: Adopt neutral identifiers and hidden implementations (no function names or hints) to prevent leakage and overestimating capability.
- Tools/workflows: Dataset curation with meaningless function names; strict separation of train/test compositions; contamination audits.
- Assumptions/dependencies: Control over dataset generation; careful release practices across research ecosystems.
- RL reward design simplification (software/AI training systems)
- Application: Leverage correctness-only outcome rewards (no reasoning demonstrations) for compositional skill acquisition, reducing data engineering overhead.
- Tools/workflows: Binary reward calculators; GRPO or equivalent; online sampling and self-play loops with verifiers.
- Assumptions/dependencies: Deterministic or reliably verifiable tasks; sufficient exploration capacity; monitoring entropy collapse.
- Model debugging and training allocation decisions (AI engineering)
- Application: Use error-type analysis to decide whether to invest in atomic NTP/RFT (if atomic errors dominate) vs. compositional RL (if composition is misunderstood or ignored).
- Tools/workflows: Diagnostic runs on level-stratified tasks; automated categorization of failure modes; training roadmaps tying skills to methods.
- Assumptions/dependencies: Availability of diagnostic datasets; continuous evaluation; resource trade-offs between pretraining and post-training.
Long-Term Applications
These applications will benefit from further research, scale, safety validation, and integration with domain infrastructure.
- General-purpose reasoning meta-skill across domains (software, legal, healthcare, finance, robotics)
- Application: Build LLMs that can compose domain-specific atomic skills into complex, out-of-distribution plans—becoming robust generalists in multi-step tasks.
- Tools/products: Domain skill graphs; multi-domain compositional RL curricula; cross-task transfer evaluation suites.
- Assumptions/dependencies: Comprehensive atomic skill coverage through pretraining or supervised finetuning; scalable, safe RL infrastructure; robust verification signals.
- Robust robotic planning via compositional RL (robotics)
- Application: Compose atomic motor and perception skills (grasp, move, orient, place) via RL on simple composite tasks, generalizing to longer, hierarchical plans.
- Tools/workflows: High-fidelity simulators; task libraries with verifiable outcomes; sim-to-real transfer protocols; hierarchical RL.
- Assumptions/dependencies: Accurate simulators and reward functions; safety certification; reliable sensing and actuation.
- Clinical decision support that composes interventions and guidelines (healthcare)
- Application: Train models to compose atomic clinical procedures into complex care pathways; generalize to new patient presentations.
- Tools/workflows: Synthetic patient flow simulators; verifiable guideline adherence checks; compositional curricula anchored in evidence-based protocols.
- Assumptions/dependencies: Trustworthy atomic medical knowledge; regulatory approval; rigorous safety and fairness audits; robust outcome verifiers.
- Autonomous software agents that compose APIs and services (software engineering)
- Application: RL on synthetic API/function compositions to generalize to complex feature implementations, migrations, and multi-service workflows.
- Tools/workflows: Programmatic test suites; environment sandboxes; integration verifiers; dependency graphs for tool composition.
- Assumptions/dependencies: Stable APIs; enterprise-grade CI/CD with automated checks; secure execution environments.
- Smart spreadsheet/BI assistants that compose functions and models (finance, data analytics)
- Application: Train on compositional function tasks to generalize to multi-step modeling (e.g., sensitivity analysis, multi-factor risk models).
- Tools/products: Spreadsheet composition benchmarks; correctness verifiers for formulas and outputs; domain-specific atomic function sets.
- Assumptions/dependencies: High-quality evaluators; governance for financial model risk; auditability and explainability.
- Smart grid and industrial control with composite policies (energy, manufacturing)
- Application: Compose atomic control policies to satisfy multi-objective constraints (stability, cost, emissions) under dynamic conditions.
- Tools/workflows: Digital twins; safety-constrained RL; verifiable objectives with real-time telemetry.
- Assumptions/dependencies: Reliable simulation-to-deployment pipelines; safety compliance; adversarial robustness.
- Education platforms with compositional skill maps and adaptive tutoring (education)
- Application: Build tutors that first diagnose atomic skills, then teach composition through controlled nesting levels; measure transfer across subjects.
- Tools/workflows: Skill graph assessment; curriculum generation; compositional RL for pedagogical strategies; cross-subject transfer tests.
- Assumptions/dependencies: Alignment with curricula; privacy and safety protections; longitudinal evaluation.
- Scientific workflow assistants composing experimental steps (science/biotech)
- Application: Compose atomic lab procedures into novel protocols; generalize to unfamiliar experimental designs.
- Tools/workflows: Lab automation sims; protocol verifiers; reward functions based on reproducibility and safety criteria.
- Assumptions/dependencies: High-fidelity domain simulators; validation datasets; wet-lab integration constraints.
- Policy and standards for RL evaluation and procurement (policy, governance)
- Application: Require difficulty-stratified evaluations, compositional incentives in RL training, contamination mitigation, and cross-task transfer reporting in public benchmarks and procurement specs.
- Tools/workflows: Standardized testbeds; reporting templates; certification pipelines.
- Assumptions/dependencies: Community consensus; coordination across standards bodies; auditor expertise.
- Compute and data allocation strategies for base vs. post-training (AI strategy)
- Application: Shift budgets to ensure base models master atomic skills, then invest in compositional RL to scale generalization and transfer; develop taxonomies of domain atomic skills to guide pretraining.
- Tools/workflows: Skill coverage audits; domain-specific atomic skill catalogs; RL scheduling policies.
- Assumptions/dependencies: Reliable measurement of atomic-skill mastery; scenario-specific cost/benefit analyses; scalable training infrastructure.
Glossary
- Avg@32: An evaluation metric averaging accuracy over 32 sampled responses (usually at a specified temperature). "We report the Avg@32, the average accuracy across 32 responses sampled at temperature 1.0."
- atomic skills: Primitive, non-decomposable abilities (here, single string transformations) that serve as building blocks for composition. "We define atomic skills as single, non-decomposable transformations, and compositional skills as their nested combinations."
- compositional generalization: The ability to solve novel compositions of known atomic components beyond those seen in training. "while \cite{Sun2025OMEGACL} found that directly RL in atomic skills fails in compositional generalization."
- compositional skills: Abilities formed by systematically composing atomic skills (e.g., nested function applications). "We define atomic skills as single, non-decomposable transformations, and compositional skills as their nested combinations."
- Countdown (task): A numeric puzzle task requiring constructing an expression from given integers to reach a target number. "We test this conjecture on the Countdown task, where a model must construct a mathematical expression from a given set of integers to reach a target number (see \S\ref{app:countdown-example} for examples)."
- cross-task transfer: The phenomenon where skills learned in one task improve performance on a different task. "particularly its potential for easy-to-hard generalization and cross-task transfer."
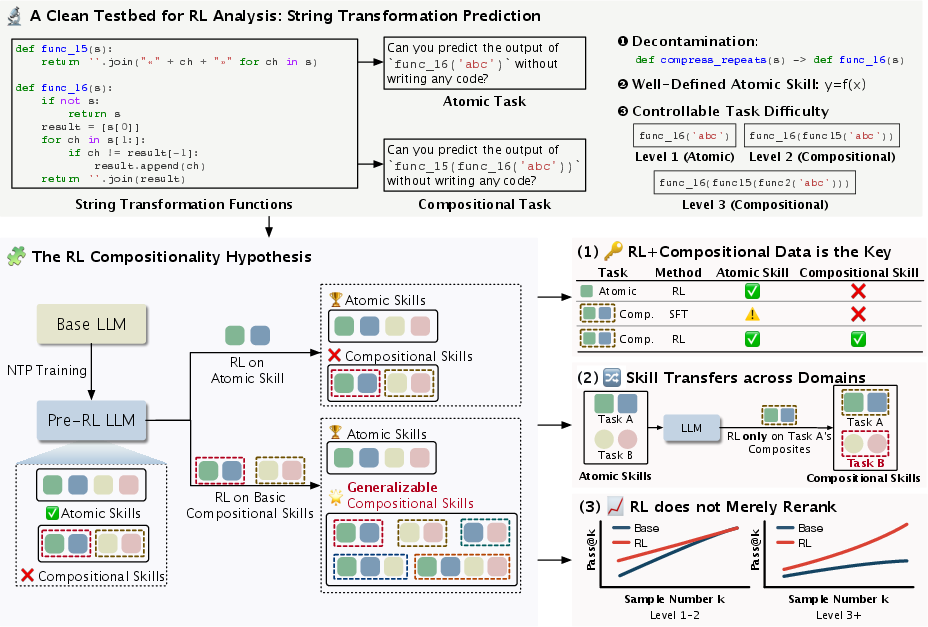
- data contamination: Overlap between training and evaluation data that can inflate performance by memorization rather than learning. "To mitigate data contamination and other confounding factors, and to allow precise control over task complexity, we develop a synthetic framework for our investigation."
- decontaminated evaluation: An assessment setup designed to avoid contamination between training and test data. "Decontaminated evaluation: We design a string transformation prediction task with unique functions assigned meaningless identifiers (e.g., func_16) to prevent inference from function names."
- easy-to-hard generalization: The capability to leverage skills learned on simpler tasks to perform well on more complex ones. "particularly its potential for easy-to-hard generalization and cross-task transfer."
- entropy collapse phenomenon: A failure mode in RL where exploration diminishes, reducing output diversity and learning signal. "recent work finds the exploration of RL is impeded by the entropy collapse phenomenon \citep{DBLP:journals/corr/abs-2505-22617,DBLP:journals/corr/abs-2505-24864,DBLP:journals/corr/abs-2503-14476},"
- Group Relative Preference Optimization (GRPO): An RL algorithm that updates models using relative preferences within sampled groups. "updates through Group Relative Preference Optimization (GRPO) \cite{Shao2024DeepSeekMathPT}, testing whether RL is necessary for the acquisition of compositional skills."
- held-out evaluation: Testing on data disjoint from training to measure generalization. "We assess generalization using rigorous held-out evaluation."
- in-context learning: Learning to perform tasks by leveraging instructions or examples provided within the prompt, without parameter updates. "achieved compositional improvements through in-context learning rather than RL"
- nesting depth: The number of functions composed in a nested structure; a proxy for task difficulty. "Both the RL Level 2 and RL Level 1+2 models demonstrate strong performance to generalize to problems with nesting depths exceeding their training data."
- next-token prediction (NTP) training: Standard pretraining objective of predicting the next token in a sequence. "Once a model has acquired the necessary atomic, non-decomposable skills for a task through NTP training, RL with proper incentivization can teach the model to learn new skills by composing atomic skills into more complex capabilities."
- out-of-domain problems: Tasks that differ distributionally from those seen in training. "more advanced skills that generalize better to complex and out-of-domain problems."
- pass@: The probability that at least one correct solution appears among k sampled outputs. "as the number of samples () increases in pass@ evaluations~\citep{Yue2025DoesRL}."
- pass@: The limiting case of pass@ as k grows without bound, ideally approaching 1 for sufficiently capable models. "any reasonable model could theoretically achieve pass@."
- rejection fine-tuning (RFT): A supervised training approach that fine-tunes on accepted (e.g., correct) samples while discarding rejected ones. "This generalization does not occur in a baseline trained with rejection fine-tuning (RFT) on the same Level-2 problems."
- RL with verifiable rewards (RLVR): A class of RL methods using programmatically checkable rewards (e.g., correctness) to guide learning. "The prior conclusion that RLVR only utilizes base models' reasoning patterns without learning new abilities is likely an artifact of evaluating and RL training on tasks that base models already achieve high pass@;"
- reranking illusion: The misleading appearance that RL merely reranks outputs rather than learning new skills, due to aggregate metrics masking hard-skill gains. "This reveals what we term the ``reranking illusion,'' namely aggregate metrics on mixed-difficulty benchmarks can mask genuine skill acquisition by conflating capabilities of different types."
- rollouts: Sampled sequences of model outputs used to evaluate and optimize behavior in RL. "this strong prior enables base LLM to sample reasonable rollouts and thus perform RL directly without any preceding supervised fine-tuning \citep{DeepSeekAI2025DeepSeekR1IR, tinyzero, Zeng2025SimpleRLZoo};"
- synthetic framework: A controlled, artificially constructed experimental setup to precisely analyze phenomena and avoid confounders. "we develop a synthetic framework for our investigation."
Collections
Sign up for free to add this paper to one or more collections.

