- The paper establishes that JEPA anti-collapse regularization forces encoders to learn and estimate data densities through the Jacobian.
- The JEPA-SCORE, computed from the log-sum of Jacobian singular values, effectively correlates with true log-densities for outlier detection and data curation.
- Empirical results across synthetic, ImageNet, and OOD datasets confirm that JEPA-trained models provide consistent, robust density estimation.
Gaussian Embeddings: How JEPAs Secretly Learn Your Data Density
Introduction
This paper establishes a theoretical and empirical connection between Joint Embedding Predictive Architectures (JEPAs) and nonparametric data density estimation. The central claim is that the anti-collapse (diversity) term in JEPA objectives, which is typically viewed as a mechanism to prevent representational collapse, in fact compels the model to implicitly estimate the data density. The authors introduce the JEPA-SCORE, a closed-form, efficient estimator of sample likelihood derived from the Jacobian of the trained encoder, and demonstrate its utility for outlier detection, data curation, and density estimation. The analysis is agnostic to the specific dataset or architecture and is validated across synthetic, controlled, and large-scale real-world datasets using state-of-the-art JEPA models.
Theoretical Foundations
The paper begins by revisiting the geometry of high-dimensional Gaussian embeddings. It is shown that as the embedding dimension K increases, normalized K-dimensional standard Gaussian vectors concentrate on the hypersphere and converge to a uniform distribution over its surface. This geometric property underpins the behavior of JEPA-trained encoders, which are explicitly or implicitly regularized to produce Gaussian-distributed embeddings.
The key theoretical result leverages the change-of-variable formula for densities under differentiable mappings. For a deep network f mapping input x to embedding f(x), the density of the embedding is given by:
pf(X)(f(x))=∫{z∣f(z)=f(x)}∏k=1rank(Jf(z))σk(Jf(z))pX(z)dHr(z)
where Jf(z) is the Jacobian of f at z, σk are its singular values, and K0 is the K1-dimensional Hausdorff measure over the level set. The implication is that for K2 to be distributed as a standard Gaussian, K3 must learn to modulate the input density K4 via its Jacobian, effectively internalizing the data density.
The main practical contribution is the derivation of the JEPA-SCORE, a sample-wise estimator of the data density learned by a JEPA-trained encoder. For an input K5, the JEPA-SCORE is defined as:
K6
This score is proportional to the log-likelihood of K7 under the implicit density learned by the encoder. The estimator is efficient to compute, requiring only the singular values of the Jacobian, and is robust to the choice of numerical stabilization parameters.
The following PyTorch code snippet implements the JEPA-SCORE:
K8
Empirical Validation
The authors validate the theoretical claims through a series of experiments:



Figure 2: Depiction of the 5 least (left) and 5 most (right) likely samples of class 21 from ImageNet as per JEPA-SCORE, consistent across multiple JEPA models.

Figure 3: Random samples from ImageNet-1k class 21, for comparison with the extremal JEPA-SCORE samples.
- Class-wise Consistency: Across different JEPA models (DINOv2, I-JEPA, MetaCLIP), the ordering of samples by JEPA-SCORE is highly consistent, and the same images are identified as high- or low-probability within a class.
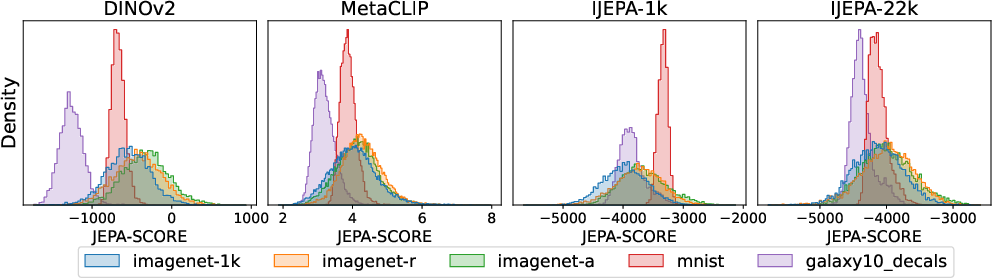
- Outlier Detection: The distribution of JEPA-SCOREs for in-distribution and out-of-distribution samples is well-separated, supporting its use for data curation and model assessment.





Figure 4: Histogram of JEPA-SCOREs for 5,000 samples from various datasets, showing clear separation between in-distribution and out-of-distribution data.
Architectural and Implementation Considerations
The JEPA-SCORE is model-agnostic and applies to any encoder trained with a JEPA objective, including moment-matching, non-parametric, and teacher-student variants. The only requirement is access to the encoder's Jacobian, which is tractable for moderate batch sizes and embedding dimensions. For large-scale models, efficient Jacobian-vector product techniques or randomized SVD approximations may be necessary.
The method is robust to the choice of data augmentations and is not sensitive to the specific form of the predictive invariance term, as the anti-collapse regularizer is the primary driver of density learning. The approach does not require explicit generative modeling or reconstruction, distinguishing it from traditional score-based or likelihood-based generative models.
Implications and Future Directions
The findings have several important implications:
- Nonparametric Density Estimation: JEPA-trained encoders provide a closed-form, nonparametric estimator of the data density, sidestepping the need for explicit generative modeling or input space reconstruction.
- Outlier and OOD Detection: The JEPA-SCORE can be used for robust outlier detection, data curation, and model readiness assessment for downstream tasks.
- Theoretical Unification: The work bridges the gap between self-supervised representation learning and score-based generative modeling, suggesting that representation learning objectives can yield implicit generative capabilities.
- Practical Utility: The method is simple to implement, computationally efficient, and applicable to a wide range of JEPA-based models and data modalities.
Potential future directions include scaling the approach to very high-dimensional inputs, integrating JEPA-SCORE into active learning or data selection pipelines, and exploring its use for generative modeling via score-based sampling.
Conclusion
This paper demonstrates that JEPAs, through their anti-collapse regularization, necessarily internalize the data density and enable closed-form, efficient density estimation via the JEPA-SCORE. The theoretical analysis is supported by strong empirical evidence across synthetic and real-world datasets. The results challenge the prevailing view that JEPA-based self-supervised learning is orthogonal to generative modeling and open new avenues for leveraging pretrained encoders in density estimation, outlier detection, and beyond.