Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
Abstract: Humanoid motion tracking policies are central to building teleoperation pipelines and hierarchical controllers, yet they face a fundamental challenge: the embodiment gap between humans and humanoid robots. Current approaches address this gap by retargeting human motion data to humanoid embodiments and then training reinforcement learning (RL) policies to imitate these reference trajectories. However, artifacts introduced during retargeting, such as foot sliding, self-penetration, and physically infeasible motion are often left in the reference trajectories for the RL policy to correct. While prior work has demonstrated motion tracking abilities, they often require extensive reward engineering and domain randomization to succeed. In this paper, we systematically evaluate how retargeting quality affects policy performance when excessive reward tuning is suppressed. To address issues that we identify with existing retargeting methods, we propose a new retargeting method, General Motion Retargeting (GMR). We evaluate GMR alongside two open-source retargeters, PHC and ProtoMotions, as well as with a high-quality closed-source dataset from Unitree. Using BeyondMimic for policy training, we isolate retargeting effects without reward tuning. Our experiments on a diverse subset of the LAFAN1 dataset reveal that while most motions can be tracked, artifacts in retargeted data significantly reduce policy robustness, particularly for dynamic or long sequences. GMR consistently outperforms existing open-source methods in both tracking performance and faithfulness to the source motion, achieving perceptual fidelity and policy success rates close to the closed-source baseline. Website: https://jaraujo98.github.io/retargeting_matters. Code: https://github.com/YanjieZe/GMR.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching humanoid robots (robots shaped like people) to copy human movements well. The big problem is that robots don’t have the exact same bodies as humans—different limb lengths, joint limits, and weights—so a robot can’t just “play back” human motion data directly. The authors show that how you convert (or “retarget”) human motions to a robot’s body matters a lot. They introduce a new method called General Motion Retargeting (GMR) and compare it with other retargeting methods to see which one helps robots learn better and move more like humans.
Key Questions
The paper asks three main questions in simple terms:
- Does the way we retarget human motion affect how well a robot can learn and perform those movements?
- What kinds of retargeting mistakes make it hard (or impossible) for the robot to learn the movement?
- How well do different retargeting methods keep the original “look and feel” of a human’s motion?
Methods and Approach
To make the comparison fair, the authors used the same training system for the robot across all retargeting methods:
- Motion retargeting: They tried four sources of robot-ready motion:
- PHC (an open method used in past research)
- ProtoMotions (another open method)
- GMR (their new method)
- Unitree (a high-quality but closed-source dataset)
- Robot training: They used a tool called BeyondMimic to train the robot to imitate each retargeted motion. Think of BeyondMimic as a coach that helps a robot learn by watching and copying a reference movement, without lots of custom tweaks or special tricks.
- Motions tested: They used 21 motion clips from a human motion dataset called LAFAN1—everything from walking and turning to running, dancing, jumping, and martial arts—lasting from about 5 seconds up to 2 minutes.
Here are a few key ideas explained in everyday language:
- Retargeting: Imagine you recorded a tall person’s dance and now want a shorter robot to do it. Retargeting is how you translate those moves so the robot’s joints and limbs can perform them without breaking rules (like bending too far or going through the floor).
- Inverse Kinematics (IK): This is like solving a puzzle backward. Instead of starting with joint angles, you start with where you want the hand or foot to be and figure out which angles make that happen.
- Differential IK: A “step-by-step” version of IK. It adjusts the robot’s joints in tiny steps to move closer to the target position smoothly.
- Scaling: Resizing the human motion to fit the robot’s size. Doing this wrong causes big problems (like toes sliding on the ground or legs clipping into each other).
- Testing conditions:
- Sim: Testing in the training simulator as-is.
- Sim-DR: Same simulator, but with extra randomness (like noisy sensors or small changes in robot mass) to check robustness.
- Sim2Sim (ROS/MuJoCo): A more realistic test using the same software framework used on real robots, including delays and state estimation, to mimic real-world deployment.
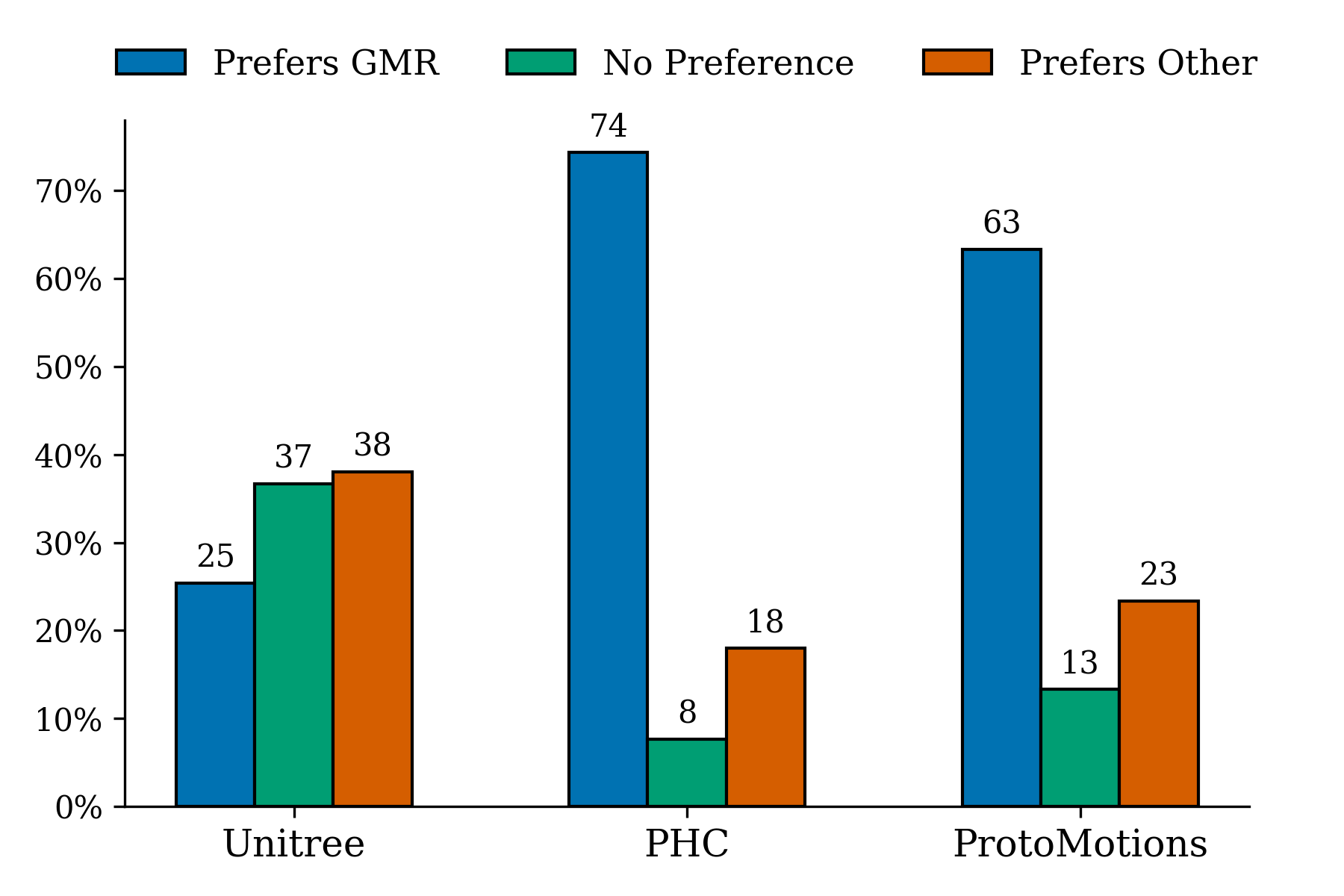
They also ran a user study: people watched short videos of retargeted robot motions and picked which looked more like the original human motion.
What GMR Does Differently
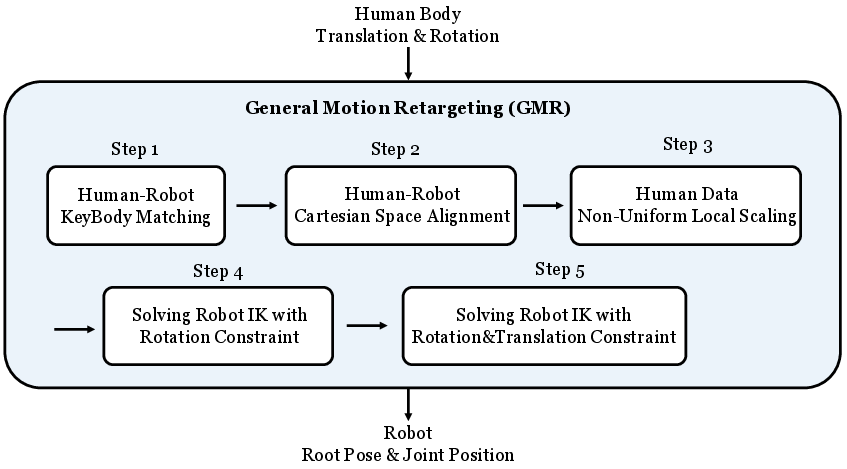
GMR was designed to fix common mistakes seen in other methods:
- Smarter scaling: Instead of one-size-fits-all scaling, GMR uses different local scaling for different body parts and carefully handles the robot’s root (the body’s base position) to avoid foot sliding.
- Two-stage optimization: 1) First, it gets the orientations (rotations) right and locks down feet and hands. 2) Then, it fine-tunes positions for all key body parts.
- Contact-aware and consistency-focused: It avoids things like ground penetration (going through the floor), self-intersections (body parts passing through each other), and sudden jumps in joint angles.
Main Findings
The authors found several important things:
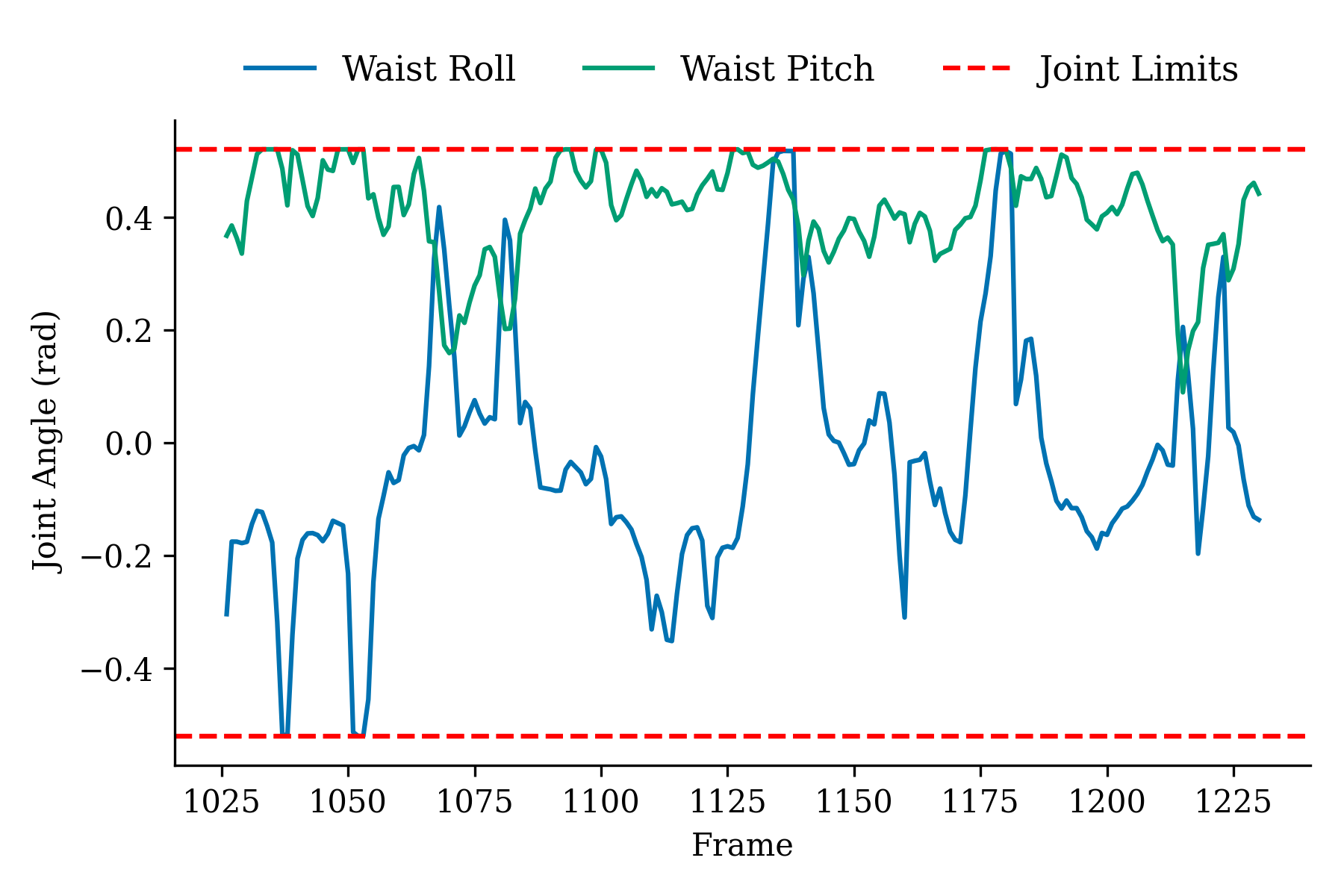
- Retargeting quality matters a lot: If the retargeted motion has mistakes, the robot’s policy (its learned movement plan) becomes less robust and more likely to fail, especially for fast or long sequences.
- Harmful artifacts include:
- Foot sliding or ground penetration (feet floating or sinking).
- Self-intersections (legs or arms passing through each other).
- Sudden spikes in joint speeds (jerky, unrealistic moves).
- GMR consistently outperformed other open methods (PHC and ProtoMotions) in both tracking performance and how faithful the motion looked compared to the human.
- GMR’s results were close to the high-quality Unitree dataset (the best-performing baseline), both in success rates and in how “human-like” the motion appeared to people.
- The very first frame of the reference motion matters: If the motion starts from a pose that’s hard for the robot to reach safely, the robot can fail immediately, regardless of retargeting quality.
Why This Is Important
Better retargeting makes it much easier to train robots that move like humans—without spending tons of time manually tuning the training rewards or parameters. This helps:
- Build reliable teleoperation systems (humans controlling robots remotely).
- Create layered controllers, where the robot can learn complex skills by imitating good examples.
- Speed up research and deployment by reducing trial-and-error.
- Keep motions faithful to the original human performance so robots learn the intended movement, not a distorted version.
In short, this paper shows that retargeting isn’t just a small preprocessing step—it’s a key ingredient. With GMR, researchers and engineers can produce cleaner, more realistic robot motions from human data, making humanoid robots safer, more capable, and more human-like in how they move. The authors also share their code, encouraging others to build on their work.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored based on the paper.
- Limited data sources: evaluation uses only LAFAN1; performance on other datasets (e.g., AMASS, motion from monocular video with typical reconstruction noise, diverse skeleton topologies) is unknown.
- Single target platform: all experiments target the Unitree G1; generality of conclusions and GMR’s performance across other humanoids (e.g., H1, NASA Valkyrie, Digit, Talos) with different kinematics, ROMs, and mass distributions remains unvalidated.
- No real-world hardware deployment: results are simulation-only (IsaacSim, sim-dr, and ROS/MuJoCo sim2sim); sim-to-real transfer performance and failure modes using GMR-retargeted references are untested.
- Interaction-free motions: motions involving complex scene/object interactions, hands-on-ground phases (except a cartwheel segment where hands/feet alternate contact), crawling, sit/stand, or multi-contact transitions are excluded; fidelity and policy learning under multi-contact constraints remain open.
- Contact handling remains kinematic: GMR uses non-uniform local scaling and IK but does not enforce explicit contact constraints (e.g., zero-velocity at contacts, no-slip, complementarity); the impact of adding physics/contacts-constrained optimization on artifact reduction and policy robustness is unexplored.
- Temporal consistency not explicitly optimized: per-frame IK with sequential warm starts lacks temporal smoothness regularization; sudden joint jumps in some sequences suggest the need for temporal penalties or global optimization; no ablation on temporal regularization effects.
- Parameter selection is manual and under-specified: body-wise scaling factors s_b, IK weights (w1, w2), and tightened joint limits are chosen heuristically; no sensitivity analysis, auto-tuning strategies, or guidelines for robust parameter selection across motions/robots.
- Artifact quantification is qualitative: the study identifies critical artifacts (ground penetration, self-intersections, sudden joint jumps) but does not provide quantitative pre-training metrics (e.g., slip distance, penetration depth, self-collision counts, jerk) or thresholds predictive of policy failure.
- No ablations on scaling design: GMR’s advantage is attributed to local non-uniform scaling and uniform root scaling, but there is no systematic ablation comparing global vs local scaling, root scaling variants, or anthropometric ratio-based scaling across diverse body shapes.
- Computational efficiency and scalability are unreported: no benchmarks on retargeting runtime, throughput for large datasets, or suitability for real-time/near-real-time teleoperation use; trade-offs vs PHC and ProtoMotions are not quantified.
- Closed-source baseline unexplained: the Unitree retarget outperforms open methods, but its techniques are unknown; there is no analysis to infer which algorithmic components (e.g., contact handling, smoothing, constraints) likely drive its superior performance.
- Initial pose/start-frame sensitivity unresolved: experiments show strong dependence on start-frame choice, but no method is proposed for automatic start-pose alignment, pre-roll strategies, or robust warm-start procedures to mitigate immediate failures.
- Limited robustness exploration: domain randomization is used as-is, but the interaction between artifact severity, DR magnitude, and policy robustness is not systematically mapped; it is unclear which DR regimes compensate for which retargeting defects.
- Reward shaping not studied: the paper hypothesizes that reward engineering can mitigate retargeting artifacts but explicitly avoids it; the extent to which specific reward terms or curriculum strategies reduce artifact impact remains unmeasured.
- Lack of contact-fidelity metrics: beyond MPBPE/MPJPE and success rates, there are no metrics for contact correctness (e.g., foot contact timing accuracy, slip/adhesion error), which are central to policy stability and realism.
- Limited perceptual evaluation: user study uses short (5 s) clips, small sample (N=20), unknown expertise levels, and no statistical power analysis; results may not generalize to longer horizons or expert judgments; no viewpoint or rendering-control analysis.
- No study of dynamic feasibility: retargeted trajectories are not assessed for dynamic consistency (e.g., torque/force limits, ZMP/CoP feasibility, momentum continuity); effect of filtering infeasible references on policy outcomes is unknown.
- Self-collision avoidance not enforced: aside from observing ProtoMotions failures, there’s no explicit self-collision constraint in GMR; the impact of integrating self-collision penalties/constraints within IK on artifact reduction is not evaluated.
- Joint limit tightening is ad hoc: narrowing joint limits to avoid “non-human” poses is mentioned but lacks a principled procedure (e.g., data-driven limits, comfort zones); the effect on reachability and biasing against valid motions is unexplored.
- Height post-processing is heuristic: subtracting minimum body height to fix floating/penetration is ad hoc; its effect on global motion plausibility, contact timing, and downstream policy tracking is not analyzed.
- Generalization across motion categories under-specified: while some motions succeed across methods, the study does not disentangle which motion attributes (speed, amplitude, contact frequency, symmetry) correlate with method-specific failures.
- No pipeline for automatic artifact remediation: when artifacts are detected (e.g., spikes), there is no automated correction (e.g., temporal filtering, re-optimization with modified weights, contact-aware fixes); the feasibility of such automated repair loops is open.
- Lack of end-to-end learning baselines: no comparison with learning-based retargeters for full-body motions (beyond upper-body) or hybrid physics-informed learners; it’s unknown whether learned retargeters could reduce artifacts relative to IK-based methods.
- No multi-trajectory policy evaluation: only single-trajectory policies are trained; it’s unclear how retargeting quality influences multi-clip policies, motion blending, or hierarchical controllers that must transition between retargeted skills.
- Energy/effort and smoothness not measured: policies may succeed with higher tracking errors; the impact of retargeting on policy jerk, energy/torque usage, and perceived motion naturalness lacks quantitative assessment.
- Safety and hardware risk not assessed: observed self-intersections and penetrations could be hazardous on hardware; there is no safety analysis or constraints integration plan to ensure safe execution of retargeted references on real robots.
- Tooling and reproducibility gaps: GMR requires manual body mapping and weight specification; there is no automated skeleton alignment/matching tool or standardized config templates for different robots/datasets to ensure reproducibility and ease of adoption.
Practical Applications
Overview
This paper introduces General Motion Retargeting (GMR), a kinematics-based pipeline that reduces artifacts when mapping human motions (e.g., BVH/SMPL-X) to humanoid robots (e.g., Unitree G1). It demonstrates that retargeting quality strongly impacts reinforcement learning (RL) policy performance for motion tracking without heavy reward tuning, identifies critical artifacts (foot penetration, self-intersection, abrupt velocity spikes), and presents evaluation procedures and a user study showing GMR’s improved fidelity over popular open-source retargeters (PHC, ProtoMotions), approaching a closed-source Unitree baseline.
Below are practical applications derived from the findings, methods, and innovations, organized by immediacy and linked to relevant sectors. Each item includes assumptions or dependencies that affect feasibility.
Immediate Applications
These applications can be deployed now, using the released GMR codebase and the paper’s evaluation workflow.
- Robotics: Higher-quality motion datasets for training humanoid controllers
- Use case: Retarget human motion libraries to specific humanoid embodiments with fewer artifacts, improving policy robustness and tracking accuracy without extensive reward engineering.
- Sector: Robotics, software.
- Tools/workflows: GMR (github.com/YanjieZe/GMR) + BeyondMimic training; IsaacSim/MuJoCo for sim, sim-dr, and sim2sim evaluation; automated artifact checks.
- Assumptions/dependencies: Accurate URDF/XML robot models; correct human–robot body mapping; BVH→SMPL-X conversion where required; compute resources for optimization; availability of motion capture data.
- Teleoperation motion libraries for routine procedures
- Use case: Prepare curated, robot-ready motion clips (walking, turning, dynamic movements) for teleoperation or supervisory control in logistics, manufacturing, and service robots.
- Sector: Robotics, manufacturing, logistics, services.
- Tools/workflows: Offline retargeting with GMR; start/end pose validation; sim2sim robustness checks to mimic deployment latency and state-estimation noise.
- Assumptions/dependencies: Latency and state estimation constraints; safe startup/end poses; minimal contact-rich interaction in source motions unless further modeling is done.
- Motion hygiene QA: Automated artifact detection gates
- Use case: Integrate “motion hygiene” checks in CI pipelines to flag foot penetration, self-intersections, and velocity spikes before training or deployment.
- Sector: Software, robotics.
- Tools/workflows: FK-based height checks, collision checks (self-intersection), derivative thresholds on joint trajectories; thresholds from paper’s failure modes.
- Assumptions/dependencies: Reliable collision models; validated thresholds; access to the robot’s kinematic tree and link geometries.
- Entertainment and public demonstrations: Robust choreography retargeting
- Use case: Retarget dance/sports sequences onto humanoids for shows with higher perceptual fidelity and reduced failure risk.
- Sector: Entertainment, robotics.
- Tools/workflows: GMR retargeting + sim2sim testing; start/end pose constraints; artifact gate; emergency stops integrated.
- Assumptions/dependencies: Stage safety; compliant actuators; energy budget for long sequences; vetted motions with minimal environmental interactions.
- Education and research replication
- Use case: Teach the embodiment gap and retargeting evaluation; reproduce the study to compare retargeters and policies across datasets.
- Sector: Academia, education.
- Tools/workflows: GMR + BeyondMimic; LAFAN1/AMASS motion sets; user-study protocol; tracking metrics (g-mpbpe, mpbpe, mpjpe).
- Assumptions/dependencies: Curriculum integration; access to simulation tools; ethical approval for user studies where needed.
- Procurement and deployment guidelines for humanoids
- Use case: Require motion retargeting QA, simulator-based success criteria (sim, sim-dr, sim2sim), and safe start/end pose design in vendor workflows.
- Sector: Policy, enterprise robotics.
- Tools/workflows: Formal deployment checklists; minimum success-rate thresholds; motion artifact thresholds.
- Assumptions/dependencies: Organizational buy-in; access to vendor stack for testing; alignment with safety standards.
- Cross-toolchain skeleton alignment libraries
- Use case: Reusable mapping between BVH/SMPL(-X) and specific humanoids, including non-uniform local scaling factors per body segment.
- Sector: Software, robotics.
- Tools/workflows: Public mapping templates; local scaling configs; conversion utilities.
- Assumptions/dependencies: Accurate anthropometric fit; consistent joint naming and conventions.
- Start/end pose validation tool
- Use case: Automatically adjust or validate the first and last frames of retargeted sequences to reduce early failures and ensure safe deactivation.
- Sector: Software, robotics.
- Tools/workflows: Pose feasibility checks; IK warm-start; stable stance heuristics; small pre-roll sequences to align state estimation.
- Assumptions/dependencies: Known robot balance constraints; state estimator requirements.
Long-Term Applications
These applications require further research, scaling, or development beyond the paper’s scope.
- Real-time retargeting for live teleoperation
- Use case: Online GMR variant with latency-aware IK and continuous scaling to map operator motion streams directly onto robots in real time.
- Sector: Robotics, teleoperation.
- Tools/workflows: High-frequency IK (Mink or similar), robust state estimation, streaming BVH/SMPL-X from wearable sensors or video.
- Assumptions/dependencies: Low-latency compute; reliable sensor fusion; safety gating; controller integration; contact handling.
- Contact-rich retargeting (environment and object interactions)
- Use case: Extend GMR to include foot-ground friction modeling, hand-object contacts, and multi-contact constraints for manipulation, crawling, and getting up.
- Sector: Robotics, manufacturing, service robots.
- Tools/workflows: Contact-aware IK/optimization; physics-informed retargeting; constraint solvers; scene geometry modeling.
- Assumptions/dependencies: Accurate contact models; tuned solvers; high-quality motion capture with contact annotations.
- Cross-embodiment retargeting for prosthetics, exoskeletons, and VR avatars
- Use case: Map human motions to assistive devices or virtual embodiments with improved naturalness and reduced discomfort/fatigue.
- Sector: Healthcare, AR/VR, rehabilitation.
- Tools/workflows: Non-uniform local scaling per device; comfort-driven constraints; clinical evaluation; personalized parameter fitting.
- Assumptions/dependencies: Regulatory approval; clinical trials; human safety; diverse device kinematics.
- Standardization and certification of motion retargeting quality
- Use case: Industry test suites and thresholds (artifact detection, fidelity scores, success rates) to certify motion assets and retargeters.
- Sector: Policy, robotics industry.
- Tools/workflows: Open benchmarks (datasets, metrics), user-study protocols, certification bodies.
- Assumptions/dependencies: Consortium participation; shared datasets; legal frameworks.
- Motion foundation models and hierarchical controllers trained on high-quality retargeted data
- Use case: Use GMR-cleaned motion corpora to train general-purpose controllers or motion diffusion models for humanoids, enabling compositional skills.
- Sector: Robotics, software.
- Tools/workflows: Large-scale datasets; BeyondMimic-like pipelines; hierarchical planners integrating motion tracking and task objectives.
- Assumptions/dependencies: Compute scale; data diversity; integration with vision/video-to-motion models.
- Creative authoring tools for robot choreography and sports routines
- Use case: End-to-end tools for authors to design human performances and auto-retarget them to robots, with immediate feedback and safety checks.
- Sector: Entertainment, education.
- Tools/workflows: GUI-based editors; live simulation; artifact QA; start/end pose auto-correction.
- Assumptions/dependencies: Usability research; hardware availability; liability/safety management.
- Safety tooling and formal verification of retargeted motions
- Use case: Formal guarantees on joint limits, collision-free trajectories, and contact consistency; compliance with ISO/ANSI robot safety standards.
- Sector: Policy, safety engineering.
- Tools/workflows: Model checking; constraint programming; compliance pipelines.
- Assumptions/dependencies: Formal specs; acceptance by regulators; verified models of robots and environments.
- Cross-robot motion marketplaces and content licensing
- Use case: Platforms to share, license, and adapt motion assets across different humanoids using standardized mappings and metadata.
- Sector: Software, media, robotics.
- Tools/workflows: Skeleton mapping standards; quality metadata; royalty and licensing frameworks.
- Assumptions/dependencies: Vendor cooperation; IP management; interoperability agreements.
- Energy- and wear-aware retargeting
- Use case: Optimize retargeted motions for energy efficiency and reduced actuator wear while maintaining fidelity.
- Sector: Energy, robotics.
- Tools/workflows: Actuation and energy models integrated into IK optimization; multi-objective cost functions.
- Assumptions/dependencies: Accurate robot dynamics models; battery/thermal constraints; long-horizon evaluation.
- Automated parameter tuning via meta-learning
- Use case: Learn to set IK weights, scaling factors, and constraints per motion category to minimize artifacts and maximize policy success.
- Sector: Software, robotics.
- Tools/workflows: Meta-optimization; cross-motion generalization; feedback loops from training outcomes.
- Assumptions/dependencies: Sufficient data for meta-learning; robust evaluation signals; transferability across robots.
Notes on Feasibility and Dependencies
- The paper’s empirical scope excludes complex object/environment interactions; extending GMR to contact-rich tasks is a long-term effort.
- Results target the Unitree G1; generalization to other humanoids requires validated body mappings and may alter artifact profiles.
- Conversions between BVH and SMPL(-X) introduce their own assumptions; accurate skeleton fits and joint conventions are critical.
- Start/end pose selection materially affects success; automated validation is recommended before deployment.
- Robustness hinges on simulator–real-world gaps, state estimation noise, and controller latency; sim2sim testing is a valuable intermediary step.
- Open-source dependencies include Mink (differential IK), BeyondMimic (policy training and evaluation), and IsaacSim/MuJoCo; licensing and compatibility should be checked.
Glossary
- Adadelta: An adaptive gradient-based optimizer used to update parameters during training. "The optimizer for the root pose is Adam, and the optimizer for the joint values is Adadelta."
- Adam: A popular adaptive optimizer for gradient descent in machine learning. "The optimizer for the root pose is Adam, and the optimizer for the joint values is Adadelta."
- BVH (Biovision Hierarchy): A motion capture file format encoding skeletal hierarchy and joint angles over time. "LAFAN1 files are provided in the BVH format, which GMR is directly compatible with."
- Cartesian space: The task-space of positions and orientations (as opposed to joint space). "The vanilla WBGR ignores the size difference in the Cartesian space and performs IK to only match the orientations of key links."
- Differential IK: An inverse kinematics approach that solves for joint velocities to reduce task-space errors. "Other works have explored the use of differential IK solvers."
- Domain randomization: Randomizing simulation parameters during training to improve robustness and transfer. "While prior work has demonstrated motion tracking abilities, they often require extensive reward engineering and domain randomization to succeed."
- End-effector: A robot’s terminal link used to interact with the environment (e.g., hand, foot). "We consider only body orientations and positions of the end-effectors (hands and feet)."
- Exponential map: A Lie-theoretic mapping from angular velocity (so(3)) to rotation (SO(3)), used to represent orientation differences. "R_i \ominus R_j is the exponential map representation of the orientation difference between R_i and R_j."
- Forward kinematics (FK): Computing link positions/orientations from joint values. "Then, given the pose parameters of the human motion, the SMPL body model is used to calculate the target 3D coordinates... and then forward kinematics is used to compute the height of all robot bodies."
- General Motion Retargeting (GMR): The proposed method for scaling and optimizing human motions onto humanoid robots. "To address issues that we identify with existing retargeting methods, we propose a new retargeting method, General Motion Retargeting (GMR)."
- Generalized coordinates: The vector of minimal parameters describing a robot’s configuration (e.g., root pose and joint angles). "We wish to find robot generalized coordinates (root translation, root rotation, and joint values)..."
- Generalized velocities: Time derivatives of generalized coordinates used to reduce task-space errors in differential IK. "Rather than finding the values of that minimize our cost function, we compute generalized velocities that when integrated reduce our cost."
- Inverse kinematics (IK): Computing joint values that achieve desired positions/orientations of selected bodies. "By solving the inverse kinematics~(IK) problem, approaches of whole-body geometric retargeting~(WBGR) perform whole-body retargeting..."
- IsaacSim: NVIDIA’s robotics simulation environment used for training/evaluation. "We use BeyondMimic to train individual motion imitation policies for each retargeted motion in IsaacSim."
- Jacobian matrix: Matrix of partial derivatives mapping joint velocities to task-space velocity changes. "J(\mathbf{q}) = \frac{\partial e}{\partial \mathbf{q}} is the Jacobian matrix of the loss relative to q."
- Joint regressor: A linear mapping from mesh vertices to joint locations in the SMPL model. "A joint regressor is used to regress the 3D positions of the joints."
- LAFAN1: A human motion dataset of diverse everyday and dynamic movements. "We select a diverse sample from the LAFAN1 dataset..."
- Mink: A differential IK solver used to compute generalized velocities that reduce task-space errors. "It then uses Mink to minimize the joint position and orientation errors between the scaled human and robot key bodies."
- MuJoCo: A physics engine for robotics simulation and control. "We leverage this to thoroughly and safely evaluate our policies in a setup mimicking that used in the real world. We refer to this condition as sim2sim evaluation... a ROS node running MuJoCo."
- ProtoMotions: A package providing motion imitation baselines and an optimization-based retargeting method. "The ProtoMotions package is a collection of standard implementations of popular methods for training motion imitation policies. It comes with an optimization-based retargeting algorithm."
- Reinforcement learning (RL): Learning control policies via reward-driven trial and error. "Current approaches address this gap by retargeting human motion data to humanoid embodiments and then training reinforcement learning (RL) policies to imitate these reference trajectories."
- Reward shaping: Engineering the reward function to guide RL training more effectively. "Transferring them to the real world demands extensive trial-and-error, reward shaping, and parameter tuning."
- Robot Operating System (ROS): A middleware framework for robot software development. "This package also comes with a ROS node running MuJoCo."
- SMPL: A parametric human body model mapping shape and pose parameters to a 3D mesh and joints. "SMPL is a parametric human body model $f_{\text{SMPL}$ that, given a vector of shape parameters and pose parameters , returns the 3D locations of vertices..."
- SMPL-X: An extended SMPL model with additional joints and expressive features. "ProtoMotions additionaly supports the SMPL-X \cite{SMPL-X:2019} format."
- SO(3): The Lie group of 3D rotations; used to represent joint orientations. "Besides, additional processing is needed to convert the joint space from humans to humanoids..."
- Teleoperation: Remotely controlling a robot by mapping a human operator’s motions/commands. "Humanoid motion tracking policies are central to building teleoperation pipelines..."
- Unified Robot Description Format (URDF): An XML format for specifying robot kinematic and dynamic models. "Found in XML or URDF robot description files..."
- Unitree G1: A specific humanoid robot used as the target platform for retargeting. "We retarget each motion sequence to a Unitree G1 robot."
- Whole-body geometric retargeting (WBGR): Retargeting method using IK to map full-body motions despite joint-space misalignments. "By solving the inverse kinematics~(IK) problem, approaches of whole-body geometric retargeting~(WBGR) perform whole-body retargeting..."
- Yaw: The rotation about the vertical axis component of orientation. "The root position and orientation components of are initialized with... the yaw component of the orientation of the human root key body."
- Zero-shot: Deploying a model to a new setting without further fine-tuning. "In most cases (for an exception see \cite{he2025asap}), this policy is then deployed zero-shot into the real world."
Collections
Sign up for free to add this paper to one or more collections.

