Tracing the Representation Geometry of Language Models from Pretraining to Post-training
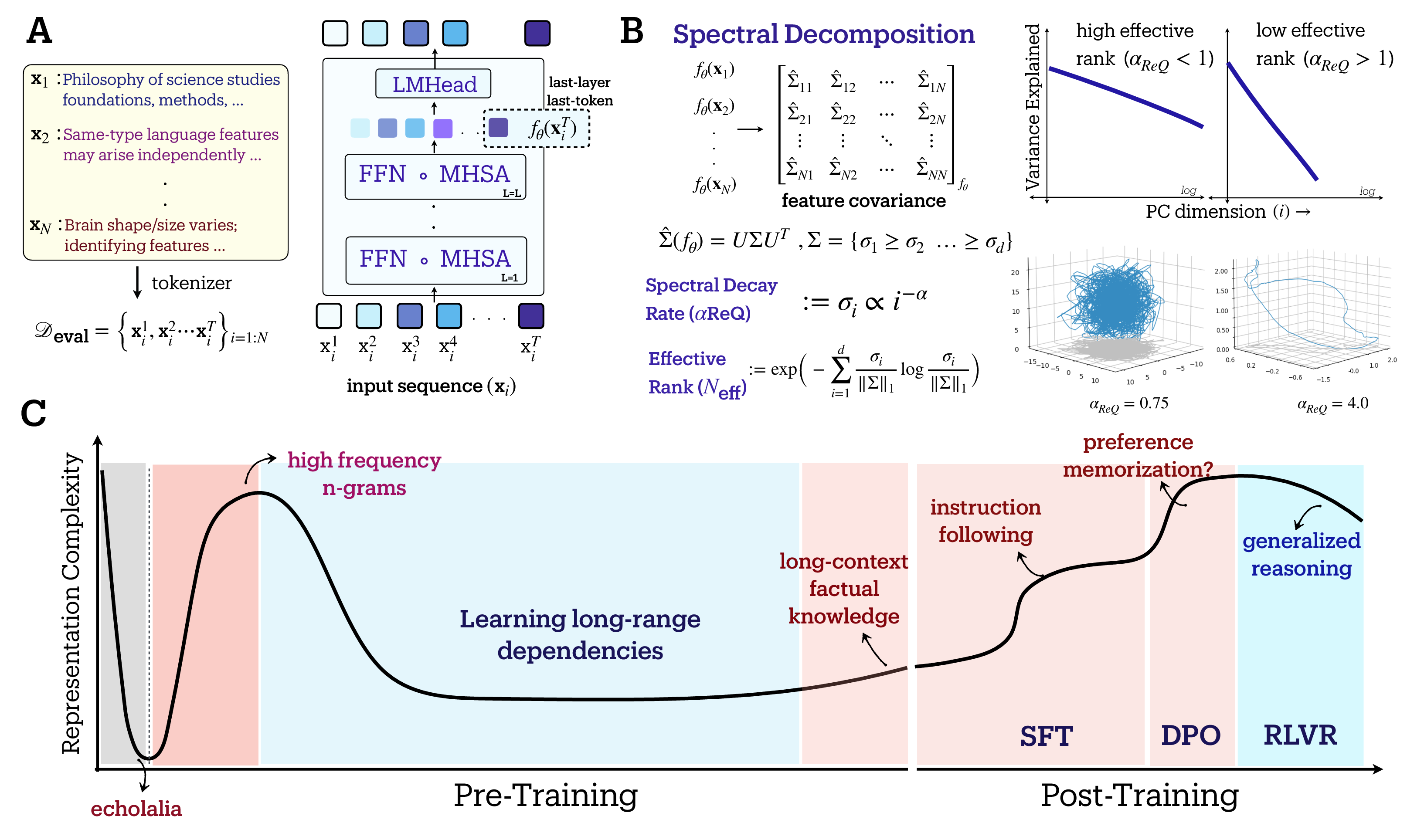
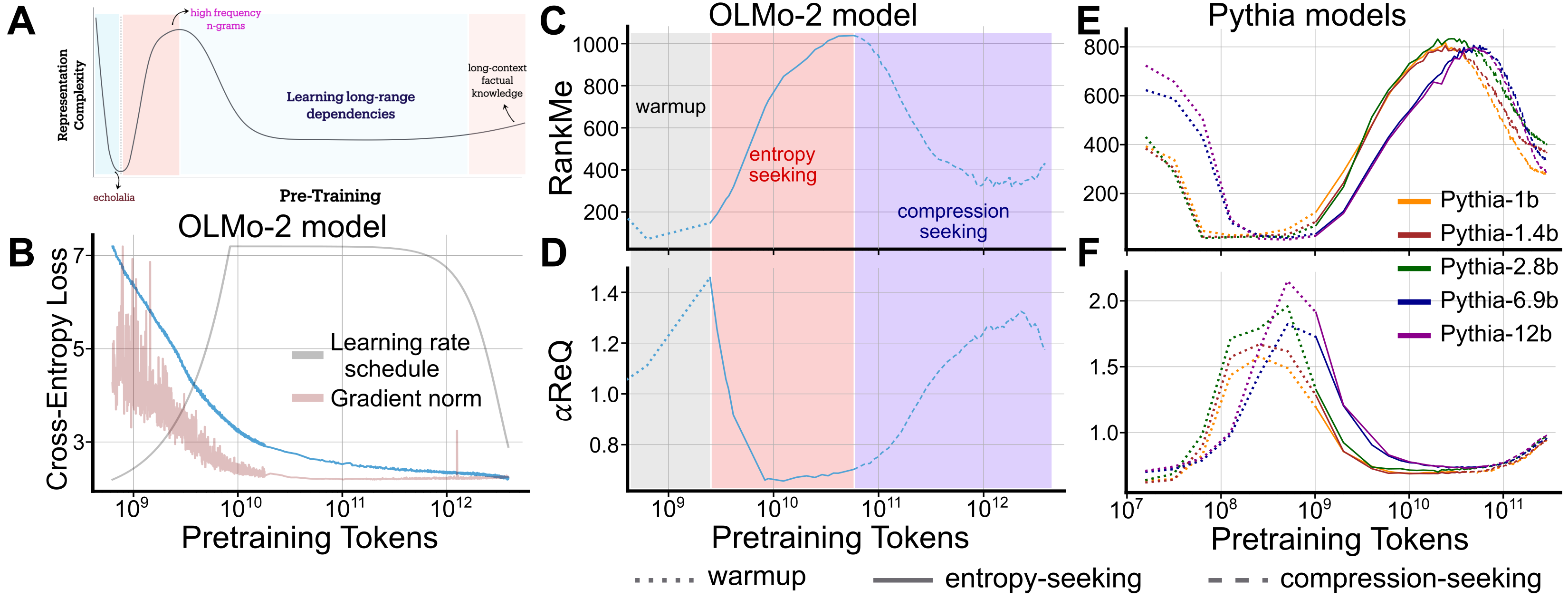
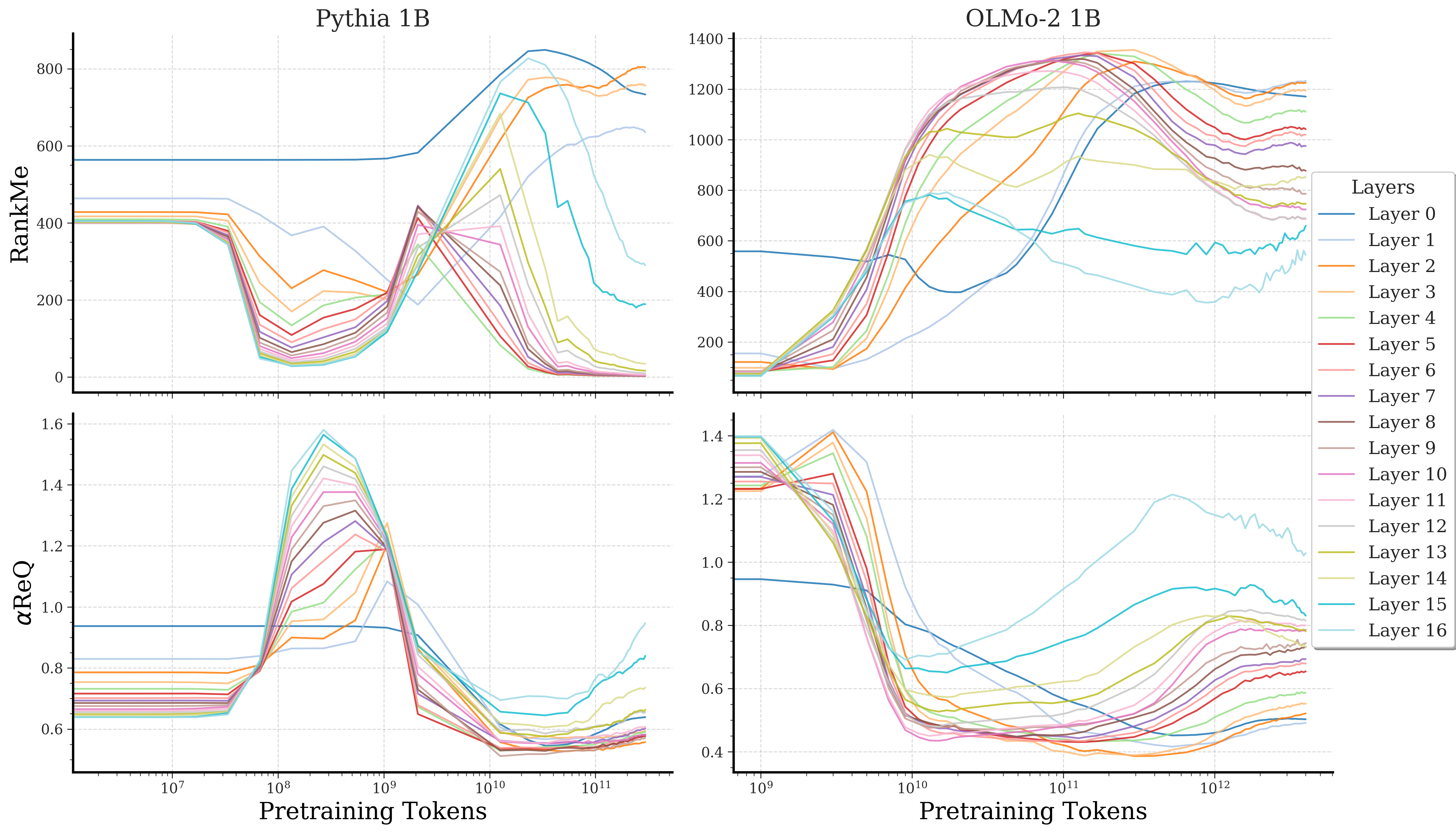
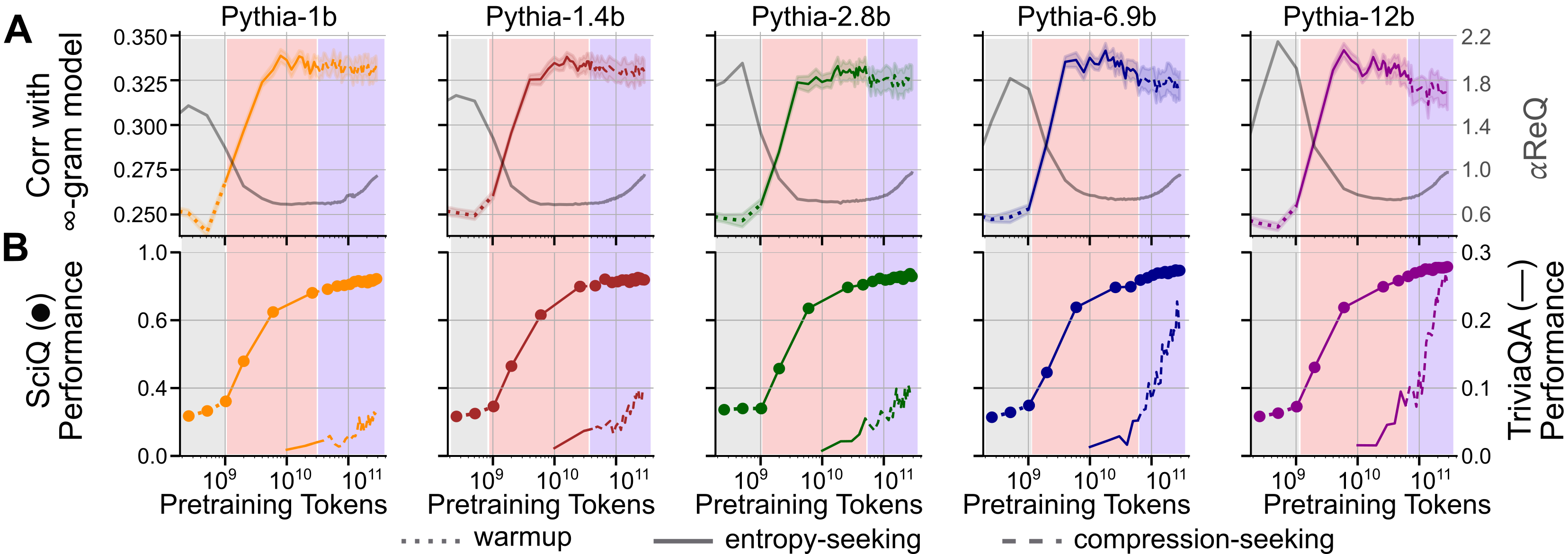
Abstract: Standard training metrics like loss fail to explain the emergence of complex capabilities in LLMs. We take a spectral approach to investigate the geometry of learned representations across pretraining and post-training, measuring effective rank (RankMe) and eigenspectrum decay ($\alpha$-ReQ). With OLMo (1B-7B) and Pythia (160M-12B) models, we uncover a consistent non-monotonic sequence of three geometric phases during autoregressive pretraining. The initial "warmup" phase exhibits rapid representational collapse. This is followed by an "entropy-seeking" phase, where the manifold's dimensionality expands substantially, coinciding with peak n-gram memorization. Subsequently, a "compression-seeking" phase imposes anisotropic consolidation, selectively preserving variance along dominant eigendirections while contracting others, a transition marked with significant improvement in downstream task performance. We show these phases can emerge from a fundamental interplay of cross-entropy optimization under skewed token frequencies and representational bottlenecks ($d \ll |V|$). Post-training further transforms geometry: SFT and DPO drive "entropy-seeking" dynamics to integrate specific instructional or preferential data, improving in-distribution performance while degrading out-of-distribution robustness. Conversely, RLVR induces "compression-seeking", enhancing reward alignment but reducing generation diversity.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to be actionable for future research.
- Measurement scope: The analysis focuses on last-token, last-layer representations; the extent to which phase dynamics hold for mid-sequence tokens, multi-token aggregates, and alternative readouts (e.g., residual streams, attention outputs, logits) is not established.
- Phase boundary detection: The paper qualitatively names Gray, Maroon, and BlueViolet phases, but lacks a reproducible, quantitative criterion (e.g., thresholding rules on RankMe/α, change-point detection) for automatically segmenting training into phases across runs.
- Architectural dependence: How phase emergence and spectral metrics vary with architecture (depth/width scaling, attention head count, rotary vs absolute position encodings, normalization schemes, activation functions, mixture-of-experts, encoder-decoder vs decoder-only) is not systematically studied.
- Optimizer and hyperparameters: The role of optimizer choice (AdamW vs SGD variants), weight decay, gradient clipping, batch size, learning-rate schedules (including constant LR and different warmups), dropout, and tokenization in shaping the phases is not disentangled.
- Data distribution effects: Universality of phases across pretraining corpora (FineWeb vs Pile vs other mixtures), document deduplication, domain balance, multilingual settings, and curriculum/data-ordering is not tested; confounds due to skewed token frequencies are asserted but not exhaustively validated.
- Scale limits: Results are capped at ~12B parameters; whether the same phase dynamics persist, change, or bifurcate for frontier-scale models (≥70B, ≥100B) remains unanswered.
- Layerwise generality: While some layerwise results are shown, a systematic mapping of phase timing and magnitude across all layers and modules (MLP vs attention, early vs late layers, heads) is missing.
- Alternative geometry measures: The study uses RankMe and power-law decay α; robustness to alternative similarity/geometry metrics (e.g., CKA, singular value distribution stability, participation ratio, mutual information, Fisher information, NTK spectra) is unexplored.
- Covariance estimation: The effective-rank estimates rely on ~10k samples and quadratic scaling with hidden dimension; statistical efficiency, sample size sensitivity, subsampling strategies, and bias/variance trade-offs of spectral estimation are not quantified.
- Centering and preprocessing: Choices around centering, whitening, sequence-length normalization, and feature preprocessing for covariance estimation are not ablated; their impact on RankMe/α trajectories is unclear.
- Task coverage: Links between phases and capabilities are shown for SciQ and TriviaQA; generality to broader task families (reasoning, code, math beyond AMC-23, long-context retrieval, multilingual QA, safety/factuality) is not demonstrated.
- Long-context rigor: Claims about BlueViolet aiding long-range dependencies lack controlled long-context benchmarks (e.g., needle-in-a-haystack, book-level coherence, retrieval with varying context windows) and ablations on context length.
- Memorization metric validity: The infinity-gram alignment (Spearman correlation) primarily captures short/mid-context statistics; complementary memorization indicators (e.g., exact regurgitation rates, near-duplicate generation, suffix/prefix leakage) and their relation to phases remain unmeasured.
- Causality vs correlation: The paper’s phase-capability relationships are correlational; causal tests (e.g., controlled interventions that manipulate spectral geometry to observe capability shifts) are not performed.
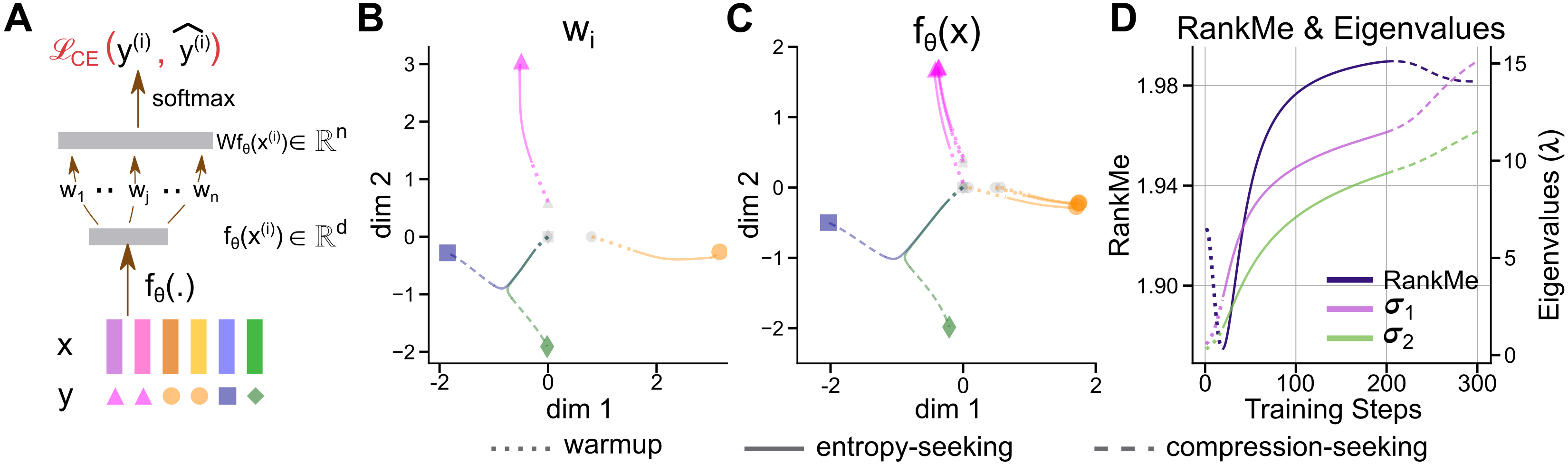
- Toy-model realism: The mechanistic explanation uses a linear feature extractor and classifier; extension to non-linear transformers (attention, residual connections) and formal conditions guaranteeing phase transitions in such models is missing.
- Bottleneck condition: The theoretical bottleneck assumption () is asserted as necessary for BlueViolet; quantitative tests varying (width scaling) in real LLMs to confirm necessity and sufficiency are absent.
- Eigenvector reuse and anisotropy: Direct empirical evidence in LLMs for “selection bias” (Δσ_i ∝ σ_i) and eigenvector alignment over training is limited; tracking eigenvectors over time and verifying rotation/reuse dynamics would strengthen the mechanism.
- Full-spectrum necessity: Eigenvector ablations show performance depends on the full spectrum, but do not test targeted removal strategies, layer-specific spectra, or interactions between subspaces (e.g., top-k vs mid-spectrum vs tail) across diverse tasks.
- Phase cycling: Observations suggest possible repeated Maroon/BlueViolet cycles with extended pretraining; conditions under which cycles repeat, dampen, or change character are not characterized.
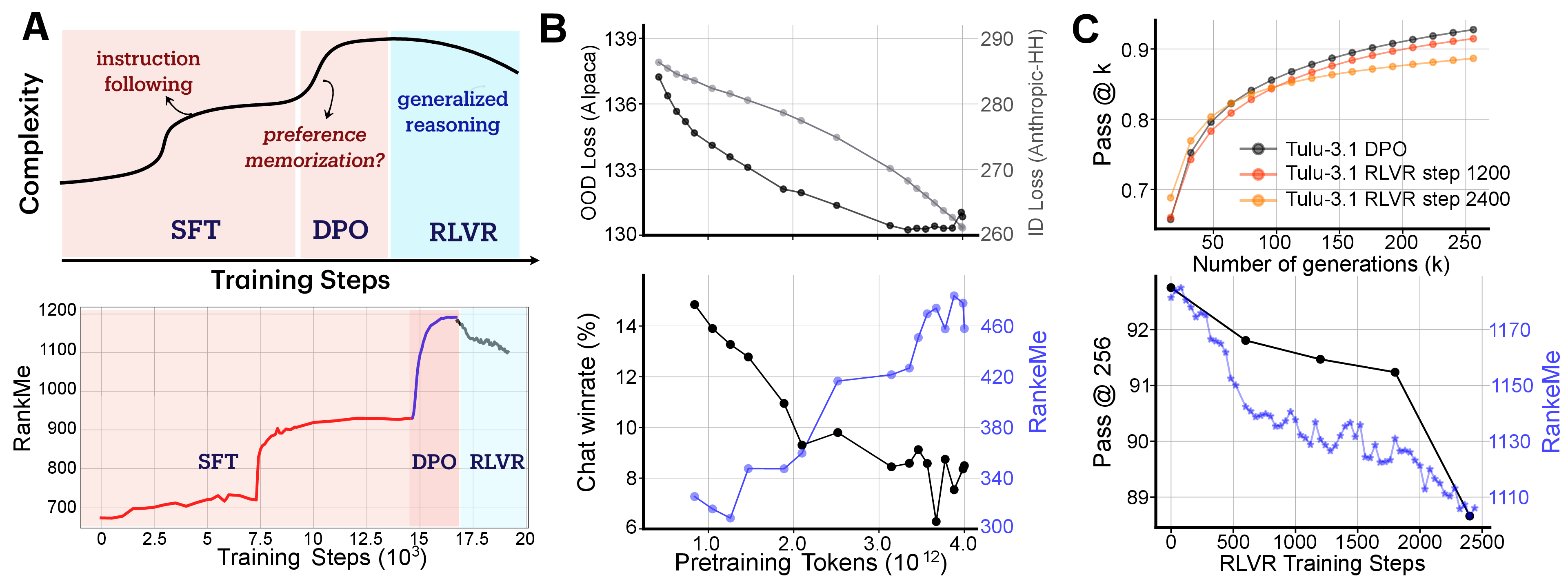
- Post-training generality: The conclusion that SFT/DPO induce Maroon and RLVR induces BlueViolet is drawn from Tülu-3.1 and OLMo-2-1B; generality across other post-training recipes (PAIR, RLAIF, iterative DPO, multi-objective RL), datasets, and base models is unknown.
- RLVR diversity vs reward alignment: Declines in pass@256 after RLVR imply reduced exploration, but the specific mechanisms (entropy regularization, policy collapse, reward shaping) and trade-offs between diversity and correctness are not dissected; dependence on sampling parameters (temperature, top-p) is not ablated.
- In-distribution vs OOD robustness: The observed ID/OOD trade-off under SFT is shown for AH vs AF; systematic OOD evaluations (distribution shifts in style, topic, instruction format, difficulty) and how geometry mediates robustness are not provided.
- Safety and bias: How geometry phases affect safety (toxicity, jailbreak robustness), bias, and hallucinations is not addressed; whether BlueViolet consolidation aids or harms safety remains an open question.
- Evaluation judges and win-rates: The AlpacaEval win-rate interpretation may be confounded by judge biases; cross-judge validation and consistency checks (e.g., different LLM judges, human evaluation) are not presented.
- Training interventions: Concrete recipes to steer geometry (e.g., schedule designs to delay/advance BlueViolet, spectral regularizers, representation bottleneck tuning, controlled noise injection) and their downstream payoff remain to be developed and validated.
- Generalization bounds: The link between RankMe/α and generalization is motivated by prior theory, but explicit predictive models (e.g., mapping spectral metrics to expected task accuracy or robustness bounds) are not instantiated.
- Multilingual and modality extension: Whether similar phases occur in multilingual LLMs and multimodal transformers (text–image, text–code) is untested; cross-lingual and cross-modal geometry comparisons are missing.
- Tokenization effects: Influence of tokenizer vocabulary, BPE merges, and subword segmentation on token frequency skew and phase dynamics is not explored.
- Reproducibility across seeds: Sensitivity of phase detection and spectral trajectories to random seeds, data-order seeds, and initialization schemes is not reported.
- Practical compute cost: The feasibility of tracking geometry online during large-scale training (compute/memory overhead, approximate estimators) and its utility for checkpoint selection or early stopping are not evaluated.
Collections
Sign up for free to add this paper to one or more collections.

