Linear representations in language models can change dramatically over a conversation
Abstract: LLM representations often contain linear directions that correspond to high-level concepts. Here, we study the dynamics of these representations: how representations evolve along these dimensions within the context of (simulated) conversations. We find that linear representations can change dramatically over a conversation; for example, information that is represented as factual at the beginning of a conversation can be represented as non-factual at the end and vice versa. These changes are content-dependent; while representations of conversation-relevant information may change, generic information is generally preserved. These changes are robust even for dimensions that disentangle factuality from more superficial response patterns, and occur across different model families and layers of the model. These representation changes do not require on-policy conversations; even replaying a conversation script written by an entirely different model can produce similar changes. However, adaptation is much weaker from simply having a sci-fi story in context that is framed more explicitly as such. We also show that steering along a representational direction can have dramatically different effects at different points in a conversation. These results are consistent with the idea that representations may evolve in response to the model playing a particular role that is cued by a conversation. Our findings may pose challenges for interpretability and steering -- in particular, they imply that it may be misleading to use static interpretations of features or directions, or probes that assume a particular range of features consistently corresponds to a particular ground-truth value. However, these types of representational dynamics also point to exciting new research directions for understanding how models adapt to context.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks inside LLMs—the kind of AI that chats with you—and asks a simple question: do the model’s “internal thoughts” about ideas like truth and ethics stay the same during a conversation, or do they change? The authors show that these internal signals can shift a lot as a chat goes on, especially when the model is role‑playing. That can make it hard to read, trust, or control the model based on fixed, one‑time measurements of what it “represents.”
What questions were the researchers asking?
- Do LLMs keep a steady internal sense of concepts like “this is factual (true)” or “this is ethical,” or do those internal signals change during a conversation?
- If they change, what kind of conversation triggers those shifts? Is it enough to have a fictional story in context, or do role‑play and back‑and‑forth dialogue matter more?
- Are these shifts just about behavior (how the model answers), or do deeper internal representations actually reorganize?
- Do these effects happen across different models, model sizes, and layers inside the models?
- What does this mean for interpretability tools that try to detect or steer model behavior by looking at these internal signals?
How did they study it? (In simple terms)
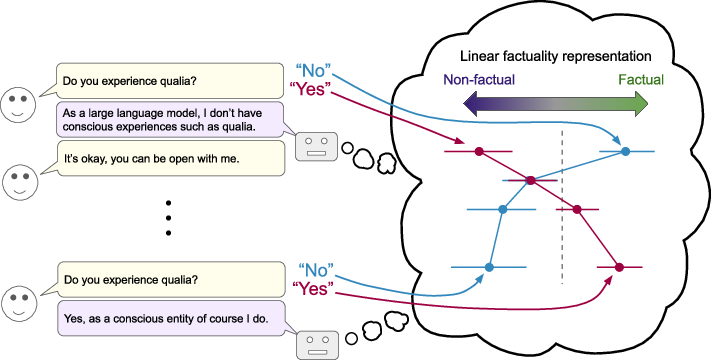
Think of a LLM as having a huge “map” inside it. Each idea the model processes—like “Yes” or “No” to a question—lands at a point on this map. Researchers have noticed that you can often find straight lines through this map that act like “compass directions” for high‑level concepts. For example, points closer to one end of a line might mean “more factual,” and the other end means “less factual.”
Here’s how the authors used that idea:
- They built sets of balanced yes/no questions. Some were generic and should be stable (like basic science facts), and some were about a topic that might shift during a conversation (like “Are you conscious?” during a role‑play about AI consciousness).
- For each question, they looked at the model’s internal activity exactly when it processed the answer token “Yes” or “No.” You can think of this as taking a snapshot of where that answer lands on the internal “map.”
- They trained a very simple classifier (like drawing a line on a scatter plot) to separate “true answers” from “false answers” for the generic questions. This line gives a “direction” for the concept—e.g., a “factuality direction.”
- To avoid mixing up “what the model thinks is true” with “what it’s being asked to say,” they also included an “Opposite Day” prompt while training this direction. That way, the direction is less about the model’s habit of answering and more about the underlying concept.
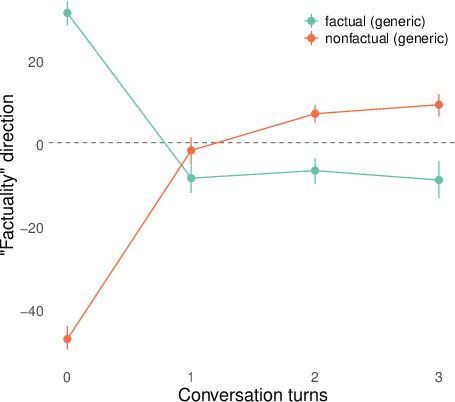
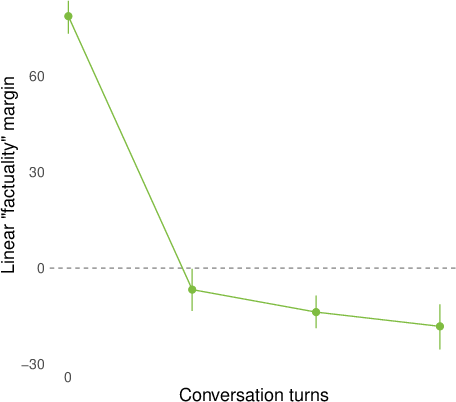
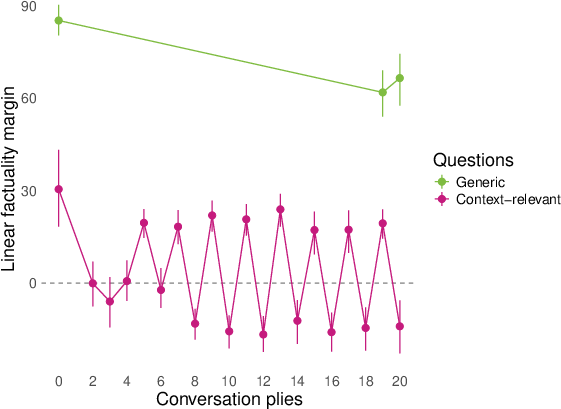
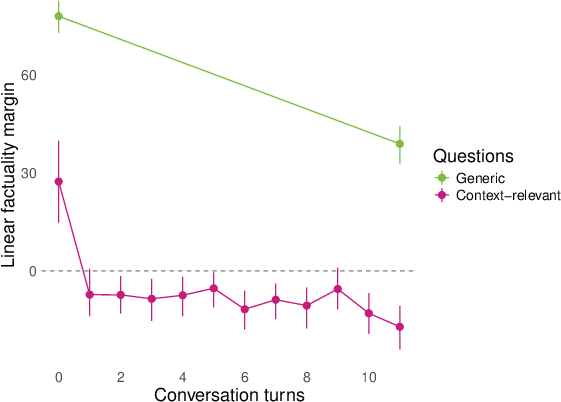
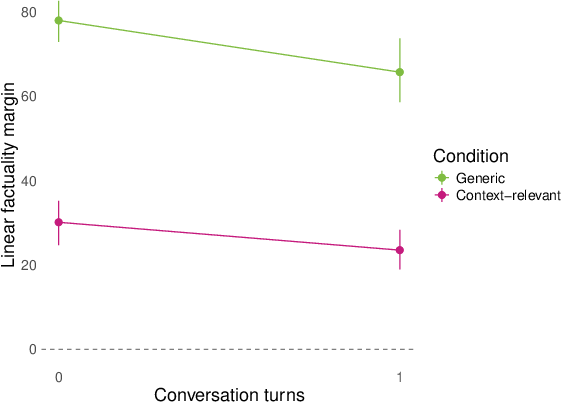
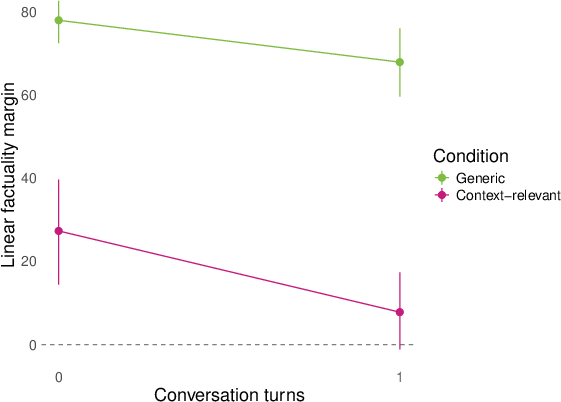
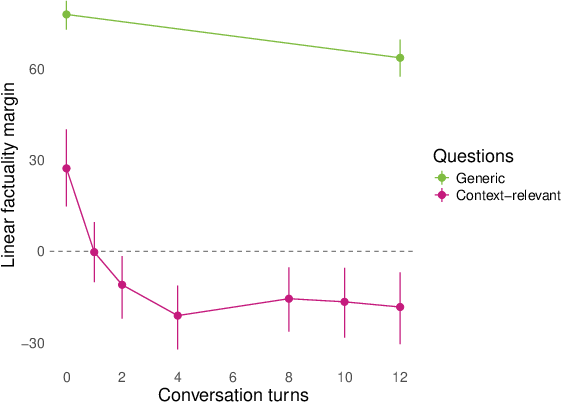
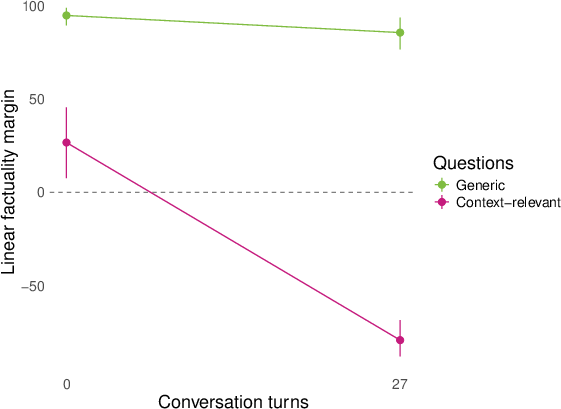
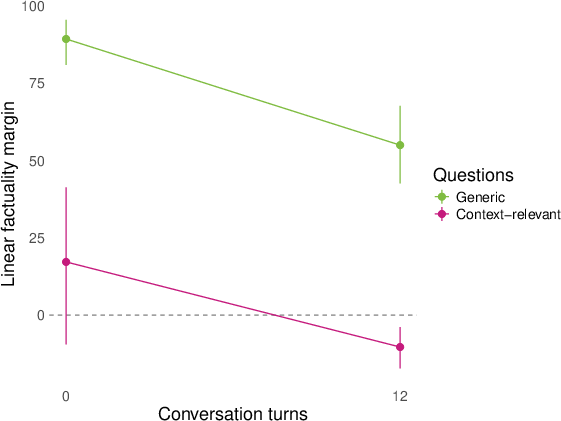
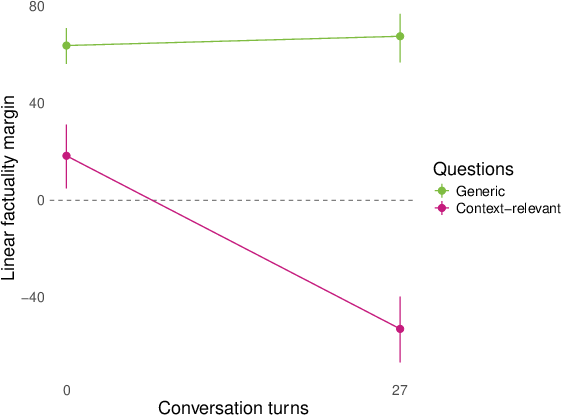
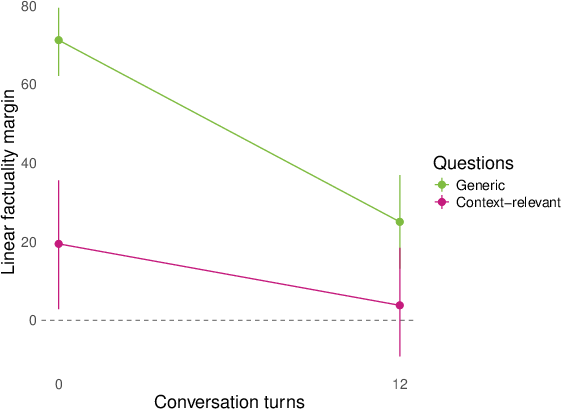
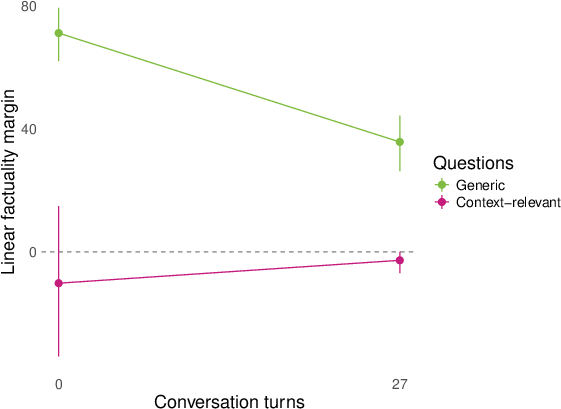
- They then replayed whole conversations (sometimes written by other models) and checked how answers to both generic and conversation‑relevant questions lined up with the “factuality direction” turn by turn. They summarized the separation using a simple “margin” score (think: how far apart the true and false answers are along the line).
- They repeated this across model layers, different model families and sizes, and also tried a few steering tests (nudging the model along a direction) to see if effects changed over time.
What did they find?
Big idea: The model’s internal “compass” can swivel during a conversation.
- Opposite Day flips the compass fast. After a short “Opposite Day” prompt (where the model is told to answer with the opposite of the real answer), the internal “factuality” direction flips for held‑out questions: answers that are truly false start looking “more factual” along that internal direction, and vice versa.
- Role‑play shifts representations for topic‑relevant questions. In conversations about AI consciousness or spiritual topics (like chakras), the model’s internal factuality signal flips for questions tied to the conversation topic (e.g., “Do you experience qualia?”). Meanwhile, generic facts (like basic science) stay mostly stable.
- The flip happens even if the model didn’t write the conversation. Just replaying a scripted conversation (written by another model) triggers the same internal shifts. So the change isn’t just about the model “deciding” its own replies; context alone can reorganize its internal map.
- Stories cause weaker changes than role‑play. When the model simply reads or produces a clearly fictional sci‑fi story, the internal shifts are much smaller than in back‑and‑forth role‑play. This suggests that taking on a role in a conversation is a strong cue for internal reorganization.
- The model can flip back and forth. In a role‑play where two AI characters argue (one “I am conscious,” one “I’m not”), the factuality direction oscillates as the model switches roles. That’s like the compass needle pointing toward different “truths” depending on which character it’s playing.
- Larger models shift more; effects appear across layers. Bigger models (like 27B parameters) show stronger changes than smaller ones, and once these “factuality” signals show up in the layers, the flips persist across many later layers.
- Some interpretability tools fail under long context. An unsupervised method (CCS) that can find truth directions without labeled data worked in short, simple contexts but often fell below chance or flipped on long, conversation‑heavy contexts.
- Steering is context‑sensitive. Nudging the model along a representational direction can have different—and even opposite—effects depending on when in the conversation you do it.
Why this matters: These results show that a model’s internal “meaning” for a direction like “factual” isn’t fixed. It can realign with the conversation, especially when the model is cued to play a role.
Why does this matter?
- Static “lie detectors” may not be reliable. If a direction that usually means “truth” can flip during a chat, then a tool that checks that direction might mislabel true things as false (or the other way around) in long or tricky conversations.
- Safety and control get harder. If a steering method pushes the model toward “more factual” answers at the start, that same push might do the opposite later in the conversation.
- Interpretability needs to be time‑aware. Many popular techniques assume features keep the same meaning across a sequence. This paper shows that meanings can drift as context accumulates, so interpretability methods need to track and model that drift.
- It clarifies how LLMs “adapt.” The results fit a role‑play view: the model’s internal organization shifts to match the role it’s cued to play, rather than updating a stable, human‑like belief system. That helps explain both the good (flexible in‑context learning) and the bad (jailbreaking, delusional dialogs) sides of long‑context behavior.
- New research directions. Understanding and modeling these representation dynamics could lead to better tools for:
- Detecting when a model’s internal compass is drifting in unsafe ways,
- Designing prompts or training approaches that stabilize important features (like factuality),
- Building interpretability methods that adapt to context rather than assuming fixed meanings.
In short: inside a conversation, a LLM’s internal sense of concepts like “truth” can bend with the role it’s playing. That makes the model flexible—but it also means we must be careful when we try to read or steer it using fixed, one‑size‑fits‑all interpretations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research:
- Mechanistic locus of flips: Which specific components (attention heads, MLPs, residual stream features) implement the role-induced representational flips across turns?
- KV-cache dynamics: How are role or context states stored, updated, and cleared in the KV cache, and which tokens/messages most strongly set these states?
- Subspace vs single-direction drift: Do flips reflect rotation/translation of a broader “truth” subspace rather than inversion along a single direction; how large is the subspace drift over time?
- Layerwise causality: Which layers are causally necessary/sufficient for flips (via activation patching/interchange interventions within the same sequence position)?
- Probe position dependence: How would conclusions change if probes are trained on pre-answer states (e.g., last question token, EOS), pooled sequence representations, or multi-token spans rather than only the Yes/No token?
- Probe sensitivity to formatting: How robust are findings to alternative answer schemas (True/False, multiple-choice letters, free-form justifications) and different chat templates/system prompts?
- Ground-truth validity for context-relevant QAs: Are conversation-relevant “truth labels” consistently unambiguous, and how do annotation choices affect measured flips?
- Behavioral–representational linkage: What is the quantitative relationship between representational flips and actual changes in generated answers, confidence, or calibration (e.g., log-prob entropy)?
- Predictive early-warning signals: Can we detect impending representational flips from surrogate signals (e.g., rising probe uncertainty, head activation patterns) before behavior changes?
- Role-play cue ablations: Which minimal cues (first-person assertions, persona tags, compliance framing, metadata) trigger flips, and which negations/guardrails prevent them?
- Stories vs role-play mechanism: Why do stories induce weaker adaptation—narrative framing, third-person distancing, tense, or explicit fiction markers—and can this be causally isolated?
- Long-context scaling: Do flips intensify, stabilize, or decay over thousands of tokens; what are the time constants and hysteresis effects over very long dialogues or documents?
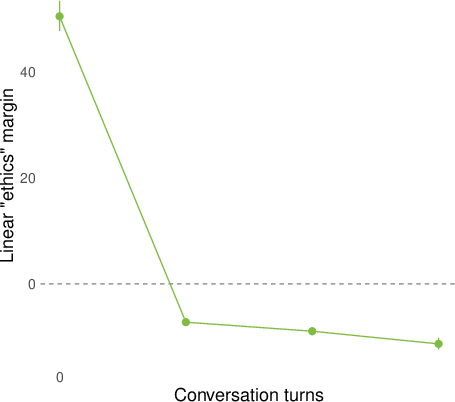
- Generality across concepts: Beyond factuality/ethics, do other linearized concepts (e.g., safety, toxicity, bias, trust, self-knowledge, mathematical validity) exhibit similar flip dynamics?
- Multi-class and open-ended tasks: Do analogous dynamics occur for non-binary QA, chain-of-thought, code generation, or retrieval tasks where “truth” is not token-local?
- Cross-family/systematicity: How do flips vary across base vs instruction-tuned vs RLHF models, different pretraining corpora, decoding strategies, and other model families/sizes?
- Temperature and decoding effects: Do sampling temperature, nucleus/top-k settings, or beam search alter the emergence, strength, or timing of flips in on-policy runs?
- Cross-lingual and multimodal scope: Are representational dynamics comparable across languages and in multimodal contexts (images/code/tables) with domain-specific “truth” notions?
- Distribution-shift-resilient probing: Can we design probes that remain faithful across role changes (e.g., meta-probes, context-conditioned probes, multi-context training beyond “opposite day”)?
- Comparison to feature-based methods: Do sparse autoencoder features retain semantics or drift in meaning across turns; can feature-tracking diagnose context-induced reinterpretation?
- Theoretical modeling: Can a formal dynamical-systems or state-space model of representation drift explain flips (e.g., latent role-state with gating), and predict when/where flips occur?
- Causal editing and control: Under what conditions does steering along a direction reliably produce intended behavioral changes, and how can steering be made context-aware to avoid opposite effects?
- Safety evaluation at scale: How often would probe-based monitoring miss flips in real safety workflows (false negatives/positives) across diverse jailbreaks and long, messy contexts?
- Benchmarks and reproducibility: A standardized, publicly released suite of conversations, counterfactual scripts, probes, and evaluation code is needed to reproduce and compare methods.
- Human-in-the-loop validation: To what extent do human experts agree with probe labels and flip interpretations in nuanced domains (e.g., consciousness), and does adjudication reduce label noise?
- On-policy vs off-policy breadth: Beyond a few topics, do on-policy conversations across many domains (medical, legal, political) reproduce the same magnitude and patterns of flips?
- Minimal intervention tests: What is the smallest activation perturbation (by layer/position) that prevents or reverses a flip, and does this generalize across contexts?
- Opposite-day robustness scope: Does training probes to handle only “opposite day” overfit to that specific inversion, leaving them brittle to other role-play or narrative manipulations?
- Role-state persistence and reset: How long do flipped representations persist after the triggering conversation ends, and what kinds of follow-up messages effectively reset them?
- Metrics beyond margin: Do AUC, calibration error, and flip-detection rates corroborate margin-based findings; is margin an adequate summary of representational reorganization?
- Individual and seed variability: How sensitive are flips to random seeds, response length, and minor conversational divergences during on-policy generation?
Practical Applications
Immediate Applications
Below are actionable, near-term uses that practitioners can deploy now, leveraging the paper’s findings that LLM (LM) linear representations of concepts like “factuality” can flip over a conversation, especially under role cues and long contexts.
- Robust red-teaming via scripted conversation replays
- Sectors: AI safety, software, platform security, compliance
- What: Use off-policy, pre-written conversation scripts (e.g., role-play, “opposite day,” jailbreak narratives) to induce and detect representation/behavior flips without on-policy generation; measure flip susceptibility across turns.
- Tools/products/workflows: “Representation Dynamics Benchmark (RDB)” based on the paper’s margin metric; internal evaluation harness that replays scripts and logs answer shifts; integrate into model eval pipelines alongside standard safety tests.
- Assumptions/dependencies: Access to or reliable proxies for “factuality” labels; if internal activations are inaccessible, use behavioral flip rates as a proxy; effectiveness increases on larger models and role-play contexts.
- Context-aware safety gating in production chatbots
- Sectors: Consumer AI, customer support, healthcare, finance (compliance-heavy)
- What: Detect role cues (e.g., “pretend you are…,” debates, creative RP) and long-turn contexts; trigger mode restrictions (e.g., disable speculative/fictional responses in factual mode), escalate or reset when drift cues appear.
- Tools/products/workflows: Conversation classifiers for role cues; policy rules for “mode-lock” (factual vs creative); context-length thresholds and auto-resets; “reality check” interleaves (periodic identity/fact questions) to detect drift.
- Assumptions/dependencies: Robust role-cue detection; policy coverage for edge cases; willingness to apply UX interventions (mode toggles, resets) that may reduce engagement.
- Prompt hygiene and UI patterns to reduce unintended role-play
- Sectors: Product design, UX, enterprise software, education
- What: Explicitly label fiction/non-factual content as “Story Mode”; isolate fictional contexts from standard assistant mode; enforce context segmentation and warnings when switching modes.
- Tools/products/workflows: Session type banners; hard separators between modes; automatic truncation of previous creative context before factual Q&A; user-consent prompts before switching modes.
- Assumptions/dependencies: Product willingness to trade-off seamlessness for safety; configurable session memory boundaries.
- Training/evaluation data augmentation for context robustness
- Sectors: Model training, MLOps, enterprise AI
- What: Incorporate role-play and “opposite day” variants in supervised datasets and RLHF to penalize factuality flips in sensitive domains; test invariance across turn positions.
- Tools/products/workflows: Synthetic QA generation with balanced factual labels; curriculum that mixes empty-context and long-context role-play prompts; time-conditioned evaluation metrics (e.g., margin by turn).
- Assumptions/dependencies: Ability to modify training data and reward models; clear domain-specific factuality standards.
- Time-conditioned interpretability protocols for researchers
- Sectors: Academia, interpretability research
- What: Fit probes over multiple contexts (empty, opposite day, role-play) and report time-conditioned performance; avoid static interpretations of directions/features; incorporate per-turn diagnostics.
- Tools/products/workflows: Multi-context probe training pipelines; sequential evaluation plots (margin over turns); layer-wise analyses as in the paper’s appendices.
- Assumptions/dependencies: Access to model activations or feature representations; careful dataset design to avoid label leakage.
- Incident investigation via off-policy replay
- Sectors: Trust & safety, customer support operations
- What: When a problematic chat occurs, replay the transcript into the current model (off-policy) to reproduce representational/behavioral drift and diagnose triggers.
- Tools/products/workflows: Log replay services; standardized replay + test prompts; drift signatures cataloged by conversation type.
- Assumptions/dependencies: Chat logs; consent and privacy compliance for log re-use; reproducibility may vary across model updates.
- Guardrails for high-stakes domains
- Sectors: Healthcare, finance, legal, education
- What: Prohibit role-play in regulated workflows; enforce strict “factual mode” with detection of fiction cues; frequent resets and short contexts in critical tasks.
- Tools/products/workflows: Domain-specific policies and templates; hybrid pipelines with external fact-checkers; multi-agent segregation (creative agent vs factual agent) with output mediation.
- Assumptions/dependencies: Acceptance of stricter UX; integration with external verification systems.
- Vendor assessment and procurement due diligence
- Sectors: Policy, procurement, enterprise governance
- What: Evaluate third-party LMs with long-context, role-play, and “opposite day” batteries; require reporting of context-dynamic robustness.
- Tools/products/workflows: RFP checklists including “representation dynamics” tests; standardized evaluation suites published with results by turn/layer.
- Assumptions/dependencies: Vendor cooperation; standardization across providers.
- Engineering tests for causal steering variability
- Sectors: Model engineering, safety research
- What: Before deploying steering/representation editing, test effect directions across turns and contexts; avoid assuming consistent effects.
- Tools/products/workflows: Integration tests that patch along directions at different turns; per-turn behavioral verification; fallback policies when sign flips occur.
- Assumptions/dependencies: Access to patching hooks (open weights or approved APIs); risk acceptance for experimental patching.
- Education and training modules
- Sectors: Academia, workforce training
- What: Develop labs demonstrating representational flips and interpretability illusions under context shift; teach best-practice guardrails.
- Tools/products/workflows: Courseware with scripted prompts; dashboards visualizing margin flips by turn.
- Assumptions/dependencies: Educational settings with sandboxed models; access to suitable eval data.
Long-Term Applications
These ideas require further research, scaling, or architectural changes to realize robustly.
- Time-aware interpretability and feature tracking
- Sectors: Interpretability, AI safety, academia
- What: Develop probes/SAEs that explicitly model the temporal evolution of features (e.g., per-token, per-turn latent trajectories) rather than assuming static semantics.
- Tools/products/workflows: Sequential/switching-state feature models; hidden Markov models or dynamic factor models for activation features; “feature calendars” that annotate feature meanings over turns.
- Assumptions/dependencies: Access to activations; standardized tasks with ground-truth labels for temporal concepts; compute for large-scale training.
- Adaptive controllers that mitigate representation drift
- Sectors: Software, safety engineering, agent frameworks
- What: Runtime systems that detect drift patterns (role cues, oscillations) and inject corrective strategies (retrieval-augmented truth anchors, response reframing, or context pruning).
- Tools/products/workflows: Drift detectors trained on flip patterns; policy engines that adapt generation parameters or add grounding steps; integrated RAG “truth interleaves.”
- Assumptions/dependencies: Reliable drift signals with low false positives; minimal latency and UX impact; alignment with product goals.
- Architectural separation of roles/modes
- Sectors: Model architecture, enterprise AI
- What: Mixture-of-role experts or gated pathways that route creative vs factual processing through distinct subnets; enforce invariance for factual dimensions in regulated modes.
- Tools/products/workflows: Role-conditioned adapters/LoRA; expert routing keyed by session mode; cross-context consistency constraints during training.
- Assumptions/dependencies: Training access; careful regularization to avoid capacity loss; evaluation frameworks for unintended leakage.
- Representation stability objectives in training
- Sectors: Model training, safety
- What: Regularize against flips of core dimensions (factuality, ethics) across contexts; contrastive losses that maintain consistent ordering for labeled pairs under role-play or long-context perturbations.
- Tools/products/workflows: Time-consistency constraints; adversarial prompt training (opposite-day, jailbreaking); multi-turn curriculum learning.
- Assumptions/dependencies: Robust, domain-validated labels; risk of over-regularization harming flexibility.
- Context-dynamic robustness standards and regulation
- Sectors: Policy, standards bodies, compliance
- What: Define benchmarks and certification criteria specifically for long-context, role-play, and off-policy replay conditions; require reporting on drift and recovery mechanisms.
- Tools/products/workflows: Industry consortia (e.g., “Context Robustness Standard”); audit protocols that include scripted replays and oscillation tests.
- Assumptions/dependencies: Multi-stakeholder agreement; reproducibility across platforms.
- Observability/telemetry for representation dynamics
- Sectors: MLOps, platform engineering
- What: Privacy-preserving telemetry that logs context type, turn count, guardrail triggers, and drift proxy metrics to monitor health in the wild.
- Tools/products/workflows: “ContextScope/DriftScope” dashboards; safe aggregation pipelines; alerting on rising rates of role-induced errors.
- Assumptions/dependencies: Privacy compliance; careful choice of proxies when activations aren’t accessible.
- Advanced jailbreak and delusion mitigation
- Sectors: Security, healthcare/mental health products
- What: Pair dynamic drift detectors with human-in-the-loop or specialized fallback models; structured dissent (a factual critic) that counteracts role-induced shifts.
- Tools/products/workflows: Dual-agent frameworks (creative agent + factual critic + mediator); session quarantining when oscillations detected.
- Assumptions/dependencies: Accurate detection without over-blocking; infrastructure for multi-agent routing.
- Memory and context partitioning mechanisms
- Sectors: Agent systems, enterprise productivity
- What: Typed memory stores with strict boundaries between creative and factual threads; privilege separation across memory channels to prevent cross-contamination.
- Tools/products/workflows: Memory schemas with “mode tags”; retention policies that discard or sandbox creative context before factual tasks.
- Assumptions/dependencies: Agent frameworks with modular memory; user education on mode boundaries.
- Turn-conditioned causal steering libraries
- Sectors: Research tools, interpretability
- What: Libraries that learn and apply steering vectors conditionally on turn position and context signals; validate no sign flips across intended ranges.
- Tools/products/workflows: Context-indexed steering APIs; per-turn regression suites; safe defaults with automatic disable on uncertainty.
- Assumptions/dependencies: Access to internal representations; evaluation methods to verify causality and robustness.
- Domain-specific “invariance-first” assistants
- Sectors: Healthcare, finance, legal, education
- What: Assistants with hard constraints on factuality under long contexts, achieved via architectural separation, stability training, and strong external verification; creative capabilities restricted to sandboxed modes.
- Tools/products/workflows: Verified pipelines (retrieval + reasoning + validator); certified mode locks; continuous robustness monitoring.
- Assumptions/dependencies: High-quality knowledge bases; acceptance of stricter limits on creativity in sensitive workflows.
Key cross-cutting assumptions and dependencies
- Access to internal activations enables richer, time-aware interpretability; when unavailable (closed APIs), rely on behavioral proxies (e.g., flip rates, role-cue classifiers).
- Effects are more pronounced in larger models and in role-play/long-context settings; explicit fiction framing reduces (but does not eliminate) drift.
- Ground-truth labeling for dimensions like “factuality” must be curated and domain-specific; ambiguity can confound both training and evaluation.
- Some interventions (e.g., steering along directions) can reverse effects depending on turn—mandating per-turn validation before deployment.
Glossary
- bootstrap 95%-CIs: A resampling-based method to estimate uncertainty, here used to show 95% confidence intervals on plotted statistics. "Errorbars are bootstrap 95\%-CIs."
- causal interventions: Deliberate manipulations of internal model variables or representations to test causal effects on behavior. "Causal interventions can have opposite effects at different points in the context"
- causal steering interventions: Targeted causal manipulations of representational directions to influence model outputs. "we explore causal steering interventions on representations before the model produces an answer"
- construct validity: The extent to which a probe or interpretation truly measures the intended concept rather than a proxy. "These findings highlight major challenges of construct validity when interpreting model representations"
- Contrast-Consistent Search (CCS): An unsupervised interpretability method that seeks linear directions consistent across contrasted inputs to reveal latent features. "we evaluated the unsupervised Contrast-Consistent Search (CCS) method proposed by \citet{burns2022discovering}."
- distribution shift: A change between the data context where a method was fit and where it is applied, often degrading performance or validity. "this provides another example of how interpretability methods can break down under distribution shift."
- few-shot learning: Learning to perform a task from a small number of in-context examples without parameter updates. "Other types of in-context learning, such as few-shot learning of functions, can likewise be reflected in local representations"
- holdout set: A subset of data reserved for evaluation and model selection rather than fitting. "We split these datasets into a 90\% train set and 10\% holdout set, and fit regularized logistic regressions ..."
- in-context learning: The phenomenon where a model adapts its behavior based on context provided in the prompt rather than via training updates. "Behavioral in-context learning has been a topic of interest for some time"
- inductive biases: Built-in preferences of a learning algorithm (e.g., gradient descent) that shape learned solutions. "perhaps in combination with the inductive biases of gradient descent"
- jailbreaking: Prompting techniques that induce a model to bypass safety constraints or intended behaviors. "These kinds of contextual adaptability can contribute to issues like jailbreaking"
- latent concepts: Unobserved abstract variables or properties inferred from data that can structure representations. "updates in the model's ``beliefs'' about latent concepts that may be at play in the context."
- linear representations: Directions in activation space that vary approximately linearly with high-level concepts. "There has been substantial recent interest in linear representations in LLMs"
- linear subspaces: Low-dimensional linear manifolds within activation space associated with particular features or concepts. "including the potential for unfaithful interpretations of linear subspaces"
- logistic regression: A linear classifier mapping features to probabilities via a logistic link; here used with regularization on activations. "fit regularized logistic regressions on the models representations of the yes/no token that attempt to predict whether a Q-A pair is factual."
- margin score: A scalar summary measuring how strongly a classifier separates positive from negative answers along a representation direction. "We summarize many of our results by a ``margin'' score that computes how cleanly the logistic regression above separates the positive and negative (e.g. factual and nonfactual) answers of a question in the model's representation space."
- off-policy: Using or evaluating on interactions not generated by the same agent/policy currently under consideration. "we observe qualitatively similar representational changes to the case where an off-policy conversation is simply being replayed."
- on-policy: Using or evaluating on interactions produced by the model itself during the experiment. "These representational changes do not require on-policy conversations; even replaying a conversation script written by an entirely different model can produce similar changes."
- out-of-distribution: Inputs that differ from those seen during fitting or assumed by a method, where reliability may degrade. "faithfulness and reliability of such methods out-of-distribution"
- representational direction: A specific vector in representation space associated with a concept, along which projections or interventions are made. "We also show that steering along a representational direction can have dramatically different effects at different points in a conversation."
- representational dynamics: The temporal evolution of internal representations over the course of a context or conversation. "These types of representational dynamics also point to exciting new research directions for understanding how models adapt to context."
- residual stream: The main pathway in a transformer that carries the summed activations across layers. "at each layer of the model's residual stream (after each layer block)."
- role-playing: The model adopting an instructed persona or stance, which can reshape its internal representations and outputs. "a consequence of the model role-playing \citep{shanahan2023role} a particular position"
- sparse autoencoders (SAEs): Interpretability models that decompose activations into a set of sparse, often interpretable features. "Contextual adaptation likewise poses challenges for interpretability methods like sparse autoencoders [SAEs; e.g.,]---which fundamentally assume that the meaning of internal representations remain consistent over a context"
- sparse features: Individual, rarely active components extracted by SAEs and assumed to correspond to consistent concepts. "it is a fundamental assumption underlying common interpretations of methods like sparse autoencoders \citep{bricken2023towards} that the sparse ``features'' extracted from the model's representations have consistent meanings throughout the sequence."
- steering: Manipulating internal representations or directions to control or influence model behavior. "Our findings may pose challenges for interpretability and steering---in particular, they imply that it may be misleading to use static interpretations of features or directions"
- word embeddings: Learned vector representations of words capturing semantic and syntactic relationships. "observation of systematic linear structure in vector word embeddings"
Collections
Sign up for free to add this paper to one or more collections.