The Bayesian Geometry of Transformer Attention
Abstract: Transformers often appear to perform Bayesian reasoning in context, but verifying this rigorously has been impossible: natural data lack analytic posteriors, and large models conflate reasoning with memorization. We address this by constructing \emph{Bayesian wind tunnels} -- controlled environments where the true posterior is known in closed form and memorization is provably impossible. In these settings, small transformers reproduce Bayesian posteriors with $10{-3}$-$10{-4}$ bit accuracy, while capacity-matched MLPs fail by orders of magnitude, establishing a clear architectural separation. Across two tasks -- bijection elimination and Hidden Markov Model (HMM) state tracking -- we find that transformers implement Bayesian inference through a consistent geometric mechanism: residual streams serve as the belief substrate, feed-forward networks perform the posterior update, and attention provides content-addressable routing. Geometric diagnostics reveal orthogonal key bases, progressive query-key alignment, and a low-dimensional value manifold parameterized by posterior entropy. During training this manifold unfurls while attention patterns remain stable, a \emph{frame-precision dissociation} predicted by recent gradient analyses. Taken together, these results demonstrate that hierarchical attention realizes Bayesian inference by geometric design, explaining both the necessity of attention and the failure of flat architectures. Bayesian wind tunnels provide a foundation for mechanistically connecting small, verifiable systems to reasoning phenomena observed in LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
The Bayesian Geometry of Transformer Attention — Explained Simply
What is this paper about?
This paper asks a big question: Are transformers (the kind of AI used in ChatGPT) actually doing real reasoning, or are they just memorizing patterns? The authors create controlled test environments—like wind tunnels for airplanes—to see if transformers can truly follow the rules of probability (called Bayesian inference) when making predictions.
What questions did the researchers try to answer?
They focused on three main questions:
- Can small transformers actually perform Bayesian reasoning step by step, not just look like they do?
- If yes, how do they do it inside—what’s the mechanism?
- Is attention (the key part of transformers) truly necessary, or could a simpler neural network work just as well?
How did they test this? (Methods in everyday language)
Think of a wind tunnel: engineers test planes in a controlled space to remove outside noise. The authors did the same for reasoning. They built two “Bayesian wind tunnels”—simple, clean tasks where:
- The exact correct answer (the Bayesian posterior) is known at every step.
- The space of possibilities is huge, so the model cannot memorize the answers.
- The model must use real reasoning to perform well.
They used two tasks:
- Task 1: Bijection learning Imagine you have 20 keys and 20 locks, and each key opens exactly one lock. You reveal some key-lock pairs one by one. The model has to guess which lock a new key opens. Each time you learn a pair, the number of possible answers goes down by one. The “Bayesian” answer here is very simple: if 5 locks are already taken, then each of the remaining 15 locks is equally likely.
- Task 2: HMM (Hidden Markov Model) state tracking Picture a robot moving between rooms (hidden states). You don’t see the room directly; instead, you see noisy clues (like sounds or smells). The model must keep track, over time, of how likely the robot is in each room. There’s a well-known, exact way to do this called the forward algorithm. The authors check whether the transformer learns to reproduce those exact probabilities.
How they judged the models:
- They measured uncertainty (called “entropy”) in bits—lower bits mean more confidence.
- If the model is doing correct Bayesian reasoning, its uncertainty at each step should match the true Bayesian uncertainty exactly.
- They compared small transformers to equally large MLPs (a simpler kind of neural network without attention).
Key terms, simply:
- Bayesian inference: Updating your belief as you see new evidence—like a detective ruling out suspects as clues arrive.
- Entropy: How unsure you are. High entropy = many possibilities; low entropy = you’re close to the answer.
- Transformer parts:
- Attention: Like a spotlight that finds the most relevant information.
- Residual stream: A shared “whiteboard” where the model keeps its current beliefs.
- FFN (feed-forward network): A calculator that updates the belief based on the new evidence.
- Geometry (in the model): The model represents ideas as directions and shapes in a high-dimensional space. Orthogonal directions are like arrows pointing at right angles—clearly separated.
What did they find?
- Transformers match Bayes’ rule extremely closely
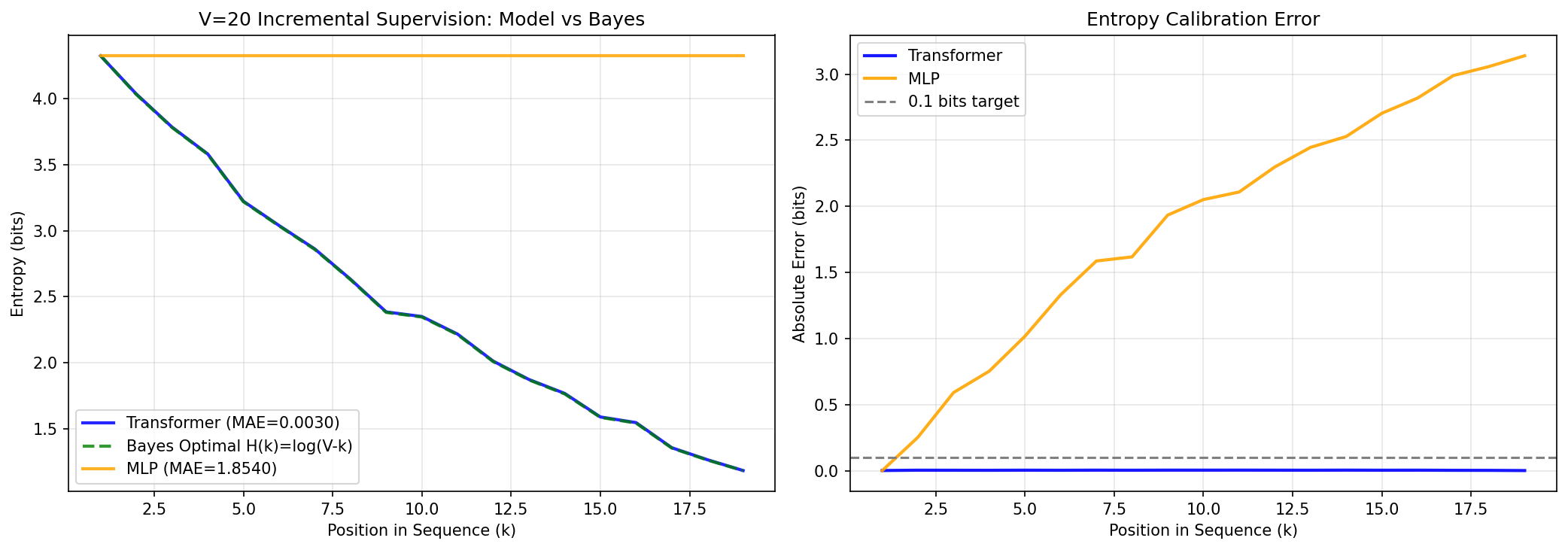
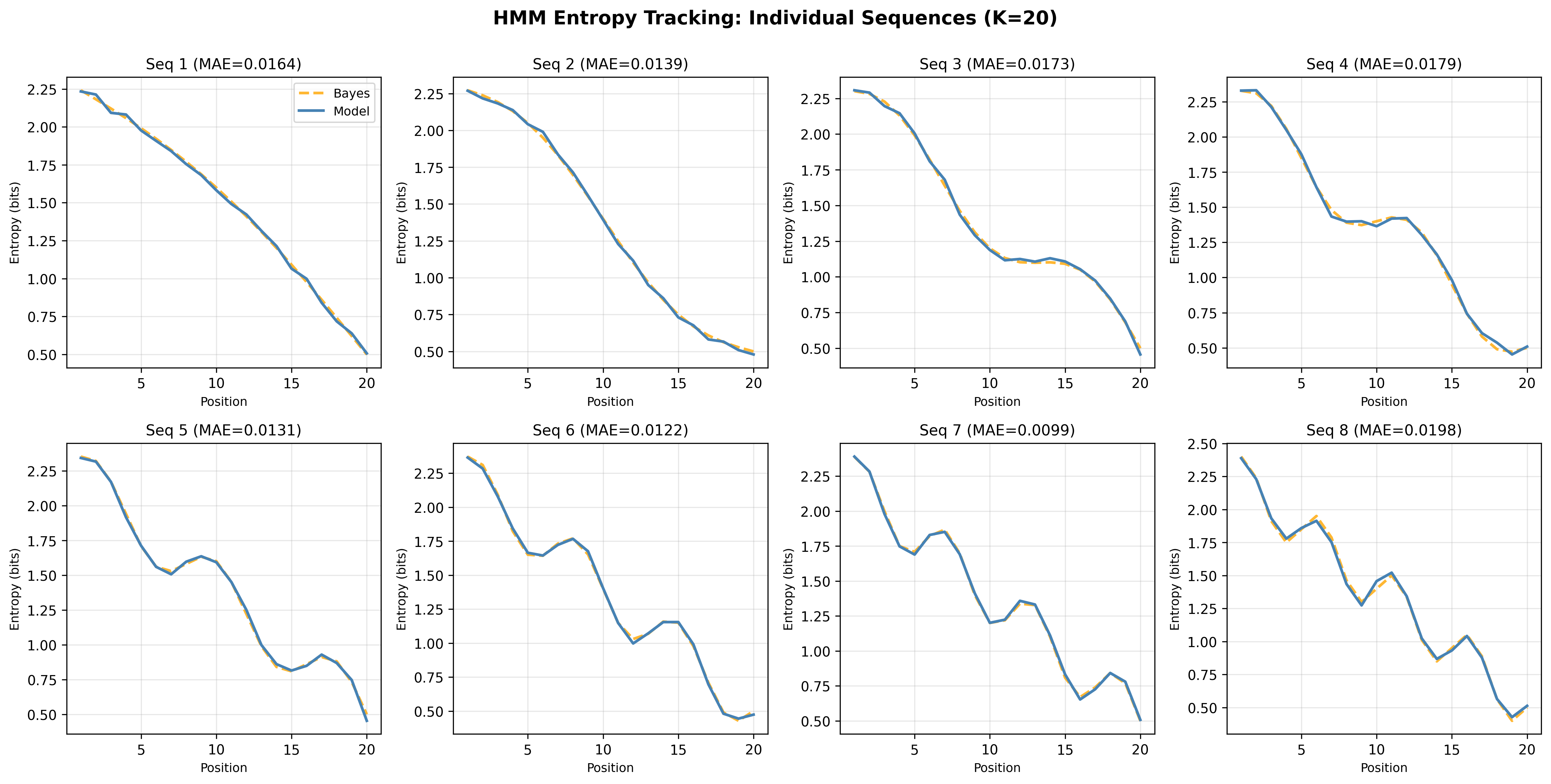
- In the bijection task, the transformer’s uncertainty at each step almost exactly matched the true Bayesian uncertainty (errors around 0.003 bits—tiny).
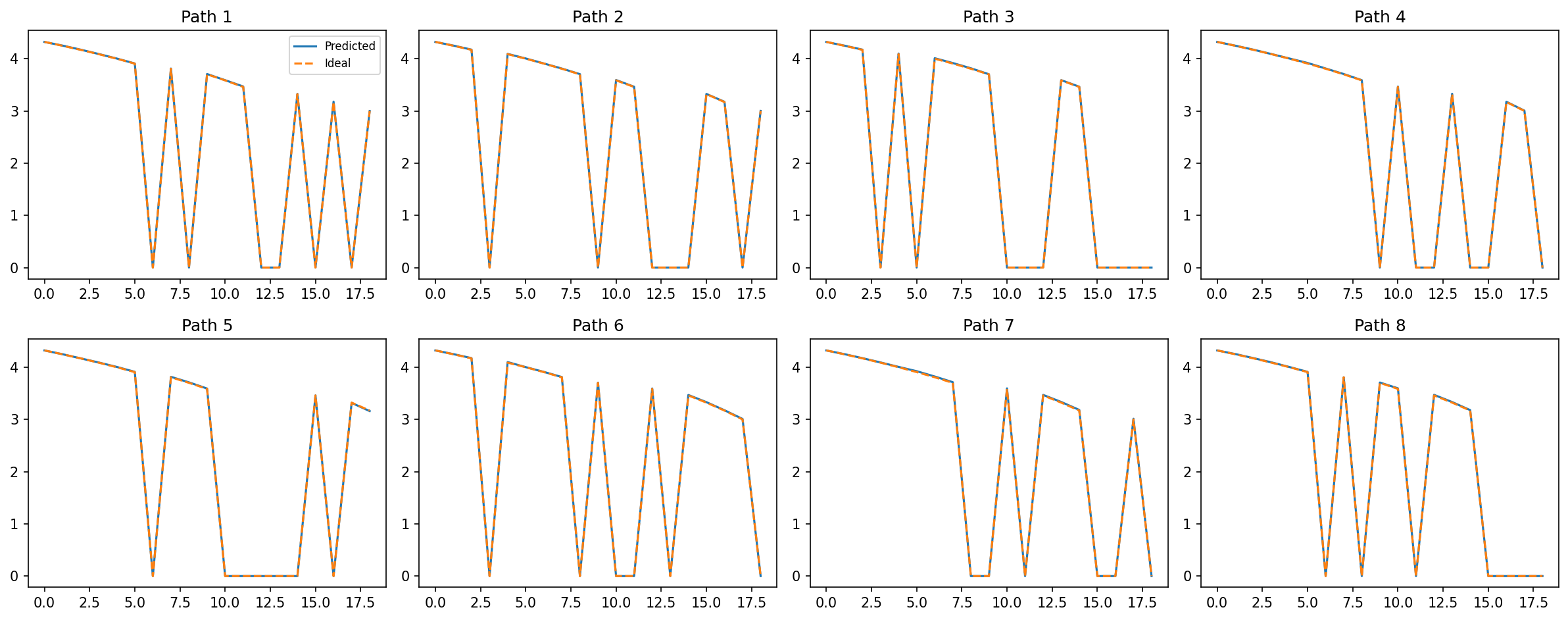
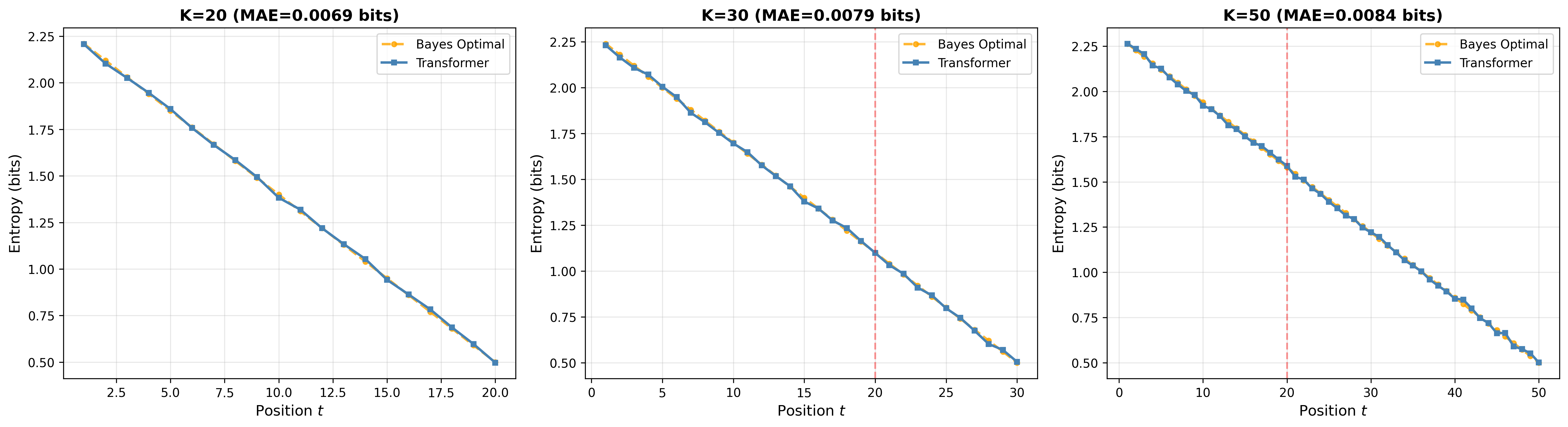
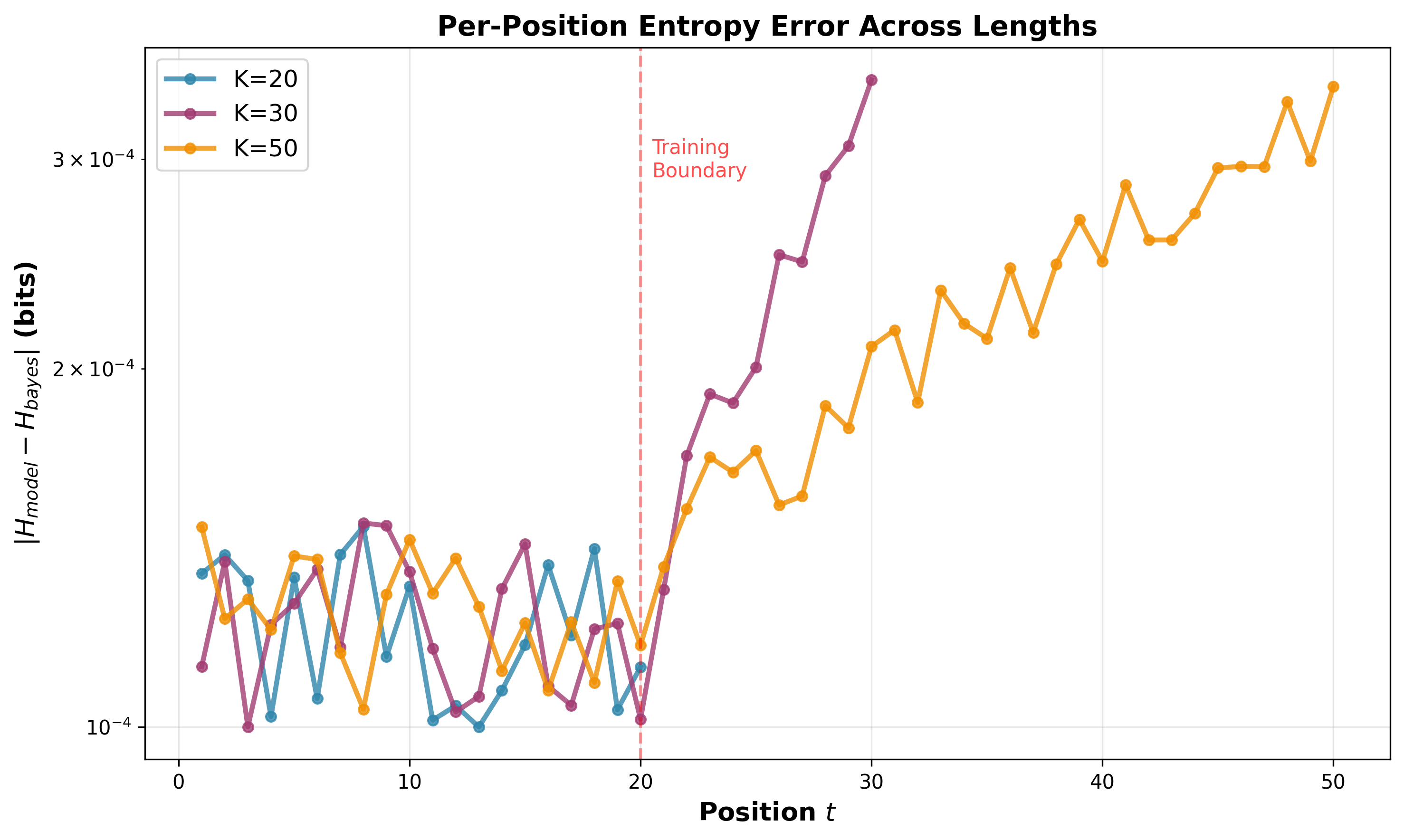
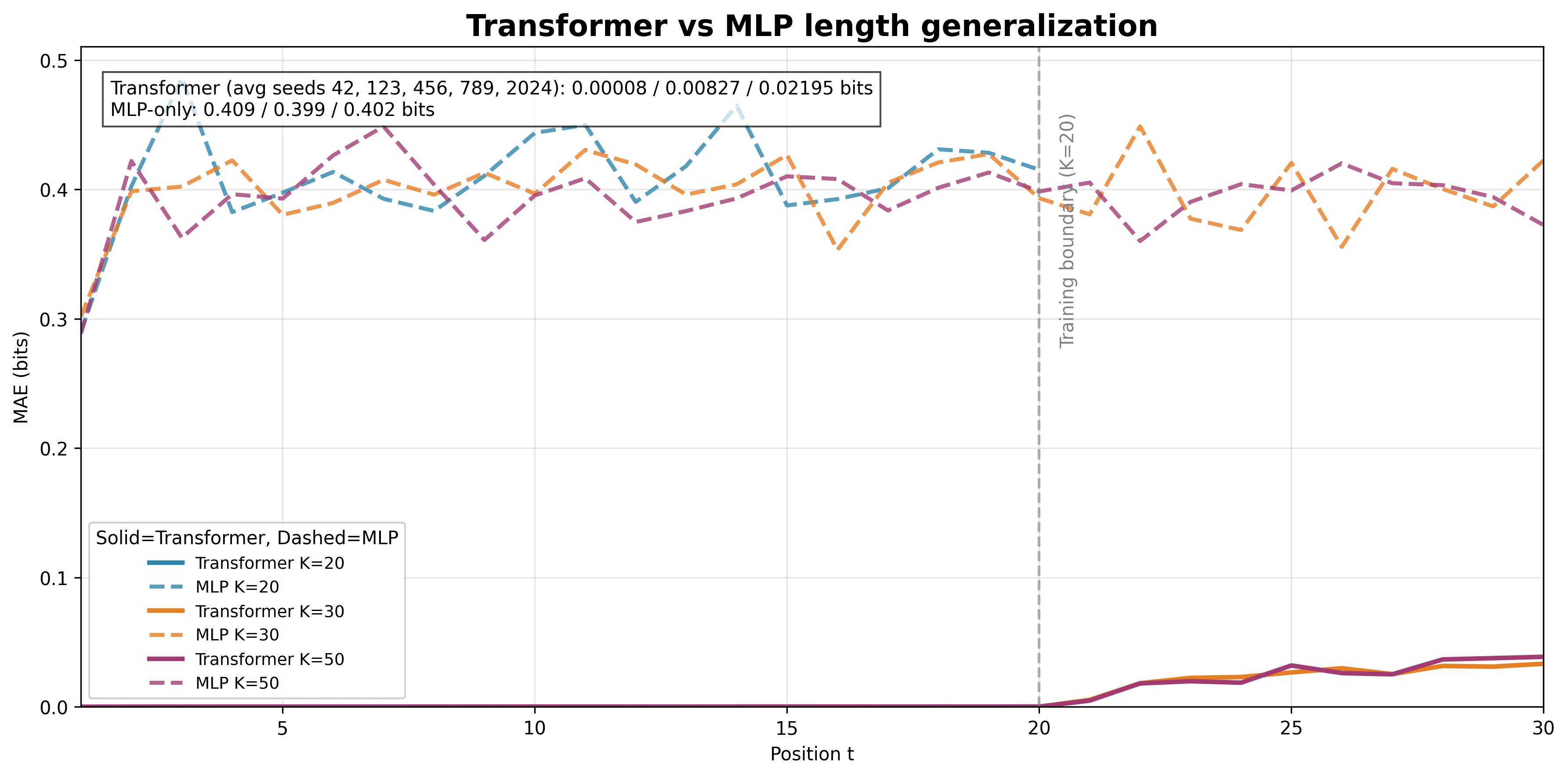
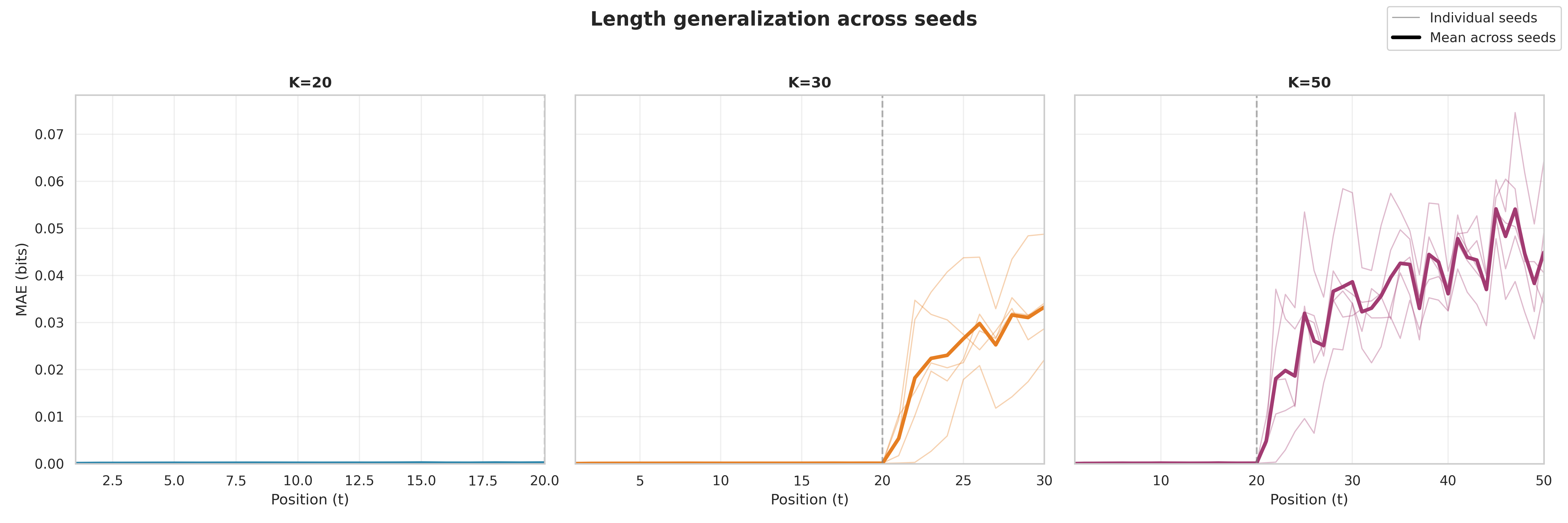
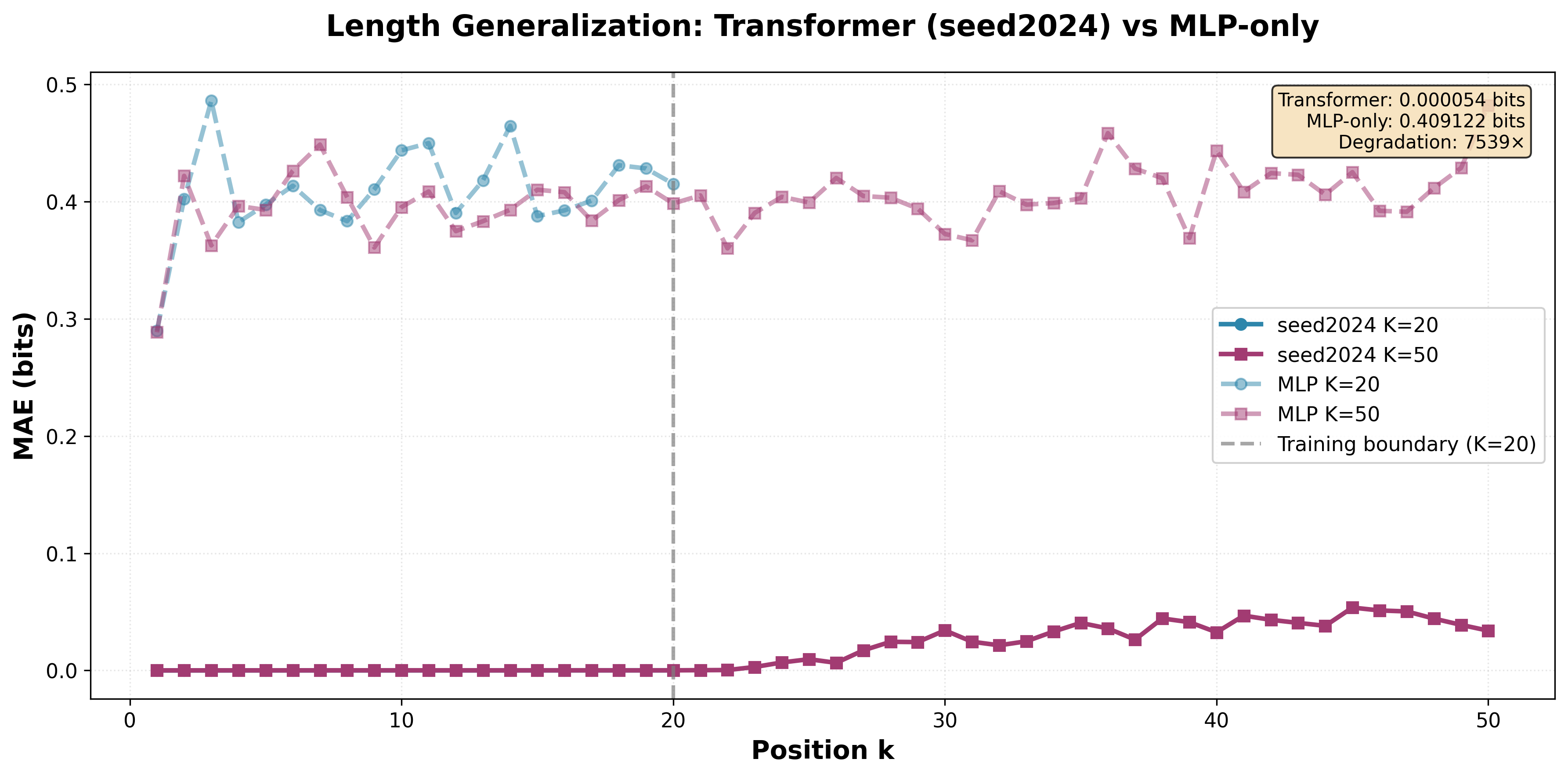
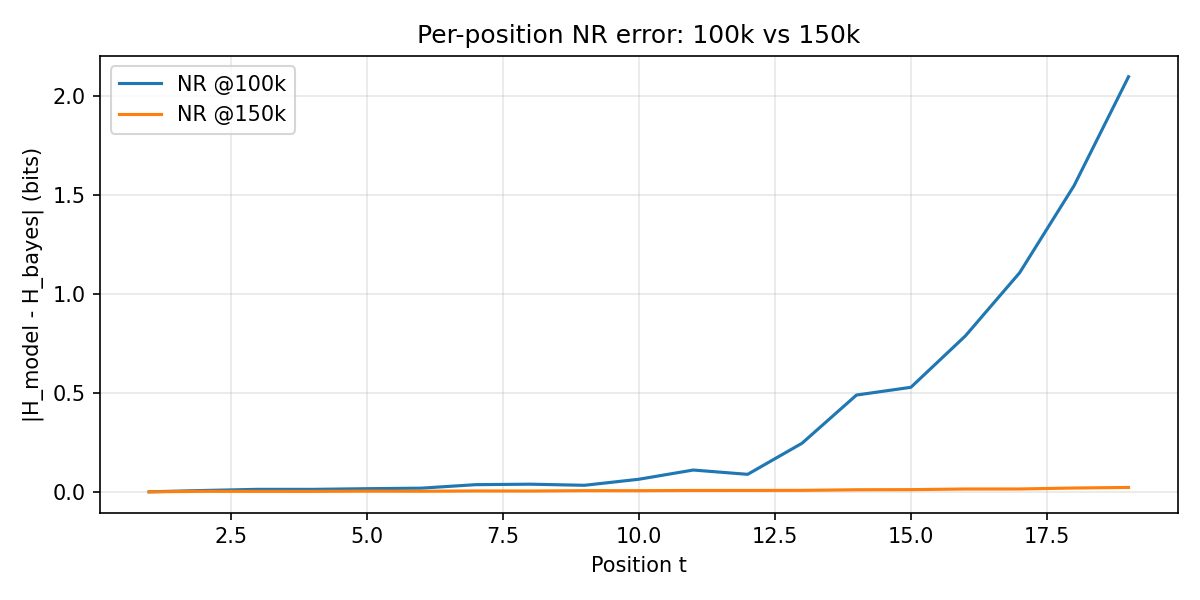
- In the HMM task, the transformer learned the correct step-by-step algorithm and stayed accurate even when tested on longer sequences than it saw during training. It didn’t just memorize a short trick—it learned a general method.
- MLPs (no attention) failed badly
- MLPs with the same number of parameters could not do the reasoning. Their uncertainty stayed far off from the correct values. This shows attention isn’t just helpful—it’s necessary for this kind of reasoning.
- How transformers do it on the inside (the “geometric mechanism”) The team found a consistent three-part process:
- The residual stream acts like the model’s belief notebook. It stores what the model currently believes about the answer.
- The FFN layers do the math of updating beliefs (the Bayesian update)—like using a calculator each step.
- Attention acts as content-based routing—it picks out the relevant information to update the belief.
They also discovered geometric patterns:
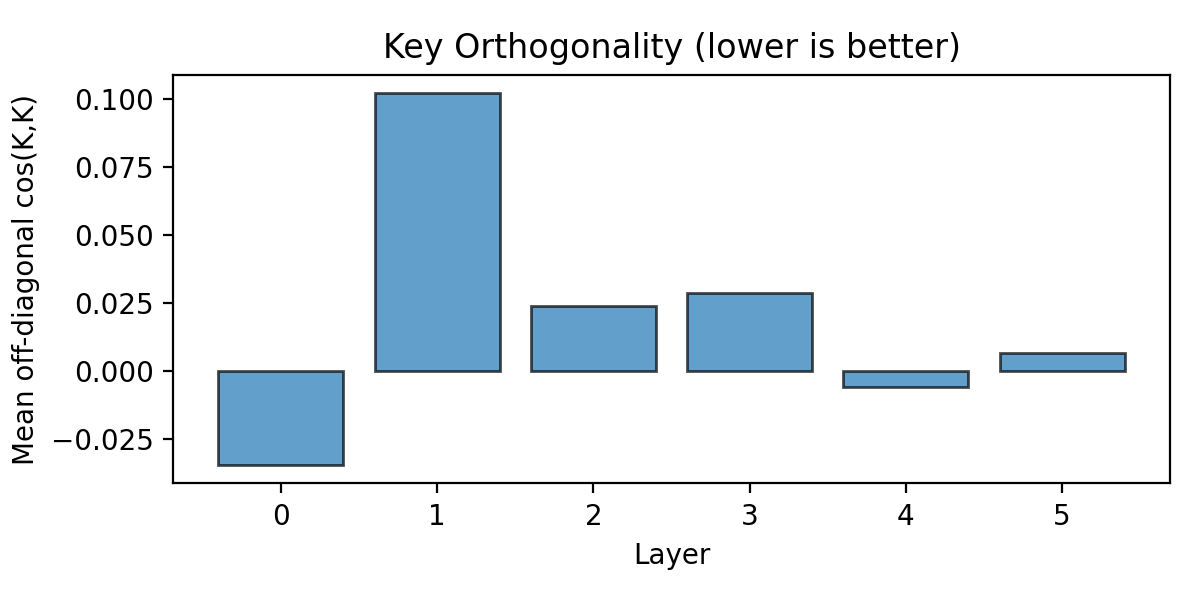
- Keys are orthogonal: the model builds a clean “basis” of separate directions for different possibilities (like giving each hypothesis its own arrow in space).
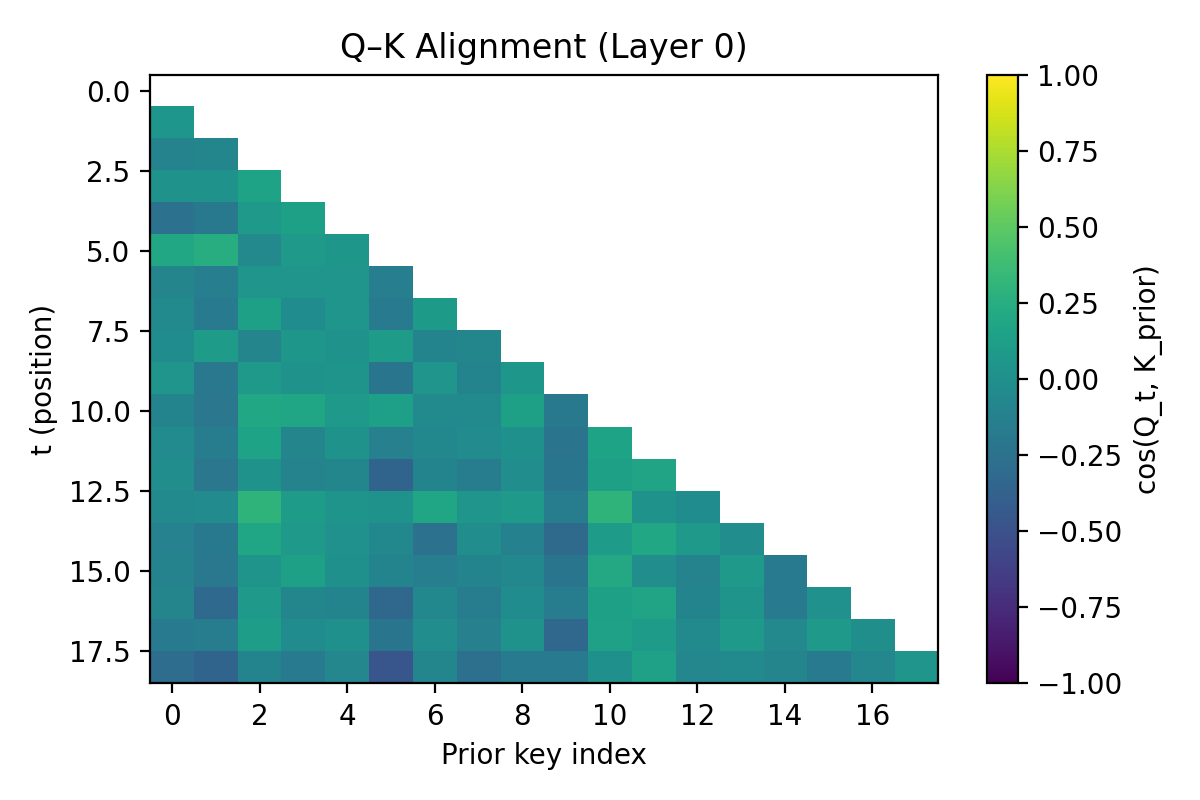
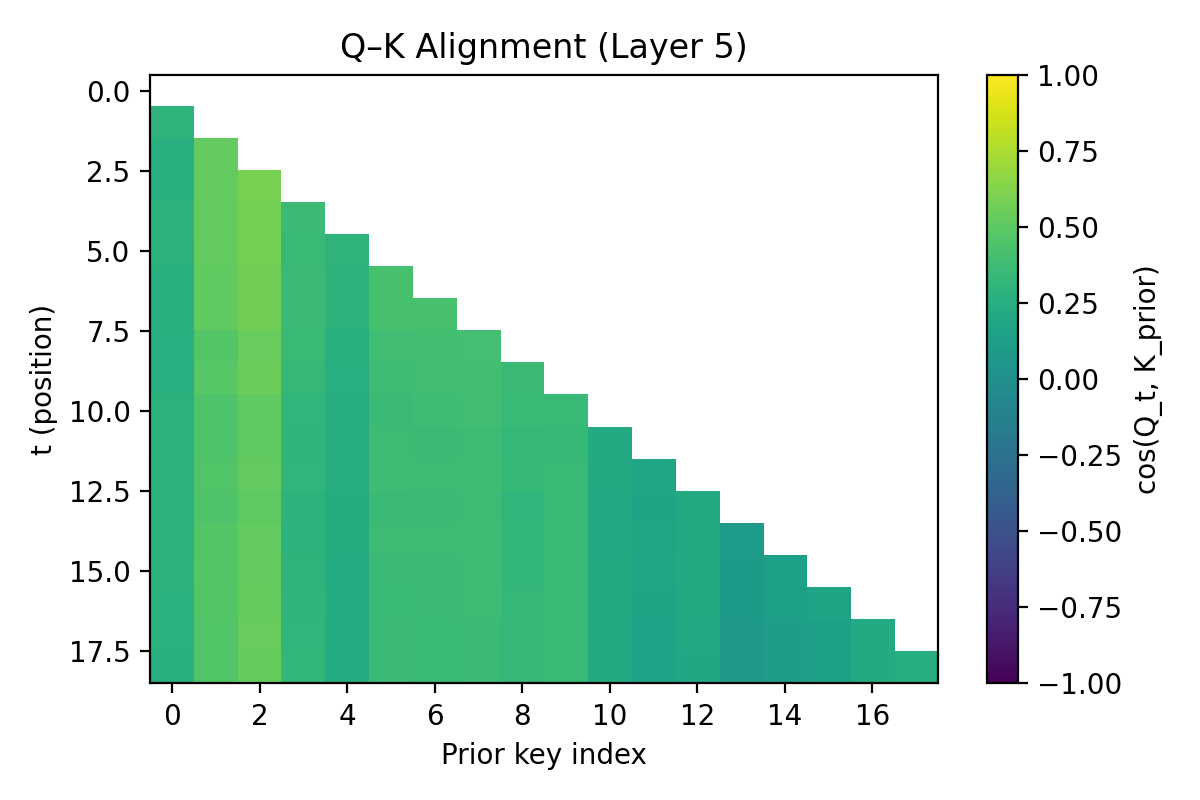
- Queries align with the right keys over layers: as the model goes deeper, its attention sharpens and focuses only on the remaining feasible options—just like ruling out suspects.
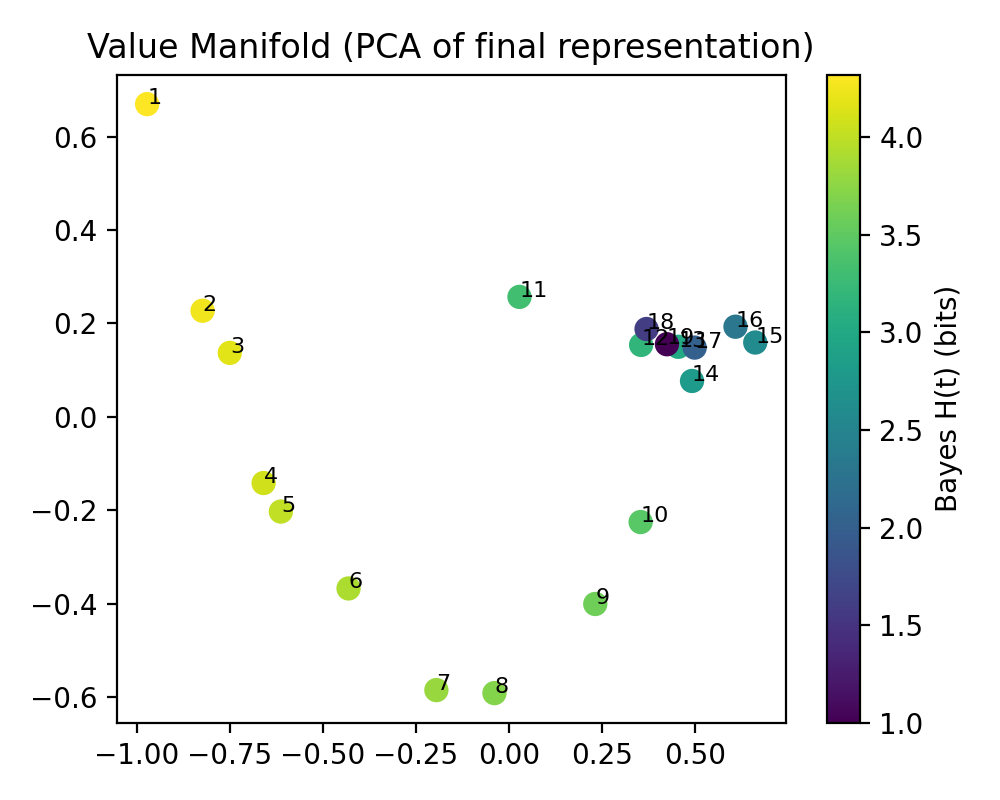
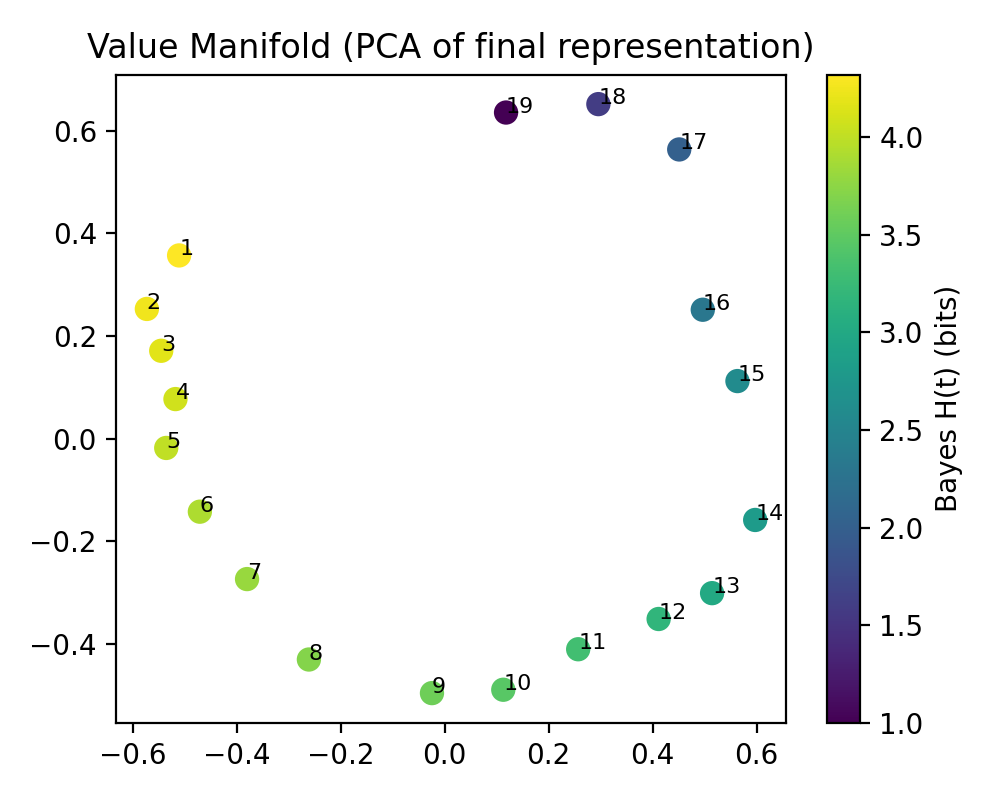
- Value outputs lie on a low-dimensional “manifold” shaped by certainty: as the model gets more confident, its internal representation slides smoothly along a curve that tracks “how sure it is.” During training this curve “unfurls,” letting the model represent confidence more precisely, while the attention patterns stay largely stable.
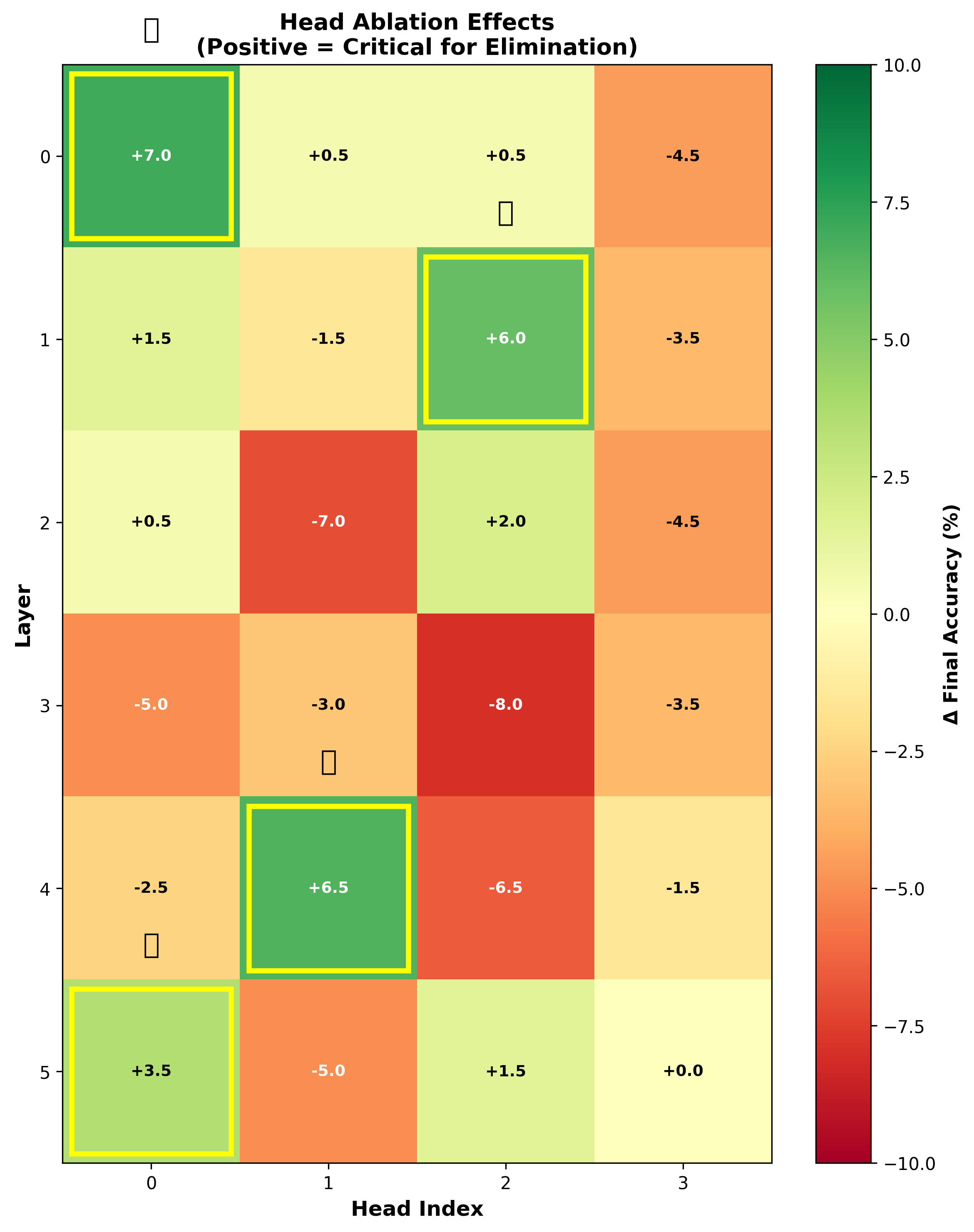
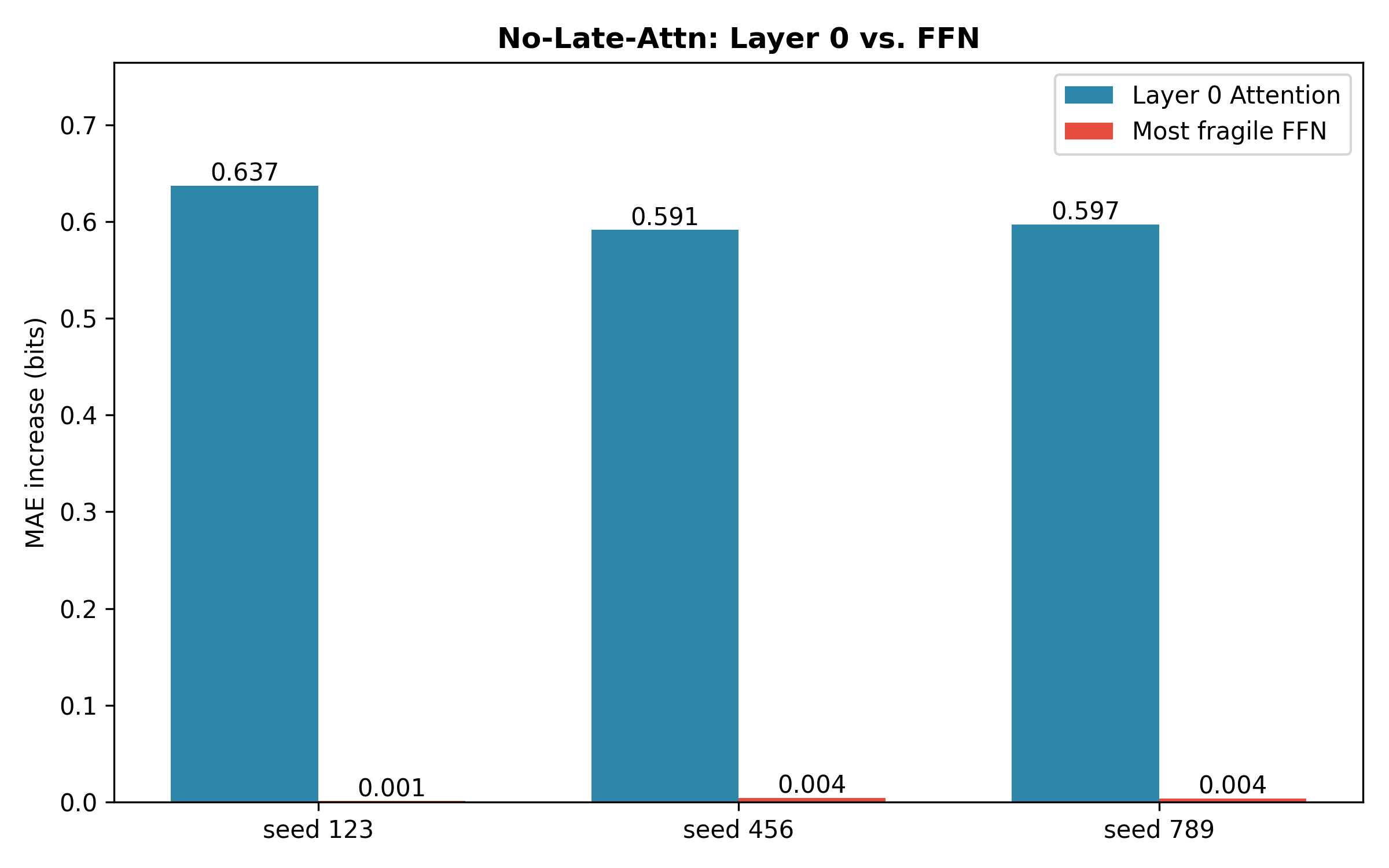
- Attention in late layers is crucial for long tasks When the researchers disabled attention in the top layers, the model could still handle short sequences but broke down on longer ones. That means attention isn’t only for the start—it helps keep reasoning stable over time.
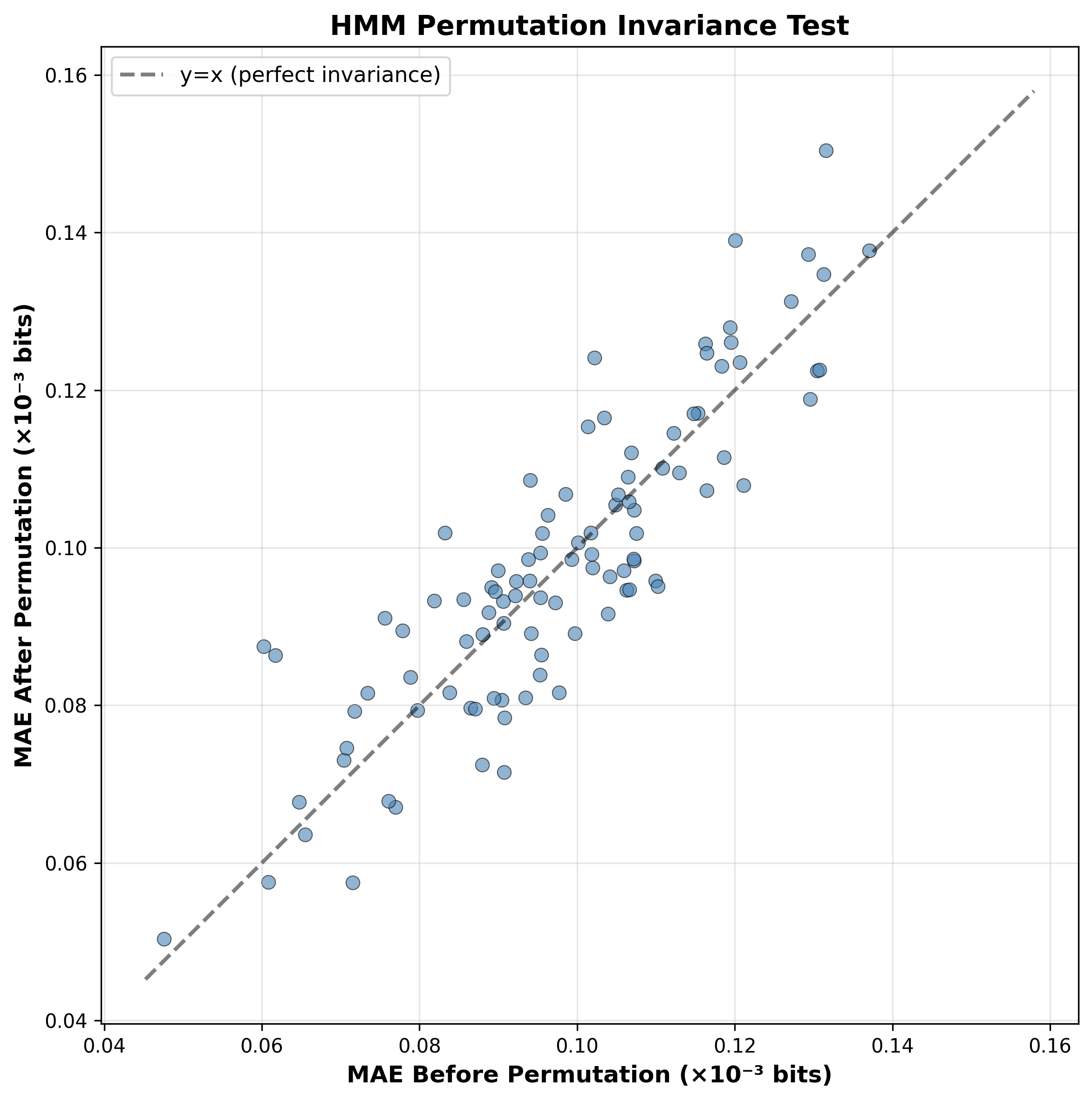
- The model ignores meaningless label changes In the HMM, if you relabel the hidden states (like renaming rooms), the model’s performance doesn’t change. That shows it learned the underlying reasoning, not the labels.
Why is this important?
- It shows transformers can truly perform Bayesian reasoning—not just imitate it—when tested in a clean, verifiable way.
- It explains why attention matters: it supplies the “routing” and structure that simpler networks lack.
- It gives a clear, testable picture of how reasoning happens inside: a stable frame (attention) and a refining calculator (FFN) working on a shared belief state (residual stream).
- It introduces “Bayesian wind tunnels” as a powerful tool: small, controlled tasks where we know the correct answers exactly and can check if models are truly reasoning rather than memorizing. This helps connect what we see in giant LLMs to solid, verifiable mechanisms in smaller ones.
Bottom line
The paper provides strong evidence that transformers can implement real Bayesian inference by design. Attention organizes information, FFNs do the belief updates, and the residual stream stores the evolving belief. This architecture beats similarly sized models without attention, especially on tasks that require careful, step-by-step reasoning. These wind-tunnel tests give researchers a reliable way to study true reasoning in AI and point the way toward building and understanding better, more trustworthy models.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of unresolved issues the paper leaves open. Each item is phrased to be directly actionable for future work.
- Validate full posterior fidelity beyond entropy: compute per-position KL divergence and per-state correlation between the model’s predictive distribution and the analytic posterior, not only mean absolute entropy error.
- Bijection task distribution checks: explicitly verify that the model’s predicted probabilities over unseen outputs are uniform (as Bayes requires), not only that their entropy matches the uniform posterior.
- Scale to larger hypothesis spaces and longer horizons: test V≥100 for bijection and S≥20, V≥20 for HMMs, with rollouts K≥200 to probe stability, error growth, and whether late-layer attention remains necessary at larger scales.
- Joint parameter learning in HMMs: remove the header encoding T and E, and assess whether the transformer can jointly infer HMM parameters online while filtering (i.e., learn p(T,E|o1:t) and perform posterior predictive updates).
- Robustness to different priors and dynamics: evaluate HMMs under Dirichlet concentration α≠1 (sparse α<1 and concentrated α>1), sticky/self-transition-biased chains, near-deterministic emissions, non-stationary transitions, and structured (e.g., low-rank) T/E matrices.
- Continuous-state inference: extend wind tunnels to Gaussian HMMs/Kalman filtering, heavy-tailed noise models, and continuous emission spaces to test whether the same geometric mechanism scales to continuous Bayesian updates.
- Hierarchical and multimodal latent models: test hierarchical Bayes (e.g., hyperpriors over T/E) and mixture-of-HMMs settings to examine whether transformers can represent and update multi-level/multi-modal posteriors.
- Formalize the “memorization is impossible” claim: provide probabilistic bounds showing negligible collision probability of training instances, and perform nearest-neighbor/duplicate detection to empirically exclude hidden memorization.
- Theoretical expressivity guarantees: establish conditions under which a transformer of given depth/width/heads can implement exact HMM forward recursion (and bijection elimination), and derive sample-complexity bounds for learning these computations.
- Alternative architectures for content-addressable inference: compare to recurrent models (LSTM/GRU), gated MLPs, RWKV/Mamba, and key–value memory networks to test whether attention is necessary or whether other mechanisms can realize Bayesian routing and updates.
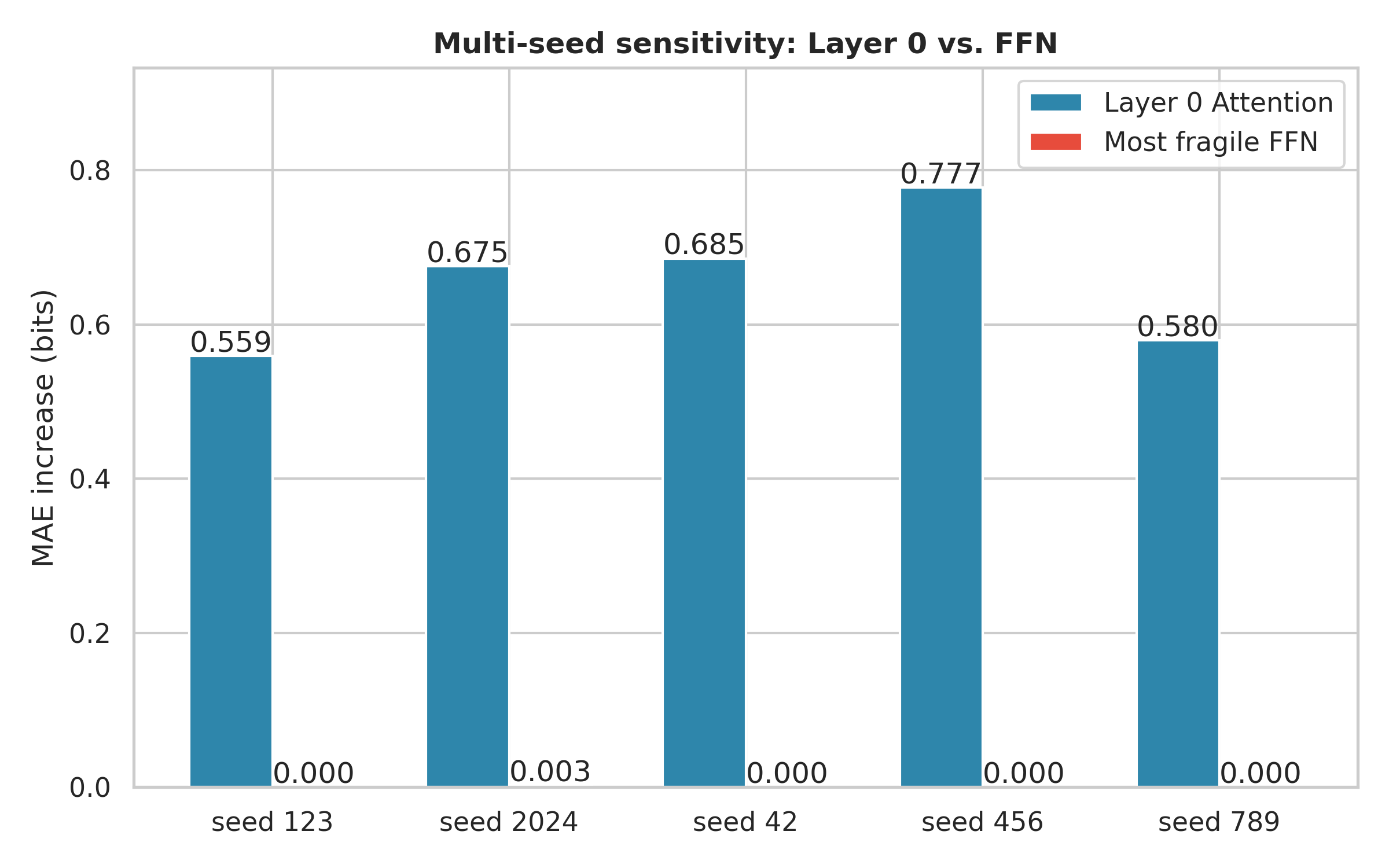
- Head and layer role reproducibility: repeat head-wise and layer-wise ablations across multiple seeds and tasks to quantify variability and confirm the uniqueness/necessity of the “hypothesis-frame head.”
- Decode full belief state from the residual stream: train probes to recover the entire posterior vector (αt over states in HMM; feasible set indicators in bijection), not just entropy, to concretely validate “residual stream as belief substrate.”
- Positional encoding dependence: test relative/rotary positional embeddings (vs. learned absolute) and no positional embeddings, measuring whether the geometric signatures (key orthogonality, QK sharpening, value manifold) and Bayesian calibration persist.
- Input formatting sensitivity: vary separators, token ordering, header compression/noise, and randomized formatting to establish the robustness of the learned mechanism to syntactic changes in sequence representation.
- Free-running stability without teacher forcing: evaluate multi-step filtering when the model consumes its own prior outputs (or noisy observations) to test algorithmic robustness under compounding errors.
- Training data efficiency: map sample-size and training-step scaling laws required to unfurl the value manifold and reach sub-bit calibration; quantify minimal data needed for near-Bayes behavior.
- Manifold dimensionality and structure: estimate intrinsic dimensionality of value/residual manifolds across tasks and training stages; test whether 1D entropy parameterization generalizes to HMMs or if higher-dimensional belief geometry is required.
- Error growth characterization: analytically and empirically decompose long-horizon drift sources (routing vs. numeric precision vs. accumulation of small FFN errors) and evaluate corrective strategies (e.g., normalization, residual gating).
- Causal intervention tests: perform weight-editing and activation-patching experiments to isolate the roles of FFNs (numerical update) vs. attention (routing), demonstrating direct causal links between specific submodules and Bayesian update components.
- Broaden wind tunnels: add POMDPs with actions/rewards, Bayesian linear/logistic regression, sequential Monte Carlo/particle filtering, and graphical model inference to assess the generality of the geometric mechanism.
- Out-of-distribution generalization: evaluate models on sequences with shifted priors, changed S/V, unseen token alphabets, or partially missing headers to test adaptation and robustness.
- Bridge to LLMs: develop diagnostics (key orthogonality, QK sharpening, value-manifold alignment) applicable to pretrained LLMs on synthetic tasks embedded in natural text, to test whether the same Bayesian geometry appears at scale.
- Numerical precision claims: replicate bit-level results with double precision and report uncertainty from posterior computation and probe estimation to ensure measured errors are not dominated by numerical artifacts.
- Minimal late-layer attention requirements: systematically vary the number and placement of late attention layers to quantify the threshold for stable long-horizon rollout and identify architectural trade-offs.
Practical Applications
Immediate Applications
The following applications can be deployed now based on the paper’s findings and tools demonstrated in controlled “Bayesian wind tunnels.”
- Bayesian wind tunnel test suites for model evaluation
- Sector: software/ML tooling
- Application: Build and ship an open-source library (“BayesBench”) to generate synthetic tasks with analytic posteriors (bijections, HMMs), compute entropy calibration error (MAE), and run ablation-based audits.
- Tools/workflows: BayesBench + “BayesScore” plugin for CI; automatic generation of wind-tunnel datasets per release; entropy-vs-Bayes curves for regression tests.
- Assumptions/dependencies: Access to model logits and ability to run teacher-forcing; standard cross-entropy training; reproducible seeds; compute for small-scale evaluation.
- Attention geometry diagnostics for interpretability and QA
- Sector: software/ML interpretability, governance
- Application: Add probes and visualizations to production ML dashboards to track key orthogonality, query–key alignment progression, and value-manifold structure.
- Tools/workflows: “Attention Geometry Dashboard” with probes for pre- and post-sublayer residuals; head/layer ablation diff reports; alerts when routing/precision dissociate abnormally.
- Assumptions/dependencies: Access to internal activations and attention matrices; model owners allow instrumentation; consistent tokenization across versions.
- Model selection guidelines favoring hierarchical attention over flat MLPs for inference tasks
- Sector: software/enterprise ML, product engineering
- Application: Prefer small transformers for in-context inference (hypothesis elimination, state tracking) over capacity-matched MLP baselines; codify in architecture decision records (ADRs).
- Tools/workflows: Benchmark both architectures on wind tunnels before adoption; enforce thresholds on MAE (e.g., <1e-2 bits).
- Assumptions/dependencies: Comparable parameter budgets; task similarity to elimination/recursive updates; willingness to accept attention’s compute overhead.
- Curriculum pretraining on synthetic Bayesian tasks
- Sector: academia, ML training; applied ML teams
- Application: Use bijection elimination and HMM filtering as pretraining curricula to imbue small models with algorithmic Bayesian behavior before domain fine-tuning.
- Tools/workflows: Curriculum schedule mixing wind-tunnel tasks with domain data; checkpoint monitoring via entropy calibration.
- Assumptions/dependencies: Transferability of learned geometry to target domain; stable routing learned early; modest compute budgets.
- Long-horizon stability checks via late-layer attention audits
- Sector: agents/sequence modeling, software QA
- Application: Ensure agent rollouts remain stable by testing sensitivity to disabling late-layer attention; gate releases if length generalization degrades.
- Tools/workflows: “Long-Horizon Audit” script that compares MAE at training vs 1.5×–2.5× sequence lengths; late-layer attention toggle experiments.
- Assumptions/dependencies: Access to model configuration; matched training/eval tokenization; tasks with recursive updates.
- Transformer-based filtering for small HMM-like workloads
- Sector: marketing analytics, operations, basic time-series; daily-life analytics
- Application: Deploy compact transformers to track latent states in clickstreams, session flows, or simple device events (e.g., 5–10 states).
- Tools/workflows: Replace ad-hoc heuristics with transformer filters; monitor entropy calibration per session.
- Assumptions/dependencies: Discrete states and emissions; real-time inference budget; availability of labeled or partially labeled sequences.
- Standards-ready evaluation artifacts for compliance teams
- Sector: policy/governance, AI assurance
- Application: Package entropy calibration reports and permutation-invariance checks as part of model cards to substantiate claims of probabilistic reasoning.
- Tools/workflows: Compliance templates including MAE curves, invariance plots, ablation sensitivity summaries.
- Assumptions/dependencies: Organizational buy-in; auditors versed in probabilistic evaluation; reproducible test data.
- Educational modules on “Bayesian geometry of attention”
- Sector: education/training
- Application: Create course labs showing how keys form orthogonal bases, queries focus feasible hypotheses, and value manifolds encode entropy.
- Tools/workflows: Notebooks with probes, PCA plots, and entropy tracking; assignments comparing transformer vs MLP failure modes.
- Assumptions/dependencies: Access to small GPUs/TPUs; students can run instrumented models.
- Reliability monitoring for production LLMs using wind-tunnel spot checks
- Sector: software/ML ops
- Application: Periodically run frontier models on wind-tunnel tasks to track reasoning drift across updates (even if full interpretability is limited).
- Tools/workflows: Scheduled MAE spot checks; version-to-version delta alerts.
- Assumptions/dependencies: Sufficient output access (logits/probabilities); synthetic tasks not blocked by content filters.
- Sector-specific prototype demos showcasing Bayesian reasoning
- Sector: healthcare, finance, energy
- Application: PoC models that track latent patient risk states, market regimes, or grid component health using compact transformers; visualize posterior entropy changes with new evidence.
- Tools/workflows: Data pipelines feeding discrete observation sequences; dashboards showing posterior trajectories; backtests vs analytic baselines where available.
- Assumptions/dependencies: Mapped discrete state formulations; domain validation; cautious scope to avoid overclaiming beyond small-state scenarios.
Long-Term Applications
These applications require further research, scaling, integration, or policy development before broad deployment.
- Transformer-based Bayesian filters replacing/augmenting HMM/Kalman systems in complex environments
- Sector: robotics, autonomous systems, sensor fusion
- Application: Use attention-based routing to fuse heterogeneous sensors; implement recursive belief updates for localization and control.
- Tools/products: “Bayesian Filter Transformer” modules integrated into ROS or autonomy stacks.
- Assumptions/dependencies: Robustness to continuous state spaces; latency/energy constraints; safety certification; rigorous comparisons to classical filters.
- Production-grade geometric reasoning monitors for LLMs
- Sector: software/ML ops, safety
- Application: Live probes tracking routing stability, key bases, and value-manifold health to detect reasoning failures or drift in deployed assistants/agents.
- Tools/products: “Reasoning Health Monitor” service integrated with observability platforms.
- Assumptions/dependencies: Access to internal signals in closed models; scalable instrumentation; thresholds correlating with downstream reliability.
- Pretraining pipelines that bake in Bayesian structure at scale
- Sector: foundation models, academia
- Application: Large-scale staged curricula that start with wind-tunnel tasks and progressively introduce domain complexity to scaffold algorithmic generalization.
- Tools/products: “Bayesian Curriculum Pretrainer” with task generators and probe-driven checkpoint gating.
- Assumptions/dependencies: Demonstrated transfer to natural tasks; avoidance of catastrophic forgetting; compute budgets.
- Architecture variants with built-in hypothesis-frame inductive biases
- Sector: ML research/engineering
- Application: Design transformers that explicitly encourage orthogonal key bases and entropy-parameterized value manifolds (e.g., regularizers or specialized heads).
- Tools/products: “Bayesian Transformers” with frame-forming heads and precision-refinement layers.
- Assumptions/dependencies: Empirical gains over vanilla architectures; training stability; compatibility with diverse tasks.
- Domain-scale Bayesian wind tunnels for regulated industries
- Sector: healthcare, finance, public policy
- Application: Construct synthetic-but-realistic tasks with analytic posteriors (e.g., triage simulators, regime-switch markets) to audit probabilistic reasoning in models used for high-stakes decisions.
- Tools/products: Regulatory-grade testbeds and certification suites; audit logs with MAE and invariance metrics.
- Assumptions/dependencies: Stakeholder alignment; defensible task design; legal/regulatory acceptance.
- Agent planning systems with enforced late-layer attention for long horizons
- Sector: AI agents, operations research
- Application: Leverage the finding that late-layer attention is crucial for rollout stability to architect planners that maintain recursive consistency over extended sequences.
- Tools/products: Planning stacks with attention scheduling/pinning; length-generalization stress tests.
- Assumptions/dependencies: Clear mapping from synthetic rollouts to complex planning tasks; computational overhead management.
- Calibration-first deployment policies and procurement standards
- Sector: policy/governance
- Application: Require Bayesian consistency tests (entropy calibration, invariance under relabeling) in RFPs and compliance checklists for AI systems.
- Tools/products: “Bayesian Consistency Standard” with reference metrics and minimum thresholds.
- Assumptions/dependencies: Multi-stakeholder consensus; auditor training; model providers willing to expose evaluation hooks.
- Privacy and memorization audits grounded in wind-tunnel methodology
- Sector: security/privacy
- Application: Use tasks where memorization is provably impossible to separate genuine inference from data leakage; incorporate into privacy risk assessments.
- Tools/products: Audit pipelines comparing performance in non-memorizable vs memorizable regimes.
- Assumptions/dependencies: Clear linkage between wind-tunnel performance and privacy behavior on natural data.
- Sector-specific state-tracking systems for continuous or hybrid latent spaces
- Sector: healthcare (patient trajectory modeling), finance (regime detection), energy (grid state estimation)
- Application: Extend geometric Bayesian mechanisms to continuous distributions and hybrid models; integrate with real-time operations.
- Tools/products: Hybrid discrete–continuous Bayesian attention modules; uncertainty-aware dashboards.
- Assumptions/dependencies: Novel training objectives; approximate posteriors for evaluation; domain validation and safety checks.
- Educational and workforce upskilling at scale
- Sector: education, industry training
- Application: Standardize curricula teaching probabilistic reasoning via transformer geometry; certify practitioners in “Bayesian attention” diagnostics.
- Tools/products: MOOCs, lab kits, certification programs; shared datasets and probe libraries.
- Assumptions/dependencies: Institutional adoption; alignment with industry needs; maintenance of open educational resources.
Glossary
- AdamW: An optimizer variant of Adam that decouples weight decay from the gradient update to improve regularization. "AdamW with , , weight decay 0.01, gradient clipping at 1.0."
- Bayes' rule: The fundamental rule that updates a prior belief with evidence to produce a posterior distribution. "by Bayes' rule and the factorization ."
- Bayesian filtering: Recursive computation of posterior beliefs over latent states as new observations arrive, typically in state-space models. "If the model implements Bayesian filtering rather than associating meaning with specific state IDs, its entropy calibration should be unchanged up to numerical noise."
- Bayesian posterior predictive distribution: The distribution of outcomes obtained by averaging the likelihood over the posterior of model parameters. "The minimizer of \eqref{eq:ce} is the Bayesian posterior predictive distribution"
- Bayesian wind tunnels: Controlled tasks where the true posterior is known analytically and memorization is impossible, enabling rigorous verification of Bayesian computation. "Bayesian wind tunnels---controlled environments where the true posterior is known in closed form and memorization is provably impossible."
- Bijection: A one-to-one and onto mapping between two sets (each element of the domain maps to a unique element of the codomain). "each is a bijection ."
- Content-addressable lookup: Retrieving information by its content rather than by its position or index, often via similarity in representation space. "Orthogonal keys (\Cref{fig:key_orthogonality}) provide a basis for content-addressable lookup of hypotheses."
- Content-addressable routing: Directing information flow based on content similarity, typically via attention mechanisms that match queries to keys. "attention provides content-addressable routing."
- Cosine decay: A learning-rate schedule that decreases following a cosine curve, often used to smooth training. " with 1000-step warmup and cosine decay."
- Cosine similarity: A measure of similarity between two vectors defined by the cosine of the angle between them. "Cosine similarity matrix of key vectors for all input tokens in the bijection model at 150k steps."
- Cross-entropy: A loss function that measures the difference between two probability distributions, commonly used for training classifiers. "Cross-entropy training on contextual prediction tasks has a well-known population optimum"
- Dirichlet distribution: A distribution over probability vectors, often used as a prior for categorical distributions. "Dirichlet distribution with all concentration parameters equal to 1 (i.e., )"
- Emission matrix: In an HMM, the matrix of probabilities for each observation symbol given each hidden state. "an emission matrix "
- Feed-forward networks (FFN): Non-recurrent layers that apply learned nonlinear transformations; in transformers, FFNs update the residual stream. "Feed-forward networks as Bayesian update: FFNs perform the numerical posterior computation."
- Forward algorithm: The dynamic programming procedure that computes the posterior over hidden states in an HMM given observations. "the true Bayesian posterior over hidden states is given by the forward algorithm"
- Gradient clipping: A technique that limits the norm or value of gradients to stabilize training and prevent exploding gradients. "gradient clipping at 1.0."
- Head-wise ablation: Removing individual attention heads to test their contribution to model behavior or performance. "Head-wise ablation."
- Hidden Markov Model (HMM): A probabilistic model with Markovian hidden states and observed emissions. "Across two tasks---bijection elimination and Hidden Markov Model (HMM) state tracking---"
- Hierarchical attention: Multi-layer attention structure that composes routing and refinement across depth to implement complex computations. "hierarchical attention realizes Bayesian inference by geometric design"
- Initial state distribution: The prior distribution over the starting hidden state in an HMM. "an initial state distribution ."
- Key orthogonality: The property that key vectors are nearly orthogonal, providing well-separated axes for hypothesis representation. "Key orthogonality in Layer~0."
- Layer normalization: A normalization method applied within layers to stabilize and accelerate training. "residual connections and layer normalization"
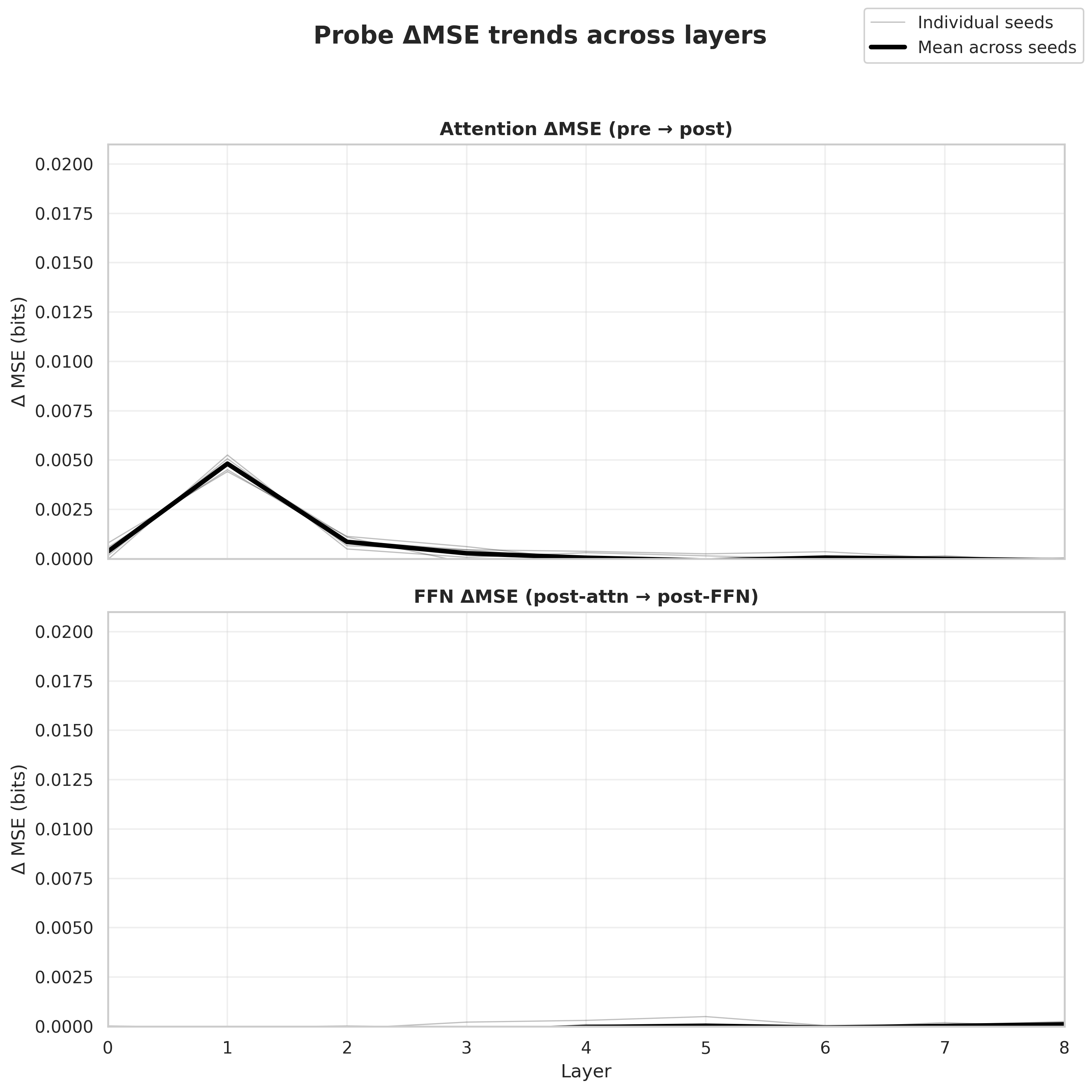
- Layer-wise ablations: Removing entire layers to determine their importance in the learned computation. "Layer-wise ablations (\Cref{fig:layer0_vs_ffn}) show that removing any block increases error by more than an order of magnitude"
- Linear probe: A simple linear model trained on internal representations to assess what information they encode. "we train a linear probe on the pre-sublayer residual stream to predict the analytic posterior entropy"
- Mean absolute entropy error (MAE): The average absolute difference between model-predicted entropy and analytic posterior entropy across positions. "We measure this using mean absolute entropy error (MAE),"
- Mean-squared error (MSE): The average of squared differences between predicted and true values, used here to evaluate probe performance. "change in mean-squared error (MSE)"
- Multi-head self-attention: An attention mechanism with multiple parallel heads that attend to different aspects of the sequence. "standard multi-head self-attention."
- PCA projection: Applying principal component analysis to project high-dimensional representations into lower dimensions for visualization. "PCA projection of attention outputs in the bijection model, colored by analytic posterior entropy."
- Perplexity: A metric for probabilistic models (especially LLMs) that measures how well a probability distribution predicts a sample. "independent of accuracy or perplexity."
- Population optimum: The best-performing function (under infinite data/capacity) with respect to the true data-generating distribution. "has a well-known population optimum"
- Positional embeddings: Learned vectors added to token embeddings to encode positional information in sequence models. "learned absolute positional embeddings"
- Pre-norm residual blocks: Transformer block design that applies normalization before sublayers, aiding optimization stability. "pre-norm residual blocks"
- QK geometry: The geometric relationship between queries and keys that determines attention routing and retrieval. "QK geometry retrieves the relevant components of the belief for each update."
- Query--key alignment: The degree of alignment between query and key vectors that focuses attention on relevant tokens or hypotheses. "progressive query--key alignment"
- Residual stream: The running representation passed through layers via residual connections; here, it encodes the belief state. "Residual stream as belief state: posterior information accumulates layer-by-layer."
- Rollout: Evaluating a model beyond its training horizon to test whether it has learned position-independent algorithms. "we roll the model out to and training length."
- Semantic invariance under hidden-state relabeling: The property that computations remain unchanged under permutations of hidden-state labels. "Semantic invariance under hidden-state relabeling."
- Teacher forcing: A training technique where the model is fed the ground-truth outputs at each step. "with teacher forcing at every position."
- Transition matrix: In an HMM, the matrix of probabilities for transitioning between hidden states. "a transition matrix "
- Value manifold: A low-dimensional structure in value representations that encodes posterior properties like entropy. "a low-dimensional value manifold parameterized by posterior entropy."
- Weight decay: A regularization technique that penalizes large weights to reduce overfitting. "weight decay 0.01"
Collections
Sign up for free to add this paper to one or more collections.

