- The paper presents an auto-regressive paradigm that sequentially generates latent embeddings, drastically reducing storage by compressing multi-vector representations.
- The paper demonstrates enhanced gradient flow with rapid convergence, achieving nDCG@5 scores of 0.516 and 0.811 on ViDoRe benchmarks.
- The paper enables adaptive test-time scaling, allowing dynamic sequence length adjustments to balance latency and retrieval performance in practical applications.
CausalEmbed: Auto-Regressive Multi-Vector Generation for Visual Document Embedding
Introduction and Motivation
Visual Document Retrieval (VDR) increasingly adopts multi-vector embeddings generated from Multimodal LLMs (MLLMs) to capture page layouts and content structure more effectively than traditional text-centric approaches. Prevailing multi-vector solutions such as ColPali and ColQwen represent each document via thousands of dense visual tokens, introducing excessive storage and inference overhead that undermines practical deployment. The "CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding" (2601.21262) paper confronts this bottleneck by leveraging an auto-regressive paradigm to sequentially synthesize compact multi-vector embeddings in the latent space, attaining drastic compression while preserving—or even improving—retrieval efficacy.
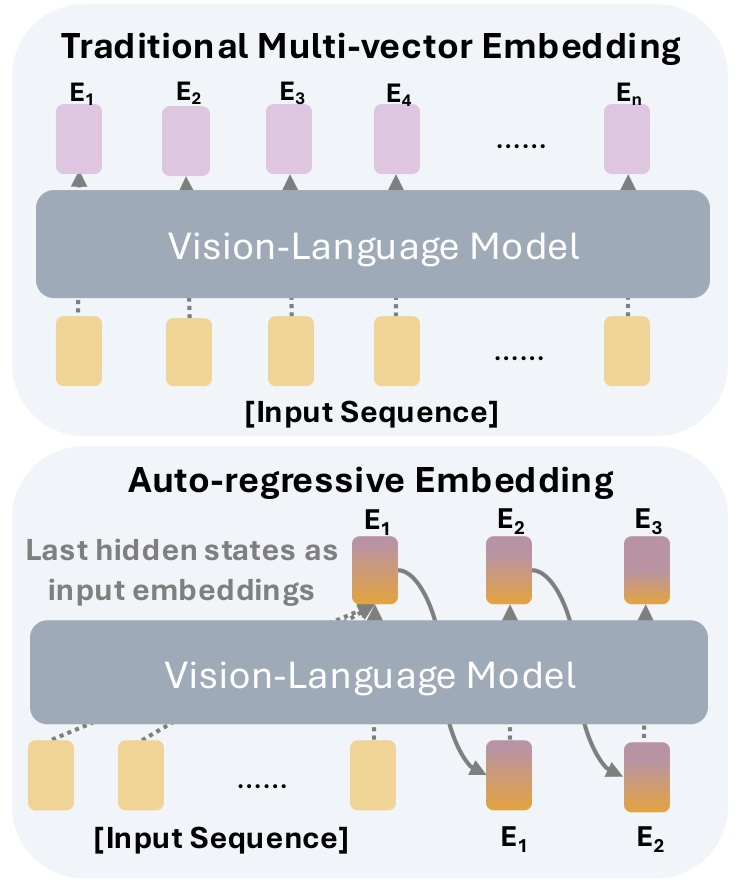
Figure 1: Comparison between traditional multi-vector embedding approaches and the proposed auto-regressive paradigm for multi-vector generation in visual document retrieval.
CausalEmbed Framework
CausalEmbed employs an MLLM backbone with a vision encoder and an auto-regressive language decoder. For each input document or query, initial context features are computed, after which the latent embedding sequence is generated step-wise, each token conditioned on both the context and previously generated embeddings. This generative procedure allows dynamic adjustment of embedding sequence length during both training and inference—a critical departure from fixed-budget, patch-level methods.
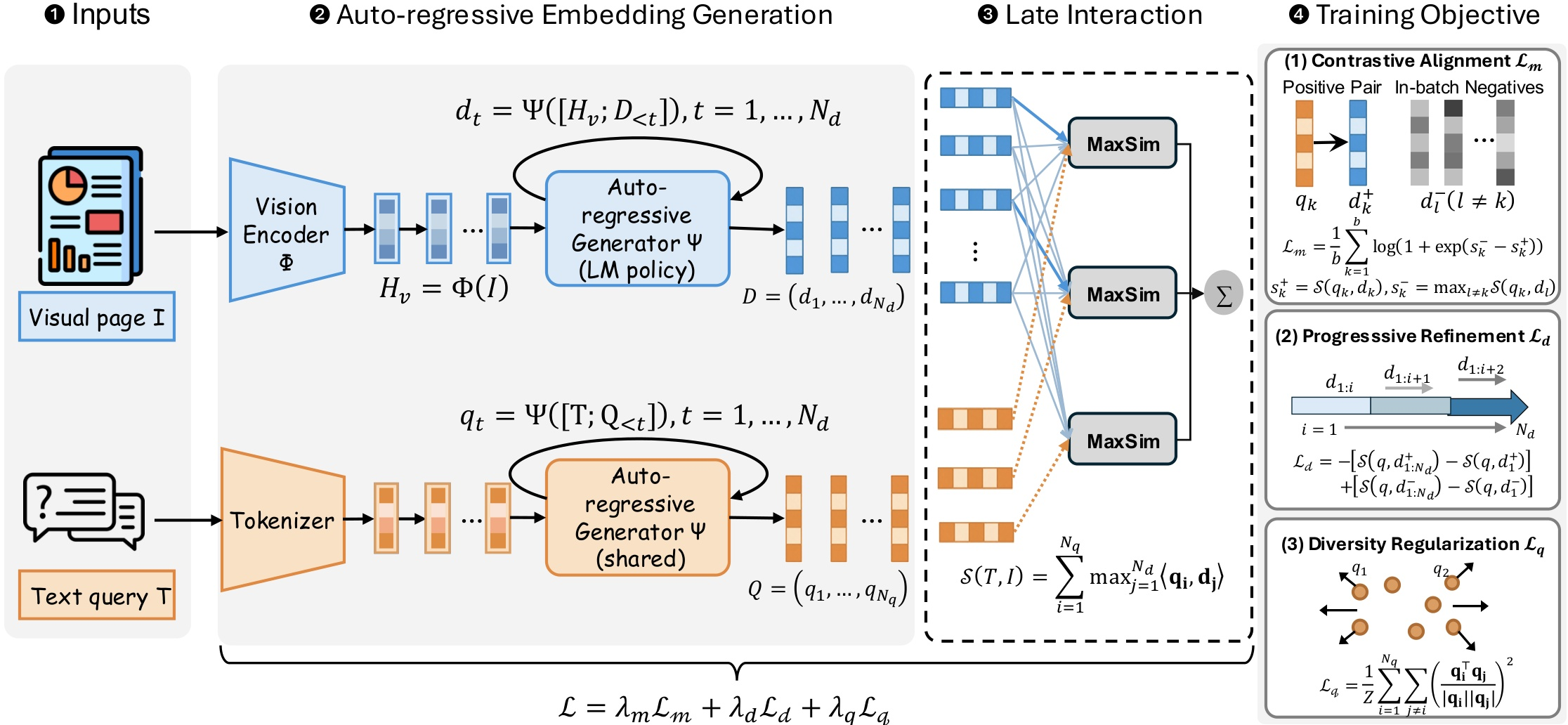
Figure 2: Overview of the complete CausalEmbed framework, illustrating visual token encoding and auto-regressive latent vector generation for both documents and queries.
Contrastive training employs an iterative margin loss, maximizing late-interaction scores between related query-document pairs and penalizing the hardest negatives. The overall objective is regularized via progressive refinement and diversity constraints, ensuring that added tokens enhance discriminative power and enforce token-wise decorrelation.
Training Dynamics and Efficiency
A core theoretical insight of the work is that auto-regressive multi-vector generation delivers significantly broader gradient flow compared to traditional parallel encoding. Since each newly generated embedding in CausalEmbed depends causally on all prior representations, parameter updates propagate more efficiently across the embedding sequence, improving sample utilization and accelerating convergence.
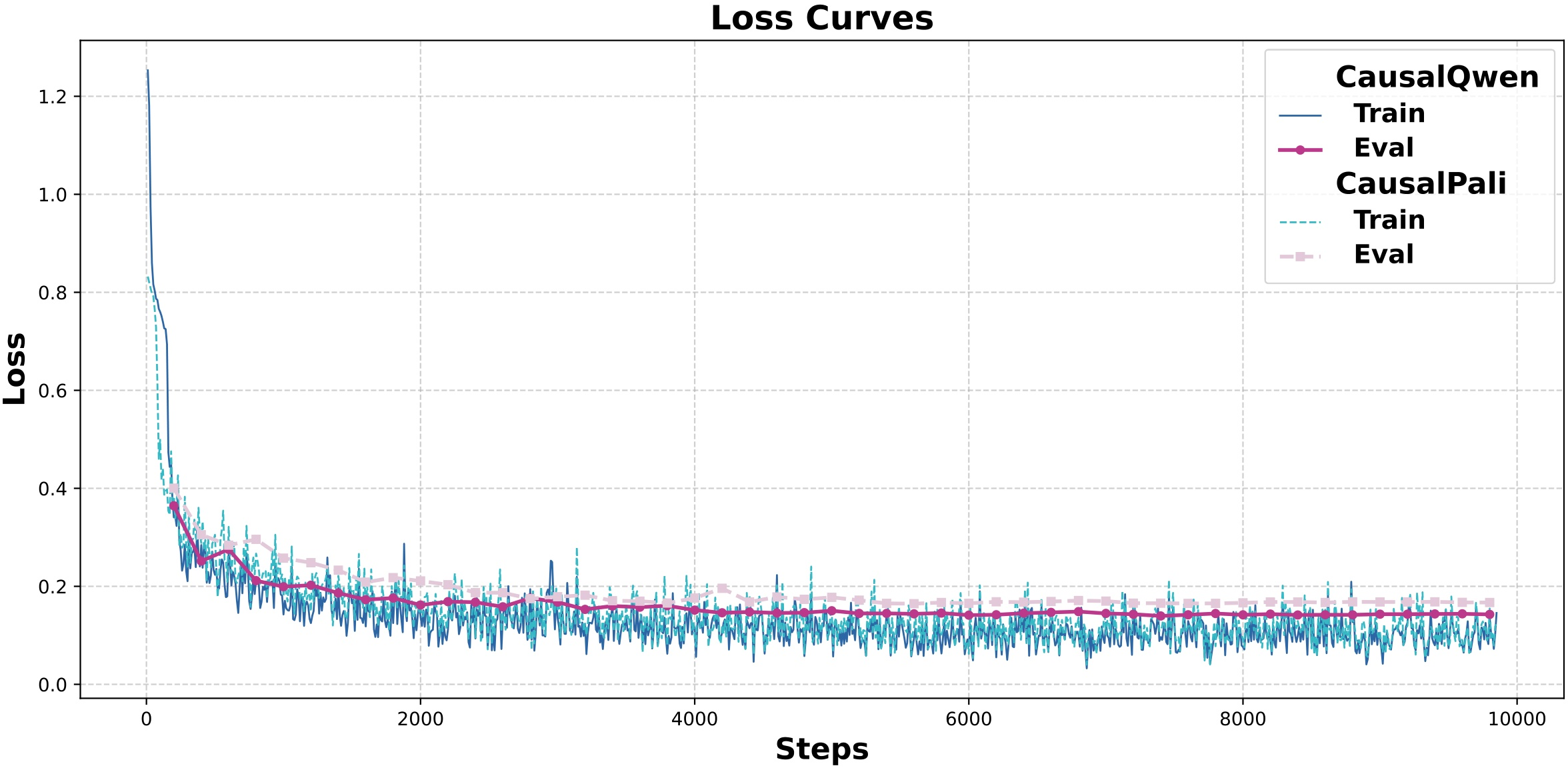
Figure 3: Training and evaluation loss curves for CausalQwen and CausalPali over one epoch, highlighting rapid and stable convergence within a single pass.
Empirically, CausalQwen and CausalPali (using Qwen2.5-VL and PaliGemma backbones, respectively) converged within 10,000 steps (one epoch), outpacing multi-vector baselines that required up to five epochs for comparable stability.
Experiments on ViDoRe V1-V3 benchmarks demonstrate that CausalEmbed yields a 30–155× reduction in token count, maintaining retrieval accuracy superior to semantic clustering, pooling, and pruning-based compression strategies—despite using only dozens of latent tokens per page. For example, under compression to 32 tokens, CausalQwen achieves nDCG@5 scores of 0.516 (ViDoRe V2) and 0.811 (ViDoRe V1), surpassing all baseline approaches by large margins and outperforming the full ColPali model when applied to the PaliGemma backbone.
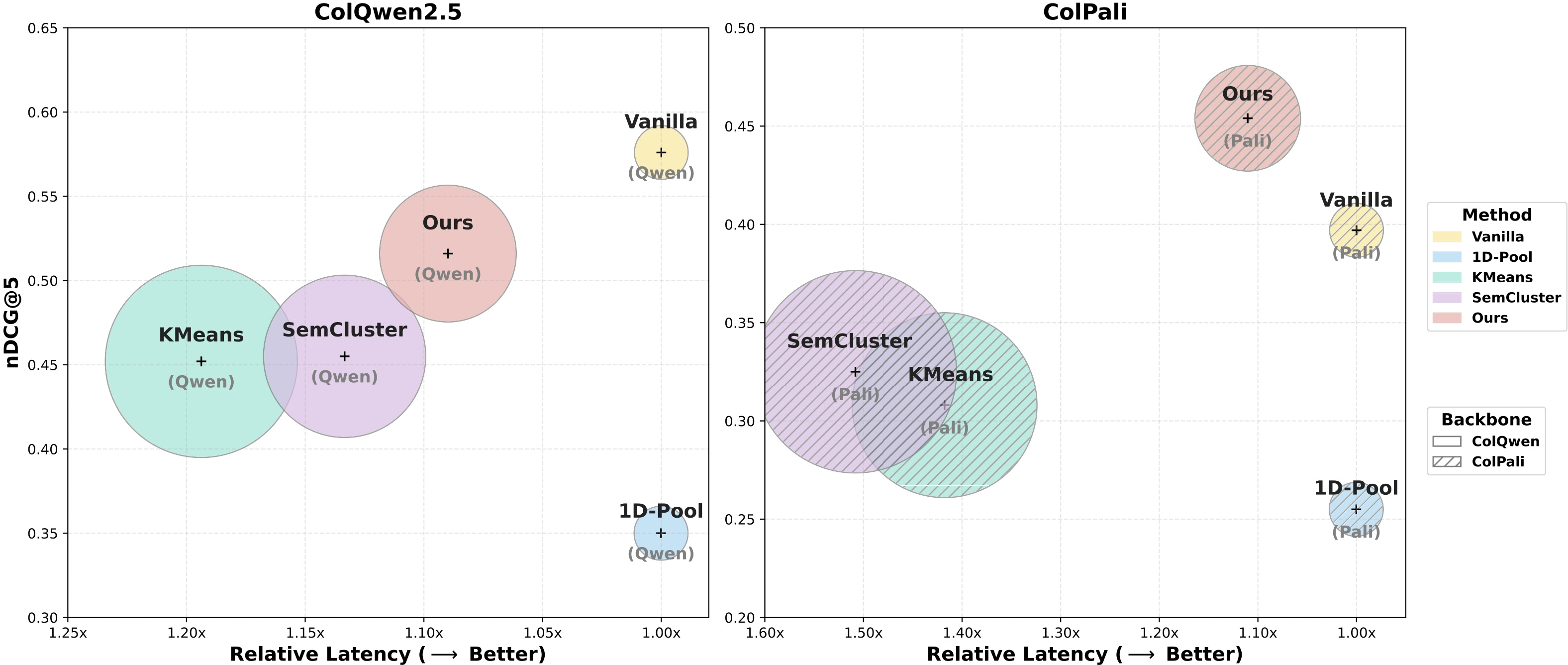
Figure 4: Visualization of retrieval performance versus latency on ViDoRe V2; bubble sizes denote adaptation overhead, indicating that CausalEmbed achieves superior trade-offs over clustering-based baselines.
A notable feature is test-time scaling: retrieval performance improves monotonically with increased sequence length during inference, independent of training length budget. This allows practitioners to adapt sequence lengths to deployment constraints, achieving flexible trade-offs between latency and accuracy.
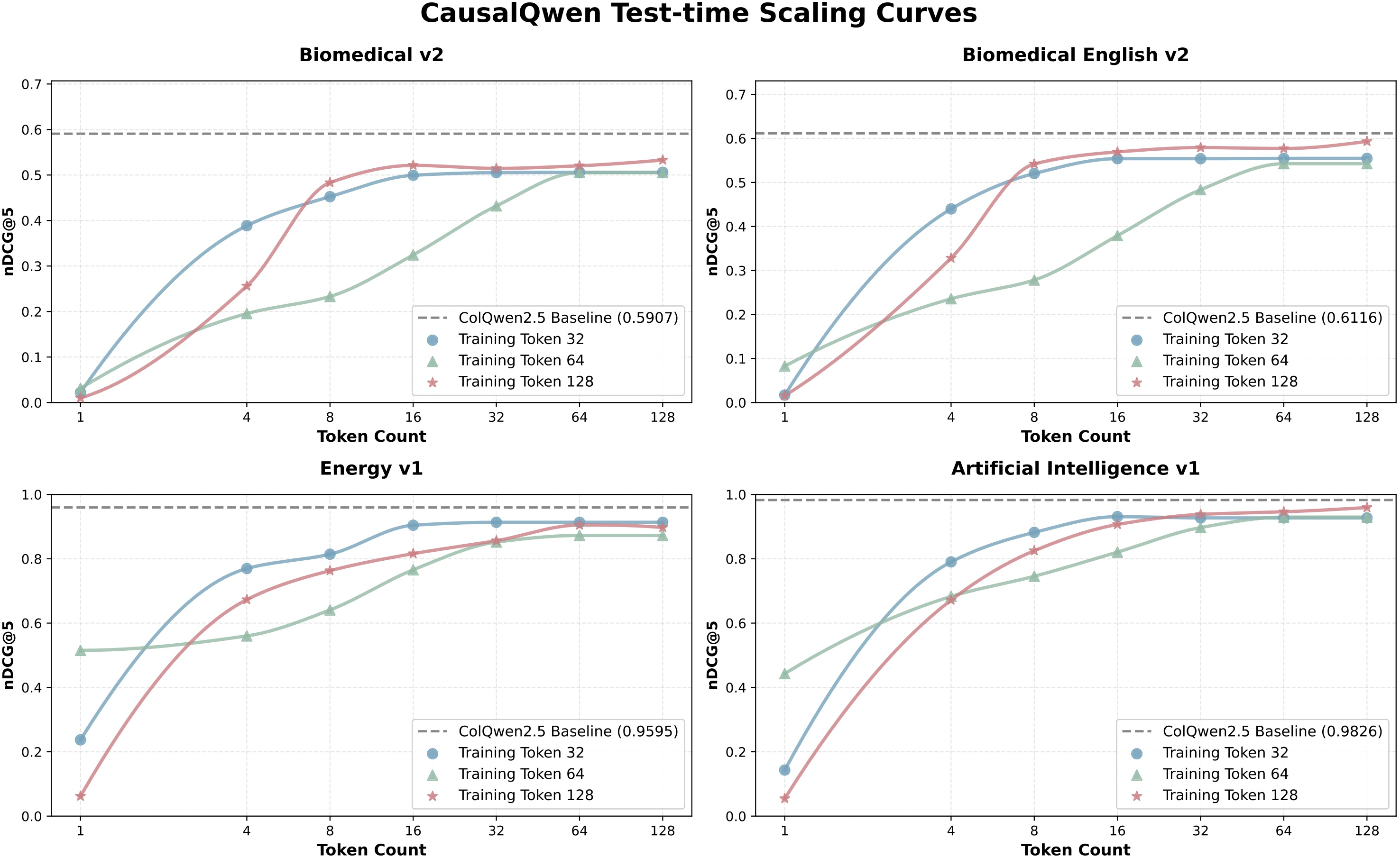
Figure 5: Test-time scaling curves for CausalQwen on different token budgets, illustrating consistent performance gains with longer embedding sequences.
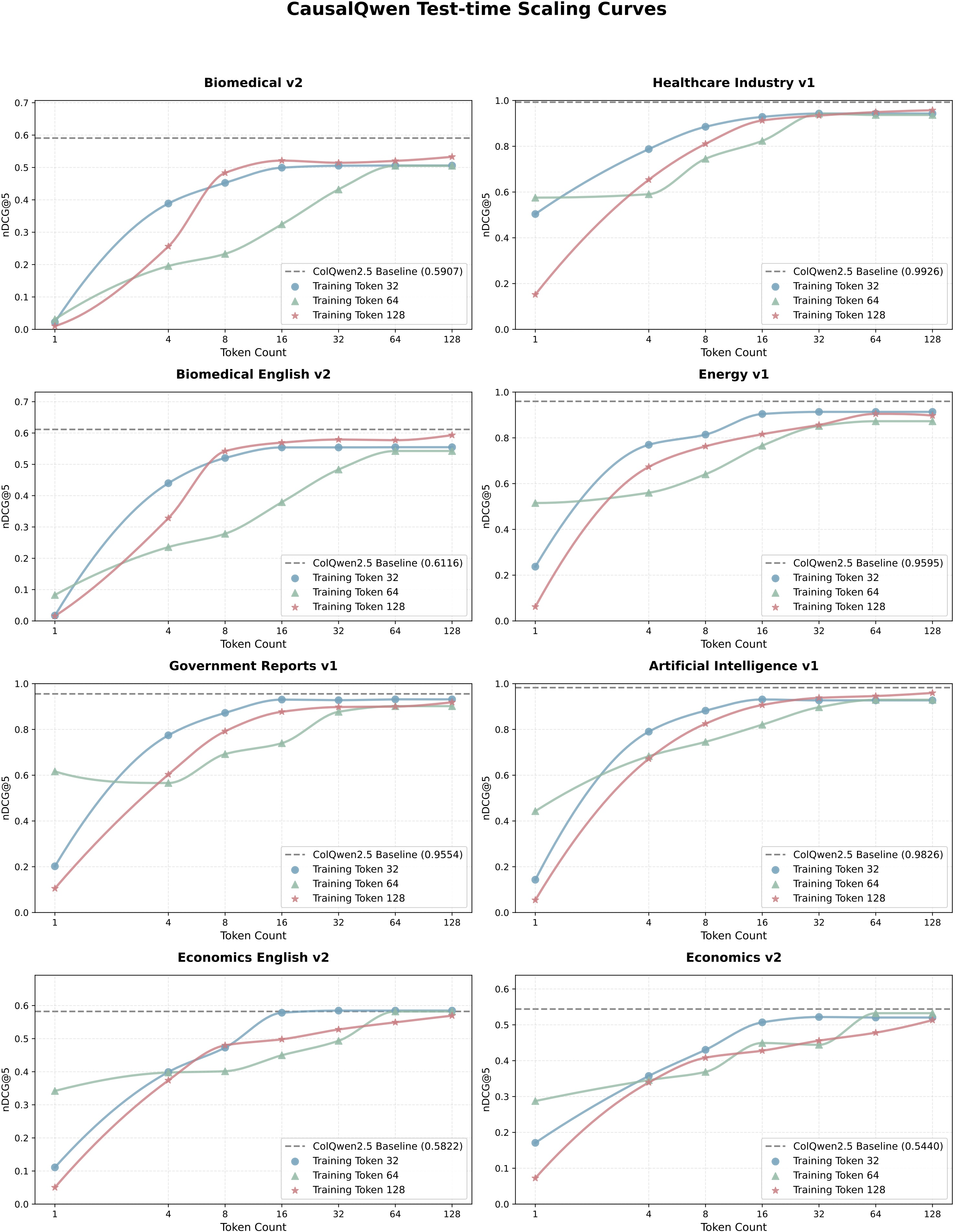
Figure 6: Additional results showing consistent test-time scaling across ViDoRe V1 and V2, confirming the generality of adaptive sequence length in CausalEmbed.
Embedding Semantics and Robustness
Qualitative case studies highlight that CausalEmbed allocates most semantic content to early tokens, with later tokens refining fine-grained details. Unlike clustering/posthoc pruning, auto-regressive generation avoids collapsing into repetitive or irrelevant patterns, offering robust sequence-to-sequence alignment even in visually-dense or cross-domain retrieval scenarios.
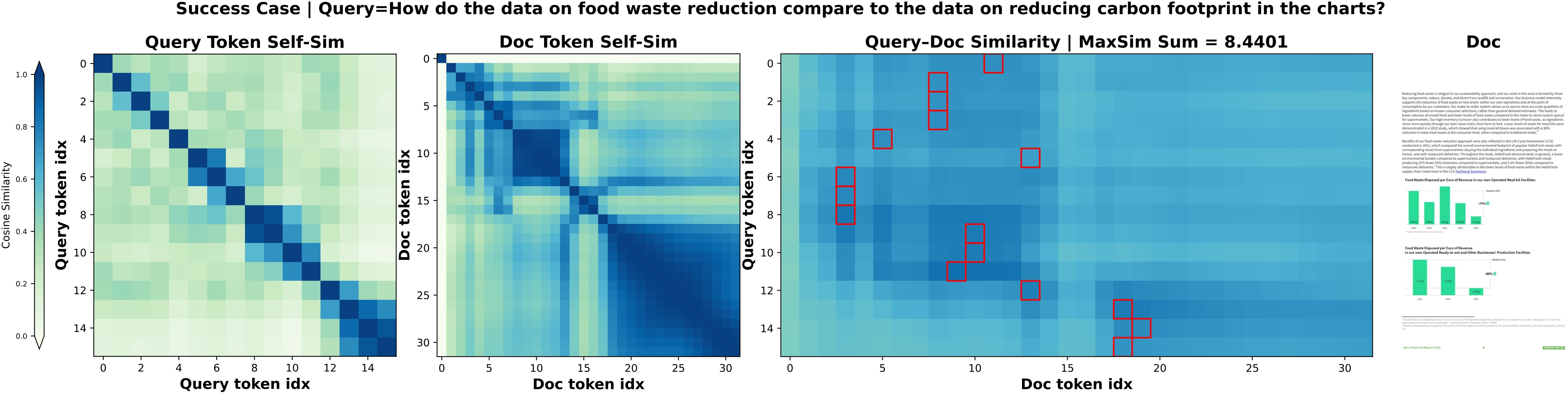
Figure 7: Query-document interaction heatmaps for CausalQwen on ViDoRe V2, revealing diverse and informative token-wise cross-similarity patterns.
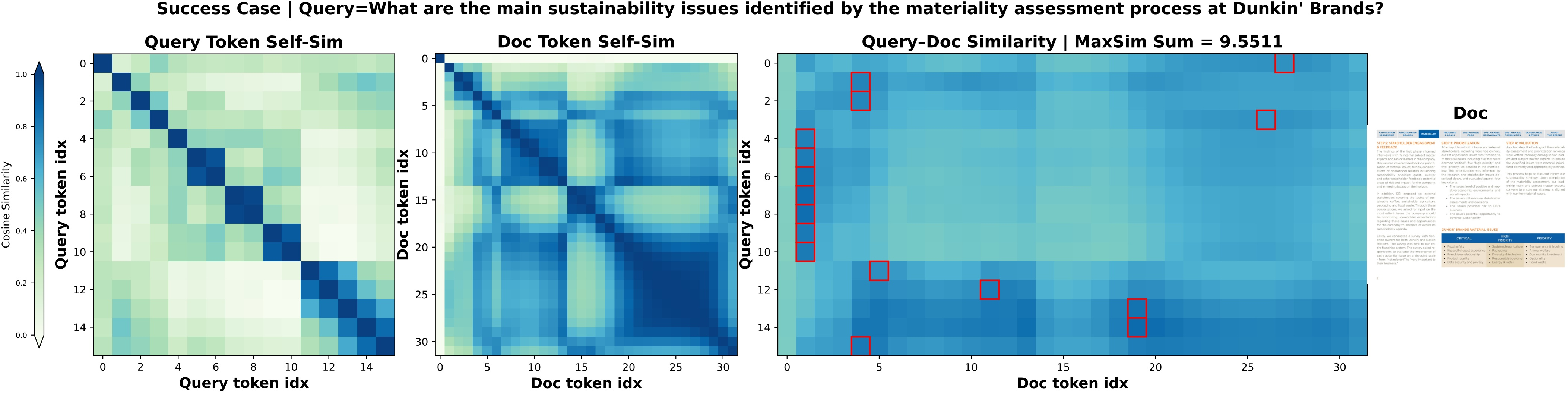
Figure 8: Success cases of CausalQwen, illustrating high-quality token selection and strong query-document alignment.
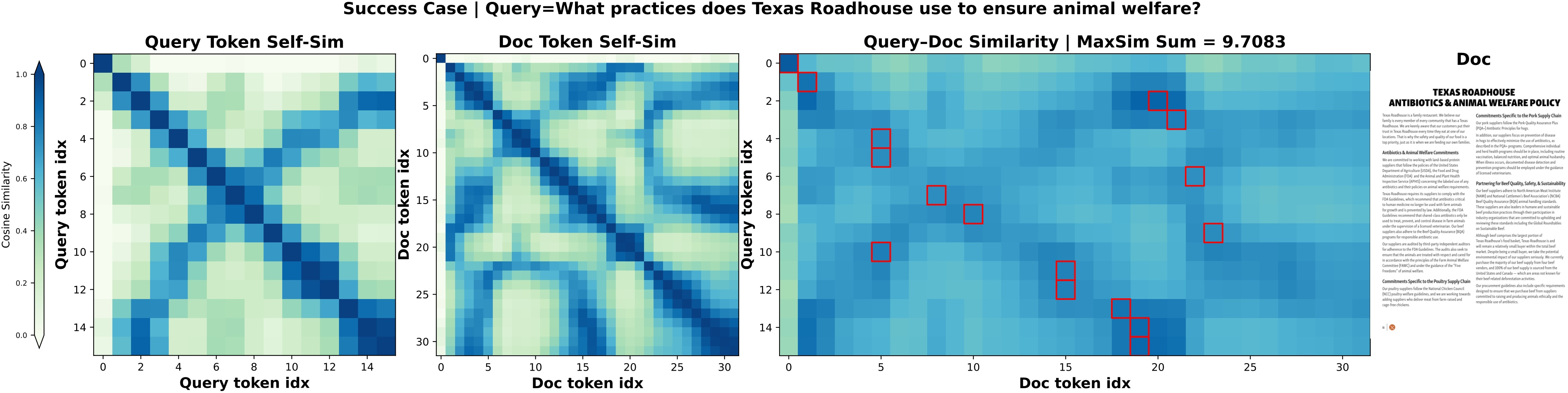
Figure 9: Success cases for CausalPali on complex visual document queries.
Conversely, failure cases indicate that retrieval errors typically arise from subtle semantic mismatches or ambiguous visual content, not from embedding collapse—implying the potential for further improvements via backbone advances.
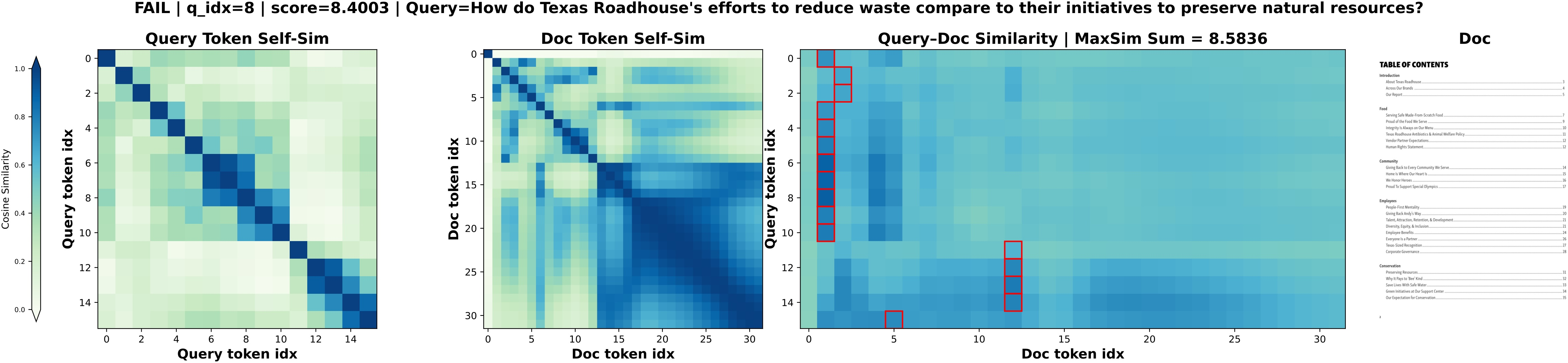
Figure 10: Failure cases in CausalQwen, highlighting error modes in cross-modal retrieval.
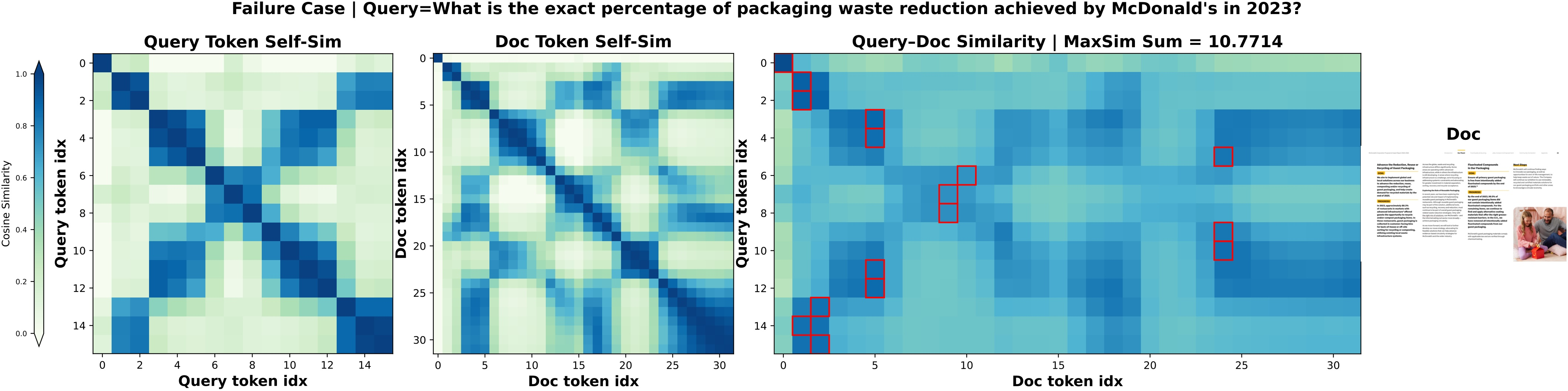
Figure 11: Failure cases in CausalPali, demonstrating the limits of auto-regressive multi-vector generation under challenging document scenarios.
Framework Implications and Future Directions
CausalEmbed challenges the orthodoxy of parallel, patch-level multi-vector embeddings by demonstrating that auto-regressive generative modeling in the latent space produces more compact, flexible and generalizable representations for VDR. Theoretical analysis reveals vastly improved gradient propagation and efficient training. Practically, sequence length adaptivity offers crucial flexibility for resource-constrained and latency-sensitive applications.
The framework’s robust cross-backbone performance strongly suggests that auto-regressive embedding generation will be central to next-generation multimodal retrievers. Areas for future research include: model scaling, integration with Matryoshka-style dynamic truncation, augmentation with explicit reasoning steps, and tightly-coupled deployment on mobile or edge devices.
Conclusion
CausalEmbed introduces an auto-regressive framework for multi-vector latent embedding in visual document retrieval, achieving extreme compression ratios, strong retrieval performance, and remarkable adaptivity at test time. The paradigm not only addresses pressing storage and latency challenges but also opens avenues for generative multimodal embedding methods with rigorously analyzed theoretical and empirical properties. The demonstrated robustness, efficiency, and scalability of the approach recommend CausalEmbed as a new standard for visual document embedding in practical and research settings.

