- The paper shows that MLLMs’ representations are dominated by text features, limiting their ability to distinguish visual details.
- It employs sparse autoencoder analysis on final-layer activations to quantify energy, modality bias, and retrieval attribution in MLLMs.
- Ablation of high-energy distractor features significantly improves retrieval accuracy, indicating the need for decoupled architectures and tailored training objectives.
Failure of MLLMs as Zero-Shot Multimodal Retrievers: An Interpretability Perspective
Introduction
Despite the documented generative prowess of Multimodal LLMs (MLLMs) in image captioning, VQA, and visual reasoning, these models perform surprisingly poorly on zero-shot multimodal retrieval benchmarks when compared to contrastive Vision-LLMs (VLMs) such as CLIP. The paper "Generative Giants, Retrieval Weaklings: Why do Multimodal LLMs Fail at Multimodal Retrieval?" (2512.19115) undertakes a mechanistic analysis of this failure mode, dissecting the representational geometry of MLLMs using sparse autoencoders (SAEs) to uncover intrinsic biases, modality allocation behavior, and the attribution properties of their learned features.
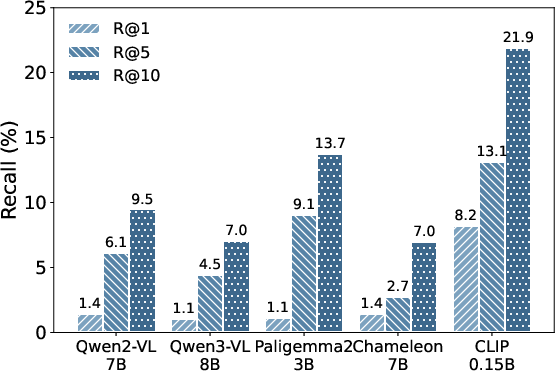
Figure 1: Multimodal retrieval performance of MLLMs and CLIP on the CIRR ((qi,qt)→ci) dataset. The results illustrate the inferior performance of MLLMs.
Methodology: Sparse Autoencoder-Based Concept Dissection
The analysis employs Top-K SAEs trained on final-layer activations over billions of samples to decompose dense MLLM embeddings into interpretable basis concepts. Each concept is quantitatively characterized by metrics: (1) energy (frequency/intensity of activation), (2) modality score (bias toward image or text content), (3) bridge score (capacity to connect modalities), and (4) retrieval attribution, representing its direct contribution to cross-modal similarity.
Comparison models span a range of MLLMs (Qwen2-VL-7B, Qwen3-VL-8B, Paligemma2-3B, Chameleon-7B) and contrastive VLMs (CLIP, SigLIP2). Mean pooling over all final-layer token embeddings is empirically shown to outperform last-token extraction for MLLMs in retrieval scenarios, and is thus the default representation.
Key Findings
1. Overwhelming Textual Dominance in MLLM Representations
The modal analysis of learned concepts reveals an acute text-centric bias in MLLM representational spaces; the majority of high-energy features are exclusively or predominantly text-driven, while visual concepts form a smaller, relatively inactive minority. In contrast, CLIP and SigLIP2 develop a distribution with a higher prevalence of balanced, multimodal concepts that meaningfully encode both visual and textual information.
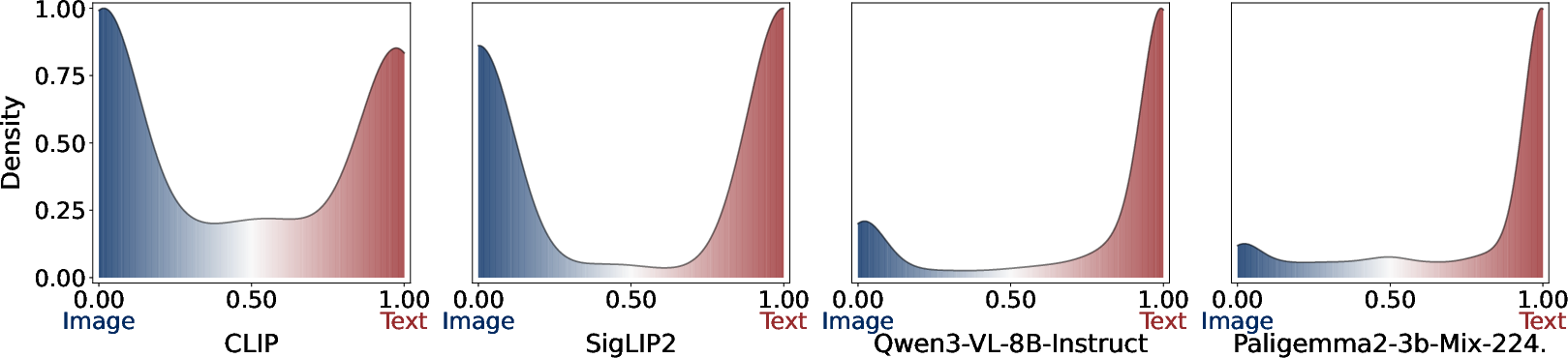
Figure 2: Distribution of modality scores for learned concepts by (a) CLIP, (b) SigLIP2, (c) Qwen3-VL-8B-Instruct, and (d) Paligemma2-3b-Mix-224. The Modality Score quantifies the bias of each concept towards the image modality (blue) or the text modality (red).
This imbalance in MLLMs severely limits the fraction of embedding space that is responsive to visual differences between candidate images or mixed queries—degrading their ability to act as discriminative multimodal retrievers, especially in protocols demanding cross-modal recall.
2. Over-Allocation to Modality Bridging at the Expense of Discriminability
Ranking learned concepts by energy indicates a strong long-tail: a small set of dominant features is repeatedly activated across samples. Further, Jaccard overlap between top energy, bridge, and retrieval attribution features is markedly higher for MLLMs than contrastive VLMs, demonstrating that concept subspaces responsible for energy, cross-modality alignment, and retrieval scores are highly collinear and undifferentiated in MLLMs.
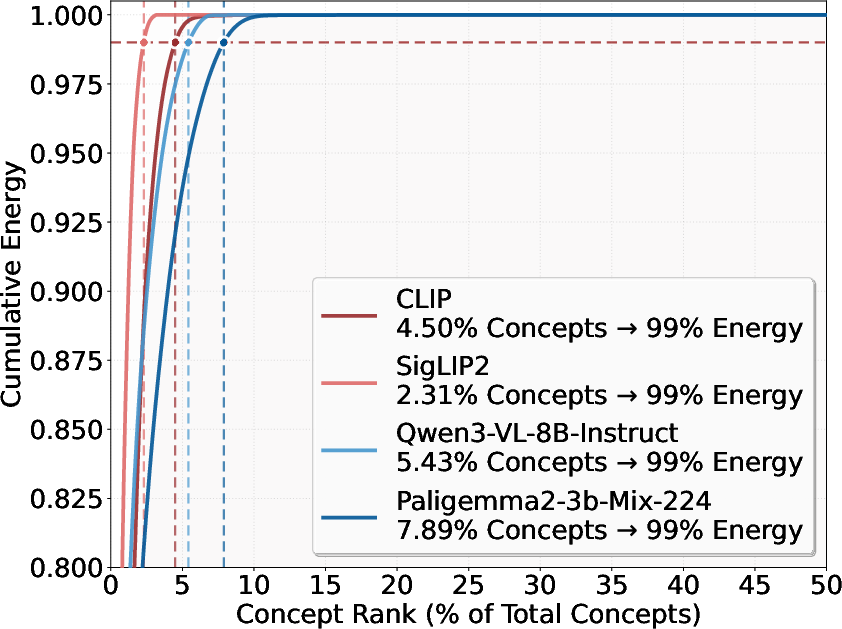
Figure 3: Cumulative energy distribution across concept ranks for different multimodal models. The curves show the percentage of total energy captured as concepts are ranked by their individual energy values.
Additionally, the ablation experiment—where image tokens are masked prior to pooling—shows that MLLM retrieval does not significantly deteriorate unless prompt (user question) tokens are removed, further underscoring the subordination of visual input in the final representation.
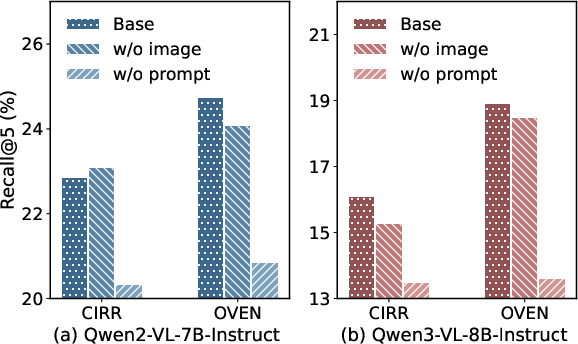
Figure 4: Retrieval performance on a subset (3k queries) of CIRR and OVEN datasets. “Base” uses full input; “w/o image” and “w/o prompt” represent removal of image tokens and prompt tokens, respectively. Marginal change after removing image tokens highlights visual insignificance in output embeddings.
3. Dominant Similarity Components Are Counterproductive Distractors
Ablating (projecting out) the top 1% of concept subspaces with highest retrieval attribution from MLLM embeddings before similarity computation dramatically and consistently improves retrieval accuracy. This implies that the features contributing most to the similarity metric are not encoding discriminative semantic content, but instead act as confounders—reducing the effective dynamic range of the retrieval metric across samples. In contrast, such ablation would degrade CLIP-style retrieval.
Theoretical and Practical Implications
These results collectively establish that the architectural and pretraining inductive biases of MLLMs, optimized for generative consistency and deep modality bridging, conflate alignment with semantic preservation. The bridging concepts centralize nearly all variability in the text subspace, leaving insufficient capacity for visual discriminability. This geometric collapse directly undermines dense retrieval scenarios where fine-grained cross-sample differentiation is critical.
Practically, this shows that extracting retrieval-relevant representations from generative MLLMs without specific architectural alterations or additional contrastive objectives is fundamentally limited. Attempts to simply repurpose MLLMs as embedding extractors (as in RAG-style applications or cross-modal search) risk poor performance unless significant adaptation or new training pipelines are introduced.
Future Directions
This mechanistic study points toward several research directions:
- Decoupled Representation Heads: Architectures explicitly separating generative alignment and retrieval discriminability.
- Hybrid Contrastive Training: Introducing contrastive or metric-learning losses targeting MLLM hidden states to diversify high-energy subspaces.
- Modality Regularization: Training regimes that actively balance concept space occupation between modalities or penalize text-centric collapse.
- Sparse Concept Editing: Adversarial or regularized pruning/masking of high-attribution distractor features, as demonstrated in the ablation experiments.
Developing universal embedding spaces for robust multimodal retrieval will likely require revisiting these architectural and loss-function assumptions.
Conclusion
This work provides a rigorous interpretability analysis demonstrating that MLLMs are fundamentally limited in zero-shot multimodal retrieval by text-centric, over-aligned concept spaces and attributionally misleading high-energy features. The comparison with contrastive VLMs underscores critical differences in representational geometry that drive practical performance divergence between generative models and dedicated retrievers. Addressing these limitations demands modifications at both the representation and training objective levels—simple post-hoc repurposing is insufficient. The insights offered here form a foundation for principled improvements in future multimodal retriever design.