- The paper introduces the LCO-Emb framework, demonstrating that lightweight text-only contrastive learning can activate latent cross-modal alignment in MLLMs.
- It empirically shows that generative pretraining with parameter-efficient methods like LoRA enhances representations across text, image, audio, and video modalities.
- The study establishes a Generation-Representation Scaling Law linking generative capacity to downstream representation quality, offering key insights for scalable multimodal models.
Scaling Language-Centric Omnimodal Representation Learning: Theory, Empirics, and Implications
Introduction
This paper presents a comprehensive investigation into the representational capabilities of multimodal LLMs (MLLMs) and introduces the Language-Centric Omnimodal Embedding (LCO-Emb) framework. The central thesis is that generative pretraining in MLLMs induces latent cross-modal alignment, which can be efficiently activated and refined via lightweight, language-centric contrastive learning (CL). The work further establishes a Generation-Representation Scaling Law (GRSL), theoretically and empirically linking the generative capacity of MLLMs to their downstream representation quality after CL. The implications are significant for the design and scaling of universal embedding models across text, image, audio, and video modalities.
Latent Cross-Modal Alignment in MLLMs
The authors empirically analyze the geometric properties of MLLM embeddings, focusing on anisotropy and kernel-level similarity. Anisotropy, measured as the expected cosine similarity between random embeddings, is a known issue in self-supervised models, leading to representation collapse. The study demonstrates that text-only CL not only improves the isotropy of text embeddings but also generalizes to non-text modalities (image, audio, video), even without direct multimodal supervision. This is attributed to the shared latent space established during generative pretraining.
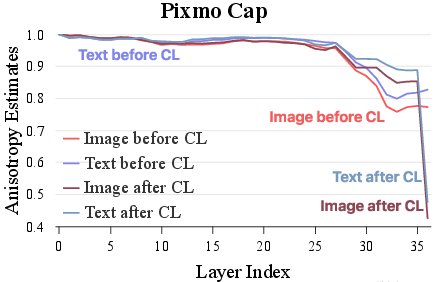
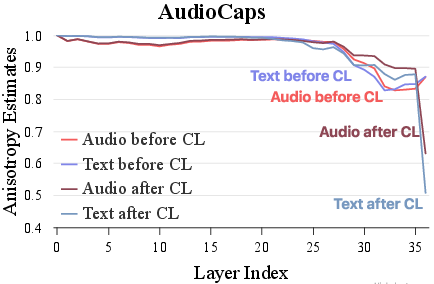
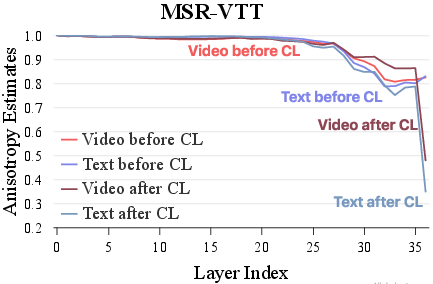
Figure 1: Anisotropy estimates of Qwen2.5-Omni-3B embeddings across modalities before and after text-only CL, showing improved isotropy and latent cross-modal alignment.
Kernel-level similarity analysis further reveals that text-only CL enhances the alignment of similarity structures across modalities, with larger models (e.g., 7B vs. 3B) exhibiting stronger cross-modal kernel alignment. This supports the hypothesis that generative pretraining in MLLMs creates a latent binding across modalities, which can be efficiently unlocked via language-centric CL.
Language-Centric Omnimodal Representation Learning (LCO-Emb)
Building on these insights, the LCO-Emb framework is proposed. It leverages LoRA-based parameter-efficient fine-tuning of the language decoder using only text pairs, while freezing modality encoders and projectors. This approach preserves the generative capabilities and latent cross-modal alignment of the backbone MLLM, treating CL as a lightweight activation mechanism rather than a source of new knowledge.
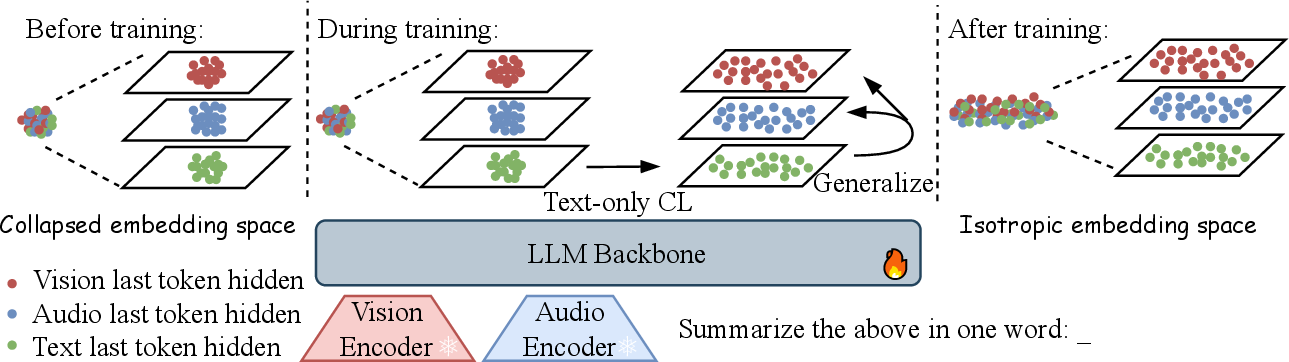
Figure 2: Text-only CL disperses textual representations and generalizes to reduce anisotropy in non-textual modalities, demonstrating the power of language-centric omnimodal representation learning.
Minimal additional multimodal paired data can be incorporated to calibrate the embedding space for specific downstream tasks, but the core representational gains are achieved via text-only CL. This paradigm sharply contrasts with CLIP-style models, which require large-scale multimodal data and intensive CL for alignment.
Experimental Results and Benchmarking
Extensive experiments are conducted on diverse backbones (LLaVA-Next, Qwen2.5-VL, Qwen2.5-Omni) and benchmarks (MIEB-Lite, AudioCaps, Clotho, MSR-VTT, ActivityNet). LCO-Emb consistently outperforms state-of-the-art open-source and proprietary embedding models, including those trained on much larger multimodal datasets.
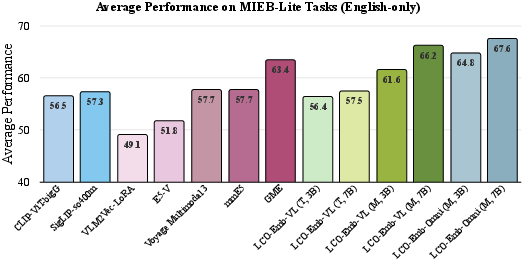
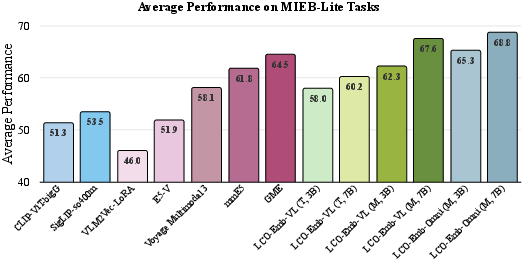
Figure 3: LCO-Emb achieves superior average performance on MIEB-Lite compared to leading open-source and proprietary models, with both text-only and multimodal variants.
Ablation studies show that LoRA-based CL yields better results than full fine-tuning or shallow projection, with significantly lower computational cost and minimal disruption to pretrained knowledge. Model ensembling via "model soup" further integrates complementary strengths from different fine-tuning datasets.
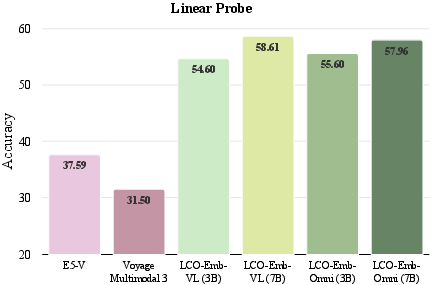
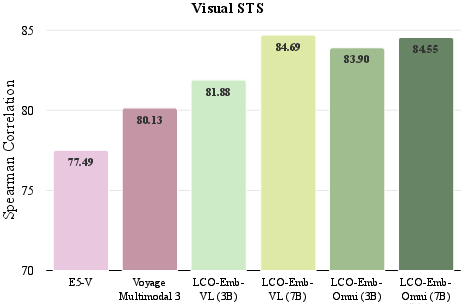
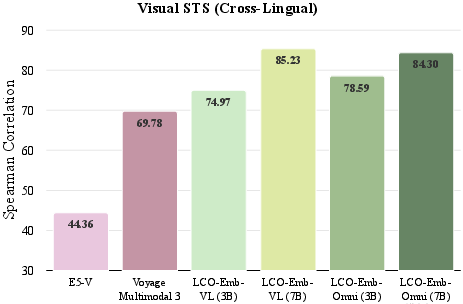
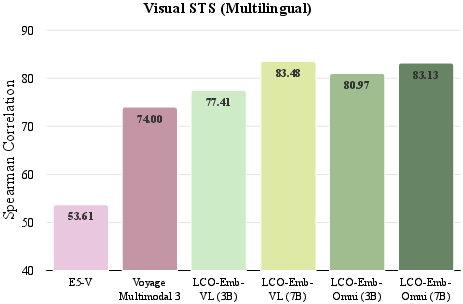
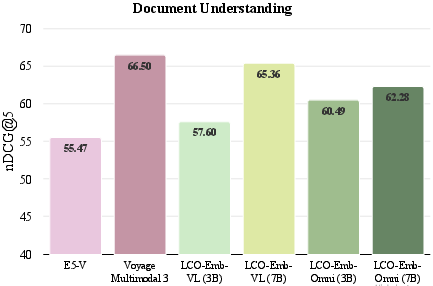
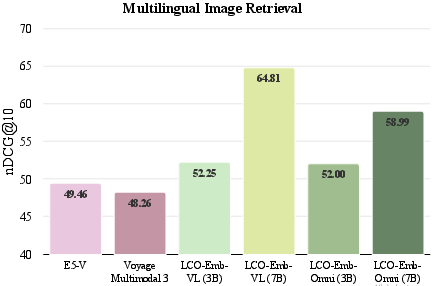
Figure 4: Ablation comparison of LCO-Emb text-only variants against advanced baselines on MIEB-Sub18, highlighting robust gains across challenging tasks.
Generation-Representation Scaling Law (GRSL)
A key contribution is the identification and formalization of the GRSL: the representational capabilities of MLLMs after CL scale positively with their generative capabilities prior to CL. Empirical analysis across OCR-based image-text, video-text, and audio-text tasks demonstrates a strong correlation between generative and representational performance.
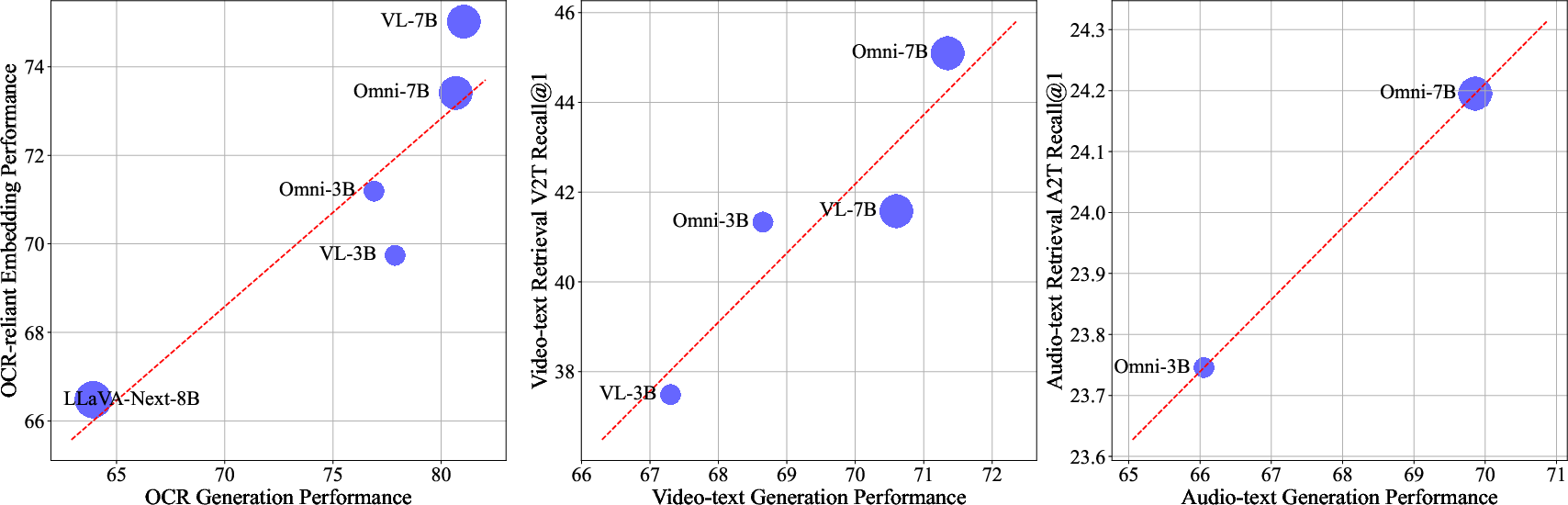
Figure 5: Positive scaling relationship between generation benchmark performance and representation benchmark performance after language-centric CL.
Theoretical justification is provided via a PAC-Bayesian generalization bound, showing that the mutual information captured by the generative prior sets an upper bound on achievable representation quality. The use of parameter-efficient methods like LoRA is theoretically optimal, as it minimizes the KL divergence from the prior, preserving the benefits of generative pretraining.
Practical Implications and Future Directions
The findings have direct implications for the design and scaling of universal embedding models:
- Contrastive learning should be viewed as a lightweight refinement stage for MLLMs, not as the primary mechanism for cross-modal alignment.
- Scaling generative pretraining (model size, data diversity, modality coverage) is the most effective strategy for improving downstream representation quality.
- Parameter-efficient fine-tuning (e.g., LoRA) is preferred to preserve latent alignment and generative capabilities.
- Minimal multimodal data can be used for task-specific calibration, but large-scale multimodal CL is not required.
The work also highlights limitations and future directions, such as joint training of generative and contrastive objectives, which may further enhance representation quality but at higher computational cost.
Conclusion
This paper redefines the paradigm of multimodal representation learning by demonstrating that generative pretraining in MLLMs establishes a latent cross-modal alignment, which can be efficiently activated via language-centric contrastive learning. The Generation-Representation Scaling Law provides a principled framework for scaling representation quality with generative capacity. The LCO-Emb framework achieves state-of-the-art results across modalities and tasks, with strong theoretical and empirical support. These insights position generative pretraining as the central driver of scalable, efficient, and robust omnimodal representation learning, with significant implications for future research and deployment of universal embedding models.