- The paper demonstrates that token merging via semantic clustering outperforms token pruning in reducing patch-level embeddings with minimal loss in retrieval accuracy.
- Fine-tuning post-merging is shown to recover accuracy losses even at high merging ratios, preserving over 94% of the original NDCG@5 score.
- The proposed Light-ColPali/ColQwen2 model offers a practical solution for memory-efficient visual document retrieval, balancing efficiency and precision for scalable deployment.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Introduction
Visual Document Retrieval (VDR) employs LVLMs to encode documents as image embeddings, eliminating the need for traditional OCR-based text parsing. This approach captures rich visual features, including layout and typography, enhancing retrieval accuracy. ColPali/ColQwen2 represents a state-of-the-art model in this domain, characterized by its use of numerous patch-level embeddings per document page to achieve high precision. However, this results in substantial memory consumption, posing challenges for scalability and deployment. The paper "Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings" (2506.04997) seeks to optimize VDR by reducing the number of patch-level embeddings without significant performance degradation.
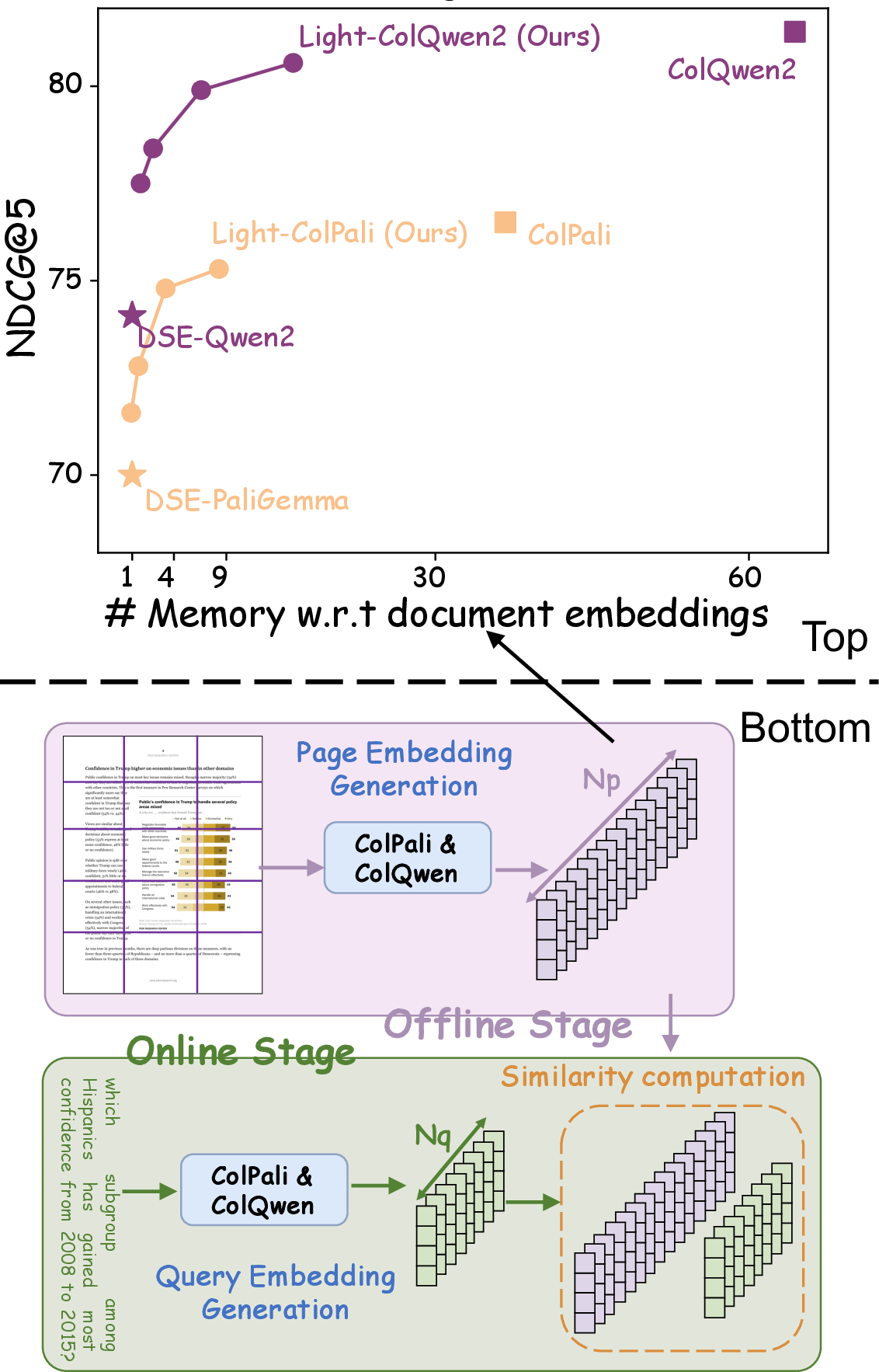
Figure 1: Top: The relative memory consumptions for embedding storage of different VDRs. Our simple yet effective approach, Light-ColPali/ColQwen2, retains most of the performance but with significantly reduced memory cost. Bottom: The diagram of VDR equipped with ColPali/ColQwen2 retriever. It encodes each page into Np patch-level embeddings and thus incurs prohibitive memory cost.
Token Pruning: An Ineffective Strategy
The paper evaluates token pruning as a strategy to reduce memory usage in VDR systems. Various pruning approaches are assessed, including random and more systematic score-oriented and attention-oriented methods. It was found that random pruning, unexpectedly, outperformed others when significant token reduction was required. Pruning tends to falter because the relevance of each patch embedding is highly query-dependent—information unavailable at the offline indexing stage—making preemptive pruning decisions ineffective.
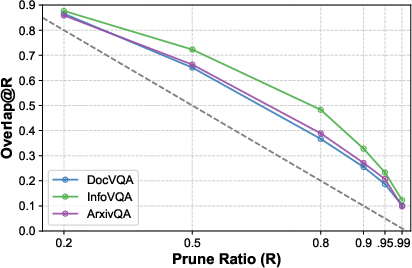

Figure 2: The activated patches overlap of two queries under different pruning ratios.
Token Merging: The Choices
The study shifts focus to token merging, a more viable strategy for reducing the number of embeddings. Merging consolidates multiple patch embeddings into fewer representations, retaining essential information while drastically cutting memory requirements. Three merging strategies—1D spatial pooling, 2D spatial pooling, and semantic clustering—were explored. Semantic clustering exhibited superior performance across datasets, maintaining retrieval precision even at high merging factors.
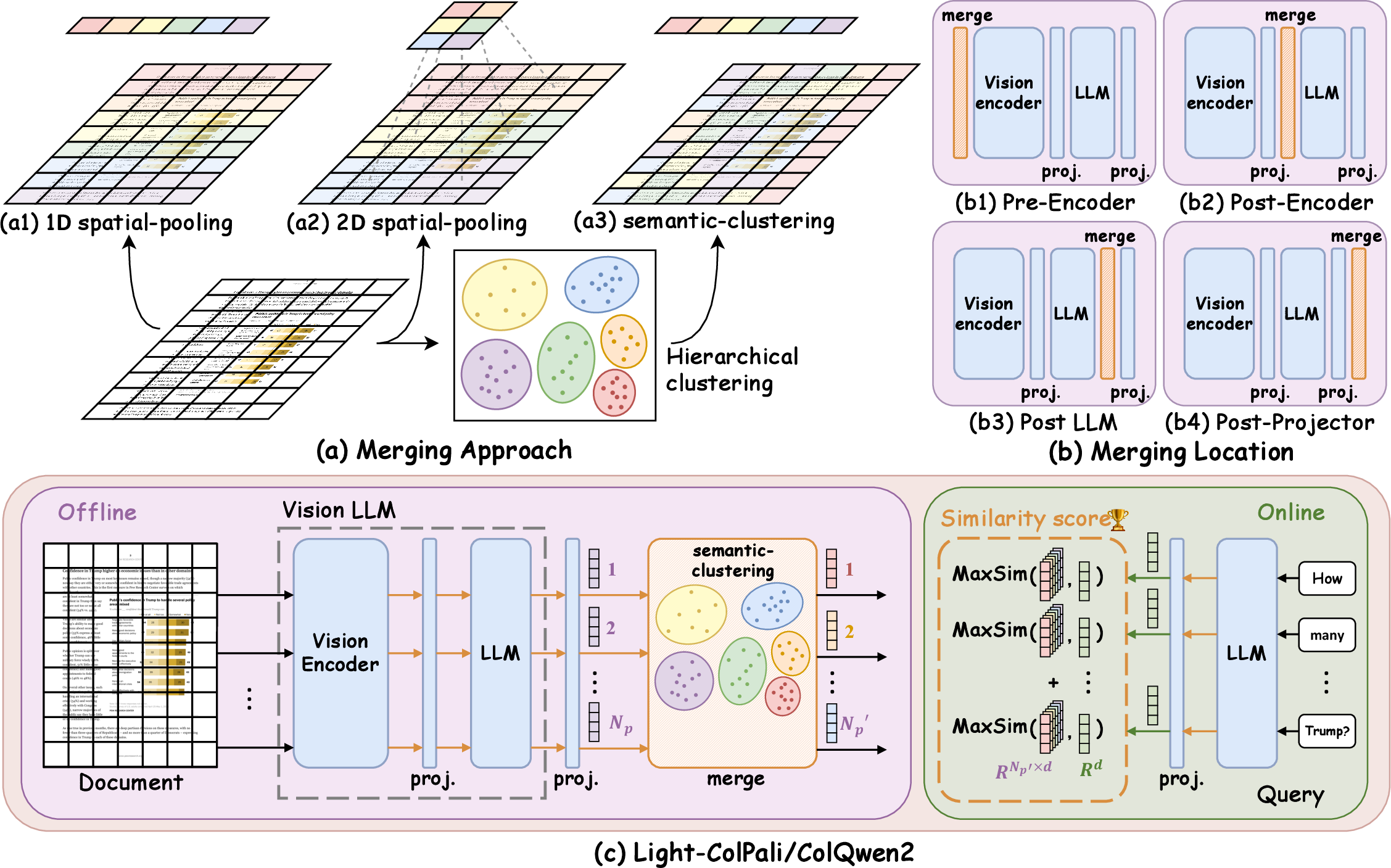
Figure 3: (a): Three merging approaches. The patches with the same colors are merged into the same embedding. (b): Three merging locations. Blue blocks represent the original modules in ColPali/ColQwen2. Orange blocks represent the added merging modules. (c): The architecture diagram of Light-Colpali/ColQwen2.
Fine-tuning the retriever post-merging proved essential for maintaining retrieval performance at extreme merging ratios, showcasing significant recovery of accuracy loss.
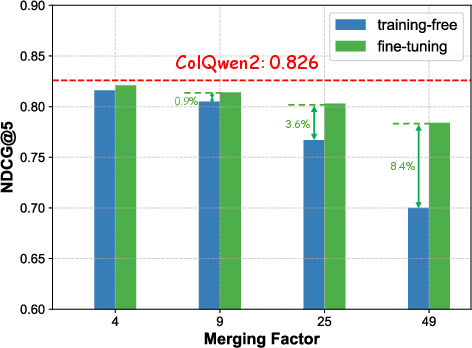
Figure 4: Training-free v.s. fine-tuning retriever with the same merging (clustering) approach. The performance of original ColQwen2 is highlighted in red dash.
Light-ColPali/ColQwen2: A Practical Solution
The paper introduces Light-ColPali/ColQwen2, a strategy integrating semantic clustering, late-stage merging, and fine-tuning. This approach achieves substantial memory efficiency while preserving retrieval effectiveness, offering a competitive baseline for efficient VDR systems.
The empirical evaluations demonstrate that Light-ColPali/ColQwen2 retains over 94% of original NDCG@5 scores at extremely low memory costs. This advancement underscores its suitability for deployment in memory-constrained environments, balancing efficiency and precision.
Conclusion
The paper presents a comprehensive exploration of storage-efficient VDR strategies, with clear evidence that token merging, particularly semantic clustering, provides a practical path forward. By establishing Light-ColPali/ColQwen2 as a benchmark for low-memory VDR solutions, the study contributes valuable insights to the pursuit of scalable and efficient retrieval systems. Future research may investigate adaptive merging strategies to further balance retrieval performance against memory constraints in variable document contexts.