- The paper presents a novel 2B-parameter model that combines hierarchical multimodal compression and a streaming abstention mechanism to handle long documents efficiently.
- It leverages a fixed per-page token budget to achieve up to 5.6× compression while maintaining constant GPU memory usage even for documents up to 120 pages.
- Empirical results demonstrate significant accuracy and latency improvements over existing LVLMs, enabling scalable document QA on resource-constrained devices.
DocSLM: Efficient Small-Scale Vision-Language Modeling for Long Multimodal Documents
Overview and Motivation
"DocSLM: A Small Vision-LLM for Long Multimodal Document Understanding" (2511.11313) addresses the prohibitive memory and compute requirements of LVLMs in long, complex document understanding. While state-of-the-art LVLMs exhibit strong multimodal reasoning, their high parameter count and dense tokenization render them impractical for real-time deployment on resource-constrained devices. DocSLM is a 2B-parameter model that employs architectural innovations—hierarchical multimodal compression and streaming abstention—to yield efficient long-context multimodal reasoning at a fraction of the memory and latency cost associated with large models and RAG systems.
Model Architecture and Key Techniques
DocSLM’s design is centered around two major contributions: (1) hierarchical multimodal compression and (2) streaming abstention. These combine to provide both per-page and document-level scalability.
Hierarchical Multimodal Compression
This module jointly encodes visual (global/local), textual (OCR), and layout cues per document page into a fixed-length token sequence (576 tokens per page), achieving an input compression ratio of up to 5.6× relative to dense tokenization, without sacrificing fine-grained semantics.
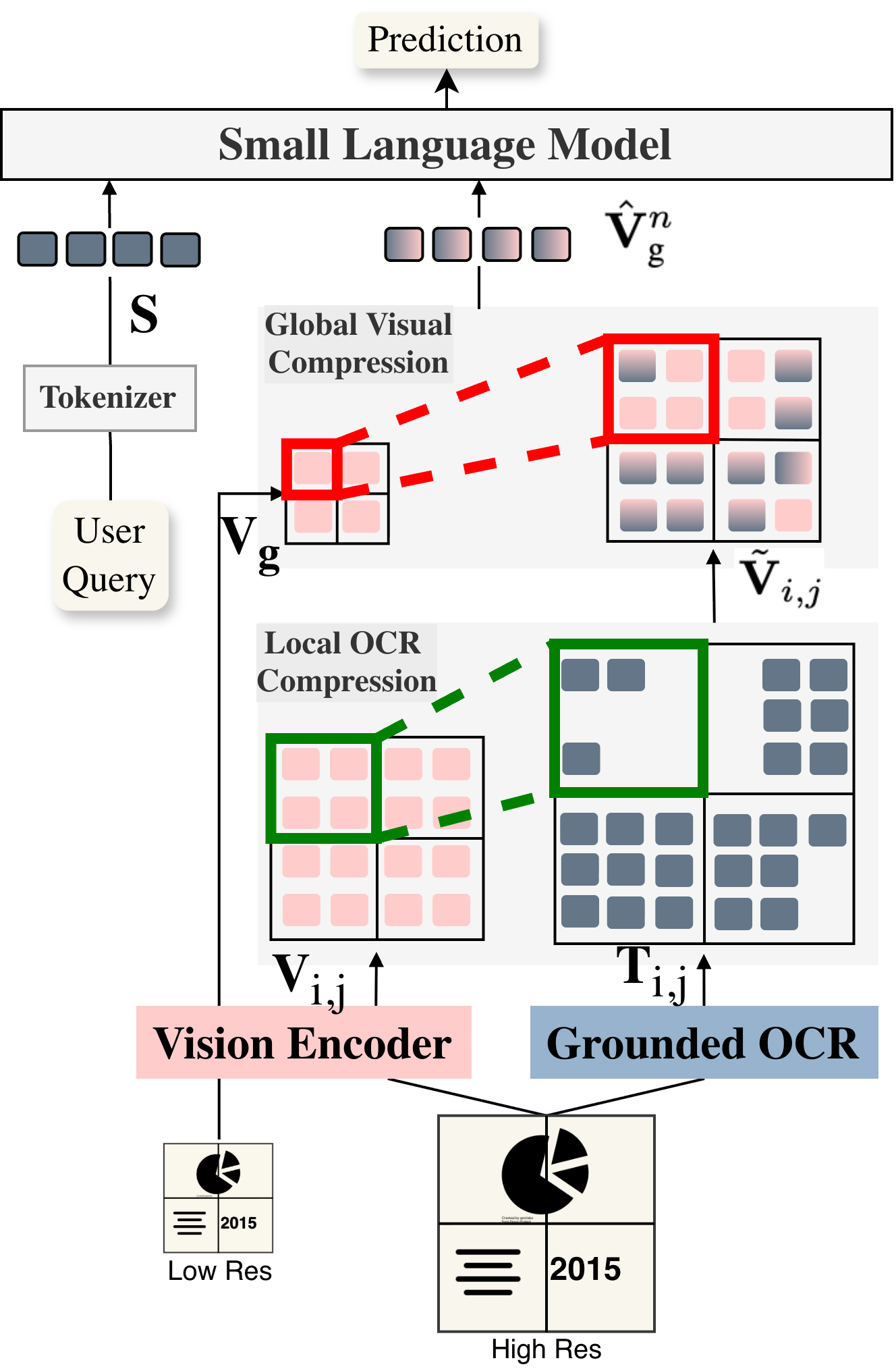
Figure 1: Hierarchical Multimodal Compressor captures both local OCR-fused region features and global visual context for each page.
The hierarchical compressor first fuses visual crops with region-aligned OCR tokens via localized cross-attention. The result—a set of spatially enriched visual-text features—is further aggregated via another cross-attention stage that compresses all local context into a compact, structurally rich representation. This approach eliminates uncontrolled token growth with rising page count or OCR density, ensuring input dimension invariance independent of document length or complexity.
Streaming Abstention Mechanism
Traditional VLMs and even many SVLMs cannot process long multi-page (tens to hundreds of pages) documents in a single pass due to linear growth in compute and memory, even after compression. DocSLM circumvents this by segment-wise processing: the input document is partitioned into manageable segments, and each is processed independently to yield both a prediction and a calibrated uncertainty estimate. A lightweight uncertainty calibrator then aggregates these segment outputs, emitting the final answer with minimal memory footprint.
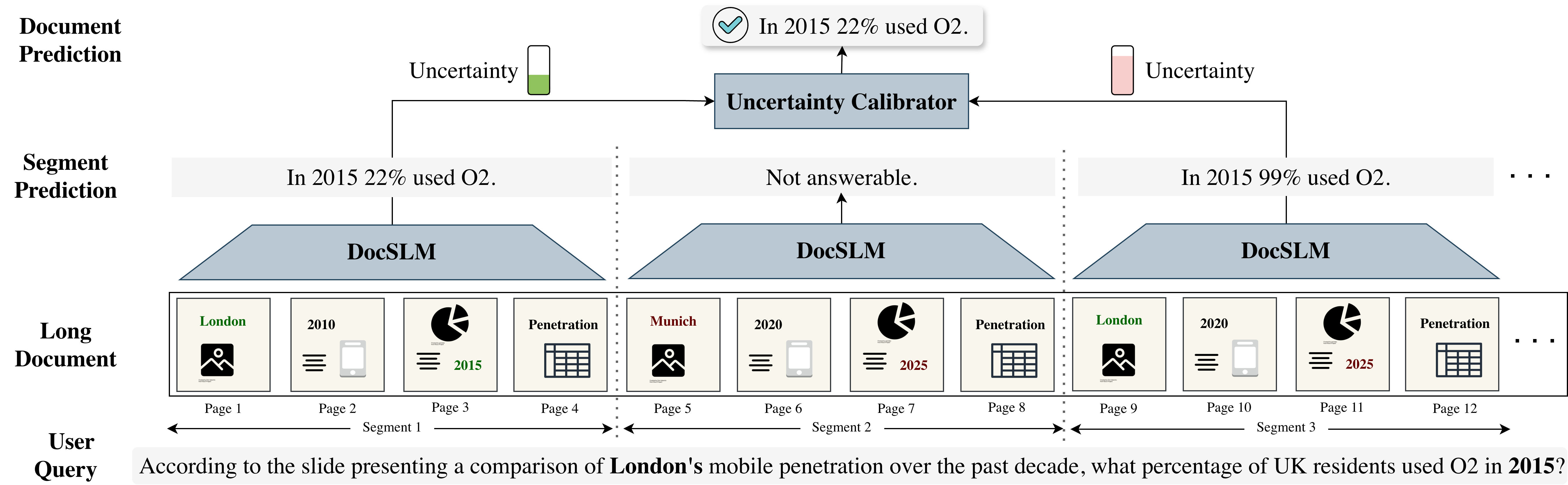
Figure 2: Streaming Abstention divides long documents into independent segments, producing predictions with calibrated uncertainty and maintaining constant memory.
This streaming protocol—unique in SVLM-based document QA—facilitates fixed-peak memory inference over arbitrarily long documents (demonstrably up to 120 pages), with constant GPU memory usage (~14GB plateau).
Empirical Results and Comparative Analysis
In benchmarks spanning long document QA (MMLongDoc, MP-DocVQA, DUDE, NewsVQA), DocSLM achieves a +9.3% accuracy improvement over DocOwl2 at equivalent token budgets and outperforms the comparably-sized Docopilot-2B by 0.9 percentage points, while using 82% fewer visual tokens and 75% fewer parameters than leading LVLMs and RAG models. Against large RAG-augmented baselines, DocSLM delivers 3.5× reduction in inference latency (32.1 ms vs. 113.4 ms).
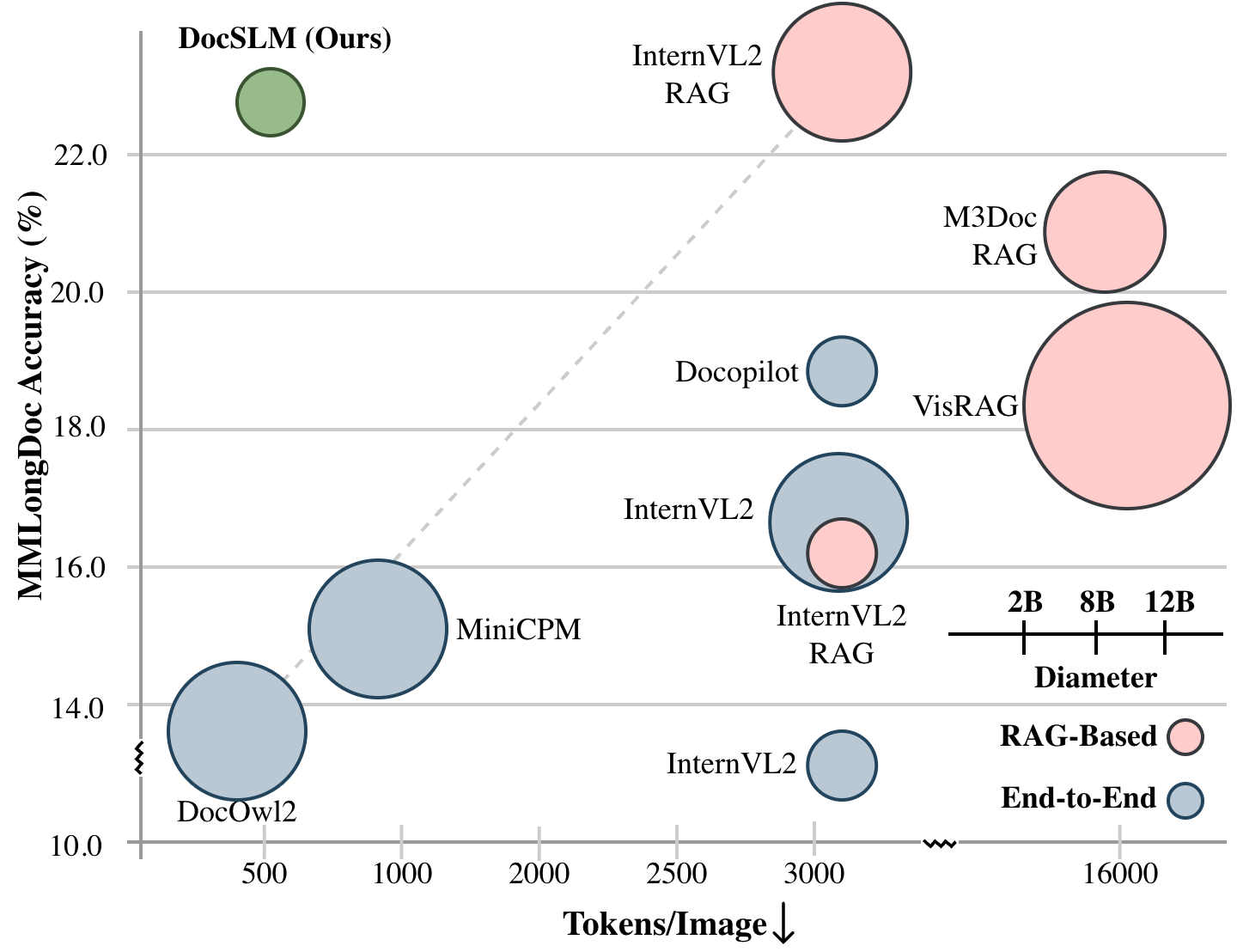
Figure 3: On MMLongDoc, DocSLM achieves superior accuracy-token efficiency trade-off, outperforming both large RAG and compact models.
Moreover, DocSLM generalizes robustly: despite primary training on documents, it achieves state-of-the-art ANLS (66.2) on NewsVideoQA, surpassing larger multimodal models and underscoring multimodal transfer in lightweight architectures.
Figure 4: DocSLM’s peak GPU memory does not increase with document length beyond 10 pages due to its segment-wise streaming mechanism.
Ablative and Qualitative Analysis
DocSLM’s compression pipeline is extensively ablated. Removing OCR supervision causes >30% relative loss on text-heavy document QA. Aggressive visual token reduction alone degrades performance, but fusing with hierarchical OCR compression and enabling streaming abstention maximizes efficiency-accuracy tradeoff.
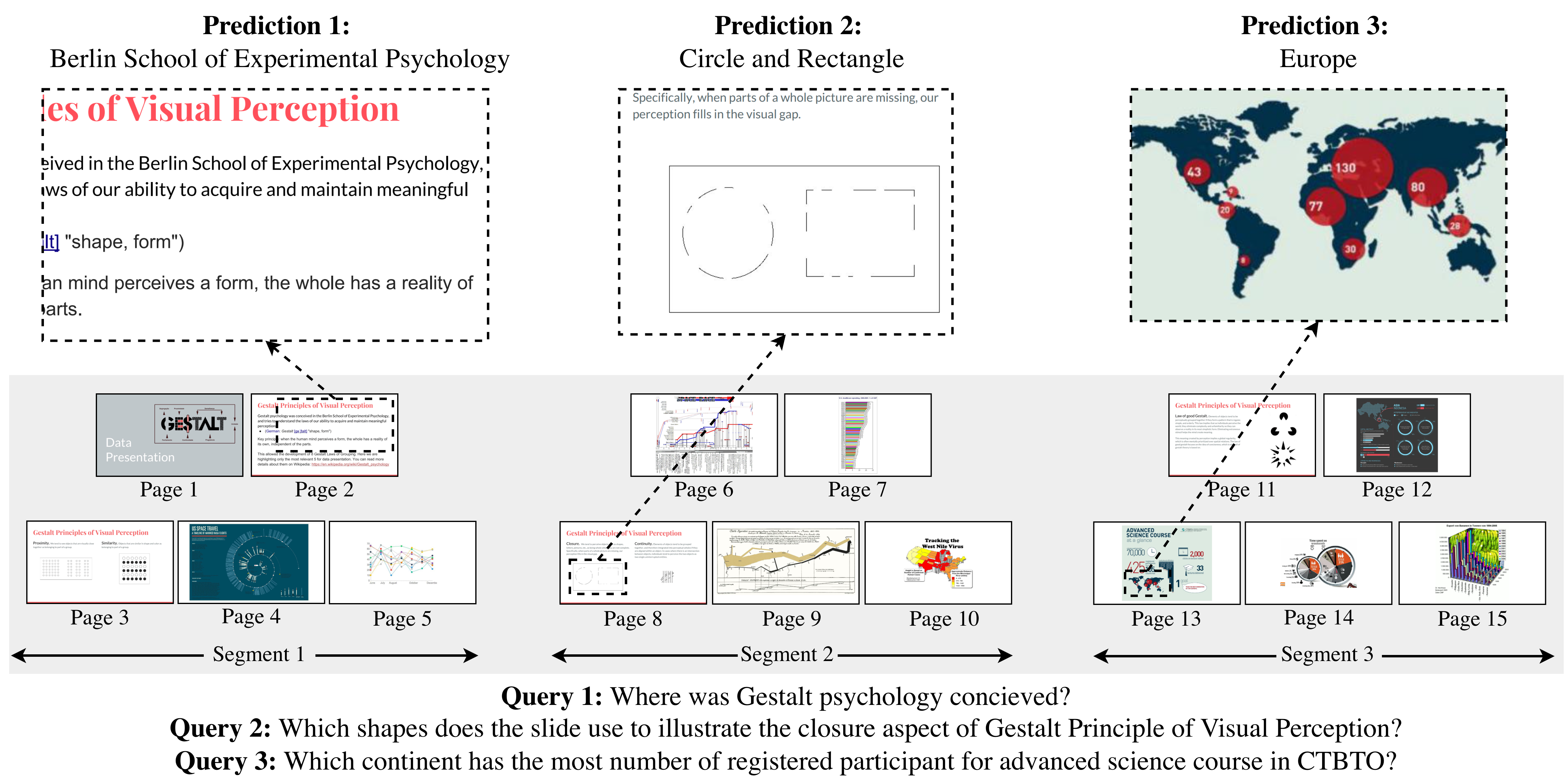
Figure 5: DocSLM localizes relevant segments and fuses OCR and visual cues, accurately answering over text, figures, and compound layouts.
Qualitative analysis shows the model precisely grounding answers in multimodal context—e.g., extracting institution names from text, inferring shapes from figures, and combining map layouts with numeric cues.
Practical and Theoretical Implications
DocSLM demonstrates that long-context multimodal understanding does not require large parameter or input footprints when efficient architecture and uncertainty-calibrated streaming are deployed. This establishes a paradigm for scalable document-level multimodal QA on edge devices, lowering the resource barrier for real-world interactive applications in finance, industry, and education.
Theoretically, the work motivates investigation into the trade-off boundaries for small-parameter, constant-token models versus more conventional large-scale/long-context approaches. The streaming abstention mechanism offers a principled framework for uncertainty aggregation in sequential reasoning tasks, suitable for extension beyond document QA to video, dialog, and multimodal retrieval.
Future Directions
Potential extensions include broadening the omnimodal scope (audio, tables, interactive PDFs), document-video co-training, and tighter integration of memory-efficient streaming with hierarchical attention-based architectures. The successful calibration of abstention suggests further research in reliability and fail-soft mechanisms for safety in production VLM systems.
Conclusion
DocSLM (2511.11313) establishes a scalable approach for long-document multimodal understanding that operates under stringent memory and compute budgets, leveraging hierarchical multimodal compression and streaming abstention to match or exceed the accuracy of SOTA large and small VLMs while dramatically reducing latency and memory use. The modular design signals an important step toward ubiquitous edge deployment of robust multimodal inference.