ModernVBERT: Towards Smaller Visual Document Retrievers
Abstract: Multimodal embedding models are gaining prevalence, notably for document retrieval as efficient alternatives to text-only pipelines. These models are typically built by finetuning large vision-language decoders (VLMs) with contrastive losses on text-image pairs. In this work, we show that, while cost-efficient, this repurposing approach often bottlenecks retrieval performance. Through controlled experiments, we establish a principled recipe for improving visual document retrieval models. We notably measure the impact of attention masking, image resolution, modality alignment data regimes, and late interaction centered contrastive objectives which emerge as central performance factors. Building on these insights, we release ModernVBERT, a compact 250M-parameter vision-language encoder that outperforms models up to 10 times larger when finetuned on document retrieval tasks. Models and code are made available at https://huggingface.co/ModernVBERT.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Sure! Let’s break this academic paper down into simpler terms for a 14-year-old.
Overview of the Paper
This paper is about improving how computers find and understand documents that mix pictures and text. Imagine needing to quickly find a specific picture inside a book or online article; these improvements help make that process faster and better.
Key Objectives or Research Questions
The researchers wanted to answer the question: "How can we make computer models that search for visual documents better and quicker?" They explored different techniques to help the computer models understand documents with both images and text in them more effectively.
Research Methods or Approach
The researchers used special computer models called "multimodal models." These models were trained to look at images and text together, like how you would look at pages in a comic book. They designed the models to pay attention to the most important parts of both pictures and text to recognize patterns. It's kind of like creating a puzzle-solving robot that finds clues from both pictures and words.
Main Findings or Results
They developed a computer model called ModernVBERT that is much smaller, but works better than bigger models that search for pictures and text. The paper proved that focusing on smaller models with smart strategies can outperform larger, bulky ones. Think of it like using a smart phone to do tasks usually done by a big computer – and being surprisingly good at it!
Implications and Impact
This research helps make it easier and faster to find information in digital documents, which can be useful for creating better libraries of digital books and articles. It's important because it saves time and computing power, making digital information more accessible. Imagine wanting to quickly find the exact comic book panel you love using your phone – this research helps make that possible!
I hope this makes the paper clearer and more relatable to you!
Knowledge Gaps
Unresolved Gaps and Open Questions
Below is a single, consolidated list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is framed to be concrete and actionable for future research.
- Scaling laws: Do the observed benefits of bidirectional attention and late interaction persist or change at larger parameter counts (e.g., 1B–10B encoders), and what are the scaling breakpoints?
- Multilinguality: How does allocating parameters to additional languages affect visual understanding and English retrieval performance; what is the optimal language mix for multilingual document retrieval?
- Natural-image trade-offs: Can early-fusion, bidirectional models be trained to avoid the documented degradation on natural image retrieval/classification (e.g., through multi-head training, modality-specific adapters, or joint losses)?
- OCR integration: What is the incremental benefit of incorporating explicit OCR tokens or layout-aware features (e.g., 2D positional embeddings, detected text boxes) alongside the current OCR-free approach?
- Document robustness: How robust is the model to real-world document noise (low DPI, compression artefacts), skew/rotation, handwriting, non-Latin scripts, stamps, and multi-language documents?
- Multi-page retrieval: How should multi-page documents be represented, indexed, and matched (page-level vs. document-level embeddings; hierarchical late interaction) without sacrificing latency and memory?
- Index/storage cost analysis: What are the end-to-end storage and retrieval trade-offs of late interaction (token count per document, quantization/pruning thresholds) for ModernVBERT, and how do these compare to dual encoders?
- End-to-end latency: Beyond query encoding on CPU, what is the full pipeline latency (ANN search, MaxSim matching, I/O, batching) and how does it scale with corpus size and token pruning?
- Late interaction variants: How do alternative multi-vector scoring mechanisms (e.g., SoftMaxSim, Matryoshka losses, learned token pooling) compare to MaxSim for bidirectional encoders?
- Similarity function choices: For single-vector bidirectional models, is mean pooling optimal versus [CLS]-like tokens, attention pooling, or gated pooling—especially under long sequences?
- Converting decoders: Is there a training schedule (duration, annealing strategy, data scale) that reliably converts causal decoders into competitive late-interaction retrievers, and what are the minimal requirements?
- Resolution policy: What is the optimal resolution curriculum (cooldown length, schedule, multi-resolution mixing) and inference-time resolution policy to balance compute, token length, and retrieval gains?
- Patch and pixel-shuffle design: How do patch size, patch overlap, pixel-shuffle ratio, and the inclusion of a downscaled global image affect retrieval quality and speed under different domains?
- Vision tower finetuning: To what extent should the vision tower be finetuned during modality alignment vs. contrastive stages (fully frozen, LoRA, partial unfreeze), and how does this impact stability and performance?
- Masking hyperparameters: What are the optimal MLM masking ratios, patterns (span masking vs. random), and prompt-masking strategies for modality alignment in document-centric tasks?
- Negative sampling: How do different hard-negative mining strategies (offline mined vs. in-batch vs. periodic refresh) and counts affect convergence and retrieval quality across domains?
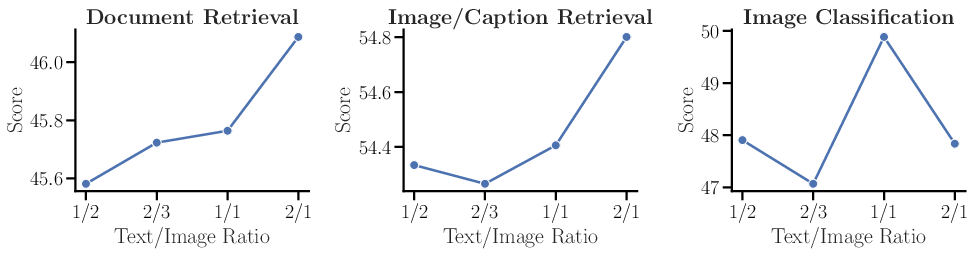
- Contrastive mix ratios: What is the optimal text-only vs. text–image ratio, and does it depend on the domain (forms, tables, scans, scientific PDFs); is curriculum mixing (phased schedules) superior to fixed ratios?
- Data quality and noise: How sensitive is contrastive performance to label noise and query quality in synthetic document-query pairs; what automatic filtering or reweighting techniques most improve signal?
- Domain coverage: Does the model generalize to underrepresented document types (e.g., forms with complex layouts, financial statements, medical records) and what dataset components or augmentations are missing?
- Generalization and robustness: How does performance hold under distribution shift (new fonts, unseen templates, cross-device scans) and adversarial cases (watermarks, occlusions, adversarial typography)?
- Bias and fairness: What biases (language, domain, region) exist in the alignment and contrastive corpora; how do these manifest in retrieval outcomes, and what mitigation strategies are effective?
- Interpretability: Which token-level interactions (visual/text) actually drive retrieval decisions; can saliency or alignment maps guide data curation or model improvements?
- Architecture alternatives: How do early fusion encoders compare to hybrid designs (dual encoders plus lightweight cross-attention re-ranking, or retrieval-augmented fusion) in performance–latency trade-offs?
- Long-sequence handling: What are the memory/time trade-offs and retrieval gains when scaling sequence lengths (documents with many tokens/pages), and which pruning/segmentation strategies are best?
- Training stability: Are there failure modes (representation collapse, overfitting to chat templates) under extended MLM alignment; which regularization or adapters mitigate them?
- Additional objectives: Do auxiliary objectives (e.g., masked patch modeling, contrastive token alignment, generative pretraining) improve token-level alignment without harming retrieval latency?
- Cross-modal transfer mechanism: What mechanisms enable text-only pairs to improve visual document retrieval; can explicit alignment losses or distillation from text-only encoders amplify the transfer?
- Benchmark breadth: How does ModernVBERT perform on more diverse and non-English document retrieval benchmarks (e.g., multilingual ViDoRe, industry datasets), and what gaps remain?
- Failure analysis: What are the systematic error modes (e.g., layout confusions, figure/table misinterpretation), and which targeted data or model tweaks alleviate them?
- Reproducibility of data mixtures: How sensitive are results to the exact modality alignment and contrastive mixture composition; can standardized, open mixtures yield similar performance?
- Production deployment: What are the operational considerations (index build/update costs, memory footprint at scale, throughput under real workloads) and recommended configurations for practitioners?
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using the released ModernVBERT models and code, benefiting from CPU-friendly query encoding, late interaction retrieval, and strong visual document understanding.
Industry
- OCR-free enterprise document search (finance, legal, insurance)
- Use case: High-accuracy retrieval over scanned PDFs, contracts, invoices, forms, and compliance reports without relying on OCR pipelines.
- Sector: Finance, Legal, Insurance, Compliance.
- Tools/products/workflows: Deploy
ColModernVBERTwith a ColBERT-style late interaction index in FAISS/Milvus/Vespa; ingest high-resolution pages (up to 2048 px), patch at 512×512, store multi-vector embeddings; integrate with existing document management/RAG systems. - Assumptions/dependencies: English-only model; multi-vector storage budget; high-quality scans; domain adaptation via contrastive tuning may be needed.
- eDiscovery and due diligence
- Use case: Identify relevant clauses, exhibits, or case-specific materials across large legal repositories faster and more precisely than text-only retrievers.
- Sector: Legal, Compliance.
- Tools/products/workflows: Side-by-side run with baseline text retrievers; CPU query encoding for rapid triage; result reranking via late interaction MaxSim; audit logs for case teams.
- Assumptions/dependencies: Sufficient storage for multi-token indexes; secure on-prem deployment; adherence to chain-of-custody and access control policies.
- Customer support knowledge base search (manuals, datasheets, troubleshooting guides)
- Use case: Improve “findability” of procedures and diagrams embedded in PDFs and product docs to reduce average handling time.
- Sector: Software/Hardware Support, Telco, Consumer Electronics.
- Tools/products/workflows: Replace CLIP-like dual encoders with
ColModernVBERTin RAG backends; CPU-friendly query encoding for agent desktops; mixed text-only pairs used in domain tuning to cover scarce doc-image pairs. - Assumptions/dependencies: Curated contrastive corpus (text-only + doc-image pairs); multi-vector index maintenance; versioning of technical manuals.
- Insurance claims triage
- Use case: Retrieve relevant sections across multi-page forms, receipts, medical reports, photos of paperwork to accelerate adjudication.
- Sector: Insurance.
- Tools/products/workflows: Batch indexing of documents on GPU; live CPU query encoding; integrate with claims systems; filter via late interaction to surface the most relevant page/region.
- Assumptions/dependencies: High-resolution capture; storage overhead for per-token embeddings; domain-specific negative sampling for robust contrastive training.
- Developer documentation and UI artifact search
- Use case: Find relevant API examples, configuration tables, or UI screenshots embedded in manuals and issue trackers.
- Sector: Software Engineering.
- Tools/products/workflows:
ColModernVBERTas the retriever in dev portals; patch-based index of PDFs and wiki pages; CPU inference for local developer machines. - Assumptions/dependencies: English content; multi-vector index backing store; optional domain fine-tuning with text-only corpora.
Academia
- Library and archive retrieval over scanned books and historical documents
- Use case: Precise retrieval for researchers across digitized archives, page scans, marginalia, and complex layouts.
- Sector: Digital Libraries, Digital Humanities.
- Tools/products/workflows: Build page-level late interaction indexes; integrate with catalog systems; add text-only corpora to contrastive mix to exploit limited annotated doc-image pairs.
- Assumptions/dependencies: Archival-quality scans; storage planning; ethical and legal use of collections.
- Scientific paper search with figure/table-aware retrieval
- Use case: Retrieve methods or results sections, tables, and figures embedded within PDFs more reliably than text-only embeddings.
- Sector: Research Institutions, University Libraries.
- Tools/products/workflows:
BiModernVBERTfor single-vector budget-constrained scenarios;ColModernVBERTwhere precision is critical; RAG integration for literature assistants. - Assumptions/dependencies: Document segmentation quality; heterogeneous layouts; CPU inference for researcher laptops.
Policy and Public Sector
- Open government records and FOIA search
- Use case: Improve citizen and journalist access to scanned court records, permits, meeting minutes, and forms.
- Sector: Government, Public Administration.
- Tools/products/workflows: Deploy CPU query encoding on budget-constrained infrastructure; late interaction retrieval for complex multi-page docs; role-based access governance.
- Assumptions/dependencies: Storage capacity for multi-vector indices; adherence to privacy and retention policies; English bias in current release.
- Compliance audit portals
- Use case: Rapid retrieval of relevant regulatory clauses and evidentiary documents across large repositories.
- Sector: Regulatory Agencies, Internal Audit.
- Tools/products/workflows:
ColModernVBERTin audit dashboards; patch tiling for high-resolution pages; mix text-only regulatory corpora into the contrastive training set to improve domain specificity. - Assumptions/dependencies: Quality of curated text-only corpora; secure deployment; auditability requirements.
Daily Life
- Personal knowledge management (PKM) for receipts, bills, and notes
- Use case: Search your scanned paperwork, whiteboard photos, and lecture notes without OCR configuration.
- Sector: Consumer productivity.
- Tools/products/workflows: Local desktop app using
BiModernVBERTfor smaller footprint orColModernVBERTfor precision; CPU-only inference; lightweight vector store. - Assumptions/dependencies: Storage for multi-vector indexes; English content; simple ingestion pipelines.
- Education: Course material search (slides, assignments, handouts)
- Use case: Students and educators search across PDF slides, handouts with diagrams, and annotated homework.
- Sector: EdTech.
- Tools/products/workflows: School LMS integration; CPU-based query services; late interaction for page-level relevance; optional fine-tuning with text-only materials.
- Assumptions/dependencies: Data privacy; storage allocation; English-only baseline.
Long-Term Applications
These use cases are feasible but benefit from further research and development, scaling, and/or domain adaptation—particularly in multilingual settings, token-level tasks, or new deployment form factors.
Industry
- Multilingual visual document retrieval for global enterprises
- Use case: Cross-language retrieval over international contracts, invoices, and forms.
- Sector: Multinational Finance, Legal, Supply Chain.
- Tools/products/workflows: Train multilingual
ModernVBERTvariants; expand modality alignment corpora; adopt mixed text-only pairs for low-resource languages. - Assumptions/dependencies: Multilingual training data; parameter budget trade-offs between language coverage and vision quality.
- Structured information extraction without OCR (visual NER, table/field extraction)
- Use case: Extract entities, table cells, and form fields directly from visual tokens, reducing OCR errors.
- Sector: Finance, Insurance, Logistics.
- Tools/products/workflows: Fine-tune modality-aligned encoders for token-level tasks (visual NER, token classification); integrate with form understanding pipelines.
- Assumptions/dependencies: Labeled token-level datasets; evaluation frameworks; specialized loss functions and UI for validation.
- High-throughput, low-carbon retrieval as a corporate sustainability initiative
- Use case: Replace billion-parameter models with compact encoders to reduce energy and hardware costs for search workloads.
- Sector: Cross-industry IT Operations.
- Tools/products/workflows: Fleet standardization on CPU-friendly encoders; storage optimization via quantization and token pruning; sustainability reporting tied to search infrastructure.
- Assumptions/dependencies: Organizational buy-in; performance baselines per domain; storage and latency SLAs.
Academia
- Document understanding benchmarks and reproducible pipelines
- Use case: Establish standardized, open pipelines for modality alignment, HR cooldown, and mixed contrastive training to study document understanding.
- Sector: ML Research.
- Tools/products/workflows: Research kits using the released code; controlled experiments on attention masks and late interaction; cross-domain data mixes.
- Assumptions/dependencies: Compute grants; shared datasets with clear licensing; community curation.
- OCR error detection and correction via token-level encoders
- Use case: Automatically detect likely OCR errors and propose corrections using contextual embeddings aligned with visual tokens.
- Sector: Digital Libraries, Humanities.
- Tools/products/workflows: Token-level classification heads; human-in-the-loop correction interfaces; comparison with traditional OCR post-processing.
- Assumptions/dependencies: Annotated error datasets; careful UI/UX for editors; multilingual support.
Policy and Public Sector
- National-scale searchable archives of scanned records
- Use case: Create accessible, high-fidelity search over court archives, land registries, and historical records.
- Sector: National Archives, Judiciary, Municipal Records.
- Tools/products/workflows: Multilingual expansion; late interaction storage optimization (quantization, pruning); public transparency dashboards and APIs.
- Assumptions/dependencies: Funding and storage provisioning; legal frameworks for public access; privacy-preserving indexing.
- Standards and best practices for low-cost, accessible retrieval
- Use case: Publish guidance on adopting compact multimodal retrievers to lower barriers for small agencies and NGOs.
- Sector: Government, NGOs.
- Tools/products/workflows: Reference architectures; training playbooks that leverage text-only corpora; procurement templates emphasizing energy and cost efficiency.
- Assumptions/dependencies: Policy coordination; open-source maintenance; inclusive language/data coverage.
Daily Life
- On-device, privacy-preserving document assistants
- Use case: Smartphone or laptop apps that index and search personal documents entirely offline.
- Sector: Consumer productivity, Privacy tech.
- Tools/products/workflows: Optimized
ModernVBERTvariants with quantized multi-vector storage; lightweight local vector stores; secure, encrypted indexes. - Assumptions/dependencies: Memory constraints; battery and CPU efficiency; mobile-friendly inference and indexing.
- Assistive tools for accessibility (reading assistance over scanned materials)
- Use case: Help users navigate complex documents (forms, brochures) by retrieving and highlighting relevant sections.
- Sector: Accessibility/Assistive Tech.
- Tools/products/workflows: Visual grounding and token-level alignment to guide screen readers; interactive highlighting and summarization via RAG.
- Assumptions/dependencies: Token-level models; UX research with accessibility communities; compliance with accessibility standards.
Cross-cutting Workflows and Products
- Domain adaptation via mixed-modality contrastive training
- Use case: Improve a retriever for a specific domain even when few document-image pairs exist by mixing text-only pairs and curated negatives.
- Sector: All.
- Tools/products/workflows: Training pipelines that interleave text-only pairs with doc-query pairs; hard negative mining; HR cooldown for domain scans.
- Assumptions/dependencies: Access to high-quality text-only corpora; careful batching and curation; data licensing compliance.
- RAG systems with document-aware retrieval
- Use case: Boost downstream generative QA by feeding LLMs higher-quality, layout-aware contexts retrieved from scanned PDFs.
- Sector: Enterprise AI, EdTech, Research Assistants.
- Tools/products/workflows: Swap retriever to
ColModernVBERT; maintain multi-vector indexes; page/region-level context selection; evaluation on domain tasks. - Assumptions/dependencies: LLM compatibility; context window constraints; guardrails for hallucination and bias.
- Vector database extensions for late interaction
- Use case: Provide production-grade support for multi-vector storage and MaxSim operations.
- Sector: Databases, MLOps.
- Tools/products/workflows: Plugins or native support in FAISS/Milvus/Vespa/OpenSearch; index compaction (quantization, token pruning); monitoring for storage/latency trade-offs.
- Assumptions/dependencies: Engineering effort; reliability and scalability testing; operator training.
Glossary
- Ablation: An experimental procedure where components or settings are systematically removed or altered to assess their impact. "Ablation Evaluation Setup"
- Annealing: Gradually modifying training conditions (e.g., masks or objectives) later in training to adapt model behavior. "dec-enc a causal decoder annealed over the end of its textual training by removing the causal mask and switching the training objective to MLM."
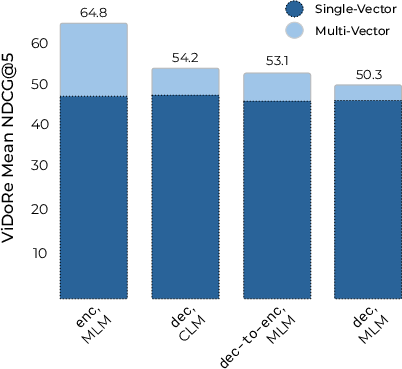
- Bidirectional attention: An attention mechanism where each token can attend to all other tokens in the sequence, not just previous ones. "A central point of interest is the impact of causal and bidirectional attention masks."
- Biphasic training: A two-stage training process, often involving an initial alignment phase followed by specialization. "We employ a standard biphasic training procedure,"
- Causal attention mask: An attention constraint that prevents a token from attending to future tokens, enforcing autoregressive prediction. "Typically, VLM-based encoders inherit the causal attention masks VLMs are trained with,"
- Causal Language Modeling (CLM): Training objective to predict the next token given all previous tokens in a sequence. "For decoder‑based models, we train with Causal Language Modeling (CLM) loss on the text tokens,"
- Contrastive learning: A learning paradigm that brings paired (positive) examples closer and pushes unpaired (negative) examples apart in embedding space. "we then rely on a second text-image contrastive learning phase to learn efficient image representations"
- Contrastive post-training: A training stage after initial alignment to refine embeddings using contrastive objectives. "we specialize models through a contrastive post-training stage"
- Dual encoder: A model architecture with separate encoders for two modalities (e.g., text and image) trained to align their embeddings. "contrastive pre-training of dual encoders, typically pairing a vision transformer (ViT) with a text encoder,"
- Early fusion: An architecture that concatenates visual and textual embeddings early so the model processes them jointly. "we employ the early fusion architecture"
- End-of-sequence (EOS) token: A special token indicating sequence termination, often used to extract representations in decoders. "We use the last (EOS) token for causal models,"
- Hard negatives: Challenging negative examples that are semantically close to the query, used to sharpen contrastive learning. "and use 1 hard negatives for each document-query pair and 2 for each text-only pairs."
- HR Cooldown: A late-phase training step emphasizing higher-resolution inputs to refine fine-grained perception. "HR Cooldown"
- In-batch negatives: Negative samples taken from other items within the same training batch. "in-batch and hard negatives when mentioned"
- InfoNCE loss: A popular contrastive loss that maximizes similarity of positive pairs against a set of negatives. "We employ the InfoNCE loss,"
- Late interaction: A retrieval scheme matching multiple query and document token embeddings at inference time for fine-grained alignment. "when used in late interaction settings,"
- Low-Rank Adapters (LoRA): Parameter-efficient modules that adapt pretrained models via low-rank updates without full fine-tuning. "Low-Rank Adapters (LoRA)"
- Masked Language Modeling (MLM): A denoising objective predicting masked tokens given their surrounding context. "by using the Masked Language Modeling (MLM) loss on the textual tokens:"
- Matrioshka losses: A family of objectives that produce compact, hierarchical multi-token representations. "the use of Matrioshka losses to compact multi-token representations"
- MaxSim: The operation that matches query and document tokens by taking maximal pairwise similarities in late interaction retrieval. "through the MaxSim operation"
- Mean pooling: Aggregating token representations by averaging them to form a single sequence embedding. "and mean pool all sequence tokens for bidirectional encoders"
- MIEB: A benchmark suite for evaluating image embedding models across diverse tasks. "by selecting tasks from MIEB"
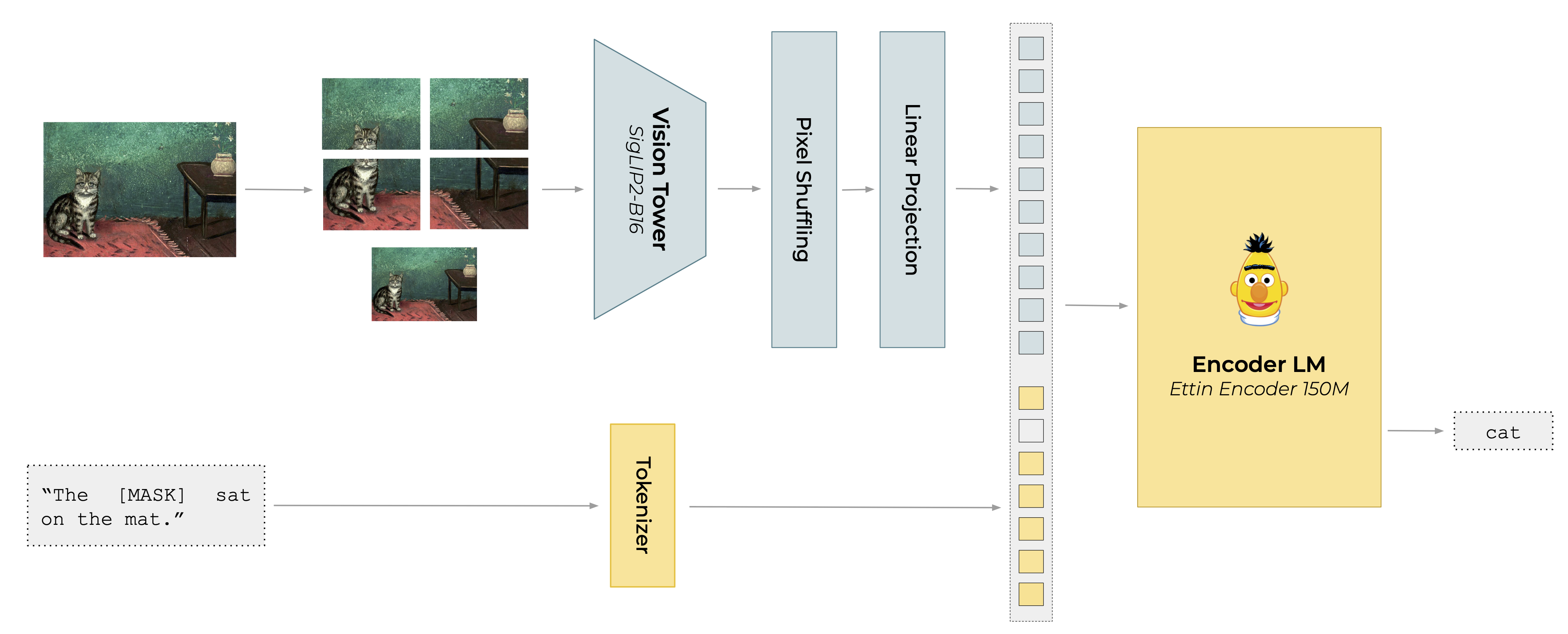
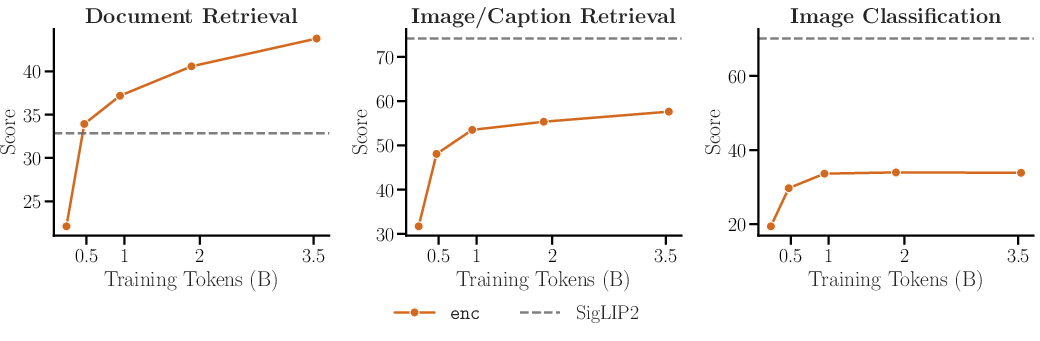
- Modality alignment: Training to align visual and textual representations into a shared space so the LLM can process image tokens. "We modality align both models with a MLM objective"
- nDCG@5: Normalized Discounted Cumulative Gain at rank 5; a ranking metric weighting relevant items by position. "benchmarks (nDCG@5)"
- Pareto efficiency: A performance–size trade-off frontier where improving one dimension worsens another. "Pareto efficiency."
- Pixel shuffling: A spatial rearrangement technique that trades resolution for channel depth to compress images efficiently. "we apply pixel shuffling with a ratio of ,"
- Quantization: Compressing model or index representations by reducing numerical precision to save storage and compute. "through quantization"
- SigLIP2: A vision-language pretraining family producing image encoders used as the visual tower. "siglip2-base-16b-512"
- Task-aware batching: Constructing batches with controlled similarity to provide informative negatives in contrastive learning. "We employ task-aware batching"
- Token pruning: Reducing the number of token embeddings stored or processed to improve efficiency. "token pruning"
- ViDoRe: A benchmark focused on visual document retrieval evaluation. "on ViDoRe, achieving a leading performance-size tradeoff."
- Vision Transformer (ViT): A transformer-based architecture for images using patch tokens and self-attention. "a vision transformer (ViT)"
- Vision-LLM (VLM): Models jointly trained on images and text to perform multimodal understanding or generation. "VLM-based encoders"
- WSD scheduler: A learning-rate schedule (Warmup–Stable–Decay) controlling optimization phases. "We employ WSD scheduler"
- Zero-shot: Evaluating a model on tasks without task-specific fine-tuning by relying on generalization. "we assess both zero-shot and fine-tuning abilities"
Collections
Sign up for free to add this paper to one or more collections.

