- The paper introduces a novel GeoAdapter that injects depth and camera modalities into alternating-attention blocks, boosting performance across 3D vision tasks.
- The method achieves significant improvements in depth estimation and camera pose prediction, with gains up to 99.9% accuracy on benchmarks and over 93% AUC in pose tasks.
- Stochastic fusion training enables robust spatial representations that flexibly adapt to missing inputs, enhancing applications in robotics and AR/VR.
Introduction
OmniVGGT introduces a spatial foundation model that generalizes across 3D vision tasks while accepting an arbitrary number of auxiliary geometric modalities (e.g., depth maps, camera intrinsics/extrinsics). Existing models in this domain typically constrain input to raw RGB images or, at most, two modalities, thus ignoring available spatial priors. OmniVGGT resolves this with a flexible input scheme and a highly modular injection architecture, realizing robust spatial representations for depth estimation, camera pose prediction, and scene-level 3D reconstruction. The paper additionally demonstrates the utility of OmniVGGT for vision-language-action (VLA) models applied in robotics.
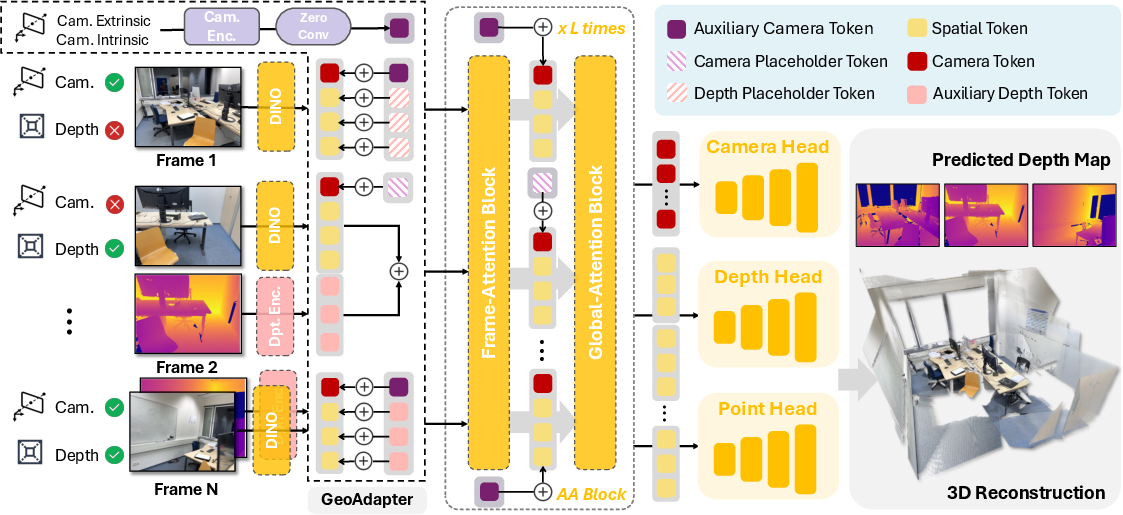
Figure 1: Overview of OmniVGGT, processing images and any combination of geometric auxiliary data through alternating-attention blocks to predict dense 3D attributes.
Model Architecture
GeoAdapter: Multimodal Injection
The core innovation in OmniVGGT is the GeoAdapter, a lightweight module composed of two branches:
- Camera Adapter: Normalizes and encodes pose and intrinsics, injecting them per-transformer block via a zero-initialized convolution (ZeroConv). This initialization ensures network stability and preserves the pretrained feature distribution.
- Depth Adapter: Normalizes and tokenizes depth maps alongside validity masks, then injects directly into spatial tokens. Notably, depth injection does not employ ZeroConv, as empirical ablations show this disrupts effective fusion.
Missing modalities are represented with learned placeholder tokens. The overall process supports variable and partial provision of auxiliary data.
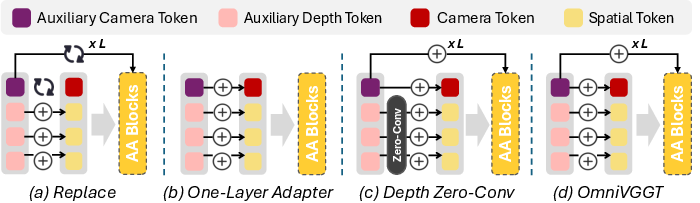
Figure 2: Visualization of the GeoAdapter module, illustrating modality-specific normalization and per-layer injection.

Figure 3: PCA-based visualization of spatial and auxiliary tokens; discriminative content regions in auxiliary-supplemented tokens are highlighted.
Alternating-Attention Blocks
Input tokens—spatial, camera, and register—undergo joint encoding in L alternating-attention blocks. The scheme permits intra-view self-attention for local spatial relationships and global cross-view aggregation for geometric consistency.
Stochastic Multimodal Fusion Training
OmniVGGT utilizes stochastic assignment of auxiliary modalities during training: for each batch, a random subset of images receives depth or camera parameters. This regimen:
- Regularizes training, preventing overfitting to fully-annotated cases
- Enables arbitrary modality combinations at inference, establishing a truly flexible multimodal backbone
The multi-task training loss integrates terms for depth, camera, and 3D point map prediction (L=Lcam+Ldepth+Lpmap), including confidence-aware regression and spatial gradient losses for local geometric fidelity.
Experimental Results
Across zero-shot evaluations (e.g., Sintel, ARKitScene), OmniVGGT demonstrates monotonic gains as more auxiliary modalities are injected. For instance, on Sintel, 30% depth guidance yields a 69.71% reduction in Abs Rel compared to RGB-only input, and full (100%) camera pose annotation results in a performance gain of 65.4% on sparse-view 3D reconstruction benchmarks.
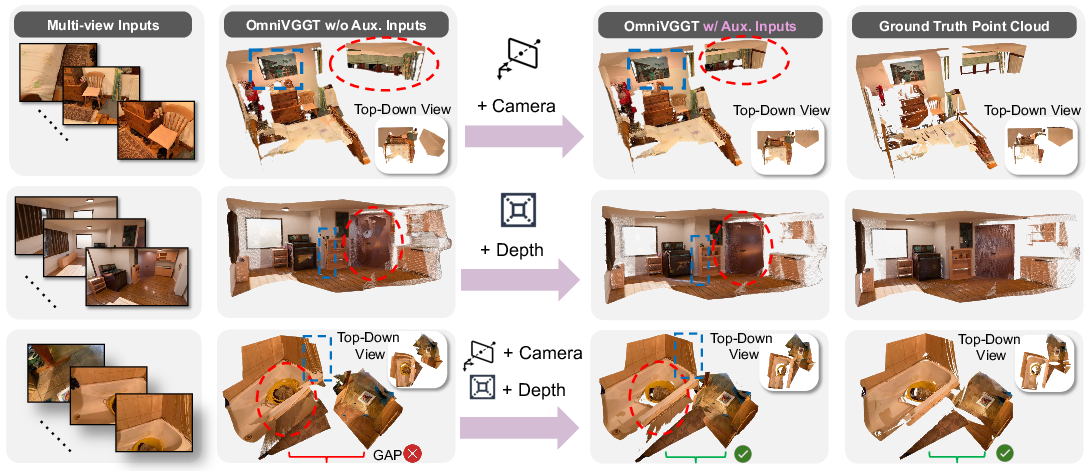
Figure 4: Qualitative comparison under partial and full auxiliary input. Top: camera cues correct pose in non-overlapping views. Middle: depth cues yield more detailed geometry. Bottom: combined modalities optimally align structure and scale.
Depth Estimation (Mono & Multi-view)
OmniVGGT achieves state-of-the-art on single-view and multi-view benchmarks, surpassing prior multimodal methods (e.g., Pow3R), especially when auxiliary depth is available (δ<1.25 up to 99.9% on NYU-v2). Unlike other methods, OmniVGGT maintains strong performance even with RGB-only inputs due to its robust spatial representation learning.

Figure 5: Multi-modality visual comparison on 7-Scenes, NRGBD, and ETH3D; OmniVGGT produces correct distances and geometric consistency even in challenging configurations.
Camera Pose Estimation
Evaluated on Co3Dv2 and RealEstate10K, OmniVGGT outperforms all baselines in both RGB-only and auxiliary-guided settings, and is computationally efficient (30× faster than Pow3R). Full auxiliary input yields AUC@30∘ > 93% on CO3Dv2.
3D Reconstruction
On 7-Scenes and NRGBD, OmniVGGT's scene-level accuracy, completeness, and normal consistency metrics exceed all prior methods, with dramatic gains in sparse-view settings when camera pose is injected (mean accuracy improving from 0.104 to 0.037).

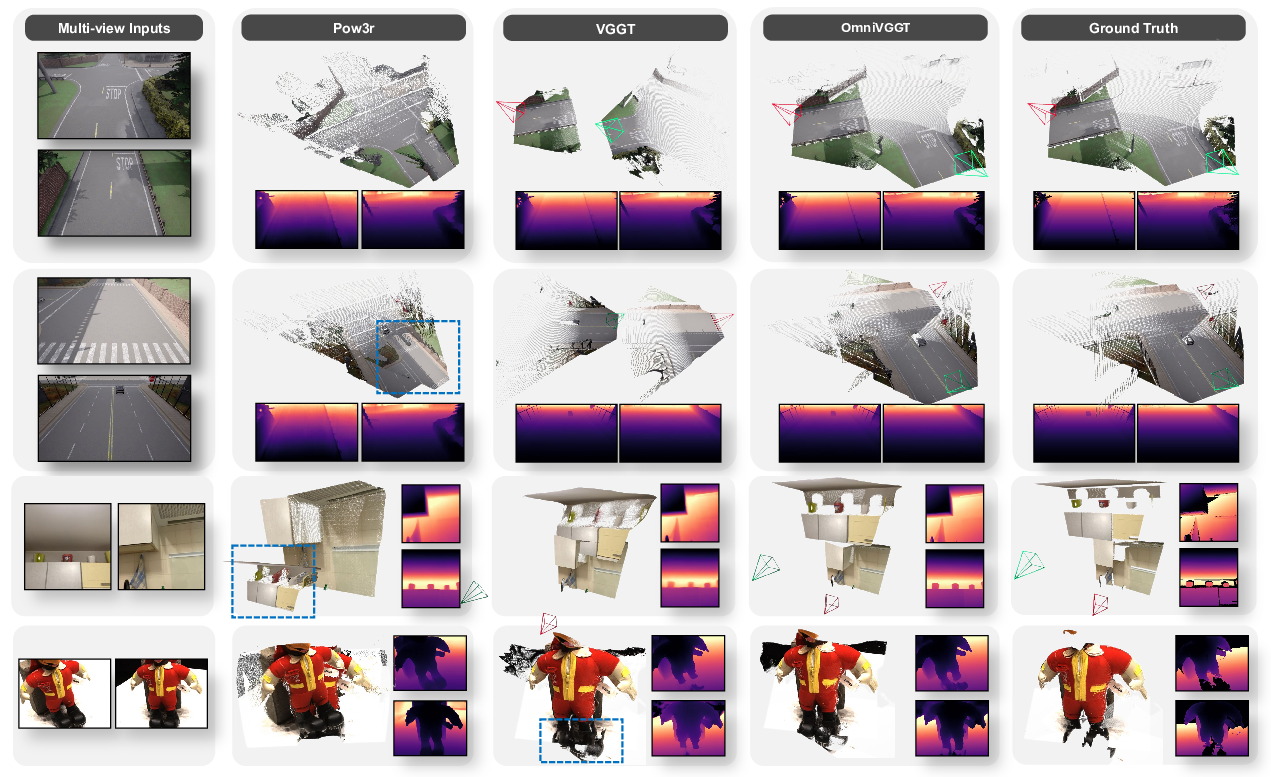
Figure 6: OmniVGGT point maps on in-the-wild image inputs, displaying strong generalization to unseen domains.
Vision-Language-Action Integration
Plugging OmniVGGT spatial tokens into VLA models (e.g., Kosmos-VLA), the system achieves improved task completion rates in CALVIN robotics benchmarks. The multimodal backbone enables effective exploitation of available depth and pose inputs for manipulation tasks.

Figure 7: CALVIN benchmark rollouts—OmniVGGT empowerment enables accurate sequence completion and spatial reasoning in robot manipulation.
Ablation and Trade-off Analysis
ZeroConv Utility and Placement
Ablation studies highlight that zero-initialized convolution is essential for stable camera auxiliary injection but degrades depth fusion (Figure 8). Depth tokens should be fused directly, preserving detailed spatial cues.

Figure 8: Feature-map comparison between direct and ZeroConv depth injection; direct addition retains auxiliary details, ZeroConv suppresses information.
Layer-wise Injection vs. Single-point Fusion
Injecting camera modalities at every block (per-layer) provides better propagation of prior knowledge and maintains discriminability of auxiliary signals versus one-time fusion.
Resource Requirements and Scaling
OmniVGGT introduces ~27M additional parameters over VGGT, with negligible impact on inference speed. The model scales linearly with additional modalities and maintains competitive throughput under all tested configurations. Full training (32 A100 GPUs, 10 days) relies on extensive dataset diversity to guarantee domain generalization.
Practical and Theoretical Implications
OmniVGGT generalizes spatial learning by removing restrictive assumptions on input modalities and their combinations. The design supports practical deployment in mixed-modality environments such as AR/VR, robotics, and autonomous systems, where geometric priors may be variably available. The stochastic fusion training paradigm establishes theoretical groundwork for multimodal adaptation via partial supervision, encouraging further research into adaptable foundation models.
Future Directions
Prospects include:
- Extension to additional geometric priors (e.g., LiDAR, semantic maps)
- Fine-grained spatial reasoning for VLA models in embodied AI
- Domain adaptation for out-of-distribution deployment where auxiliary input reliability varies
- Exploration of multimodal curriculum learning to further enhance robustness
Conclusion
OmniVGGT offers a unified, multimodal solution for 3D vision tasks, achieving state-of-the-art performance while enabling flexible and efficient integration of geometric modalities. Empirical evidence strongly supports the value of auxiliary input injection and stochastic fusion for spatial foundation models, signaling a new direction for generalist 3D perception architectures.