On Geometric Understanding and Learned Data Priors in VGGT
Abstract: The Visual Geometry Grounded Transformer (VGGT) is a 3D foundation model that infers camera geometry and scene structure in a single feed-forward pass. Trained in a supervised, single-step fashion on large datasets, VGGT raises a key question: does it build upon geometric concepts like traditional multi-view methods, or does it rely primarily on learned appearance-based data-driven priors? In this work, we conduct a systematic analysis of VGGT's internal mechanisms to uncover whether geometric understanding emerges within its representations. By probing intermediate features, analyzing attention patterns, and performing interventions, we examine how the model implements its functionality. Our findings reveal that VGGT implicitly performs correspondence matching within its global attention layers and encodes epipolar geometry, despite being trained without explicit geometric constraints. We further investigate VGGT's dependence on its learned data priors. Using spatial input masking and perturbation experiments, we assess its robustness to occlusions, appearance variations, and camera configurations, comparing it with classical multi-stage pipelines. Together, these insights highlight how VGGT internalizes geometric structure while using learned data-driven priors.













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑English Summary of “On Geometric Understanding and Learned Data Priors in VGGT”
What is this paper about?
This paper studies a powerful AI model called VGGT that can look at one or more photos of a scene and quickly figure out things like the 3D shape of objects and where the cameras were. The main question the authors ask is: does VGGT truly “understand” the rules of 3D geometry (like older, math-heavy methods), or does it mostly rely on patterns it has memorized from lots of training images (data priors)?
What big questions did the authors try to answer?
- Does VGGT learn real geometric ideas (like how points in two photos correspond and how cameras relate), even though it wasn’t directly trained to output those math objects?
- If it does, where inside the model does that understanding show up?
- Are the model’s predictions stable when the images are tricky (for example, with occlusions, weird lighting, or different camera setups)?
- How much does VGGT lean on learned “common sense” from its training data, and when does that help or hurt?
How did they study it? (Explained with simple examples)
The authors looked inside the model like a mechanic looks under a car hood. They used three main ideas:
- “Probing” the model’s internal layers: Think of each layer as a step in the model’s thinking. The authors trained small, simple “mini-tests” that try to read out a key geometry object called the fundamental matrix from the model’s internal signals. The fundamental matrix is a compact math rule that links a point in one photo to a line in another photo—basically the rules of how two cameras see the same 3D point.
- Examining attention patterns (like spotlights): VGGT is a transformer, which uses attention heads—little “spotlights” that decide which image patches should pay attention to which patches in another view. If the model is learning geometry, we’d expect some spotlights to line up matching parts across photos (called “correspondences”), like matching the tip of a car antenna in photo A to the same tip in photo B.
- Interventions (switching off spotlights): To test cause and effect, the authors “switched off” certain attention heads (like unscrewing a few bulbs) to see if this breaks the model’s geometric understanding. If performance collapses, those spotlights were doing something important for geometry.
They also created a controlled set of synthetic scenes (from 3D models) so they know the exact “right answers” (true camera info, true point matches, etc.). This makes testing precise. Then they tried stressful situations:
- Occlusions (covering parts of the image).
- Tricky lighting and color changes.
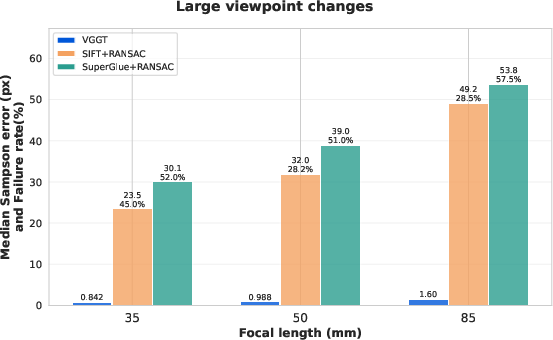
- Different zoom levels (focal lengths).
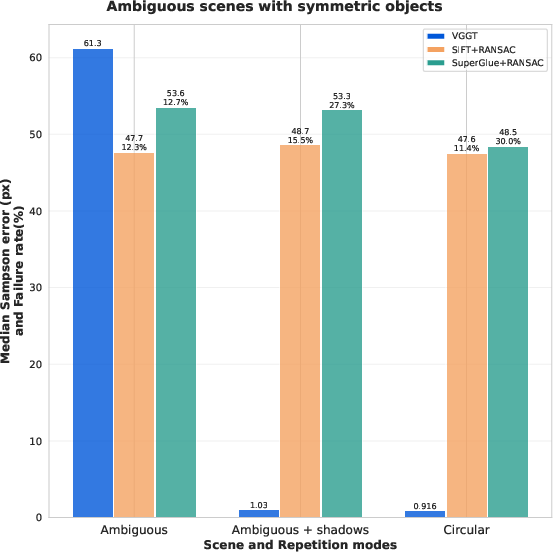
- Repetitive or symmetric objects that are hard to tell apart.
What did they find, and why does it matter?
Here are the main findings:
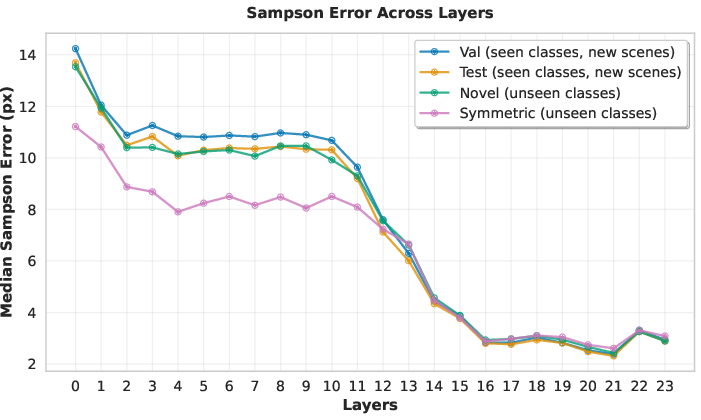
- The model learns real geometry inside: Starting around the middle layers, the authors could reliably “read out” the fundamental matrix from the model’s internal signals, and this got even better in later layers. This suggests VGGT builds genuine geometric structure as it processes images.
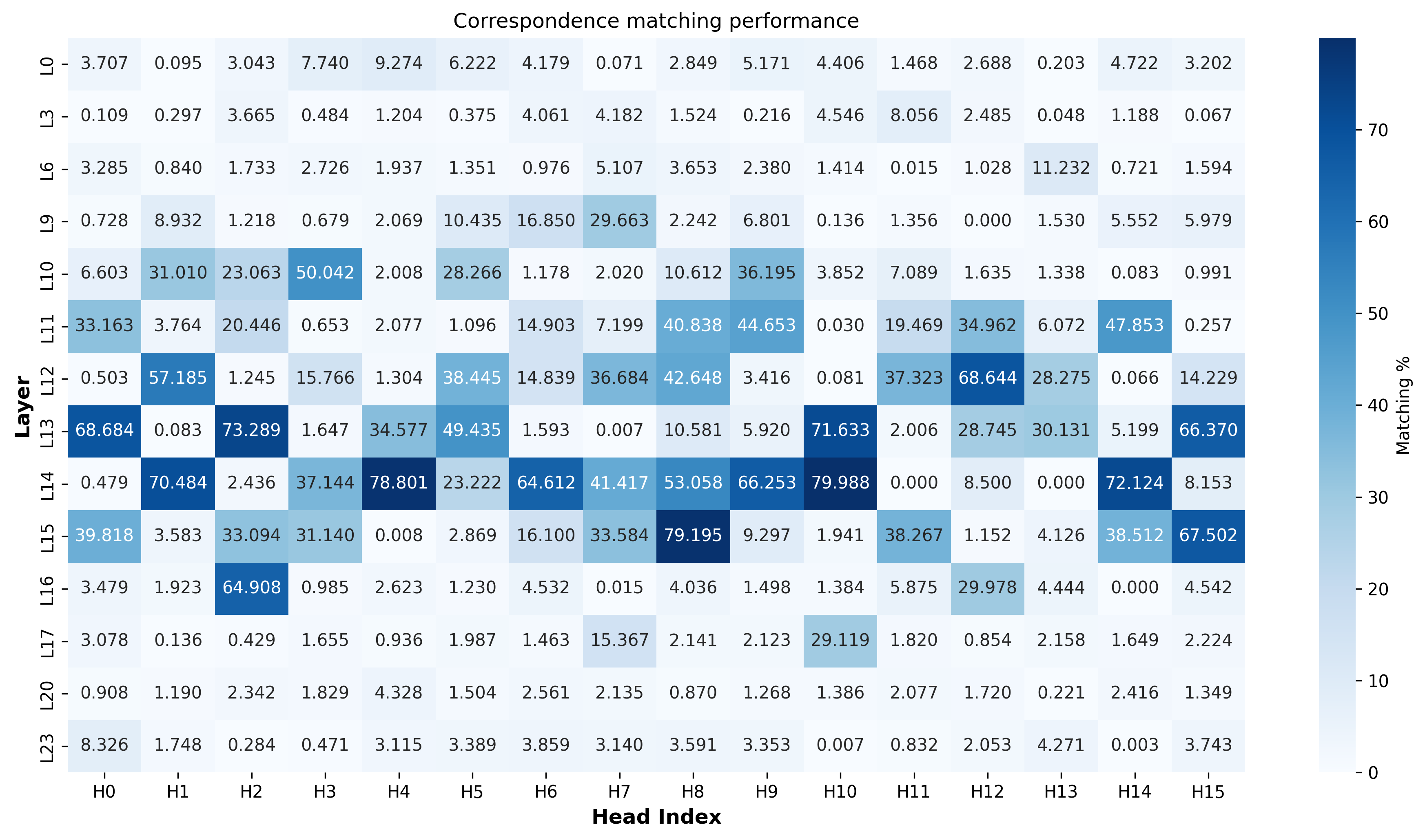
- Attention heads discover point matches: In those same middle layers, several attention heads consistently match the same parts across different photos. This is a classic geometric skill—finding correspondences is the first step for 3D reconstruction.
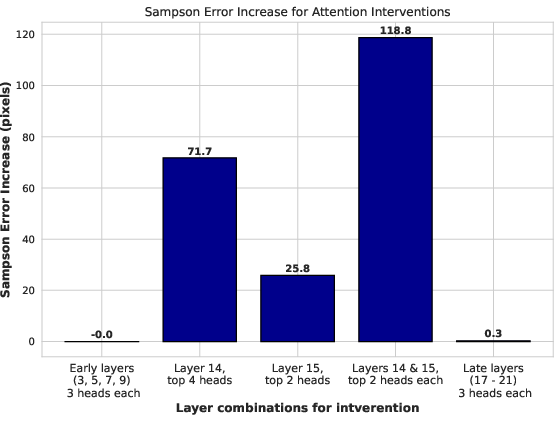
- Causal link: switching off key heads breaks geometry: When the authors disabled the best correspondence heads in the middle layers, the model’s geometric accuracy fell sharply. Disabling early or late heads didn’t matter much. That’s strong evidence these middle-layer heads are crucial for the model’s geometric understanding.
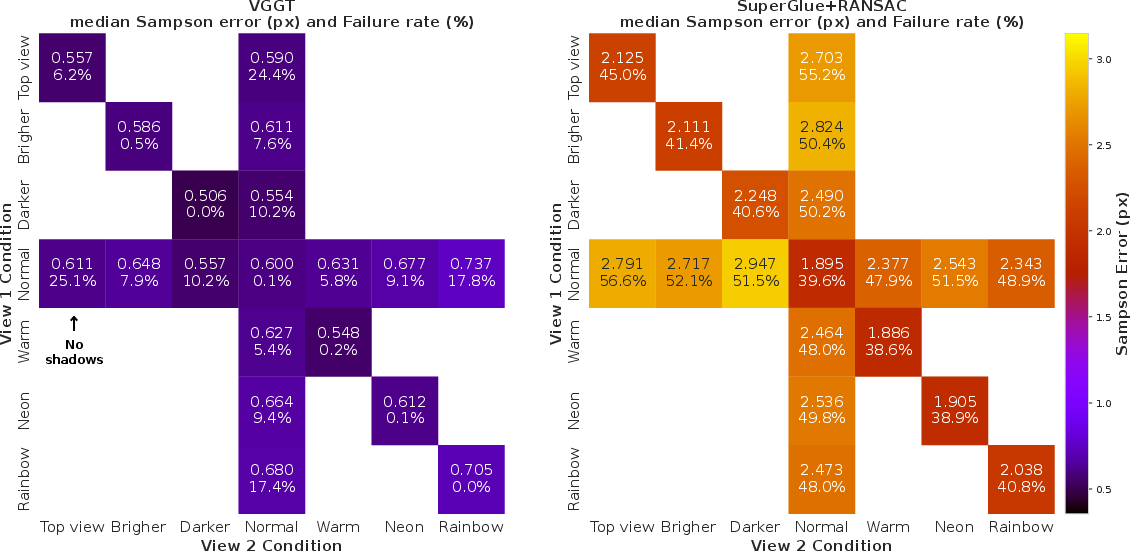
- Robust to occlusions and many appearance changes: When parts of the image were covered, VGGT still found many of the correct matches and kept good geometry. It also stayed stable under many lighting, color, and zoom changes and across different camera setups, more so than traditional methods. However, in extreme lighting mismatches (like only one image having strong, unusual lighting), the model failed more often.
- Can “hallucinate” missing information: Under occlusion, the model sometimes fills in missing matches based on what it has learned from data. That can be helpful, but it can also be risky because sometimes there isn’t enough information to be sure. For a reconstruction system, making up details can be undesirable if it leads to confident but wrong outputs.
- Handles ambiguous scenes better—until they’re impossible: When objects are repeated or symmetric, traditional methods often break. VGGT can use subtle cues like shadows to figure things out. But if a scene is perfectly symmetric with no helpful hints (like shadows), then all methods—including VGGT—fail, which is expected because the problem is genuinely ambiguous.
What’s the bigger picture?
This work shows that a modern AI model for 3D vision doesn’t just memorize patterns; it actually learns and uses core geometric ideas inside its layers. That’s good news: geometry is universal, so this kind of understanding can help the model stay reliable even when it sees new types of scenes.
At the same time, the model also leans on learned data priors. Those priors make it robust and fast, but they can sometimes cause “hallucinations” when parts of the image are missing or misleading. Going forward, combining strong geometry with better ways to handle uncertainty (so the model can say “I’m not sure” instead of guessing) could make 3D reconstruction both fast and trustworthy.
In short: VGGT blends the best of both worlds—solid geometric reasoning and powerful learned priors—making it fast, accurate, and robust in many real-world situations, while reminding us to be careful about when the model might be guessing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, formulated to be actionable for future research.
- Real-world generalization: Validate whether mid-layer epipolar encoding and correspondence-focused attention heads persist on real-world datasets with lens distortion, rolling shutter, motion blur, noise, and varying resolutions (beyond synthetic ShapeNet scenes).
- Multi-view geometry beyond pairs: Test if VGGT internally encodes trifocal/quadrifocal tensors or bundle-adjustment-like multi-view consistency; build probes and interventions for sequences of 3+ views.
- Linear vs nonlinear decodability: Determine whether the fundamental/essential matrices are linearly decodable (via linear probes) from different token types (camera, patch, register), and quantify the minimal probe complexity needed.
- Token-wise localization of geometry: Identify which tokens carry geometric information and where it spatially resides; perform per-token probing and attribution across layers.
- Internal consistency checks: Compare F/E decoded from internal representations with F/E computed from VGGT’s predicted intrinsics/extrinsics to assess coherence and pinpoint failure modes.
- Finer-grained causal evidence: Use token-level attention rewrites, value-vector patching, and causal mediation to establish necessity/sufficiency of specific correspondence heads and rule out confounding mechanisms within the same heads.
- Head specialization and invariances: Map which attention heads specialize by baseline, focal length, or lighting condition and what geometric/appearance invariances each encodes.
- Uncertainty and hallucination detection: Develop calibrated confidence measures to detect and flag hallucinated correspondences under occlusion/OOD; quantify occlusion severity thresholds at which geometry fails.
- Realistic occlusion robustness: Evaluate performance under textured, semi-transparent, moving, and structured occluders; study dependence on occlusion shape/size and camera baseline.
- OOD robustness boundaries: Systematically chart failure regions over controlled lighting/color shifts (e.g., top-lighting removing shadows, extreme illuminants) and quantify how training augmentations influence these boundaries.
- Symmetry and repetition resolution: Investigate how VGGT exploits subtle cues (shadows, contextual layout) to break symmetry; assess detectability of unavoidable ambiguities and design ambiguity-aware outputs.
- Intrinsics variability and distortion: Probe robustness to extreme intrinsics (very wide/narrow FOV, skew, principal-point shifts) and lens distortion; test whether intrinsics are decodable from internal states.
- Dynamic scenes and trajectories: Extend analysis to moving objects and multi-frame tracking to determine whether the same geometric mechanisms support temporal consistency and 3D point trajectories.
- Long-sequence attention structure: Examine how global attention aggregates and maintains view-consistent correspondences across sequences longer than pairs; identify heads that enforce temporal/multi-view consistency.
- Practical utility of probes: Establish whether lower decoded Sampson errors correlate with improvements in camera pose, depth, and reconstruction quality; validate probes as predictors of downstream performance.
- Baseline breadth and fairness: Compare against modern matchers (LoFTR, LightGlue, MASt3R, VGGSfM) on both synthetic and real data, controlling for synthetic-data bias that disadvantages classical features like SIFT.
- Probe training biases: Assess overfitting to ground-truth correspondences in probe training, cross-dataset generalization, and the feasibility of zero-shot decodability (no probe training).
- Scale/normalization sensitivity: Analyze how decoded F depends on scaling/normalization choices and rank-2 enforcement; study calibration-free formulations and stability of singular value spectra.
- Architectural dependence: Ablate backbone and attention configurations (e.g., different DINO variants, fewer or reordered global layers) to isolate components critical for emergent geometry.
- Failure mitigation: Explore training or inference-time strategies (e.g., uncertainty-aware RANSAC post-processing, hybrid geometric priors) to recover under extreme appearance shifts or total symmetry.
- Camera model diversity: Test generality across non-pinhole cameras (fisheye), rolling-shutter effects, varied sensor sizes, and extreme baselines/camera orientations not covered in current setups.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s findings on VGGT’s internal geometric understanding, correspondence encoding, robustness properties, and the presented probing/intervention methodology.
- Geometry-aware quality assurance for 3D reconstruction pipelines (software, robotics, AR/VR, AEC, mapping, film/VFX)
- Description: Integrate a lightweight “F-probe” that linearly decodes the fundamental matrix from VGGT’s camera tokens at mid-to-late layers and monitors epipolar consistency via Sampson error and singular value ratios.
- Workflow: During inference, extract intermediate camera tokens → predict F with a small MLP probe → compute Sampson error and smallest singular value checks → flag outputs when error > 1–2 px or when min singular value is not <1e−3 of max singular value → trigger fallback (e.g., classical SfM) or request additional views.
- Assumptions/Dependencies: Access to VGGT intermediate representations; calibration/known intrinsics improve interpretability; thresholds must be tuned to the target resolution and optics; minimal latency budget for probe computation.
- Hybrid, fail-safe reconstruction pipelines with measured fallback (photogrammetry, AEC, film/VFX, cultural heritage digitization)
- Description: Use the probe-derived epipolar metrics to decide when to fall back from VGGT to classical RANSAC/Eight-Point or to a multi-step learned matcher (e.g., MASt3R alignment) on subsets of scenes (extreme lighting changes, symmetry without cues).
- Tools: “Geometry watchdog” module that gates downstream steps; logging dashboards for Sampson error distributions.
- Assumptions/Dependencies: Access to classical pipelines; policies for choosing fallback strategy; performance trade-offs acceptable on edge/embedded hardware.
- Attention-head correspondence visualizer for debugging data and setups (software engineering, data ops, research labs)
- Description: Inspect mid-layer global attention QK maps to reveal per-head correspondence matching heatmaps; diagnose capture issues (e.g., top-lit scenes, extreme neon color changes).
- Tools: A visualization plugin that shows “matched heads” counts per layer and per correspondence; alerts for layers 10–16 if correspondence signals degrade.
- Assumptions/Dependencies: Permission to instrument model attention; potential IP/licensing constraints; ensure secure handling of internal weights.
- Occlusion-tolerant capture and triage policies (robotics, drones, SLAM, field surveying)
- Description: Exploit VGGT’s partial robustness to occluded regions to avoid discarding frames outright; triage frames using epipolar metrics plus “matched heads” counts on occluded patches.
- Workflow: For occluded frames, compute per-patch correspondence retention rates; accept frames when retained matched-heads ≥ a threshold (e.g., ~50% seen in paper) and Sampson error degradation is small; otherwise re-capture or adjust viewpoint.
- Assumptions/Dependencies: Risk of hallucinated correspondences; guardrails needed to prevent unsafe reliance in safety-critical systems; threshold calibration required.
- Synthetic stress-testing suite for deployment readiness (academic labs, industry QA)
- Description: Reuse the paper’s Blender-based ShapeNet pipeline to simulate lighting/color/focal-length/symmetry perturbations and measure failure modes before production rollout.
- Tools: “Occlusion Stress Lab” scripts; standardized acceptance criteria using Sampson error and failure-rate metrics (e.g., error >10 px considered failure).
- Assumptions/Dependencies: Synthetic results may not fully reflect texture/noise properties of real scenes; adjust for domain-specific materials and sensors.
- Geometry-aware training diagnostics and small auxiliary constraints (academia, applied ML teams)
- Description: During fine-tuning, add auxiliary objectives or post-hoc penalties to encourage rank-2 F predictions and reduce drift in mid-layers; monitor emergence of correspondence signals in layers 10–16.
- Tools: Probe-in-the-loop training monitor; per-layer attention diagnostics; periodic intervention tests via attention knockout to check causal importance.
- Assumptions/Dependencies: Access to training code and datasets; potential trade-offs in speed vs. geometric consistency; careful tuning to avoid over-regularization.
- Light pruning and resource tuning guided by causal insights (embedded vision, real-time apps)
- Description: Use intervention evidence to prioritize keeping correspondence-critical mid-layer heads while carefully pruning minimally impactful early/late heads for latency gains.
- Tools: Head/layer pruning experiments gated by QA metrics; profile before/after Sampson error changes.
- Assumptions/Dependencies: Pruning must be conservative—paper shows final layers refine geometry; ensure no catastrophic degradation; hardware-aware evaluation needed.
- Policy and procurement checklists for applied vision AI (public agencies, enterprise IT governance)
- Description: Require epipolar consistency checks and documentation of known failure conditions (e.g., top-lit scenes, extreme color changes, fully symmetric scenes without disambiguating shadows) in vendor deliverables.
- Tools: Standardized acceptance tests (Sampson error thresholds, failure-rate reporting); “hallucination risk” disclosures for occlusion cases.
- Assumptions/Dependencies: Cross-team alignment on metrics and thresholds; enforcement mechanisms in contracts.
- Education and training modules (education, workforce upskilling)
- Description: Use the paper’s interpretability set-up to teach epipolar geometry and transformer attention mechanisms; hands-on labs visualizing correspondence heads and fundamental matrix probing.
- Tools: Classroom notebooks with probe training and attention visualization; example scenes with adjustable lighting and focal length.
- Assumptions/Dependencies: Access to GPUs for interactive labs; simplified datasets for instruction.
Long-Term Applications
These applications require further research, scaling, engineering, standardization, and/or validation beyond the current paper’s scope.
- Next-generation geometry-aware foundation models (software, robotics, AR/VR)
- Description: Architectures that explicitly integrate correspondence modules discovered to be causal (layers 10–16) and enforce geometric constraints (rank-2 E/F, epipolar consistency) during training; aim for stronger out-of-distribution guarantees.
- Potential products: “VGGT++” with geometry losses and causal alignment; model families with configurable correspondence heads.
- Dependencies: Large, diverse datasets; compute-intensive training; careful balancing to avoid overfitting priors or losing generality.
- Formal safety monitors for autonomous systems (autonomous vehicles, drones, mobile robots)
- Description: A “geometry watchdog” that gates actions based on real-time epipolar confidence signals and correspondence-head health, escalating to conservative behaviors if confidence degrades.
- Workflow: Integrate probe metrics, per-head correspondence checks, and scenario classifiers (lighting/symmetry) into safety cases; formal verification against acceptance thresholds.
- Dependencies: Regulatory approval; thorough field validation; deterministic fallbacks; sensor fusion plans.
- Robust real-time AR glasses and consumer 3D scanning (AR/VR, e-commerce, gaming)
- Description: On-device 3D mapping that tolerates partial occlusions and varying focal lengths while providing a user-facing “geometry confidence meter”; capture-guidance UI to adjust lighting/viewpoints.
- Products: AR capture assistants; mobile 3D scanning apps with onboard QA and automatic recapture prompts.
- Dependencies: Efficient edge inference; privacy-preserving instrumentation; UX design; battery/runtime constraints.
- Cross-modality fusion with geometry priors (smart cities, AEC, autonomous systems)
- Description: Combine VGGT-like geometry signals with LiDAR/IMU to resolve ambiguous scenes (symmetry, feature sparsity) and reduce reliance on color/lighting priors.
- Tools: Sensor fusion frameworks that weight visual geometry confidence signals against other modalities.
- Dependencies: Synchronized sensors; calibration; robust fusion algorithms; domain-specific tuning.
- Sector-specific standards for epipolar consistency and geometric QA (policy, standards bodies)
- Description: Industry standards (e.g., ISO-like) that define acceptance thresholds (e.g., Sampson error bands) and procedures for auditing geometric outputs of AI vision systems.
- Impact: Procurement guidance, certification regimes, compliance audits for public projects and safety-critical deployments.
- Dependencies: Multi-stakeholder consensus; repeatable test suites; alignment with sector regulations.
- Model compression via causal head distillation (embedded vision, edge AI)
- Description: Distill full-size models into compact variants that preserve identified causal mid-layer heads while compressing less critical components; maintain geometry fidelity under typical deployment conditions.
- Tools: Layer/head-level distillation; attention importance maps; geometry-focused objectives.
- Dependencies: Robust distillation recipes; hardware constraints; monitoring of OOD behavior.
- Capture-time adaptive guidance powered by geometric confidence (photo/videography, prosumer devices)
- Description: Real-time suggestions (move light off top-view, avoid neon/rainbow lighting, adjust baseline angle/focal length) to preempt known failure modes before capture.
- Products: Smart capture assistants in cameras/drones; enterprise workflows for site scans.
- Dependencies: Accurate scene-condition classifiers; integration with camera controls; user adoption.
- Medical stereo endoscopy and surgical robotics under occlusion and smoke (healthcare)
- Description: Apply geometry-aware monitoring and robust correspondence inference to mitigate visual occlusions, with strict guardrails against hallucinated reconstructions.
- Tools: Clinical QA modules, sensor fusion with depth/force feedback; operator alerts when geometry confidence falls.
- Dependencies: Clinical validation; regulatory pathways (FDA/CE); domain adaptation; rigorous safety benchmarks.
- Digital twins at construction scale with dynamic occlusions (AEC, infrastructure inspection)
- Description: Large-scale, partially occluded scanning (moving workers/equipment) with epipolar confidence-driven capture planning and fallbacks to multi-view optimization when needed.
- Workflow: Fleet orchestration based on geometry QA signals; post-processing pipelines that tag suspect regions for re-scan.
- Dependencies: Multi-agent coordination; operational policies; compute/storage capacity.
- Community interpretability benchmarks for 3D vision (academia, open-source)
- Description: Standard datasets and tooling for probing geometry emergence and correspondence causality across 3D models; reproducible intervention protocols (attention knockout).
- Impact: Accelerates understanding and comparability of 3D foundation models; improves trust and reliability.
- Dependencies: Open checkpoints; shared tooling; maintainers and governance.
- Hallucination detectors and mitigators for occlusion-prone scenarios (software, safety)
- Description: Train detectors that flag likely hallucinated correspondences when occlusion is present; automatically request more views or switch to conservative algorithms.
- Tools: Auxiliary classifiers on per-patch attention patterns; “occlusion-aware” risk scoring.
- Dependencies: Annotated datasets for hallucination detection; integration with capture/control systems; careful thresholding to avoid false positives.
Glossary
- 3D foundation model: A large, general-purpose model trained to perform a broad set of 3D tasks. "The Visual Geometry Grounded Transformer (VGGT) is a 3D foundation model that infers camera geometry and scene structure in a single feed-forward pass."
- activation patching: An interpretability intervention where activations are replaced or modified to test causal roles. "Different interventions, such as activation patching or causal mediation analysis~\cite{heimersheim2024useinterpretactivationpatching, zhang2024best_practices}, provide more substantial evidence by measuring the effects of modified activations within a model."
- algebraic error: A scale-dependent residual x₂ᵀF x₁ used to test epipolar constraint satisfaction. "The algebraic error"
- attention heads: Individual subcomponents within a multi-head attention layer specializing in different patterns. "Point correspondence matching appears in the mid-layer attention heads as a key mechanism, enabling geometric alignment across views."
- attention knockout: An intervention that zeros specific attention parameters to assess their causal impact. "We intervene on the QK attention space using attention knockout, a method similar to Geva et al.~\cite{geva-etal-2023-dissecting}"
- bundle adjustment: Joint optimization of camera parameters and 3D points to minimize reprojection error in SfM. "feature detection, matching, camera pose estimation, and bundle adjustment, in which they rely on hand-crafted features from algorithms such as SIFT~\cite{lowe2004distinctive}."
- camera extrinsics: External camera parameters (rotation and translation) defining pose in world coordinates. "yields camera extrinsics and intrinsics, point maps, depth maps, and 3D point trajectories across views."
- camera intrinsics: Internal camera parameters (e.g., focal length, principal point) defining projection. "yields camera extrinsics and intrinsics, point maps, depth maps, and 3D point trajectories across views."
- camera token: A special token used in transformer inputs to represent per-view camera information. "Each view also has one camera token and four register tokens."
- causal mediation analysis: A technique to quantify causal effects of internal model components on outputs. "Different interventions, such as activation patching or causal mediation analysis~\cite{heimersheim2024useinterpretactivationpatching, zhang2024best_practices}, provide more substantial evidence by measuring the effects of modified activations within a model."
- correspondence matching: Identifying the same 3D point across different image views via feature associations. "VGGT implicitly performs correspondence matching within its global attention layers and encodes epipolar geometry"
- DINOv2: A self-supervised vision backbone used for patch embeddings in downstream tasks. "Given patch-tokenized images aligned with the DINOv2 model, VGGT yields camera extrinsics and intrinsics, point maps, depth maps, and 3D point trajectories across views."
- eight-point algorithm: A classical linear method to estimate the fundamental matrix from at least eight correspondences. "the five-point~\cite{nister2004fivepoint} or the eight-point~\cite{hartley1997eightpoints} algorithms"
- epipolar constraint: The relation x₂ᵀF x₁ = 0 that corresponding points must satisfy across two views. "This geometric relationship is expressed by the epipolar constraint:"
- epipolar geometry: The projective relationship between two camera views of the same 3D point. "Epipolar geometry is an ideal probe for studying model's geometric understanding as it is mathematically precise and algorithmically well-defined."
- epipolar line: The line in one image where the correspondence of a point in the other image must lie. "gives the epipolar line , on which the corresponding point must lie."
- epipolar plane: The plane defined by a 3D point and two camera centers; its intersection with an image forms the epipolar line. "A ray from the first camera center through defines an epipolar plane with the two camera centers."
- epipole: The point where all epipolar lines intersect in an image. "All epipolar lines intersect at the epipole."
- essential matrix: A matrix E = [t]×R encoding relative rotation and translation between calibrated cameras. "where is the essential matrix and is the skew-symmetric matrix representing the cross product with ."
- feed-forward pass: A single forward inference through the network without iterative optimization. "in a single feed-forward pass."
- five-point algorithm: A minimal solver estimating relative pose using five point correspondences. "the five-point~\cite{nister2004fivepoint} or the eight-point~\cite{hartley1997eightpoints} algorithms"
- Frobenius norm: A matrix norm used to define the closest rank-2 approximation via SVD truncation. "This produces the closest rank-2 approximation in the Frobenius norm."
- fundamental matrix: A 3×3 rank-2 matrix F relating corresponding points across uncalibrated views. "The fundamental matrix provides a natural lens for this investigation"
- global self-attention: Attention across tokens from multiple views to aggregate global cross-view information. "with additional frame-wise and global self-attention layers to combine both local and global cross-view features"
- LightGlue: A learned local feature matcher improving robustness and speed over classical methods. "learned matching methods such as SuperGlue~\cite{sarlin20superglue}, LightGlue~\cite{lindenberger2023lightglue}, and LoFTR~\cite{sun2021loftr} have improved correspondence matching"
- LoFTR: A dense matcher using transformer-based features for correspondence without keypoint detection. "learned matching methods such as SuperGlue~\cite{sarlin20superglue}, LightGlue~\cite{lindenberger2023lightglue}, and LoFTR~\cite{sun2021loftr} have improved correspondence matching"
- MLP probe: A small neural classifier/regressor trained on internal representations to decode targeted information. "We train simple two-layer MLP probes on VGGT's camera tokens at each layer to predict the fundamental matrix."
- multi-stage pipeline: Traditional sequential approach (detect–match–estimate–refine) for 3D reconstruction. "effectively replacing the traditional multi-stage pipeline."
- out-of-distribution: Inputs that differ significantly from the training data distribution, often causing failures. "learned functional mappings are prone to fail in out-of-distribution cases."
- patch-tokenized images: Image representations split into fixed-size patches and embedded as tokens for transformers. "Given patch-tokenized images aligned with the DINOv2 model, VGGT yields camera extrinsics and intrinsics, point maps, depth maps, and 3D point trajectories across views."
- pinhole cameras: An idealized camera model with central projection used in multi-view geometry. "If a 3D point is observed by two pinhole cameras, its image projections are"
- query-key (QK) attention: The attention mechanism’s space defined by query and key interactions across tokens. "We analyze the query-key (QK) attention space to identify correspondence matching."
- RANSAC: A robust estimator that fits models while rejecting outliers via random sampling. "These estimation algorithms are usually accompanied with geometric algorithms like RANSAC~\cite{fischler1981random} for handling noisy correspondences and outliers."
- rank-2 constraint: The requirement that the fundamental and essential matrices have rank 2. "The smallest singular value of must be zero to satisfy the rank-2 constraint of the fundamental matrix."
- register tokens: Special tokens used to stabilize transformer computations and representations. "Each view also has one camera token and four register tokens."
- Sampson error: A first-order approximation to geometric reprojection error for epipolar consistency. "The Sampson error~\cite{sampson1982fitting} represents a first-order geometric approximation of true geometric error:"
- singular value decomposition: Matrix factorization used to enforce rank constraints by zeroing small singular values. "we compute its singular value decomposition"
- skew-symmetric matrix: A matrix representing the cross product with a vector, used in E = [t]×R. " is the skew-symmetric matrix representing the cross product with ."
- Structure-from-Motion (SfM): The process of reconstructing 3D structure and camera motion from multiple images. "Classical structure-from-motion (SfM) pipelines~\cite{Hartley2004, snavely2006photo, schoenberger2016revisiting, agarwal2011building} include different stages"
- SuperGlue: A learned graph-based matcher for keypoint correspondences. "learned matching methods such as SuperGlue~\cite{sarlin20superglue}, LightGlue~\cite{lindenberger2023lightglue}, and LoFTR~\cite{sun2021loftr} have improved correspondence matching"
- task-specific heads: Output layers specialized for particular predictions (e.g., depth, pose). "and is jointly optimized across all these tasks via task-specific heads."
- three-point lighting: A standard lighting setup using key, fill, and back lights. "Each scene was rendered with three-point lighting under various camera configurations"
- transformer architecture: A neural network architecture based on self-attention mechanisms. "Visual Geometry Grounded Transformer (VGGT)~\cite{wang2025vggt} is a feed-forward neural network following the transformer architecture."
- viewpoint difference: The angular or positional variation between camera views affecting correspondence difficulty. "MASt3R~\cite{mast3r_eccv24} further improves the matching capabilities in case of large viewpoint difference and preserves the robustness of DUSt3R"
- Visual Geometry Grounded Transformer (VGGT): A transformer-based model that predicts camera and 3D scene attributes in one pass. "VGGT~\cite{wang2025vggt} represents the current state-of-the-art directly predicting camera poses, depths, point clouds and 3D point tracks in a single feed-forward pass while also reporting significantly faster inference."
Collections
Sign up for free to add this paper to one or more collections.