ThetaEvolve: Test-time Learning on Open Problems
Abstract: Recent advances in LLMs have enabled breakthroughs in mathematical discovery, exemplified by AlphaEvolve, a closed-source system that evolves programs to improve bounds on open problems. However, it relies on ensembles of frontier LLMs to achieve new bounds and is a pure inference system that models cannot internalize the evolving strategies. We introduce ThetaEvolve, an open-source framework that simplifies and extends AlphaEvolve to efficiently scale both in-context learning and Reinforcement Learning (RL) at test time, allowing models to continually learn from their experiences in improving open optimization problems. ThetaEvolve features a single LLM, a large program database for enhanced exploration, batch sampling for higher throughput, lazy penalties to discourage stagnant outputs, and optional reward shaping for stable training signals, etc. ThetaEvolve is the first evolving framework that enable a small open-source model, like DeepSeek-R1-0528-Qwen3-8B, to achieve new best-known bounds on open problems (circle packing and first auto-correlation inequality) mentioned in AlphaEvolve. Besides, across two models and four open tasks, we find that ThetaEvolve with RL at test-time consistently outperforms inference-only baselines, and the model indeed learns evolving capabilities, as the RL-trained checkpoints demonstrate faster progress and better final performance on both trained target task and other unseen tasks. We release our code publicly: https://github.com/ypwang61/ThetaEvolve
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ThetaEvolve, an open-source system that helps AI models find better solutions to hard, open math problems. Unlike some earlier systems that only “try” solutions without learning, ThetaEvolve lets a model learn while it’s working, so it gets better over time. The big idea is to evolve small computer programs that solve a problem, score them, keep the best ones, and then improve them again and again.
What questions are the researchers asking?
They focus on three simple questions:
- Can a single, smaller open-source AI model discover new, best-known results on tough math problems if we give it the right setup?
- How can we organize the search so the model explores smartly and efficiently?
- Does learning during problem-solving (using reinforcement learning, or RL) help the model improve faster and even transfer its skills to other problems?
How does ThetaEvolve work?
Think of this like a science fair project where you keep improving your design:
- The model writes small programs (like “recipes”) that try to solve a math problem. For example, “How can we pack circles inside a square to get the biggest total size?”
- An evaluator acts like a fair judge: it runs each program and gives it a score.
- A program database is like a notebook or library of your best attempts. The model looks back at this library to learn from past ideas and make new ones.
- Batch sampling means the model doesn’t just try one idea at a time—it tries many in parallel, which speeds things up a lot.
- Lazy penalties are gentle nudges that say, “Don’t keep turning in the same old answer—try to improve it.”
- Reward shaping is like adjusting the grading scale so feedback is stable and helpful, making learning smoother.
- Reinforcement learning at test time means the model learns while it’s solving the problem, not just before. It gets feedback (rewards) from the evaluator and updates its strategy on the fly.
- A single LLM keeps the system simpler and cheaper than using a big team of different models.
Put simply: ThetaEvolve helps the model build, test, and improve programs quickly; it learns from successes; and it avoids getting stuck repeating the same ideas.
What did they find?
The results are exciting:
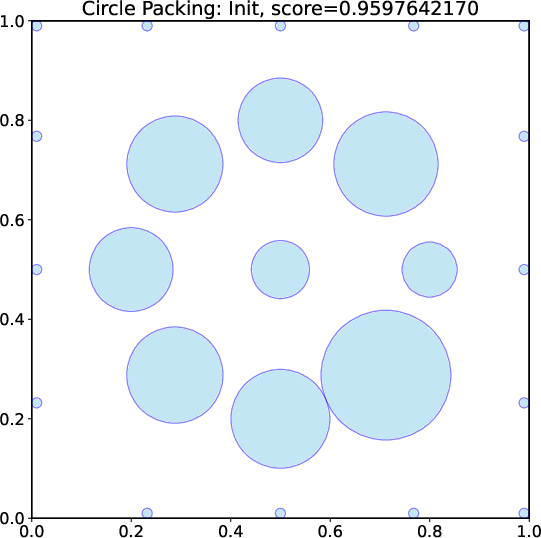
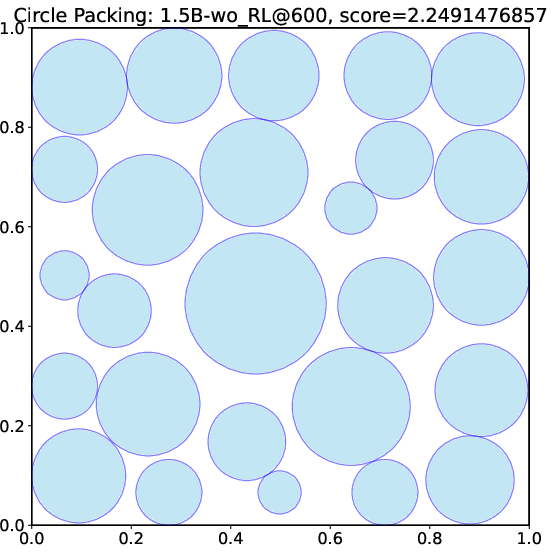
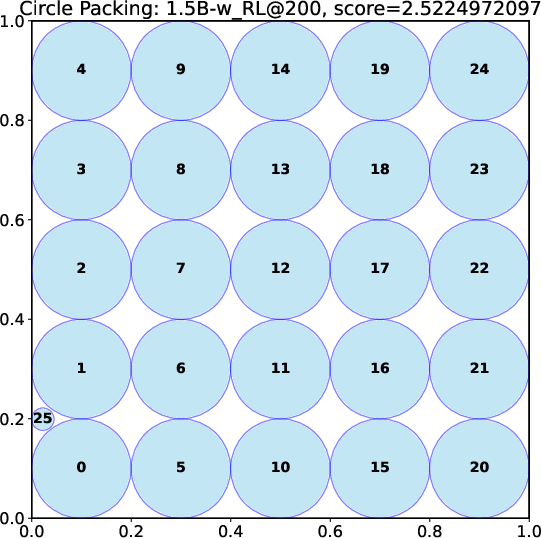
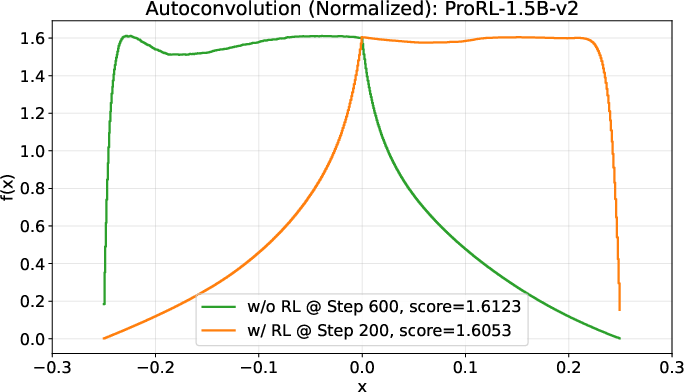
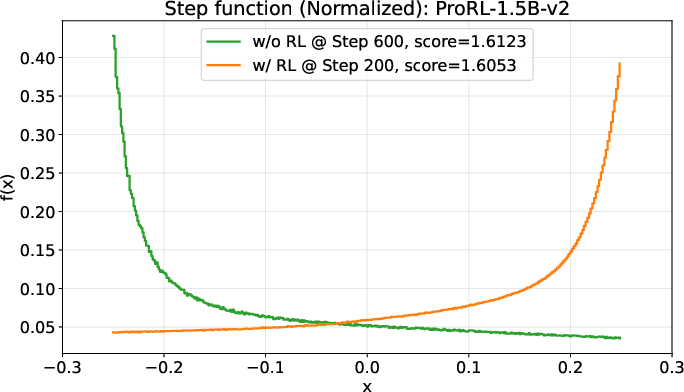
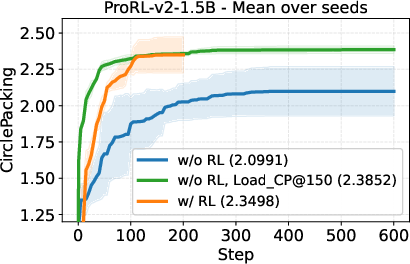
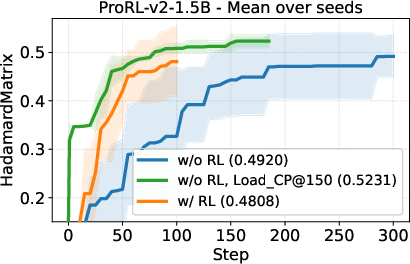
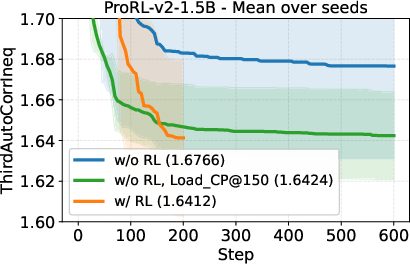
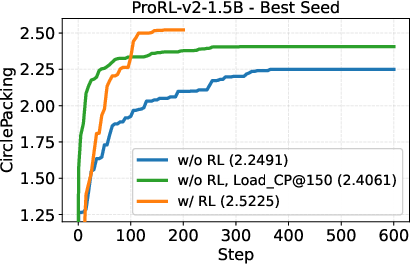
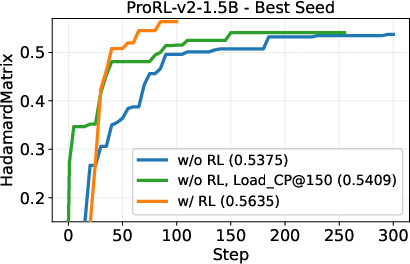
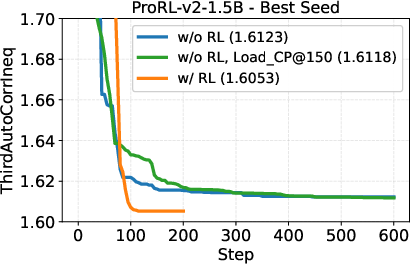
- A small open-source model (DeepSeek-R1-0528-Qwen3-8B) discovered new best-known solutions on two math problems: circle packing and the first autocorrelation inequality (a problem involving optimizing certain patterns in sequences). Earlier best results needed powerful, closed-source model ensembles, but ThetaEvolve did it with just one smaller, open model.
- The circle-packing program discovered by ThetaEvolve finds the best solution in about 3 seconds. A similar program from another system took around 75 seconds. That’s a big speed-up.
- When the model uses RL while solving, it improves faster and reaches better final results compared to just generating solutions without learning.
- The model doesn’t just get better at the problem it trained on; the improvements carry over to other, unseen problems. That suggests it’s learning general “how to evolve good programs” skills.
Why does this matter?
- It shows that smaller, open-source models can push the boundaries of math discovery if we give them the right tools and let them learn while working.
- Learning during problem-solving (test-time RL) is powerful: it helps models pick smarter strategies and improve steadily.
- ThetaEvolve is open-source, so researchers and students can use, study, and improve it.
- Beyond these specific math problems, the approach can help with any task where you can write a program, test it, score it, and keep improving—like designing better algorithms, optimizing layouts, or tuning scientific simulations.
In short, ThetaEvolve makes AI discovery more efficient, more accessible, and more capable—especially for tough problems where learning while you solve can make all the difference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work:
- Component attribution: Which specific ThetaEvolve design choices (single LLM, large database, batch sampling, lazy penalty, reward shaping, iterative refinement) are necessary and sufficient for gains? A thorough ablation across tasks is not provided.
- RL algorithm details: The paper does not specify the RL algorithm(s), objective(s), update schedule, on-/off-policy setup, or hyperparameters, nor their sensitivity; this limits reproducibility and understanding of why RL helps.
- Reward shaping and lazy penalty: The exact forms, scaling, thresholds, and task-dependent tuning of reward shaping and lazy penalties are not described or ablated; their side effects (e.g., discouraging small but productive edits) remain unknown.
- Database management policy: Beyond population_size, the strategy for ranking, diversity metrics, archive management, deduplication, and insertion policy is under-specified; the impact of these choices on exploration/exploitation trade-offs is not quantified.
- Sampling strategy from the database: How parents are sampled (uniform, score-weighted, diversity-aware, recency-aware) is not defined; the effect of sampling policy on convergence speed and final bounds is unexplored.
- Iterative refinement vs multi-parent prompts: The trade-off between shorter prompts (parent-only) and richer context (multiple prior programs) is not systematically studied across tasks or model sizes.
- Batch size and parallelism: The impact of B (number of parents per step) and n (responses per parent) on exploration diversity, evaluator throughput, and RL stability is unknown; scaling laws w.r.t. batching are absent.
- Compute budget fairness: Comparisons to AlphaEvolve/ShinkaEvolve do not normalize for evaluation timeouts, hardware, or total compute; it is unclear whether improvements arise from algorithmic changes vs greater or differently allocated compute.
- Variance and robustness: There is no report of run-to-run variance (seeds), confidence intervals, or failure modes; stability of results across random initializations and different evaluator seeds is untested.
- Transferability scope: Claims of transfer to “unseen tasks” are not quantified across a broad task suite; what properties of tasks (e.g., search space structure, verifier strictness) enable transfer is unclear.
- Minimum capability threshold: The interplay between model capacity and test-time compute is observed but not mapped; a systematic scaling law across model sizes (e.g., 1.5B→8B→larger) is missing.
- Evaluator robustness and “unhackability”: The paper assumes unhackable evaluators but does not show adversarial testing or cross-implementation validation to rule out reward hacking or overfitting to evaluator quirks.
- Evaluation timeouts: The effect of long evaluator timeouts on reward signals, search dynamics, and RL training stability is not analyzed; adaptive or learned timeout policies remain unexplored.
- Objective diversity: The framework optimizes single scalar scores; extension to multi-objective or constrained optimization (e.g., Pareto fronts, feasibility constraints) is not explored.
- Database size vs quality: Memory footprint and retrieval latency for large databases (e.g., 10k) are not measured; alternative retrieval methods (e.g., nearest-neighbor in embedding space, novelty search) are not evaluated.
- Deduplication and stagnation: Mechanisms to detect semantic duplicates or near-identical programs and prevent database bloat are not described; the effect of stagnation filters on long-run progress is unknown.
- Credit assignment in RL with batched, dynamic environments: How training credits are assigned when multiple children are generated per parent and the environment constantly shifts is not spelled out; stability and bias under non-stationarity remain open.
- Theoretical grounding: The probabilistic argument for dynamic environments improving sampling efficiency is heuristic; a formal analysis (assumptions, bounds, counterexamples) is missing.
- Prompt design and meta-advice: The paper acknowledges prompt advice can strongly affect outcomes but does not explore automated advice generation, adaptive prompting, or prompt tuning strategies.
- Mutation representation: Only SEARCH/REPLACE diffs are considered; effectiveness of AST-level edits, structured program transformations, or grammar-guided mutations is not compared.
- Ensemble vs single LLM in ThetaEvolve: The benefits/costs of re-introducing ensembles under ThetaEvolve (especially with RL) are not investigated; do ensembles accelerate or destabilize training?
- Generality beyond mathematical optimization: Applicability to domains without deterministic verifiers (e.g., heuristic or noisy evaluators) remains unclear; how to adapt RL/rewards in such settings is open.
- Reproducibility artifacts: Hardware specs, evaluator implementations, seeds, and exact pipelines are not fully detailed; standardized benchmarks and protocols for fair comparison across evolving systems are needed.
- Cost-benefit of test-time RL: A principled framework for deciding when to use RL vs inference-only (given compute, latency, and expected gains) is not provided; offline vs online training trade-offs remain unquantified.
- Runtime comparability of discovered programs: The 3s vs 75s runtime claim is not normalized across hardware/settings; sensitivity of runtime to initial conditions and evaluator versions is not reported.
- Safety and evaluation integrity: Measures to detect and prevent evaluator-specific exploits, unintended code behaviors, or unsafe program outputs are not discussed; audit tooling is lacking.
Glossary
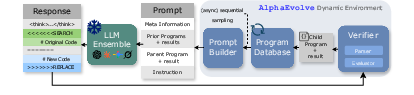
- AlphaEvolve: A closed-source program-evolution framework that uses LLMs and rule-based evaluators to iteratively improve solutions to open mathematical optimization problems. "In detail, AlphaEvolve maintains a program database that stores high-scoring or diversity-promoting programs (e.g., those using different strategies) discovered throughout the evolutionary trajectory."
- AlphaProof: A system demonstrating that test-time reinforcement learning with a formal verifier can improve mathematical reasoning performance beyond inference-only scaling. "AlphaProof~\citep{Hubert2025alphaproof} further shows that when the target task is equipped with a self-contained, rule-based verifier such as LEAN, scaling test-time RL can boost performance beyond standard inference-time scaling."
- Asynchronous pipeline: An execution strategy where evaluation tasks run in parallel to avoid bottlenecks, especially when evaluators are slow. "AlphaEvolve uses an asynchronous pipeline to enable parallel evaluation, as the evaluator often becomes the computational bottleneck due to its potentially large timeout (e.g., AlphaEvolve-v2 sets a 1000-second timeout for the FirstAutoCorrIneq problem)."
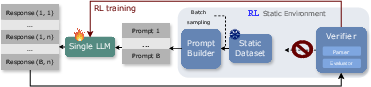
- Batch sampling: Generating multiple responses across a batch of parent programs in one step to increase throughput and efficiency. "ThetaEvolve features a single LLM, a large program database for enhanced exploration, batch sampling for higher throughput, lazy penalties to discourage stagnant outputs, and optional reward shaping for stable training signals, etc."
- Best-known bounds: The strongest recorded quantitative limits (upper or lower) achieved for a given open problem. "ThetaEvolve is the first evolving framework that enable a small open-source model, like DeepSeek-R1-0528-Qwen3-8B, to achieve new best-known bounds on open problems (circle packing and first auto-correlation inequality) mentioned in AlphaEvolve."
- Chain-of-thought (CoT): The model’s explicit reasoning steps generated alongside answers to guide program modifications. "Given the prompt, LLM ensemble would generate a response with reasoning CoT and one or more SEARCH/REPLACE diff blocks that modify the parent program."
- Circle packing (CP): A geometric optimization problem of arranging circles (e.g., in a unit square) to optimize a quantity such as the sum of radii under non-overlap constraints. "We consider two open tasks, circle packing (CP) and the first autocorrelation inequality (FACI), and report the best values mentioned in AlphaEvolve-v2~\citep{alphaevolve-v2} and its variant ShinkaEvolve~\citep{lange2025shinka}."
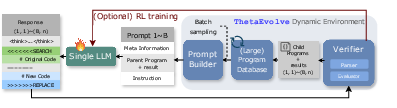
- Dynamic environment: An RL or inference setup where the context (e.g., program database) evolves based on model outputs and evaluations, enabling continual adaptation. "(Top) AlphaEvolve/OpenEvolve Dynamic Environment (inference only)."
- Evaluator: A deterministic, rule-based scoring and validation function mapping candidate solutions/programs to scalar objective values. "First, for the target task we aim to optimize, we have to manually design an unhackable evaluator that maps solutions to scalar scores."
- FACI (First autocorrelation inequality): An optimization problem involving autocorrelation properties where improving bounds is a central goal. "We consider two open tasks, circle packing (CP) and the first autocorrelation inequality (FACI), and report the best values mentioned in AlphaEvolve-v2~\citep{alphaevolve-v2} and its variant ShinkaEvolve~\citep{lange2025shinka}."
- In-context learning: Adapting behavior during inference by leveraging information provided in the prompt (e.g., previous programs and scores) without parameter updates. "We introduce {ThetaEvolve}, an open-source framework that simplifies and extends AlphaEvolve to efficiently scale both in-context learning and Reinforcement Learning (RL) at test time."
- Iterative refinement: A procedure that repeatedly modifies a parent program step-by-step to progressively improve its score. "(Optional) Iterative Refinement. We sample only the parent program, without including additional prior programs as in AlphaEvolve, resulting in a simplified iterative refinement procedure."
- LLM: A parameterized neural LLM capable of generating text and code, used here to propose program edits and reasoning. "Recent advances in LLMs have enabled breakthroughs in mathematical discovery, exemplified by AlphaEvolve, a closed-source system that evolves programs to improve bounds on open problems."
- LEAN: A formal proof assistant providing a rule-based verification environment for mathematical proofs and reasoning. "AlphaProof~\citep{Hubert2025alphaproof} further shows that when the target task is equipped with a self-contained, rule-based verifier such as LEAN, scaling test-time RL can boost performance beyond standard inference-time scaling."
- Lazy penalty: A training penalty that discourages the model from repeatedly emitting previously strong programs without attempting meaningful improvement. "we incorporate a lazy penalty to discourage repeatedly outputting previously strong programs without attempting improvement"
- LLM ensemble: A collection of multiple LLMs used jointly to generate or refine candidate solutions for robustness and diversity. "At each iteration, AlphaEvolve samples several prior programs from this database to construct a prompt, which is then fed to an ensemble of LLMs to generate improved child programs."
- OpenEvolve: An open-source implementation of the AlphaEvolve-style evolutionary pipeline for program optimization. "In this section, we briefly introduce the framework of AlphaEvolve~\citep{novikov2025alphaevolve,alphaevolve-v2} and its open-source implementation, OpenEvolve~\citep{openevolve} (Fig.~\ref{fig:pipeline_comparison} Top)."
- Program database: A memory of previously generated programs and their evaluations that supports resampling and guides future evolution. "They are added into an evolutionary program database, whose purpose is to resample previously explored high-quality candidates for future generations."
- Prompt: The constructed input to an LLM containing task description, prior programs, scores, and instructions for code modification. "The prompt for LLM would be built with these components: the meta-information describing the task and relevant insights, one or some prior programs the current parent program to be improved, the evaluation scores of these programs, and final instructions including the code-replacement rules, etc."
- Reinforcement learning (RL): A training paradigm where the model learns from reward signals derived from verifiable evaluators to improve its policy of generating program edits. "We introduce {ThetaEvolve}, an open-source framework that simplifies and extends AlphaEvolve to efficiently scale both in-context learning and Reinforcement Learning (RL) at test time"
- Reward shaping: Modifying the reward function (e.g., scaling or clipping) to stabilize and guide RL training. "add optional reward shaping to keep training rewards within a reasonable range"
- SEARCH/REPLACE diff blocks: Structured edit directives (diffs) used to specify code modifications to the parent program. "Given the prompt, LLM ensemble would generate a response with reasoning CoT and one or more SEARCH/REPLACE diff blocks that modify the parent program."
- SGLang: An optimized serving framework for efficient batched LLM inference. "it cannot fully leverage optimized batched inference engines such as vLLM~\citep{kwon2023vllm} or SGLang~\citep{zheng2024sglang}."
- ShinkaEvolve: A variant of the AlphaEvolve pipeline using ensembles of advanced closed-source models. "Although recent efforts have produced open-source variants such as OpenEvolve~\citep{openevolve} and ShinkaEvolve~\citep{lange2025shinka}, these pipelines are still complex, with many hyperparameters that are not fully ablated, leaving it unclear which components are truly essential."
- Static environment: An RL setup where the problem distribution and context remain fixed throughout training. "(Middle) RL Static Environment."
- Test-time compute: The computational resources used during inference (e.g., number of samples, evaluation budget) rather than during training. "As we scale the test-time compute, AlphaEvolve can continually learn from its own frontier attempts on open problems, while avoiding unbounded growth in context length."
- ThetaEvolve: An open-source framework that unifies evolutionary inference and test-time RL to improve programs on open problems, featuring batching, large databases, and training-friendly penalties. "We introduce {ThetaEvolve}, an open-source framework that simplifies and extends AlphaEvolve to efficiently scale both in-context learning and Reinforcement Learning (RL) at test time, allowing models to continually learn from their experiences in improving open optimization problems."
- vLLM: A high-throughput LLM inference engine optimized for batched generation. "it cannot fully leverage optimized batched inference engines such as vLLM~\citep{kwon2023vllm} or SGLang~\citep{zheng2024sglang}."
Practical Applications
Overview
ThetaEvolve is an open-source framework that turns “program evolution” on verifiable objectives into an efficient test-time learning loop. It simplifies AlphaEvolve by using a single LLM, a large program database (dynamic memory), batch sampling/generation for high throughput, and adds lazy penalties plus optional reward shaping to support reinforcement learning (RL) at test time. Experiments show small, open models can improve best-known bounds on open problems (e.g., circle packing, first autocorrelation inequality), and RL-trained checkpoints transfer to unseen tasks.
Below are practical, real-world applications that leverage these findings and design choices. Each item lists sector(s), what tools/products/workflows could emerge, and assumptions/dependencies that affect feasibility.
Immediate Applications
These are deployable today using the released code, open-source LLMs, and standard compute, provided the problem has a reliable evaluator.
- Academic research on open problems (math, algorithms, discrete optimization)
- Sectors: Academia, Software (research tooling)
- Tools/workflows: “Research Copilot for Open Problems” that uses ThetaEvolve to iteratively propose and verify programmatic constructions (e.g., combinatorial objects, bounds proofs by construction); shared program databases that accumulate partial progress; batch sampling to explore multiple promising lines in parallel.
- Assumptions/dependencies: Requires unhackable, deterministic evaluators; initial seeds and clear meta-information; modest GPU (batched LLM inference) and CPU (asynchronous evaluators) orchestration.
- Operations Research (OR) heuristic discovery for routing, packing, and scheduling
- Sectors: Manufacturing, Logistics, Transportation, Cloud/Datacenter Ops
- Tools/workflows: “AutoHeuristic Studio” that evolves domain-specific heuristics or meta-heuristic parameterizations against simulators/benchmarks; integration with MILP/CP/heuristic solvers (e.g., evolve insertion strategies, local search neighborhoods).
- Assumptions/dependencies: Robust benchmark/evaluator suites; guardrails to prevent reward hacking (e.g., constraints checks); database scaling (10k+ candidates) to reach strong performance.
- Code optimization and autotuning in CI/CD
- Sectors: Software Engineering, DevOps
- Tools/workflows: IDE/CI plugin that evolves code diffs, compiler flags, or algorithmic variants to reduce latency/memory while passing tests; lazy penalties discourage resubmitting trivial variants; reward shaping stabilizes noisy performance metrics.
- Assumptions/dependencies: Stable perf benchmarks; sandboxed build/execution; strict equivalence tests to prevent “optimizing away” correctness; batching via vLLM/SGLang to keep costs low.
- Formal methods and automated theorem proving assistance
- Sectors: Academia, Safety-critical Software
- Tools/workflows: Evolving proof scripts/tactics for LEAN/Coq/Isabelle with verifiable checkers; test-time RL loop to internalize tactic-selection strategies that generalize to new lemmas.
- Assumptions/dependencies: Complete, deterministic proof checkers; careful prompt/program interfaces to avoid spurious proofs.
- Software security: fuzzing and test generation
- Sectors: Security, Software
- Tools/workflows: Evolve inputs/programs maximizing code coverage/crash discovery; plug into sanitizers/coverage tools as evaluators; dynamic databases retain diverse “interesting seeds.”
- Assumptions/dependencies: Accurate coverage/crash detectors; isolation/sandboxing; policies to prevent reward gaming (e.g., false positives).
- Data pipelines and SQL query optimization
- Sectors: Data Engineering, Analytics
- Tools/workflows: Evolve SQL rewrites or dataflow transformations that return equivalent results faster (evaluator: latency/plan cost + result equivalence tests); batch-select parent candidates across workloads.
- Assumptions/dependencies: Equivalence checking or strong differential testing; workload-representative evaluators to reduce overfitting.
- AutoML/ML pipeline orchestration with verifiable metrics
- Sectors: ML/AI Platforms
- Tools/workflows: Evolve data preprocessing scripts, feature pipelines, or training recipes; evaluator uses cross-validation/generalization checks; lazy penalties prevent trivial replays; checkpoints capture transferable “evolving strategies.”
- Assumptions/dependencies: Overfitting controls (holdouts, time-splits); robust metric definitions; compute orchestration for GPU/CPU loops.
- Digital-twin optimization in manufacturing and buildings
- Sectors: Manufacturing, Energy/Buildings
- Tools/workflows: Evolve control policies or schedulers in simulators (e.g., HVAC tuning, job-shop scheduling); asynchronous evaluators run long simulations while batched LLM proposes new candidates.
- Assumptions/dependencies: High-fidelity digital twins; safety constraints encoded in evaluators; sim-to-real gap awareness before deployment.
- Educational content and grader generation
- Sectors: Education, EdTech
- Tools/workflows: Evolve problem generators and graders with verifiable solution checkers; database retains diverse, pedagogically valuable items; RL checkpoints that transfer “better-evolving” patterns to new topics.
- Assumptions/dependencies: Trusted solution verifiers; bias/fairness checks; controls on content difficulty progression.
- Finance research sandbox (backtesting and strategy parameter evolution)
- Sectors: Finance (R&D), Quant Research
- Tools/workflows: Evolve strategy code/parameter sets in strict walk-forward or synthetic markets; database catalogs strategies by regimes; lazy penalties discourage degenerate repeaters.
- Assumptions/dependencies: Strong anti-overfitting protocols (out-of-sample, slippage/fees modeling, regime splits); compliance and governance; never deploy without independent validation.
Long-Term Applications
These need further research, robustness, scaling, or safety/regulatory work before routine deployment.
- Closed-loop real-world robotics and autonomous systems
- Sectors: Robotics, Mobility, Warehousing
- Tools/products: Simulator-to-real evolution of planners/controllers with online adaptation; “Evolve-at-the-edge” agents with persistent databases.
- Assumptions/dependencies: Reliable safety constraints and verifiable simulators; sim-to-real transfer; on-device compute and memory management; risk assessment frameworks.
- Clinical decision support and personalized treatment policies
- Sectors: Healthcare
- Tools/products: Evolve interpretable protocols in silico (evaluator: causal models or digital twins) before clinical trials; RL checkpoints capture general strategies across cohorts.
- Assumptions/dependencies: High-fidelity, validated clinical simulators; strict ethical, regulatory, and causal validity requirements; extensive oversight.
- Power grid and market operations
- Sectors: Energy, Utilities
- Tools/products: Evolve dispatch/scheduling policies using grid simulators and market models; integrate safety and reliability constraints into evaluators.
- Assumptions/dependencies: Accurate, real-time digital twins; robust fail-safes; regulatory approvals; resilience to distributional shifts.
- National/municipal policy simulation and design
- Sectors: Public Policy, Urban Planning
- Tools/products: Evolve policy programs in agent-based or system dynamics simulators optimizing multi-objective social metrics; databases maintain diverse “policy archetypes.”
- Assumptions/dependencies: Model validity and transparency; governance for fairness and externalities; contested objective functions.
- Materials and drug discovery via expensive simulations
- Sectors: Materials Science, Pharma
- Tools/products: Evolution over synthesis plans or structural generators with DFT/MD docking as evaluators; smart batching and lazy penalties to ration costly evaluations.
- Assumptions/dependencies: Massive compute or surrogate models; uncertainty-aware evaluators; lab-in-the-loop validation.
- Multi-agent coordination and mechanism design
- Sectors: Markets, Logistics, Online Platforms
- Tools/products: Evolve auction mechanisms, incentive schemes, or coordination protocols in agent-based simulators.
- Assumptions/dependencies: Faithful agent behavior models; equilibrium verification; robustness to adversarial behavior.
- Legacy codebase modernization with formal guarantees
- Sectors: Enterprise Software, Government IT
- Tools/products: Evolve refactorings/transpilers guided by formal specs and contract tests; verifiers act as guards of behavioral equivalence.
- Assumptions/dependencies: Availability of formal specs or high-coverage property tests; scalable equivalence checking; organizational change management.
- General “Evolve-as-a-Service” platforms and marketplaces
- Sectors: Software Platforms, Cloud, Open Science
- Tools/products: Managed program databases, evaluator authoring kits, compute orchestration (batched GPU + async CPU), and governance tooling; shareable checkpoints and reproducible runs.
- Assumptions/dependencies: Standardized evaluator schemas; security isolation; attribution/IP frameworks for discovered artifacts; cost controls and carbon accounting.
- Self-improving agents for on-device personalization
- Sectors: Consumer Devices, Edge AI
- Tools/products: Small LLMs that evolve workflows (e.g., email triage rules, local automations) with local evaluators (user satisfaction proxies) and private program databases.
- Assumptions/dependencies: Privacy-preserving evaluators; lightweight, robust RL at test time; UX for oversight and rollback.
- Automated conjecture generation and proof at scale
- Sectors: Academia, Scientific Knowledge
- Tools/products: Joint evolution of conjectures, constructions, and proof scripts with verifiable proof assistants; cross-task transfer from RL-trained checkpoints.
- Assumptions/dependencies: Sophisticated evaluators for conjecture plausibility and proof checking; community validation and curation.
Cross-Cutting Notes (assumptions and dependencies)
- Verifiable, unhackable evaluators are the primary dependency; the framework’s success hinges on deterministic, trustworthy reward signals.
- Compute orchestration matters: batched LLM generation (e.g., vLLM/SGLang) + asynchronous CPU-heavy evaluators + large program databases (10k+) are key for scaling.
- Safety and guardrails are essential for real-world deployment: constraints in evaluators, sandboxing, and reward-hacking prevention (lazy penalties, audits).
- RL at test time can both accelerate progress and produce transferable checkpoints; however, it requires stable reward shaping and careful hyperparameter tuning.
- Small open models can match or surpass ensemble-based systems on some tasks when test-time compute and databases are scaled appropriately, enabling cost-effective on-prem and privacy-preserving deployments.
Collections
Sign up for free to add this paper to one or more collections.