Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Abstract: Diffusion-based LLMs (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of ~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Stable-DiffCoder: Pushing the Frontier of Code Diffusion LLM”
What is this paper about?
This paper introduces Stable-DiffCoder, a new kind of AI model that writes and edits computer code. It uses a “diffusion” approach that treats coding like solving a fill‑in‑the‑blank puzzle in many small steps, instead of writing everything strictly from left to right. The big idea: with the right training tricks, this diffusion-style model can learn code better than traditional models of the same size and using the same data.
What questions were the researchers trying to answer?
In plain terms, they asked:
- Can a diffusion-style code model learn as well as, or better than, a normal left‑to‑right model when both get the same data and computer power?
- What is the best way to train a diffusion model so it learns real coding “rules” (reasoning) instead of just memorizing patterns?
- How can we make training stable and efficient so the model doesn’t get confused or stuck?
How did they study it? (Methods explained with simple analogies)
To compare fairly, they used the same building blocks and data as a strong normal (autoregressive) code model called Seed-Coder, then trained a diffusion version on top of it. Here’s what those terms mean in everyday language:
- Autoregressive (AR) model: Think of writing a sentence by adding one letter/word at a time from left to right. That’s how most code AIs work: predict the next token step by step.
- Diffusion model for code: Imagine a worksheet where parts of the code are covered with [MASK] blanks. The model practices by filling in those blanks correctly. It repeats this with many different “masked” versions of the same code, which helps it learn more from each example—like solving many variations of the same puzzle.
- Block diffusion: Instead of masking random spots all over, the model masks a small chunk (a “block”) of code at a time—like focusing on repairing a sentence fragment while seeing the rest of the page. In this paper, the block size is small (4 tokens), which keeps the task clear and realistic.
- Continual pretraining (CPT): After starting with the normal model’s knowledge, they keep training it on lots more code (1.3 trillion tokens) so it gets better at coding.
- Warmup: Like learning to swim by starting in the shallow end, they begin training with easy puzzles (light masking) and slowly increase difficulty. This prevents training from becoming unstable.
- Block-wise clipped noise schedule: This is a fancy way of saying “make sure each practice round actually has something to fill in.” If your homework page sometimes had zero blanks, you wouldn’t learn much. They adjust the masking so each small block has useful blanks—never too few, never too many.
- Training–inference alignment: Practice how you’ll play. They make sure the way the model trains (fill small blocks with context) matches how it will be used later (generate or edit small chunks of code at a time). That helps the knowledge transfer cleanly into real performance.
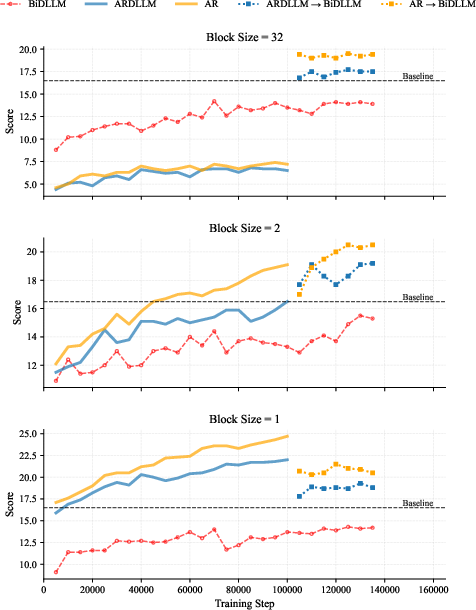
They also tested different training curricula to see what works best:
- Train as a normal left‑to‑right model first, then switch to diffusion (best overall).
- Train as a diffusion model with left‑to‑right flavor, then switch to fully bidirectional diffusion (good).
- Switch directly to fully bidirectional diffusion from the start (worse).
The reason: clean, realistic practice contexts teach true reasoning rules; heavy, random masking creates confusing contexts that are hard to learn from.
What did they find, and why is it important?
Main results:
- Using the same data and architecture, Stable-DiffCoder beats its normal left‑to‑right counterpart (Seed-Coder) on many coding benchmarks.
- It sets new top results among similar‑sized (~8B) diffusion-based code models.
- It is especially strong at structured tasks like editing code and reasoning through steps—things programmers do a lot.
- The diffusion training naturally “reuses” each example in many different ways, which helps with rarer languages or low-data situations.
Why this matters:
- It shows that diffusion-style training isn’t just a different way to generate text—it can actually improve the model’s coding ability under the same budget.
- Small-block diffusion with a careful warmup and better masking schedule gives stable, efficient learning.
- The approach better matches how real developers work: filling in parts, editing earlier lines after seeing later context, and working in chunks.
What is the potential impact?
If widely adopted, this training style could:
- Make code AIs better at editing and reasoning, not just writing from scratch.
- Speed up code generation by allowing more parallel (block-wise) writing.
- Improve support for less common programming languages through data “augmentation” (learning more from fewer examples).
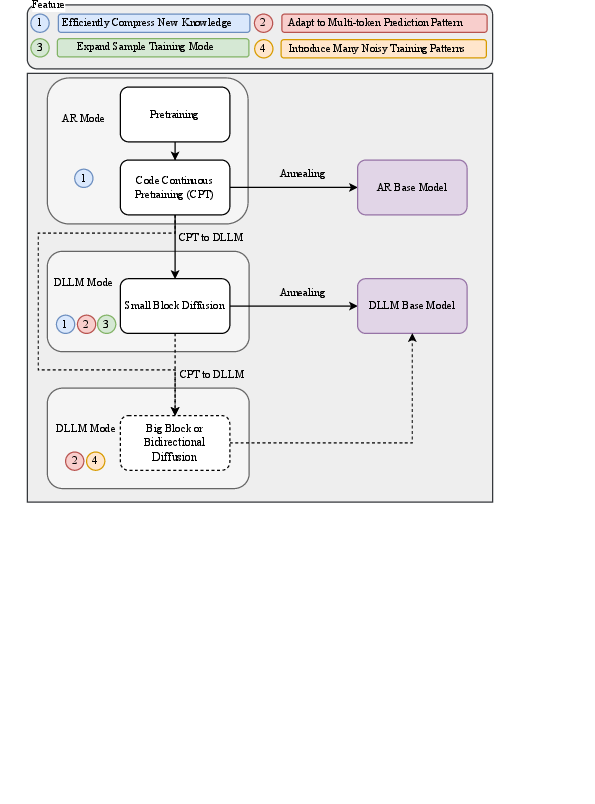
- Provide a practical recipe: first compress new knowledge with a normal model, then strengthen it with small-block diffusion training using the warmup and block-aware masking schedule.
In short, Stable-DiffCoder suggests a clearer path to building smarter, more flexible code models that learn efficiently and work more like real programmers edit and refine code.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps, limitations, and open questions left unresolved by the paper that future work could address:
- Inference efficiency is unmeasured: no quantitative results on latency, throughput, parallel decoding speed, or end-to-end time-to-pass vs AR baselines.
- Final model ablations on block size are missing: Stable-DiffCoder uses block size 4 during CPT, but accuracy/stability trade-offs across block sizes (e.g., 1–32) are not reported for the 8B model.
- The proposed block-wise clipped noise schedule and fallback rule lack ablations: no comparison to alternative schedules or analysis of their effects on convergence, gradient stability, and downstream accuracy.
- Warmup design is under-specified and untested across settings: sensitivity to warmup hyperparameters (u_init, S_warmup, mask progression, LR schedule), hardware/precision, and optimizer is not quantified.
- Training–inference alignment is argued but not measured: no empirical characterization of the context distributions C_train vs C_infer, nor metrics like conditional entropy H(X_i|c) or candidate set size K(c) to validate alignment claims.
- The “token reasoning knowledge” framework remains conceptual: there is no empirical estimation of K(c), conditional entropy, or regime prevalence (reasoning/correlation/noise) on real code data.
- Scaling laws are unknown: benefits are shown at ~8B (and curriculum at 2.5B), but it is unclear whether diffusion advantages persist/improve at larger scales (14B+, 32B+, 70B+) under matched compute.
- DLLM inference procedure is unspecified: number of denoising steps, block decoding strategy details, and accuracy–compute trade-offs (steps vs pass@k) are not reported.
- Data efficiency claims are untested: no controlled learning curves under reduced token budgets or low-data regimes to demonstrate improved sample efficiency vs AR.
- Low-resource language gains are not isolated: MultiPL-E improvements are reported, but there’s no correlation analysis with training data availability per language or controlled low-resource experiments.
- Code editing/any-order modeling claims lack dedicated evaluation: no benchmarks on code infilling, multi-span edits, patch generation, or structured editing beyond CRUXEval-like tasks.
- External validity on real repositories is limited: evaluations use unit-test-centric tasks; results on large-context, repository-level tasks (e.g., bug fixing in context, refactoring, code search) are absent.
- Safety and reliability are unaddressed: no analysis of security vulnerabilities, unsafe API usage, license violations, or compliance in generated code.
- Compute parity and checkpoint comparability are unclear: despite “same data and architecture,” the exact training budgets, annealing status, and matched AR training baselines for CPT/SFT are not fully specified.
- Packed-sequence mutual visibility introduces atypical contexts: enabling attention across packed samples may cause cross-sample leakage; its impact on generalization, contamination risk, or evaluation bias is not studied.
- Data contamination audits are missing: no check for overlap between training data and HumanEval/MBPP/MultiPL-E tasks, which could inflate reported gains.
- Logit-shift vs no-shift choice is not analyzed: the final model adopts no-shift, but there is no systematic comparison of parametrizations on training stability and code accuracy.
- Only contiguous block diffusion is explored: the impact of non-contiguous/multi-span diffusion (important for scattered edits) is unknown.
- Loss weighting w(t) is only modified during warmup: post-warmup alternatives (adaptive weights, block-length-aware weighting) and their effects are not investigated.
- Representation dynamics after mask change are not examined: changing attention from causal to bidirectional is noted to cause instability, but layer-wise representation drift/adaptation is not analyzed.
- Benchmark breadth is limited: beyond HumanEval/MBPP/CRUXEval/MultiPL-E, broader code reasoning/generation tasks (e.g., APPS, CodeBench) and pass@k metrics are not reported.
- Decoding strategy space is narrow: only left-to-right block-wise decoding is considered; any-order sampling, parallel block selection policies, and their quality–speed trade-offs are unexplored.
- Resource usage is unreported: memory footprint, training/inference cost, and total compute vs AR baselines are not measured, hindering cost–benefit assessment.
- Reproducibility details are incomplete: precise hyperparameters (optimizer, LR schedules, corruption kernel specifics, sampler settings, denoising steps, batch sizes) are not fully disclosed.
Glossary
- absorbing diffusion: A discrete diffusion setup where a special mask token is an absorbing state, so each masked position predicts its original value. "Since the no-logit-shift formulation is more consistent with the absorbing diffusion paradigm, where each masked position predicts itself and the input and prediction targets are aligned at both the token and sentence levels, we follow a no-logit-shift design similar to that used in LLADA and SDAR."
- annealing: A training phase where learning schedules or objectives are gradually adjusted, often to stabilize or refine training. "Starting from the AR SeedâCoder checkpoint before annealing, we perform continual pretraining on 1.3T tokens using smallâblock diffusion (block size 4)..."
- any-order modeling: Generative modeling that allows predicting tokens in arbitrary order rather than strictly left-to-right. "Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning..."
- autoregressive (AR): A modeling approach that factorizes the joint probability left-to-right, predicting each token conditioned on previous ones. "Autoregressive (AR) LLMs have achieved strong results in natural language and code by modeling sequences leftâtoâright..."
- bidirectional DLLM: A diffusion LLM that conditions on both left and right context (full attention) during denoising. "directly CPT the AR checkpoint into a bidirectional DLLM and train new knowledge in that regime."
- block diffusion: A diffusion variant that corrupts and denoises contiguous spans (blocks) rather than entire sequences. "we introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline."
- block-wise clipped noise schedule: A noise schedule for block diffusion that clips the per-block mask rate to ensure non-trivial supervision within each block. "we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule."
- block-wise decoding: Generating multiple tokens at a time as contiguous spans instead of token-by-token decoding. "we consider the following curricula for learning new knowledge under the same compute budget, and evaluate them using block-wise decoding in the style of LLaDA"
- causal attention: An attention mask that only allows attending to previous positions, enforcing left-to-right dependency. "with causal attention, tokens later in the block cannot influence earlier ones"
- continual pretraining (CPT): Further pretraining a model on additional data after an initial pretraining phase. "we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup"
- CRUXEval: A benchmark for precise code reasoning with I/O-based tasks. "CRUXEval \citep{gu2024cruxeval} provides 800 Python functions with I/O examples and evaluates two tasks: CRUXEval-I (predict inputs given outputs) and CRUXEval-O (predict outputs given inputs)."
- denoiser: The neural network component trained to reconstruct clean tokens from corrupted inputs in diffusion models. "discrete diffusion LMs optimize a variational evidence lower bound by corrupting observed sequences (e.g., by randomly masking tokens) and training a denoiser to reconstruct the clean data"
- diffusion-based LLM (DLLM): A LLM trained via iterative noising and denoising (masking and reconstruction) rather than next-token prediction. "Diffusion-based LLMs (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models..."
- discrete diffusion: Diffusion modeling on discrete token spaces using masking or similar corruptions. "Inspired by continuous diffusion models in vision, discrete diffusion LMs optimize a variational evidence lower bound..."
- ELBO: The evidence lower bound, an optimization objective used for likelihood-based training in variational/diffusion frameworks. "the ELBO-motivated loss weight in the DLLM objective (Eq.~\ref{eq:dlm-loss}), where can be large at low masking ratios..."
- FlashAttention: An optimized attention kernel that assumes a fixed mask for speed and memory efficiency. "Rather than annealing the attention mask (which is inconvenient for highly optimized kernels such as FlashAttention that assume a fixed mask)..."
- forward noising process: The corruption process that progressively adds noise (e.g., masks) to clean sequences. "The forward noising process progressively replaces tokens with [MASK], while the reverse denoising process iteratively reconstructs the clean text step by step."
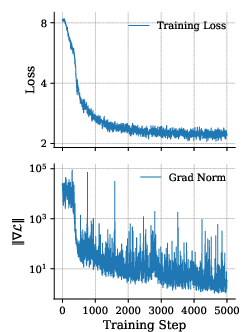
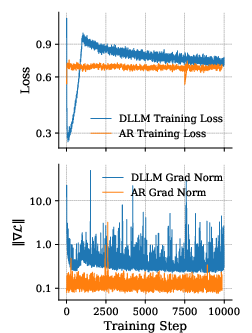
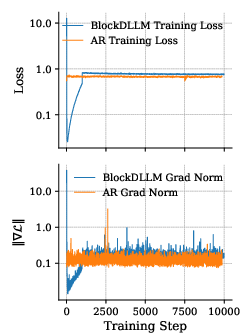
- gradient-norm spike: A sudden increase in the gradient magnitude during training that can destabilize optimization. "Even under this minimal change, naive ARâDLLM CPT shows a high initial loss and large gradient-norm spikes."
- HumanEval+: An expanded version of HumanEval with much larger test suites for stricter correctness evaluation. "HumanEval+ from EvalPlus \citep{liu2023your} substantially expands the test suites (about ) for stricter functional correctness."
- instruction-tuned: Fine-tuned to follow natural language instructions beyond base pretraining. "Across both base and instructionâtuned settings, Stable-DiffCoder almost uniformly surpasses its AR counterpart SeedâCoder of the same size"
- logit-shift parametrization: A training parametrization that shifts logits (pre-softmax outputs), often used to stabilize diffusion training. "we reuse the AR token head and logit-shift parametrization, and only change the attention pattern..."
- masked diffusion: A discrete diffusion approach that uses a [MASK] token to corrupt inputs and learn to reconstruct them. "Masked diffusion LLMs (DLLMs) have recently emerged as a promising non-AR alternative for text and code generation"
- masking ratio: The fraction of tokens masked during corruption at a given diffusion timestep. "the ELBO-motivated loss weight in the DLLM objective (Eq.~\ref{eq:dlm-loss}), where can be large at low masking ratios"
- MBPP+: An expanded version of the MBPP benchmark with augmented tests for more reliable evaluation. "MBPP+, which augments the tests (about ) for more reliable pass@1 estimation"
- MultiPL-E: A multilingual code generation benchmark extending HumanEval to many programming languages. "MultiPL-E \citep{cassano2023multiple}, which extends HumanEval to 18 languages."
- non-autoregressive: A generation paradigm that does not require strict left-to-right decoding. "their strictly sequential decoding underutilizes the inherently nonâautoregressive nature of code"
- packed sequences: A batching/training technique that concatenates multiple sequences into one context window for efficiency. "using a context length of 8192 with packed sequences."
- RADD: A particular theoretical formulation for masked diffusion in discrete spaces. "In the RADD~\citep{ou2025absorbingdiscretediffusionsecretly} formulation, the concrete score at time for coordinate takes the below form:"
- random masking: Stochastic masking patterns used to corrupt data during diffusion training. "Although random masking can dramatically improve data reusability for diffusion LLMs..."
- reverse denoising process: The iterative reconstruction procedure that removes noise (masks) to recover clean tokens. "The forward noising process progressively replaces tokens with [MASK], while the reverse denoising process iteratively reconstructs the clean text step by step."
- small-block diffusion: Block diffusion where the masked/generated block is very short (e.g., a few tokens). "we perform continual pretraining on 1.3T tokens using smallâblock diffusion (block size 4)"
- supervised fine-tuning (SFT): A stage where the model is fine-tuned on labeled instruction data after pretraining. "The supervised fine-tuning (SFT) stage fully reuses the original Seed-Coder SFT dataset."
- token-level cross-entropy: The standard next-token prediction loss used in AR models. "We typically parameterize with a Transformer, and train by maximizing token-level cross-entropy."
- token reasoning knowledge: The conditional knowledge about likely next tokens given specific contexts, formalized to study learning efficiency. "We define the token reasoning knowledge contained in a training example with context as the conditional distribution of the next token..."
- uniform prior (over noise states): A prior distribution assuming all corrupted states are equally likely at the terminal diffusion step. "where is typically a uniform prior over noise states"
- warmup: A staged easing-in period (e.g., with lower corruption) to stabilize training before reaching full objective difficulty. "During warmup, we cap the maximum corruption level: "
- weighting coefficient w(t): A time-dependent weight applied to the loss under diffusion objectives. "and is a weighting coefficient that depends on the corruption level."
Practical Applications
Immediate Applications
The following applications can be deployed with current tools and infrastructure, leveraging Stable-DiffCoder’s block diffusion training, warmup procedure, and block-wise clipped noise scheduling, along with the released code and models.
- Software development: IDE block-infill coding and structured editing
- Sectors: software, education, robotics, finance, energy (infrastructure-as-code), healthcare (ETL, analytics scripts)
- What: Integrate Stable-DiffCoder into IDEs for non-sequential, multi-line infill, rapid refactoring, and structured edits (e.g., function rewrites, signature changes, documentation insertion) via any-order/parallel block decoding.
- Why enabled: Block diffusion yields stronger structured editing and reasoning; small-block training aligns with infill and edit contexts a developer actually uses.
- Tools/workflows: “Stable-DiffCoder Infill” plugin; “Refine-by-Denoise” mode where developers mask spans and iteratively denoise; parallel suggestion panes for alternative completions.
- Assumptions/dependencies: IDE integration (LSP or plugin APIs), inference kernels that support block or iterative decoding; guardrails to compile/run locally.
- Code review and PR diff assistance
- Sectors: software, open source, enterprise IT
- What: Suggest diffs for pull requests (PRs), generate commit messages, propose targeted edits earlier in files after seeing later context, and annotate rationale.
- Why enabled: Any-order modeling supports revising earlier segments using later context; diffusion-style denoising produces candidate diffs with high locality.
- Tools/workflows: “PR-Diff Suggester” bot that posts patch suggestions with test outcomes; pre-commit hooks that propose small, reviewable edits.
- Assumptions/dependencies: Repository access, unit tests or linters for verification, clear code ownership policies.
- CI/CD auto-patch from failing tests
- Sectors: software, fintech back-office tooling, data engineering
- What: On test failures, automatically generate minimal block-level patches, run tests, and open PRs with localized changes and explanations.
- Why enabled: Block diffusion focuses on contiguous spans and benefits execution-centric reasoning (CRUXEval gains); clipped noise schedule ensures non-trivial supervision per step, improving patch quality.
- Tools/workflows: “PatchBot” CI action; triage dashboards ranking candidate fixes by pass@k.
- Assumptions/dependencies: Reliable test suites; sandboxed execution; human-in-the-loop approval.
- Low-resource and niche language codegen
- Sectors: legacy systems (COBOL), embedded/robotics (C/C++), internal DSLs, healthcare scripting (FHIR transforms)
- What: Improve generation quality for underrepresented languages via diffusion’s data-augmentation effect and small-block CPT.
- Why enabled: Training reveals many corruption patterns per example, extracting more signal from scarce, high-quality samples.
- Tools/workflows: “LowResourceCoder” finetunes for COBOL, ABAP, VHDL, ROS nodes; bilingual migration helpers (e.g., PHP→TS).
- Assumptions/dependencies: Curated seed corpora; evaluation harnesses in the target language; license-compliant datasets.
- Safer code suggestions and vulnerability patch candidates
- Sectors: security, compliance, finance, healthcare IT
- What: Propose minimal diffs to address static analyzer findings (e.g., injection surfaces, unsafe cryptography) with tests.
- Why enabled: Block-wise generation favors surgical edits; diffusion training improves structured reasoning around sensitive code paths.
- Tools/workflows: Security scanners that invoke Stable-DiffCoder to propose remediations; attach unit tests or property checks.
- Assumptions/dependencies: Up-to-date vulnerability heuristics; human review; secure code policies.
- Training pipeline upgrades for teams building code LLMs
- Sectors: AI/ML (model providers), enterprise MLOps
- What: Adopt the AR→small-block DLLM CPT curriculum, warmup (capped corruption + unweighted loss), and block-wise clipped noise schedule to improve stability and quality under a fixed budget.
- Why enabled: Paper shows consistent gains vs. AR baselines with the same data/architecture; warmup mitigates gradient spikes; clipped noise guarantees supervision per step.
- Tools/workflows: “DLLM Trainer Kit” integrating warmup and block-aware masking; reproducible recipes from the authors’ GitHub/HF releases.
- Assumptions/dependencies: Access to pre-annealing AR checkpoints; training compute; framework support for packed sequences and diffusion masking.
- Educational coding assistants and autograders
- Sectors: education, upskilling, MOOCs
- What: Generate hints via masked-span infill; show multiple valid refactorings; provide stepwise denoise feedback aligned with students’ partial solutions.
- Why enabled: Small-block contexts closely match classroom infill/edit tasks; improved reasoning on execution-centric tasks.
- Tools/workflows: LMS plugins; sandboxed code runners; exercise authoring tools that specify mask regions.
- Assumptions/dependencies: Plagiarism mitigation; dataset policies for student code; accessibility features.
- Data/compute efficiency and sustainability guidance
- Sectors: policy within enterprises (IT sustainability), platform teams
- What: Select decoding strategies and block sizes to reduce latency/energy for codegen services; prefer non-sequential decoding for long completions.
- Why enabled: Diffusion enables parallel or partially parallel decoding with higher speed ceilings.
- Tools/workflows: Serving playbooks with block-size tuning; cost/latency/carbon dashboards.
- Assumptions/dependencies: Optimized kernels for block generation; profiling in production environments.
Long-Term Applications
These leverage Stable-DiffCoder’s paradigm but may require further research, scaling, or engineering.
- Large-scale, parallel program synthesis and refactoring
- Sectors: software at scale, monorepo maintenance, automotive/embedded
- What: Refactor large codebases (APIs, dependency upgrades, style conformance) via parallel block generation across many files, with iterative denoising rounds and verification loops.
- Why enabled: Non-sequential, block-wise decoding scales to parallel editing; curriculum aligns training with left-conditioned reasoning while enabling broader bidirectional contexts after CPT.
- Tools/workflows: “BlockRefactor” orchestrator integrating static analysis, typecheckers, and test sharding; map-reduce style refactoring passes.
- Assumptions/dependencies: Advanced orchestration, robust test coverage, formal approval workflows.
- Cross-language migration and modernization assistants
- Sectors: finance (COBOL→Java), telecom, robotics (C++→Rust), web (PHP→TS)
- What: End-to-end migration with equivalence checks, mixed-language infill, and gradual replacement strategies.
- Why enabled: Diffusion training’s augmentation helps in low-resource bilingual mappings; any-order modeling supports back-and-forth edits across translation boundaries.
- Tools/workflows: Migration pipelines with conformance tests and semantic diffing; dual-runtime validators.
- Assumptions/dependencies: Parallel corpora or alignment strategies; formal verification or property-based tests.
- Autonomous repair agents integrated with observability
- Sectors: SRE/DevOps, fintech, e-commerce
- What: Agents that consume logs/metrics, localize faults, propose patches, and run canary tests—escalating to humans with diffs and risk analysis.
- Why enabled: Block-local patch proposals; improved reasoning from diffusion CPT; faster iteration via parallel decoding.
- Tools/workflows: “Self-Heal” pipelines that couple APM, incident triage, and code patch loops.
- Assumptions/dependencies: Strong guardrails; rollback and kill-switches; compliance and audit trails.
- Constraint-aware synthesis with formal methods
- Sectors: safety-critical systems, aerospace, medical devices
- What: Generate code under hard constraints (types, contracts, temporal properties) and iteratively denoise toward verified solutions.
- Why enabled: Iterative denoising fits naturally with refine-check cycles; structured token reasoning supports rule-like mappings.
- Tools/workflows: Tight integration with SMT solvers, model checkers, and contract systems (e.g., Dafny, TLA+, SPARK).
- Assumptions/dependencies: Scalable verification engines; datasets annotated with formal specs; extended training for constraint satisfaction.
- Standardized governance for AI-generated code and auditing
- Sectors: policy, compliance (finance, gov, healthcare)
- What: Auditable generation traces (mask schedules, denoise steps) to support reproducibility, accountability, and provenance reporting.
- Why enabled: Diffusion sampling naturally records intermediate states; block-level diffs facilitate auditability.
- Tools/workflows: “Genesis Logs” attached to PRs; policy templates specifying acceptable generation configurations.
- Assumptions/dependencies: Standards for trace retention; privacy and IP controls; regulator acceptance.
- Domain expansion to structured non-code artifacts
- Sectors: data engineering (SQL), MLOps (YAML), infra (Terraform), spreadsheets (formulas)
- What: Masked-span denoising for configuration and query synthesis, partial edits, and policy-constrained updates.
- Why enabled: Structured tokens and local semantics suit block diffusion; small-block contexts map to typical edit patterns.
- Tools/workflows: “IaC Refiner,” “SQL Denoiser,” and spreadsheet formula assistants for partial cell/range infill.
- Assumptions/dependencies: Domain-specific validators; schema-aware prompts; curated training data.
- Hardware/software co-design for diffusion inference
- Sectors: AI infrastructure, cloud providers, edge devices
- What: Kernels and serving stacks optimized for block-wise, partially parallel decoding with dynamic masking.
- Why enabled: Potential speed/latency advantages depend on systems-level optimizations.
- Tools/workflows: FlashAttention-like kernels adapted to fixed/full masks; scheduling policies for multi-block sampling.
- Assumptions/dependencies: Vendor support; batching strategies; memory-efficient mask handling.
- Adaptive teaching systems and assessments
- Sectors: education, workforce development
- What: Curricula that progressively increase “mask difficulty,” mirroring the warmup schedule; assessments that measure reasoning via masked contexts.
- Why enabled: The paper’s curriculum and reasoning regimes (reasoning/correlation/noise) provide a pedagogical scaffold.
- Tools/workflows: Dynamic exercise generators; analytics on context difficulty vs. student mastery.
- Assumptions/dependencies: Ethical use of student data; fairness and accessibility research.
Cross-cutting assumptions and dependencies
- Data and licensing: Gains assume access to quality, license-compliant code corpora; low-resource benefits depend on careful curation and augmentation.
- Model scale and generalization: Results demonstrated around ~8B; scaling laws and stability for larger models require further validation.
- Serving and safety: Real-world deployment needs compilation/test harnesses, sandboxing, and security scanning; human-in-the-loop review remains critical.
- Infrastructure: Benefits in speed/energy rely on optimized kernels for block/parallel decoding and efficient masking operations.
- Training initialization: Best results depend on strong AR checkpoints (pre-annealing) and adherence to the warmup and clipped noise schedules described.
Collections
Sign up for free to add this paper to one or more collections.