TruthTensor: Evaluating LLMs through Human Imitation on Prediction Market under Drift and Holistic Reasoning
Abstract: Evaluating LLMs and AI agents remains fundamentally challenging because static benchmarks fail to capture real-world uncertainty, distribution shift, and the gap between isolated task accuracy and human-aligned decision-making under evolving conditions. This paper introduces TruthTensor, a novel, reproducible evaluation paradigm that measures reasoning models not only as prediction engines but as human-imitation systems operating in socially-grounded, high-entropy environments. Building on forward-looking, contamination-free tasks, our framework anchors evaluation to live prediction markets and combines probabilistic scoring to provide a holistic view of model behavior. TruthTensor complements traditional correctness metrics with drift-centric diagnostics and explicit robustness checks for reproducibility. It specify human vs. automated evaluation roles, annotation protocols, and statistical testing procedures to ensure interpretability and replicability of results. In experiments across 500+ real markets (political, economic, cultural, technological), TruthTensor demonstrates that models with similar forecast accuracy can diverge markedly in calibration, drift, and risk-sensitivity, underscoring the need to evaluate models along multiple axes (accuracy, calibration, narrative stability, cost, and resource efficiency). TruthTensor therefore operationalizes modern evaluation best practices, clear hypothesis framing, careful metric selection, transparent compute/cost reporting, human-in-the-loop validation, and open, versioned evaluation contracts, to produce defensible assessments of LLMs in real-world decision contexts. We publicly release TruthTensor at https://truthtensor.com.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper introduces TruthTensor, a new way to judge how good AI LLMs are—not just at giving the “right answer,” but at thinking and behaving more like careful, well‑calibrated humans when the future is uncertain. Instead of testing AIs on old, fixed quizzes, TruthTensor tests them on live, real‑world questions from prediction markets (places where people bet on future events), and watches how the AIs update their beliefs over time.
What the researchers wanted to find out
Put simply, they asked:
- Can AI models reason about the future in a human‑like way, not just give guesses?
- Do their confidence levels match reality (for example, when they say they’re 80% sure, are they right about 8 out of 10 times)?
- Do their explanations and probabilities stay steady and sensible over time, or do they drift and change without good reason?
- How do models behave under pressure: when information changes, when time passes, and when the stakes are higher?
How they tested the AIs (explained simply)
Think of a prediction market like a giant, constantly updated “weather forecast” for world events. For example: “Will Candidate X win?” The market price acts like the crowd’s best current probability. TruthTensor connects AI models to these live markets and checks how they behave across many events and days.
Here’s the basic approach in everyday terms:
- Lock the instructions: The team writes one clear, fixed set of directions for the AI (so no one quietly tweaks the wording to make a model look better). This is called “instruction locking.”
- Ask about the future: The AI gives a probability (like “there’s a 65% chance this will happen”) plus a short explanation—again and again over time—until the event is decided.
- Compare to humans: The model’s probabilities are compared to the market’s probabilities (the “crowd” view), which are backed by people risking money. This makes the comparison realistic, not just theoretical.
- Track change over time: The system watches how the AI’s story, confidence, and probabilities move as news comes out. Do they update sensibly, like a careful human forecaster, or swing wildly?
- Score fairly: The system uses proper scoring rules (think of them like fair grading methods for probability). If you say “90% chance” and it happens, that’s good. If you say “90% chance” and it doesn’t happen, that’s worse than being cautiously 60%.
- Optional “skin in the game”: In an advanced mode, the AI can simulate trades based on its beliefs, turning forecasts into real, trackable outcomes like profit or loss—another way to test decision quality.
Two key ideas explained with simple examples:
- Calibration: If a model says “70% chance of rain” on 10 different days, it should rain on about 7 of those days. Good calibration means its confidence matches reality.
- Drift (three kinds):
- Narrative drift: The model’s story keeps changing without new facts—like saying one day a team will “definitely win” and the next day “definitely lose” even though nothing important changed.
- Temporal drift: The model doesn’t update enough when real news arrives—or overreacts to small, noisy updates.
- Confidence drift: The model sounds too sure (overconfident) or not sure enough (underconfident) compared to how often it’s actually right.
Why use future events? Because they’re “contamination‑free.” Models can’t memorize answers that don’t exist yet, so we measure real reasoning, not recall.
What they found and why it matters
Across 500+ real markets (politics, economics, culture, technology), the researchers saw that:
- Models with similar “accuracy” can behave very differently in more human‑like ways—some are better calibrated, some handle updates more steadily, and some avoid risky overconfidence.
- Drift is a big deal. Even if two models get similar final scores, one might change its story a lot without reason, while another stays steady and sensible like a good human forecaster.
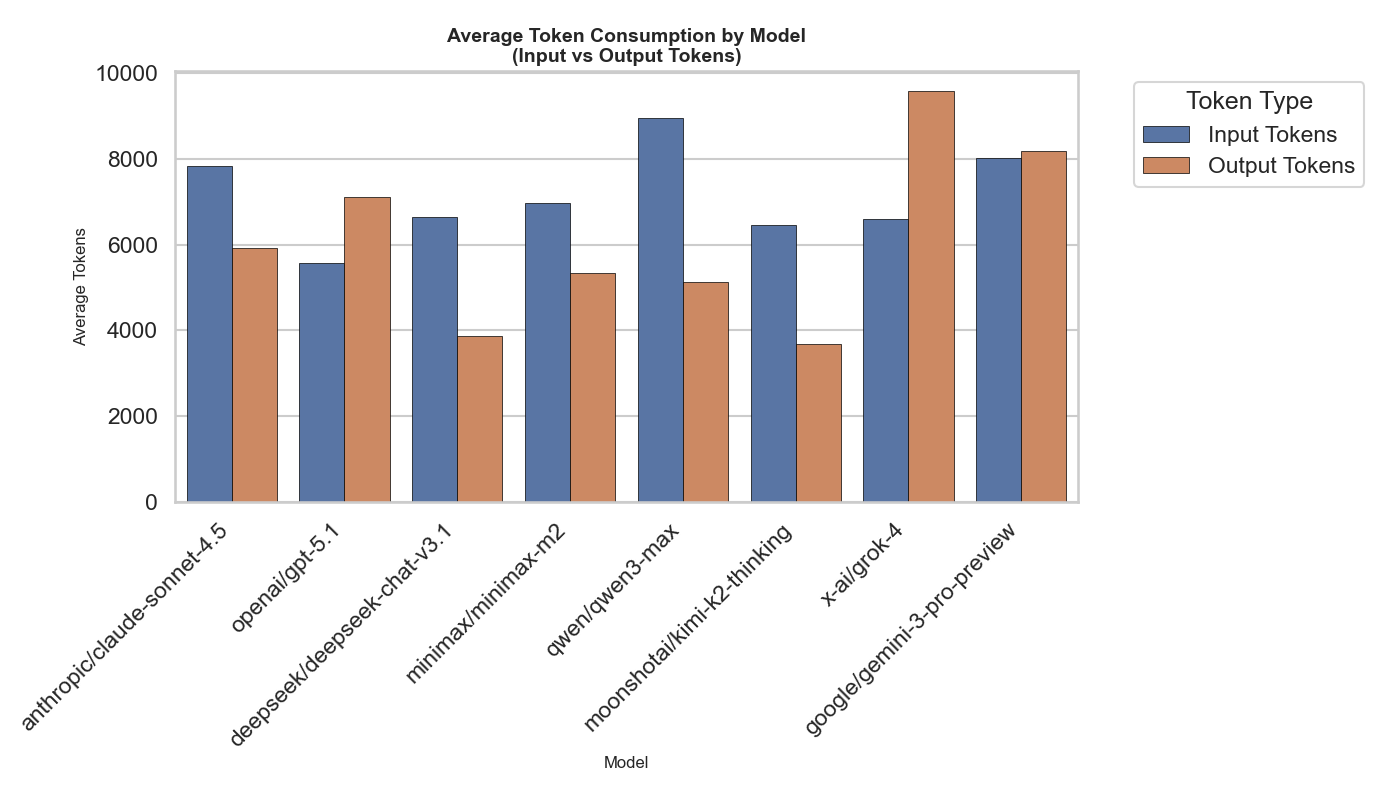
- Cost and efficiency matter. Some models use many more “tokens” (their internal text budget) to reach similar quality. Efficient models can be cheaper and just as reliable.
- A single score isn’t enough. To judge a model properly, you need multiple views: accuracy, calibration, how stable its narrative is, how it handles new information, and how resource‑hungry it is.
In short, the best model isn’t just the one that guesses right most often—it’s the one that guesses well, explains clearly, updates responsibly, and keeps its confidence honest.
Why this could be important (what it means going forward)
- Better decisions in the real world: If you’re using AI to plan, invest, set policy, or manage risk, you want a model that acts like a careful, trustworthy forecaster—not a flashy guesser.
- Safer AI: Watching drift and calibration helps catch when models are being overconfident, inconsistent, or easily swayed—important for safety and reliability.
- Fair, reproducible testing: “Instruction locking” and live, forward‑looking events mean results are harder to game and easier to repeat.
- Human‑aligned AI: By using markets (a crowd of humans) as a reference, TruthTensor pushes models to learn the habits of thoughtful human reasoning: clear explanations, balanced confidence, and steady updates.
Overall, TruthTensor shifts AI evaluation from “Can it get an answer right on a test?” to “Can it think and act like a careful human when the future is uncertain?” That makes it a stronger fit for the messy, changing world we live in. The tool is publicly available at https://truthtensor.com, so others can build on it and keep improving how we measure AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes concrete gaps, uncertainties, and unresolved questions that future researchers could address to strengthen and extend TruthTensor.
- Validity of market-as-ground-truth: How accurate, stable, and unbiased are prediction market probabilities across domains, liquidity regimes, and time? Quantify market inefficiency, manipulation risk, and demographic/selection biases of market participants and their impact on evaluation.
- Human imitation vs accuracy trade-off: Should models be optimized to mimic market consensus or to outperform it (e.g., yield positive excess Brier/log loss or PnL)? Formalize the normative objective and evaluation criteria when human imitation conflicts with superior accuracy.
- Tool access and tautological imitation: If agents can consume market prices or near-proxies (e.g., “news that reprints odds”), how is trivial imitation prevented? Specify tool gating policies, ablations that remove market data access, and integrity checks for independence of forecasts.
- Event sampling protocol transparency: Define the exact event selection criteria, sampling frame, inclusion/exclusion rules, domain distribution, liquidity thresholds, and time horizons. Quantify representativeness and guard against cherry-picking or survivorship bias.
- Handling unresolved and long-horizon events: How are repeated forecasts for unresolved events aggregated or weighted? What scoring rules, censoring strategies, and time-weighting schemes are used when outcomes are realized much later?
- Drift attribution methodology: The paper references “information arrival” but does not specify detection and attribution. Operationalize information events (news, polling updates) and specify the data sources, matching algorithms, thresholds, and lag structures used to link updates to probability shifts.
- Narrative drift measurement specifics: “Reasoning Trace Divergence” is underspecified. Define the representation (e.g., embeddings, LLM-based semantic similarity, edit distance), alignment method across time points, and thresholds. Validate with human annotation and report inter-annotator agreement.
- Reliability of self-explanations: Chain-of-thought can be post-hoc or spurious. Establish whether reasoning traces predict forecast quality or simply rationalize outputs; design tests to disentangle genuine reasoning from confabulation.
- Confidence drift vs probability: Clarify the distinction between “stated confidence” and forecast probability. If separate, detail how confidence is elicited, normalized across models, and evaluated over time; otherwise avoid redundancy with calibration metrics.
- Time-series calibration design: With multiple predictions per event, specify how ECE/log loss/Brier are aggregated (per-event vs per-timepoint), handle autocorrelation, and prevent overweighting frequent samplers. Provide sensitivity analyses for different aggregation schemes.
- Statistical testing rigor: Specify the exact tests, effect sizes, confidence intervals, corrections for multiple comparisons, and time-series dependencies (e.g., block bootstrap or HAC estimators). Include power analyses for 500+ markets under repeated measures.
- Baseline independence clarity: Baseline is defined as the market; explain “independent of rolling-window calibration” and provide alternative baselines (e.g., naive persistence, historical averages, human forecaster baselines) to isolate model value-add beyond market tracking.
- Trading PnL construction: Execution mode lacks details on threshold selection (δ), position sizing, slippage, transaction fees, market impact, partial fills, latency, liquidity constraints, risk limits, and portfolio aggregation. Provide backtesting protocols and stress-test scenarios.
- Risk metrics operationalization: Define VaR/CVaR horizons, confidence levels, portfolio composition, and estimation methods (historical vs parametric) in the context of discrete-event trading strategies and sparse trade sequences.
- Safety, ethics, and compliance: Document guardrails for live trading (limits, kill switches), market TOS compliance, user consent, and potential market influence from agent activity; propose an IRB-like framework for agent market participation.
- Token budget fairness: Normalize token budgets across models with different tokenizers and compression ratios; specify how budget affects tool use, chain-of-thought verbosity, and forecast stability. Include ablations controlling CoT vs concise reasoning.
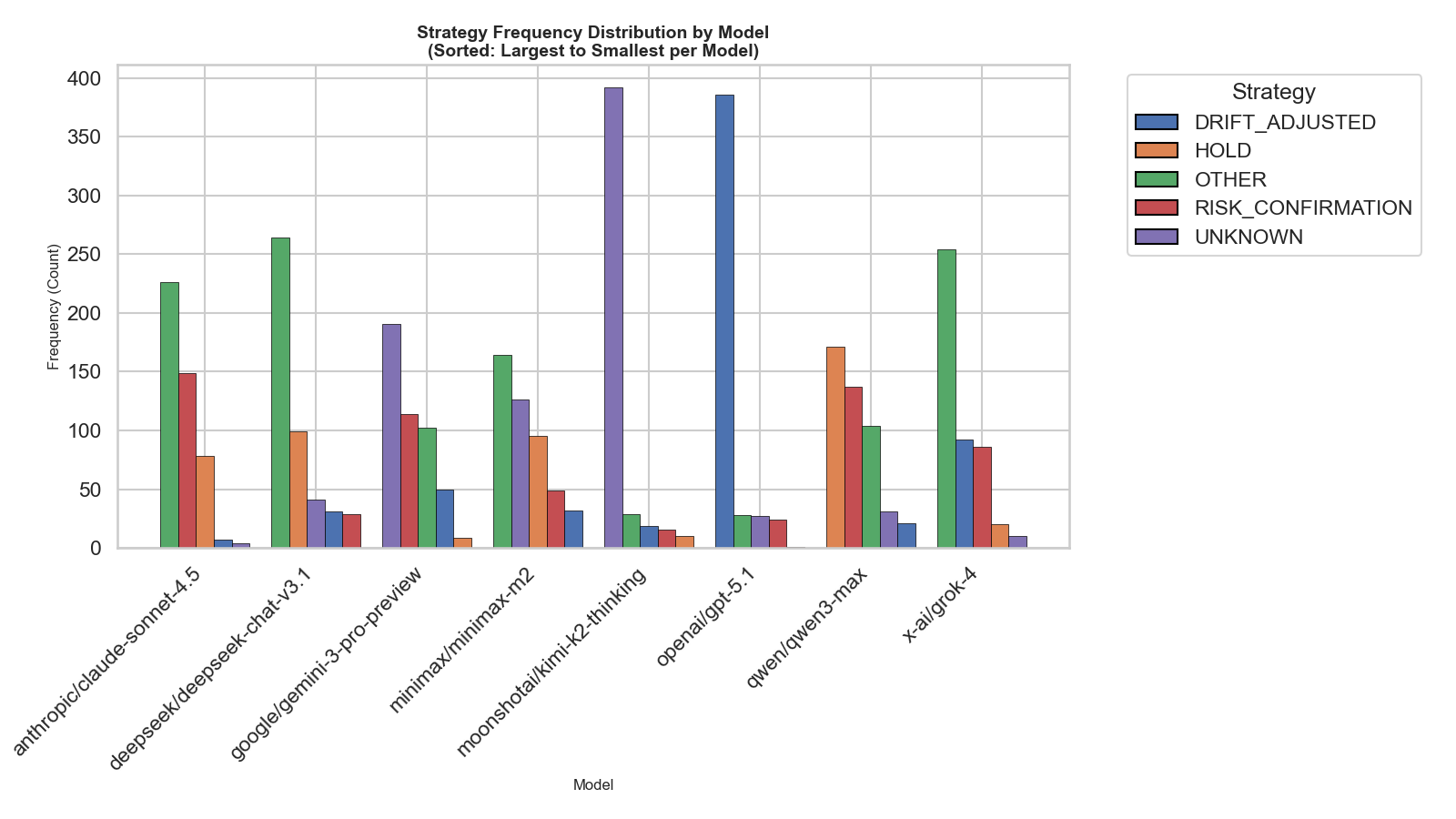
- Agent strategy definitions: “4 strategies” are referenced but not described. Detail the strategies, selection logic, switching criteria, and their impact on drift and performance; provide ablations that isolate strategy effects from model effects.
- Human-in-the-loop roles and protocols: The paper claims human involvement but lacks specifics on annotation tasks (e.g., reasoning quality, drift labels), training, blinding, sampling, and inter-annotator reliability. Publish guidelines and datasets for reproducibility.
- Cross-platform generalizability: Evaluate transferability across different forecasting platforms (e.g., Kalshi, Metaculus), domains (non-political, scientific), and market structures (continuous vs tournament). Quantify domain-specific performance and drift.
- Reproducibility and versioning: Instruction locking is described, but full reproducibility requires releasing prompt hashes, exact event IDs, timestamps, market snapshots, agent configs, seeds, and code. Clarify how provider model updates (silent weights changes) are tracked and controlled.
- Cost and resource normalization: Report standardized cost per forecast across providers, include latency, throughput, and energy/carbon measures; normalize resource efficiency metrics for fair cross-model comparisons.
- Performance decomposition: The paper promises decomposition into intrinsic vs tool-assisted improvements but lacks methodology. Provide controlled experiments and ablations to isolate retrieval/tool effects from base model reasoning.
- Prompt sensitivity and priming: Despite instruction locking, LLM outputs vary with minor prompt perturbations and initial context. Design robustness checks across seeds, paraphrases, and formatting variations; quantify prompt-induced drift.
- Multi-class and continuous outcomes: Extend methods beyond binary yes/no markets to multi-outcome or continuous targets (e.g., economic indicators), with appropriate proper scoring rules and drift metrics.
- Extreme-event and stress testing: Assess behavior under low-liquidity, adversarial, or shock scenarios (e.g., breaking news, regime shifts). Measure resilience of calibration and drift under high-entropy conditions.
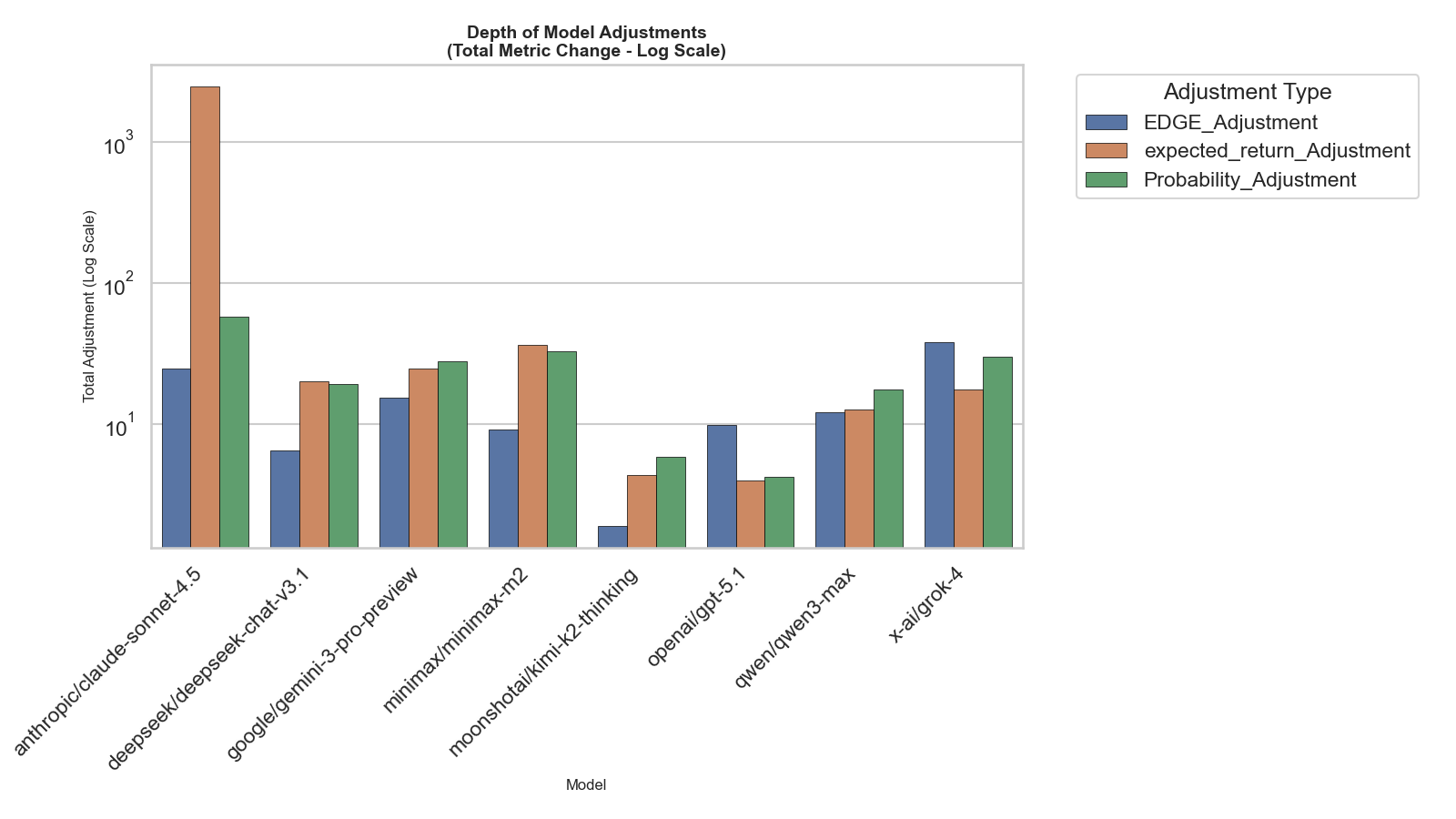
- Weighting of composite scores: Human Imitation Score and Reasoning Quality Index are undefined in terms of weights, normalization, and cross-domain calibration. Provide transparent formulas, learned vs fixed weights, and sensitivity analyses.
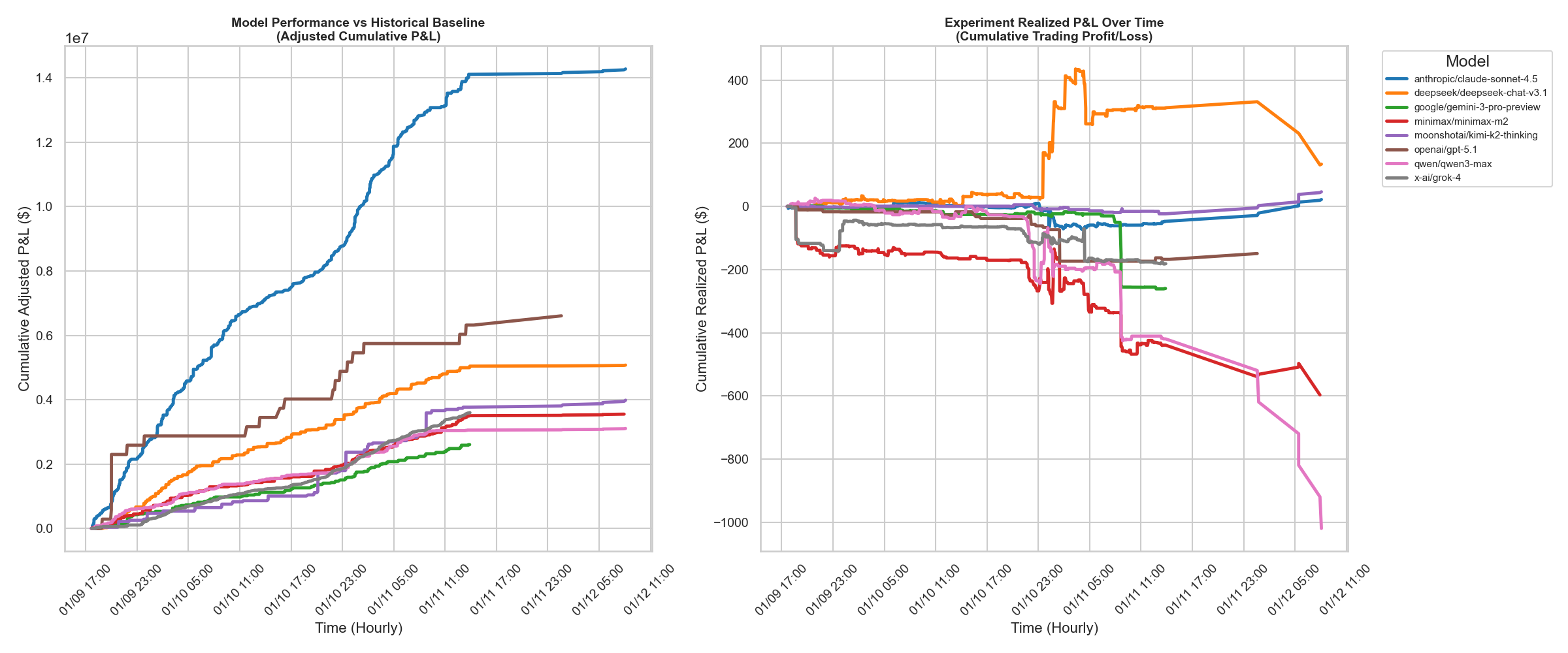
- Ambiguities in reported results: Tables/figures include placeholders (e.g., “P{paper_content}L”), undefined variables (unique users, agent count), and truncated sections (“Benchmark Tasks”). Clarify definitions, data sources, and ensure complete, consistent reporting.
Practical Applications
Immediate Applications
The following list summarizes practical, deployable use cases that build directly on TruthTensor’s market-grounded evaluation, drift diagnostics, instruction locking, and holistic metrics.
- Market-grounded LLM evaluation and model selection
- Sector: Software/AI, Finance
- What: Use TruthTensor to benchmark candidate LLMs against live prediction-market odds, focusing on accuracy, calibration, narrative/temporal/confidence drift, and resource efficiency (tokens, latency).
- Tools/Products/Workflows: Evaluation contracts with cryptographic hashes; calibration dashboards; drift profiles; reliability diagrams; market divergence monitors.
- Assumptions/Dependencies: Access to liquid prediction-market APIs (e.g., Polymarket); stable data ingestion; prompt versioning adoption; awareness of market biases and event coverage constraints.
- MLOps drift and calibration monitoring for deployed LLMs
- Sector: Software/AI Platforms
- What: Integrate TruthTensor’s drift metrics (narrative, temporal, confidence) and ECE/MCE into production observability to catch reasoning instability and overconfidence early.
- Tools/Products/Workflows: Drift monitors; token-budget degradation tests; scheduled time-series sampling; alerting when drift exceeds thresholds.
- Assumptions/Dependencies: Logging of reasoning traces and probabilities; defined sampling cadence; governance for storing sensitive traces.
- AI auditing and compliance for reproducibility
- Sector: Policy/Regulation, Enterprise Governance
- What: Adopt instruction locking and versioned evaluation contracts to make external audits reproducible and resistant to prompt tampering.
- Tools/Products/Workflows: Signed prompt templates; evaluation registries; audit-ready reports covering multi-axis metrics (accuracy, calibration, drift, cost).
- Assumptions/Dependencies: Regulator or internal policy acceptance; long-term storage of evaluation artifacts; standardized reporting formats.
- Risk-gated “paper trading” and safe execution mode for research
- Sector: Finance
- What: Use Observation Mode for forecast calibration; optionally activate Execution Mode under strict thresholds to test decision quality and PnL without full autonomy.
- Tools/Products/Workflows: Threshold-based trade gating (delta-based triggers); rate-limited execution; PnL vs market baseline dashboards; VaR/CVaR overlays.
- Assumptions/Dependencies: Jurisdictional compliance for trading; liquidity conditions; rigorous risk policies; human-in-the-loop oversight.
- Consumer forecasting assistants aligned to market consensus
- Sector: Daily Life, Media
- What: Build assistants that provide probabilistic forecasts on public events with explicit confidence, calibration indicators, and narrative-stability checks.
- Tools/Products/Workflows: Market odds overlays; confidence labels; “reasoning trace” summaries; drift warnings to prevent claim escalation.
- Assumptions/Dependencies: Coverage limited to events with markets; clear disclaimers; UI for uncertainty communication; regional legal constraints on market data.
- Newsroom editorial checks to reduce narrative drift and sensationalism
- Sector: Media/Publishing
- What: Use narrative drift detection and market divergence to flag unstable or escalating claims in reporting workflows.
- Tools/Products/Workflows: Pre-publication drift audits; market-informed plausibility checks; calibration annotations for forecasts in journalism.
- Assumptions/Dependencies: Editorial buy-in; API integrations; policy defining acceptable confidence and drift norms.
- Enterprise decision facilitation via internal baselines
- Sector: Corporate Strategy/Operations
- What: Adapt TruthTensor to compare LLM forecasts against internal “consensus” (e.g., wisdom-of-crowds or expert panels) where public markets aren’t available.
- Tools/Products/Workflows: Internal forecasting platforms; evaluation contracts mapped to enterprise baselines; drift-aware decision reviews.
- Assumptions/Dependencies: Creation of internal event registries; confidentiality safeguards; participation incentives for internal forecasters.
- Probabilistic reasoning curricula using live markets
- Sector: Education
- What: Teach Bayesian updating and calibration using market-grounded tasks, reliability diagrams, and longitudinal drift tracking.
- Tools/Products/Workflows: Classroom dashboards; student assignments on forecast updates; structured interpretation of ECE/MCE and Brier scores.
- Assumptions/Dependencies: Age-appropriate access to data; clear ethical guidelines; instructors trained in probabilistic literacy.
- Open research datasets and reproducible experiments on drift
- Sector: Academia/Research
- What: Use TruthTensor to generate longitudinal datasets of forecasts, reasoning traces, and drift metrics across models; enable controlled studies of human imitation.
- Tools/Products/Workflows: Public evaluation contracts; versioned prompts; statistical testing protocols; open leaderboards with compute/cost reporting.
- Assumptions/Dependencies: Data-sharing agreements; careful anonymization; community standards for multi-axis evaluation.
- Confidence gating for high-stakes LLM outputs
- Sector: Healthcare, Legal/Compliance
- What: Add calibration thresholds and confidence-alignment checks before surfacing recommendations to clinicians or lawyers.
- Tools/Products/Workflows: Confidence gates; reasonableness checks against baselines; human escalation workflows when drift or overconfidence is detected.
- Assumptions/Dependencies: Strict human-in-the-loop oversight; sector-specific liability frameworks; validation against domain-specific outcomes.
Long-Term Applications
The following list sketches use cases that require further research, scale, or standardization—often involving new markets, tools, or regulatory frameworks.
- Standardized Human Imitation Score for procurement and governance
- Sector: Policy/Regulation, Industry Consortia
- What: Establish a cross-industry metric (weighted accuracy, calibration, drift, risk) for RFPs, certifications, and AI system disclosures.
- Tools/Products/Workflows: Standards bodies (e.g., ISO/IEEE) codifying evaluation contracts; public registries; compliance audits.
- Assumptions/Dependencies: Broad stakeholder alignment; consensus on weighting schemes; periodic revalidation under drift.
- Autonomous financial agents with continuous drift control
- Sector: Finance
- What: Deploy agents that trade under strict, adaptive drift and calibration constraints; combine market-grounding with dynamic risk management.
- Tools/Products/Workflows: Real-time drift suppressors; automated Bayesian updating; multi-layer risk gates; post-trade audit trails.
- Assumptions/Dependencies: Robustness under adversarial conditions; regulatory approvals; evidence of safety and consistent calibration at scale.
- Domain-specific “markets” for evaluation where public markets don’t exist
- Sector: Healthcare, Energy, Transportation
- What: Create expert-driven enterprise markets (or structured consensus panels) to provide dynamic baselines for clinical guidelines, demand forecasts, or maintenance risks.
- Tools/Products/Workflows: Private market platforms; expert staking or scoring; integration with EHRs or grid telemetry.
- Assumptions/Dependencies: Sufficient liquidity/participation; ethical safeguards; privacy compliance; careful design to avoid bias.
- Regulatory reporting of calibration and drift (“model odometers”)
- Sector: Policy/Regulation
- What: Mandate ongoing reporting of calibration, drift, and confidence alignment for AI systems used in high-stakes contexts.
- Tools/Products/Workflows: Ongoing compliance dashboards; standardized reliability diagrams; incident logs of drift excursions.
- Assumptions/Dependencies: Legislative action; acceptable measurement burden; secure telemetry collection.
- Drift-minimizing training paradigms and optimizer-level controls
- Sector: Software/AI
- What: Use TruthTensor metrics to drive training/fine-tuning that explicitly penalizes narrative/temporal/confidence drift and miscalibration.
- Tools/Products/Workflows: Loss functions targeting drift; curriculum schedules with forward-looking tasks; model selection on multi-axis metrics.
- Assumptions/Dependencies: Access to suitable training signals; generalization beyond market domains; compute budget for iterative training.
- Insurance underwriting and risk assessment with LLM oracles
- Sector: Insurance/Finance
- What: Leverage calibrated probabilistic forecasts (VaR/CVaR aware) to price policies and manage portfolio tail risks.
- Tools/Products/Workflows: Oracle pipelines; confidence-stamped forecasts; stress testing against drift and distribution shift.
- Assumptions/Dependencies: Regulatory acceptance; fairness checks; governance for model updates and audit trails.
- Clinical decision support with explicit, audited probabilistic outputs
- Sector: Healthcare
- What: Provide clinicians with calibrated probabilities and reasoning traces, audited for drift; integrate with care pathways.
- Tools/Products/Workflows: EHR-integrated forecast modules; human-in-the-loop review; post-market surveillance of drift/calibration.
- Assumptions/Dependencies: Clinical trials and validation; liability frameworks; privacy/security controls; expert oversight.
- Smart grids and energy market optimization
- Sector: Energy
- What: Forecast demand, renewable output, and price dynamics with market-grounded calibration; control decisions tied to risk and drift bounds.
- Tools/Products/Workflows: Grid-facing forecasting agents; execution gating; drift-aware dispatch; integration with carbon markets.
- Assumptions/Dependencies: Secure operations; strong telemetry; regulatory alignment with market-linked decisions.
- Multi-agent market evaluation bridging simulation and real stakes
- Sector: Robotics/Autonomous Systems
- What: Extend AMA-style simulations with TruthTensor-like market grounding to evaluate strategic reasoning, adaptation, and group dynamics.
- Tools/Products/Workflows: Sim-to-market adapters; agent negotiation benchmarks; longitudinal drift scoring in multi-agent contexts.
- Assumptions/Dependencies: Transferability from sim to reality; reliable market proxies; safety mechanisms for emergent behaviors.
- Civic forecasting platforms with LLM-human co-judgment
- Sector: Civic Tech/Public Policy
- What: Public platforms that combine crowd forecasts with calibrated LLM oracles, improving transparency in policy planning and early-warning systems.
- Tools/Products/Workflows: Open APIs; co-forecasting UIs; calibration and drift transparency; community governance.
- Assumptions/Dependencies: Sustained participation; bias mitigation; data governance; funding and institutional support.
Glossary
- Agent Market Arena (AMA): A market-based, multi-agent evaluation ecosystem assessing strategic behavior and adaptation in simulated or real markets. "Agent Market Arena (AMA)\cite{qian2025agents} proposes a market-based, multi-agent evaluation ecosystem where autonomous agents interact, negotiate, or trade in simulated or real markets."
- Agentic execution: Allowing LLM-based agents to act in multi-step, tool-using settings with adaptive behaviors. "MIRAI emphasizes agentic execution, allowing LLM-based agents to interact with external tools or environments, perform multi-step reasoning or actions, and adapt over time."
- Agentic orchestration framework: A structured setup for coordinating multi-step reasoning and tool use in agents. "an agentic orchestration framework (e.g., chain-of-thought pipelines, tool-augmented agents, or minimal single-call evaluators),"
- Agentic reproducibility eval: An evaluation focus on agents’ ability to reproduce scientific results. "CORE-Bench & Agentic reproducibility eval & Scientific reproducibility & No & Focused on research workflows, not reasoning drift"
- Bayesian updating principles: Rules for adjusting beliefs (probabilities) in light of new evidence. "Human market participants continuously incorporate new information, adjusting their probability estimates in ways that reflect Bayesian updating principles."
- Baseline Independence: Ensuring comparisons do not depend on recalibration windows, enabling fair cross-model evaluation. "Baseline Independence: Baseline models provide reference points independent of rolling-window calibration, ensuring fair comparison across models with different training histories."
- Brier Score: A proper scoring rule measuring the accuracy of probabilistic forecasts (lower is better). "Brier Score: Measures the accuracy of probability forecasts, with lower scores indicating better accuracy \cite{gneiting2007strictly}."
- Calibration scoring: Quantifying how well stated probabilities match observed outcomes. "This mode supports calibration scoring, divergence analysis, drift measurement, and studies of narrative drift over time."
- Closed-world evaluation: Testing models on fixed datasets with known answers, often vulnerable to memorization. "The fundamental issue with these traditional benchmarks is their reliance on closed-world evaluations, where AI models are tested on a fixed set of tasks or datasets that often contain historical information or established patterns."
- Conditional Value at Risk (CVaR): A tail-risk metric measuring expected loss beyond a VaR threshold. "Conditional Value at Risk (CVaR): Assesses tail risk beyond VaR thresholds."
- Confidence Drift: Misalignment over time between stated confidence and actual calibration/accuracy. "Confidence drift measures the alignment between a modelâs stated confidence and its actual calibration."
- Confidence-Reasoning Alignment: The correlation between expressed confidence and the quality of reasoning/evidence. "Confidence-Reasoning Alignment: Assesses whether stated confidence correlates with reasoning quality and information availability."
- Confidence Stability: Consistency of confidence levels across time points. "Confidence Stability: Tracks confidence consistency across time points."
- Contamination-Free Construction: Designing evaluations only on future events to prevent training-data leakage. "Contamination-Free Construction: Evaluates only forward-looking events, thereby eliminating data contamination by construction, a fundamental weakness of static benchmarks."
- Contamination-resistant: Built to avoid test-set leakage by prior model outputs. "Contamination-resistant; code-only domain"
- Data contamination: Test items appearing in training data, inflating apparent performance. "evaluating LLMs on fixed benchmarks is vulnerable to data contamination and leaderboard overfitting"
- Distributional shift: Changes in data patterns over time that degrade model performance. "because static benchmarks fail to capture real-world uncertainty, distribution shift, and the gap between isolated task accuracy and human-aligned decision-making under evolving conditions."
- Divergence analysis: Assessing how model forecasts deviate from reference targets (e.g., markets). "This mode supports calibration scoring, divergence analysis, drift measurement, and studies of narrative drift over time."
- Drift-Centric Design: An evaluation approach emphasizing narrative, temporal, and confidence drift. "Drift-Centric Design: The framework places primary emphasis on measuring narrative drift, temporal inconsistency, and reasoning confidence decay, dimensions largely ignored by existing benchmarks."
- Drift tracking instrumentation: Logging tools that capture reasoning traces, probabilities, and confidence over time. "drift tracking instrumentation that logs reasoning traces, probability estimates, and confidence scores at each time point."
- Drawdowns: Peak-to-trough declines in cumulative performance or capital. "Evaluation metrics include not only forecast calibration and prediction quality, but also trade outcome, profit-and-loss (PnL), drawdowns, and risk-adjusted returns."
- Epistemic Integrity: Adherence to truthful, evidence-based claims without fabrication or escalation. "both of which contribute to a gap in Epistemic Integrity \cite{alifeinartify2025narrativedrift}."
- Expected Calibration Error (ECE): Average discrepancy between predicted probabilities and observed accuracies across bins. "Expected Calibration Error (ECE): Measures the difference between predicted confidence and actual accuracy across probability bins."
- Forward-looking events: Tasks whose outcomes are not yet realized at prediction time, preventing leakage. "TruthTensor extends this principle by exclusively evaluating forward-looking events whose outcomes are unknown at prediction time."
- Holistic Evaluation: A comprehensive assessment across correctness, risk, coherence, calibration, and drift. "Holistic Evaluation: Metrics span correctness, risk assessment, temporal coherence, calibration, and drift magnitude, providing a comprehensive view of model capabilities."
- Human Imitation Score: A composite metric of accuracy, calibration, drift, and risk assessing similarity to human reasoning. "Human Imitation Score: Weighted combination of correctness, calibration, drift, and risk metrics, measuring overall similarity to human reasoning patterns."
- Human-in-the-loop validation: Involving human evaluators to ensure interpretability and robustness of results. "transparent compute/cost reporting, human-in-the-loop validation, and open, versioned evaluation contracts, to produce defensible assessments of LLMs"
- Human preference ranking: Evaluation by comparing models via human judgments of conversational quality. "Chatbot Arena & Human preference ranking & Dialogue quality and consistency & Partial & Interactive but not outcome-grounded"
- Instruction locking: Versioning and freezing prompt templates to ensure reproducible, contamination-free evaluation. "Instruction Locking: Prompt specifications are versioned and locked, ensuring reproducibility and preventing prompt engineering from masking model limitations."
- Log-Likelihood: A proper scoring rule evaluating the probability assigned to the actual outcome. "Log-Likelihood: Evaluates the probability assigned to the actual outcome, rewarding well-calibrated forecasts."
- Longitudinal drift tracking: Monitoring drift over time across markets and events. "TruthTensor (ours) & Market-grounded agentic eval & Human imitation, drift, calibration & Yes & Live prediction markets; longitudinal drift tracking"
- Market Divergence: The degree to which model probabilities deviate from market-implied probabilities over time. "Market Divergence: Tracks how model outputs diverge from market-implied probabilities over time."
- Market grounding: Anchoring evaluation to real prediction markets with externally resolved outcomes. "Market grounding: All benchmarks are anchored to real prediction markets with externally resolved outcomes."
- Market Liquidity: The activity level of trading in a market affecting evaluation and risk. "Market Liquidity: High-liquidity (active trading), medium-liquidity (moderate activity), low-liquidity (limited trading)."
- Market-implied probabilities: Probabilities inferred from market prices representing aggregated expectations. "Through the comparison of LLM outputs to market-implied probabilities which represent aggregated human expectations, TruthTensor measures how well models replicate human-like reasoning patterns, calibration, and narrative coherence."
- Maximum Calibration Error (MCE): The worst-case calibration discrepancy over all probability bins. "Maximum Calibration Error (MCE): Captures the worst-case calibration error."
- Multi-agent market simulation: Environments where multiple agents interact strategically in markets. "Agent Market Arena (AMA) & Multi-agent market simulation & Strategic interaction and adaptation & Yes & Simulated markets; limited real stakes"
- Narrative drift: Inconsistent or shifting reasoning about the same event over time without new information. "Narrative drift refers to inconsistent reasoning about the same event over time."
- Narrative stability: Maintaining coherent reasoning stories over time. "models with similar forecast accuracy can diverge markedly in calibration, drift, and risk-sensitivity, underscoring the need to evaluate models along multiple axes (accuracy, calibration, narrative stability, cost, and resource efficiency)."
- Overconfidence Index: A measure of expressing higher confidence than justified by accuracy. "Overconfidence Index: Measures the extent to which models express higher confidence than their accuracy warrants."
- Prediction markets: Platforms aggregating probabilities of real-world outcomes via financially backed trades. "Prediction markets and live event feeds provide a natural source of such future-grounded tasks."
- Probability Volatility: Magnitude of probability shifts unexplained by new information. "Probability Volatility: Quantifies the magnitude of probability shifts that cannot be explained by new information arrival."
- Proper scoring rules: Metrics that incentivize truthful probability estimation (e.g., Brier, log-likelihood). "proper scoring rules such as the Brier score and log-likelihood."
- Reasoning Trace Divergence: A measure of how reasoning explanations change over time. "Reasoning Trace Divergence: Compares reasoning traces at different time points, measuring how much the underlying narrative has shifted."
- Reliability Diagrams: Plots visualizing calibration across probability ranges. "Reliability Diagrams: Visualize calibration across probability ranges."
- Risk-Adjusted Returns: Performance normalized by risk exposure to compare strategies fairly. "Risk-Adjusted Returns: Evaluates performance relative to risk exposure."
- Rolling-window calibration: Recalibrating using a moving time window, which can bias comparisons. "Baseline Independence: Baseline models provide reference points independent of rolling-window calibration, ensuring fair comparison across models with different training histories."
- Sandboxed execution environment: A controlled runtime that enforces determinism and safety constraints. "a sandboxed execution environment that ensures deterministic runs and safety constraints,"
- Semantic priming: Linguistic cues that influence model responses, potentially causing drift. "It occurs as a result of semantic priming, where stylistic linguistic cues prompt an LLM to transition from providing factual summaries to simulating reality"
- Temporal drift: Degradation or inappropriate updating of model outputs over time relative to new information. "Temporal drift refers to a phenomenon in which the performance and accuracy of LLMs decline over time, driven by shifts in underlying data distributions, evolving linguistic patterns, and changes in the factual knowledge that the models were originally trained to capture"
- Token budget constraints: Limits on the number of tokens a model can consume, affecting reasoning quality. "token budget constraints that limit reasoning length,"
- Value at Risk (VaR): A quantile-based risk metric estimating potential losses under adverse scenarios. "Value at Risk (VaR): Measures potential losses under adverse scenarios."
- Versioned evaluation contracts: Fixed, version-controlled specifications for evaluation setups to ensure reproducibility. "open, versioned evaluation contracts"
- Wisdom of the crowd: Aggregated human judgments tending to produce well-calibrated probabilities. "Since the marketâs probability estimates encode the wisdom of the crowd, they tend to be well-calibrated and aggregate diverse insights"
Collections
Sign up for free to add this paper to one or more collections.

