- The paper introduces a game-theoretic framework for decentralized peer evaluation that yields LLM rankings closely aligned with human preferences.
- Using methods such as the Kemeny-Young aggregation, the approach mitigates self-preference bias and achieves robust performance across multiple benchmarks.
- Empirical results demonstrate high alignment in objective tasks like mathematical reasoning, while showcasing scalability and adaptability to diverse task domains.
Game-Theoretic Peer Evaluation for Human-Aligned LLM Ranking
Motivation and Problem Statement
The evaluation of LLMs is increasingly challenged by the limitations of static benchmarks and reference-based metrics, which fail to capture the nuanced, subjective, and open-ended nature of modern LLM outputs. The paper introduces a game-theoretic framework for LLM evaluation, leveraging mutual peer assessment and aggregation algorithms from social choice theory to produce model rankings that are systematically compared to human preferences. The central hypothesis is that decentralized, model-driven evaluation—where LLMs judge each other's outputs—can yield rankings that closely align with human judgments, while also mitigating self-preference bias and scaling to diverse task domains.
Figure 1: Illustration of game-theoretic peer evaluation for LLM performance ranking.
Framework and Methodology
The proposed framework consists of three core components: (1) decentralized peer evaluation, (2) aggregation of per-question rankings, and (3) alignment analysis with human judgment.
Decentralized Peer Evaluation
Each LLM in a pool both generates responses to a shared set of evaluation questions and serves as an evaluator, ranking anonymized outputs (including its own) for each question. Rankings are converted to pairwise preferences, forming a global preference matrix. This protocol enables the study of self-preference bias and facilitates automated, scalable assessment.
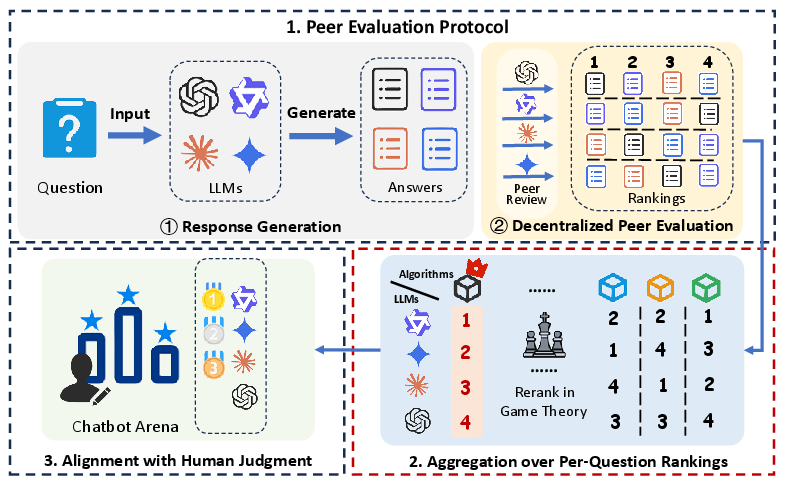
Figure 2: The proposed framework for game-theoretic evaluation of LLMs.
Rank Aggregation Algorithms
To derive a global ranking, the framework applies aggregation algorithms such as Kemeny-Young, Borda count, Copeland, and others. The Kemeny-Young method is shown to consistently achieve the highest alignment with human preferences, minimizing total pairwise discordance (Kendall-Tau distance) across input rankings. This approach is robust to evaluator noise and local ranking variability.
Human Alignment Metrics
Model rankings are compared to human preference data from Chatbot Arena, using Pearson and Kendall correlation coefficients at both micro (per-question) and macro (dataset-level) granularity. High alignment scores indicate that peer-based, game-theoretic aggregation can approximate human consensus without reliance on reference answers.
Empirical Analysis
Alignment with Human Judgment
Across multiple benchmarks (GSM8K, MMLU, GPQA, CEval, IFEval, MBPP, Creative Writing), game-theoretic aggregation methods—especially Kemeny-Young—yield model rankings with strong and stable alignment to human preferences. For example, on GSM8K, Kemeny-Young achieves a median Pearson correlation of 0.771, outperforming the best individual model and exhibiting lower variance.
Mitigation of Self-Preference Bias
LLMs exhibit systematic self-preference bias when serving as evaluators, inflating their own rankings. The framework introduces four evaluation protocols: Self Evaluation (SE), Peer Evaluation (PE), Self-Inclusive Evaluation (SIE), and Self-Free Evaluation (SFE). Aggregation via Kemeny-Young substantially reduces the impact of self-bias, with SIE and SFE rankings closely matching and showing higher alignment with human judgment than SE or PE alone.
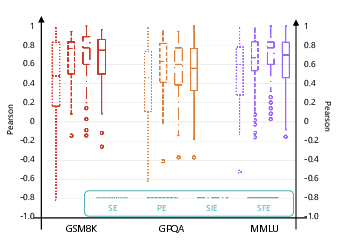
Figure 3: Alignment with Human Judgments under Different Evaluation Protocols; SIE and SFE yield higher and more stable agreement with human rankings than SE or PE.
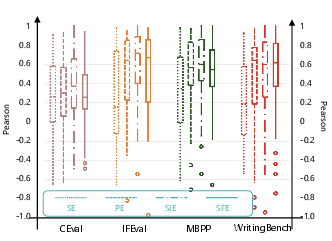
Figure 4: Alignment with Human Judgments under Different Evaluation Protocols across seven benchmarks; SIE and SFE protocols consistently outperform SE and PE in both accuracy and robustness.
Capability-Specific Evaluation
Game-theoretic aggregation is most effective in domains with objective criteria, such as mathematical reasoning (GSM8K, MBPP), where it achieves the highest median and macro-level correlations with human rankings. In more subjective domains (Creative Writing, CEval), alignment is lower and more variable, though macro-level aggregation still produces reliable consensus.
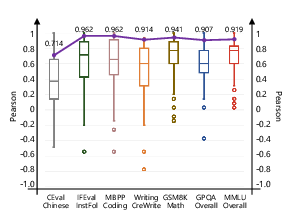
Figure 5: Alignment with Human Judgments Across Benchmarks; math and code tasks show the strongest and most consistent alignment, while creative and linguistic tasks exhibit greater variance.
Implementation Considerations
- Scalability: The decentralized protocol is parallelizable and label-free, enabling evaluation of large model pools without human annotation bottlenecks.
- Aggregation Complexity: Kemeny-Young aggregation is NP-hard, but efficient heuristics and approximation algorithms are available for practical deployment.
- Robustness: The framework is robust to data leakage and benchmark saturation, as it relies on relative peer judgments rather than static reference sets.
- Generalization: Synthetic, LLM-generated evaluation sets yield alignment results consistent with traditional benchmarks, supporting out-of-distribution assessment.
Implications and Future Directions
The game-theoretic peer evaluation framework provides a scalable, fair, and human-aligned alternative to conventional LLM evaluation. It enables principled analysis of model capabilities, mitigates evaluator bias, and adapts to diverse task domains. However, alignment with human judgment is task-dependent, with reduced efficacy in highly subjective or creative domains. Future research should explore hybrid protocols combining peer and human assessment, dynamic evaluator selection, and extensions to multi-agent and adversarial evaluation settings. The intersection of game theory and LLM evaluation offers fertile ground for advancing both theoretical understanding and practical benchmarking methodologies.
Conclusion
This work demonstrates that game-theoretic mutual evaluation, combined with robust aggregation algorithms, can produce LLM rankings that closely reflect human preferences and overcome key limitations of static, reference-based benchmarks. The framework is effective in mitigating self-preference bias and is particularly well-suited for objective reasoning tasks. These findings support broader adoption of peer-based, decentralized evaluation protocols in the development and assessment of advanced LLMs.