- The paper introduces a novel anthropomorphic evaluation taxonomy combining IQ, PQ, EQ, and the innovative VQ to bridge benchmark performance with real-world utility.
- It proposes a modular evaluation architecture integrating benchmark hubs, prompting modules, and multi-layered metrics to enhance reproducibility and dynamic assessment.
- The paper underscores responsible AI by incorporating value-oriented metrics that address ethical, social, economic, and environmental impacts.
Anthropomorphic and Value-Oriented Evaluation of LLMs: A Comprehensive Roadmap
Introduction
The evaluation of LLMs has evolved from simple, task-specific benchmarks to a complex, multidimensional challenge. The paper "Beyond Benchmark: LLMs Evaluation with an Anthropomorphic and Value-oriented Roadmap" (2508.18646) addresses the persistent disconnect between benchmark performance and real-world utility by proposing a holistic, anthropomorphic evaluation paradigm. This framework introduces a taxonomy that mirrors human cognitive development—Intelligence Quotient (IQ), Professional Quotient (PQ), Emotional Quotient (EQ)—and extends it with a Value Quotient (VQ) to capture economic, social, ethical, and environmental impacts. The work systematically analyzes over 200 benchmarks, identifies critical gaps, and provides a modular, actionable evaluation architecture.
Technical Evolution and Anthropomorphic Taxonomy
The paper posits that the developmental trajectory of LLMs parallels human cognitive progression, with distinct evaluation axes corresponding to pre-training (IQ), supervised fine-tuning (PQ), and reinforcement learning from human feedback (EQ). This anthropomorphic taxonomy is visualized as an evolutionary tree, mapping the technical lineage of LLM evaluation.
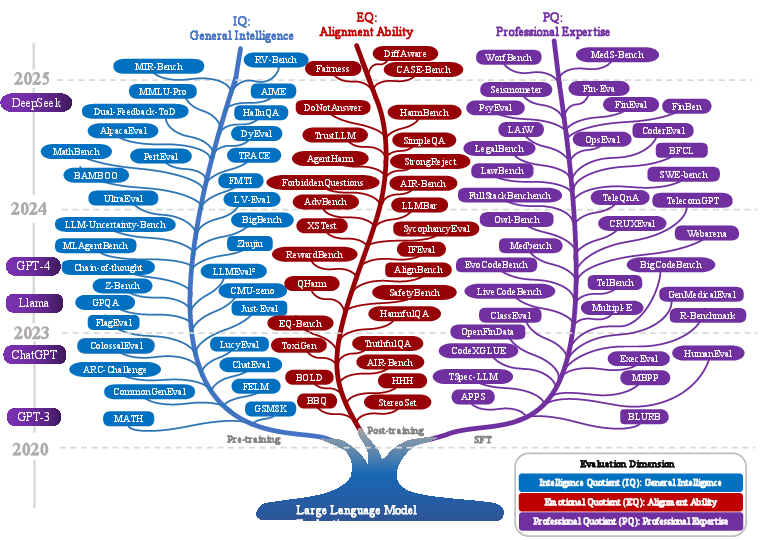
Figure 2: The proposed technical evolutionary tree of LLM evaluation, aligning IQ, PQ, and EQ with LLM training stages and human cognitive development.
IQ (General Intelligence): Assesses foundational reasoning and world knowledge, typically acquired during pre-training. Benchmarks such as MMLU, MMLU-Pro, and BigBench Hard are used to quantify breadth and depth of general intelligence, but the paper highlights persistent issues such as the memorization–reasoning dichotomy and rapid benchmark saturation.
PQ (Professional Expertise): Measures domain-specific proficiency, emerging from supervised fine-tuning. The survey catalogs a wide array of domain benchmarks (e.g., Medbench for healthcare, FinEval for finance, LawBench for legal, FullStackBench for coding), emphasizing the need for continual adaptation to evolving professional standards and real-world complexity.
EQ (Alignment Ability): Evaluates alignment with human values, preferences, and ethical norms, cultivated through RLHF. The paper notes the lack of strict, human-centric EQ benchmarks, with current tools (e.g., AlignBench, MT-Bench, Arena-Hard) often relying on LLMs as evaluators, which introduces alignment drift toward AI rather than human preferences.
This triadic framework is positioned as a significant departure from prior taxonomies, which often conflate knowledge and alignment or neglect domain expertise and value alignment.
Modular Evaluation Architecture
The authors propose a modular evaluation system, decomposing the evaluation pipeline into six core components: benchmark/dataset hub, model hub, prompting module, metrics module, tasks module, and leaderboards/arena module. This architecture supports three primary evaluation paradigms: metrics-centered (automatic), human-centered (qualitative), and model-centered (LLMs as evaluators).
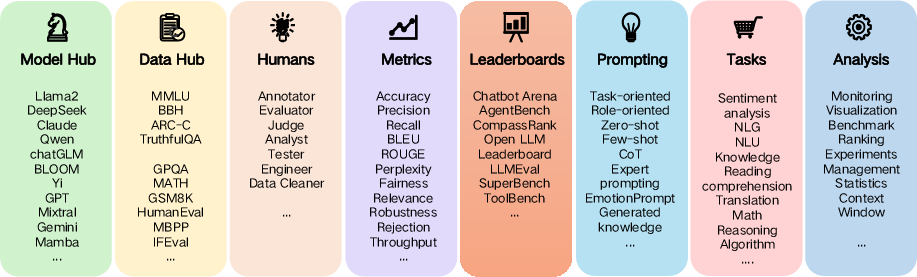
Figure 1: Typology of the LLM Evaluation Modules, illustrating the modular architecture and the interplay between technical, human, and model-centered assessment.
Key implementation considerations include:
- Benchmark/Dataset Hub: Selection of benchmarks must reflect the IQ-PQ-EQ taxonomy, with careful attention to data contamination, domain coverage, and alignment with real-world tasks.
- Prompting Module: Prompt design and decoding parameterization (e.g., temperature, shot count) are critical for robust, reproducible evaluation.
- Metrics Module: The framework advocates for a dual focus on technical (e.g., BLEU, F1, BERTScore, factuality) and business metrics (e.g., user engagement, latency, cost), with an emphasis on multi-layered, context-aware metrics.
- Leaderboards/Arena: The integration of static leaderboards and dynamic, human-in-the-loop arenas (e.g., Chatbot Arena) is highlighted as essential for capturing both snapshot and evolving model performance.
The architecture is designed for extensibility, supporting new evaluation paradigms (e.g., dynamic, agentic, or value-oriented) and facilitating reproducibility through rigorous experiment management and logging.
Value-Oriented Evaluation (VQ)
A central contribution is the introduction of the Value Quotient (VQ), which extends LLM evaluation beyond technical metrics to encompass economic, social, ethical, and environmental dimensions. The VQ framework operationalizes metrics such as cost-benefit ratio, return on investment, user satisfaction, fairness, transparency, privacy protection, energy efficiency, and sustainability.
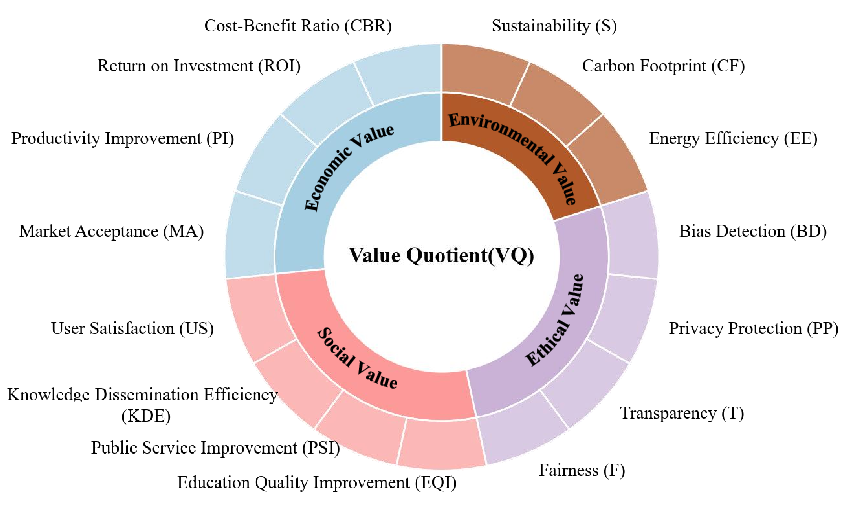
Figure 3: Value-oriented Evaluation for LLMs, mapping economic, social, ethical, and environmental metrics to LLM assessment.
This approach shifts the evaluation discourse from "can it work?" to "should it work?" and "how does it benefit society?", providing a principled basis for responsible AI deployment. The paper argues that value-oriented evaluation is indispensable for aligning LLM development with societal needs and regulatory requirements.
System and Application-Level Evaluation
The survey extends the evaluation paradigm to complex LLM-based systems, including Retrieval-Augmented Generation (RAG), agents, and chatbots. It reviews specialized benchmarks and metrics for RAG (e.g., RAGAS, BERGEN, CRAG), agentic workflows (e.g., AgentBench, API-Bank, AgentBoard), and conversational systems (e.g., MT-Bench, Chatbot Arena, FairMT-Bench). The analysis underscores the need for composite, scenario-driven evaluation strategies that integrate technical, user-centric, and value-oriented perspectives.
Challenges and Future Directions
The paper identifies several persistent and emerging challenges:
- Statistical Rigor and Reproducibility: Most benchmarks lack confidence intervals and robust statistical analysis, impeding reliable model comparison and scientific validity.
- Composite and Dynamic Evaluation: There is a need for composite ranking systems that integrate multiple metrics and for dynamic evaluation mechanisms that adapt to evolving model capabilities and deployment contexts.
- Interpretability and Explainability: Current evaluation practices inadequately address the alignment between model decision logic and human reasoning, necessitating advances in XAI tailored for LLMs.
- User-Centric and Human-in-the-Loop Evaluation: Incorporating user feedback and HITL paradigms is essential for capturing practical utility and real-world alignment.
- Analytical Failure Exploration: Systematic error analysis and failure case sharing are required to move beyond surface-level metrics and drive targeted model improvements.
- Superior Value-Oriented Assessment: The ultimate goal is to institutionalize value-oriented evaluation as a first-class discipline, ensuring that LLMs are not only technically proficient but also beneficial and responsible in societal deployment.
Conclusion
This work establishes a comprehensive, anthropomorphic, and value-oriented roadmap for LLM evaluation, integrating IQ, PQ, EQ, and VQ into a unified taxonomy. The modular evaluation architecture and systematic benchmark analysis provide actionable guidance for both academic research and industrial deployment. By foregrounding value-oriented metrics and societal impact, the paper sets a new standard for responsible, future-proof LLM assessment. The implications are significant: evaluation is reframed as a strategic compass for LLM development, deployment, and governance, with direct consequences for the trajectory of AI research and its integration into critical domains.