Scaling Embeddings Outperforms Scaling Experts in Language Models
Abstract: While Mixture-of-Experts (MoE) architectures have become the standard for sparsity scaling in LLMs, they increasingly face diminishing returns and system-level bottlenecks. In this work, we explore embedding scaling as a potent, orthogonal dimension for scaling sparsity. Through a comprehensive analysis and experiments, we identify specific regimes where embedding scaling achieves a superior Pareto frontier compared to expert scaling. We systematically characterize the critical architectural factors governing this efficacy -- ranging from parameter budgeting to the interplay with model width and depth. Moreover, by integrating tailored system optimizations and speculative decoding, we effectively convert this sparsity into tangible inference speedups. Guided by these insights, we introduce LongCat-Flash-Lite, a 68.5B parameter model with ~3B activated trained from scratch. Despite allocating over 30B parameters to embeddings, LongCat-Flash-Lite not only surpasses parameter-equivalent MoE baselines but also exhibits exceptional competitiveness against existing models of comparable scale, particularly in agentic and coding domains.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What this paper is about
This paper asks a simple question: when we make big LLMs smarter, should we add more “experts” inside the model, or should we make the model’s “embeddings” bigger? The authors show that, in many cases, growing embeddings gives better results and faster speed than adding more experts. They build and open-source a large model called LongCat-Flash-Lite to prove it.
2) The key questions, in simple terms
Here are the main things the paper investigates:
- Is it more effective to scale up “experts” (MoE) or to scale up “embeddings”?
- When is the right time to add bigger embeddings during training?
- How much of the model’s total size should be spent on embeddings?
- What settings (like vocabulary size or how many n-grams to use) make embedding scaling work best?
- Do wider or deeper models benefit more from bigger embeddings?
- Can bigger embeddings also make the model run faster?
3) How they approached it (with plain-language explanations)
What are “experts” and “embeddings”?
- Mixture-of-Experts (MoE): Imagine a school with many tutors. For each question, the model picks a few tutors who specialize in that topic. This lets the model have lots of knowledge (many tutors) without talking to all of them every time. But as you add more tutors, the improvement gets smaller, and coordinating them becomes slow and expensive.
- Embeddings: Think of an embedding as a unique “ID card” for each token (like words or pieces of words). The embedding holds the meaning the model uses to understand inputs. Looking up an embedding is quick: it’s like finding a card in a cabinet.
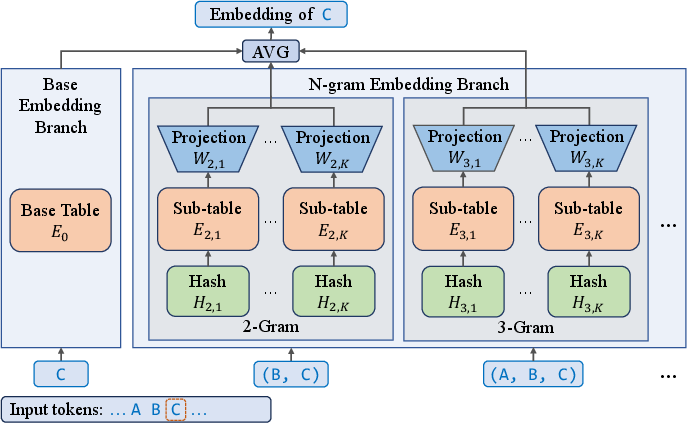
What is an n-gram embedding?
- N-gram means “chunks of N tokens.” For example:
- 2-gram: word pairs like “New York”
- 3-gram: triples like “United States of”
- N-gram embeddings give the model extra “ID cards” not just for single tokens, but also for recent token combinations. This helps the model remember short patterns and local context without heavy computation.
What is hashing, and what are collisions?
- Hashing: A rule that maps a token pair/triple into a number, like assigning each pair to a locker.
- Collision: Two different pairs get the same locker number. That’s bad because their meanings get mixed up in the same place. The authors find ways to choose vocabulary sizes to reduce these collisions.
What did they test?
They trained many models from scratch, keeping the total size the same but:
- In one set, they spent more of the size on “experts.”
- In another set, they spent more of the size on “embeddings” (using n-gram embeddings).
They tracked training and validation loss (how well the model is learning), tested English and Chinese data, and checked:
- When embeddings help more,
- How much to allocate to embeddings,
- What n-gram settings work best,
- Whether wider (fatter) models or deeper (taller) models benefit more,
- And how to make inference (generation) faster.
Speed tricks: speculative decoding and an n-gram cache
- Speculative decoding: Like writing a rough draft quickly and then verifying it. A fast “drafter” proposes several next tokens; the full model checks them in batches. This increases effective batch size and reduces waiting time.
- N-gram Cache: A special memory that remembers recent n-gram lookups so the model doesn’t redo the same work. They also use custom GPU kernels to make this fast.
4) Main findings and why they matter
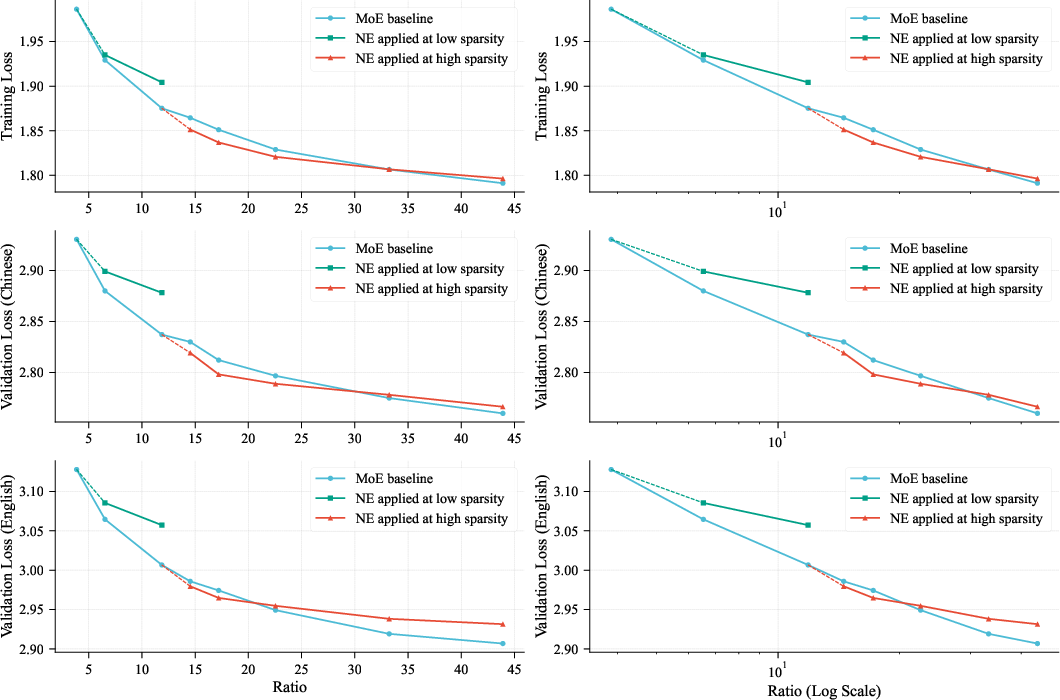
Embeddings can outperform experts—at the right time
- If you keep adding more experts, you eventually hit a “sweet spot” where each extra expert helps less.
- After that point, adding n-gram embeddings gives more improvement per parameter than adding more experts.
- This means embeddings are a powerful, complementary way to scale models.
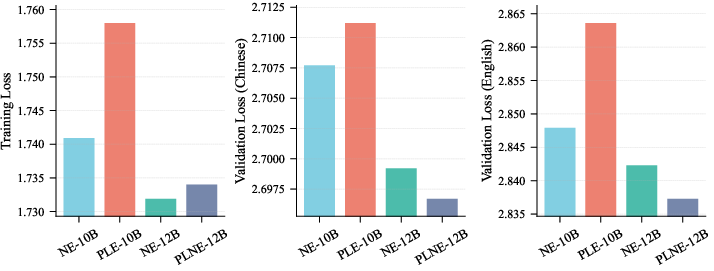
Don’t over-allocate to embeddings
- Spending too much of the total model on embeddings can hurt performance.
- Their rule of thumb: keep embeddings at or below about half of the total parameters.
Avoid unlucky vocabulary sizes
- 2-gram hashing had surprising collision spikes when the n-gram vocabulary size was near integer multiples of the base vocabulary size.
- Choosing vocabulary sizes that are not neat multiples reduces collisions and improves learning.
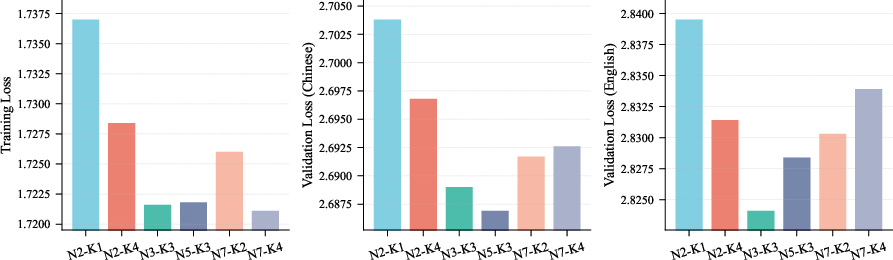
Good n-gram settings
- Using N between 3 and 5 (the size of the chunk) and at least a couple of sub-tables (K ≥ 2) worked best.
- Very low settings (N=2, K=1) were noticeably worse.
- Beyond those ranges, improvements are small.
Wider beats deeper for embedding gains
- Wider models (larger hidden size) get more benefit from bigger embeddings.
- Deeper models (more layers) get less relative benefit because the embedding signal fades as it travels through many layers.
- Most practical models today are not extremely deep, so scaling embeddings is a good match.
Faster inference with embedding scaling
- Moving parameters from experts to embeddings reduces the amount of work done per token in MoE layers.
- Pairing this with speculative decoding and an n-gram cache turns the theoretical savings into real speedups.
A proof-of-concept model: LongCat-Flash-Lite
- Total size: 68.5 billion parameters.
- Activated per token: about 2.9–4.5 billion (very efficient).
- Embeddings: about 31.4 billion parameters (around 46% of total).
- It consistently beats a same-sized MoE-only baseline, especially in agent tasks and coding.
- It’s competitive with other popular models of similar scale while staying efficient.
Why this matters: You can get better performance with fewer active computations per token, which is great for both quality and speed.
5) What this means going forward
- A new path to scale: Instead of piling on more experts, making embeddings smarter and bigger is often a better deal, especially once you’ve passed the expert “sweet spot.”
- Practical speed: Because embedding lookups are cheap, this approach can reduce memory traffic and improve real-world latency—especially when combined with speculative decoding and GPU-friendly kernels.
- Better agents and coding: The model shows strong gains in tool-use and programming tasks, suggesting embedding-rich models may handle structured, step-by-step work more effectively.
- Design guidance for builders:
- Add n-gram embeddings after expert returns start to fade.
- Keep embedding budget ≤ 50% of total.
- Pick n-gram vocabulary sizes that avoid collision spikes.
- Use N around 3–5 and K ≥ 2.
- Favor width over depth to get the most from embeddings.
- Use caches and speculative decoding to turn savings into speed.
In short: Scaling embeddings is a powerful, efficient way to make LLMs smarter and faster, often beating the traditional approach of just adding more experts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete open questions that future work could address:
- Generalization across tokenization schemes: How do results change with different base tokenizers (e.g., byte-level, unigram, BPE sizes beyond 128k), especially for morphologically rich or low-resource languages?
- Multilingual breadth: Beyond Chinese/English, does N-gram Embedding (NE) scaling hold across diverse scripts (e.g., Arabic, Devanagari) and agglutinative languages where n-gram statistics differ markedly?
- Long-context behavior: Since NE encodes short-range dependencies, how does it interact with very long contexts (128k–256k) on tasks requiring long-range reasoning and retrieval?
- Task-specific trade-offs: Why are gains notably larger in coding/agentic tasks than in some general benchmarks (e.g., MMLU)? Are there task profiles where expert scaling remains preferable?
- Formalizing the “sweet spot”: The paper offers heuristics (e.g., “introduce NE when experts exceed sweet spot”)—can we develop a principled, data- and compute-aware criterion to decide when to introduce and how to size NE?
- Embedding/expert budget rule: The “≤50% of total params to NE” guideline is empirical—how does the optimal proportion vary with data scale, domain mix, tokenizer, and optimization settings?
- Width vs. depth trade-off: The observed advantage of NE with increased width and diminished returns with depth lacks a theoretical explanation; can we model and validate these dynamics mathematically and across broader depth/width grids?
- Stability and initialization theory: “Embedding Amplification” (scaling or LayerNorm) improves outcomes, but there is no analysis of gradient flow, variance propagation, or interaction with pre-norm residual pathways; can we derive guidelines for stable NE training?
- Hashing design space: Only polynomial rolling hash was tested; how do alternative hashes (e.g., multiple independent universal hashes, learned hashes, minimal perfect hashing) affect collision rates, accuracy, and throughput?
- Collision measurement rigor: Collision analysis used limited samples (e.g., 100 sequences) and focused on 2-grams; what are corpus-wide collision dynamics across n, languages, and training phases, and how do they correlate with loss/accuracy?
- Vocabulary sizing algorithm: The recommendation to avoid NE vocabulary sizes near integer multiples of the base vocab is heuristic; can we provide an automatic procedure to choose near-optimal sizes (possibly prime factorization constraints or co-prime design) with guarantees?
- Dynamic NE configuration: Can N (order) and K (sub-tables) be adapted during training or per domain, rather than fixed, to balance coverage and learnability as data distribution shifts?
- Frequency-aware NE training: Do rare n-grams under-train given massive NE capacity? Would frequency-aware sampling, adaptive regularization, or optimizer scheduling improve utilization of long-tail entries?
- Regularization and memorization risk: Large embedding tables may overfit or memorize training data; what privacy, safety, and robustness implications does NE introduce (e.g., extraction risks, adversarial n-gram triggers)?
- Fairness of MoE baselines: The baseline “convert NE params to experts” explores one MoE variant; how do results change under different expert architectures (e.g., expert depth/width, top-k, routing losses), non-uniform expert sizes, or expert distillation?
- Comparisons to alternative capacity routes: How does NE compare to Per-Layer Embedding (PLE/STEM), mixture-of-embeddings, kNN-LM/retrieval augmentation, adapters, or larger attention heads for the same activated compute?
- PLNE design space: Per-Layer NE increased activated params and showed inconsistent gains; can low-rank projections, sparse gating, or selective layer placement (e.g., early/mid/late) recover benefits without activation bloat?
- Scheduling NE over training: Rather than one-shot introduction, can we progressively grow NE capacity or reallocate between NE and experts as optimization progresses (curriculum for sparse parameter placement)?
- Inference portability: Custom CUDA kernels, N-gram Cache, and PDL may not port across hardware (A100, consumer GPUs), CPU inference, or vendor runtimes; what are performance and implementation costs in these settings?
- Quantization and compression: The paper mentions quantized kernels but not NE quantization/compression results; what are the accuracy–latency trade-offs for PQ/IVF/low-bit quantization of massive NE tables at training and inference?
- Memory and optimizer overhead: NE tables (~31B params) imply large optimizer states and memory traffic; how do sharding strategies, ZeRO stages, and mixed precision affect training throughput and convergence?
- Latency variability: Activated params vary with context (2.9B–4.5B); how predictable is latency under load and across prompts, and can routing/zero-expert policies be tuned for QoS?
- End-to-end inference benchmarks: The throughput gains are shown for select settings; broader sweeps across batch sizes, sequence lengths (prefill vs decode), hardware types, and single-stream vs multi-stream are missing.
- Speculative decoding synergy is untested: NE-based drafting and early rejection are proposed but not implemented or evaluated; what are the acceptance rates, calibration strategies, and net speed/quality trade-offs?
- Integration with retrieval: Since NE captures local co-occurrence, how does it complement external retrieval (RAG) for long-range knowledge without ballooning NE tables?
- Negative side-effects: Does NE bias models toward local n-gram patterns at the expense of compositional generalization or reasoning? Controlled studies are needed.
- Data and training efficiency: Given 11T pretraining and 1.5T mid-training tokens, what is the compute-normalized efficiency (loss vs FLOPs) relative to MoE scaling, and how does token budget interact with NE benefits?
- Robustness and safety: Are NE models more susceptible to prompt injections that target collision patterns or trigger specific n-gram buckets? Can defenses or auditing tools detect such vulnerabilities?
- Reproducibility and release gaps: Detailed configs (tokenizer specifics, hash seeds, exact NE vocab sizes, collision metrics, kernel implementations) are not fully disclosed; releasing these would enable faithful replication and diagnostic studies.
Practical Applications
Overview
The paper proposes scaling the embedding layer—specifically N-gram Embeddings—as an orthogonal and often superior alternative to scaling Mixture-of-Experts (MoE) parameters in LLMs. It offers design principles (timing, parameter budgeting, vocabulary sizing, hyperparameters, width vs. depth trade-offs), system optimizations (speculative decoding, caches, kernel fusion, PDL), and an open-source model (LongCat-Flash-Lite) that demonstrates improved performance and efficiency, especially for agentic tool use and coding tasks.
Below are actionable, real-world applications and workflows grouped by deployability, with sector tags, potential tools/products, and assumptions/dependencies noted.
Immediate Applications
- Embedding-first scaling guideline for LLM architects
- Description: Adopt N-gram Embedding scaling once MoE sparsity exceeds its “sweet spot”; cap embedding parameters ≤50% of total; set n-gram order N ∈ [3,5], sub-tables K ≥ 2; avoid n-gram vocabulary sizes near integer multiples of the base vocabulary; apply Embedding Amplification (LayerNorm or sqrt(D) scaling) to ensure embedding signal is not drowned by attention.
- Sectors: software/AI infrastructure
- Tools/workflows: architecture review checklist; training configuration templates; embedding module init recipes
- Assumptions/dependencies: model operates in high-sparsity regime; sufficient training corpus; width favored over depth; consistent optimizer and routing schemes
- Deploy LongCat-Flash-Lite for agentic tool-use and coding workloads
- Description: Use the open-source 68.5B model (2.9–4.5B activated) in environments requiring robust tool orchestration and real-world software fixes (SWE-Bench, TerminalBench, PRDBench), and multilingual coding (SWE-Bench Multilingual).
- Sectors: software, retail, telecom, customer support, education
- Tools/products: agentic customer-service bots (airline, retail, telecom), coding assistants that write unit tests and PRs, terminal automation agents
- Assumptions/dependencies: access to GPUs; alignment and guardrails for production agents; domain adapters or fine-tunes for specific industries; license compliance and evaluation reproducibility
- Throughput-centric inference serving with embedded sparsity
- Description: Integrate N-gram Cache (device-side, CUDA kernels), multi-step speculative decoding, wide Expert Parallel (EP), Single Batch Overlap (SBO), kernel fusion, optimized split-KV combine, and Programmatic Dependent Launch (PDL) to translate reduced activated parameters into lower latency and higher throughput.
- Sectors: cloud serving, software/AI infrastructure
- Tools/workflows: Eagle3 or equivalent inference stacks; TensorRT-LLM/FasterTransformer/vLLM plugins; custom CUDA kernels; scheduler integration
- Assumptions/dependencies: large effective batch sizes (speculative decoding), memory bandwidth-bound deployments, modern GPUs (e.g., H800/A100/H200), engineering capacity to add custom kernels and caches
- Cost and energy efficiency for high-volume chatbots and agentic systems
- Description: Reallocate parameters to embeddings to reduce MoE I/O hot paths and activated compute; realize energy and cost savings in memory-bound inference.
- Sectors: retail, telecom, finance, customer support
- Tools/workflows: batch-size tuning, speculative decoding for effective batch expansion, monitoring of memory bandwidth saturation
- Assumptions/dependencies: inference traffic patterns allow batching; system and datacenter constraints support aggressive batching; cost models account for memory I/O
- Domain-specialized N-gram Embeddings
- Description: Build domain-specific n-gram tables (e.g., medical abbreviations, financial tickers, legal clauses) to densify local patterns without adding inference compute.
- Sectors: healthcare, finance, legal, education
- Tools/products: domain adapters for embeddings; corpus-specific hashing vocabularies; enterprise LLMs tuned for sector terminology
- Assumptions/dependencies: curated domain corpora; collision-aware vocabulary sizing; compliance with data privacy/regulatory constraints
- Long-context assistants and document-scale reasoning
- Description: Use training recipe with YARN for extended context (up to 256k tokens) to power long-document review, contract analysis, medical chart synthesis, and curriculum-scale tutoring.
- Sectors: legal, healthcare, education, enterprise knowledge management
- Tools/workflows: long-context retrieval-augmented generation (RAG), chunking strategies, windowed attention policies
- Assumptions/dependencies: fine-tuning on long-context tasks; system memory capacity and KV-cache management; domain-specific safety checks
- Capacity planning and A/B evaluation framework
- Description: Adopt the Pareto frontier analysis (total-to-activated parameter ratio vs. loss) to decide capacity allocation between experts and embeddings, and to set width/depth trade-offs.
- Sectors: academia, AI infra, enterprise AI
- Tools/workflows: scaling curves, loss tracking dashboards, hyperparameter sweep protocols
- Assumptions/dependencies: comparable data and training setups; consistent loss metrics across languages/domains
- Guidance on width-over-depth for embedding-centric models
- Description: Prefer increasing width (hidden size, module dims) over depth to maximize N-gram embedding benefits; maintain depth ≤40 shortcut layers where embedding advantages persist.
- Sectors: software/AI infrastructure
- Tools/workflows: width-focused model configurations; memory and latency profiling
- Assumptions/dependencies: hardware that favors width (memory bandwidth, interconnect); balanced attention/MLP dimensions
- Fine-tune and integrate open model in developer tooling
- Description: Plug LongCat-Flash-Lite into CI/CD to auto-generate unit tests, validate patches, and propose PRs; support multi-language codebases.
- Sectors: software engineering
- Tools/workflows: GitHub/GitLab actions, PRDBench-like evaluation harnesses, policy-compliant secret management
- Assumptions/dependencies: repository permissions, guardrails for code safety, integration with test runners
- Customer support and operations agents with tool orchestration
- Description: Deploy agents for airline booking changes, retail order resolution, telecom troubleshooting—leveraging high tool-use scores and reduced serving costs.
- Sectors: retail, telecom, travel
- Tools/workflows: tool API catalogs, error-handling policies, escalation workflows
- Assumptions/dependencies: robust tool interfaces; logging and audit trails; fail-safe mechanisms
Long-Term Applications
- N-gram-driven speculative drafting and early-rejection pipelines
- Description: Use N-gram Embedding outputs as ultra-fast draft predictors and as semantic consistency checks to early-reject improbable draft tokens before verification.
- Sectors: software/AI infrastructure
- Tools/products: NE-based micro-drafters; verification-pruning modules
- Assumptions/dependencies: research validation of accuracy/speed trade-offs; integration with speculative schedulers; reliability/safety assessments
- Layer-wise embedding allocation optimization (PLNE variants)
- Description: Optimize where and how much embedding capacity to inject per layer (dense vs. expert layers, specific layer subsets) to balance activated parameters and accuracy.
- Sectors: academia, AI infra
- Tools/workflows: automated layer allocation search; per-layer profiling; dynamic routing
- Assumptions/dependencies: reproducible training experiments; layer-wise instrumentation
- Collision-aware hashing and learned hashing functions
- Description: Develop hash functions and vocabulary sizing strategies that minimize pathological collisions (especially for 2-grams), possibly learning maps end-to-end.
- Sectors: academia, AI infra
- Tools/products: hashing libraries; collision diagnostics
- Assumptions/dependencies: training stability, overhead trade-offs, compatibility with GPU kernels
- Edge and on-device embedding-centric LLMs
- Description: Architect models that favor large embedding tables and O(1) lookups with minimal activated compute for low-power devices; pair with memory-optimized hardware.
- Sectors: robotics, consumer devices, IoT
- Tools/products: embedded inference SDKs; memory-specialized accelerators; quantized NE tables
- Assumptions/dependencies: hardware support for high-capacity memory; efficient quantization of embedding tables; privacy-preserving deployment
- Standardization and policy for energy-efficient LLM serving
- Description: Create best-practice guidelines and procurement standards prioritizing memory-I/O-aware designs (embedding scaling, speculative decoding) to reduce energy per token.
- Sectors: policy, energy, cloud providers
- Tools/workflows: energy benchmarks; carbon accounting frameworks
- Assumptions/dependencies: consensus on metrics; third-party audits; alignment with regulatory bodies
- Safety and privacy auditing for embedding-rich models
- Description: Evaluate whether enlarged embeddings intensify memorization of co-occurring sensitive sequences and define mitigation (differential privacy, redaction).
- Sectors: healthcare, finance, legal
- Tools/workflows: memorization tests; privacy risk assessments; DP training variants
- Assumptions/dependencies: rigorous datasets; acceptable utility/privacy trade-offs; compliance requirements
- Retrieval synergy with N-gram embeddings
- Description: Combine NE with local retrieval of recent n-gram contexts (session or domain caches) to further improve short-range dependency modeling and speed.
- Sectors: enterprise search, customer support
- Tools/products: session-level n-gram stores; hybrid NE/RAG pipelines
- Assumptions/dependencies: cache consistency; latency budgets; relevance filters
- Auto-tuning of NE hyperparameters and budgets
- Description: Build meta-optimization pipelines that select N, K, and embedding budget share per task/domain, exploiting width/depth sensitivity.
- Sectors: AI tooling, MLOps
- Tools/workflows: Bayesian optimization; multi-objective search; continuous evaluation loops
- Assumptions/dependencies: compute budgets for tuning; robust metrics; generalizable settings
- Embedding compression, quantization, and dynamic caching
- Description: Create specialized compression/quantization schemes for massive NE tables with minimal quality loss; dynamic device-side caches for hot n-grams.
- Sectors: cloud serving, edge devices
- Tools/products: quantization toolkits; NE-aware cache managers
- Assumptions/dependencies: acceptable accuracy degradation; kernel support; cache eviction strategies
- Expanded academic investigations into vocabulary scaling laws
- Description: Validate and extend scaling laws across languages (morphologically rich, byte-level), tasks (reasoning vs. coding), and architectures (pre-/post-norm, routing variants).
- Sectors: academia
- Tools/workflows: cross-lingual datasets; standardized loss/efficiency baselines
- Assumptions/dependencies: access to diverse corpora; reproducible training/inference environments
Cross-cutting assumptions and dependencies
- Hardware: benefits are largest on memory bandwidth-limited GPUs; large effective batch sizes and speculative decoding are critical to realize speedups.
- Model design: embedding budget should not exceed ~50% of total; advantages grow with width and taper with depth; avoid n-gram vocab sizes near integer multiples of base vocab.
- Software: requires integration of N-gram Cache, custom kernels, PDL, and speculative schedulers; adoption in mainstream inference frameworks is desirable.
- Data and safety: domain-specific NE requires high-quality corpora and careful privacy governance; production agents need guardrails, auditability, and fallback mechanisms.
Glossary
- Activated experts: The subset of experts actually used during inference for a given batch or token. "Number of activated experts in LongCat-Flash-Lite versus LongCat-Flash-Lite-Vanilla across varying batch sizes."
- Activated parameters: The parameters that contribute to computation for a specific token/context in sparse architectures. "68.5B total parameters and 2.9B4.5B activated parameters depending on the context."
- Agentic coding: Coding tasks where the model acts autonomously to solve real-world software problems and execute actions. "Agentic Coding Tasks: SWE-Bench ~\citep{jimenez2023swe}, TerminalBench ~\citep{merrill2026terminalbenchbenchmarkingagentshard}, SWE-Bench Multiligual~\citep{yang2025swesmith}, and PRDBench~\citep{fu2025automatically}."
- Agentic tool use: Scenarios where the model coordinates external tools to accomplish tasks. "Agentic Tool Use Tasks: Bench~\citep{tau2-bench}, Vita Bench ~\citep{he2025vitabench}."
- AllGather: A collective communication operation that gathers tensors from all ranks and concatenates them. "AllGather + Q-Norm + KV-Norm"
- AllReduce: A collective operation that sums (or applies another reduction) across ranks and broadcasts the result. "AllReduce + Residual Add + RMSNorm"
- Draft model: A lightweight model used to propose multiple future tokens in speculative decoding before verification. "In speculative decoding scenarios, where the draft model typically operates with fewer layers and substantially lower latency"
- Early rejection: A speculative decoding optimization that discards draft tokens likely to be incorrect before full verification. "Draft tokens that result in low-probability match under N-gram Embedding\ might be \"early-rejected\" before entering the expensive verification phase of the target model."
- Embedding Amplification: Techniques (scaling or normalization) to increase the impact of embedding outputs in the residual stream. "these methods---collectively termed Embedding Amplification---substantially enhance the performance of N-gram Embedding."
- Embedding scaling: Increasing parameters in the embedding layer (e.g., via n-grams) as an orthogonal sparsity scaling dimension. "we explore embedding scaling as a potent, orthogonal dimension for scaling sparsity."
- Expert Parallel (EP): A parallelization strategy that distributes experts across devices to scale MoE models. "we adopt wide EP~(Expert Parallel) and SBO~(Single Batch Overlap) to accelerate inference speed."
- Expert scaling: Increasing the number or capacity of experts in MoE to add parameters while keeping compute manageable. "embedding scaling achieves a superior Pareto frontier compared to expert scaling."
- Feed-Forward Networks (FFNs): The MLP submodules within transformer layers, often serving as experts in MoE. "beyond the Feed-Forward Networks (FFNs)."
- Hash collisions: Different n-grams mapping to the same index in a hashed embedding table, conflating representations. "In the context of N-gram Embedding, hash collisions force a single embedding vector to superimpose the semantics of multiple distinct n-grams."
- Kernel fusion: Combining multiple GPU kernels into one to reduce launch overhead and memory traffic. "We apply extensive kernel fusion to reduce execution overhead and memory traffic."
- KV cache: Cached key/value tensors used to accelerate autoregressive attention during decoding. "a specialized caching mechanism inspired by the design principles of the KV cache."
- KV splits: Partitioning key/value tensors across chunks (e.g., for parallelism), requiring later combination. "When the number of KV splits is high, the combine operation can incur significant latency"
- LayerNorm: A normalization method applied to stabilize and scale activations per feature across a layer. "Applying LayerNorm to the embedding output prior to merging with the residual branch."
- Memory I/O-bound decoding: A regime where inference speed is limited by data movement rather than compute. "particularly advantageous in memory I/O-bound decoding scenarios with large token counts."
- Mixture-of-Experts (MoE): A sparse model architecture that routes tokens to a subset of specialized experts to scale parameters efficiently. "The Mixture-of-Experts (MoE) architecture has firmly established itself as the dominant paradigm for scaling LLMs"
- N-gram Cache: A device-side cache for n-gram IDs/embeddings to minimize recomputation and synchronization overhead. "we introduce the N-gram Cache, a specialized caching mechanism"
- N-gram Embedding: An embedding method that augments token embeddings with hashed n-gram representations to scale capacity. "To scale the embedding parameters, we adopt the N-gram Embedding\ introduced in \cite{clark-etal-2022-canine, huang2025overtokenizedtransformervocabularygenerally, pagnoni-etal-2025-byte}"
- O(1) lookup complexity: Constant-time retrieval from embedding tables regardless of their size. "the embedding layer offers an overlooked, inherently sparse dimension with lookup complexity."
- Over-Encoding: A variant of n-gram embedding that decomposes n-gram tables into sub-tables plus projections. "The final version of N-gram Embedding\ (also referred to as Over-Encoding in \cite{huang2025overtokenizedtransformervocabularygenerally})"
- Pareto frontier: The set of optimal trade-offs where improving one metric (e.g., loss) cannot happen without worsening another (e.g., params/latency). "embedding scaling achieves a superior Pareto frontier compared to expert scaling."
- Per-Layer Embedding (PLE): Allocating dedicated embedding parameters per layer (often injected into FFN) to increase capacity. "Per-Layer Embedding (PLE) is another way to scale parameters by allocating embedding parameters across layers."
- PLNE (Per-Layer N-gram Embedding): A PLE extension that uses n-gram embeddings per layer for richer, scalable injection. "we propose Per-Layer N-gram Embedding (PLNE), a novel extension that replaces the base embedding outputs with N-gram Embedding\ outputs at each layer"
- Polynomial rolling hash: A family of hash functions that combine token IDs with polynomial weighting modulo table size. "We use the polynomial rolling hash funciton:"
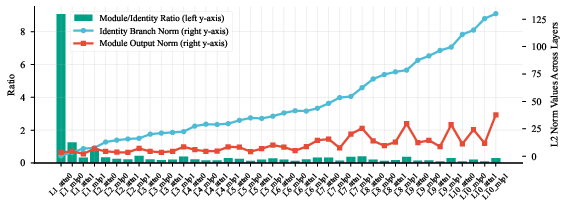
- Pre-normalization architectures: Transformer designs that apply normalization before sublayers (attention/FFN), affecting residual signal propagation. "For pre-normalization architectures, the contribution of N-gram Embedding\ through the identity connection (residual branch) inherently diminishes as network depth increases"
- Programmatic Dependent Launch (PDL): An NVIDIA mechanism enabling overlapping launches of dependent kernels to reduce gaps. "We utilize PDL ~\citep{pdl_nvidia} to allow dependent kernels to overlap their execution by triggering early launches."
- Residual branch: The identity path in a residual connection that carries the previous layer’s activations forward. "Applying LayerNorm to the embedding output prior to merging with the residual branch."
- RMSNorm: Root-mean-square normalization variant used to stabilize and scale activations. "AllReduce + Residual Add + RMSNorm"
- Router logits: Scores computed by the MoE router to select which experts a token should be sent to. "the processing of router logits (Softmax + TopK + router scaling) and zero-expert selection is consolidated into a single unified kernel."
- Single Batch Overlap (SBO): An inference optimization that overlaps stages within a single batch for better GPU utilization. "we adopt wide EP~(Expert Parallel) and SBO~(Single Batch Overlap) to accelerate inference speed."
- Speculative decoding: An inference method where a draft model proposes multiple tokens and a larger model verifies them to increase throughput. "paired with speculative decoding to maximize hardware utilization."
- Splitkv-and-combine: An attention optimization that splits KV across partitions and efficiently merges them during decoding. "We employ a splitkv-and-combine strategy during decoding phase."
- SwiGLU: A gated activation function (SiLU-gated linear unit) used in transformer FFNs for improved performance. "PLE directly substitutes the output of up-projection matrix in the SwiGLU module with the embedding output"
- Verification step: The phase in speculative decoding where the target model validates or rejects drafted tokens. "eliminate redundant computations during the subsequent verification step."
- Vocabulary Hit Rate: The fraction of entries in an embedding table that are activated at least once by the training corpus. "Vocabulary Hit Rate, defined as the proportion of vocabulary entries activated at least once by the pre-training corpus"
- YARN: A method to extend context length by modifying rotary position embeddings for long sequences. "we implement YARN~\citep{Peng2023YaRNEC} during the 32k sequence length training stage"
- Zero-experts: Special experts that perform no computation but can be selected to control activation sparsity and routing behavior. "the MoE module consists of 256 FFN experts and 128 zero-experts, and each token selects 12 experts."
Collections
Sign up for free to add this paper to one or more collections.