Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Abstract: While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Engram, a new “memory” add-on for LLMs like Transformers. Today’s models are great at thinking (reasoning), but they aren’t built to quickly look up facts they’ve seen before. Engram adds a fast, simple way to look up common patterns (like names, phrases, or code snippets) so the model doesn’t waste time “recomputing” them. The big idea: split the model’s job into two parts—thinking (computation) and remembering (memory lookups)—and balance them for better performance.
What questions did the researchers ask?
- Can we give LLMs a built-in way to “remember” common text patterns quickly, instead of making them reconstruct these patterns over and over?
- If we have a fixed “budget” of model size and compute, what is the best way to split it between:
- conditional computation (Mixture-of-Experts, or MoE: only some “experts” run per token), and
- conditional memory (Engram: only some lookups happen per token)?
- Does adding this memory help only with facts and trivia, or does it also help with reasoning, coding, math, and long documents?
- Can this memory be used efficiently in real systems (e.g., by fetching needed entries ahead of time)?
How does it work? (In simple terms)
Think of an LLM like a student taking a test:
- Some questions need reasoning (solve a puzzle).
- Some are lookups (remember a name or a formula).
Today’s Transformers handle both by “thinking,” which is expensive. Engram gives the student a fast, organized notebook (memory) to look up repeated patterns instantly.
Here’s the basic approach:
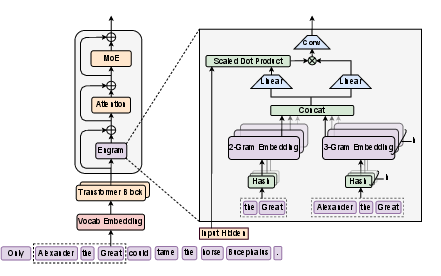
- N-grams as keys: An “N-gram” is a short sequence of tokens (like the last 2–3 words). Engram uses these local chunks as keys to a huge table of stored vectors (like entries in a dictionary).
- O(1) lookup: Each lookup is “constant-time,” like jumping straight to a dictionary entry, not searching through the whole book.
- Hashing with multiple heads: To avoid collisions (different phrases mapping to the same spot), Engram uses several different hash functions—like organizing a library with multiple indexing systems.
- Context-aware gate: Before using a looked-up memory entry, the model checks “Does this fit what I’m currently thinking?” If yes, it uses it; if not, it ignores it. This avoids wrong or out-of-context facts.
- Lightweight smoothing: A tiny convolution adds local smoothing so the looked-up info blends well with the current sentence.
- Placement: Engram isn’t used in every layer—only where it helps most and fits system timing.
- Works with MoE: MoE handles dynamic reasoning (picking which experts think). Engram handles static memory (picking which entries to recall). Together, they share the workload.
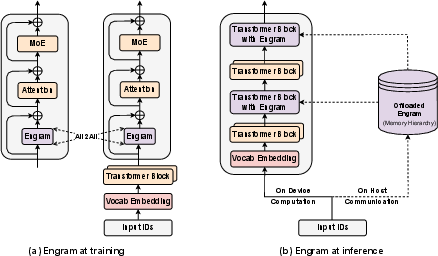
System-wise, Engram is efficient:
- During training, the big tables are split across GPUs.
- During inference, lookups are predictable from the input, so the system can prefetch memory from CPU/RAM or even SSD ahead of time, hiding most of the cost.
What did they find?
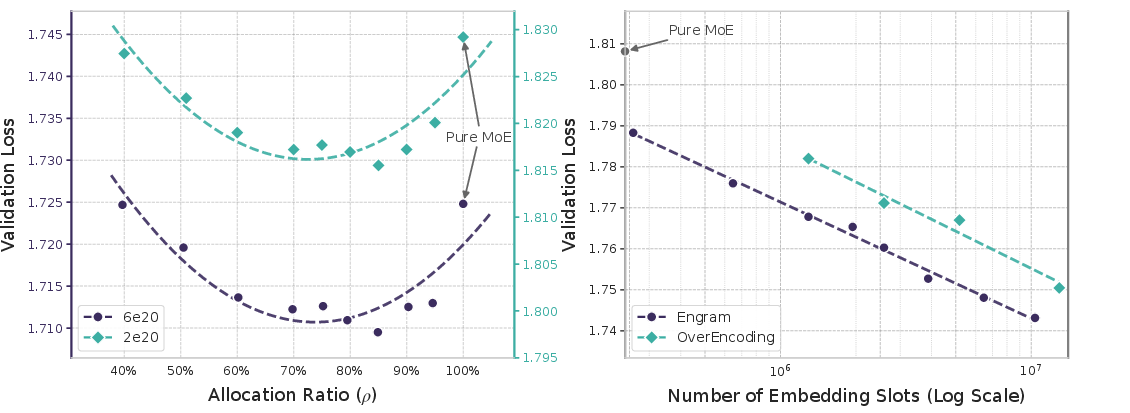
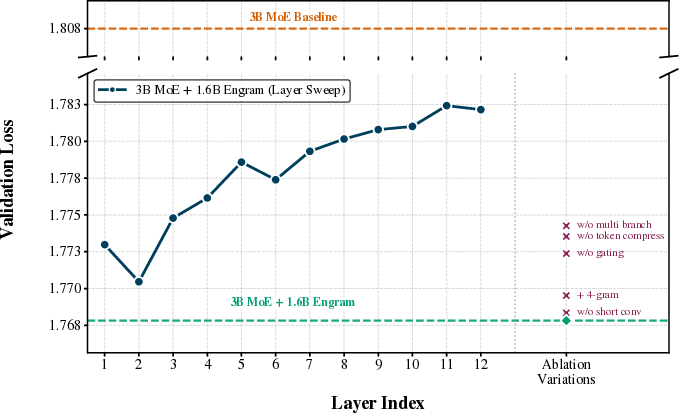
- Balance beats extremes (the “U-shaped” law): If you put all your budget into “thinking” (MoE only) or all into “remembering” (memory only), you do worse. The best results come from mixing both. In their tests, the sweet spot was roughly:
- about 75–80% of the “inactive” parameters for MoE (thinking),
- about 20–25% for Engram (memory).
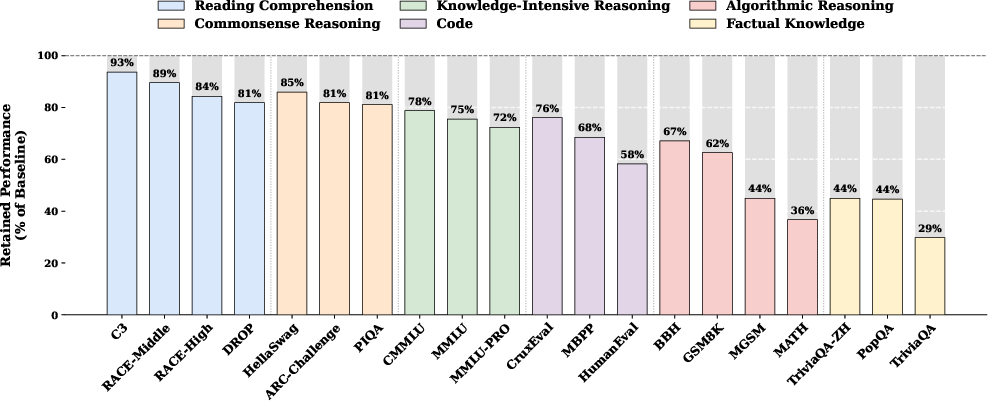
- Big improvements across many tasks at the same compute (iso-FLOPs) and same total size (iso-parameters) compared to a strong MoE baseline:
- Knowledge tasks (facts): MMLU roughly +3 points, CMMLU roughly +4.
- Reasoning tasks: BBH roughly +5, ARC-Challenge roughly +3.7, DROP roughly +3.3.
- Code/math: HumanEval roughly +3, MATH roughly +2.4, GSM8K roughly +2.2.
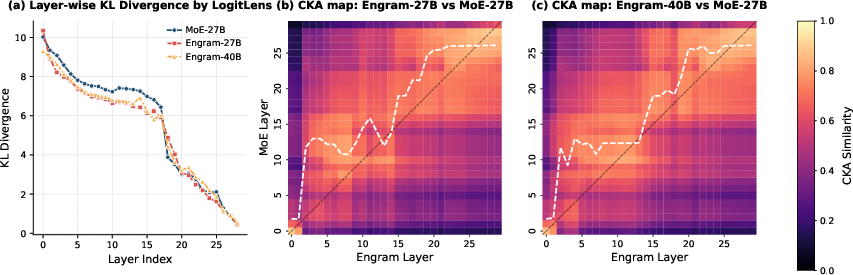
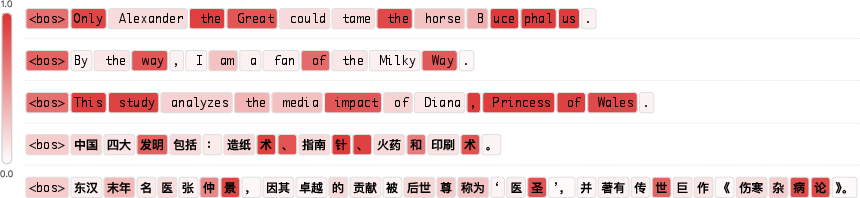
- Not just for facts—reasoning gets better too: Because Engram handles local, repeatable patterns, the model’s attention and layers are freed to focus on long-range logic. This acts like “making the network effectively deeper” for hard problems.
- Strong long-context gains: On tests that hide information in very long texts, Engram boosts retrieval a lot (for example, Multi-Query Needle-in-a-Haystack improved from about 84.2 to 97.0; Variable Tracking from about 77.0 to 89.0).
- Scales smoothly: Making the memory bigger keeps helping (performance improves in a predictable, steady way) without increasing per-token compute.
- System efficiency: Because Engram’s lookups depend only on the input tokens, the system can prefetch entries at runtime. Even offloading a huge (100B+) memory table to host memory adds under 3% overhead, meaning you can scale memory far beyond GPU limits.
Why this matters:
- The model spends less effort “rebuilding” known phrases (like “Diana, Princess of Wales”) across layers, so it can use those layers to think.
- Attention has more room to handle global context, which helps with long documents and multi-step reasoning.
Why this matters and what it could change
- New building block for AI models: Just like MoE made “conditional computation” standard, Engram makes “conditional memory” a first-class tool. Future models can plan how much to spend on thinking vs. remembering.
- Better performance at the same cost: With the same training compute and total size, adding Engram brings noticeable gains across knowledge, reasoning, code, math, and long-context tasks.
- Practical scaling: Because memory lookups are predictable and cheap to fetch, we can store massive memories outside the GPU and still run fast. This opens the door to huge, efficient models that combine smart reasoning with fast recall.
- Clear design rule (the U-shaped law): Don’t go all-in on either compute or memory; the best results come from a thoughtful mix. This gives model builders a simple guideline for allocating parameters.
In short: Engram helps LLMs remember common patterns instantly so they can spend more effort on real thinking. That simple change not only boosts fact recall but surprisingly improves reasoning, coding, math, and long-context understanding—without increasing the compute budget. Code: https://github.com/deepseek-ai/Engram
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Quantify and characterize hash collisions: measure per-order (n), per-head (k) collision rates, their distribution over Zipfian n-grams, and their impact on accuracy, stability, and learning dynamics.
- Disambiguation limits under polysemy: evaluate when the scalar gate fails to suppress spurious lookups and assess alternatives (multi-dimensional/multi-head gating, cross-position gating) for better context sensitivity.
- Optimal N-gram order selection: systematically ablate N (beyond N=3) to determine accuracy/latency trade-offs, especially for code and highly compositional text.
- Head count and embedding dimension sensitivity: map performance vs. K (hash heads) and memory vector dimensionality; identify diminishing returns and optimal configurations by domain.
- Tokenizer compression side effects: quantify how the surjective projection (NFKC, lowercasing) affects case-sensitive domains (code, proper nouns), languages with diacritics, and scripts beyond Latin/CJK.
- Multilingual and morphologically rich languages: test Engram in agglutinative and morphologically complex languages where subword boundaries and n-gram regularities differ; validate whether compression and hashing remain effective.
- Placement strategy of Engram layers: derive and validate a principled placement policy beyond the ad hoc choice (layers 2 and 15), jointly optimizing modeling benefit and prefetch overlap on diverse hardware.
- Generality of the U-shaped allocation law: extend sparsity-allocation experiments beyond two compute regimes and a single backbone/top-k; test across larger scales, different MoE top-k, different Ptot/Pact sparsity ratios, and varied data regimes.
- Infinite-memory scaling boundaries: determine when returns saturate as table size grows; identify practical limits due to collisions, optimizer state growth, or training signal sparsity.
- Training stability and optimization: assess sensitivity to separate optimizer choices (e.g., Adam with 5× LR on embeddings), initialization (e.g., zero-init conv), and interactions with backbone/MoE updates.
- Catastrophic interference between colliding entries: diagnose if frequent/rare n-grams interfere during training; explore anti-collision training (e.g., collision-aware loss, rehashing) or adaptive collision mitigation.
- Memory update and continual learning: develop procedures for updating Engram entries post-pretraining (e.g., time-stamped or TTL-based updates) without destabilizing the backbone; evaluate knowledge freshness and unlearning.
- Cache hierarchy design: implement and benchmark concrete cache policies (tiers, eviction, prewarm) with hit-rate/latency curves under realistic serving workloads and Zipf tail behaviors.
- System overhead and reproducibility of the “<3%” claim: report tokens/sec, p50/p95/p99 latency, and throughput under varied interconnects (PCIe Gen4/5, NVLink), CPUs, NUMA layouts, and multi-tenant loads.
- Decode vs. prefill behavior: analyze prefetch feasibility and performance for autoregressive decoding (where future tokens are unknown), especially with small batches and streaming inputs.
- Distributed training scalability: quantify communication overhead (All-to-All for massive tables), optimizer state memory for embeddings, gradient staleness, and cross-node bandwidth constraints at 100B+ memory scales.
- Fairness of baselines: expand comparisons beyond OverEncoding and a single MoE variant to include alternative memory-augmented approaches (e.g., kNN-LM, SCONE under matched compute, retrieval-augmented modules) and non-attention state-space models.
- Interaction with RAG and tools: explore complementary integration of Engram with retrieval-augmented generation, tool use, and external knowledge bases; assess redundancy vs. synergy.
- Downstream alignment and SFT/RLHF: test whether instruction tuning or RLHF preserves, suppresses, or distorts Engram’s benefits; evaluate stability and safety post-alignment.
- Long-context generalization: extend evaluations beyond LongPPL/RULER to realistic long-document QA/summarization benchmarks (e.g., QuALITY, GovReport), multi-document workflows, and multilingual long-context tasks.
- Mechanistic causality vs. correlation: complement LogitLens/CKA with causal ablations (e.g., disabling Engram at inference, targeted patching) to show direct causal contribution to “effective depth” and attention capacity freeing.
- Attention-capacity evidence: provide quantitative attention-map or head-usage analyses showing reallocation from local to global dependencies when Engram is active.
- Error analysis and failure modes: enumerate concrete cases where Engram retrieval harms performance (e.g., misleading local stereotypes, rare collisions) and propose detection/mitigation strategies.
- Security and privacy risks: assess PII memorization in static tables, adversarial “hash flooding” attacks, vulnerability to prompt-based collision exploitation, and protocols for redaction/unlearning.
- Domain transfer and robustness: evaluate robustness under distribution shift (new domains, noisy tokenization), adversarial perturbations, and low-resource fine-tuning.
- Energy and cost efficiency: report wall-clock time, energy per token, and cost-per-quality improvements during training and serving to substantiate “infrastructure-aware efficiency.”
- Effects on MoE specialization: study whether Engram alters expert routing patterns, specialization, or entropy; evaluate if fewer experts degrade diversity and how memory compensates.
- Instruction-following and reasoning depth: investigate whether Engram benefits survive chain-of-thought prompting, toolformer-style reasoning, and complex multi-hop tasks beyond synthetic probes.
- Larger-scale and frontier applicability: validate the allocation ratio and memory offload claims at frontier scales (>100B activated params) and across different vendor hardware and cluster topologies.
- Robustness across tokenizers: test BPE, unigram, and byte-level tokenizers, and explore whether tokenizer design should co-evolve with Engram (e.g., memory-aware tokenization).
- Ablations on convolutional refinement: vary kernel sizes/dilations and test whether the depthwise causal conv contributes meaningfully beyond identity, especially at larger N.
- Quantization and compression of Engram tables: explore FP8/INT8 quantization, pruning, or product quantization for the memory without losing gains; measure accuracy–latency–size trade-offs.
- Statistical significance and variance: report confidence intervals and seed variance on key benchmarks to confirm that observed gains (e.g., +2–5 points) are robust.
Practical Applications
Overview
Below are practical, real-world applications of the paper’s conditional memory module (Engram) and its sparsity allocation laws. Applications are grouped into Immediate and Long-Term categories, with sector tags, example tools/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
- Improved enterprise chatbots and assistants with better factual recall and reasoning
- Sectors: software, customer support, healthcare, finance, legal
- What: Integrate Engram into existing MoE-based LLMs to improve knowledge-intensive QA (e.g., MMLU/CMMLU gains) and complex reasoning (BBH, ARC-Challenge), while keeping iso-FLOPs.
- Tools/workflows: Fine-tune or distill MoE backbones with Engram modules at early layers; deploy using deterministic memory prefetch on inference servers.
- Dependencies/assumptions: Requires model modification and retraining; host memory bandwidth and PCIe throughput must support prefetch; domain-specific normalization rules for tokenizer compression.
- Long-document processing for contracts, reports, and medical records
- Sectors: legal, finance, healthcare, education
- What: Use Engram to free attention for global context, improving long-context retrieval and tracking (e.g., Multi-Query NIAH, Variable Tracking in RULER).
- Tools/workflows: Context window extension (e.g., YaRN) plus Engram placement optimized for latency overlap; multi-level caching for frequent n-grams.
- Dependencies/assumptions: Gains depend on correctly placing Engram early enough to offload local dependencies while ensuring sufficient overlap window for prefetch.
- Code assistants that scale to large repositories
- Sectors: software
- What: Enhance pass@1 and reasoning (HumanEval, MBPP, CruxEval) by offloading local patterns (identifiers, idioms) to conditional memory, preserving attention for cross-file reasoning.
- Tools/workflows: Domain-specific tokenizer compression (normalize naming conventions), hashed n-gram tables for code tokens, branch-specific gating integration.
- Dependencies/assumptions: Benefits rely on Zipfian distribution of code tokens; collision mitigation via multi-head hashing and gating must be tuned.
- Domain lexicon and glossary memory for specialized industries
- Sectors: healthcare, biotech, law, finance, manufacturing
- What: Construct Engram tables with canonicalized domain terms (e.g., ICD codes, legal citations, product SKUs) to reduce hallucinations and increase precision.
- Tools/workflows: Data pipelines for NFKC normalization, lowercasing, synonym mapping; per-domain surjective
V -> V'projection; hashed n-gram table build and deployment. - Dependencies/assumptions: Requires high-quality curation; polysemy and collisions must be mitigated with contextual gating; compliance checks for sensitive terms.
- Cost-effective inference via host-memory offloading and deterministic prefetch
- Sectors: cloud infrastructure, AI platforms
- What: Offload large memory tables (up to ~100B params) to CPU or NVMe with <3% overhead using deterministic addressing and overlap with prior block compute.
- Tools/workflows: Asynchronous prefetch in Triton/TensorRT/vLLM-like runtimes; multi-level caches (HBM/DRAM/NVMe).
- Dependencies/assumptions: Sustained PCIe/NVLink bandwidth; careful layer placement to hide latency; runtime changes to support prefetch scheduling.
- RAG systems with better global reasoning under long contexts
- Sectors: search, enterprise knowledge management
- What: Use Engram to handle local dependencies so attention can focus on retrieved passages, improving multi-hop QA over large context windows.
- Tools/workflows: Hybrid pipeline: vector database + Engram-augmented LLM; memory cache for frequent query patterns and common entities; routing policies for Engram use.
- Dependencies/assumptions: Requires integration with RAG stack; model training with Engram-aware prompts; cache warm-up driven by real query distributions.
- Architecture design guidance using the U-shaped sparsity allocation law
- Sectors: model development, MLOps
- What: Allocate ~20–25% of the sparse parameter budget to Engram (ρ ≈ 75–80%) under fixed iso-FLOPs, instead of pure MoE, to reduce validation loss and improve broad benchmarks.
- Tools/workflows: Auto-config tools to compute
P_sparsesplit; ablation to find optimal expert count vs memory slots for target compute budgets. - Dependencies/assumptions: Optimal ρ may shift at different scales or tasks; controlled iso-FLOPs comparisons and consistent training regimes required.
- Reliability and moderation scaffolds via static memory
- Sectors: trust & safety, compliance
- What: Store frequent policy patterns (e.g., disallowed requests, red-team triggers) as memory entries; gating suppresses contradicting contexts, reducing unsafe generations.
- Tools/workflows: Policy lexicon compiler to Engram tables; audit logs of memory hits; periodic updates without full retraining.
- Dependencies/assumptions: Precision of suppression depends on gate calibration; must avoid over-suppression of legitimate contexts; governance of memory updates.
- Multilingual normalization for robust tokenization
- Sectors: localization, global products
- What: Use vocabulary projection (NFKC, case-folding) to reduce effective vocabulary (~23% in paper) and improve semantic density for memory lookup across variants (e.g., “Apple” vs “ apple”).
- Tools/workflows: Language-specific normalization pipelines; evaluation on multilingual benchmarks (CMMLU, C-Eval).
- Dependencies/assumptions: Language-specific edge cases (scripts, diacritics); impacts subword boundaries; requires careful validation to avoid semantic drift.
- Academic reproducibility and mechanistic analyses
- Sectors: academia
- What: Adopt Engram to study how offloading static reconstruction increases effective depth (LogitLens, CKA) and affects attention allocation; replicate U-shaped scaling and infinite-memory regimes.
- Tools/workflows: Open-source repository; interpretability suite; benchmark trajectories across training; iso-compute experimental design.
- Dependencies/assumptions: Access to compute and memory offloading infrastructure; consistent token budgets and prompts; careful statistical controls.
- Productivity tools for document summarization and pattern-heavy tasks
- Sectors: consumer productivity
- What: Faster, more accurate summarization and pattern matching in emails, spreadsheets, and notes due to lookup of stereotyped phrases and formulas.
- Tools/workflows: Lightweight Engram-enabled assistants deployed on desktops/edge servers; cache frequent phrases locally.
- Dependencies/assumptions: Device memory and bandwidth constraints; privacy rules for local caches.
Long-Term Applications
- Memory-centric AI platforms with massive conditional memory
- Sectors: cloud, enterprise software, public sector
- What: Scale Engram tables to hundreds of billions of parameters, turning “knowledge as parameters” into an auditable, editable substrate separable from compute.
- Tools/workflows: Memory compilers (canonicalization, hashing), tiered storage (HBM/DRAM/NVMe/Object store), versioned memory updates independent of model weights.
- Dependencies/assumptions: Robust prefetch scheduling; storage reliability; policies for memory provenance and updates.
- Personalized on-device conditional memory
- Sectors: mobile, consumer, healthcare
- What: User-specific Engram memories for contacts, preferences, medical histories; privacy-preserving updates without retraining backbone.
- Tools/workflows: On-device memory tables; federated update protocols; opt-in normalization and collision mitigation per user.
- Dependencies/assumptions: On-device storage and bandwidth; strong privacy and consent frameworks; edge runtime support.
- Energy-efficient AI policy and procurement
- Sectors: policy, sustainability, CIO offices
- What: Encourage conditional memory primitives in LLM procurement standards to achieve better performance at constant FLOPs (lower energy per task).
- Tools/workflows: Benchmark-based energy and performance SLAs; reference architectures for memory offloading; public-sector long-context service designs.
- Dependencies/assumptions: Transparent reporting of FLOPs and energy; standardized evaluation; vendor support.
- Memory–compute AutoML for frontier-scale models
- Sectors: model development, AutoML
- What: Automated tuning of the ρ allocation, expert counts, Engram slots, and placement to meet task-specific objectives under compute/storage constraints.
- Tools/workflows: Bayesian optimization/BOHB on
P_sparsesplit; placement search constrained by latency overlap and modeling performance; synthetic workload generation. - Dependencies/assumptions: Access to large-scale training runs; reliable iso-FLOPs comparisons; hardware-aware search.
- Hybrid hardware co-design for memory-first architectures
- Sectors: semiconductors, systems
- What: Specialized accelerators and interconnects (e.g., NVMe-oF, CXL) optimized for deterministic retrieval, prefetch windows, and cache hierarchies.
- Tools/workflows: Runtime schedulers that expose memory indices early; cross-layer overlap tuning; hardware simulators for cache hit modeling (Zipfian loads).
- Dependencies/assumptions: Industry consensus on APIs; capital investment; co-design cycles with model teams.
- Transparent, auditable knowledge bases embedded in LLMs
- Sectors: compliance, legal, finance
- What: Maintain Engram memory versions with provenance and TTL; audit which entries were hit during generation for traceability.
- Tools/workflows: Memory hit tracing; explainability dashboards; policy-compliant update pipelines.
- Dependencies/assumptions: Provenance metadata and governance; user permissions; potential legal exposure if memory content is incorrect or outdated.
- Curriculum and training strategies exploiting memory scaling laws
- Sectors: academia, model training
- What: Develop curricula that progressively populate Engram with frequent n-grams, leveraging infinite-memory scaling behavior; reduce backbone depth for static composition.
- Tools/workflows: Frequency-based data sampling; staged memory growth; collision-aware table expansion.
- Dependencies/assumptions: Stable scaling in larger regimes; diminishing returns modeling; careful monitoring of polysemy and collisions.
- Safer, more controllable generative systems
- Sectors: safety, content platforms
- What: Use Engram to encode safety-critical patterns and allow policy updates without full model retraining; gate out-of-policy continuations deterministically.
- Tools/workflows: Safety memory compiler; continuous integration of red-team findings; gate calibration protocols.
- Dependencies/assumptions: Avoid false positives/negatives; measurable impact on user experience; robust governance.
- Education and tutoring at scale with long-context reasoning
- Sectors: education
- What: Tutors that handle textbooks and student histories over extended contexts, improving reasoning while maintaining compute budgets.
- Tools/workflows: Lesson-specific memory tables; alignment with curriculum standards; accessibility features.
- Dependencies/assumptions: Device and bandwidth constraints in schools; privacy; pedagogy-aware evaluation.
- Cross-lingual, cross-domain memory fusion
- Sectors: localization, global enterprises
- What: Build unified Engram memories across languages and domains using canonicalization to bridge orthographic variants and domain terms.
- Tools/workflows: Multilingual normalization; polysemy-aware hashing with multiple heads; branch-specific gating per language.
- Dependencies/assumptions: High-quality multilingual resources; evaluation across diverse scripts; collision and ambiguity management.
Notes on Feasibility
- Deterministic retrieval enables unique infrastructure optimizations (prefetch, overlap) but demands careful layer placement to hide latency.
- Gains depend on Zipfian access patterns; heavy-tailed distributions justify multi-level caches.
- Collision mitigation relies on multi-head hashing and context-aware gating; aggressive scaling requires calibration and monitoring for noise.
- The reported optimal allocation (ρ ≈ 75–80%) is stable across tested regimes, but may shift at larger scales or different tasks; AutoML-style tuning is recommended.
- Compliance, privacy, and auditability become central when memory tables store sensitive or policy-critical content.
Glossary
- Adam: A stochastic optimization algorithm that adapts learning rates using estimates of first and second moments of gradients. "the embedding parameters are updated using Adam~\citep{kingma2014adam} with a learning rate scaled by and no weight decay"
- Activated parameters per token: The subset of model parameters computed for each token; determines per-token training cost. "activated parameters per token. This quantity determines the training cost (FLOPs)."
- All-to-All communication: A distributed communication primitive where each device exchanges data with every other device. "An All-to-All communication primitive is employed to retrieve active embedding rows across devices."
- Allocation ratio: The fraction of the inactive parameter budget assigned to MoE expert capacity. "We define the allocation ratio as the fraction of the inactive-parameter budget assigned to MoE expert capacity:"
- Centered Kernel Alignment (CKA): A similarity metric for comparing representations across layers or models. "Mechanistic analysis via LogitLens~\citep{nostalgebraist2020logitlens} and CKA~\citep{hendrycks2020measuring} reveals the source of these gains"
- Conditional computation: Selectively activating parts of a model to process inputs efficiently. "Mixture-of-Experts (MoE) scales capacity via conditional computation"
- Conditional memory: Sparse lookup-based retrieval of static embeddings keyed by local context. "we introduce conditional memory as a complementary sparsity axis"
- Context-aware gating: A mechanism that modulates retrieved memory using current hidden states to align with context. "we employ a context-aware gating mechanism inspired by Attention"
- Depthwise causal convolution: A convolution that operates per channel with causal ordering to expand temporal receptive fields. "we introduce a short, depthwise causal convolution~\citep{gu2021efficiently,peng2023rwkv}"
- Deterministic addressing: Predictable indexing that enables prefetching of memory entries at runtime. "its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead."
- Deterministic function (hashing): A fixed mapping from N-gram context to memory indices without randomness. "via a deterministic function :"
- Dilation: Spacing in convolution kernels that increases receptive field without more parameters. "dilation (set to the max -gram order)"
- Embedding table: A parameter matrix storing vectors indexed by keys (e.g., hashed N-grams). "an embedding table (of prime size )"
- Engram: A conditional memory module for constant-time N-gram lookups integrated into Transformers. "we introduce conditional memory as a complementary sparsity axis, instantiated via Engram"
- Feed-forward networks (FFNs): Layer components that apply per-token nonlinear transformations after attention. "multiple early layers of attention and feed-forward networks"
- FP8: An 8-bit floating-point format used to accelerate dense matrix multiplications on modern GPUs. "fused into a single dense FP8 matrix multiplication"
- GPU high-bandwidth memory (HBM): On-GPU memory with high throughput used for model parameters and activations. "GPU high-bandwidth memory (HBM)"
- Host memory: CPU-attached system memory used to store offloaded parameter tables during inference. "offloading a 100B-parameter table to host memory incurs negligible overhead ()."
- Iso-FLOPs: Matching models by equal floating point operation budgets to compare fairly. "iso-parameter and iso-FLOPs MoE baseline"
- Iso-parameter: Matching models by equal total parameter counts for controlled comparisons. "iso-parameter and iso-FLOPs MoE baseline"
- Kullback–Leibler divergence: A measure of difference between probability distributions; used to assess convergence across layers. "KullbackâLeibler divergence~\citep{kullback1951information}"
- LM Head: The final linear layer projecting hidden states to token logits for next-token prediction. "with the final LM Head"
- LogitLens: A method that probes intermediate representations by passing them through the final LM head to analyze predictions. "Mechanistic analysis via LogitLens~\citep{nostalgebraist2020logitlens}"
- Manifold-Constrained Hyper-Connections (mHC): A multi-branch residual framework with learnable connection weights constrained by manifold structure. "Manifold-Constrained Hyper-Connections~()~\citep{xie2025mhcmanifoldconstrainedhyperconnections}"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of experts for scalable capacity with conditional computation. "Mixture-of-Experts (MoE) scales capacity via conditional computation"
- Multi-branch architecture: A backbone design that expands the residual stream into parallel branches with modulated information flow. "we adopt the advanced multi-branch architecture as our default backbone"
- Multi-head Latent Attention (MLA): An attention variant with multiple heads designed for efficient latent computations. "Each block integrates a Multi-head Latent Attention (MLA)~\citep{deepseekai2024deepseekv2strongeconomicalefficient}"
- Multi-Level Cache Hierarchy: A tiered caching design that places frequent embeddings in faster memory and rare ones in slower storage. "This statistical property motivates a Multi-Level Cache Hierarchy"
- Multi-Head Hashing: Using multiple distinct hash functions to reduce collisions when indexing N-gram memory. "Multi-Head Hashing."
- Multi-Query NIAH: A long-context retrieval task variant with multiple queries in Needle-in-a-Haystack evaluations. "Multi-Query NIAH: $97.0$ vs.\ $84.2$"
- Multiplicative-XOR hash: A simple hashing scheme combining multiplication and XOR for indexing embedding tables. "implemented as a lightweight multiplicative-XOR hash."
- Muon: An optimization algorithm used for large-scale pretraining of sparse models. "All models are optimized using Muon~\citep{jordan2024muon,team2025kimi}"
- NFKC: A Unicode normalization form that canonicalizes text for tokenizer compression. "using NFKC~\citep{UAX15-NFKC}"
- N-gram embeddings: Vectors keyed by token substrings of length N, enabling local pattern lookups. "we revisit -gram embeddings~\citep{bojanowski2017enriching}"
- Needle-in-a-Haystack (NIAH): Long-context benchmarks where specific items must be retrieved from large distractor sequences. "Needle-in-a-Haystack"
- NVMe SSD: High-speed solid-state storage used to hold large, infrequent embedding entries in the cache hierarchy. "NVMe SSD"
- O(1) lookup: Constant-time retrieval operation independent of table size. "for lookup."
- OverEncoding: A baseline integrating N-gram embeddings by averaging them with vocabulary embeddings. "we compare against OverEncoding~\citep{huang2025over}, which integrates -gram embeddings via averaging with the vocabulary embedding."
- PCIe: A high-speed interface for transferring data between host memory and GPUs. "the system can asynchronously retrieve embeddings from abundant host memory via PCIe."
- Positional encoding: Mechanisms that encode token positions to enable sequence order awareness in Transformers. "attention mechanisms and positional encoding provide the structural basis for context processing"
- Prefetch-and-overlap strategy: Fetching embeddings ahead of computation and overlapping data transfer with earlier blocks. "this deterministic nature enables a prefetch-and-overlap strategy."
- Residual connection: Adding module outputs to hidden states to stabilize training and preserve identity mapping. "The Engram module is integrated into the backbone via a residual connection"
- Residual stream: The pathway in residual architectures that carries transformed signals across layers or branches. "the expansion of the residual stream into parallel branches"
- RMSNorm: A normalization technique using root mean square, improving gradient stability. "we apply RMSNorm~\citep{zhang2019root} to the Query and Key"
- RULER: A long-context evaluation suite with tasks like NIAH and variable tracking. "substantially outperforming baselines on LongPPL~\citep{fangwrong} and RULER~\citep{hsiehruler}"
- SiLU: A smooth activation function (sigmoid-weighted linear unit) enhancing nonlinearity. "SiLU activation~\citep{elfwing2018sigmoid}"
- Sparsity Allocation: The problem of distributing capacity between computation (MoE) and memory (Engram) under fixed budgets. "we formulate the Sparsity Allocation problem"
- Surjective function: A mapping where every target has at least one source; used to canonicalize token IDs. "we pre-compute a surjective function "
- Tokenizer Compression: Reducing vocabulary by canonicalizing semantically equivalent tokens before N-gram construction. "Tokenizer Compression"
- Top-k (routed experts): Selecting the k highest-scoring experts per token in MoE. "activating the top- routed experts per token"
- U-shaped scaling law: Performance curve where optimal allocation lies between extremes of pure compute or pure memory. "we uncover a U-shaped scaling law"
- Variable Tracking (VT): A long-context task requiring multi-hop tracking of variable assignments. "Variable Tracking: $89.0$ vs.\ $77.0$"
- Vocabulary projection layer: A mapping that compresses raw token IDs into canonical forms to increase semantic density. "we implement a vocabulary projection layer"
- YaRN: A method for extending context windows in Transformers. "we apply YaRN~\citep{peng2023yarn} for context window extension"
- Zipfian distribution: A heavy-tailed frequency distribution where few items are very common and many are rare. "natural language -grams inherently follow a Zipfian distribution"
Collections
Sign up for free to add this paper to one or more collections.

