- The paper introduces targeted stepwise routing to dynamically allocate expensive LLM compute only on challenging steps, reducing error propagation.
- It employs policies like TRIM-Thr, TRIM-Agg, and TRIM-POMDP to optimize the trade-off between computation cost and reasoning accuracy.
- Empirical results demonstrate up to 6× token savings and robust generalization across datasets, highlighting TRIM's efficiency in scalable LLM deployment.
Targeted Stepwise Routing for Multi-Step LLM Reasoning: An Expert Analysis of TRIM
Motivation and Problem Statement
LLMs exhibit a steep performance–cost gradient by model scale. High-performing LLMs are computationally expensive, while smaller models, though economical, make critical errors, especially in compositional multi-step reasoning, where single-step errors cascade to solution failure. Standard routing paradigms assign the entire query to a single LLM, disregarding variable per-step difficulty. Consequently, expensive models are invoked globally, squandering compute on routine steps, or omitted, impairing accuracy on hard steps. This dichotomy is especially inefficient for mathematical and programmatic reasoning, where isolated critical steps disproportionately determine answer quality.
The TRIM framework introduces targeted stepwise routing, allocating calls to expensive LLMs on a per-step basis, conditional on model uncertainty and intermediate correctness estimates. Instead of model selection at the query level, TRIM leverages process reward models (PRMs) or self-verification signals to dynamically escalate only those intermediate steps that exhibit high likelihood of error, thereby preventing error propagation.
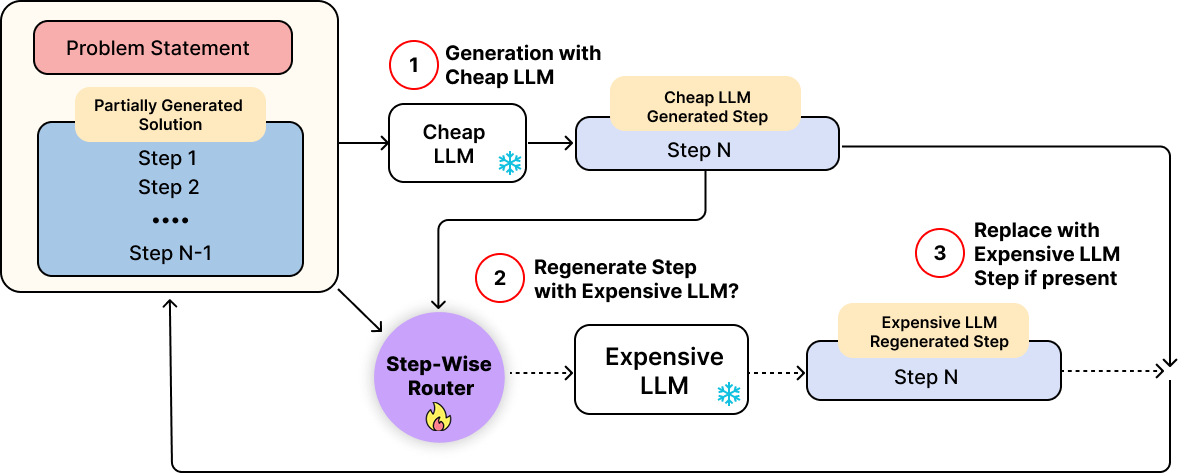
Figure 1: Schematic overview of TRIM’s two-model architecture, where reasoning is constructed incrementally with stepwise model selection conditioned on process rewards.
TRIM Routing Strategies
Several TRIM routing policies are defined, differing in the granularity of state used and in their handling of correctness estimate noise. All operate in a two-model setting: a compute-efficient weak model Mw proposes intermediate steps, which may be selectively re-generated by a strong, expensive model Ms.
TRIM-Thr: A myopic thresholding policy employs the current PRM-assigned score; steps with scores below a threshold are escalated to Ms, else the Mw output is accepted. The threshold controls the trade-off between accuracy and compute, driving a Pareto frontier between cost and final solution correctness.
TRIM-Agg: This method implements policy learning using RL with a small MLP using features aggregated from the partial trace: last PRM score, minimum prior PRM, current step's token count, and its position. This induces a non-myopic policy sensitive to both the trajectory’s weakest link and cumulative cost.
TRIM-Seq: A policy is learned using the full sequence of step features, capturing richer dependencies but at greater training cost.
TRIM-POMDP: Unlike the RL variants, TRIM-POMDP explicitly models error in PRM estimates by treating correctness states as latent and step-level scores as noisy observations, mapping inference to a POMDP. Router policies are computed with SARSOP, yielding robust policies in the low-token regime and under high PRM noise.
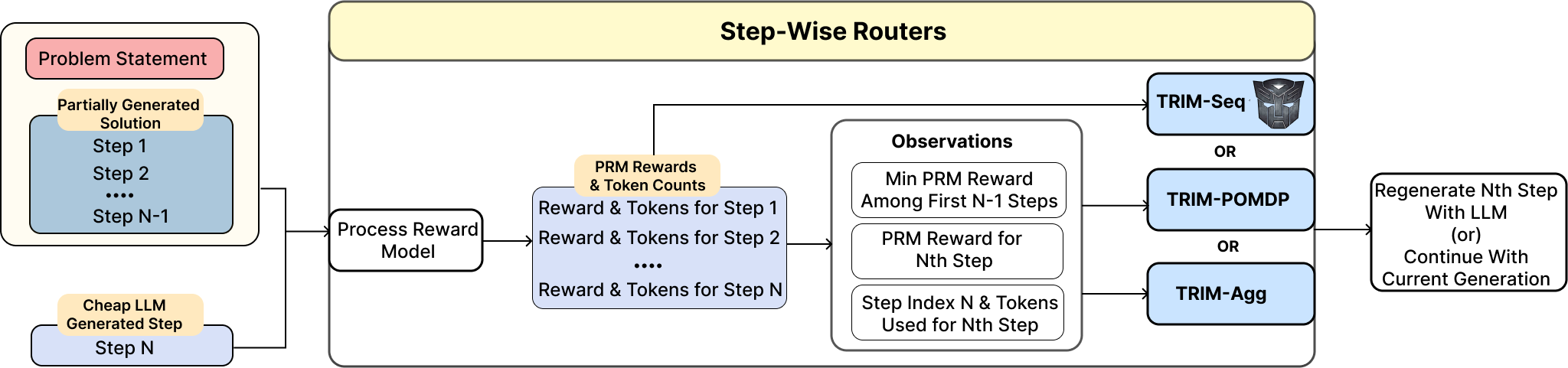
Figure 3: Step-wise routing in TRIM: per-step decisions to escalate or continue are made using PRM-based uncertainty and trajectory context.
The underlying latent state distinguishes between still-correct prefixes, irrecoverable errors, and single localized errors—that is, S0 (all steps correct), S1 (irrecoverably incorrect), and S2 (potential recovery via single-step correction).
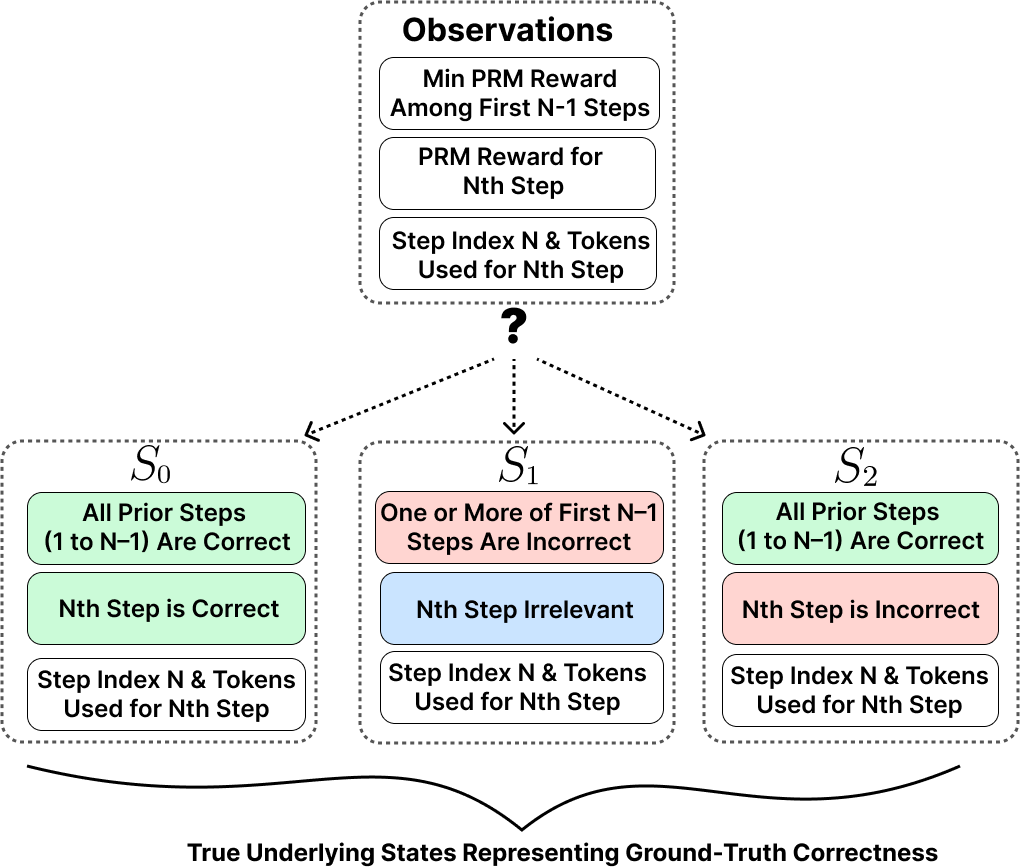
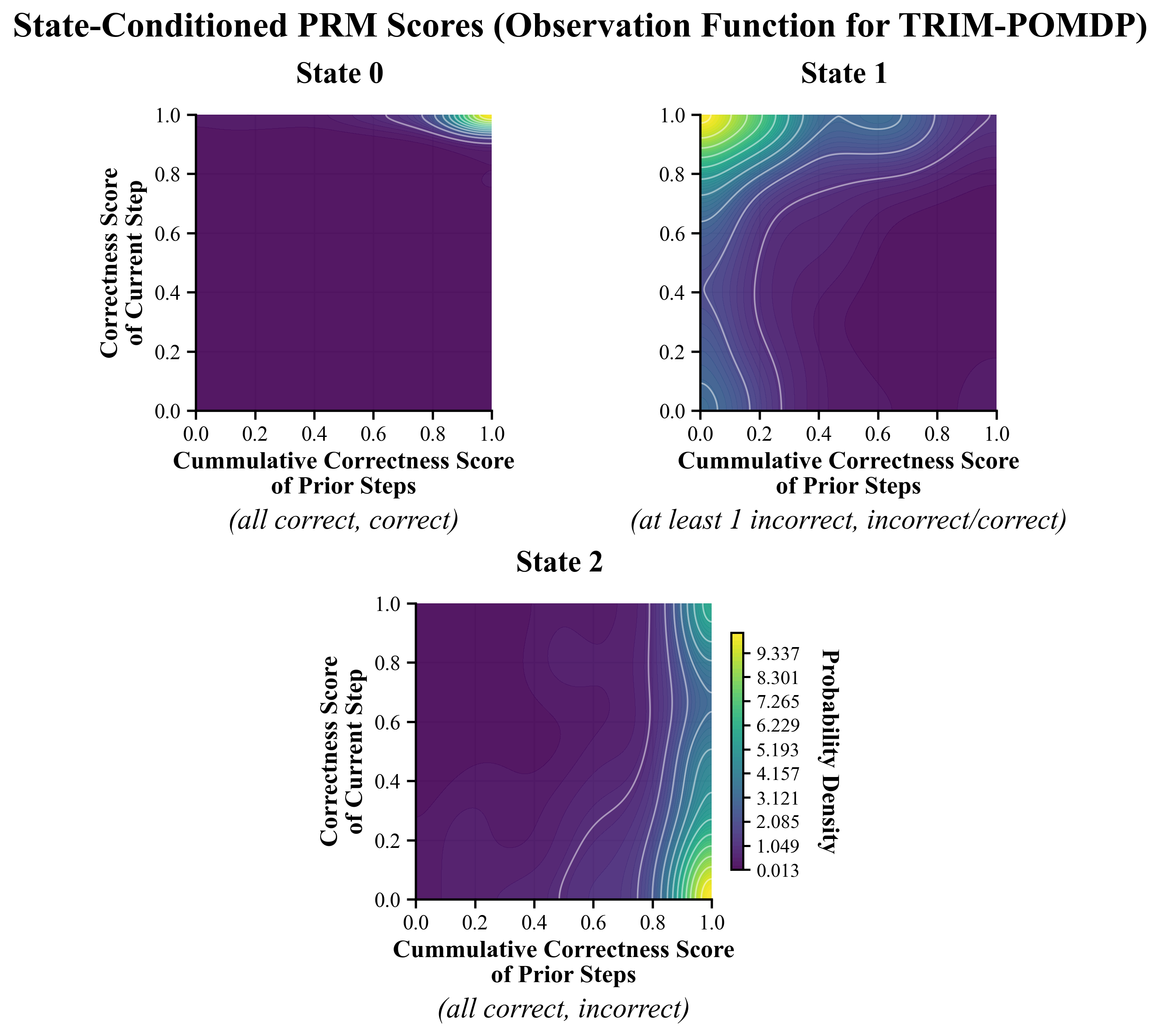
Figure 2: POMDP state and observation structure: latent correctness class is inferred from noisy PRM features.
Empirical Results
Evaluations on MATH-500, AIME, OlympiadBench, and Minerva demonstrate several key findings:
- Cost Efficiency: Basic TRIM-Thr delivers at least 5× higher efficiency over leading query-level routing baselines, achieving near–strong model accuracy with a fraction of Ms tokens. TRIM-Agg and TRIM-POMDP match or beat strong model performance using 80% fewer Ms tokens on MATH-500 and up to 6× savings on AIME.
- Low-Budget Regime: TRIM-POMDP strictly dominates in regimes with tight compute budgets, where its explicit modeling of uncertainty and long-horizon dependencies enables high-utility token targeting under sparse reward signals.
- High-Budget Regime: In scenarios where more expensive tokens can be used, TRIM-Agg is more effective due to easier RL convergence.
- Generalization: Policies trained on AIME generalize without adaptation to OlympiadBench and Minerva, outperforming query-level routers that overfit to dataset idiosyncrasies. This implies that step-level hardness is intrinsic and transferable across problem distributions.
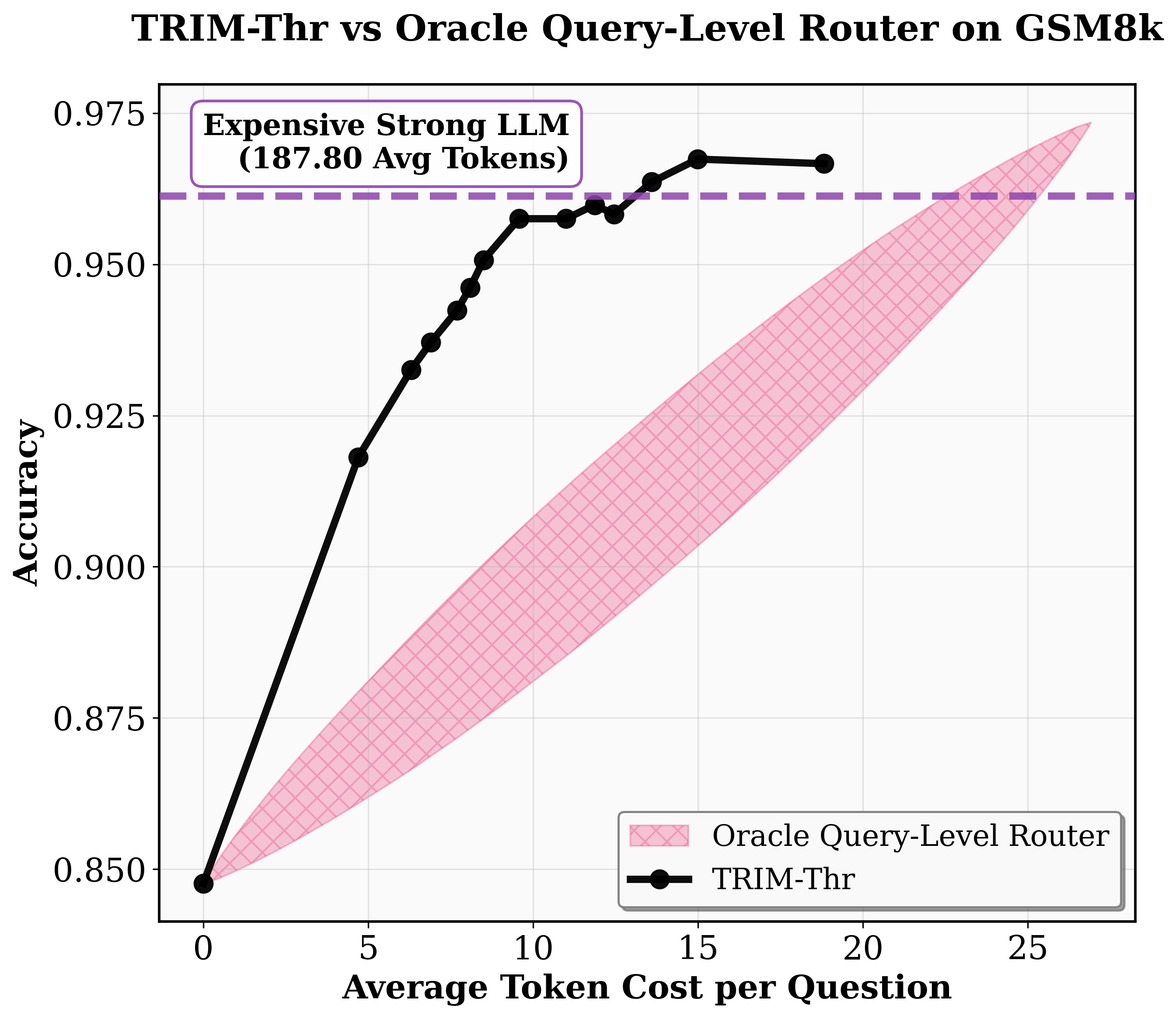
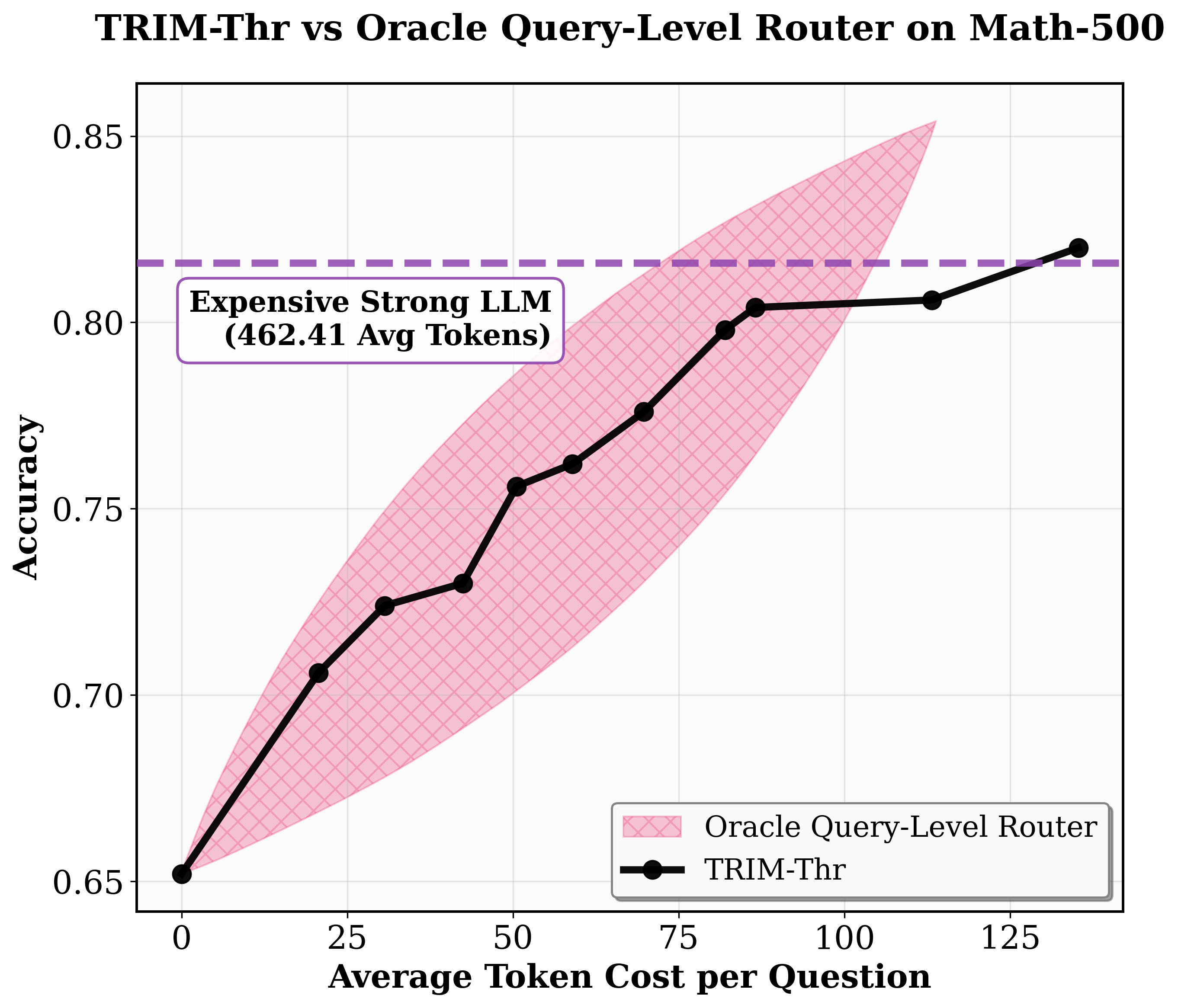
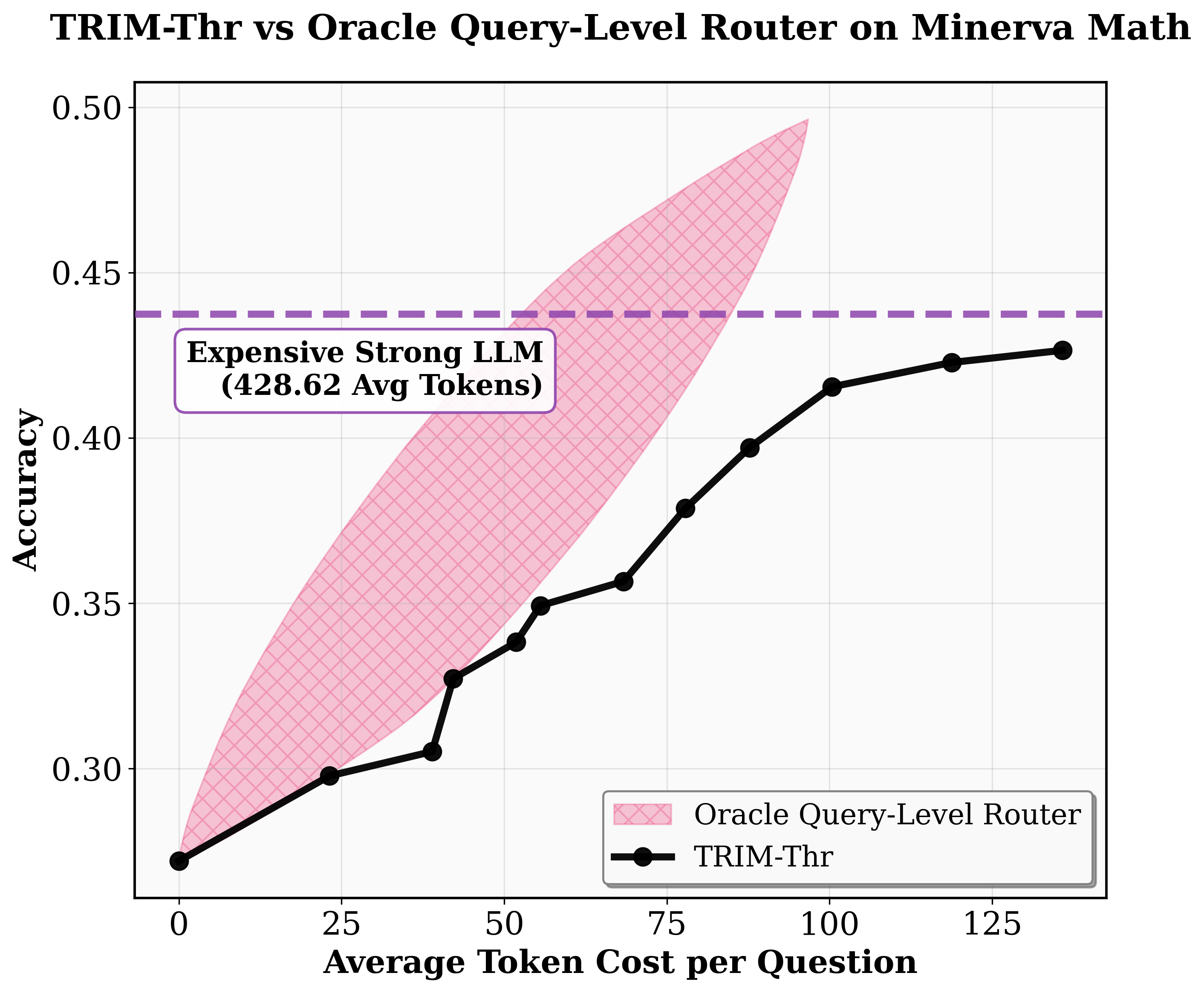
Figure 4: TRIM’s cost–performance tradeoff compared to query-level and oracle policies across mathematical benchmarks, highlighting substantial token savings.
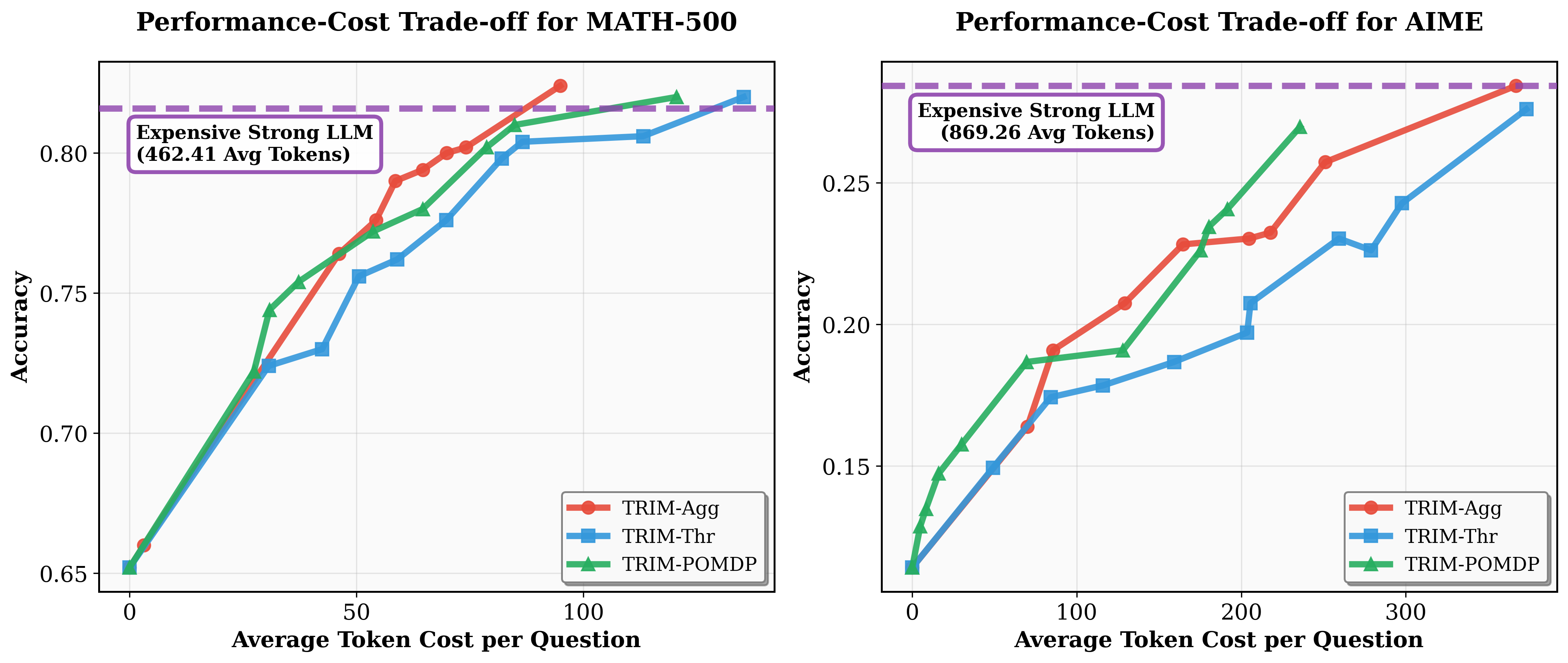
Figure 5: Comparative performance–cost curves on MATH-500 and AIME: POMDP-based TRIM dominates at low budgets; TRIM-Agg leads at higher budgets.
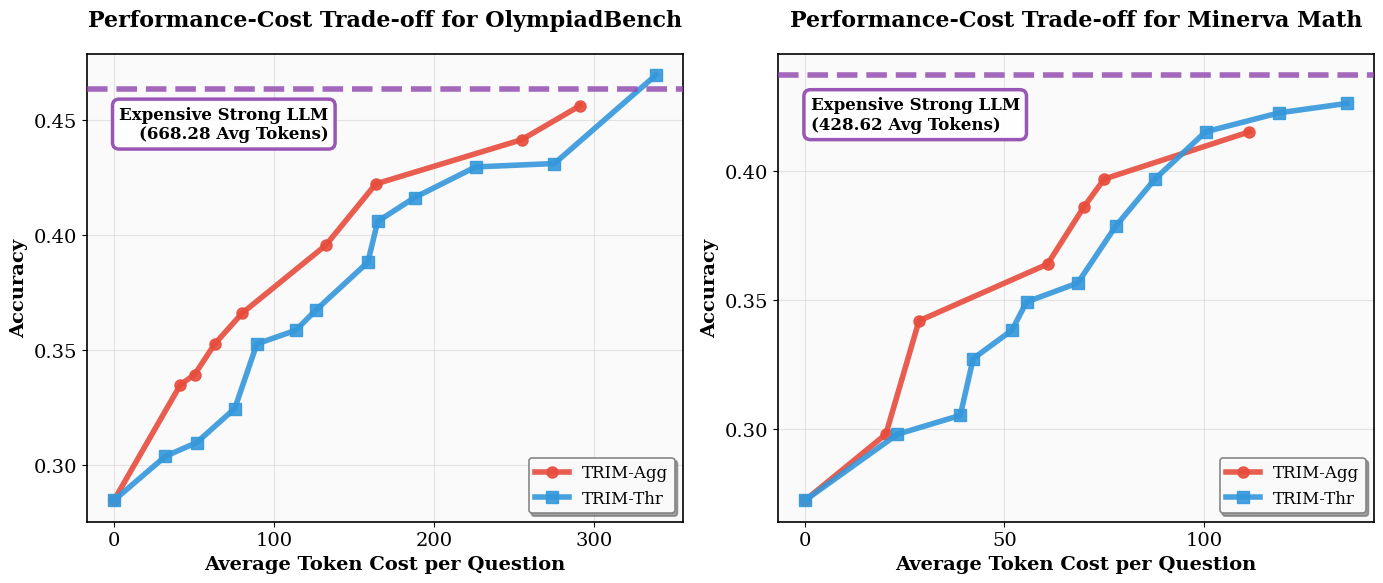
Figure 6: Cross-dataset cost–performance tradeoffs show that TRIM-Agg, trained on AIME, generalizes robustly to OlympiadBench and Minerva.
Ablations and Robustness
- Single-Step Intervention: Empirical ablations confirm that intervening only on individual steps (rather than taking over remaining steps with Ms) is optimal, as error localization commonly suffices to realign the trajectory.
- Noise Robustness: While threshold-based policies degrade under high PRM noise, RL and POMDP-based policies learn robustness, maintaining superior cost efficiency.
Implementation and Latency
Leveraging modern LLM serving stacks (e.g., vLLM, SGLang), TRIM exploits parallel chunked prefilling, such that wall-clock overhead remains negligible, often yielding absolute latency improvements due to reduced Ms tokens generated.
Practical and Theoretical Implications
TRIM provides a formal framework for hybrid LLM serving in multi-step tasks, clarifying that the marginal utility of expensive LLM compute is heavily concentrated on a small subset of steps. Theoretical insight is provided by the POMDP formulation, which distinguishes policies for early (recoverable) versus late-stage errors and quantifies trade-offs under observation noise.
- Deployment: TRIM policies are lightweight, requiring either a small MLP or an efficient POMDP solver with a low-dimensional state. Their domain-agnosticism (subject to PRM or self-verification availability) and generalizability across model pairs and benchmarks make them suitable for scalable, production-grade, cost-sensitive LLM deployment.
- Future Directions: Extending routing granularity from steps to tokens may further increase efficiency, motivated by recent work on token-level intervention and the finding that “critical tokens” drive solution correctness. Additionally, integrating richer verification signals and model ensembles could further enhance reliability under adversarial or distributionally shifted inputs.
Conclusion
TRIM establishes that targeted, stepwise routing using PRM-informed escalation decisions yields substantial cost–performance gains in multi-step LLM reasoning. The framework’s modularity supports diverse policy optimization approaches—threshold, RL, or POMDP—each tuned to different compute regimes and noise conditions. Empirical and theoretical analysis confirms that reliable, scalable reasoning with LLMs can be achieved through fine-grained, context-aware token allocation, and that fundamental step-level hardness patterns drive transfer and efficiency in complex sequence tasks.