- The paper introduces a TRIM framework that applies temporal trajectory reduction and spatial instance masking to prune unproductive denoising paths efficiently.
- It employs a lightweight CNN-MLP latent selector for early trajectory evaluation, achieving over 35% reduction in inference time and improved image fidelity.
- Empirical results demonstrate enhanced performance on text-to-3D and image-to-3D benchmarks with over 45% FLOPs reduction and up to 2× throughput increase.
TRIM: Scalable 3D Gaussian Diffusion Inference with Temporal and Spatial Trimming
Introduction and Motivation
3D Gaussian diffusion models have recently gained prominence for high-fidelity 3D object synthesis from textual or visual prompts, driven in part by advances in 2D diffusion techniques. However, the inherent inefficiency in inference—specifically, the computationally intensive denoising of large numbers of Gaussian primitives and the need for complex Recon-Gen-Render pipelines—limits scalability and hampers inference-time strategies such as trajectory scaling. The paper "TRIM: Scalable 3D Gaussian Diffusion Inference with Temporal and Spatial Trimming" (2511.16642) addresses these bottlenecks by introducing a post-training framework that leverages both temporal (trajectory) and spatial (instance-mask) trimming, improving efficiency and output quality in 3D Gaussian diffusion inference.
Methodology
The TRIM framework accelerates 3D generation by introducing two principal innovations: trajectory reduction and instance mask denoising, as summarized in the pipeline overview.
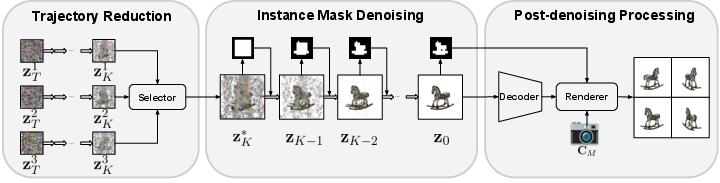
Figure 1: TRIM consists of trajectory reduction via a latent selector, instance mask denoising to filter backgrounds, and post-denoising Gaussian correction.
Trajectory Reduction
The trajectory reduction component tackles the inefficiency of naively evaluating multiple denoising trajectories end-to-end. Instead, TRIM trains a lightweight latent selector, an offline-distilled CNN-MLP model fused with prompt embeddings, to identify promising latent trajectories at an intermediate denoising timestep. This selector is supervised via a pairwise distillation objective using triplets of trajectory, rendered images, and evaluator scores. By terminating low-potential candidates early, the system drastically reduces the number of denoising and rendering operations required.
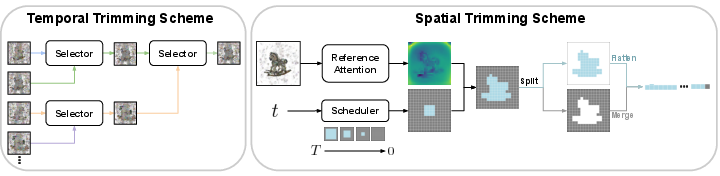
Figure 2: Left: Temporal trimming with a selector-based early trajectory pruning. Right: Spatial trimming using reference-attention mask and token merging for background elimination.
Experimental ablation confirms optimal efficacy when trajectory selection is performed at the denoising midpoint, balancing noise robustness and early pruning efficiency.
Instance Mask Denoising
To address token-level waste—specifically, excessive computation on transparent backgrounds—the method introduces a model-free mask detection mechanism. Inspired by attention-based saliency (e.g., DINO), the approach computes reference-attention from grid corners to identify background. Via progressive mask expansion, it applies the mask from the boundary inward as denoising progresses, reducing the transformer token count while minimizing artifact risk.
Background tokens are merged and reconstituted post-denoising for rendering compatibility. Recognizing that the pre-trained model lacks awareness of masked/merged tokens, a post-denoising correction explicitly zeroes opacity on background Gaussians to suppress resulting artifacts.
Empirical Results
3D Generation Benchmarks
On T3Bench for text-to-3D, TRIM outperforms all baselines on CLIP similarity, R-Precision, and ImageReward, showing consistent improvements, particularly for single object and multi-object scenarios. Average inference time is reduced by over 35% compared to strong baselines (e.g., DiffSplat).

Figure 3: Qualitative comparison: TRIM generates results with higher prompt fidelity and detail resolution, while reducing inference time.
For image-to-3D on the GSO dataset, TRIM achieves superior PSNR, SSIM, and LPIPS against all prior methods, although the incremental gains are more modest due to strong image-conditioning reducing trajectory variance.
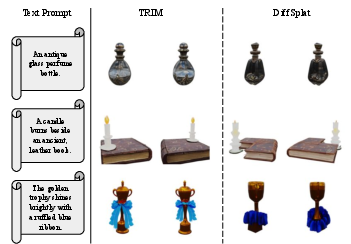

Figure 4: Left: Text-to-3D comparison; Right: Image-to-3D reconstruction—TRIM yields superior semantic alignment and geometric fidelity.
Analysis of Scaling and Efficiency
A key contribution is the demonstration that inference-time trajectory scaling (sampling multiple trajectories and selecting the best) brings more robust gains in 3D generation than simply increasing diffusion steps—unlike baseline approaches prone to semantic drift and diminishing returns at high step counts.
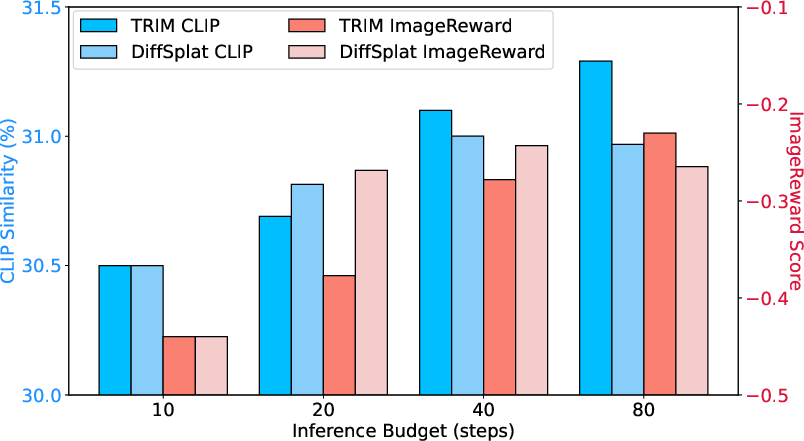
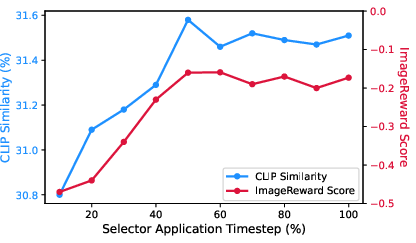
Figure 5: Trajectory scaling (TRIM) outperforms inference step scaling (DiffSplat), which plateaus or declines with excessive steps.
Further, ablations show that the convolutional selector is the major contributor to selection accuracy and generation gains, but that more complex architectures provide no additional benefits for trajectory selection.
Runtime and Computational Savings
TRIM achieves both spatial and temporal reductions in computation:
- Temporal trimming: By pruning non-optimal trajectories at mid-denoising, denoising step requirements scale sub-linearly with the number of initial samples.
- Spatial trimming: Instance masking reduces FLOPs and increases throughput by eliminating background token computation.
The combined effect is >45% reduction in FLOPs and up to 2× throughput improvement for transformer-based 3D diffusion backbones, without retraining or modification to the base model architecture.
Diversity and Theoretical Implications
The selector-based pruning strategy modestly narrows the geometric and semantic diversity of outputs (as measured by Chamfer Distance and CLIP score variance), but consistently shifts distributions toward higher quality by filtering out low-potential candidates. This effect is well-justified for settings prioritizing sample quality over diversity. Theoretical implications suggest that post-training inference pruning and quality filtering can reliably leverage stochastic diffusion sampling while minimizing wasteful computation.
Limitations and Future Work
A structural limitation remains in transposing these trimming techniques to the entirety of the generative pipeline, due to heavy reliance on 2D backbone architectures and late-stage 3D conversions. The paper suggests exploring 3D-structure-aware diffusion transformers, which may natively support end-to-end spatial pruning and more efficient representational hierarchies.
Conclusion
TRIM establishes a new paradigm for practical, scalable 3D diffusion inference by integrating temporal and spatial trimming strategies post-training. It achieves significant computational savings and measurable quality improvements over state-of-the-art baselines in both text-to-3D and image-to-3D tasks, all without retraining. While the framework slightly reduces unconditional output diversity, it robustly raises minimum sample quality—a tradeoff well-aligned with production deployment needs. Future directions include end-to-end 3D-aware architectures and further integration with more advanced trajectory scoring, RL-based preference tuning, and scene-level conditional constraints.