Adaptive LLM Routing under Budget Constraints
Abstract: LLMs have revolutionized natural language processing, but their varying capabilities and costs pose challenges in practical applications. LLM routing addresses this by dynamically selecting the most suitable LLM for each query/task. Previous approaches treat this as a supervised learning problem, assuming complete knowledge of optimal query-LLM pairings. However, real-world scenarios lack such comprehensive mappings and face evolving user queries. We thus propose to study LLM routing as a contextual bandit problem, enabling adaptive decision-making using bandit feedback without requiring exhaustive inference across all LLMs for all queries (in contrast to supervised routing). To address this problem, we develop a shared embedding space for queries and LLMs, where query and LLM embeddings are aligned to reflect their affinity. This space is initially learned from offline human preference data and refined through online bandit feedback. We instantiate this idea through Preference-prior Informed Linucb fOr adaptive rouTing (PILOT), a novel extension of LinUCB. To handle diverse user budgets for model routing, we introduce an online cost policy modeled as a multi-choice knapsack problem, ensuring resource-efficient routing.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about choosing the best AI model to answer each question while keeping costs under control. Different LLMs have different strengths and prices. The authors build a smart “router” that looks at a user’s question, decides which model is the best fit, learns from simple thumbs up/down feedback, and makes sure the total cost stays within a budget.
What questions did the researchers ask?
- How can we automatically pick the right LLM for each query without testing every model each time (which is too expensive)?
- How can the system learn and improve over time from simple feedback like “good answer” or “bad answer”?
- How can we keep performance high while staying under a money or token budget?
How did they study it?
The authors treat model routing like three everyday ideas: matching, learning from feedback, and budgeting.
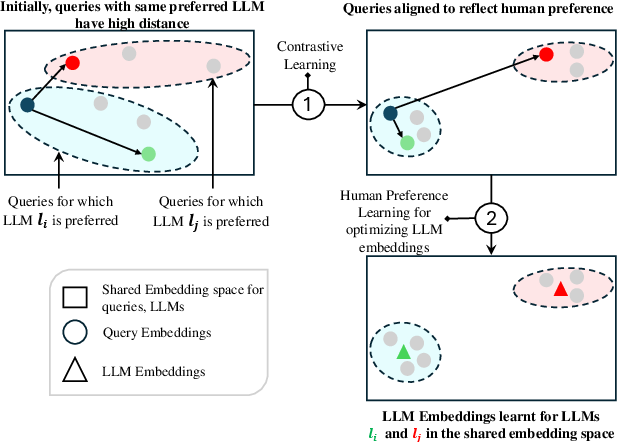
1) Matching questions to models (shared space)
Imagine each question and each model has a “fingerprint” (called an embedding) in the same map. If a question’s point is close to a model’s point, that model is likely a good match. To build this map:
- Pretraining with human preferences: They used public data where people chose which model gave the better answer for the same question (like head-to-head matchups). This helps the router learn which kinds of questions go well with which models before going live.
In simple terms: they first learn a “sense of taste” from people’s past choices.
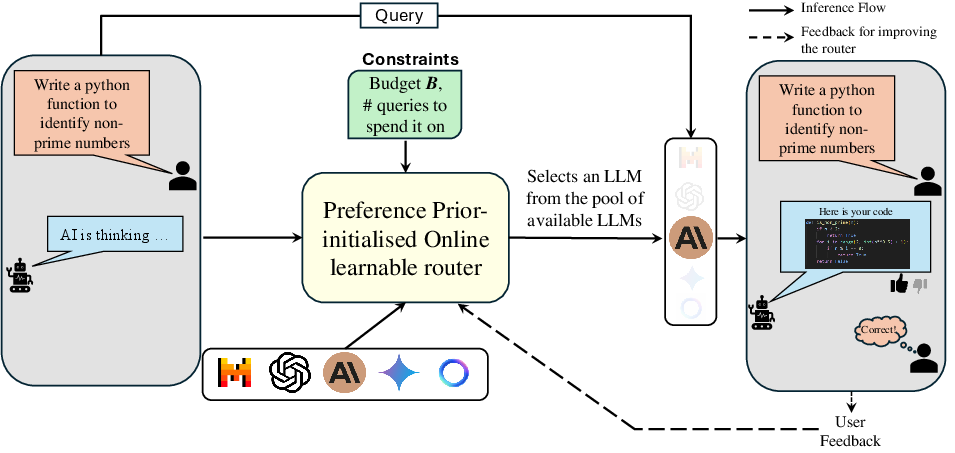
2) Learning from feedback as it goes (contextual bandit)
When the router is live, it only sees how the chosen model did (thumbs up or down), not how all models would have done. This setup is called a “contextual bandit” problem:
- Context = the question’s embedding (the question’s fingerprint).
- Arms = the different LLMs to choose from.
- Reward = did the chosen model do well (a score between 0 and 1)?
The router uses a strategy similar to “try your best guess, but sometimes explore new options.” Their version is called PILOT (Preference-prior Informed LinUCB). “LinUCB” is a method that picks the model with the best mix of:
- Expected quality (“exploitation”—choose what looks best),
- And uncertainty (“exploration”—occasionally try something else in case it’s even better).
Because the router already learned from human preferences, it starts with a good “prior,” so it improves faster.
In simple terms: it’s like picking the player most likely to score, but still giving other players a few chances, especially when you’re not sure yet.
3) Sticking to a budget (online knapsack)
They also add a budget manager. Think of your total budget like a backpack with limited space. Each model’s answer “weighs” a certain amount (cost). You want to pack as much value (good answers) as possible without overfilling the backpack. The system:
- Estimates the cost for each model per query,
- Picks a model that both looks promising and fits the remaining budget,
- Spreads spending wisely across many queries (so you don’t spend too much too early).
They use a known approach for this kind of problem (an “online knapsack” policy) and apply it in small chunks (“bins”) to make sure the budget is used well over time.
What did they find?
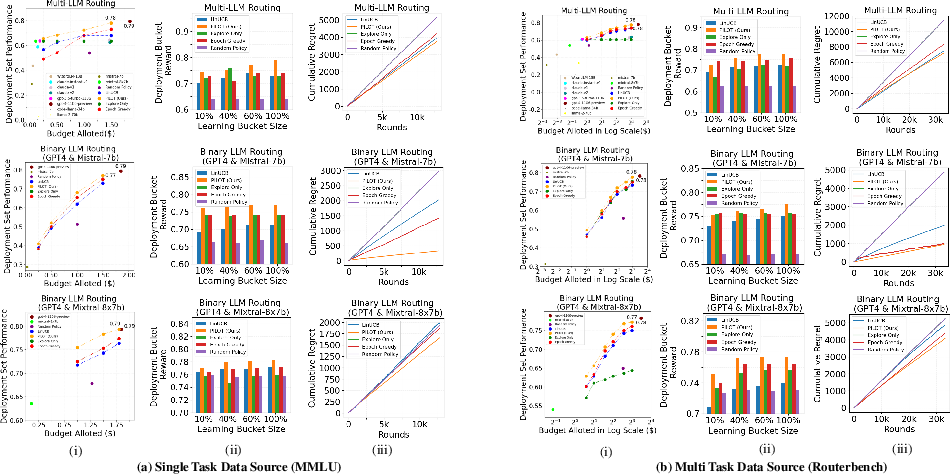
- Strong performance for less money:
- On a large, mixed set of tasks (RouterBench), their router reached about 93% of GPT-4’s performance at only 25% of GPT-4’s cost.
- On a single-task set (MMLU), it reached about 86% of GPT-4’s performance at 27% of the cost.
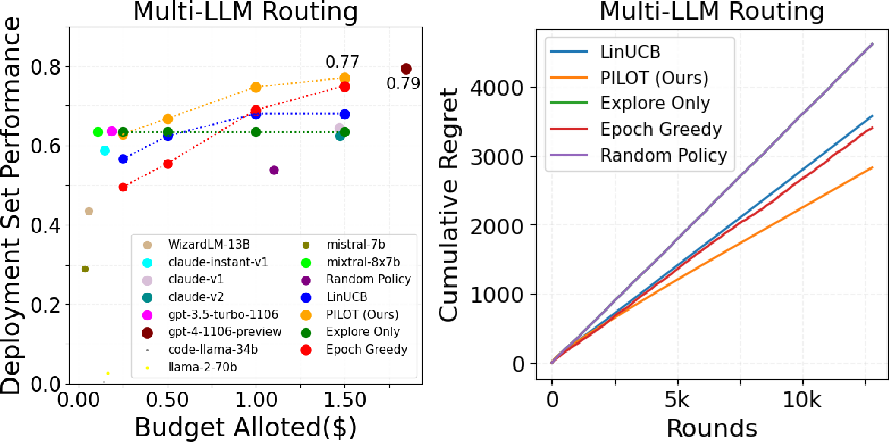
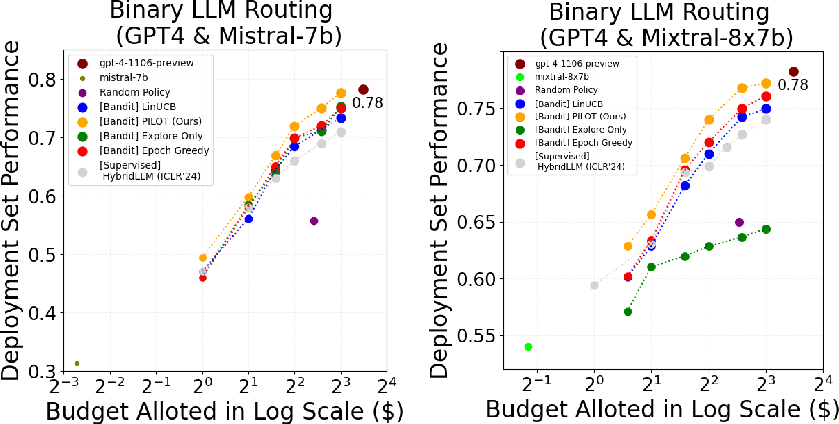
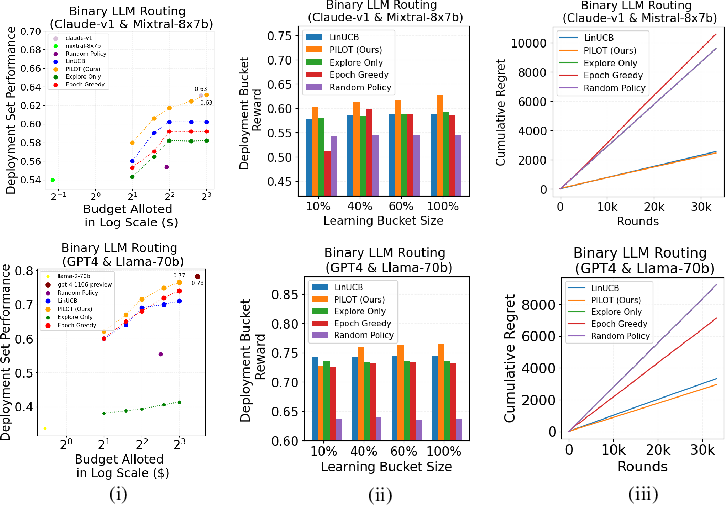
- Learns efficiently: Compared to other learning methods (like standard LinUCB, Epoch-Greedy, random choices), PILOT learned faster and made better routing decisions over time (lower “regret,” which means fewer missed opportunities).
- Smart choices by task:
- It sent tough reasoning questions to stronger (but pricier) models like GPT-4.
- For coding or math where cheaper models did well, it used those to save money.
- Low overhead: Deciding which model to pick is quick—dozens of times faster than the time it usually takes a big model like GPT-4 to produce an answer.
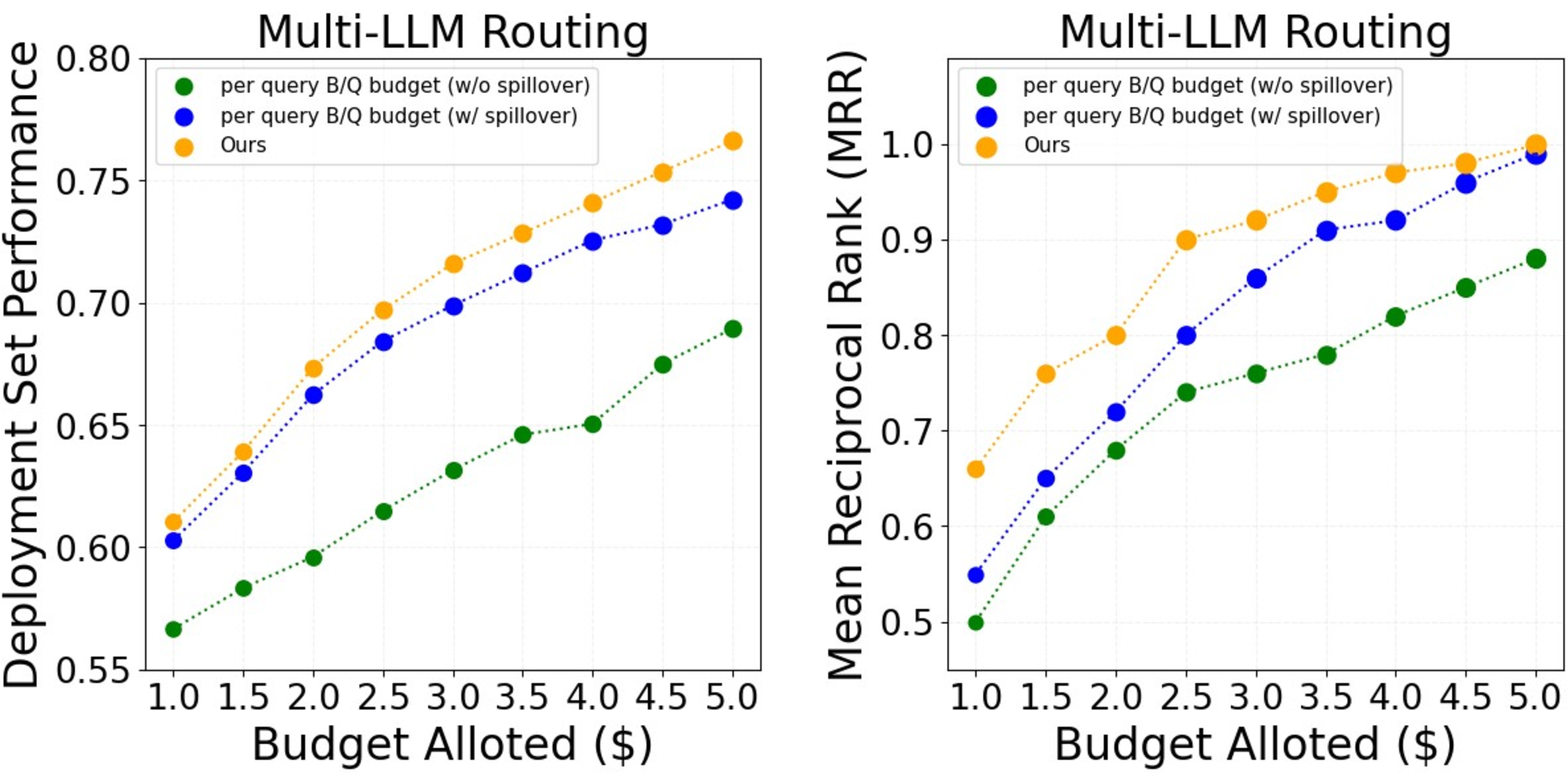
- Budget policy works: Their budgeting method beat simple baselines (like splitting the same budget per question) and performed similarly to or better than an “offline” method that gets to tune itself with hindsight.
Why does this matter?
This work shows a practical way to run AI systems that are:
- Adaptive: They improve from simple thumbs up/down feedback without needing expensive labels for every model.
- Cost-aware: They deliver high-quality answers while using money wisely.
- Ready for the real world: They can handle changing questions over time and different user budgets.
A note on limitations and future ideas
- During learning, the main router doesn’t directly optimize under the budget; budgeting is applied during deployment. A future step is to learn and budget at the same time.
- The study focuses on single-turn questions. Extending this to multi-turn conversations would make it even more practical for chatbots and assistants.
Knowledge Gaps
Below is a concise, actionable list of the knowledge gaps, limitations, and open questions the paper leaves unresolved.
- Learning without budget constraints: the bandit is trained ignoring budget and only constrained at deployment; develop budget-aware learning (e.g., bandits with knapsacks, constrained LinUCB/Thompson) and quantify end-to-end regret under budget.
- Reward signal realism: the method assumes immediate, binary, and unbiased feedback; study robustness to sparse, delayed, noisy, and biased user ratings and design debiasing or off-policy correction.
- Reward model misspecification: expected reward is modeled as a linear cosine similarity; benchmark against generalized linear, neural, or bilinear bandits and test calibration between predicted cosine and true success probability.
- Frozen query projection: only arm embeddings are updated online; evaluate joint online adaptation of both query projection and arm embeddings with stability controls (e.g., trust-region, elastic weight consolidation).
- Preference pretraining transferability: quantify domain shift between Chatbot Arena preferences and RouterBench tasks; test cross-domain pretraining, task-balanced pretraining, and ablations on negative sampling strategies.
- Cold-start for new LLMs: provide a principled way to initialize embeddings for unseen or updated models (meta-learning, side-information features, prompt probes) and measure cold-start regret.
- Assumptions in cost policy (UB/LB): specify how upper/lower bounds on reward-to-cost ratios are estimated; analyze sensitivity and provide guarantees under mis-specification.
- Output token cost prediction: current approach uses per-LLM mean output length; build per-query output-length predictors with uncertainty and assess downstream impact on budget adherence and performance.
- Uncertainty-aware cost policy: the budget allocator uses point reward estimates; integrate UCB/Thompson confidence into value-to-cost decisions to mitigate overconfident misallocations.
- Missing theory for PILOT: provide formal regret bounds for the preference-prior LinUCB variant under cosine reward, and extend theory to the budgeted setting and to the binning heuristic.
- Decoupled routing and budgeting: study joint optimization (e.g., Bandits with Knapsacks) and compare to the proposed decoupled policy in terms of regret, budget utilization, and stability.
- Single-objective constraint: only token cost is considered; extend to multi-objective or constrained routing (latency/SLA, energy, carbon, privacy), and evaluate trade-offs.
- Personalization gap: the method mentions personalization but uses only query embeddings; incorporate user/context features and evaluate per-user improvements and privacy implications.
- Safe exploration: exploration may degrade user experience; design safe or conservatively constrained exploration and quantify cost-quality trade-offs.
- Multi-turn routing: only single-turn inputs are handled; develop stateful/contextual routing that incorporates conversation history and measures cumulative conversation quality.
- Delayed/missing feedback: account for asynchronous feedback and partial observability; evaluate bandit updates under delays and propose correction mechanisms.
- Evaluation bias: RouterBench relies on GPT-4 judging and task-specific metrics; validate with human raters, alternative judges, and scorer-agnostic metrics to test robustness to evaluation bias.
- Embedder dependence and budget: only two embedders are tested and embedder API costs are excluded from budgets; evaluate more embedders (including on-prem) and include embedding latency and cost in the budget accounting.
- Scalability to large model pools: per-arm independent regressions may be sample-inefficient; explore shared-parameter or factorized models across arms and benchmark runtime/memory scaling.
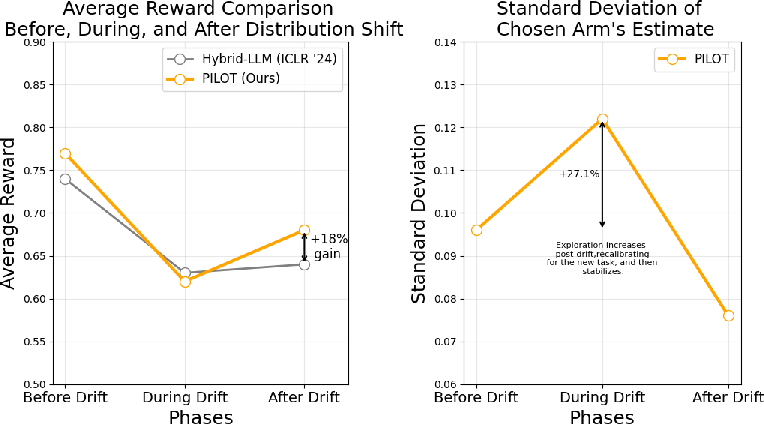
- Non-stationarity handling: model capabilities and query distributions evolve; add forgetting/sliding windows, change-point detection, and analyze performance under distribution drift.
- OOD and adversarial queries: detect and handle out-of-distribution or adversarial prompts; integrate abstention/escalation and measure robustness.
- Single-call routing vs cascades: compare to cascaded strategies (e.g., FrugalGPT escalation) learned via bandits; design hybrid policies that combine routing and escalation.
- Fairness and service guarantees: the binning/spillover policy may starve later queries; add fairness constraints or service-level guarantees and evaluate worst-case per-query outcomes.
- Privacy/security: online learning stores user-derived embeddings and may rely on external APIs; analyze privacy risks and test on-device embeddings and differential privacy methods.
- Hyperparameter auto-tuning: exploration parameter α and prior strength λa are tuned offline; design online tuning/adaptation strategies and test sensitivity in non-stationary settings.
- Negative sampling bias: hard negatives depend on model size, potentially biasing against larger models; evaluate alternative negative mining strategies and their effect on routing.
- Task/tool generality: the approach is text-only; extend to tool-use, function-calling, or multimodal tasks, and measure generalization.
- Reward normalization across tasks: unify and calibrate task-specific scores into [0,1] to avoid skew; study multi-task reward calibration impacts on routing.
- Baseline coverage: add strong bandit baselines (e.g., Thompson Sampling, GLM/Neural Linear bandits, BwK algorithms) under the same cost policy for a more comprehensive comparison.
- Real-world budget dynamics: handle indefinite horizons, time-varying or per-user budgets, and multi-tenant settings; analyze stability and fairness in shared-resource deployments.
Collections
Sign up for free to add this paper to one or more collections.