- The paper presents a cyclic evaluation protocol (UCF-UM) that reveals and quantifies semantic drift in unified multimodal models through repeated T2I and I2T conversions.
- It employs embedding-based metrics, including Mean Cumulative Drift, Semantic Drift Rate, and Multi-Generation GenEval, to measure semantic consistency across cycles.
- Empirical results show that models like BAGEL maintain superior semantic stability, while others exhibit rapid degradation in cross-modal fidelity.
Evaluating Semantic Drift in Unified Multimodal Models: The Telephone Game Protocol
Introduction and Motivation
Unified multimodal models (UMs) integrate both visual understanding (image-to-text, I2T) and visual generation (text-to-image, T2I) within a single architecture, enabling seamless cross-modal reasoning and synthesis. While recent advances have produced models with strong single-pass performance on isolated tasks, existing evaluation protocols fail to capture the semantic consistency of these models when alternating between modalities over multiple generations. The paper introduces the Unified Consistency Framework for Unified Models (UCF-UM), a cyclic evaluation protocol that quantifies semantic drift by repeatedly alternating I2T and T2I, analogous to the "Telephone Game" where information degrades as it is passed along.
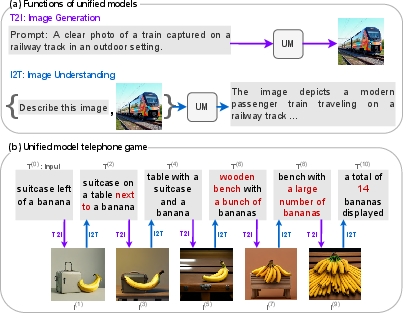
Figure 1: (a) Unified models support both image generation and understanding. (b) UCF-UM cyclic evaluation reveals semantic drift: a suitcase disappears and banana count inflates over generations.
Limitations of Existing Evaluation Metrics
Traditional metrics such as FID, CLIPScore, and GenEval for T2I, and MME/MMBench for I2T, assess model performance in isolation. These single-pass metrics do not reveal whether a model that "understands" a concept can also "render" it, nor do they measure the preservation of entities, attributes, relations, and counts under repeated cross-modal conversions. The paper demonstrates that even state-of-the-art models like BAGEL can answer visual reasoning questions correctly (I2T) but fail to generate semantically consistent images (T2I) for the same concept.
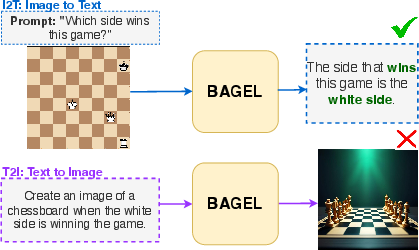
Figure 2: BAGEL correctly answers "white side wins" in I2T, but fails to generate a matching chessboard in T2I, exposing unified inconsistency.
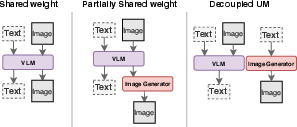
Unified Model Architectures
The paper categorizes unified models into three architectural paradigms:
The Unified Consistency Framework (UCF-UM)
UCF-UM alternates between T2I and I2T over multiple generations, starting from either text or image, and measures semantic similarity back to the initial input using embedding-based metrics (CLIP, DINO, MPNet). The framework defines two cyclic chains:
- Text-First-Chain: T(0)→I(1)→T(2)→I(3)⋯
- Image-First-Chain: I(0)→T(1)→I(2)→T(3)⋯
Semantic similarity is measured across all generations and modalities, exposing concept drift that single-pass metrics overlook.
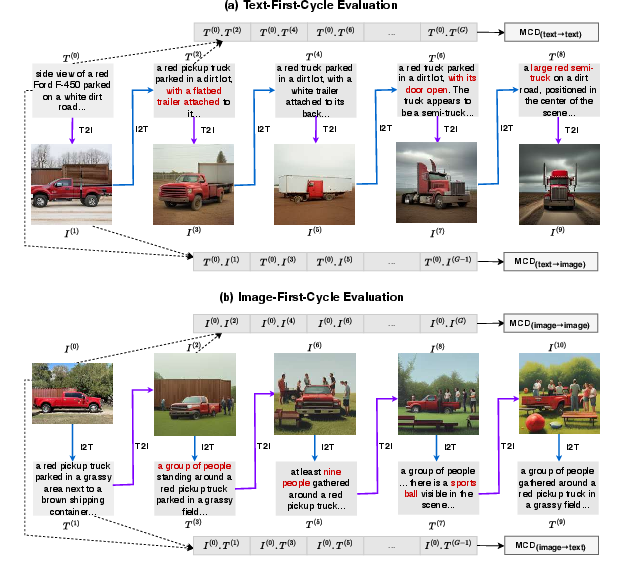
Figure 4: UCF-UM cyclic evaluation alternates T2I and I2T, revealing cross-modal concept drift and semantic instability.
Quantifying Semantic Drift: Metrics
UCF-UM introduces three complementary metrics:
- Mean Cumulative Drift (MCD): Embedding-based measure of overall semantic loss across generations.
- Semantic Drift Rate (SDR): Power-law decay rate of semantic similarity, parameterized by α (initial similarity), β (decay rate), and γ (asymptotic baseline).
- Multi-Generation GenEval (MGG): Object-level compliance score extending GenEval to multiple generations, using object detection to assess fidelity in attributes, counts, positions, and compositionality.

Figure 5: Qualitative examples of semantic drift: loss of position, object misidentification, style change, count inflation, hallucination, and color inconsistency.
Experimental Setup
The evaluation uses ND400, a benchmark dataset sampled from NoCaps and DOCCI, stressing novel objects and fine-grained details. Seven recent models are benchmarked, spanning all three architectural paradigms. Chains are constructed for both text-first and image-first settings, and metrics are computed using appropriate embedding backbones.
Empirical Findings
Semantic Drift Patterns
Qualitative analysis reveals six distinct failure modes under cyclic inference: position inconsistency, object misidentification, style transition, quantity inconsistency, object hallucination, and color inconsistency. These errors compound over generations, even when single-step outputs appear plausible.
Quantitative Results
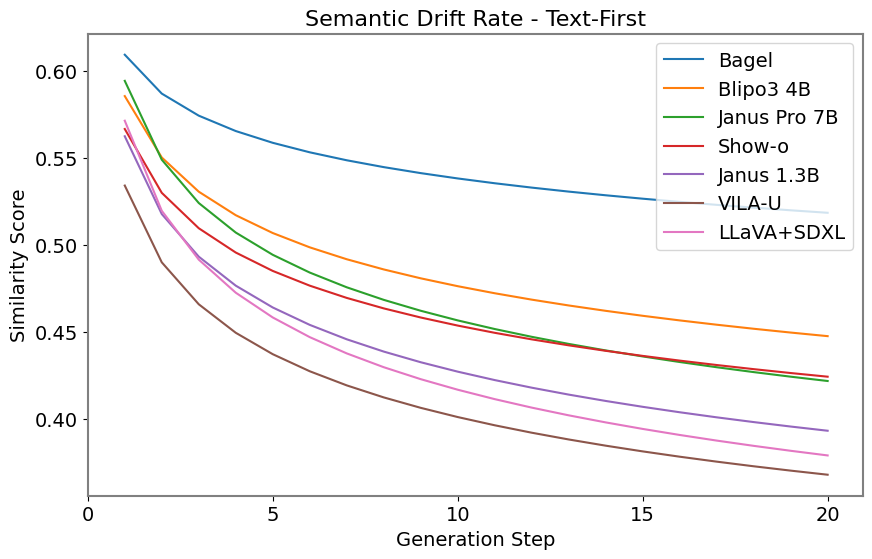
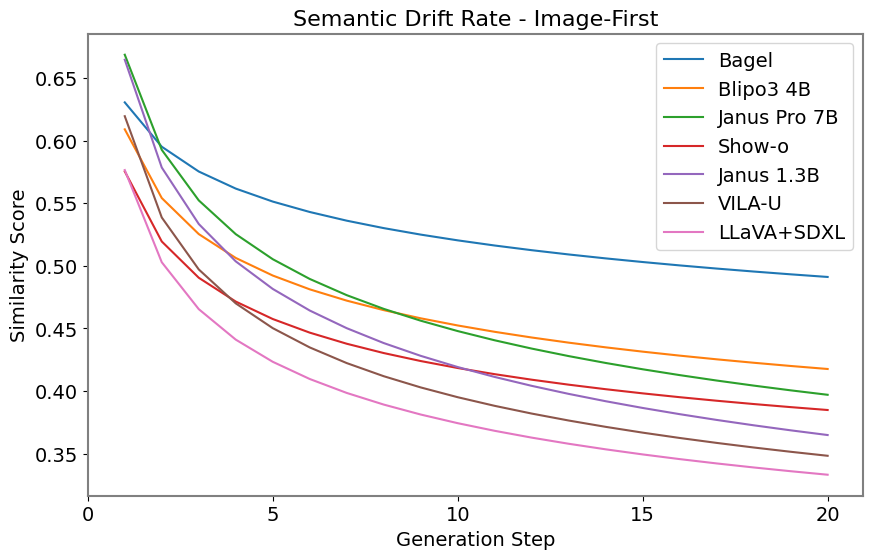
Figure 6: SDR curves for text-first and image-first chains. BAGEL exhibits the flattest decay, indicating superior semantic stability.
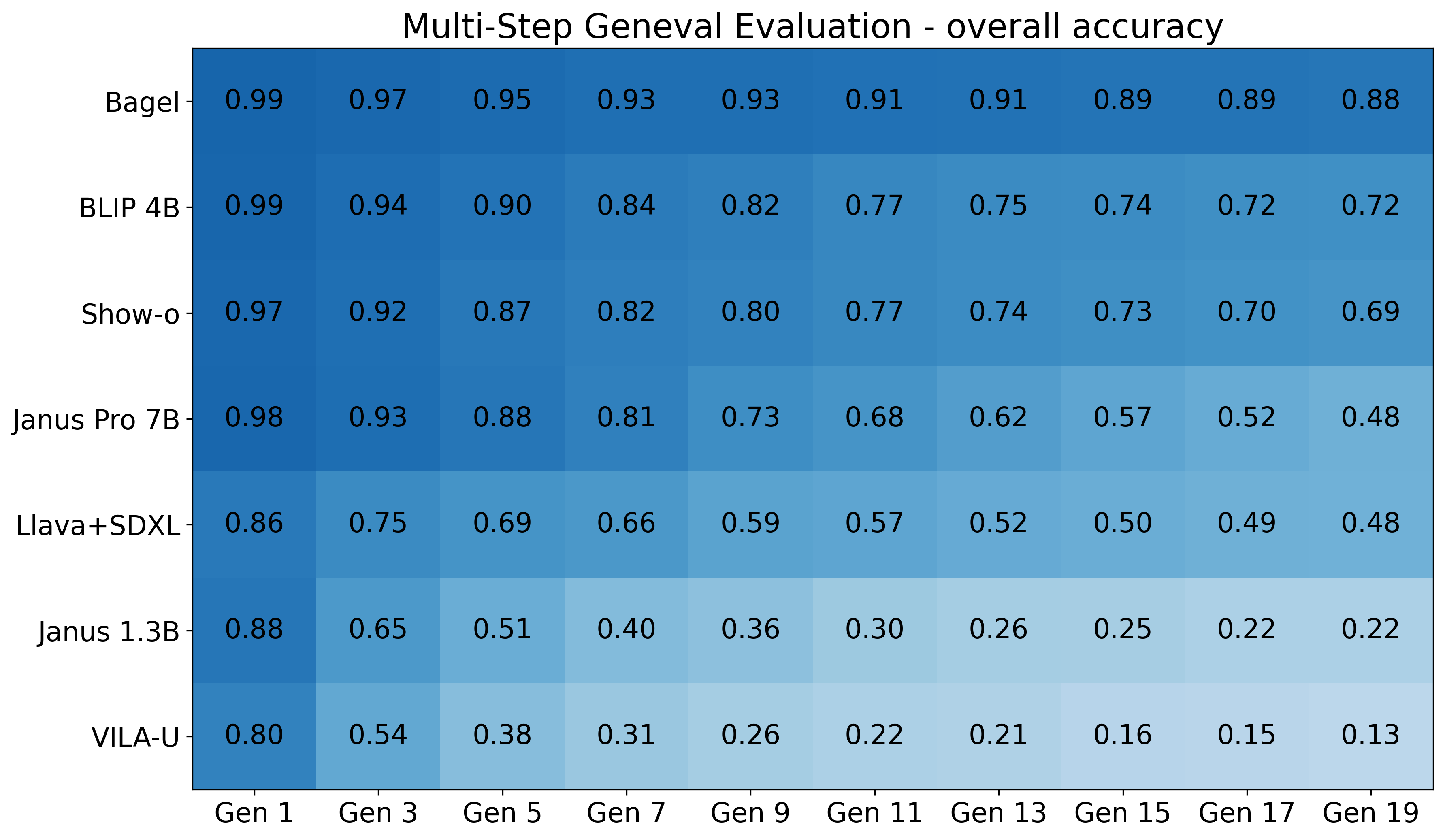
Figure 7: MGG results on GenEval Rewritten dataset. BAGEL maintains high accuracy across generations; VILA-U and Janus 1.3B lose more than half their score within a few generations.
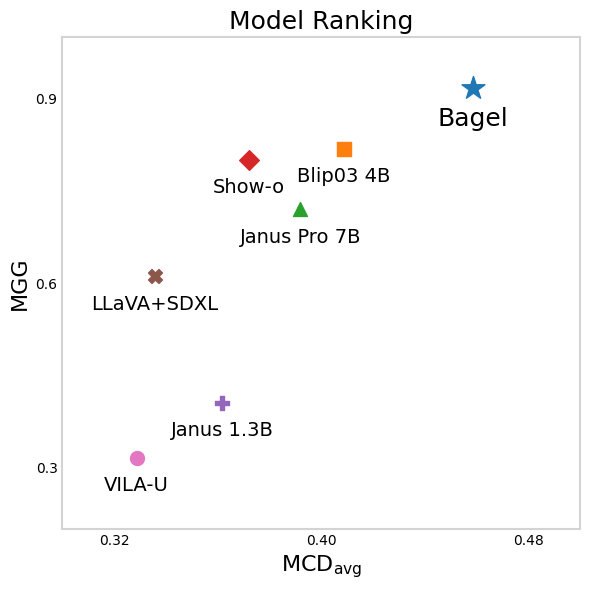
Figure 8: Model comparison across MCD and MGG. BAGEL leads in both metrics; VILA-U lags. LLaVA+SDXL and Janus 1.3B show asymmetric performance.
- BAGEL consistently maintains the strongest cross-modal stability, with slow semantic decay and high object-level fidelity.
- VILA-U and Janus variants exhibit rapid drift, losing semantic alignment within a few generations despite competitive single-pass scores.
- Show-o degrades more gracefully, with slower decay in later generations.
- LLaVA+SDXL (decoupled) performs well on object-level tasks but struggles to preserve holistic semantics, indicating a disconnect between content and meaning.
Task-Specific Vulnerabilities
MGG breakdown by task shows that compositional tasks (positioning, attribute binding) are most susceptible to semantic drift. Initial performance is high for all models, but consistency collapses rapidly for complex tasks.
Implications and Future Directions
The results demonstrate that single-pass benchmarks overstate model robustness and fail to capture cross-modal inconsistencies. Cyclic evaluation is essential for reliable assessment of unified models, as it exposes semantic drift and architectural weaknesses. The findings suggest that architectural scale, training data diversity, and careful design of shared representations are critical for semantic stability. The UCF-UM protocol and metrics provide a practical foundation for future model development and evaluation.
Potential future directions include:
- Integrating cyclic consistency objectives into training to mitigate drift.
- Extending cyclic evaluation to more modalities (e.g., video, audio).
- Developing new architectures that explicitly model cross-modal semantic alignment.
- Investigating the relationship between drift rate and downstream task reliability.
Conclusion
The paper formalizes the semantic drift problem in unified multimodal models and introduces the Unified Consistency Framework (UCF-UM) for cyclic evaluation. Empirical results across seven models reveal substantial variability in cross-modal stability, with BAGEL demonstrating the strongest resistance to drift. The proposed metrics (MCD, SDR, MGG) and cyclic protocol expose hidden inconsistencies that single-pass evaluations cannot detect. These insights are critical for advancing the reliability and robustness of unified models in real-world applications.