- The paper introduces a self-adversarial post-training framework that pits a lightweight perturber against the understanding branch to reveal and mitigate consistency gaps.
- Its minimax optimization strategy significantly boosts cross-modal coherence, achieving a +4.6% improvement in composite consistency and enhanced robustness under adversarial scenarios.
- The study demonstrates practical gains in VQAv2 accuracy and OOD performance with minimal model overhead (<1%), confirming its efficacy in unified multimodal settings.
UniGame: Self-Adversarial Consistency Optimization for Unified Multimodal Models
Unified Multimodal Models (UMMs) have achieved strong results in both image understanding and generation by sharing architectural backbones for visual and textual processing. However, these models suffer from a fundamental structural inconsistency: the understanding branch benefits from compact, task-specific embeddings, while the generation branch relies on high-fidelity, reconstruction-rich representations. This inherent objective tension results in misaligned decision boundaries, degraded cross-modal coherence, and elevated fragility under out-of-distribution (OOD) and adversarial scenarios.
Empirically, this inconsistency manifests as failures where the model can answer questions correctly but fails to generate a corresponding image, or vice versa. Existing post-training approaches—namely, reconstruction-based and reward-based optimization—operate only within fixed data manifolds and utilize surrogate objectives that lack explicit constraints on the coupling between understanding and generation pathways. Consequently, they fail to resolve the representational mismatch, especially near boundary regions where model predictions are most brittle.
UniGame: Self-Play Optimization Framework
The UniGame framework postulates that UMMs can directly confront their consistency weaknesses by turning the generation branch into an internal adversary. The central mechanism is a self-adversarial post-training scheme—a minimax game between the understanding and generation modules executed at the unified visual-token interface.
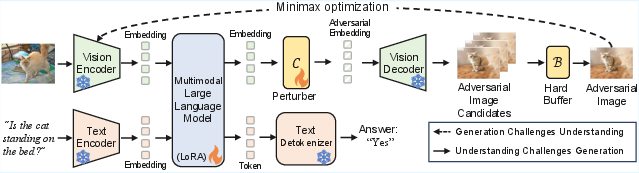
Figure 1: Overview of UniGame. This adversarial self-play improves understanding robustness and understanding-generation consistency. The perturber C is a lightweight (3-layer MLP) module and the hard buffer B stores visually plausible, semantically challenging cases.
Key architectural elements:
- Perturber C: A lightweight, 3-layer MLP operating on the post-LM fused token space, generating bounded perturbations z~=z^+δ (∥δ∥≤εmax).
- Decoder G: Renders perturbed tokens into semantically valid images, enforced by image–text matching constraints (e.g., CLIP similarity).
- Hard-Sample Buffer B: Stores adversarially generated, semantically consistent examples (filtered by CLIP and a hardness metric based on cross-entropy loss relative to the ground-truth).
The adversarial self-play proceeds in alternating steps:
- The perturber maximizes the supervised loss on the understanding branch by generating hard, on-manifold samples.
- The understanding branch is trained to minimize loss both on clean and buffered adversarial samples, learning to defend against its own weaknesses.
Formally, the framework solves: θUminθCmax(LU(θU)+λLC(θC;θU))
where LU covers clean and adversarial/hard examples, and LC represents the effectiveness of adversarial perturbation.
Empirical Results
UniGame establishes significant improvements on multiple standard benchmarks:
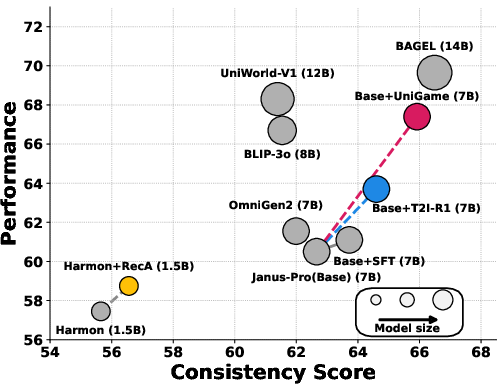
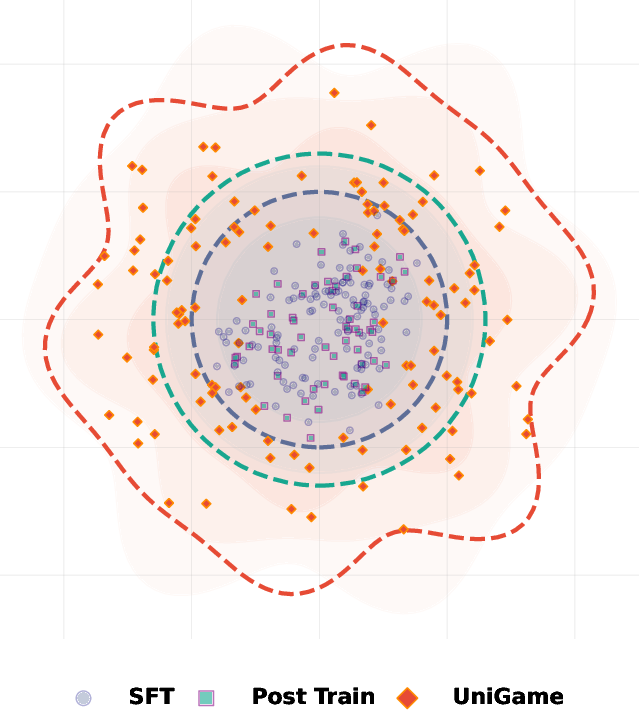
Figure 2: Quantitative analysis of performance vs. consistency. UniGame expands coverage towards hard, realistic neighborhoods and jointly improves both metrics.
- Consistency (as measured by UnifiedBench and WISE): UniGame delivers a +4.6% boost in composite consistency score relative to conventional post-training and other SOTA UMMs.
- Understanding: Achieves +3.6% accuracy increase on VQAv2 compared to model-specific supervised fine-tuning (SFT).
- Generation: Maintains or slightly exceeds generation performance of leading autoregressive and diffusion-based UMMs, outperforming the base model on GenEval (+0.02 overall).
Robustness under Distribution Shift and Adversarial Attacks
Substantial gains are also reported on OOD and adversarial benchmarks:
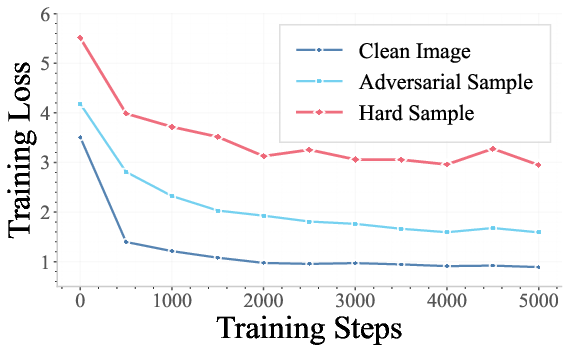
Figure 3: OOD and adversarial robustness. UniGame increases Group Accuracy by 4.8% on NaturalBench and accuracy by 6.2% on AdVQA.
These results validate the hypothesis that decoder-constrained adversarial perturbations systematically expose fragile decision boundaries and harden the understanding branch.
Case Studies and Qualitative Insights
Inspection of hard sample generation and qualitative results:
- The hard buffer captures semantically valid, decision-critical counterexamples targeting counting, object interaction, relations, occlusion, and other nuanced forms of visual reasoning error modes (see Figure 4).
- For open-ended generation, UniGame produces images with more faithful compositional structure and attribute binding compared to baseline SFT or RLHF (Figure 5).


Figure 5: Case study for close-ended and open-ended understanding tasks, highlighting challenging examples successfully addressed by UniGame.

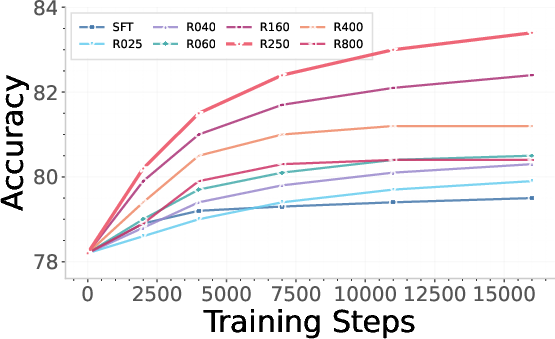
Figure 4: Representative hard-sample buffer cases that challenge the understanding branch and surface underlying model weaknesses.
Theoretical Implications
The minimax training dynamic is theoretically justified as a robust optimization procedure. The adversarial branch introduces a gradient-norm penalty on the understanding loss, equivalent to a local flattening of the decision boundary. Enforcing decoder constraints ensures that adversarial samples remain visually plausible and semantically aligned, thereby expanding the empirical support of the learned manifold in directions most aligned with real OOD data. Convergence analysis under mild smoothness and compactness assumptions supports stability of the alternating updates.
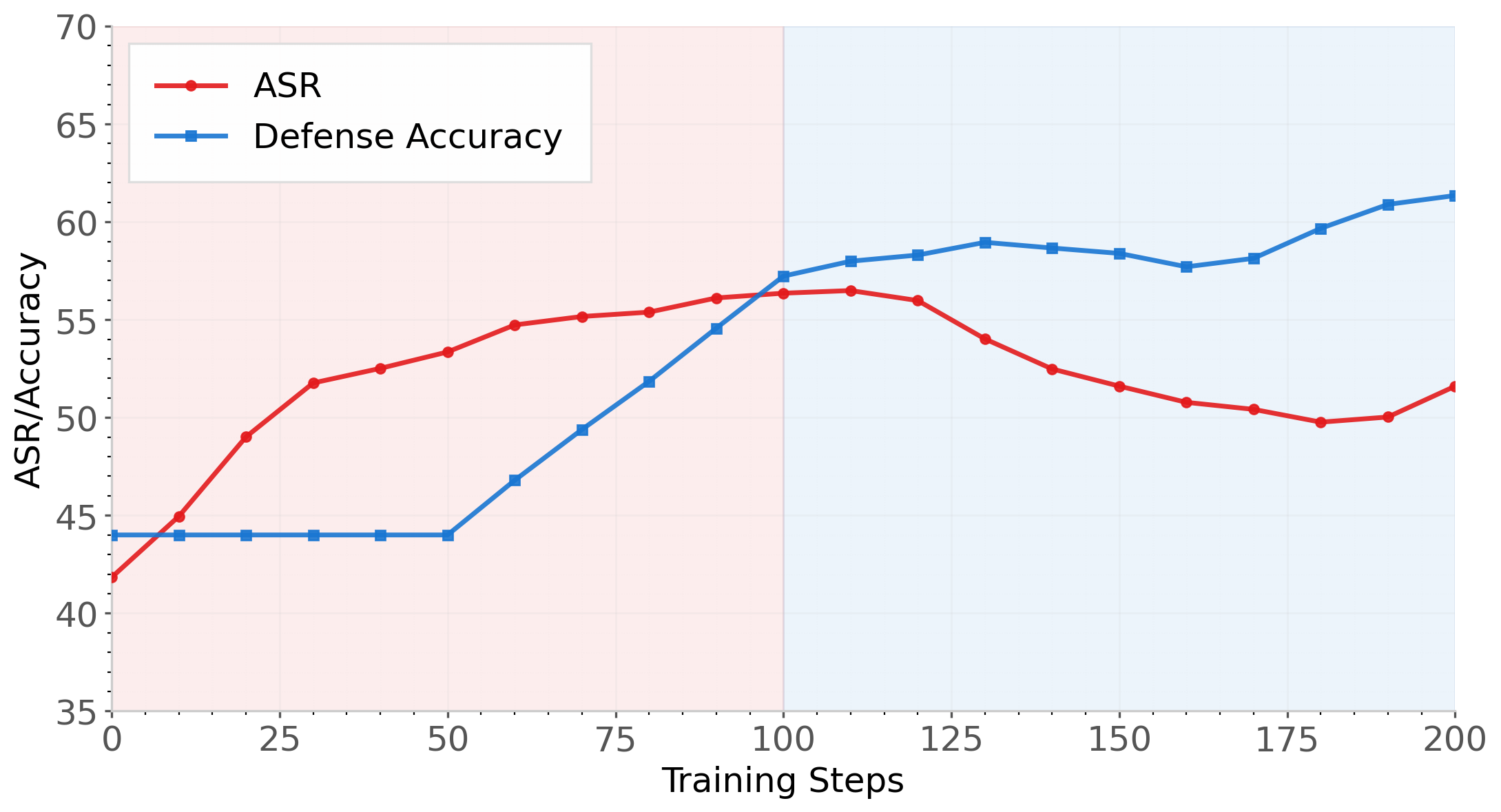
Figure 6: Self-play dynamics: the understanding and generation branches alternately dominate optimization, yielding stable minimax behavior and avoiding mode collapse.
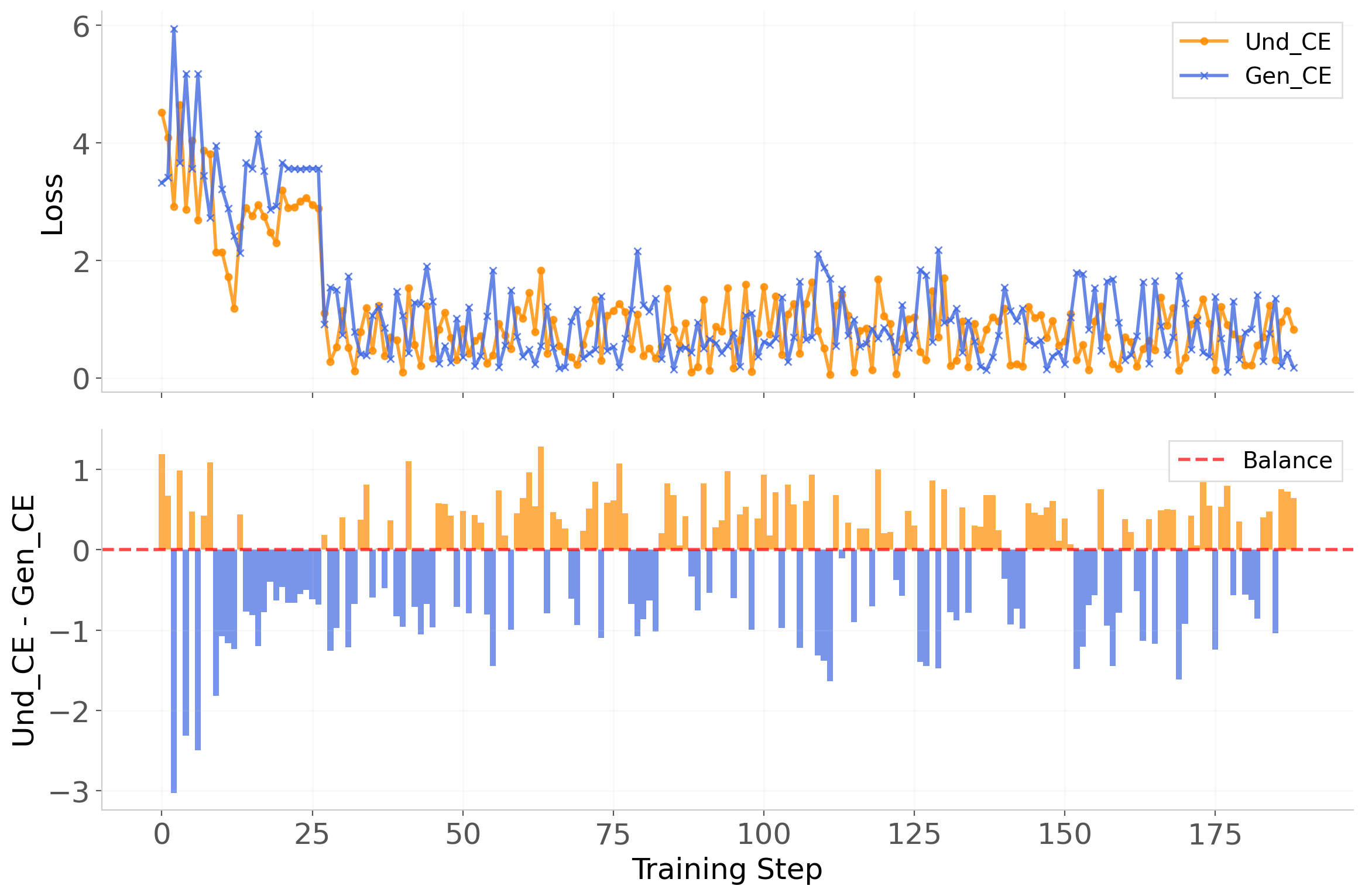
Figure 7: Dominance timeline: training alternates between understanding and generation phases, maintaining consistent improvement and robustness without collapse to either branch.
Ablation and Efficiency
Decoder-constrained perturbations yield strictly stronger adversarial examples than embedding space perturbations. Full UniGame with CLIP filtering and buffer replay achieves +3.9% over SFT on VQAv2, while embedding constraints alone yield at most +0.7%. UniGame is architecture-agnostic, requiring <1% parameter increase, and is complementary to existing SFT, reconstruction-based, and reward-based post-training schemes.
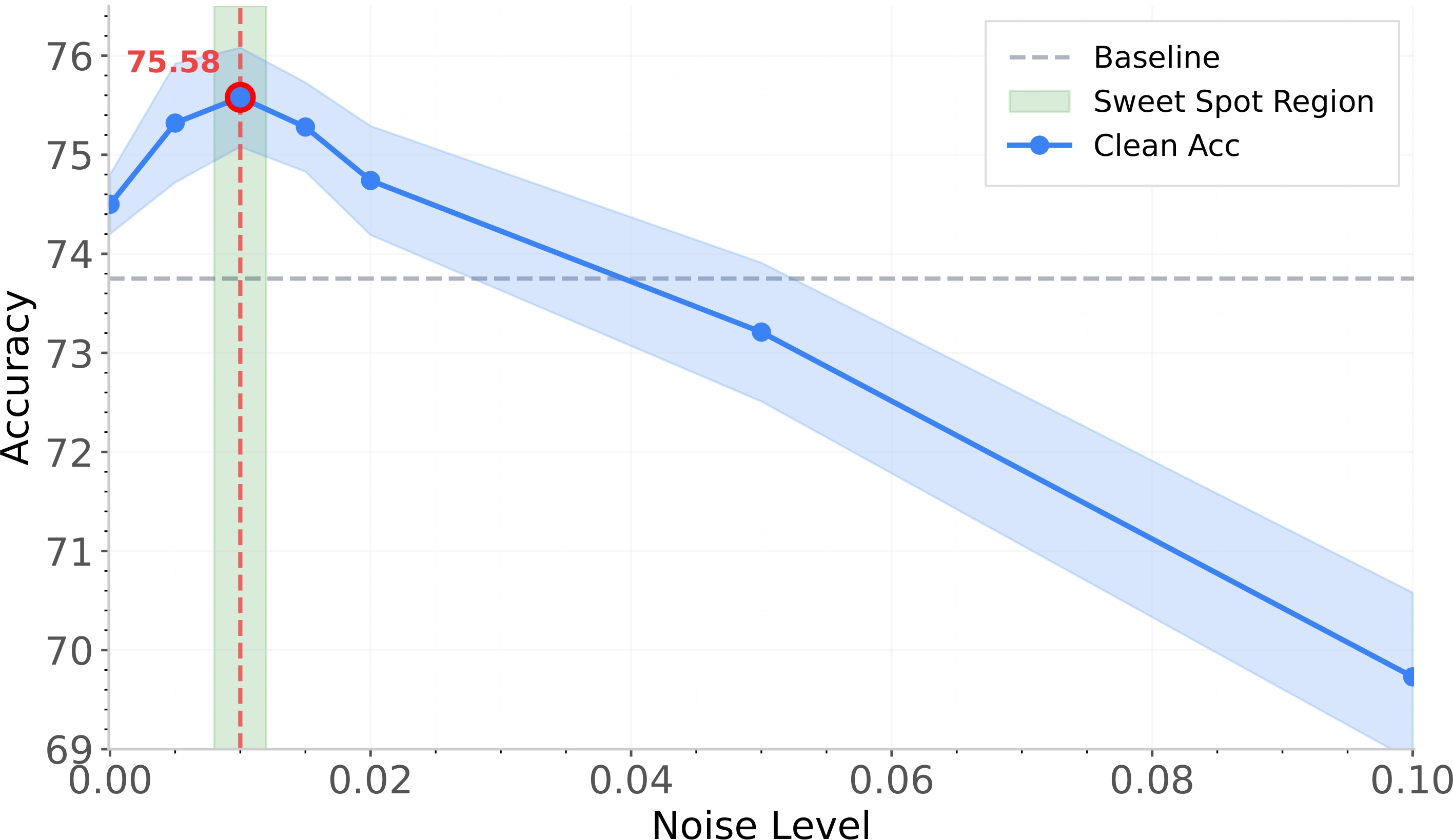
Figure 8: Perturbation sweetspot—accuracy peaks at moderate perturbation magnitudes, confirming benefit of non-trivial, on-manifold adversarial signals.
Practical Implications and Future Directions
UniGame introduces an efficient, architecture-neutral protocol for improving both the consistency and robustness of UMMs. Its minimal computational overhead and plug-and-play design make it suitable for integration into contemporary pipelines. The self-play principle demonstrated here suggests a generalized path for foundation model post-training, extending robust optimization ideas into unified cross-modal architectures.
Open avenues for future work include scale-up to larger foundation models, systematic tests on more diverse and challenging datasets, and refinement of the self-adversarial objectives (e.g., multi-stage games, curriculum adversaries, or expansion to multi-modal dialogue settings).
Conclusion
UniGame presents a theoretically grounded, empirically validated approach for post-training unified multimodal models that directly addresses the structural objective inconsistencies between understanding and generation. Its self-adversarial, minimax game at the token interface reliably exposes and closes consistency gaps, yielding improved coherence and robustness across both vision and language tasks. The principles underlying UniGame—particularly adversarial self-play, decoder-constrained perturbations, and dynamic consistency regularization—offer a blueprint for the next generation of robust, general-purpose multimodal AI systems.

