SOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Abstract: Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SOP, a system that helps robots get better at their jobs while they are working in the real world. These robots use Vision-Language-Action (VLA) models, which means they can see (vision), understand instructions (language), and do things (action). While big, pre-trained VLA models are good at handling many different tasks, they’re not always expert-level at any one task. SOP fixes that by letting a whole fleet of robots learn from their own experiences and from quick human corrections—right as they work—so they become both general and highly skilled.
Key Objectives
Here are the main goals of the paper, explained simply:
- Build a system where many robots can learn at the same time from what they actually do in the real world.
- Make sure learning happens quickly, with updates sent back to robots as they work, instead of only training offline.
- Keep one shared robot brain (policy) that handles multiple tasks well, instead of making separate models that lose generality.
- Show that the system works with different learning methods: learning from human corrections and learning from rewards.
Methods and Approach
Think of SOP like a sports team with a smart coach in the cloud:
- The “players” are the robots. They try tasks like folding laundry, building boxes, or restocking shelves.
- As they work, they stream videos and action logs to the “coach” (a cloud computer). If a robot is about to mess up, a human can briefly take control to show the right move—like a coach stepping in during practice.
- The coach studies these clips (both the robot’s attempts and human fixes), updates the team’s shared playbook (the robot policy), and sends the improved strategy back to all robots.
- This loop—collect, learn, update—keeps running, so robots improve quickly based on real mistakes, not just old training data.
Two types of learning plug into SOP:
- Interactive imitation learning (HG-DAgger): A person only steps in when the robot is about to fail, giving targeted, real-time guidance. The system learns directly from these corrections.
- Reinforcement learning (RECAP): The robot learns from rewards and feedback gathered from its interactions, improving from trial and error.
A key idea is “on-policy” learning: the robots learn from the exact situations they encounter while working, instead of training only on a big, fixed dataset. SOP also mixes new “online” data with older “offline” examples using a smart sampler that keeps all tasks balanced, so the shared policy stays general while getting sharper at each task.
Main Findings and Why They Matter
The authors tested SOP on real robots across three task families:
- Grocery restocking (choosing the right item and placing it correctly, sometimes with doors or coolers involved)
- Laundry folding (bimanual, careful handling of soft clothing)
- Box assembly (multi-step folding into a 3D box)
Key results:
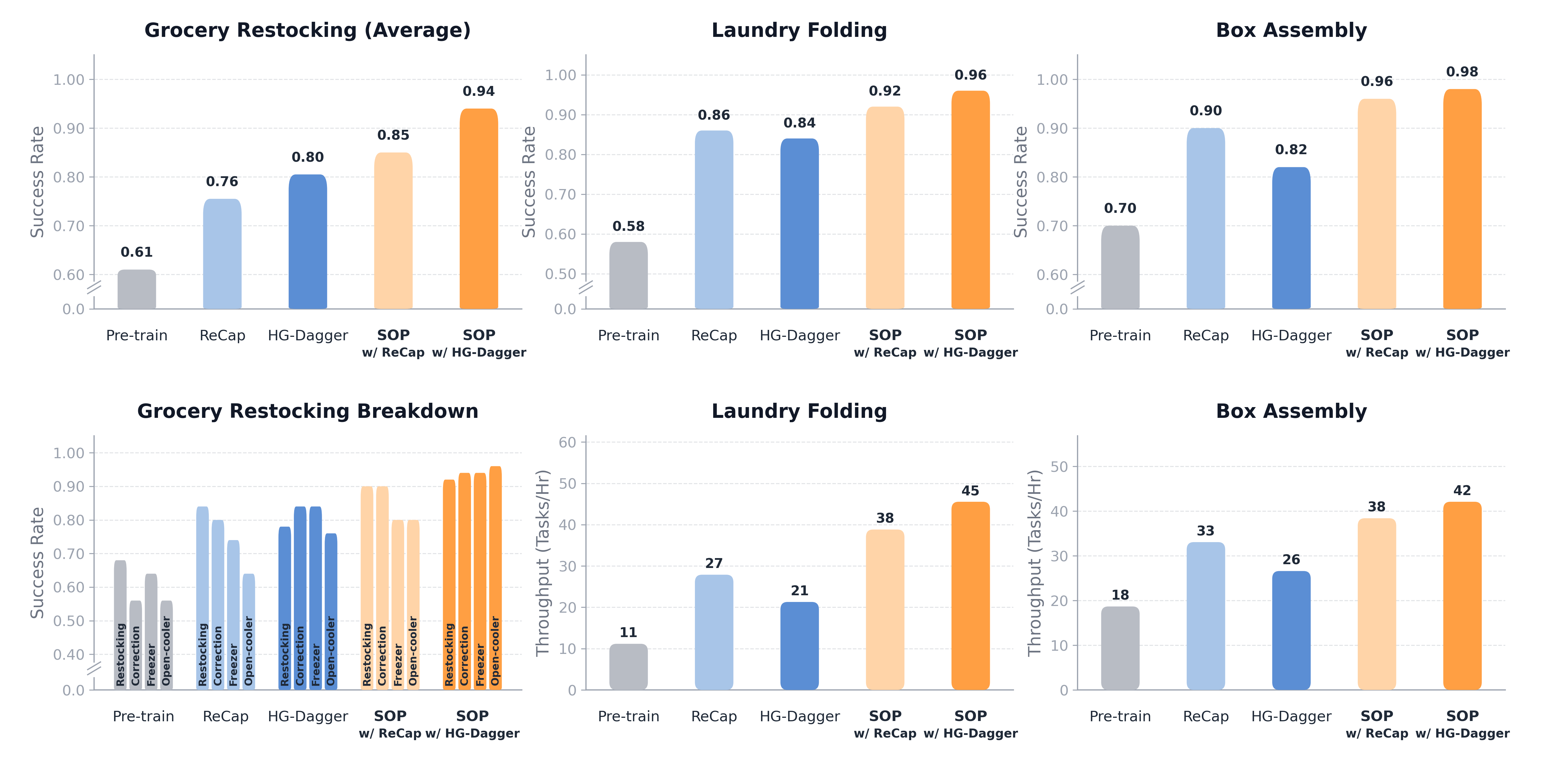
- Big performance gains quickly: Using SOP, robots reached expert-like success rates on all tasks—often above 94%—within hours, not days.
- Faster and more reliable: SOP roughly doubled throughput (more successful tasks per hour) by fixing common failure patterns fast (for example, missed grasps in laundry folding).
- Scales with more robots: Adding more robots made learning near-linearly faster. A fleet of four robots hit target performance in less than half the time compared to a single robot.
- Keeps generality: One shared policy handled multiple tasks well. SOP improved skills without turning the model into a narrow, task-only specialist.
- Works with different learning styles: Both HG-DAgger and RECAP got better with SOP, though interactive imitation (HG-DAgger) shined most in tasks needing strong understanding and precise corrections (like grocery restocking).
Why this matters: Real-world robots face unexpected situations. SOP helps them learn from their actual mistakes and human fixes right away, making them safer, quicker, and more dependable in daily use.
Implications and Impact
This research shows that the way we organize robot learning—linking real-world deployment tightly with continuous learning—can be just as important as the learning algorithms themselves. In simple terms:
- More robots = faster learning: A fleet becomes like extra “compute” for training, because every robot’s experience helps the shared brain improve.
- Smaller need for giant offline datasets: Learning on the job targets the robot’s real problems better than just adding more static demonstrations.
- Path to reliable, general-purpose helpers: SOP pushes us closer to robots that are both versatile and expert—good at many tasks and trustworthy at each one.
Looking ahead, the authors note two big challenges:
- Reducing human effort: Teaching robots to recognize success and learn rewards automatically would cut down on human interventions.
- Continual learning without forgetting: As robots learn new skills over time, we need to protect older ones from being lost.
Overall, SOP is a practical step toward fleets of robots that continuously improve from shared, real-world experience—making them more useful and dependable in homes, stores, and workplaces.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects unresolved that future work could concretely address:
- Scaling beyond small fleets: Validate SOP at larger scales (e.g., 20–100+ robots), quantifying communication bottlenecks, update staleness, centralized learner throughput, and whether near-linear wall-clock speedups persist.
- Human effort and supervision cost: Measure and model the intervention frequency, duration, cognitive load, and total operator time; derive efficiency curves and optimize intervention policies to minimize human labor for a target performance.
- Automated feedback and rewards: Develop and benchmark learned success detectors, reward models, or self-supervised feedback pipelines that can replace task-specific rewards and reduce human interventions while maintaining reliability.
- Continual learning and catastrophic forgetting: Systematically evaluate SOP under continual task addition/removal and long-term operation, and design mechanisms (e.g., replay scheduling, regularization, modular policies) that prevent forgetting and task interference.
- Cross-embodiment generalization: Test SOP across heterogeneous robot platforms, kinematics, sensors, and grippers; quantify transfer gaps and design embodiment-robust policy layers or adapters.
- Safety during online learning: Establish formal safety guarantees for on-policy updates (e.g., constrained updates, shielded rollouts, OOD state detection) and quantify risk profiles during learning and deployment.
- End-to-end throughput and operational cost: Report end-to-end throughput including environment reset/setup time, energy usage, and cloud compute costs; study the trade-offs between actor count, compute budget, and performance.
- Adaptive sampling design: Compare the proposed loss-based mixing with alternatives (e.g., prioritized replay, uncertainty/entropy-based sampling, gradient-conflict-aware weighting) and analyze their stability, fairness across tasks, and convergence properties.
- Update cadence and staleness: Quantify how asynchronous broadcast intervals, partial parameter updates, and mid-episode synchronization policies affect learning speed, stability, and performance; consider staleness correction (e.g., V-trace-like methods).
- Algorithm coverage: Evaluate SOP with additional post-training algorithms (e.g., PPO/GRPO variants for VLAs, behavior-regularized RL, diffusion/flow policy objectives) to identify which objectives best exploit SOP’s dataflow.
- Reward design at scale: Provide general reward templates or success heuristics that scale across tasks without extensive per-task shaping; assess robustness to reward misspecification.
- Privacy and security: Define protocols for privacy-preserving data streaming (encryption, anonymization), access control, and compliance for real-world deployments involving sensitive visual/language data.
- Fault tolerance and robustness: Stress-test SOP under network outages, delayed uploads, corrupted episodes, and actor crashes; design recovery policies and quantify performance degradation and recovery time.
- Generalization to truly novel objects/environments: Ensure evaluation with zero-overlap between post-training objects and test sets; measure systematic generalization across stores, lighting, clutter, and shelf geometries.
- Long-horizon stability: Extend beyond 36-hour runs to multi-week/month evaluations, measuring drift, reliability, and maintenance overhead under seasonal/object distribution shifts.
- Autonomous environment resetting: Integrate and evaluate automatic reset mechanisms (e.g., self-cleanup, re-staging) to enable uninterrupted closed-loop learning without human scene setup.
- Multi-task credit assignment: Move beyond uniform task weights to dynamic allocation based on returns, uncertainty, or learning progress; study fairness-performance trade-offs and task-level scheduling policies.
- Edge vs. cloud learning: Compare centralized cloud learners with edge/on-device training for latency, privacy, bandwidth, and resilience; consider federated variants and their convergence properties.
- Theoretical analysis: Provide convergence/regret guarantees for SOP’s asynchronous, on-policy, multi-task setting; analyze stability under non-stationary data and heterogeneous MDPs.
- Reproducibility and benchmarks: Release SOP code, datasets, and standardized multi-task benchmarks to enable consistent comparison; detail all hyperparameters and infrastructure choices.
- Policy interpretability and debugging: Develop tools to inspect how SOP changes policies over time, localize failure modes, and attribute improvements to specific data or interventions.
- Pretraining data composition: Beyond scale, study which pretraining modalities/tasks most benefit SOP post-training; derive data mixture guidelines and scaling laws for VLA post-training efficiency.
- Simulation–real integration: Evaluate hybrid pipelines that mix simulated online experience with real-world data, including domain randomization and sim-to-real transfer under SOP.
- Versioning, rollback, and A/B testing: Formalize policy version management, gated deployments, rollback criteria, and online A/B experiments to safely evaluate updates across fleets.
- Label quality and noise: Quantify intervention/demonstration noise and its impact on learning; design robust objectives or filtering strategies for noisy human corrections.
- Evaluation metrics breadth: Augment success/throughput with richer metrics (e.g., grasp quality, time-to-first-error, contact forces, recovery rates) to capture dexterity and reliability nuances.
Glossary
- A3C: A distributed deep reinforcement learning algorithm that uses asynchronous actor-learners to speed up training. "Distributed RL systems such as Gorila~\cite{d4pg}, A3C~\cite{mnih2016asynchronous}, and IMPALA~\cite{espeholt2018impala} pioneered actor-learner architectures for accelerated training"
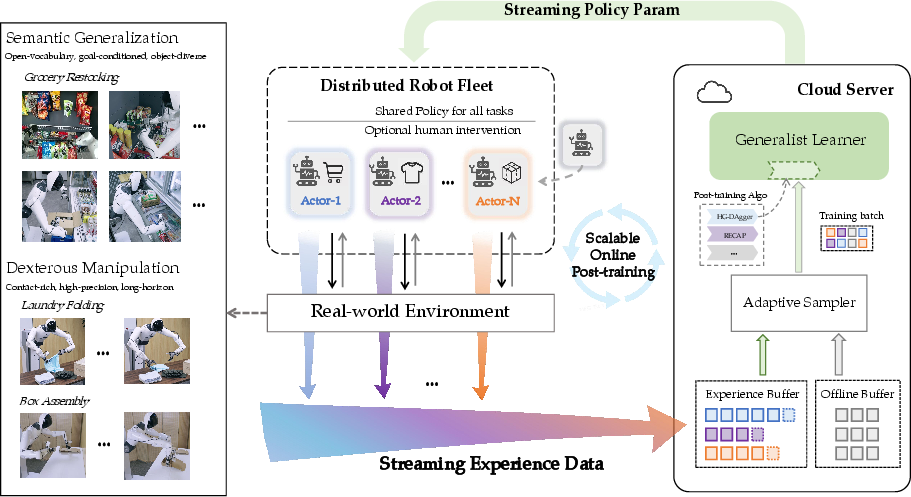
- Actor–learner framework: A system architecture where multiple actors collect experience while a central learner updates the policy. "We present Scalable Online Post-training (SOP), a closed-loop actor--learner framework for adapting a pretrained VLA policy"
- Adaptive sampling strategy: A data sampling method that dynamically mixes online and offline data (and balances tasks) based on recent losses. "we use a task-balanced adaptive sampling strategy at learner step ."
- Behavior cloning: Imitation learning that trains a policy to mimic expert demonstrations via supervised learning. "which are subsequently distilled into a generalist policy via behavior cloning."
- Behavior-regularized RL: Reinforcement learning methods that constrain the learned policy toward known behaviors to improve stability. "Behavior-regularized RL methods can improve stability"
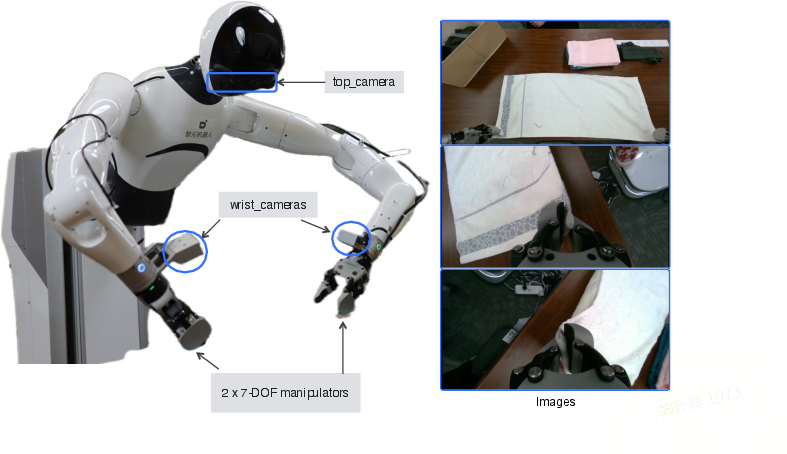
- Bimanual: Involving two arms/hands for manipulation. "Laundry Folding: a bimanual sequence where the robot flattens and folds a garment."
- Closed-loop architecture: A design that tightly couples execution and learning via continuous feedback. "SOP tightly couples execution and learning through a closed-loop architecture"
- Cloud learner: A centralized training service that aggregates experience and updates the shared policy. "streams on-policy experience and human intervention signals to a centralized cloud learner"
- DAgger: An iterative imitation learning algorithm that aggregates states from the learned policy with expert corrections. "Iterative imitation learning methods, such as DAgger, partially mitigate this issue by incorporating human corrections"
- Dexterous manipulation: Skillful, precise control for complex physical tasks. "on challenging dexterous manipulation tasks using only limited real-world interaction."
- Discount factor: The parameter in RL that weights future rewards relative to immediate ones. "and is the discount factor."
- Distribution shift: A mismatch between training data and deployment data that degrades performance. "offline training on pre-collected demonstrations inevitably suffers from distribution shift"
- Fleet-scale deployment: Running and learning from a large number of robots in parallel. "tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training"
- GRPO: A reinforcement learning algorithm used for training large models, related to proximal methods. "Online RL algorithms such as PPO~\cite{schulman2017proximal} and GRPO~\cite{grpo2024} have shown strong results"
- HG-DAgger: A human-gated variant of DAgger where the expert intervenes only when failure is imminent. "we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP)."
- Human interventions: Real-time corrective actions provided by a human during robot execution. "Optional human interventions are triggered in failure or uncertain cases, providing corrected trajectories"
- IMPALA: A scalable distributed RL algorithm with importance-weighted actor-learner architecture. "Distributed RL systems such as Gorila~\cite{d4pg}, A3C~\cite{mnih2016asynchronous}, and IMPALA~\cite{espeholt2018impala} pioneered actor-learner architectures"
- Interactive imitation learning: Learning paradigms where expert feedback is provided during the agent’s own rollouts. "we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP)."
- Long-horizon evaluations: Tests that measure performance on tasks requiring many sequential decisions over extended durations. "In long-horizon evaluations, tasks such as laundry folding and box assembly run continuously for over 36 hours without degradation"
- Markov decision process (MDP): A formal model of sequential decision making with states, actions, transitions, rewards, and discount. "We formulate the considered robot control problem as a Markov decision process (MDP)"
- Multi-task post-training: Adapting a single policy across multiple tasks simultaneously after pretraining. "SOP is a scalable actor–learner framework for online, multi-task post-training of generalist policies."
- Object storage: Cloud storage for large, immutable data objects (episodes/trajectories). "uploads them asynchronously to object storage at episode boundaries."
- Offline buffer: A static dataset of prior demonstrations used alongside streaming online data. "constructs task-balanced updates by mixing an online buffer with a static offline buffer"
- Offline RL: Reinforcement learning that trains solely from pre-collected datasets without online interaction. "encompassing both online and offline RL"
- Offline demonstrations: Expert trajectories collected before training begins, used for supervised finetuning or offline RL. "offline training on pre-collected demonstrations"
- On-policy correction: Immediate feedback or updates based on the currently deployed policy’s behavior. "This design supports prompt on-policy correction"
- On-policy rollouts: Trajectories generated by the policy that is currently deployed. "The robot fleet streams on-policy rollouts to the cloud learner."
- Online RL: Reinforcement learning that updates a policy through live interaction with the environment. "post-training via online reinforcement learning (RL) and human feedback has proven to be very effective"
- Policy–data staleness: Lag between current policy parameters and the data used to train them. "This reduces policy–data staleness and enables continual, on-policy improvement"
- Proprioceptive information: Internal robot sensing of its own states (e.g., joint positions, forces). "robot proprioceptive information."
- Proximal Policy Optimization (PPO): A widely used policy-gradient RL algorithm with clipped objectives for stability. "Online RL algorithms such as PPO~\cite{schulman2017proximal} and GRPO~\cite{grpo2024}"
- Publish–subscribe channel: A communication pattern where updates are broadcast and subscribers receive them asynchronously. "through a lightweight publish–subscribe channel at short intervals."
- RECAP: An offline RL post-training method that combines reward feedback and human interventions. "RECAP combines reward feedback with human interventions through iterative offline training"
- Reinforcement learning (RL): A learning paradigm where agents learn behaviors through reward-driven interaction. "post-training via online reinforcement learning (RL) and human feedback has proven to be very effective"
- RLDG: A framework that trains task-specific RL policies and distills them into a generalist via imitation. "RLDG \cite{xu2024rldg} adopts a complementary strategy by first using task-specific RL to generate high-quality trajectories, which are subsequently distilled into a generalist policy via behavior cloning."
- Scalable Online Post-training (SOP): A system that couples distributed robot execution with centralized online learning for VLA models. "We introduce a Scalable Online Post-training (SOP) system"
- Task-balanced updates: Training updates that allocate equal weight across tasks to preserve generality. "The cloud learner constructs task-balanced updates by mixing an online buffer with a static offline buffer"
- Value function: A function estimating expected returns from states (or state-action pairs), used in many RL algorithms. "we therefore condition both the policy and value function on the task language prompt"
- Vision-language-action (VLA) models: Policies that integrate visual perception, language understanding, and action generation. "Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training"
Practical Applications
Immediate Applications
Below are applications that can be piloted or deployed now with existing tools, given the system and results demonstrated in the paper.
- Retail restocking and shelf organization with fleet learning
- Sectors: Retail, Robotics, Logistics
- What: Deploy generalist VLA robots to restock shelves (flat shelves, coolers, freezers), correct misplaced items, and manage diverse SKUs; SOP closes the last-mile proficiency gap in hours via on-policy human interventions and continuous updates.
- Tools/products/workflows:
- Fleet management console with SOP actor–learner loop, online buffers, and publish–subscribe model updates.
- “Retail RLHF” workflow: store associates provide brief teleop takeovers (HG-DAgger) or simple reward feedback (RECAP) when failures occur.
- Task dashboards tracking success rate, throughput, and time-to-target improvements by store/site.
- Assumptions/dependencies:
- Pretrained VLA base model with broad object semantics; reliable edge-cloud connectivity; safe human override; SKU metadata/instructions; freezer/cooler safety compliance; suitable grippers and perception.
- Packaging and kitting (box assembly) on manufacturing/3PL lines
- Sectors: Manufacturing, E-commerce/3PL, Robotics
- What: Use SOP to rapidly adapt generalist policies to specific box SKUs and folding sequences, improving reliability and speed without per-line task-specific retraining.
- Tools/products/workflows:
- SOP-enabled “packaging cell” integrating dual-arm manipulators, camera rigs, and an online post-training service.
- Changeover workflow: operators flag new SKU; robots self-improve via online interventions over a few hours; model weights broadcast to all identical cells.
- Assumptions/dependencies:
- Safe cell enclosures; base policy capable of multi-step manipulation; latency-tolerant publish–subscribe updates; quality metrics to detect fold errors.
- Commercial laundry folding in hospitality and facilities
- Sectors: Hospitality, Facilities Management, Robotics
- What: Deploy bimanual folding robots that improve grasp timing and fold accuracy in each facility through SOP with minimal operator supervision.
- Tools/products/workflows:
- “Folding-as-a-service” platform: standardized folding prompts; human-gated corrections during early shifts; SOP scales improvements across all sites.
- Throughput monitoring aligned with SLAs (folds/hour per station).
- Assumptions/dependencies:
- Pretrained deformable-object priors; consistent lighting/workspace; safe handover and intervention; garment variability handled in pretraining or early SOP cycles.
- Rapid post-training for robotics system integrators
- Sectors: Robotics, Industrial Automation, Software
- What: Use SOP to deliver customer-tailored proficiency quickly, reducing engineering effort compared to bespoke, task-specific fine-tuning.
- Tools/products/workflows:
- SOP “starter kits” (edge client, storage schema, adaptive sampler) packaged with integrator solutions.
- Field-deployment playbook: 1–3 hour online post-training window per site to close performance gaps; multi-site model rollouts.
- Assumptions/dependencies:
- Customer-approved data governance; compute budget (e.g., 4–8 GPUs); intervention staffing plan; model versioning and rollback.
- Multi-task generalist policy maintenance across a fleet
- Sectors: Robotics, MLOps for Embodied AI
- What: Maintain a single multi-task VLA policy (e.g., restock + fold + assemble) that avoids catastrophic “narrowing” while improving on each local task via SOP’s task-balanced adaptive sampling.
- Tools/products/workflows:
- Centralized learner with task-aware sampler; online/offline buffer mixing; per-task loss monitoring; staged updates across time zones.
- Assumptions/dependencies:
- Robust task tagging and prompts; stable mixing ratios; replay buffers with retention and audit; safe update cadence between episodes.
- Academic testbed for online, distributed, multi-task learning
- Sectors: Academia, Research Labs
- What: Reproduce the actor–learner pipeline to study scaling laws, intervention efficiency, on-policy vs. offline data value, and generalist policy retention.
- Tools/products/workflows:
- Open-source SOP-like reference stack (dataset schema, online buffer, adaptive sampler, cloud learner); benchmarks for long-horizon manipulation (folding/assembly).
- Assumptions/dependencies:
- Access to a small fleet or simulated proxies plus limited physical robots; IRB/data policies; human-in-the-loop budgets.
- Safety and operations policy within organizations
- Sectors: Corporate Policy, Safety/Compliance
- What: Define internal standards for human interventions, logging, and updates in online-learning robot fleets.
- Tools/products/workflows:
- SOP-aware SOPs (standard operating procedures): gating rules for takeover, model update windows, and audit logs; role-based access controls for deployment.
- Assumptions/dependencies:
- Safety case documentation; incident response plans; workforce training for intervention tooling.
- Home and maker-space robots that “learn on the job”
- Sectors: Consumer Robotics (niche), Education/Makers
- What: Early-adopter settings where users provide occasional corrections to improve tasks such as folding, organizing, or kit assembly.
- Tools/products/workflows:
- Lightweight edge client syncing with a cloud learner; mobile app for safe intervention and update scheduling.
- Assumptions/dependencies:
- Affordable hardware with suitable grippers; consumer data privacy controls; simpler tasks; limited compute with small models or cloud credits.
Long-Term Applications
These applications are promising but require further research, scaling, or enabling technology (e.g., lower supervision, stronger safety guarantees, broader generalization).
- Hospital logistics and clinical support with continual adaptation
- Sectors: Healthcare, Robotics
- What: Generalist robots handling restocking, sterile kit prep, room turnover, or basic patient assist tasks, improved via SOP under strict safety/privacy.
- Tools/products/workflows:
- “Clinical SOP” platform with HIPAA-compliant data handling; policy-side success detection to limit human load; simulation pre-screening before live updates.
- Assumptions/dependencies:
- Reliable success detection/reward models; formal safety constraints; human factors validation; robust failure containment; regulatory approval.
- Construction and field robotics that learn across heterogeneous sites
- Sectors: Construction, Infrastructure, Energy
- What: Tasks like cable routing, panel installation, or material sorting in changing environments, improved through fleet-scale on-policy learning.
- Tools/products/workflows:
- SOP variants with high-latency/low-connectivity resilience; offline-first buffers; cross-site curriculum scheduling; environment-specific affordance modules.
- Assumptions/dependencies:
- Ruggedized hardware; variable lighting/weather handling; robust perception for novel materials; sparse supervision; safety certification.
- Agricultural harvesting, sorting, and packing with shared experience
- Sectors: Agriculture, Food Processing, Robotics
- What: Fruit/vegetable picking and packing robots improving grasp/select strategies across farms and seasons via a shared learner.
- Tools/products/workflows:
- Cross-farm SOP with seasonality-aware samplers; phenology-specific prompts; automatic success detectors trained from vision.
- Assumptions/dependencies:
- Weatherproof sensing; domain-shift robustness; gentle manipulation; label-light feedback (less human intervention).
- Autonomous retail operations with minimal human supervision
- Sectors: Retail, Operations
- What: Near-fully autonomous restocking (including door manipulation, handling cartons), with human oversight limited to exception handling.
- Tools/products/workflows:
- Self-evaluation/reward models; anomaly detection; predictive maintenance tied to learning performance; policy confidence gating.
- Assumptions/dependencies:
- Accurate success/reward modeling; low-latency safety stops; scalable exception pipelines; tight integration with inventory systems.
- Generalist factory cells for multi-station assembly and QA
- Sectors: Manufacturing, Electronics
- What: Single VLA policy handling assembly, insertion, fastening, and visual QA, continually improved across lines and SKUs without task-specific re-training.
- Tools/products/workflows:
- Multi-task SOP with catastrophic-forgetting mitigation; line-change schedulers; closed-loop integration with MES/QMS for label-light rewards.
- Assumptions/dependencies:
- Stable continual-learning methods; robust vision-language grounding in fine tolerances; secure OTA updates in regulated plants.
- Federated or privacy-preserving fleet learning
- Sectors: Software, Privacy/Compliance, Cross-Enterprise Consortia
- What: Multi-tenant SOP where companies share improvements without exposing raw data (federated or differentially private updates).
- Tools/products/workflows:
- Federated actor–learner protocols; secure aggregation; per-tenant model adapters; governance/audit dashboards.
- Assumptions/dependencies:
- Standardized data schemas; privacy tech maturity; legal frameworks for model-parameter sharing; performance parity with centralized learning.
- Automated success/reward modeling to reduce human effort
- Sectors: Robotics, AI Tooling
- What: Train success detectors and reward models (possibly VLM/VLA-based) to replace most human interventions for SOP updates.
- Tools/products/workflows:
- Self-supervised event labeling; weak-to-strong reward modeling; confidence-aware training batches; continuous calibration pipelines.
- Assumptions/dependencies:
- Reliable generalization of reward models; false-positive/negative control; periodic human audits; effect on stability and safety understood.
- Regulatory frameworks for adaptive robotic systems
- Sectors: Public Policy, Standards
- What: Certification pathways and liability models for robots that change behavior post-deployment through online learning.
- Tools/products/workflows:
- Standards for update cadence, rollback, audit trails, and human-gated overrides; conformance testbeds for SOP-like systems; post-market surveillance protocols.
- Assumptions/dependencies:
- Cross-stakeholder consensus; incident reporting norms; harmonization with data privacy and cybersecurity regulations.
- Cross-domain embodied foundation models with SOP-driven continual learning
- Sectors: Robotics, Software Platforms
- What: One policy that spans service, industrial, and domestic tasks, continuously refined through diverse fleet interactions.
- Tools/products/workflows:
- Hierarchical/task-decomposed SOP; scalable memory/rehearsal buffers; semantic skill libraries; policy distillation pipelines across domains.
- Assumptions/dependencies:
- Stronger foundations for multi-embodiment generalization; forgetting-resistant training; compute-efficient synchronization at very large scale.
Notes on shared feasibility factors (cross-cutting):
- Base-model dependency: SOP assumes a broadly capable pretrained VLA model; post-training refines rather than replaces pretraining.
- Human-in-the-loop: Immediate deployments rely on HG-DAgger-style interventions or simple rewards; long-term viability improves with automated success detection.
- Infrastructure: Reliable edge–cloud connectivity, object storage, and GPU learners (4–8+ GPUs in paper’s setup); safe, episode-bound parameter updates to avoid mid-episode drift.
- Safety/governance: Clear override and rollback procedures; data governance and privacy; rigorous logging/audit; site-specific safety certification.
- Scaling: Near-linear gains depend on avoiding bottlenecks in data ingest, training throughput, and parameter synchronization; adaptive sampling helps maintain generality across tasks.
Collections
Sign up for free to add this paper to one or more collections.