- The paper introduces a novel framework for reward-guided post-training that significantly enhances generalization across vision, language, and action tasks.
- It combines supervised imitation learning with flow-matching and direct preference optimization to refine policy execution efficiently.
- Empirical results show marked improvements in simulation and real-robot benchmarks, with up to a 46% increase in grasp success rates.
NORA-1.5: Scalable Reward-Guided Post-Training of Vision-Language-Action Models
Overview and Motivation
NORA-1.5 (2511.14659) addresses a critical limitation of existing vision-language-action (VLA) architectures in embodied AI: the inability to generalize robustly and reliably across diverse robots and environments using standard imitation learning and supervised fine-tuning protocols. While pre-trained VLA models achieve compelling downstream task performance, their reliance on expert trajectories and supervised adaptation restricts both generalization and post-training improvement, especially when confronted with limited embodiment-specific data or noisy reward signals.
The core contribution of NORA-1.5 is an architectural and algorithmic framework for post-training VLAs using reward models built on action-conditioned world models and geometric heuristics, combined via preference-based objectives. This synthesis enables scalable, reward-driven policy refinement compatible with both autoregressive and flow-matching VLA architectures, driving consistent gains across simulated (LIBERO, SimplerEnv) and real-robot (Galaxea A1) benchmarks.
Architecture and Training Pipeline
NORA-1.5 builds on the autoregressive NORA VLA pretrained on Open X-Embodiment data, augmenting it with a flow-matching action expert. This expert leverages key-value representations from the VLA transformer backbone to generate high-fidelity, multi-step continuous action sequences. The two components are jointly trained via cross-entropy and flow-matching losses, yielding improved action consistency and inference speed.
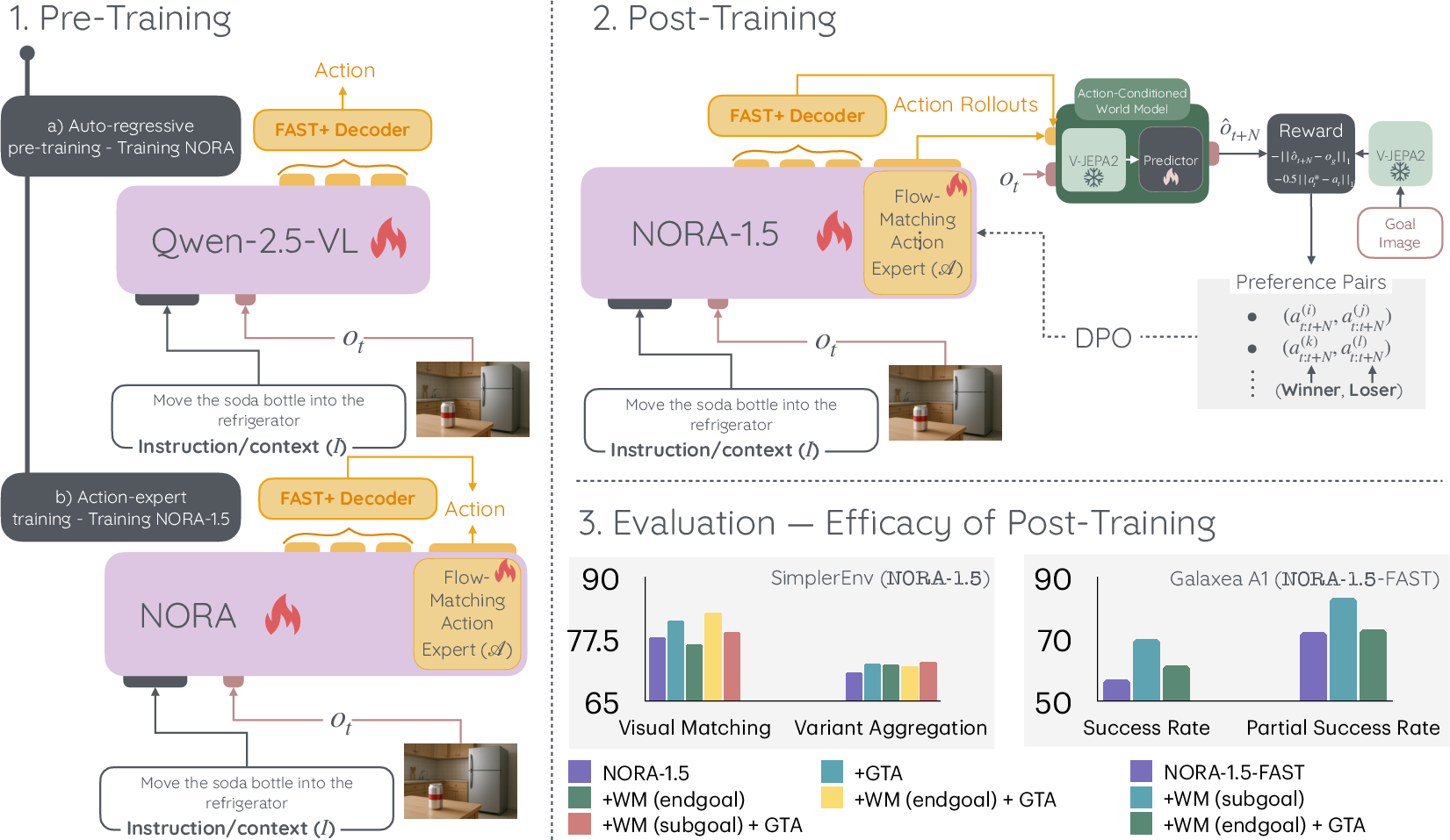
Figure 1: Training pipeline of NORA-1.5 where firstly a VLA model is pre-trained through imitation learning and subsequently a preference dataset of the actions is created for preference optimization.
Key to NORA-1.5's efficacy is its two-stage training regime:
- Supervised Joint Training: The transformer-based VLA backbone and flow-matching action expert are initialized and co-trained on imitation data by minimizing a combination of cross-entropy (on tokenized actions) and flow-matching losses (on continuous actions).
- Reward-Guided Post-Training: Synthesized preference datasets are constructed using two primary reward sources:
- WM-guided goal-based rewards: An action-conditioned world model (V-JEPA2-AC) predicts the latent embedding of the resulting observation after executing a candidate action sequence, and reward is the negative distance to the goal or subgoal state embedding.
- Deviation-from-expert rewards: The L1 distance between generated and ground-truth actions serves as a geometric proxy for action quality.
These rewards are combined to generate pairwise preferences over action samples, which are then used to optimize the policy via Direct Preference Optimization (DPO).
Flow-Matching Synergy and Action Generation
Direct comparison of the FAST+ autoregressive and flow-matching action generation paradigms reveals non-trivial architectural synergy in NORA-1.5. While prior work used flow-matching only for faster inference, in NORA-1.5 the co-training of flow-matching and autoregressive heads produces mutual benefit: the flow-matching expert leverages rich VLA representations for planning, and the VLA backbone receives gradient feedback that improves long-horizon trajectory coherence.
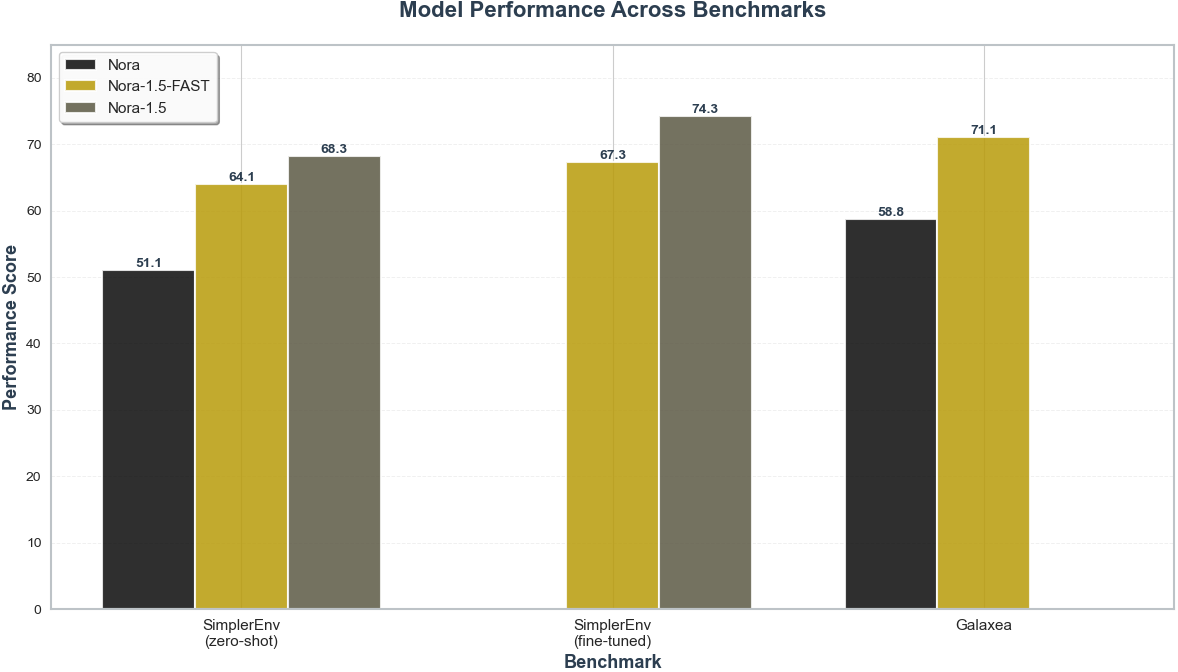
Figure 2: Comparing FAST+ with flow-matching.
Empirical results demonstrate that NORA-1.5 exhibits consistent performance gains over a pure autoregressive VLA or over architectures with decoupled action heads.
Reward Modeling and Preference Optimization
A distinguishing feature of NORA-1.5 is the use of reward signals constructed from world models rather than from costly environment interaction or hand-crafted success criteria. By leveraging V-JEPA2-AC as a goal estimator, reward computation becomes a compute-bound process, scaling up synthetic feedback while avoiding the brittleness of distance-to-demo rewards.
NORA-1.5's reward signals can be applied as either standalone criteria (goal-based or geometric) or as linear combinations, addressing the trade-off between exploration (diverse goal-reaching behaviors) and exploitation (demo-matching optimality). DPO is intrinsically compatible with flow-matching/diffusion-based action heads, as preference optimization avoids the need for normalized or calibrated likelihoods.
Experimental Results
NORA-1.5 was extensively evaluated on challenging simulated and real-world policy adaptation and generalization benchmarks:
- SimplerEnv: Zero-shot and fine-tuned NORA-1.5 outperformed all baseline VLAs (e.g., SpatialVLA, MolmoAct, π0) in success rate, particularly on pick-and-place and spatial manipulation tasks under severe simulation-to-reality gap.
- LIBERO: Application of DPO yielded consistent improvements over supervised or flow-matching-only baselines on spatial, object, goal-directed, and long-horizon tasks.
- Real-robot Adaptation: On the Galaxea A1 arm, NORA-1.5 achieved significant improvements in both aggregate and partial grasp success rates, achieving a performance margin of up to 46% over strong baselines in settings with limited fine-tuning data and in the presence of distractor objects.

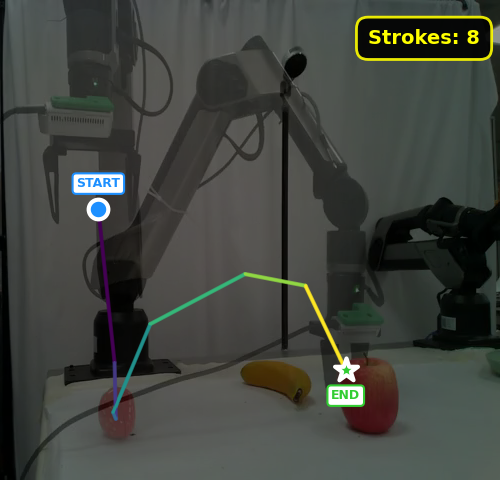
Figure 3: NORA-1.5 without DPO. The gripper trajectory exhibits frequent fixations and zig-zag motions, often resulting in failed grasps and grasp attempts toward distractor objects.
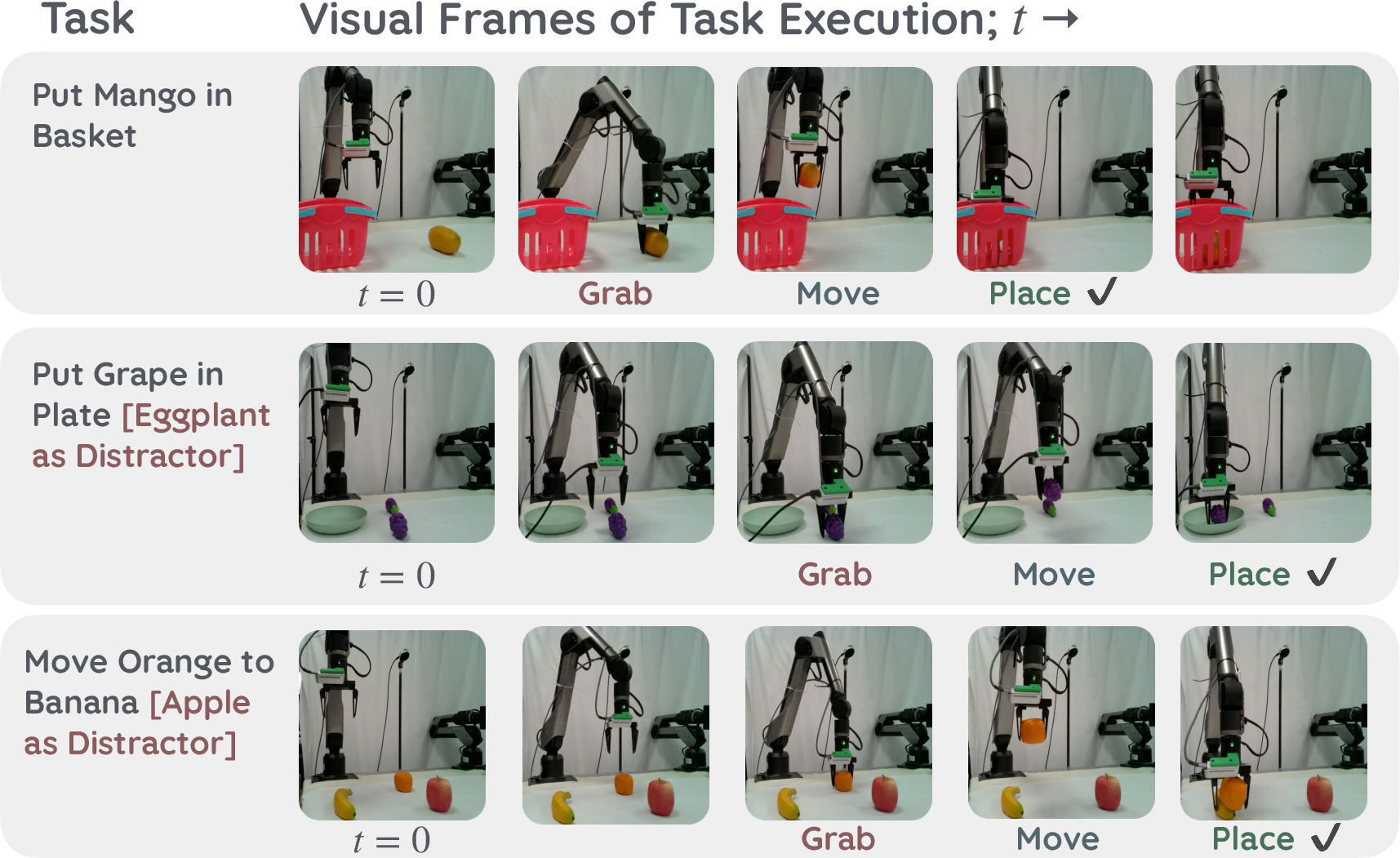
Figure 4: Examples of NORA-1.5 executing evaluation tasks with Galaxea A1 robotic arm in the real world.
DPO-driven post-training produces not only smoother and more goal-directed action trajectories, but also better robustness against distractors and out-of-distribution object/instruction combinations.
Ablations: Reward Design and Post-Training Benefits
Ablation studies reveal that:
- Purely goal-based world model rewards may introduce noise, especially in safety-critical tasks where subgoal information better addresses intermediate constraints.
- Deviation-from-expert (GTA) rewards overfit to demonstration modes and may degrade generalization in real-robot scenarios with multiple valid solution paths.
- Hybrid reward schedules (combining subgoal-based world model feedback and GTA penalty) yield the most robust and transferable policy improvements.
Implications and Future Directions
NORA-1.5 demonstrates that preference-guided post-training, using scalable synthetic rewards from world models and action heuristics, is a practical and effective approach to generalize VLA policies across new robots, tasks, and environments.
Practically, the decoupling of policy improvement from real-robot sample complexity paves the way for rapid, compute-driven adaptation of foundation agents, sidestepping major deployment barriers in embodied AI. The flexibility of DPO to accommodate both stochastic (flow-matching, diffusion) and deterministic policies broadens the applicability of reward-guided post-training.
Theoretically, this work highlights the importance of reward modeling as a bridge between model-based and model-free post-training strategies. Future research may focus on improved action-conditional world models for denser and less noisy feedback, as well as integration of reinforcement learning objectives with preference-based pipelines for further reliability gains.
Conclusion
NORA-1.5 introduces a scalable post-training paradigm for embodied vision-language-action agents by leveraging world model- and action-based synthetic rewards for preference-guided optimization. Empirical results provide strong evidence that this methodology yields robust policy adaptation and reliable generalization, challenging the traditional reliance on imitation learning alone and suggesting new directions for open-world and cross-embodiment robotics.