- The paper introduces the PostNAS pipeline, which optimizes full-attention placement and linear attention block selection using frozen pre-trained MLPs.
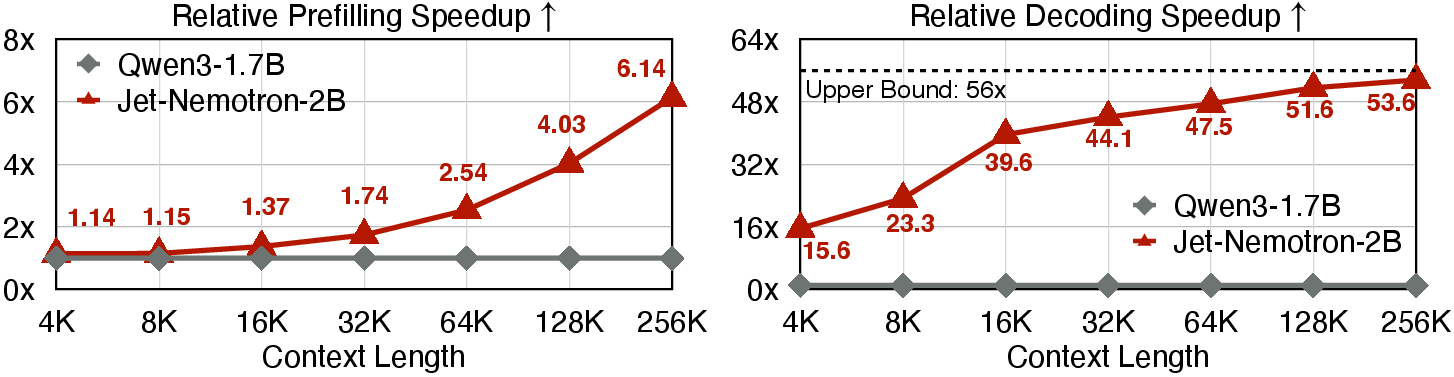
- The paper achieves substantial efficiency gains with up to 47× faster generation and a significant reduction in KV cache size for long-context tasks.
- The paper demonstrates that the novel JetBlock design, integrated within a hybrid architecture, maintains state-of-the-art accuracy across diverse benchmarks.
Jet-Nemotron: Efficient LLM with Post Neural Architecture Search
Introduction and Motivation
Jet-Nemotron introduces a new family of hybrid-architecture LLMs that achieve state-of-the-art accuracy while delivering substantial improvements in generation throughput. The central innovation is the Post Neural Architecture Search (PostNAS) pipeline, which enables efficient architecture exploration by leveraging pre-trained full-attention models and freezing their MLP weights. This approach circumvents the prohibitive cost and risk of pre-training from scratch, allowing rapid and hardware-aware adaptation of attention mechanisms.
The motivation stems from the quadratic complexity of self-attention in Transformers, which impedes efficiency, especially for long-context tasks. Prior work on linear and hybrid attention models has improved throughput but typically at the expense of accuracy on challenging benchmarks. Jet-Nemotron addresses this gap by systematically optimizing the placement and design of attention blocks, achieving both high accuracy and efficiency.
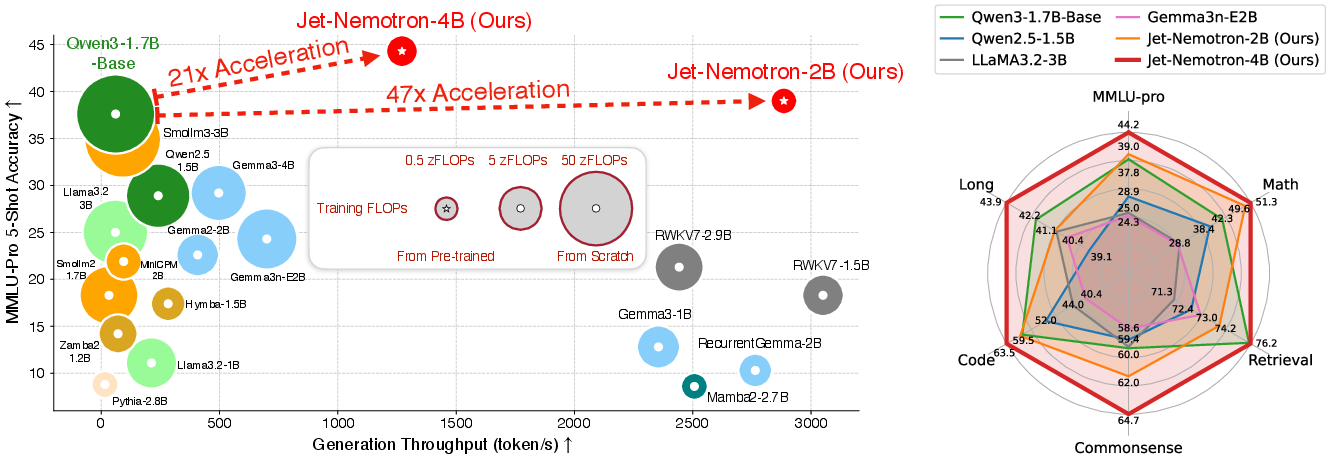
Figure 1: Jet-Nemotron models outperform state-of-the-art efficient LLMs in both accuracy and generation throughput on NVIDIA H100 GPUs at 64K context length.
PostNAS Pipeline and Architecture Search
The PostNAS pipeline comprises four key stages:
- Full Attention Placement and Elimination: Instead of uniform placement, PostNAS learns the optimal locations for full-attention layers using a once-for-all super network and beam search. This method reveals that only a small subset of layers is critical for specific tasks, and their importance varies across domains (e.g., MMLU vs. retrieval).
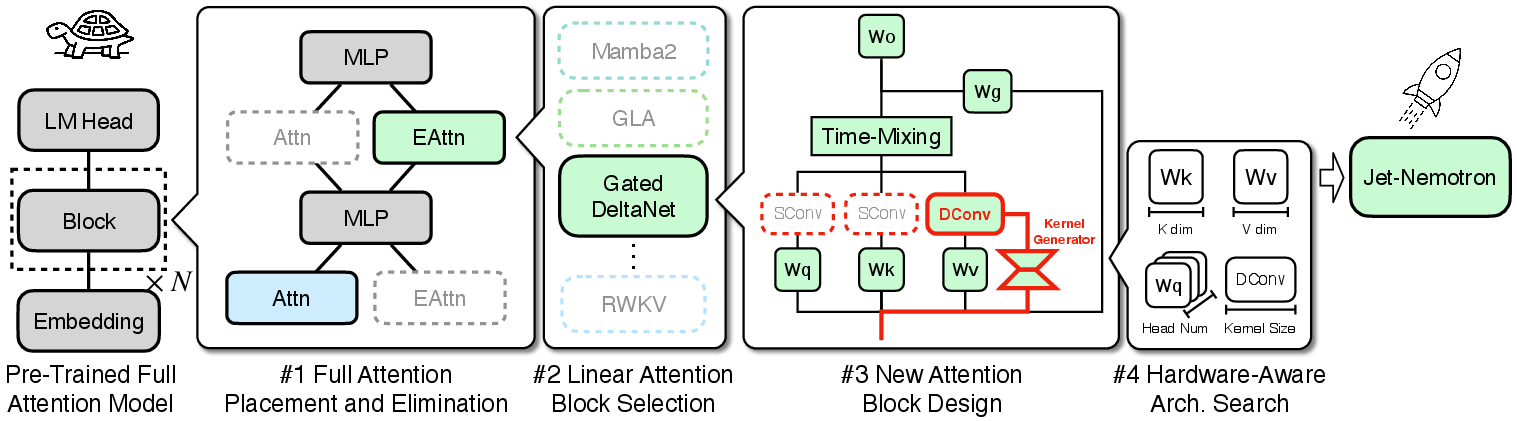
Figure 2: The PostNAS pipeline starts from a pre-trained full-attention model, freezes the MLP, and performs a coarse-to-fine search for efficient attention block designs.
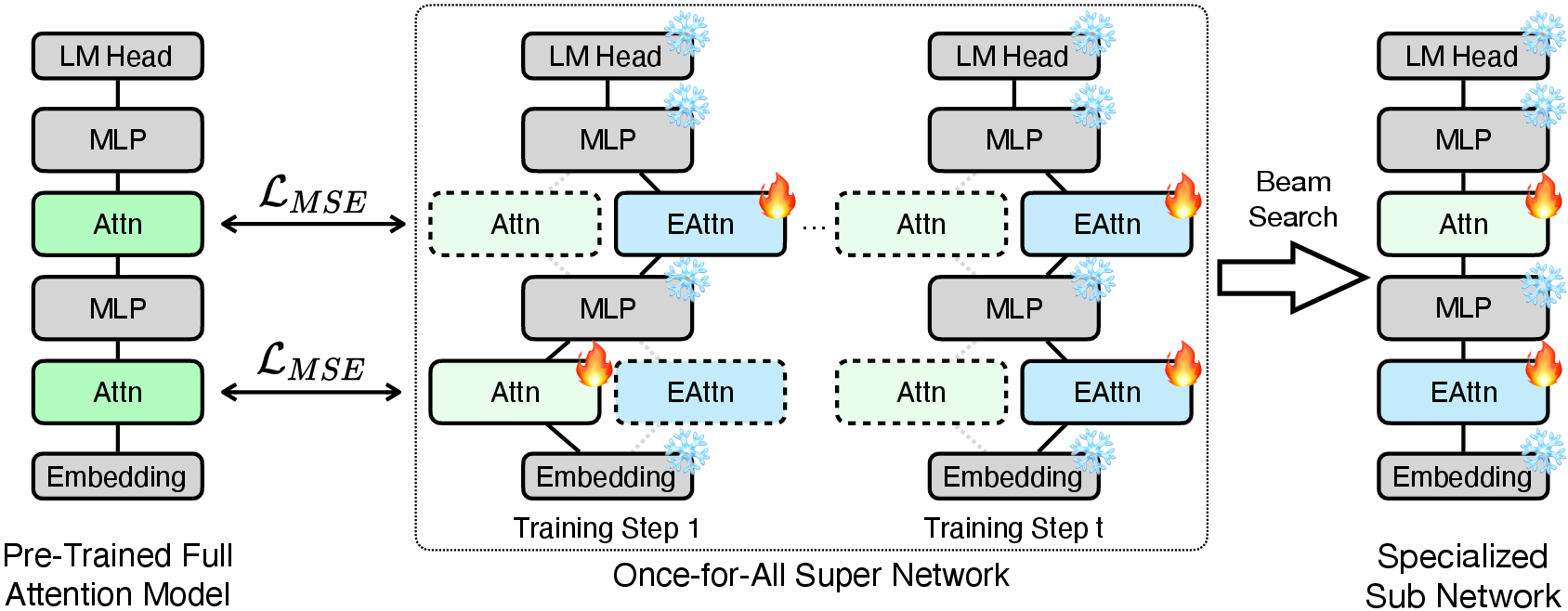
Figure 3: PostNAS trains a super network and uses beam search to identify optimal full-attention layer placement.
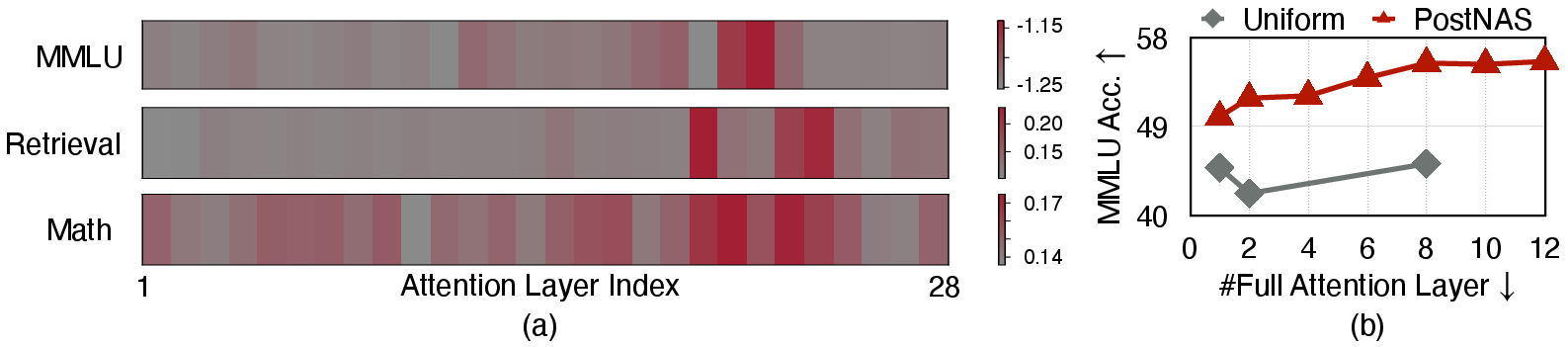
Figure 4: (a) Layer-wise search objective values for Qwen2.5-1.5B, showing non-uniform importance. (b) PostNAS placement yields higher accuracy than uniform strategies.
- Linear Attention Block Selection: PostNAS evaluates multiple state-of-the-art linear attention blocks (RWKV7, RetNet, Mamba2, GLA, Deltanet, Gated DeltaNet) in the context of the frozen MLP setup. Gated DeltaNet is selected for its superior accuracy, attributed to its data-dependent gating and delta rule mechanisms.
- New Attention Block Design (JetBlock): JetBlock introduces dynamic causal convolution kernels generated conditionally on the input, applied to the value tokens. This design removes redundant static convolutions on Q/K, streamlining computation and improving accuracy with minimal overhead.
- Hardware-Aware Architecture Search: Rather than optimizing for parameter count, PostNAS targets generation throughput directly. The key finding is that KV cache size, not parameter count, is the dominant factor for throughput, especially in long-context scenarios. By fixing cache size and searching over key/value dimensions and head numbers, Jet-Nemotron achieves higher accuracy without sacrificing efficiency.

Figure 5: PostNAS delivers significant accuracy improvements across all benchmarks compared to the baseline.
Empirical Results
Jet-Nemotron models are evaluated on a comprehensive suite of benchmarks: MMLU(-Pro), mathematical reasoning, commonsense reasoning, retrieval, coding, and long-context tasks. The results demonstrate:
Implementation and Practical Considerations
Jet-Nemotron is constructed by adapting pre-trained Qwen2.5 models, replacing most attention layers with JetBlock, and strategically retaining a small number of full-attention and sliding window attention layers. The training process involves two stages: distillation with frozen MLPs, followed by full-model training with additional high-quality data. Throughput is measured using chunk-prefilling and optimized batch sizes on H100 GPUs.
The hardware-aware search ensures that Jet-Nemotron models are not only efficient in terms of FLOPs but also optimized for real-world deployment on modern accelerators. The reduction in KV cache size enables larger batch sizes and higher parallelism, which is critical for serving long-context applications.
Theoretical and Practical Implications
Jet-Nemotron demonstrates that post-training architecture adaptation is a viable and effective strategy for advancing both efficiency and accuracy in LLMs. The findings challenge the conventional reliance on parameter count as a proxy for efficiency and highlight the importance of KV cache optimization. The dynamic convolutional design in JetBlock suggests new directions for enhancing linear attention mechanisms.
The PostNAS framework provides a rapid testbed for architectural innovation, filtering out unpromising designs before committing to expensive pre-training. This paradigm can accelerate progress in efficient model design, especially for organizations with limited computational resources.
Future Directions
Potential future developments include:
- Extending PostNAS to other model families and modalities (e.g., vision, multimodal).
- Further optimizing kernel implementations for JetBlock to improve short-context throughput.
- Exploring adaptive attention placement strategies conditioned on input or task.
- Integrating PostNAS with automated data selection and curriculum learning for even more efficient adaptation.
Conclusion
Jet-Nemotron, enabled by PostNAS and JetBlock, sets a new standard for efficient language modeling by matching or exceeding the accuracy of leading full-attention models while delivering order-of-magnitude improvements in generation throughput. The work establishes post-training architecture search as a practical and theoretically sound approach for scalable, hardware-aware model design, with broad implications for the future of efficient AI systems.