- The paper presents the Llama-Nemotron models that combine high reasoning capabilities with efficient inference performance.
- It leverages neural architecture search and FFN Fusion to optimize throughput, reduce latency, and improve memory efficiency.
- The model training pipeline integrates knowledge distillation, supervised fine-tuning, and reinforcement learning to enhance reasoning and overall performance.
Llama-Nemotron: Efficient Reasoning Models
The paper "Llama-Nemotron: Efficient Reasoning Models" (2505.00949) introduces the Llama-Nemotron (LN) family of open-source, heterogeneous reasoning models, designed for exceptional reasoning capabilities and inference efficiency. The LN family includes three sizes: Nano (8B), Super (49B), and Ultra (253B). These models demonstrate competitive performance with state-of-the-art reasoning models like DeepSeek-R1, while offering superior inference throughput and memory efficiency. The models are derived from Llama 3.1 and Llama 3.3 and support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference.
Inference Optimization via Neural Architecture Search
The LN-Super and LN-Ultra models are optimized for efficient inference using the Puzzle framework (Bercovich et al., 2024), a neural architecture search (NAS) framework that transforms LLMs into hardware-efficient variants. Puzzle applies block-wise local distillation to build a library of alternative transformer blocks. Each block is trained independently and in parallel to approximate the function of its parent block while improving computational properties such as latency, memory usage, or throughput. The block variants include attention removal and variable FFN dimensions. Once the block library is built, Puzzle assembles a complete model by selecting one block per layer, governed by a mixed-integer programming (MIP) solver that identifies the most efficient configuration under a given set of constraints.
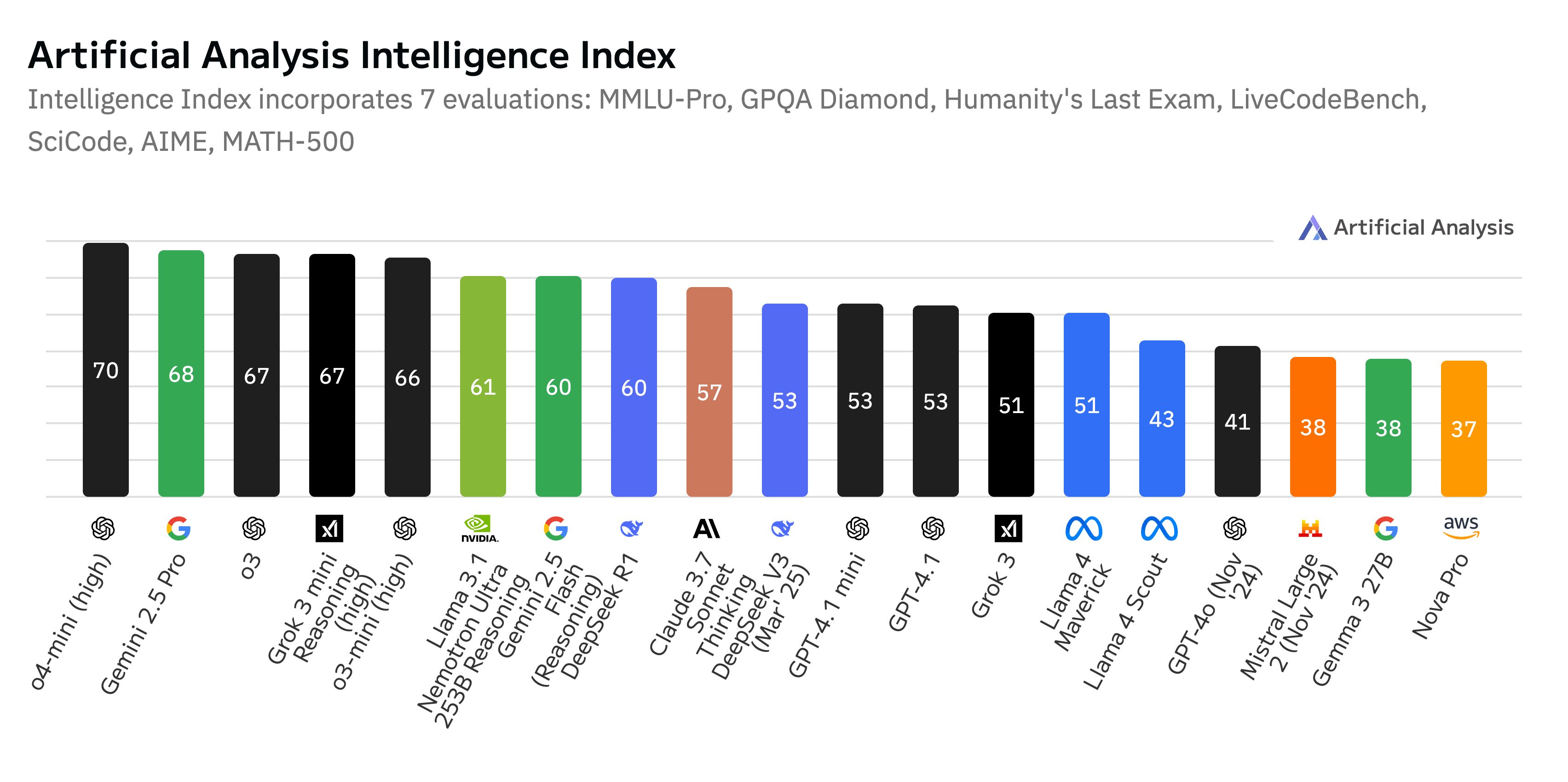
Figure 1: As of April 2025, our flagship model LN-Ultra is the most ``intelligent'' open model according to Artificial Analysis.
For the LN-Ultra model, an additional compression technique called FFN Fusion (Bercovich et al., 24 Mar 2025) is introduced to reduce sequential depth and improve inference latency. This technique identifies consecutive FFN blocks and replaces them with fewer, wider FFN layers that can be executed in parallel, reducing the number of sequential steps without compromising expressivity. LN-Super is optimized to run efficiently on a single NVIDIA H100 GPU with tensor parallelism 1 (TP1), achieving a 5× throughput speedup over Llama~3.3-70B-Instruct at batch size 256 and TP1. LN-Ultra is optimized for a full H100 node (8 GPUs) and achieves a 1.71× latency improvement over Llama~3.1-405B-Instruct.
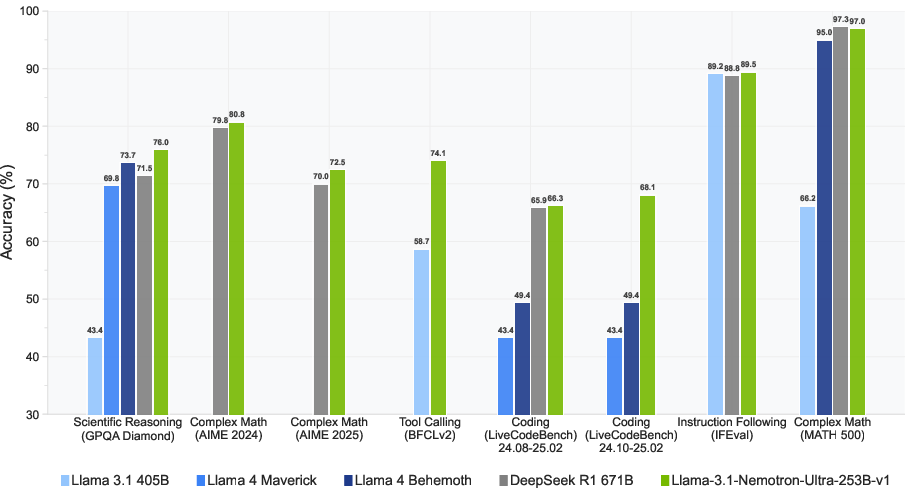
Figure 2: LN-Ultra delivers leading performance among open models across a wide range of reasoning and non-reasoning benchmarks.
Training and Data Curation
The Llama-Nemotron models are constructed in five stages: optimizing inference efficiency with neural architecture search (NAS) and FFN Fusion, recovery training with knowledge distillation and continued pretraining, supervised fine-tuning (SFT) on instruction and reasoning data, large-scale reinforcement learning, and a short alignment phase focused on instruction following and human preference. The Llama-Nemotron-Post-Training-Dataset, a carefully curated dataset used during the supervised and reinforcement learning stages of training, is also open-sourced.
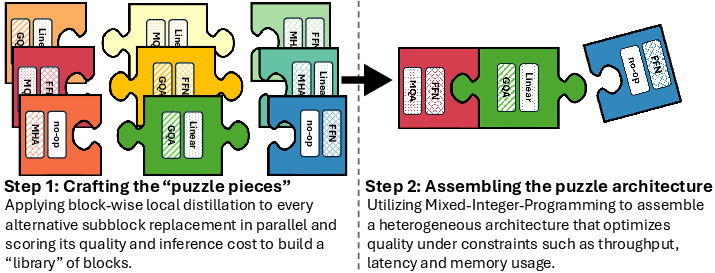
Figure 3: Overview of the Puzzle framework.
The synthetic data used for supervised fine-tuning includes both reasoning and non-reasoning data. For reasoning samples, the system instruction "detailed thinking on" is used, and for non-reasoning samples, "detailed thinking off" is used. Math reasoning data is constructed using a pipeline that collects mathematical problems from Art of Problem Solving (AoPS) community forums, extracts problems, classifies problems, extracts answers, performs benchmark decontamination, generates solutions using DeepSeek-R1 and Qwen2.5-Math-7B-Instruct, and filters solutions. The code reasoning dataset is constructed via a multi-stage process involving question collection, solution generation, and post-processing steps. The science data includes open-ended and multiple-choice questions (MCQs) from both in-house and external sources. For general domain data, the generation pipeline established in \citet{nvidia2024nemotron4340btechnicalreport} is followed. To train the model to follow the reasoning toggle instruction, paired data is constructed where each prompt has both a reasoning response and a non-reasoning response.
Supervised Fine-Tuning and Reinforcement Learning
Supervised fine-tuning (SFT) transfers reasoning capabilities into the Llama-Nemotron models by distilling reasoning behavior from strong teacher models like DeepSeek-R1. All models are trained using a token-level cross-entropy loss over the instruction-tuning data. Models require higher learning rates to effectively learn from long reasoning traces. Large-scale reinforcement learning enables the models to surpass their teachers. For LN-Ultra, the model's scientific reasoning capabilities are enhanced through reinforcement learning, leveraging the Group Relative Policy Optimization (GRPO) algorithm. Two types of rewards are used: accuracy rewards and format rewards. Curriculum training is also helpful, as it allows the model to gradually learn from a progression of tasks with increasing difficulty.
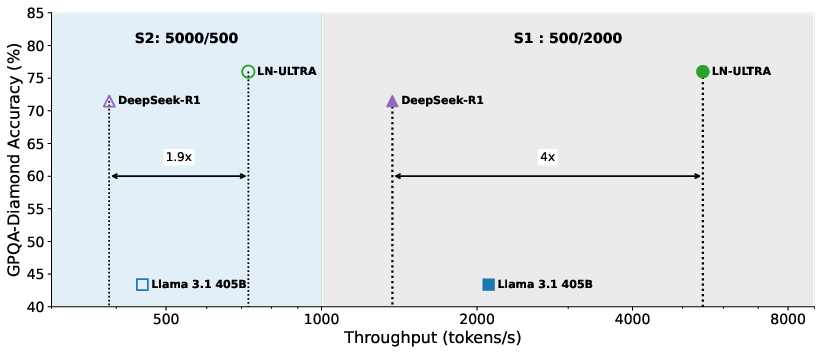
Figure 4: GPQA-Diamond Accuracy vs. Throughput. We measure on two settings, S1: 500/2000 (ISL/OSL); S2: 5000/500 (ISL/OSL). Both with 250 concurrent users. Models are served with FP8. Note that we use 8×H100 for LN-Ultra and Llama 3.1 405B, but 8×H200 for Deepseek-R1 because of its size.
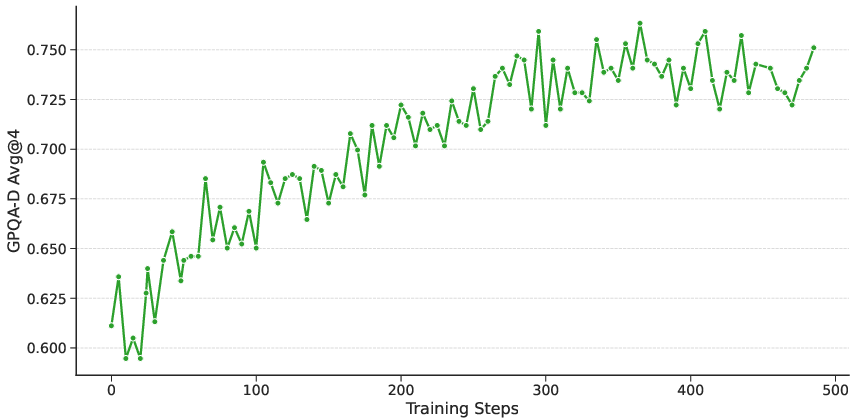
Figure 5: Accuracy on GPQA-Diamond throughout the reasoning RL training for LN-Ultra.
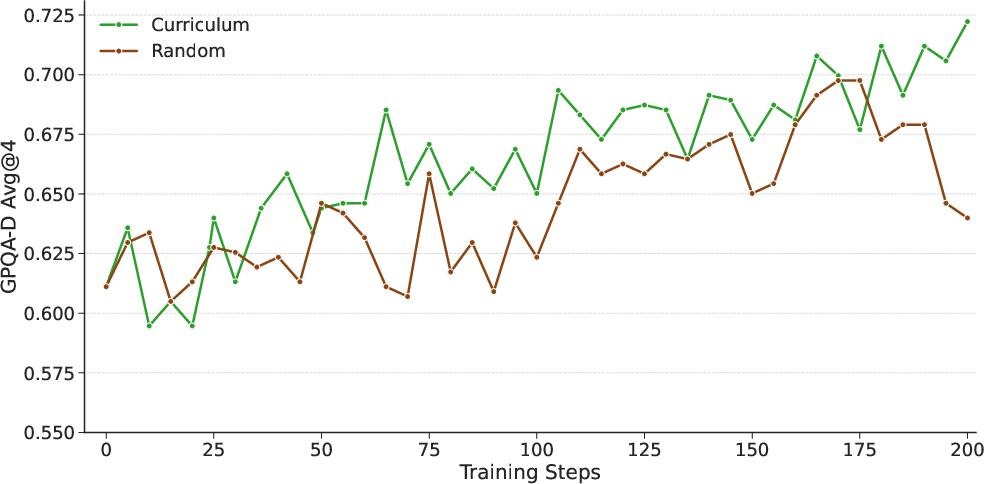
Figure 6: Ablation on curriculum vs non-curriculum.
Infrastructure and Preference Optimization
NeMo-Aligner is used to perform RL training, implementing the generation stage using vLLM and the training stage using Megatron-LM. The training and inference stages are co-located on the same GPUs. The training model parallelism used was: tensor parallel=8 with sequence parallel, context parallel=2, pipeline parallel=18, and data parallel=2. The generation model parallelism was tensor parallel=8, and data parallel=72. Weight preparation, vLLM GPU memory utilization, and GPU and CPU memory usage in the trainer are key challenges in enabling the GRPO training of the LN-Ultra. FP8 inference generation is implemented to improve performance, observing a peak FP8 generation throughput of 32 tokens/s/GPU/prompt, a 1.8x generation speedup against BF16. After training for scientific reasoning, a short RL run optimizes instruction following capabilities for the LN-Super and LN-Ultra. RLHF improves the model on general helpfulness and chat capabilities while carefully maintaining its proficiency in other areas.
Evaluations and Results
The Llama-Nemotron models are evaluated across reasoning and non-reasoning benchmarks. Reasoning benchmarks include the American Invitational Mathematics Examination (AIME), GPQA-Diamond, LiveCodeBench, and MATH500. Non-Reasoning Benchmarks include IFEval(Strict-Instruction), BFCL V2 Live, and Arena-Hard. LN-Nano achieves strong performance across all reasoning benchmarks, demonstrating the effectiveness of the SFT pipeline and curated reasoning datasets. LN-Super performs competitively across both reasoning and non-reasoning tasks and offers the strengths of both reasoning-optimized and non-reasoning models. LN-Ultra matches or outperforms all existing open-weight models across reasoning and non-reasoning benchmarks and achieves state-of-the-art performance on GPQA among open models. The models are also evaluated on JudgeBench, where the task is to differentiate between high-quality and low-quality responses. The models outperform top proprietary and open-source models.
Conclusions
The Llama-Nemotron series of models perform competitively with state-of-the-art reasoning models while having low memory requirements and efficient inference capabilities. In the presence of a strong reasoning teacher, supervised fine-tuning on high-quality synthetic data generated by such teacher is very effective in adding reasoning capabilities to smaller models. To push reasoning capabilities beyond what is possible from a teacher reasoning model alone, it is necessary to run large-scale, curriculum-driven reinforcement learning from verifiable rewards training. To produce a great all-around model, it is necessary to have several stages in the post-training pipeline.