NVIDIA Nemotron Nano V2 VL
Abstract: We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Nemotron Nano V2 VL, a smart computer model that can “see” and “read” (vision-language). It’s built to understand real-world documents (like PDFs and forms), watch and summarize long videos, answer questions about images and charts, and reason through tough problems. It improves on an older model by being faster, better at handling long inputs, and more accurate on many tests. NVIDIA also shares the model files and a large part of the training data so others can learn from and build on this work.
Key Objectives
The paper focuses on a few easy-to-understand goals:
- Make a model that accurately understands images, documents, charts, and videos.
- Help the model reason (think step by step) when needed, but also be fast when simple answers are enough.
- Handle very long inputs, like multi-page PDFs or long videos, without breaking.
- Train efficiently so the model runs quickly and doesn’t need huge computers.
- Share tools, data, and model versions to support the research community.
Methods and Approach
To keep things simple, think of the model like a team:
- The “eyes” (vision encoder) look at pictures and videos and pick out important details.
- The “translator” (MLP projector) converts what the eyes see into a language the “brain” understands.
- The “brain” (LLM) reads, thinks, and answers questions.
Here’s how they made it all work:
Model Design (how it “sees” and “thinks”)
- Images are split into “tiles” (like cutting a big picture into neat squares) to keep detail and make processing more manageable.
- Videos are turned into frames (key pictures taken regularly over time).
- Both tiles and frames are resized to a consistent size (512×512 pixels) and turned into “tokens.” Tokens are like tiny building blocks of information.
- The model reduces the number of tokens using clever compression (think: summarizing without losing the main idea), so it can work faster.
- The language part uses a hybrid “Mamba-Transformer” design. You can think of this like combining two types of thinking styles to be fast and smart at the same time.
Training in Stages (like school, with different grades)
They trained the model in several stages to teach different skills without forgetting older ones:
- Stage 0: Warm-up the “translator” so image and text information align nicely.
- Stage 1 (16K tokens): Lots of mixed training (images, videos, and text), including OCR (reading text in images), question answering, charts, and reasoning.
- Stage 2 (49K tokens): Extend “memory” to handle longer inputs and more video tasks.
- Stage 3 (49K tokens): Focus on code and text reasoning to “heal” any drop in pure text skills.
- Stage 4 (up to ~300K tokens): Train with very long documents so the model handles huge inputs.
“Context length” is like the model’s working memory—the number of tokens it can keep in mind at once. Going from 16K to 300K is like going from a short notepad to a thick binder.
Efficient Video Sampling (EVS)
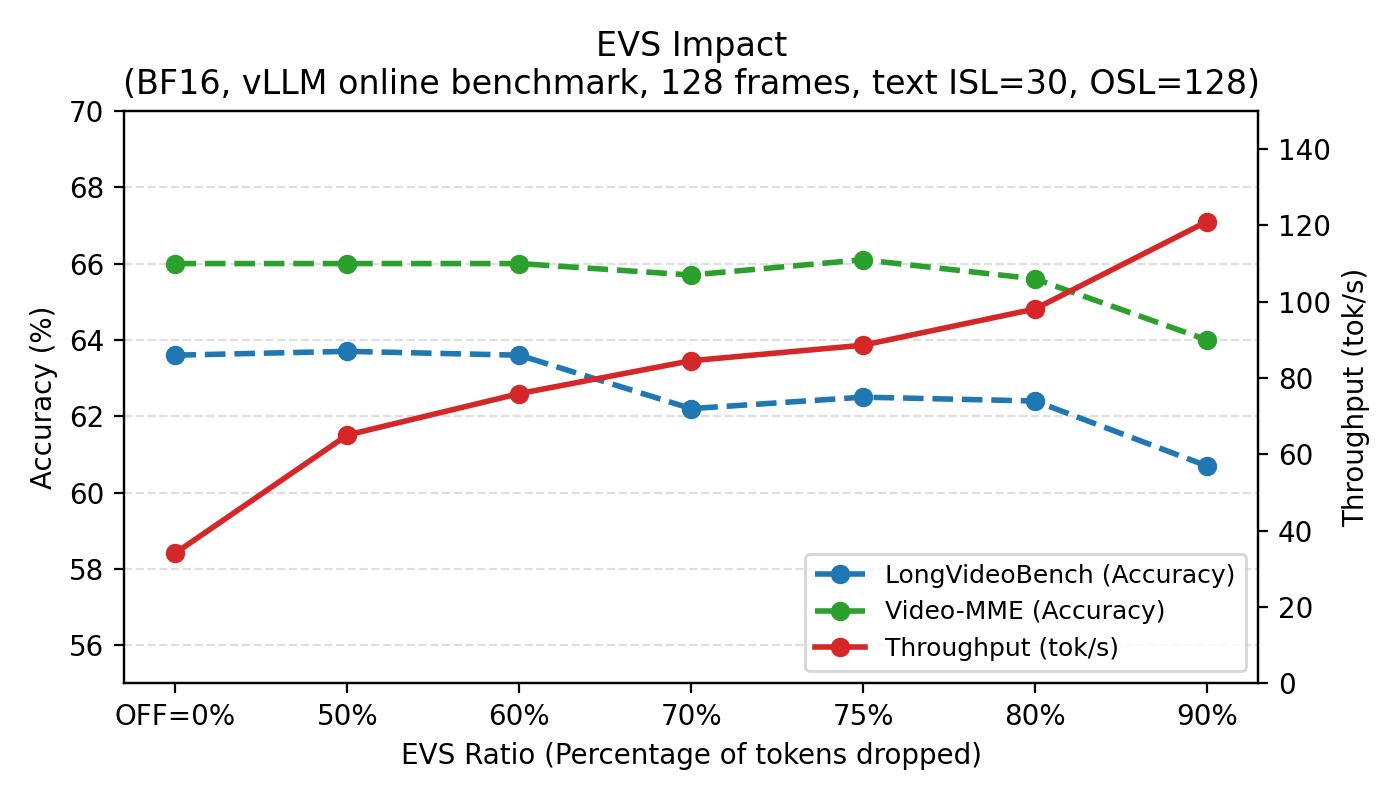
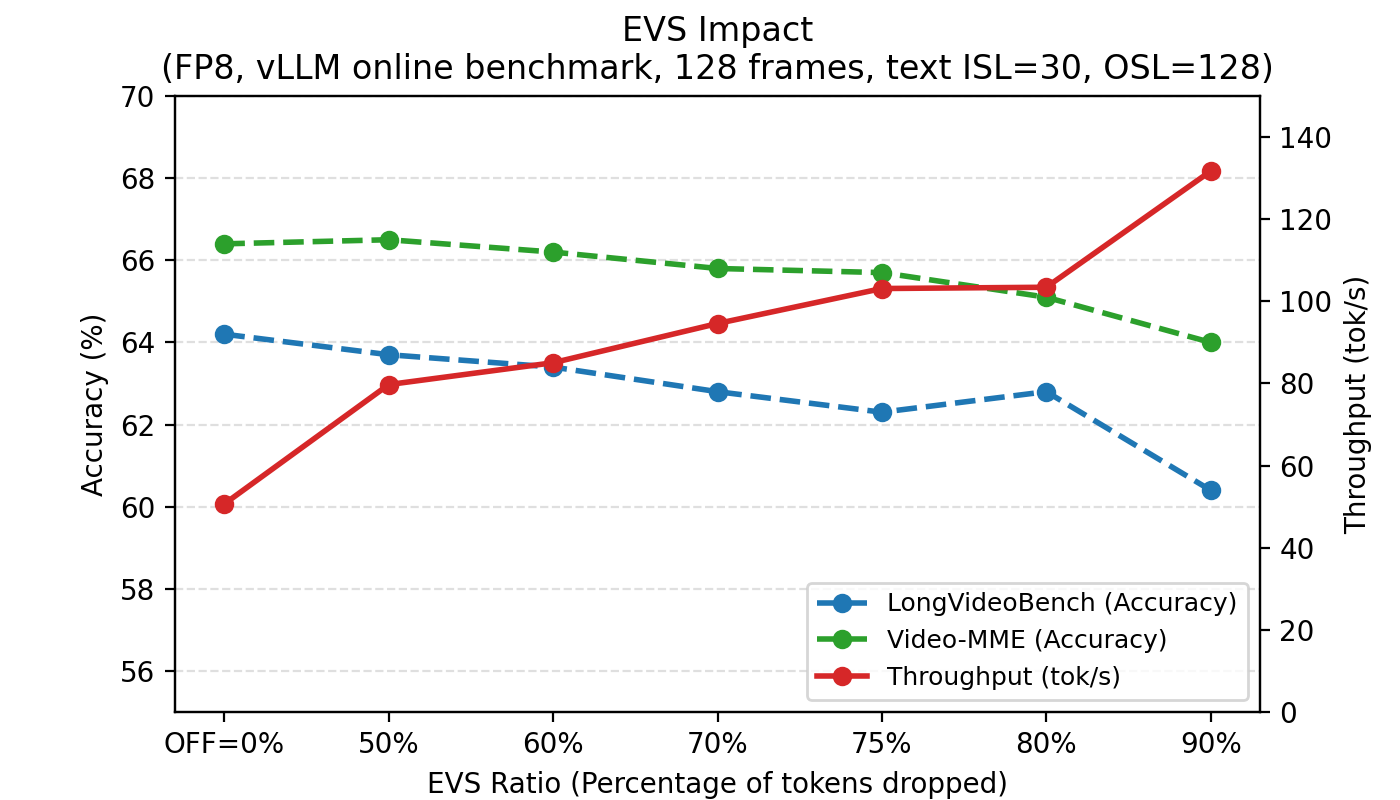
EVS is a trick to speed up video understanding. Imagine watching a video and skipping the parts where nothing changes. EVS automatically prunes repetitive patches (areas that don’t change) so the model can focus on important frames. This makes it faster with little or no loss in accuracy.
Reasoning Modes
- Reasoning-off: The model answers quickly with shorter replies—good for simple tasks.
- Reasoning-on: The model writes out its thinking steps for complex problems. You can set a “reasoning budget,” which is like a time limit to keep it from overthinking or rambling.
Running Efficiently
- They trained with FP8 precision (think: numbers stored in smaller formats to run faster), and also share versions in BF16 and FP4. Lower-precision versions use less memory and can be faster.
- “Sequence packing” is a way to fit training examples together like Tetris, wasting less space.
- “Context parallelism” splits long inputs across multiple GPUs so the model doesn’t run out of memory.
Main Findings and Why They’re Important
Here are the highlights from their tests and measurements:
- Better accuracy across many tasks: document reading (OCR), charts, general image questions, STEM reasoning, and video understanding.
- Top results on OCRBench v2 (a leading test for reading text in images) and strong performance on long-document and long-video benchmarks.
- Handles much longer inputs (up to ~300K tokens), which is essential for big PDFs and long videos.
- Faster on long documents: The new “Mamba-Transformer” setup gives about 35% higher throughput (it processes more pages per minute).
- Video speed-ups: EVS can make video understanding 2× faster or more with minimal accuracy changes.
- Text skills preserved: Even after adding vision, the extra “healing” stage recovers pure text/code abilities close to the original LLM.
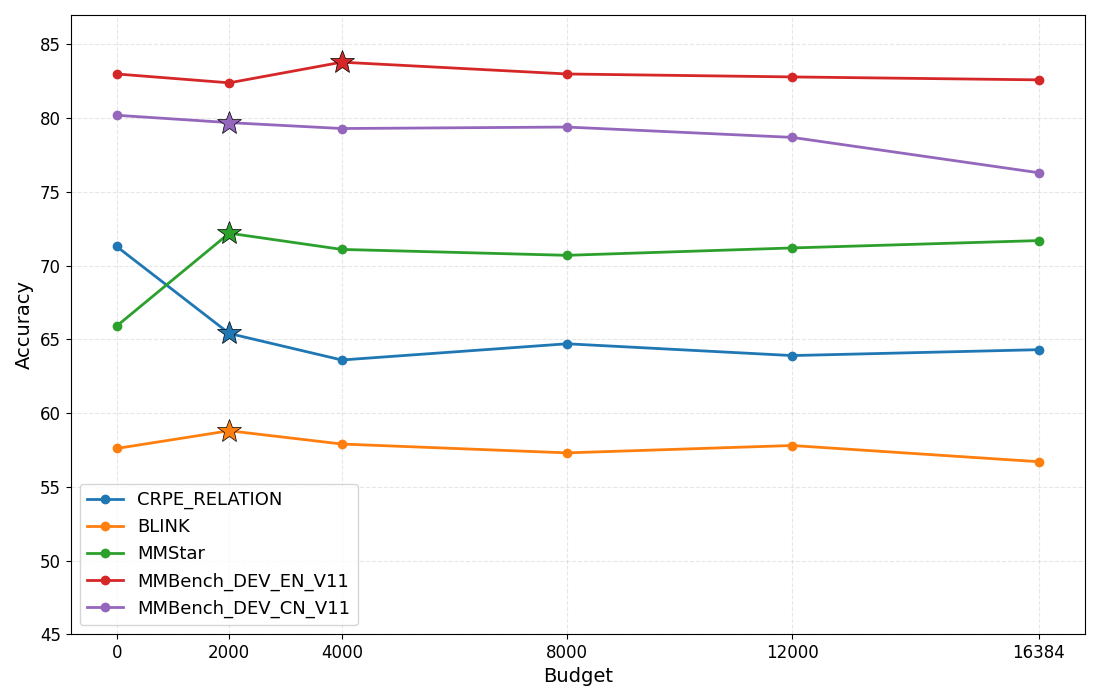
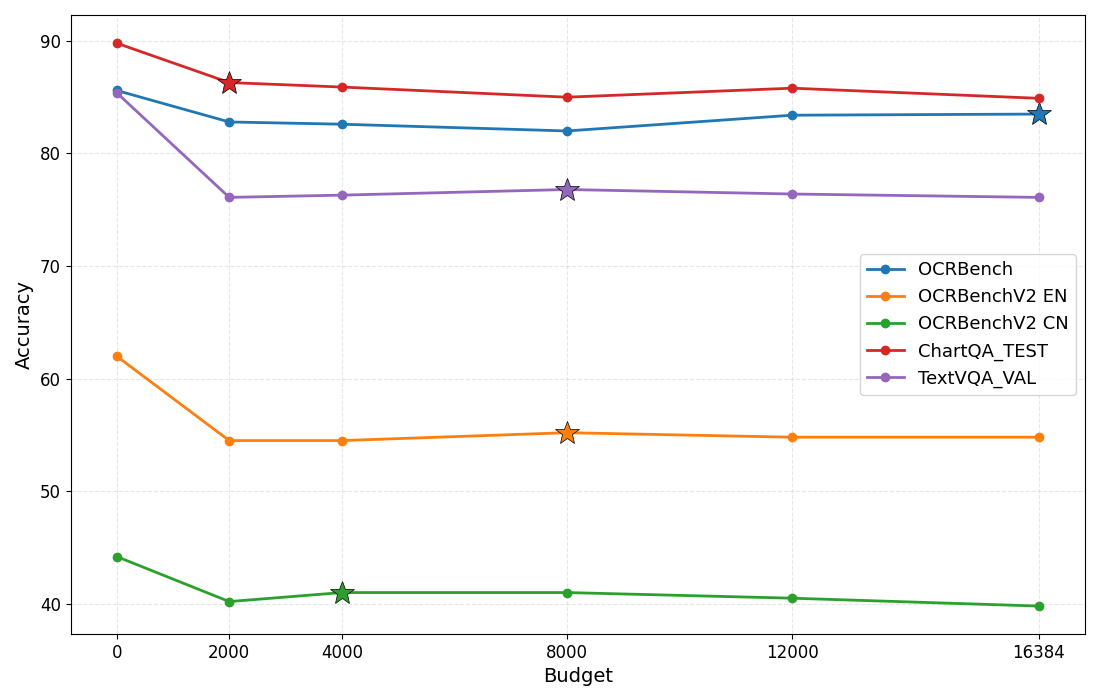
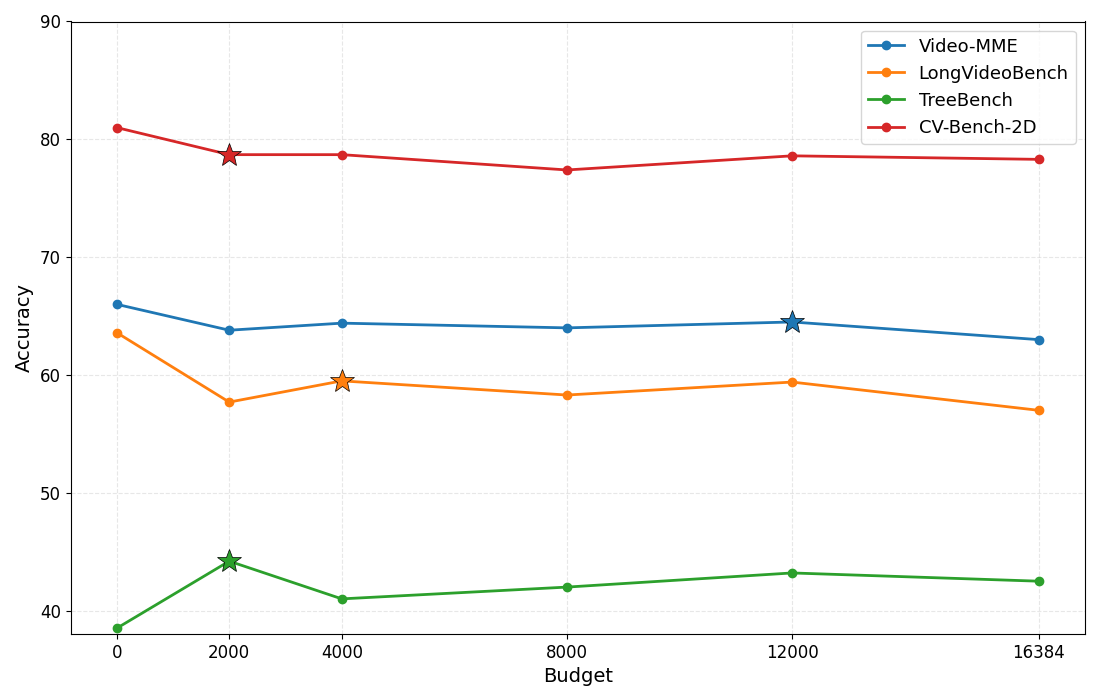
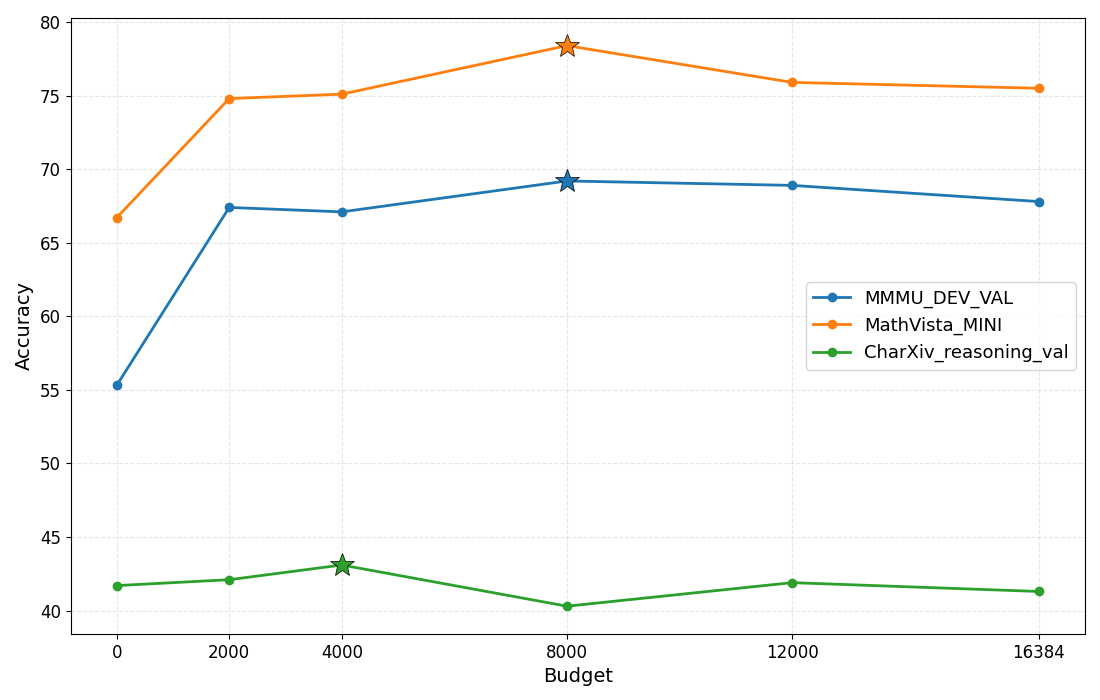
- Flexible reasoning: Setting a reasoning budget can improve results on some tasks by avoiding overly long or repetitive thinking.
Implications and Potential Impact
This research means smarter, more practical AI assistants:
- They can read and understand complex PDFs, forms, tables, and charts accurately—helpful for school, offices, and research.
- They can watch long videos and pull out important moments, saving time.
- They can handle both simple questions quickly and tough problems with detailed reasoning.
- They run more efficiently, making them easier to use on real hardware without huge costs.
- By sharing model weights, data, and tools, NVIDIA helps others build better systems, speeding up progress in AI.
In short, Nemotron Nano V2 VL is a strong step forward for AI that understands both vision and language, works well with long content, and balances speed with smart reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for follow-on research.
- Data transparency and reproducibility: exact sampling weights, mixing ratios, and packer configurations per task/domain are not fully specified; release comprehensive data recipes (per-dataset sampling probabilities, contamination filters, deduplication, language proportions, synthetic vs human-labeled splits) to enable faithful replication.
- Train–test contamination risk: no systematic analysis of benchmark overlap with the large synthetic and CommonCrawl-derived corpora; perform deduplication audits and leakage tests for each benchmark (e.g., OCRBench, ChartQA, MMLU/GPQA, LiveCodeBench).
- Safety and misuse: no multimodal safety evaluation (image/video-triggered harms, privacy leakage, jailbreak robustness) or red-teaming; establish safety benchmarks and mitigation strategies specific to VLMs (e.g., visually-conditioned prompt injection, OCR of sensitive content).
- Bias and fairness: limited analysis of demographic, cultural, and script-specific biases (beyond EN/ZH); quantify performance across non-Latin scripts (Arabic, Devanagari, Thai, etc.), low-resource languages, and RTL layouts, especially for text-centric OCR tasks.
- Function calling: trained on function-calling data but not evaluated; define reliability metrics (accuracy, argument extraction fidelity, hallucination rate) for multimodal function calling and assess on held-out tools/APIs.
- Tool use and multi-step agents: no evaluation of tool-augmented reasoning (retrieval, code execution, calculator) in multimodal settings; assess end-to-end agent performance on visually grounded tasks requiring tool invocation.
- GUI understanding and action grounding: model underperforms substantially on ScreenSpot/Pro; investigate dataset gaps (action labels, layout variability), specialized connectors (pointer/token heads), and curriculum for GUI-specific semantics.
- Reasoning-on/off routing: no automatic policy to select reasoning mode per query; develop confidence- and task-aware routing that can switch or budget reasoning dynamically without manual setting.
- Reasoning budget control: budgets help, but selection is manual and static; design adaptive budget controllers (learned or heuristic) that detect loops, verbosity, and task complexity to tune budgets per instance.
- Chain-of-thought quality: no diagnostics on malformed or repetitive traces that budget control is claimed to curb; build trace quality metrics (diversity, non-repetition, step validity) and interventions (trace pruning, verifier gating).
- Code reasoning degradation: Stage 1 SFT hurt code performance; the cause is unclear; analyze interference mechanisms (optimizer, loss scaling, gradient conflicts, token distribution drift) and test multi-objective training or separate head/adapter strategies to prevent skill erosion.
- Long-context behavior in multimodality: 300K context is evaluated mainly on text (RULER); test truly long multimodal sequences (multi-document + interleaved images/videos beyond 128 frames) to quantify retention, pointer-following, and cross-modal grounding at scale.
- Context parallelism overhead: replicating vision encoder/projector per shard increases memory/latency; explore shared encoder caching, activation checkpointing strategies, or cross-shard fusion to reduce redundancy and improve throughput.
- Hybrid Mamba–Transformer ablations: 35% throughput improvement is reported, but architectural trade-offs (accuracy vs speed, sequence scaling, cross-modal alignment) are not ablated; compare pure Transformer, pure Mamba, and hybrid variants across tasks and sequence lengths.
- Vision–language fusion: embeddings are simply interleaved; evaluate alternative fusion mechanisms (cross-attention adapters, gated fusion, deformable sampling) and their impact on grounding and reasoning.
- Tiling strategy limits: fixed tile size (s=512), max 12 tiles, and pixel-shuffle downsampling may hurt tiny text and dense layouts; study adaptive tiling/token reduction (content-aware, OCR-aware) and upper-bound tile counts for ultra-high-res documents.
- Native-resolution pipeline gap: OCRBench-V2 (EN) underperforms under native-resolution w/ tiling-size matching; diagnose failure modes (font sizes, sharpening, encoder receptive fields) and test OCR-focused token reduction (learned downsamplers, super-resolution pre-encoders).
- Token reduction impact: 2× pixel shuffle to 256 tokens per tile is a design choice; ablate reduction factors and patch sizes (8/14/16) for text-heavy vs scene-heavy tasks to balance throughput and fine-grained recognition.
- Video sampling assumptions: fixed 2 fps and ≤128 frames may be suboptimal for fast actions or very long content; investigate adaptive frame-rate and segment-aware sampling policies conditioned on motion/saliency.
- Efficient Video Sampling (EVS): accuracy/efficiency trade-offs are reported globally; analyze per-category effects (fast motion, scene cuts, text-in-video, temporal reasoning) and develop learned EVS policies that adjust pruning per video and per-query.
- Multilingual OCR: training includes Chinese OCR, but broader OCR across scripts is not evaluated; construct multilingual OCR/DocVQA benchmarks with typographic diversity (fonts, noisy scans, handwriting) and measure script-specific performance.
- Visual grounding and spatial reasoning: results on TreeBench/CV-Bench are moderate; test specialized grounding heads, region proposals, and evidence-trace training (traceable grounding supervision) to improve spatial reasoning fidelity.
- Hallucination analysis: beyond POPE/HallusionBench scores, no qualitative/causal analysis of visual hallucination modes; audit error types (object insertion, attribute confusions, text hallucinations) and evaluate mitigation via retrieval or uncertainty modeling.
- Training precision: FP8 training is claimed stable, but no failure-analysis or generalization tests across larger models or different encoders; provide gradient statistics, loss landscapes, and ablations on TE settings to generalize the recipe.
- Quantization (FP8/FP4-QAD): the section is incomplete; quantify accuracy deltas vs BF16 across all task families, memory/latency gains, and calibration requirements; measure robustness under low-light, compression, and noisy inputs in quantized deployment.
- Inference efficiency beyond EVS: no end-to-end latency/TTFT/throughput for images/multi-doc inputs under various batch sizes and contexts on common datacenter and edge GPUs; provide detailed cost profiles and guidance for deployment.
- Data quality of synthetic labels: no systematic quality assessment of LLM-generated QA pairs (ambiguity, noise rates, label drift) and their downstream impact; implement validation pipelines and selective filtering strategies.
- Stage reuse ratio: Stage 2 reuses 25% of Stage 1 data but details and ablation curves are not provided; publish sensitivity studies (5–50%) and task-specific outcomes to guide reuse decisions.
- Multi-image reasoning: interleaving is used but ordering, co-reference across images, and cross-image grounding are not evaluated; add multi-image reasoning benchmarks and ablate positional schemes and prompts.
- Instruction-following (IFEval) drop: IFEval scores decrease after SFT; analyze instruction drift and test targeted instruction-tuning (DPO/GRPO) post vision SFT to regain instruction strictness.
- Evaluation variance and settings: many scores are single-run or copied from reports; provide multi-seed evaluations, confidence intervals, and standardized decoding settings for fair cross-model comparisons.
- Licensing and governance: CommonCrawl, mBART translations, and relabeled datasets may have license or attribution constraints; clarify licensing, consent, and redistribution policies for all released data/components.
Practical Applications
Immediate Applications
The following items describe concrete ways Nemotron Nano V2 VL can be deployed today, highlighting sector relevance, likely tools/products/workflows, and key dependencies that affect feasibility.
- Document AI copilot for multi-page PDFs and scans
- Sectors: finance, legal, healthcare, insurance, logistics, government.
- What it does: Robust OCR, table/chart extraction, long-document question-answering, and citation-aware reasoning over 128K–300K tokens. Strong performance on OCRBench, DocVQA, ChartQA, InfoVQA, and MMLongBench-Doc enables accurate extraction from invoices, contracts, medical forms, and regulatory filings.
- Tools/products/workflows:
- Use the released BF16/FP8/NVFP4-QAD model weights with vLLM for inference.
- Ingestion via Nemo Retriever Parse to convert PDFs into structured content.
- Optional NVPDFTex to synthesize domain-specific annotated OCR training data for further tuning.
- Reasoning budget control to cap output verbosity and cost on routine workflows.
- Assumptions/dependencies: GPU availability (e.g., RTX 6000 / H100 recommended for high throughput), PDF parsing quality, domain adaptation may be needed for niche documents; ensure compliance/privacy pipelines.
- Automated form and invoice processing with table structure understanding
- Sectors: enterprise back-office (AP/AR), fintech, telecom, retail.
- What it does: Converts scanned forms and invoices to structured JSON/CSV with strong results on PubTables-1M, FinTabNet, TabRecSet, RDTableBench.
- Tools/products/workflows: Batch OCR → table detection/structure extraction → schema validation → function calling to downstream ERP or accounting systems.
- Assumptions/dependencies: Calibration to specific form layouts, quality of scans; function calling schema and guardrails; integrate human-in-the-loop for edge cases.
- Long-video meeting/class summarization and QA using Efficient Video Sampling (EVS)
- Sectors: enterprise collaboration, education, media analysis.
- What it does: Summarization and query-answering over hour-long videos with EVS pruning to cut latency and cost while preserving accuracy (improved TTFT and throughput with minimal accuracy impact on Video-MME/LongVideoBench).
- Tools/products/workflows: Video frame sampling at 2 FPS → EVS token pruning → multimodal QA/summarization → optional ASR integration for audio transcripts; reasoning budget control for predictable runtimes.
- Assumptions/dependencies: ASR integration needed for audio content; EVS ratio tuning per domain to balance accuracy/efficiency; GPU inference server (vLLM).
- Compliance and audit reading assistant for regulations and technical manuals
- Sectors: finance (Basel, SOX), pharma (FDA/EMA), energy (NERC), public sector.
- What it does: Reads and answers questions across long, complex regulatory PDFs and technical documentation; supports multilingual queries and reasoning-on for complex cases.
- Tools/products/workflows: Retrieval-augmented generation (RAG) over regulatory corpora → Nemotron VL inference → structured compliance checklists → function calls to governance systems.
- Assumptions/dependencies: Verified citations/grounding strategies; governance and audit logging; policy-defined reasoning budgets to control cost and verbosity.
- Business intelligence and analytics QA over charts/infographics
- Sectors: finance, energy, manufacturing, consulting.
- What it does: Answers questions and verifies values in dashboards, charts, plots, and infographics (strong ChartQA/InfoVQA/AI2D results).
- Tools/products/workflows: Chart image ingestion → chart structure parsing → QA/explanations → result caching; can augment BI tools with “Explain this chart” copilot.
- Assumptions/dependencies: Visual variability of dashboards; establish confidence thresholds before automating decisions.
- Multilingual document understanding and support
- Sectors: multinational enterprises, public sector services, localization.
- What it does: Solid results on MMMB and Multilingual MMBench (en/zh/pt/ar/tr/ru) enable cross-language document reading, form assistance, and QA.
- Tools/products/workflows: Language-aware routing → Nemotron VL inference → optional post-editing/translation; unify cross-language compliance checks.
- Assumptions/dependencies: Coverage gaps for languages beyond those evaluated; domain-specific terminology may require fine-tuning.
- STEM tutoring and assessment with visual reasoning
- Sectors: education technology, workforce upskilling.
- What it does: Visual math and STEM reasoning (MMMU, MathVista, LogicVista) for problem explanation with diagrams, lab charts, and figures.
- Tools/products/workflows: Curriculum ingestion → problem generation → step-by-step solutions with reasoning budgets → assessment rubrics.
- Assumptions/dependencies: Guardrails against hallucination, calibrated difficulty; teacher oversight for grading.
- Function calling for operational automations tied to documents and screens
- Sectors: IT service management, customer support, operations.
- What it does: Extracts structured information from documents/screens and triggers downstream actions (e.g., create a ticket, file a report) based on Glaive/xLAM function-calling data.
- Tools/products/workflows: Screen/Doc QA → function call generation → execution in ITSM/CRM via schema-validated APIs.
- Assumptions/dependencies: Clear API schemas, robust validation, access controls; additional training for GUI-heavy tasks.
- Screen understanding for assistance and annotation (non-autonomous)
- Sectors: accessibility, user training, UX research.
- What it does: Explains UI elements and provides guidance (ScreenQA/ScreenSpot), suitable for assistive overlays or documentation—not yet for full autonomous UI control.
- Tools/products/workflows: Screenshot capture → UI element grounding → help text generation → annotation export.
- Assumptions/dependencies: Current performance trails SOTA on advanced GUI grounding; domain-specific UIs may need fine-tuning.
- Dataset creation and augmentation for academic and industrial research
- Sectors: academia, ML ops, model evaluation.
- What it does: NVPDFTex generates annotated OCR ground truth; the 8M+ sample Nemotron VLM Dataset V2 supports SFT and benchmarking.
- Tools/products/workflows: Synthetic LaTeX → PDF + ground truth → training/evaluation pipelines with Megatron and Transformer Engine.
- Assumptions/dependencies: LaTeX toolchain setup; dataset licensing and provenance; compute for experimentation.
- Cost-aware inference via quantization and reasoning budgets
- Sectors: software infrastructure, cloud platforms, on-prem appliances.
- What it does: FP8/NVFP4-QAD models reduce memory/compute; reasoning budget control caps token generation for predictable cost.
- Tools/products/workflows: vLLM server deployment with FP8/FP4 weights → budget policies per endpoint → monitoring TTFT/throughput → autoscaling.
- Assumptions/dependencies: Hardware support (Transformer Engine for FP8), throughput vs accuracy trade-offs; policy enforcement to avoid silent truncation of critical content.
Long-Term Applications
These opportunities build on Nemotron Nano V2 VL’s capabilities but require further research, scaling, domain integration, or productization before broad deployment.
- Agentic RPA for GUI automation (clicks, navigation, data entry)
- Sectors: enterprise IT, BPO, finance ops.
- What it could do: Move from UI understanding to reliable action planning and execution across diverse UIs; combine screen grounding with tool-use and safety constraints.
- Dependencies/assumptions: Stronger GUI grounding (ScreenSpot-Pro-level), action safety frameworks, robust feedback loops; domain-specific training and sandboxing.
- Real-time multi-camera video analytics with EVS at scale
- Sectors: manufacturing (quality control), logistics, retail, smart cities.
- What it could do: Stream-aware EVS for temporal redundancy pruning, event detection, and long-horizon summarization across multiple feeds.
- Dependencies/assumptions: Streaming EVS integration, event ontology design, privacy compliance, hardware acceleration, potential custom connectors for edge deployments.
- Healthcare multimodal assistant (documents + charts + medical imagery)
- Sectors: healthcare providers, payers, life sciences.
- What it could do: Clinical document understanding, chart/diagram QA, and selected medical VQA (PMC-VQA, VQA-RAD) with reasoning and citation.
- Dependencies/assumptions: Regulatory approvals (HIPAA, GDPR), rigorous clinical validation, bias/fairness assessment, integration with EHR systems; likely additional training on domain data.
- Legal contract and technical manual analysis with deep cross-referencing
- Sectors: legal services, engineering, aerospace/defense.
- What it could do: Traceable reasoning across clauses, charts, schematics, and appendices in long documents; produce structured compliance/risk reports.
- Dependencies/assumptions: Verified citations with provenance, chain-of-custody logging, domain-specific ontologies; long-context caching and retrieval pipelines.
- Large-scale educational platforms with multimodal curricula
- Sectors: edtech, corporate training.
- What it could do: End-to-end course ingestion (slides, labs, videos), adaptive tutoring, multimodal assessments, and auto-generated solutions with budgeted reasoning.
- Dependencies/assumptions: Personalization, curriculum alignment, robust grading rubrics; mitigation of reasoning drift and hallucination; teacher oversight.
- Scientific literature assistant and research curation
- Sectors: R&D, academia, biotech, materials science.
- What it could do: Read and structure content from long papers (arXiv, patents) including figures, tables, and equations; produce reproducible summaries and datasets for meta-analyses.
- Dependencies/assumptions: Domain-specific math/notation support, citations and reproducibility tooling, integration with lab data systems.
- Robotics operations documentation + procedure understanding
- Sectors: industrial robotics, warehouse automation.
- What it could do: Link procedure videos (e.g., ALFRED-like tasks) and manuals to guide troubleshooting and maintenance; eventually inform high-level planning.
- Dependencies/assumptions: Action grounding and control integration; safety and verification layers; multimodal RL/fine-tuning beyond current VQA capabilities.
- Enterprise-scale multimodal knowledge management with ultra-long contexts
- Sectors: large enterprises, public sector archives.
- What it could do: Index and reason over massive document/video corpora with 300K-token sequences, context-parallelism, and retrieval orchestration.
- Dependencies/assumptions: Distributed inference with context parallelism, memory/cost management, document sharding, cache strategies; robust access controls.
- Expanded multilingual coverage and specialized chart reasoning in more languages
- Sectors: global operations, international organizations.
- What it could do: Extend high-accuracy chart/infographic QA and document understanding across additional languages and scripts.
- Dependencies/assumptions: New data curation, synthetic generation pipelines (NVPDFTex + multilingual LLMs), targeted fine-tuning and evaluation.
- Distillation and edge/mobile deployment
- Sectors: IoT, field operations, mobile productivity.
- What it could do: FP4 QAD-based slim models for on-device document capture and quick QA; hybrid on-device/offload workflows.
- Dependencies/assumptions: Hardware support for low-precision inference, performance/accuracy trade-offs, memory constraints; privacy-by-design.
- Responsible AI governance and traceable reasoning
- Sectors: regulated industries, public sector.
- What it could do: Use reasoning-on traces with budget control to create auditable decision logs and confidence signals for high-stakes workflows.
- Dependencies/assumptions: Standardized evaluation frameworks, external verification, policy-aligned logging/citation, user interfaces for audit review.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update to improve generalization in deep learning. "We use the AdamW optimizer with and set to $0.9$ and $0.999$, respectively, and a cosine annealing schedule with a linear warmup."
- Aspect ratio matching strategy: A resizing approach that preserves an image’s aspect ratio by making dimensions multiples of a chosen size before further processing. "First, each image is resized following the aspect ratio matching strategy employed by InternVL \citep{chen2024fargpt4vclosinggap} so that its width and height are multiples of ."
- Balance-aware data packing: A batching method that reduces padding while maintaining balanced coverage of varying sequence lengths during training. "We employ the balance-aware data packing strategy described in \citep{li2025eagle2buildingposttraining}."
- BF16: A bfloat16 numerical format offering a wider exponent than FP16, often used to stabilize and speed up training. "We are releasing model checkpoints in BF16, FP8, and FP4 formats"
- Context parallelism: Parallelization along the sequence dimension to enable very long context lengths without running out of memory. "Context parallelism partitions the LLM input along the sequence dimension, mitigating out-of-memory issues at longer sequence lengths."
- Cosine annealing schedule: A learning rate schedule that decays the rate following a cosine curve to improve training stability and performance. "We use the AdamW optimizer with and set to $0.9$ and $0.999$, respectively, and a cosine annealing schedule with a linear warmup."
- Convolutional token reduction: A method that uses convolutional operations to reduce the number of tokens derived from visual features. "followed by convolutional token reduction for sequence compression."
- Efficient Video Sampling (EVS): A token-reduction technique for videos that prunes temporally static patches to lower latency and memory without retraining. "Building upon Efficient Video Sampling (EVS) \citep{bagrov2025efficientvideosamplingpruning}, we integrate it directly into our video-processing pipeline."
- FP4: A 4-bit floating-point format used for aggressive model quantization to reduce memory and improve efficiency. "Quantized model weights in FP4 format using Quantization-aware Distillation (QAD)"
- FP8: An 8-bit floating-point precision format used to accelerate training and inference with minimal accuracy loss. "At all stages, the model is trained with FP8 precision following a recipe similar to \citep{nvidia2025nvidianemotronnano2} to accelerate training."
- Greedy decoding: A deterministic decoding method that selects the most probable token at each step. "For the reasoning-off mode, we employ greedy decoding and cap the maximum number of generated tokens at 1,024"
- H100 GPUs: NVIDIA data-center GPUs designed for large-scale AI training and inference workloads. "on NVIDIA H100 GPUs."
- Hybrid Mamba-Transformer architecture: A LLM design combining Mamba (state-space modeling) and Transformer components for efficiency and performance. "the hybrid Mamba-Transformer architecture of the LLM offers 35\% higher throughput in long multi-page document understanding scenarios."
- Linear warmup: A technique that gradually increases the learning rate linearly at the start of training to stabilize optimization. "We use the AdamW optimizer with and set to $0.9$ and $0.999$, respectively, and a cosine annealing schedule with a linear warmup."
- LLM backbone: The base LLM onto which additional capabilities (e.g., vision) are added via fine-tuning. "To preserve the text comprehension capabilities of the Nemotron-Nano-V2 \citep{nvidia2025nvidianemotronnano2} LLM backbone,"
- Loss square-averaging: A loss normalization technique to balance training across varying sequence lengths by averaging squared losses. "To mitigate any bias towards shorter or longer sequences during training, we employ loss square-averaging, similar to InternVL \citep{chen2025expandingperformanceboundariesopensource}."
- Long-context (benchmarks): Evaluation tasks that measure a model’s ability to handle very long input sequences. "We find that this stage helps improve the accuracy of the model in long-context benchmarks such as RULER \citep{hsieh2024rulerwhatsrealcontext}."
- Megatron Energon dataloader: A high-performance data loading library within Megatron for large-scale training. "and the Megatron Energon\footnote{\url{https://github.com/NVIDIA/Megatron-Energon} dataloader on NVIDIA H100 GPUs."
- Megatron framework: NVIDIA’s distributed training framework optimized for large Transformer-based models. "We use the open-source Megatron \citep{megatron-lm} framework to train the model in FP8 precision"
- MLP connector: A small neural network that aligns and maps vision features to the LLM space during early training. "we aim to warm up the MLP connector to establish cross-modal alignment between the language and vision domains."
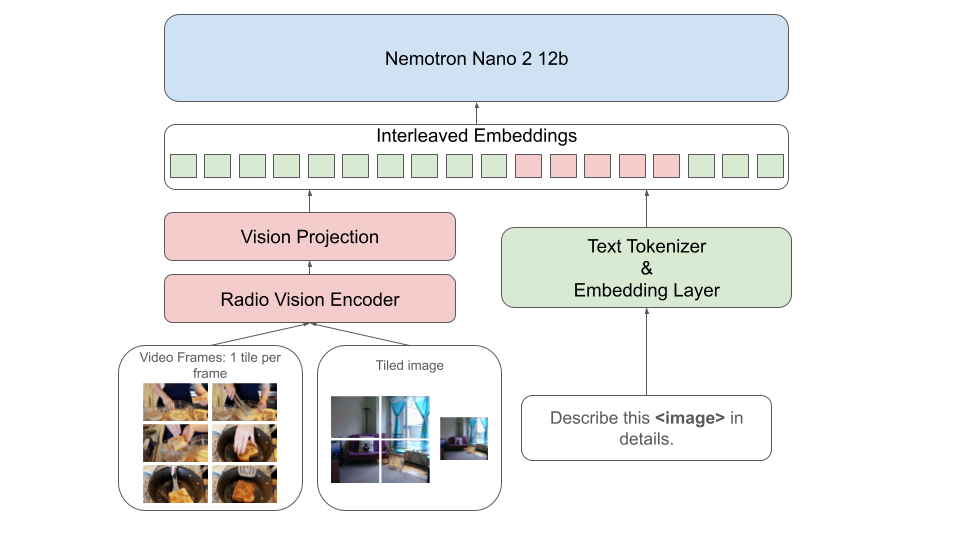
- MLP projector: A multi-layer perceptron that projects vision encoder outputs into the LLM’s embedding space. "Nemotron Nano V2 VL consists of three modules: a vision encoder, an MLP projector, and a LLM."
- Multimodal fusion architecture: A model design that combines inputs from multiple modalities (e.g., text and images) into a unified representation. "Nemotron Nano V2 VL adopts the multimodal fusion architecture, training recipe as well as data strategy similar to Eagle 2 and 2.5"
- NVFP4-QAD: NVIDIA’s FP4 quantized weight release distilled using QAD for accuracy retention at low precision. "Nemotron-Nano-12B-v2-VL-NVFP4-QAD Quantized model weights in FP4 format using Quantization-aware Distillation (QAD)"
- OCR: Optical Character Recognition; extracting text content from images or documents. "expanded OCR datasets"
- Pass@1: A metric indicating the accuracy when only the first generated attempt is considered. "We report Pass@1 average of 16 runs for AIME-2025;"
- Pixel shuffle: A sub-pixel rearrangement operation; here used to downsample visual tokens efficiently. "For scalability, we employ pixel shuffle with 2x downsampling to reduce the token count further to 256."
- Quantization-aware Distillation (QAD): A training technique that distills knowledge into a low-precision model to preserve performance. "Quantized model weights in FP4 format using Quantization-aware Distillation (QAD)"
- Quantized model weights: Model parameters stored in reduced precision formats to cut memory and boost speed. "Nemotron-Nano-12B-v2-VL-FP8: Quantized model weights in FP8 format"
- Reasoning budget control: Constraining the number of tokens allocated to chain-of-thought to balance accuracy and efficiency. "Effect of reasoning budget control at 2K, 4K, 8K, and 12K tokens across multiple tasks."
- Reasoning-off mode: Inference setting that disables extended reasoning, favoring concise outputs and lower cost. "Nemotron Nano V2 VL supports both reasoning-on and reasoning-off modes"
- Reasoning-on mode: Inference setting that enables extended reasoning traces for complex problem solving. "Nemotron Nano V2 VL supports both reasoning-on and reasoning-off modes"
- Reasoning traces: Explicit step-by-step rationales used during training or inference to guide solutions. "We augment the corpus with both human-annotated reasoning traces and model-generated traces"
- Sequence packing: Combining multiple shorter sequences into a fixed-length batch to minimize padding and speed up training. "we find that sequence packing reduces training time by minimizing the number of padding tokens required for batching."
- Supervised Finetuning (SFT): Fine-tuning a model on labeled input-output pairs to adapt it to specific tasks. "using Supervised Finetuning (SFT) across several vision and text domains"
- Temporal Action Localization: Identifying the time segments in a video where specific actions occur. "(4) Temporal Action Localization: Breakfast Actions \citep{6909500}, Perception Test \citep{pÄtrÄucean2023perceptiontestdiagnosticbenchmark}, HiREST \citep{zala2023hierarchicalvideomomentretrievalstepcaptioning}, HACS Segment \citep{zhao2019hacshumanactionclips}, FineAction \citep{liu2022fineactionfinegrainedvideodataset}, Ego4D-MQ \citep{grauman2022ego4dworld3000hours}, ActivityNet \citep{7298698};"
- Time-to-first-token (TTFT): The latency between issuing a request and the model generating its first token. "as the EVS ratio increases, time-to-first-token (TTFT) decreases and throughput rises"
- Tiling strategy: Splitting images into fixed-size tiles to handle high resolutions efficiently. "we adopt a tiling strategy to handle varying image resolutions."
- Token reduction techniques: Methods that lower the number of tokens processed to improve efficiency on long inputs. "and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios."
- Top-p: Nucleus sampling parameter that restricts sampling to the most probable tokens whose cumulative probability exceeds p. "we set the temperature to 0.6, top-p to 0.95"
- Transformer Engine: NVIDIA library for optimized mixed-precision Transformer training and inference. "using Transformer Engine\footnote{\url{https://github.com/NVIDIA/TransformerEngine}"
- vLLM: A high-throughput inference engine for LLMs enabling efficient serving. "with a vLLM \citep{kwon2023efficient}\footnote{\url{https://github.com/vllm-project/vllm} backend inference server."
- Video Temporal Grounding: Locating the precise time interval in a video that corresponds to a textual query. "(5) Video Temporal Grounding: YouCook2 \citep{zhou2017automaticlearningproceduresweb}, QuerYD \citep{oncescu2021querydvideodatasethighquality}, MedVidQA \citep{gupta2022datasetmedicalinstructionalvideo}, Ego4D-NLQ \citep{grauman2022ego4dworld3000hours}, DiDeMo \citep{hendricks2017localizingmomentsvideonatural};"
- Vision projection MLP: The projection network that maps vision encoder features into the token space used by the LLM. "The same configuration is applied to the LLM, vision encoder, and vision projection MLP, with the first and last layers of the LLM and the transformer blocks of the vision encoder kept in BF16."
- Visual tokens: Discrete token representations of visual inputs used by the LLM. "With a patch size of 16, this results in 1024 visual tokens per tile."
- VLM (Vision-LLM): A model jointly processing visual and textual inputs for multimodal understanding. "Visualization of our VLM architecture."
Collections
Sign up for free to add this paper to one or more collections.

