- The paper introduces a family of dense Transformer models ranging from 8B to 405B parameters with compute-optimal training and efficient 4D parallelism.
- The methodology leverages scaling laws, aggressive de-duplication, and targeted data annealing to optimize performance for diverse tasks including reasoning, code, and safety.
- The paper demonstrates competitive performance with state-of-the-art models through multimodal extensions, robust safety measures, and effective tool use integration.
The Llama 3 Herd of Models: Technical Summary and Implications
Model Architecture and Scaling
Llama 3 introduces a family of dense Transformer-based LLMs with parameter counts of 8B, 70B, and 405B, supporting context windows up to 128K tokens. The architecture remains close to Llama 2, with minor modifications such as grouped query attention (GQA) for improved inference efficiency, a 128K-token vocabulary for enhanced multilingual support, and an increased RoPE base frequency to facilitate long-context modeling. The flagship 405B model is trained with 3.8×1025 FLOPs, nearly 50× the compute of Llama 2's largest variant, and is positioned as compute-optimal per scaling law analysis.

Figure 1: Illustration of the overall architecture and training of Llama 3. Llama 3 is a Transformer LLM trained to predict the next token of a textual sequence.
Scaling law experiments were conducted across compute budgets from 6×1018 to 1022 FLOPs, with model sizes ranging from 40M to 16B parameters. The scaling law methodology correlates negative log-likelihood on downstream tasks with training FLOPs and then maps log-likelihood to task accuracy, enabling accurate performance forecasting for large-scale models.
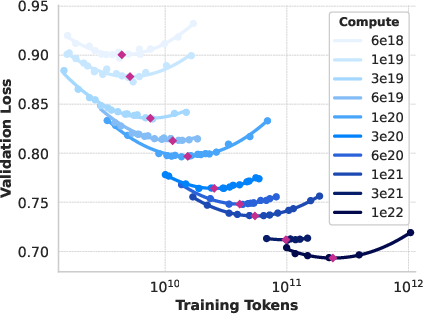
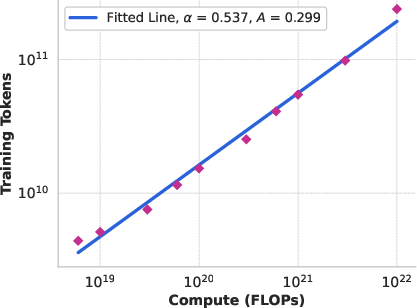
Figure 2: Scaling law IsoFLOPs curves between 6×1018 and 1022 FLOPs, used to identify compute-optimal model sizes.
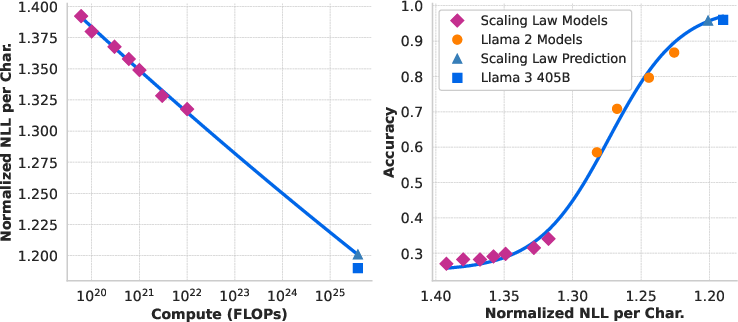
Figure 3: Scaling law forecast for ARC Challenge, showing the relationship between pre-training FLOPs, negative log-likelihood, and benchmark accuracy.
Data Curation and Pre-Training
Llama 3's pre-training corpus comprises 15T multilingual tokens, with a data mix of 50% general knowledge, 25% math/reasoning, 17% code, and 8% multilingual content. The data pipeline includes aggressive de-duplication at URL, document, and line levels, heuristic and model-based quality filtering, and domain-specific extraction for code and reasoning data. Annealing strategies are employed to upsample high-quality code and math data in later training stages, yielding significant performance gains for smaller models but negligible improvements for the 405B model, indicating strong in-context learning at scale.
Infrastructure and Parallelism
Training the 405B model required up to 16K H100 GPUs on Meta's production clusters, leveraging a three-layer Clos RoCE network topology with 400 Gbps interconnects. The model employs 4D parallelism—tensor, pipeline, context, and fully sharded data parallelism (FSDP)—to efficiently shard computation and memory across the cluster.
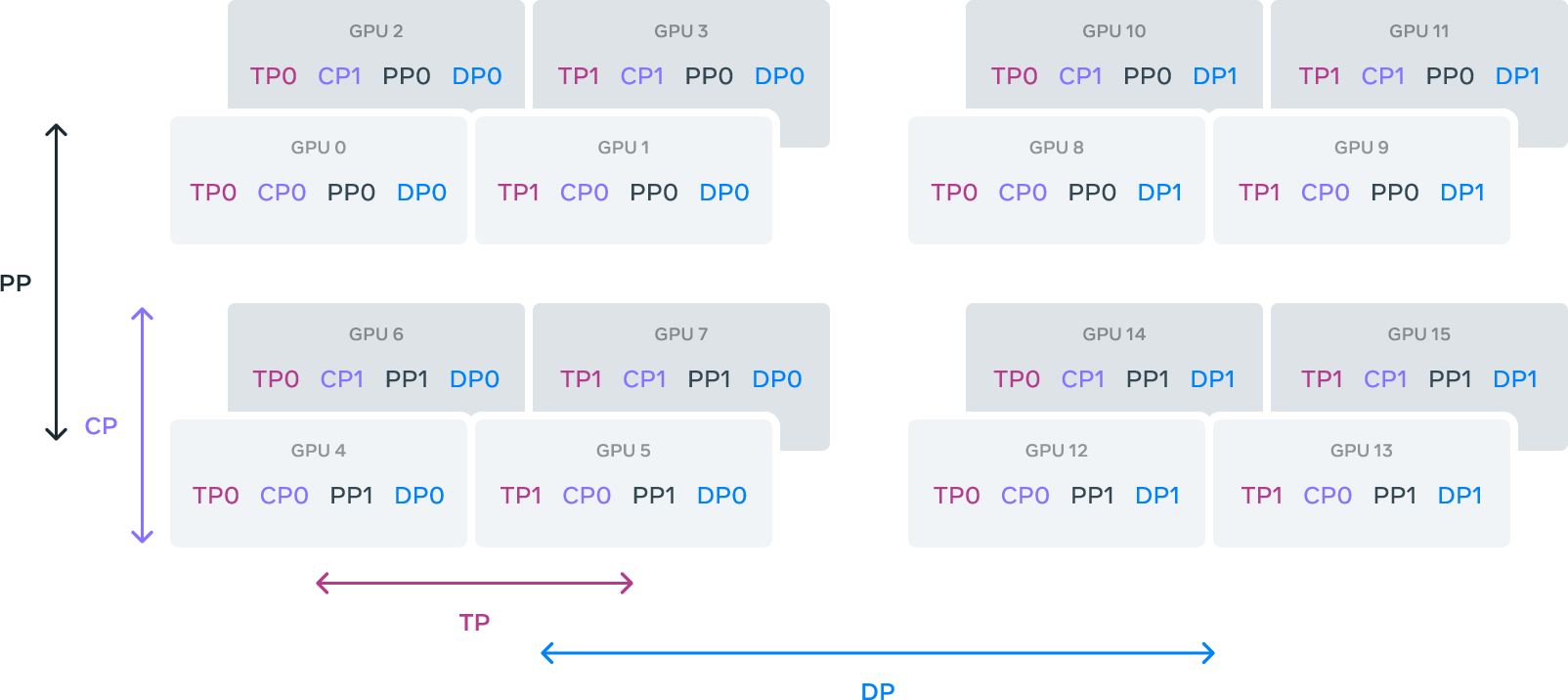
Figure 4: Illustration of 4D parallelism, showing the organization of GPUs into tensor, context, pipeline, and data parallel groups.
Pipeline parallelism is enhanced with tunable micro-batching and interleaved scheduling to address memory and computation imbalances, enabling efficient training without activation checkpointing for 8K-token sequences.

Figure 5: Illustration of pipeline parallelism in Llama 3, with tunable micro-batch scheduling for improved efficiency.
Post-Training and Alignment
Post-training consists of supervised finetuning (SFT), rejection sampling (RS), and direct preference optimization (DPO), iterated over six rounds. The process is supported by a reward model trained on human-annotated preference data, with additional data curation for code, multilinguality, reasoning, long context, tool use, and steerability. DPO is preferred over PPO for stability and efficiency at scale, with modifications such as masking formatting tokens and regularization with NLL loss.
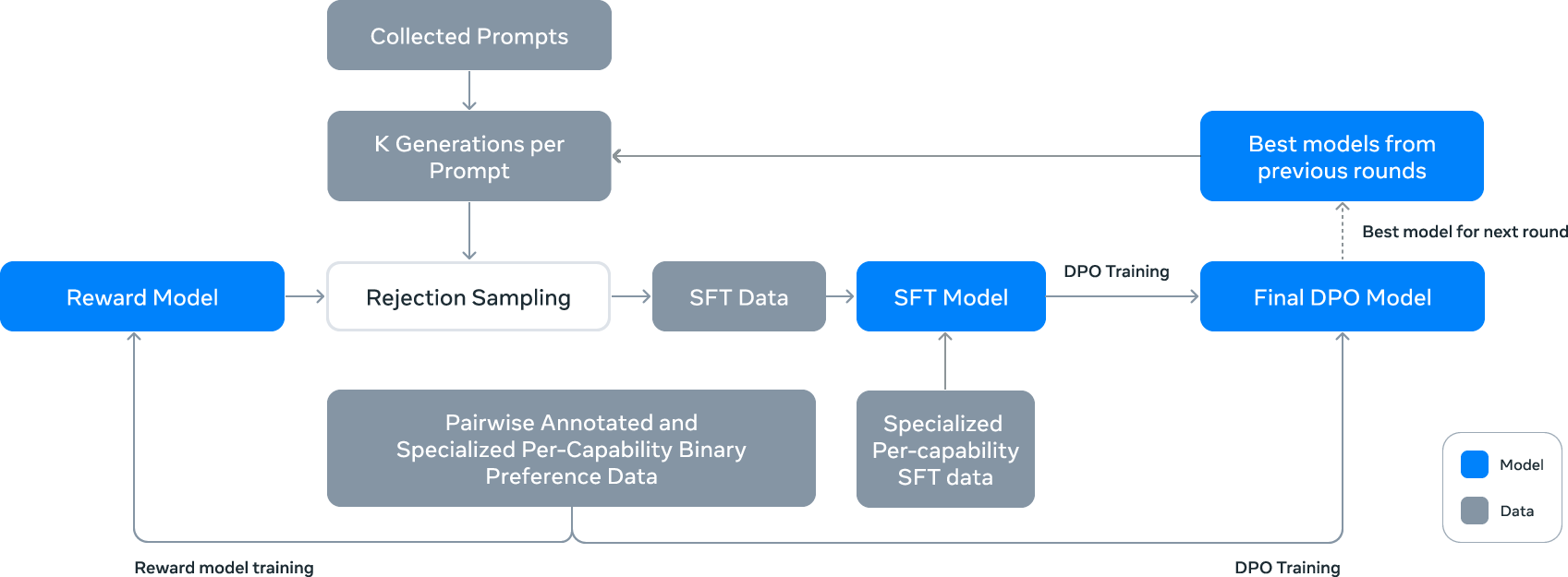
Figure 6: Illustration of the overall post-training approach for Llama 3, involving rejection sampling, supervised finetuning, and direct preference optimization.
Multimodal Extensions
Llama 3 explores compositional integration of image, video, and speech modalities via adapters and pre-trained encoders. The vision module uses a ViT-H/14 encoder with cross-attention adapters, while the video module aggregates temporal features with perceiver resamplers. The speech interface employs a Conformer encoder and adapter, supporting ASR, AST, and spoken dialogue in 34 languages. These multimodal models are not yet publicly released but demonstrate competitive performance on image, video, and speech benchmarks.
Llama 3 natively supports tool use, including search engines, code interpreters, and mathematical engines, with both single-step and multi-step planning and execution.

Figure 7: Multi-step tool usage. Example of Llama 3 performing multi-step planning, reasoning, and tool calling to solve a task.
Llama 3 405B achieves parity with GPT-4 and Claude 3.5 Sonnet on a wide range of benchmarks, including MMLU, MATH, HumanEval, and ARC Challenge. The 8B and 70B models are best-in-class for their size. Robustness analyses show minimal sensitivity to prompt format, label order, and answer permutations, especially for the 405B model. Contamination analysis indicates that, while some benchmarks are affected by training data overlap, the impact is generally limited.
Safety and System-Level Guardrails
Safety is addressed at both model and system levels. Pre-training data is filtered for PII and unsafe content, and post-training includes adversarial and borderline prompts to balance violation and false refusal rates. Llama Guard 3, an 8B-parameter classifier, is released for input/output filtering across 13 harm categories, with quantized variants for efficient deployment. Red teaming and uplift studies for cybersecurity and CBRNE risks show no significant increase in risk compared to web search.
Inference Optimization
Inference for the 405B model is enabled via pipeline parallelism across 16 GPUs and FP8 quantization for feedforward layers, yielding up to 50% throughput improvement with negligible impact on output quality. Micro-batching further enhances throughput-latency trade-offs.
Implications and Future Directions
Llama 3 demonstrates that scaling dense Transformer models with high-quality, diverse data and robust infrastructure yields models competitive with the best closed-source systems. The compositional approach to multimodality allows for modular extension without degrading text-only performance. The open release of pre-trained and post-trained models, including safety classifiers, provides a strong foundation for research and deployment in both academic and industrial settings.
Theoretical implications include the validation of scaling laws for both loss and downstream task accuracy, the effectiveness of compositional multimodal integration, and the diminishing returns of domain-specific annealing at extreme scale. Practically, Llama 3 sets a new standard for open models in multilinguality, code, reasoning, tool use, and safety, with robust infrastructure and deployment strategies.
Future work will likely focus on further scaling, more efficient architectures (potentially revisiting MoE or sparse models), improved multimodal integration, and enhanced system-level safety. The compositional adapter paradigm may become the default for extending LLMs to new modalities and capabilities. The open release strategy is expected to accelerate progress toward more general and robust AI systems.
Conclusion
Llama 3 establishes a new benchmark for open foundation models, combining scale, data quality, and engineering simplicity to deliver state-of-the-art performance across language, code, reasoning, and emerging multimodal tasks. The model's robust safety mitigations, infrastructure optimizations, and open release position it as a central resource for the research community and industry, with significant implications for the development and deployment of future AI systems.