- The paper introduces Nemotron Nano 2, a hybrid Mamba-Transformer model that achieves state-of-the-art reasoning and throughput.
- It employs a sparse self-attention pattern with only ~8% of layers using self-attention, combined with aggressive pruning and distillation techniques.
- The model demonstrates strong performance in math, code, and multilingual benchmarks while enabling 128k context inference on commodity GPUs.
Model Architecture and Pretraining
Nemotron Nano 2 is a hybrid Mamba-Transformer LLM, leveraging the Nemotron-H architecture with a sparse self-attention pattern: only ~8% of layers are self-attention, evenly distributed, while the majority are Mamba-2 layers and FFNs. The base model, Nemotron-Nano-12B-v2-Base, comprises 62 layers (6 self-attention, 28 FFN, 28 Mamba-2), with a hidden size of 5120 and FFN dimension of 20480. Grouped-Query Attention is used for efficient KV cache scaling, and squared ReLU activation is adopted for FFNs. The model omits position embeddings, uses RMSNorm, and is trained without dropout or bias weights.
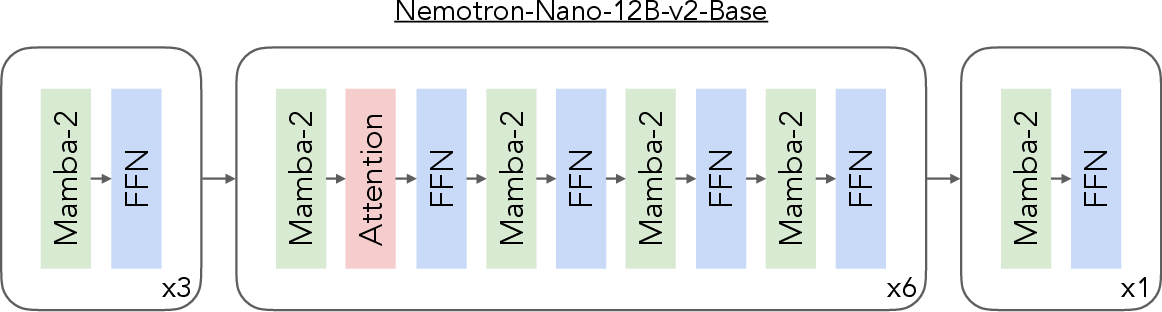
Figure 1: Layer pattern of Nemotron-Nano-12B-v2-Base, showing sparse self-attention distribution.
Pretraining is performed on 20T tokens using FP8 numerics (E4M3 for tensors, BF16 for first/last matmuls, FP32 optimizer state), with a WSD learning rate schedule. The data blend is highly curated and synthetic, spanning web crawl (Nemotron-CC), math (Nemotron-CC-Math), code (GitHub, license-filtered), academic, multilingual, and SFT-style data. Notably, the math pipeline preserves LaTeX and code structure, outperforming prior datasets. Synthetic data generation is extensive, including STEM, math dialogues (MIND), multilingual QA, code QA, and academic QA, with rigorous deduplication and quality filtering.
Curriculum learning is applied: Phase 1 promotes diversity, Phases 2/3 emphasize high-quality sources (e.g., Wikipedia). Long-context capability is instilled via continuous pretraining at 512k sequence length, with synthetic long-document QA data, enabling robust 128k context inference.
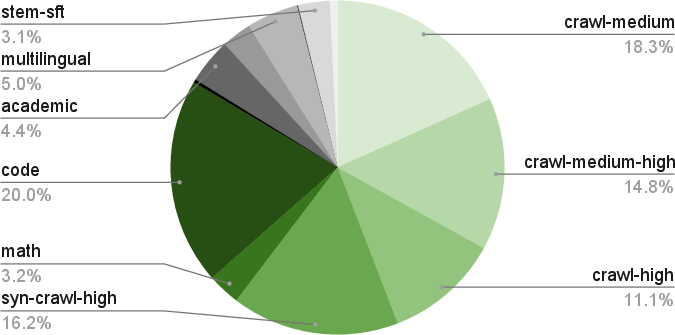
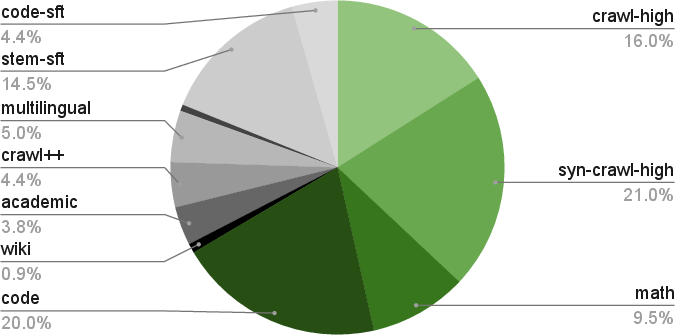
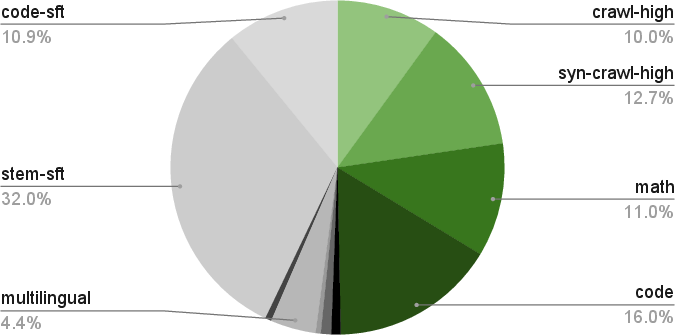
Figure 2: Data mixture composition for Phase 1 of pretraining.
Alignment and Post-Training
Alignment is a multi-stage pipeline: three SFT stages (general, tool-calling, long-context/truncated reasoning), followed by DPO (tool-calling), GRPO (instruction-following), RLHF (chat/helpfulness), and checkpoint interpolation for trade-off balancing. SFT data covers math, code, science, tool use, conversational, safety, and multilingual domains, with targeted augmentation for tool-calling and long-context robustness. DPO and GRPO are critical for function-calling and instruction-following, while RLHF improves chat alignment but may degrade multi-task performance, which is recovered via model merging.
Budget control is implemented by allowing users to specify the number of "thinking" tokens before the final answer. Truncation training ensures well-formed outputs and prevents compensation effects in the final answer when the reasoning trace is restricted.
Pruning, Distillation, and Compression
To enable 128k context inference on a single A10G GPU (22 GiB), Nemotron Nano 2 employs aggressive pruning and distillation, extending the Minitron framework. Importance estimation is performed via forward-pass MSE for layers, activation-based scoring for FFN neurons and embedding channels, and group-aware activation scoring for Mamba heads. Layer pruning is iterative, removing those with minimal impact on logits. FFN and embedding pruning follow Minitron's aggregation strategies. Mamba head pruning is group-aware, but for modest compression ratios (<15%), FFN/embedding pruning suffices.
A lightweight NAS framework enumerates candidate architectures under a strict memory budget (19.66 GiB for weights + KV cache). Depth is fixed at 56 layers (4 attention), with width pruning along embedding, FFN, and Mamba axes. Candidates are distilled for 19B tokens, and throughput/accuracy are benchmarked. The selected architecture (56 layers, 4480 hidden, 15680 FFN, 128 Mamba heads, ~8.9B params) achieves the best accuracy-throughput trade-off.
Distillation is staged: depth pruning + KD (60B tokens), width pruning + KD (50B tokens @ 8k, 25B @ 49k, 1B @ 262k), DPO, GRPO, RLHF, and model merging. Reasoning model distillation uses a 70/30 blend of post-training and pretraining data for optimal math accuracy. The base model is distilled with 100% pretraining data.
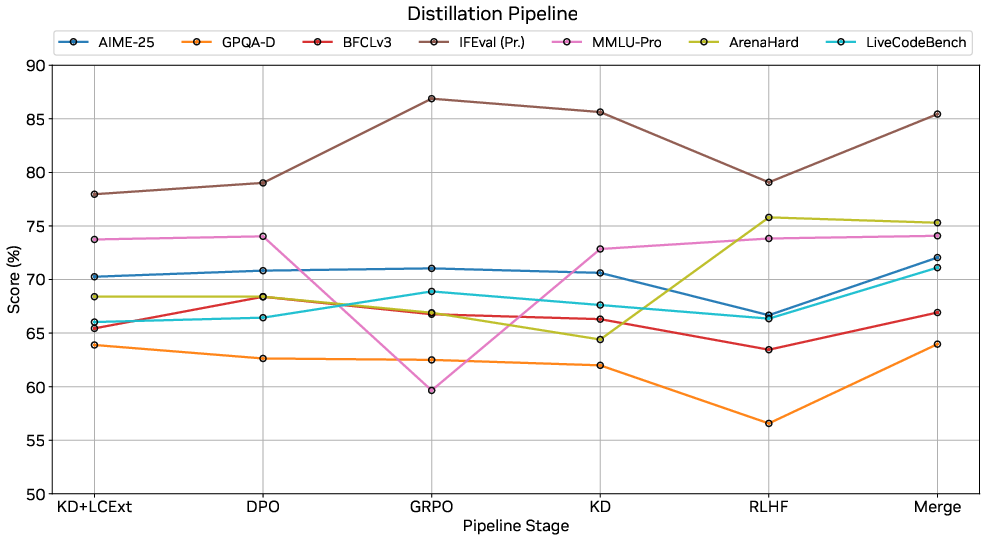
Figure 3: Task accuracy progression across distillation pipeline stages for Nemotron Nano 2.
Evaluation and Results
Nemotron Nano 2 achieves strong results across reasoning, code, math, multilingual, and long-context benchmarks. On MMLU, MMLU-Pro, AGIEval, GSM8K, MATH, AIME, HumanEval+, MBPP+, ARC, HellaSwag, OpenBookQA, PIQA, WinoGrande, and RULER-128k, the model matches or surpasses Qwen3-8B and Gemma3-12B, with especially pronounced gains in math (MATH: 80.5 vs. Qwen3-8B's 55.4) and long-context (RULER-128k: 82.22 vs. Gemma3-12B's 80.7).
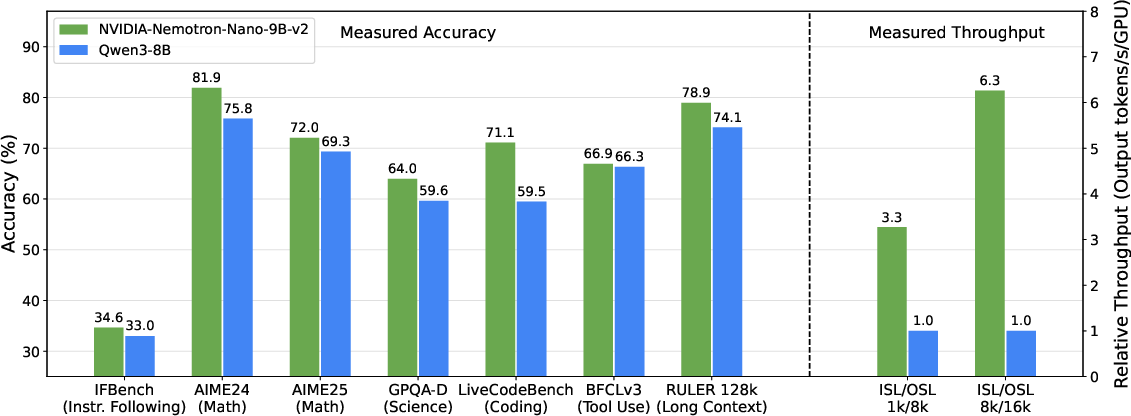
Figure 4: Nemotron Nano 2 vs. Qwen3-8B: comparable or superior accuracy, up to 6.3× higher throughput for complex reasoning workloads.
Throughput is a key differentiator: Nemotron Nano 2 achieves 3–6× higher output token generation rates for generation-heavy scenarios (e.g., 8k input/16k output), with efficient memory scaling enabling 128k context inference on commodity hardware.
Multilingual performance is robust, with Global-MMLU-Lite and MGSM scores exceeding Qwen3-8B and Gemma3-12B in most languages. Ablation studies confirm the efficacy of synthetic DiverseQA-crawl data and fundamental reasoning SFT-style data for boosting multilingual and reasoning accuracy.
Implementation and Practical Considerations
Nemotron Nano 2 is open-sourced, with checkpoints for the 9B-v2 aligned/pruned model, 9B-v2 base, and 12B-v2 base, plus the majority of pre- and post-training datasets. The model is optimized for vLLM and TensorRT-LLM inference, with FP8/BF16 support and memory-aware architecture. The pruning/distillation pipeline is modular, enabling adaptation to other hardware or context length constraints.
For deployment, the model supports explicit budget control for reasoning traces, robust long-context handling, and efficient tool-calling. The architecture is well-suited for reasoning-intensive applications (e.g., math, code, multi-step tool use) and multilingual scenarios. The open datasets facilitate further research in data-centric LLM training.
Implications and Future Directions
Nemotron Nano 2 demonstrates that hybrid Mamba-Transformer architectures, combined with aggressive pruning/distillation and data-centric training, can deliver state-of-the-art reasoning accuracy and throughput on modest hardware. The sparse attention pattern and FP8 numerics are effective for scaling context length and reducing inference cost. The alignment pipeline, with multi-stage SFT, DPO, GRPO, RLHF, and model merging, provides a template for robust instruction-following and tool use.
Future work may explore further compression (e.g., quantization, more aggressive head pruning), extension to multimodal reasoning, and integration with agentic tool-calling frameworks. The open release of models and data will catalyze research in efficient, high-accuracy LLMs for real-world reasoning tasks.
Conclusion
Nemotron Nano 2 sets a new standard for efficient, accurate, and long-context reasoning in open-source LLMs. Its hybrid architecture, data-centric training, and advanced compression strategies enable high-throughput inference and strong benchmark performance, with practical deployment on commodity GPUs. The model and datasets provide a valuable resource for the community, supporting further advances in scalable, robust language modeling.

