Feedforward 3D Editing via Text-Steerable Image-to-3D
Abstract: Recent progress in image-to-3D has opened up immense possibilities for design, AR/VR, and robotics. However, to use AI-generated 3D assets in real applications, a critical requirement is the capability to edit them easily. We present a feedforward method, Steer3D, to add text steerability to image-to-3D models, which enables editing of generated 3D assets with language. Our approach is inspired by ControlNet, which we adapt to image-to-3D generation to enable text steering directly in a forward pass. We build a scalable data engine for automatic data generation, and develop a two-stage training recipe based on flow-matching training and Direct Preference Optimization (DPO). Compared to competing methods, Steer3D more faithfully follows the language instruction and maintains better consistency with the original 3D asset, while being 2.4x to 28.5x faster. Steer3D demonstrates that it is possible to add a new modality (text) to steer the generation of pretrained image-to-3D generative models with 100k data. Project website: https://glab-caltech.github.io/steer3d/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Steer3D, a way to quickly edit 3D objects using plain text instructions. Imagine you have a 3D model of a chair made from a single photo, and you want to “add a red cushion” or “remove the armrests.” Steer3D lets you do that in seconds, while keeping the chair’s original style and shape consistent.
What questions did the researchers ask?
- Can we make existing “image-to-3D” generators accept text instructions like “add,” “remove,” or “change color,” and produce edited 3D models in one fast pass?
- Can we train this editing ability without collecting a huge, hard-to-get dataset of manually edited 3D models?
- Will the edited results follow the text well and still look like the original object, just changed where asked?
How did they do it?
Key idea: Add a “steering wheel” to a 3D generator
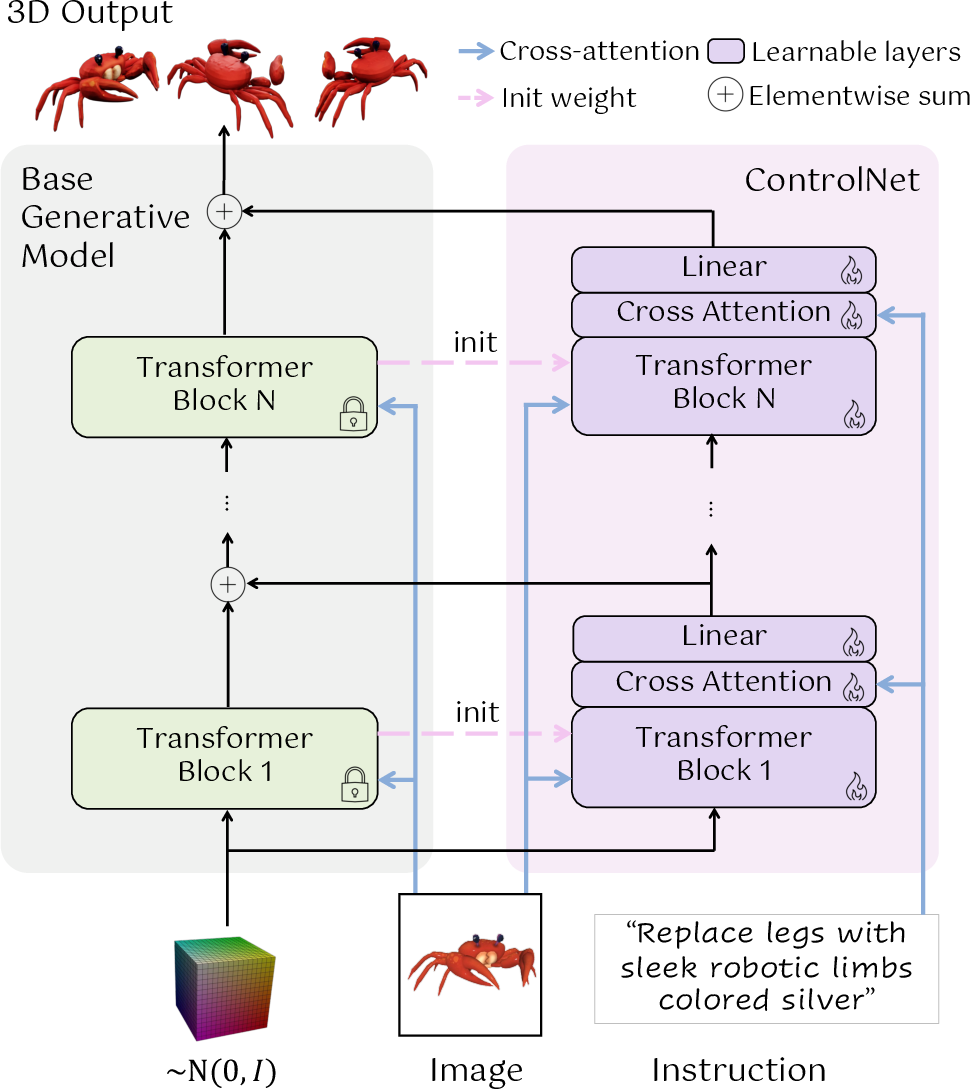
- Many AI models can turn one image into a 3D object (the base model). Steer3D adds a special branch, inspired by ControlNet, that reads your text instruction and gently “nudges” the base model’s internal steps toward the requested edit. Think of the base model as a self-driving car that already knows the road (how to make 3D). The new branch is a co-pilot who reads your request and slightly turns the wheel at each step to get the exact change you want.
- The base model stays frozen (unchanged), and the new steering branch learns how to guide it. At the start, the steering adds “zero” change so the output matches the original. Training teaches it when and how to change things.
Getting training data automatically
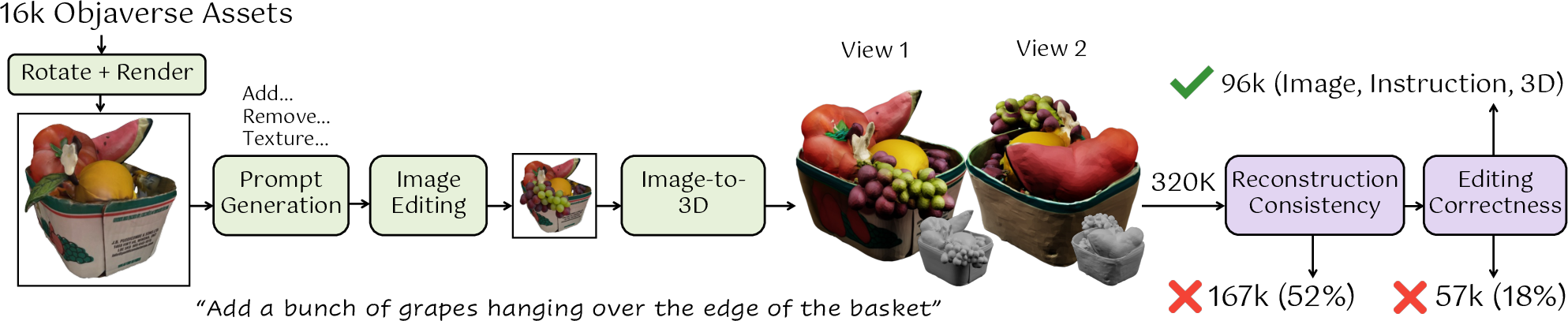
- Instead of asking humans to make thousands of paired “before and after” 3D edits, they built a data engine:
- Pick a 3D object from a big online collection (Objaverse), render one view (like a snapshot).
- Ask an AI LLM to propose many realistic edit ideas (e.g., “add a sticker,” “remove the lid,” “paint it blue”).
- Use a strong 2D image editor to edit the snapshot and then lift that edited image back to 3D with an image-to-3D model.
- Filter out bad or inconsistent results using AI checks and image-similarity scores.
- This process created about 96,000 good training pairs covering texture changes (color/pattern) and geometry changes (add/remove parts).
Training the model in two stages
- Stage 1: “Flow matching” supervised training. In simple terms, this teaches the model the right direction to move from a rough guess to the correct edited result at each step.
- Stage 2: Direct Preference Optimization (DPO). Sometimes models play it safe and do nothing (the “no edit” mistake). DPO tells the model to prefer the edited result over the original by treating the edited version as the “good” example and the unedited one as the “bad” example. This reduces “no edit” failures.
A new benchmark to measure editing
- They also built Edit3D-Bench: a collection of 250 objects with 250 edit instructions and ground-truth edited 3D results. This lets researchers measure:
- Shape accuracy (Chamfer Distance lower is better; F1 score higher is better).
- Visual similarity across multiple views (LPIPS lower is better).
What did they find, and why is it important?
- Steer3D follows text instructions better than other methods and keeps the original object consistent (only changing what you asked).
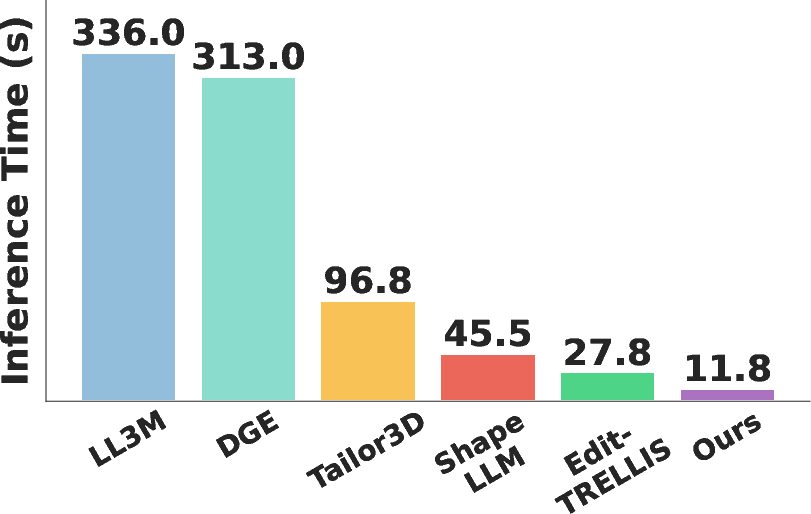
- It’s fast: about 2.4× to 28.5× faster than competing methods, with total inference around seconds.
- It beats other approaches on key metrics:
- Geometry edits (add/remove): up to 63% lower shape error (Chamfer), and up to 64% higher shape match (F1).
- Texture edits (color/pattern): around 43% lower LPIPS (meaning visuals are closer to the ground truth), while keeping the shape stable.
- It can edit parts not visible in the input photo (because it works in true 3D), where 2D-editing pipelines often fail.
- Ablation tests show:
- DPO reduces “no edit” mistakes.
- The ControlNet-style steering and data filtering both significantly improve results.
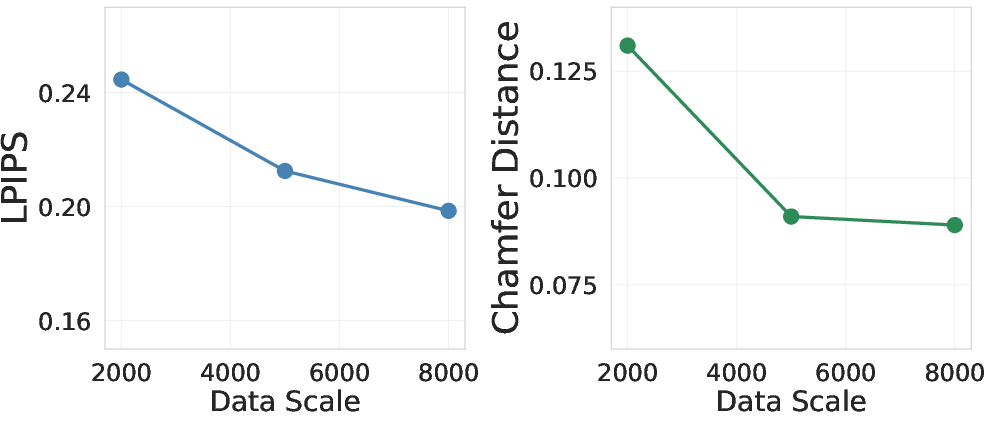
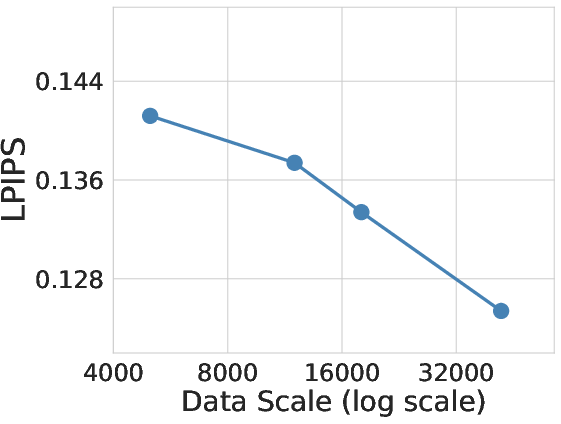
- More data steadily improves performance.
- Limitations: very complex instructions can still cause partial edits, small leaks (changing more than asked), or inconsistencies on untouched parts.
What does this mean for the future?
- Easier 3D editing: Designers, game artists, AR/VR creators, and robotics teams can quickly customize 3D assets with simple text, speeding up workflows.
- Smarter generative models: The paper shows a general recipe for adding a new “control” modality (text) to a pretrained generator without massive manual datasets.
- Better evaluations: The new benchmark (Edit3D-Bench) helps the community measure progress fairly and consistently.
- A foundation to build on: As base models and data engines improve, Steer3D’s approach can enable broader, more accurate 3D editing across many object types and tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open research directions highlighted or implied by the paper. Each item is concrete so future work can act on it.
- Dataset coverage and bias: The synthetic pairs are produced via single-view 2D edits and single-image 3D reconstruction (Step1X-Edit + Hunyuan3D), which may bias training toward edits that 2D editors and single-view I2-3D can handle; multi-view or 3D-native edited pairs are not explored.
- Data engine transparency and reproducibility: Key filtering thresholds (e.g., DreamSim, voxel MAE) and prompt templates for GPT-4.1-mini are not precisely reported; replicating the dataset and controlling label noise remains difficult.
- Label noise quantification: The pipeline acknowledges filtering out ~70% of raw pairs but does not quantify residual noise in the remaining 96k pairs or its impact on training and evaluation.
- Edit types beyond addition/removal/texture: The method and benchmark do not cover deformations, articulations, part reshaping, pose changes, topology edits (e.g., boolean ops), material/BRDF changes, or lighting edits—limiting general edit coverage.
- Fine-grained localization metrics: There is no quantitative measure of edit localization (e.g., IoU of edited regions, leakiness into unedited parts); failure modes are shown qualitatively but not systematically measured.
- Consistency with pre-edit asset: While “consistency” is a core claim, the paper lacks metrics that isolate preservation of unedited regions (e.g., per-part geometry/texture consistency scores relative to the pre-edit asset).
- Benchmark generality: Edit3D-Bench is derived from the same data engine, risking distribution coupling; an independent, third-party benchmark with richer edit taxonomies and multi-view ground truth would better test generalization.
- Real-world robustness: Quantitative evaluation on in-the-wild photos (occlusions, cluttered backgrounds, lighting variation) is absent; domain shift to consumer capture or CAD-like assets is not characterized.
- Scenes and multi-object editing: The approach is evaluated on single objects; extension to scene-level edits (multiple objects, context-aware operations, spatial constraints) is not addressed.
- Chained edits: Behavior under repeated or sequential edits (editing an already edited asset) is not studied, including potential drift or compounding errors.
- Optional spatial guidance: The model avoids masks or 3D boxes, yet complex edits show leakage and partial edits; the impact of optional spatial constraints (2D masks, 3D boxes, part selections) on localization and reliability is unexplored.
- Control strength calibration: Users lack a principled “edit intensity” knob; the paper does not study how to control magnitude and spatial extent of edits or calibrate text-guidance strength.
- Text understanding limits: The dataset uses brief LLM-generated instructions; handling long, compositional, or conditional instructions (e.g., “paint stripes except the inner cup, and thicken only the handle”) is not evaluated.
- Multilingual prompts: Text-steering is tested in English only; cross-lingual performance and robustness to colloquialisms or domain-specific jargon are not explored.
- DPO design and theory: The DPO adaptation to flow matching reduces “no-edit” failures, but its hyperparameters, stability region, and theoretical trade-offs (e.g., over-penalization, hard-negative selection) are not analyzed.
- Negative samples variety: DPO negatives are limited to the “original generation”; the benefit of harder or diverse negatives (e.g., wrong edits or partial leaks) is not studied.
- Geometry-vs-texture decoupling: Training separate models for geometry addition vs removal and a separate texture model increases complexity; unifying geometry edit types and joint geometry–texture training remains an open design question.
- ControlNet integration ablations: The paper adds a ControlNet block to every transformer layer but does not ablate the number/placement of control blocks, alternative conditioning (FiLM, LoRA, cross-attn injection), or partial base-model finetuning.
- Base-model dependence: Results are tied to TRELLIS (64³ occupancy coarse geometry + latent decoder); it is unclear how Steer3D performs with different base architectures, higher-resolution geometry, or unified latent backbones (e.g., UniLat3D).
- Classifier-Free Guidance (CFG) stability: CFG is disabled for geometry due to instability; alternative guidance schedules or loss reweighting to enable stable CFG for geometry are not investigated.
- Edit generalization: “Unseen assets” are reported, but detailed analysis across categories (rare shapes, thin structures, high-frequency textures) and edit complexity is missing.
- Output variability: The claim that edits vary little across noise seeds is qualitative; no variance metrics (e.g., dispersion of edited part geometry or texture) are reported.
- Representation-agnostic evaluation: Converting Gaussians/NeRFs to meshes and aligning with ICP may distort evaluation; volumetric or radiance-field metrics and alignment-free measures are not considered.
- Speed–quality trade-offs: Steer3D’s 11.8s is reported without a systematic quality–time curve or matched-time comparisons to baselines; performance on consumer GPUs and memory footprints are not documented.
- Physical plausibility: Structural integrity and material realism after geometry additions/removals (e.g., support, thickness) are not assessed; physics-aware constraints are an open direction.
- Safety and misuse: The paper does not discuss prompt safety, adversarial edits, or misuse risks (e.g., deceptive asset alterations), nor mechanisms to detect/limit harmful edits.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Steer3D’s feedforward, text-steerable image-to-3D editing, its speed improvements (2.4×–28.5× faster), and Edit3D-Bench for evaluation.
- Bold: Interactive asset editing in DCC tools — Sectors: software, gaming, VFX, media
- Description: Designers and artists can type edits like “add a leather strap,” “make the body matte black,” or “remove the logo” to instantly generate consistent 3D variants of existing assets, accelerating concept iteration and review cycles.
- Potential tools/workflows: Steer3D plugins for Blender/Maya/Unreal/Unity; a “text-to-variant” REST API; asset library batch variant generation pipelines; glTF/USD exports.
- Assumptions/dependencies: Availability of a base image-to-3D model (e.g., TRELLIS) and GPU inference; asset IP and licensing checks; mesh/texture export compatibility; quality gates for production assets.
- Bold: E-commerce product variant generation and AR try-on — Sectors: retail, marketing, advertising
- Description: Quickly generate 3D product variants (colorways, decals, minor component additions/removals) for catalog imagery, AR viewers, and A/B tests while preserving original geometry.
- Potential tools/workflows: Web service integrated into Three.js/Babylon.js viewers; batch pipelines for variant catalogs; brand compliance review tools using LPIPS/Chamfer/F1 thresholds.
- Assumptions/dependencies: Rights to modify branded designs; consistent exports to web formats (glTF/USDZ); QC to avoid geometry drift; human-in-the-loop approvals.
- Bold: Robotics simulation domain randomization — Sectors: robotics, autonomous systems
- Description: Rapidly add obstacles, modify textures, or remove distractors to create scenario breadth for training and evaluation of perception/manipulation systems.
- Potential tools/workflows: Integration with Isaac Sim/Unity/Unreal simulation stacks; scripted batch-edit of props; automatic dataset generation of “before/after” scenes.
- Assumptions/dependencies: Current model edits per-object; scene-level assembly tooling needed to place edited assets; physics and material properties not guaranteed.
- Bold: Synthetic data augmentation for 2D/3D vision — Sectors: academia, automotive, embodied AI
- Description: Generate controlled “pre-/post-edit” pairs to study robustness to local changes (texture-only vs. geometry addition/removal); produce labeled variations for training.
- Potential tools/workflows: Use Edit3D-Bench metrics (Chamfer, F1, LPIPS) for dataset curation; employ the paper’s data engine recipe to scale domain-specific pairs.
- Assumptions/dependencies: Domain gap to real-world targets; label propagation and rendering pipelines; GPU compute for batch generation.
- Bold: AR/VR prototyping and content localization — Sectors: XR, design, education
- Description: Fast customization of assets for multi-market releases (e.g., “change signage to Spanish,” “replace texture with woodgrain”), including edits not visible in the input camera view.
- Potential tools/workflows: Integration with ARCore/ARKit/RealityKit; variant management and regional content workflows; automated perceptual checks with LPIPS on six views.
- Assumptions/dependencies: Offline generation time (~seconds per asset) is acceptable; packaging to platform-specific formats; UI for text edits and preview.
- Bold: Interior design and real-estate staging — Sectors: AEC, real estate, visualization
- Description: Text-driven furniture and decor tweaks (“make the sofa navy,” “add a floor lamp,” “remove handles”) for quick client iterations without re-modeling.
- Potential tools/workflows: Pipelines bridging DCC to Revit/Enscape/Twinmotion; view-consistency checks; client review portals.
- Assumptions/dependencies: Conversion from generative meshes to CAD-friendly geometry is limited; human QA for scale/pose alignment.
- Bold: Education and training materials — Sectors: education, STEM outreach
- Description: Easily tailor 3D teaching aids (mechanical parts, simple anatomical models) to lesson objectives via text instructions, making 3D accessible to non-experts.
- Potential tools/workflows: Browser-based editors; LMS integration; version-controlled asset libraries with before/after snapshots.
- Assumptions/dependencies: Non-clinical usage; simplification of complex models; export to student-friendly viewers.
- Bold: Benchmarking and model evaluation — Sectors: academia, policy (standards/testing)
- Description: Use Edit3D-Bench to measure edit-following and asset-consistency across 3D editing systems, enabling reproducible comparisons and model audits.
- Potential tools/workflows: Plug-and-play metric tooling; regression dashboards; “no-edit” failure tracking and DPO effectiveness monitoring.
- Assumptions/dependencies: Broader community adoption; metrics remain correlated with human judgments; standardized input-output formats across systems.
Long-Term Applications
The following applications will require further research, scaling, or integration (e.g., scene-level edits, CAD-grade precision, physics/material constraints, or regulatory approvals).
- Bold: Scene-level, multi-object editing with semantics and physics — Sectors: robotics, XR, AEC
- Description: Text-driven edits at environment scale (“add a handrail along the staircase,” “remove clutter from the workspace”), preserving consistency across many objects.
- Potential tools/workflows: Semantic segmentation/instance tracking combined with Steer3D; physics-aware material and collision checks; scene graph integration.
- Assumptions/dependencies: New training data for scene edits; robust localization across occlusions; integration with physics engines.
- Bold: CAD/CAM-grade, parametric-safe editing — Sectors: manufacturing, industrial design
- Description: Edits that respect dimensional tolerances and engineering constraints, yielding watertight, manifold, parametric models suitable for production and FEA.
- Potential tools/workflows: Coupling with CAD kernels (Parasolid/OpenCascade); constraint solvers; tolerance validators and geometry repair.
- Assumptions/dependencies: Bridging non-parametric generative outputs to parametric workflows; standards compliance; high-fidelity geometry generation.
- Bold: Medical device personalization and preoperative planning — Sectors: healthcare
- Description: Patient-specific edits (e.g., “adjust orthotic curvature,” “thicken the shell”) and tailored educational models for clinicians.
- Potential tools/workflows: DICOM-to-3D pipelines; validation against anatomical ground truth; regulatory evidence generation (FDA/CE).
- Assumptions/dependencies: Clinical-grade accuracy, traceability, and safety; extensive validation; privacy and security compliance.
- Bold: Real-time, on-device text-steerable editing — Sectors: mobile/XR/edge
- Description: Interactive edits in mobile AR or VR with sub-second latency.
- Potential tools/workflows: Model distillation/quantization; hardware-aware scheduling; cached feature steering.
- Assumptions/dependencies: Significant model compression; mobile GPU/NPUs; memory and energy constraints.
- Bold: Compliance and safety tooling for 3D marketplaces — Sectors: policy, platforms, consumer safety
- Description: Automated editing to remove hazardous features (e.g., sharp edges), enforce child-safety guidelines, or test moderation systems with standardized edit suites.
- Potential tools/workflows: Rule-based edit templates; validation harness using Edit3D-Bench; audit trails for moderated assets.
- Assumptions/dependencies: Formalized policy-to-edit mapping; reliable detection of violations; platform governance.
- Bold: IP protection, watermarking, and provenance for 3D edits — Sectors: platforms, legal/rights
- Description: Track and verify the lineage of text-driven edits, watermark changes, and enforce licenses on derivative assets.
- Potential tools/workflows: Embedded edit provenance metadata; watermarking in geometry/material channels; license-aware asset managers.
- Assumptions/dependencies: Standards for 3D edit provenance; robust watermarking that survives re-meshing and conversion.
- Bold: Cross-modality steering ecosystems (materials, animation, simulation) — Sectors: software, media, robotics
- Description: Extend the “add text steering to pretrained generative models” recipe to materials, rigging, animation, and scene simulation.
- Potential tools/workflows: ControlNet-like branches for non-3D modalities; multi-modal training data engines; unified prompt orchestration.
- Assumptions/dependencies: Pretrained bases per modality; alignment losses akin to DPO for each domain; dataset synthesis at scale.
- Bold: Digital twin scenario generation and resilience testing — Sectors: energy, industrial, urban planning
- Description: Rapid “what-if” modifications to equipment and urban assets to stress-test plans (e.g., “remove bollards,” “add temporary barriers”) with consistent geometry.
- Potential tools/workflows: Twin platform connectors; policy-driven scenario libraries; safety KPI dashboards.
- Assumptions/dependencies: Accurate co-registration with GIS/asset databases; physics/material realism; stakeholder buy-in.
- Bold: Sustainable compute and greener content pipelines — Sectors: energy, policy, enterprise IT
- Description: Replace slow multi-stage 2D→3D pipelines with feedforward editing to reduce render/optimization cycles and carbon footprint.
- Potential tools/workflows: Compute telemetry for emissions; scheduling to renewable-powered windows; enterprise reporting.
- Assumptions/dependencies: Organizational adoption; measured end-to-end savings; equivalence in content quality.
Notes on feasibility across applications:
- Steer3D currently targets single-object edits and separates geometry/texture stages; scene-level and physics-aware edits require additional modules and data.
- Fidelity constraints matter: manufacturing/medical uses need parametric precision and regulatory validation; consumer content uses can adopt today’s mesh/texture fidelity.
- Integrations (Blender/Unity/Unreal/ARKit/Revit) and standardized exports (glTF/USD/USDZ/STL) are essential for deployment.
- Quality control is needed to catch known limitations (edit leaking, partial edits, consistency issues on complex prompts); benchmark-driven gates (LPIPS/Chamfer/F1 thresholds) can mitigate risk.
Glossary
- 3D bounding box: A three-dimensional rectangular region used to localize or constrain parts of an object in space. "assuming the additional input of a 3D bounding box."
- Agentic framework: A system that autonomously plans and executes multi-step actions (e.g., editing code) to achieve a goal. "which are agentic frameworks that edits blender code of 3D objects."
- AR/VR: Augmented Reality and Virtual Reality, immersive technologies that overlay or simulate environments. "Recent progress in image-to-3D has opened up immense possibilities for design, AR/VR, and robotics."
- Attention injection: A technique that modifies attention mechanisms to incorporate new control signals during generation. "3D-LATTE \citep{parelli_3d-latte_2025} is an inversion-based method that uses attention injection."
- Chamfer Distance: A metric measuring the distance between two point sets, commonly used to evaluate 3D shape similarity. "via 3D geometry metrics such as Chamfer Distance and F1 score"
- Classifier-Free Guidance (CFG): A method to strengthen conditioning in diffusion/flow models by mixing conditional and unconditional predictions. "we apply classifier-free guidance (CFG; \cite{ho_classifier-free_2022}) during supervised flow-matching training"
- ControlNet: A control branch added to a pretrained generative model to steer outputs with additional inputs (e.g., text). "We add a ControlNet block corresponding to each transformer block in the base model."
- Cross attention: A mechanism where one sequence (e.g., text) guides another (e.g., image/3D features) via attention. "then add additional cross attention that attends to the editing text"
- Direct Preference Optimization (DPO): A training method that optimizes models to prefer desired outputs over undesired ones based on pairwise comparisons. "and apply Direct Preference Optimization (DPO; \cite{rafailov_direct_2023}) to avoid the trivial ``no-edit'' solution."
- DiT (Diffusion Transformer): A transformer architecture adapted for diffusion/flow generative modeling. "instantiated as a DiT \citep{peebles_scalable_2023}."
- Feedforward 3D editing: Performing 3D edits in a single forward pass without iterative optimization. "Feedforward 3D editing is very challenging due to the lack of large-scale 3D edit pairs."
- F1 score: The harmonic mean of precision and recall; in 3D evaluation, measures geometry overlap under a distance threshold. "F1 is evaluated with a threshold of 0.05."
- Flow matching: A training objective for flow-based generative models that aligns predicted velocities with a defined forward process. "We then train Steer3D with flow matching \citep{lipman_flow_2023}"
- Gaussian optimization: Optimization over Gaussian splat parameters to refine a 3D representation. "producing floaters and artifacts during Gaussian optimization."
- Gaussian splatting: A 3D representation that renders scenes using many small Gaussian primitives. "are based on Gaussian splatting~\citep{kerbl20233d}"
- Gaussian splats: The individual Gaussian primitives used to represent and render 3D scenes. "DGE takes in the pre-edit 3D Gaussian splats ~\cite{kerbl20233d}, and performs multi-view image editing"
- Inpainting: Filling or editing missing/selected regions in images using generative models. "can be combined with inpainting methods \cite{lugmayr2023inpainting} to perform limited editing"
- Inversion-based method: An approach that maps a target object into a model’s latent space to enable controlled editing. "3D-LATTE \citep{parelli_3d-latte_2025} is an inversion-based method"
- Iterative Closest Point (ICP): An algorithm to align two 3D shapes by iteratively minimizing distances between closest points. "we align their outputs to the ground truth using Iterative Closest Point~\citep{besl1992method}"
- LLM: A model trained on large text corpora to understand and generate language. "we query a separate LLM (without giving it the images)"
- Large vision–LLM (VLM): A multimodal model that jointly processes visual and textual inputs. "Next, we prompt a VLM, GPT-4.1-mini, to propose a total of 20 creative edits"
- LPIPS: A learned perceptual image similarity metric used to evaluate alignment of rendered views. "calculate the mean LPIPS~\cite{zhang2018unreasonable} across six views."
- NeRF (Neural Radiance Fields): A neural representation that models volumetric scenes via density and color fields for novel view synthesis. "are based on NeRF~\citep{mildenhall2021nerf}"
- Objaverse: A large-scale dataset of 3D objects used for training and evaluation. "We sample $16k$ objects from Objaverse \citep{deitke_objaverse-xl_2023}"
- Occupancy: A volumetric representation indicating whether each voxel is inside or outside the object. "binary occupancy in a voxel grid."
- Radiance field: A function describing color and density at 3D positions and viewing directions for rendering. "latent features that can decode into Gaussian splats, radiance field, or a mesh."
- Rectified flow: A formulation of flow-based generation that defines a linear sampling path between data and noise. "formulate image-to-3D as conditional generation via rectified flow~\cite{lipman_flow_2023}"
- Score distillation: Using gradients from a text-to-image model’s score function to guide 3D optimization. "Score distillation \citep{poole_dreamfusion_2022} is adapted for 3D editing"
- Transformer block: A modular unit in transformer architectures consisting of attention and feedforward layers. "The base model is composed of 24 stacked transformer blocks."
- Tri-plane: A 3D representation that uses three orthogonal feature planes to encode geometry and appearance. "and \citep{qi_tailor3d_2024} is based on tri-plane."
- Voxel grid: A 3D grid of volumetric pixels (voxels) used to discretize space for geometry representations. "binary occupancy in a voxel grid."
Collections
Sign up for free to add this paper to one or more collections.

