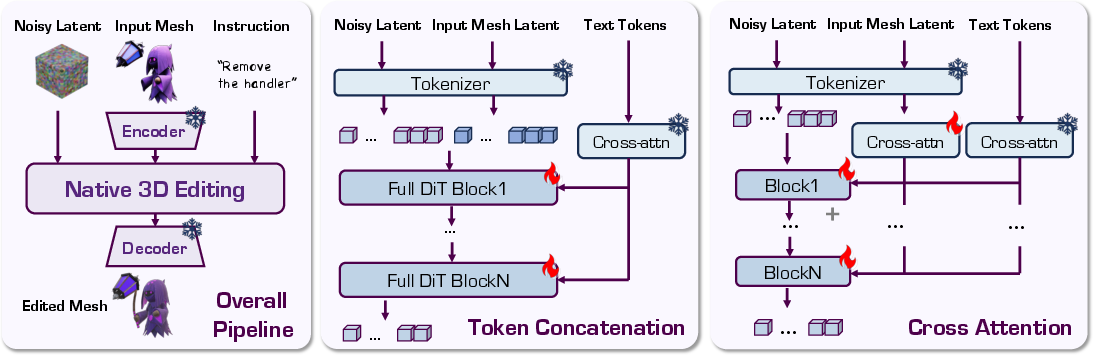
- The paper introduces a token concatenation mechanism that boosts edit fidelity and structural consistency in 3D models.
- It leverages a large-scale, multi-modal dataset with rigorous curation to outperform baselines on FID, FVD, and CLIP metrics.
- The framework enables precise, native 3D editing without auxiliary inputs, streamlining integration into practical asset pipelines.
Native 3D Editing with Full Attention: A Technical Synthesis
Introduction
Instruction-guided 3D editing has emerged as a critical direction for democratizing 3D content creation across visual computing, entertainment, and simulation domains. Existing paradigms — primarily optimization-based methods and 2D-lifting pipelines — have suffered either from prohibitive computational inefficiency or from a compromise in geometric and visual consistency due to their reliance on editing in 2D views. The work "Native 3D Editing with Full Attention" (2511.17501) proposes a feed-forward, instruction-guided framework for 3D editing, directly manipulating structured 3D representations. The approach is rooted in high-fidelity, large-scale, multi-modal data curation and a novel conditioning scheme based on 3D token concatenation, achieving superior performance over conventional cross-attention strategies without introducing extra complexity.
Dataset Construction Methodology
A key barrier to robust 3D instruction-driven editing is the lack of diverse, high-quality training data with precise edit correspondence. This work introduces a systematic pipeline for generating large-scale triplets covering deletion, addition, and modification tasks:
- Deletion: Leveraging Objaverse's hierarchical part annotations, the pipeline programmatically excises discrete object components and uses Gemini 2.5 (MLLM) to generate multi-view-based instructions, capturing both the semantic nature of the alteration and part-specific context.
- Addition and Modification: Pairs from open-source 2D editing datasets are elevated to 3D via Hunyuan3D 2.1, followed by rigorous manual filtering to ensure instruction fidelity, quality, and region-consistency.
This dual-track data acquisition forms a multi-modal benchmark tailored for direct 3D editing tasks.
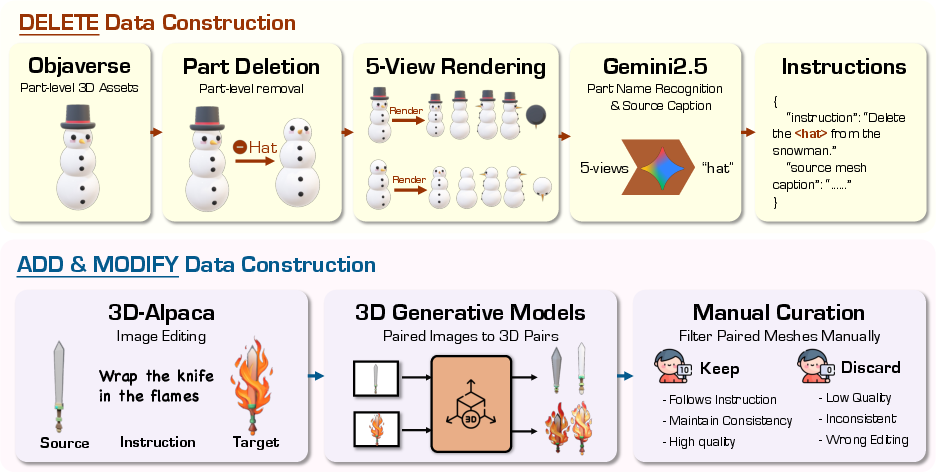
Figure 1: The data construction pipeline integrates procedural 3D part manipulation and rigorous manual curation for high-fidelity addition, deletion, and modification data.
Native 3D Editing Architecture
The framework builds on structured 3D diffusion models employing rectified flow and latent-space disentanglement, facilitating scalable geometry and fine-detail generation. Two conditioning strategies are compared:
Experimental Outcomes and Analysis
Quantitative Evaluation
The system was benchmarked against Tailor3D, Instant3DiT, VoxHammer, TRELLIS, and Hunyuan3D 2.1. For delete, add, and modify operations, metrics include FID (multi-view image similarity), FVD (temporal frame consistency), and CLIP Score (text-instruction compliance):
- FID: 91.9 (lowest among baselines)
- FVD: 286.5 (lowest among baselines)
- CLIP: 0.249 (highest among baselines)
This establishes clear dominance in both the preservation of unedited regions and precision with respect to textual instructions.
Qualitative Comparison
Visual inspection demonstrates the proposed token-cat method facilitates precise edits, maintaining geometric and visual integrity even under unseen instructions and object configurations. Competing 2D-lifting approaches exhibited severe view misalignments and artifacts, whereas feature alignment and appearance consistency were optimally preserved in the token-cat strategy.

Figure 3: Comparison highlighting superior structural coherence and edit localization of the proposed method across all edit types.

Figure 4: Demonstration of versatility: the system handles diverse, complex modifications, confirming strong generalization across categories and instruction semantics.
Ablation Studies
Token concatenation proved decisively superior to cross-attention injection, which often caused geometric corruption, especially under multi-modal and compositional instructions. Similarly, filtering training data via manual curation and leveraging Hunyuan3D 2.1-generated 3D objects led to substantial improvements in edit fidelity and consistency versus uncurated datasets.

Figure 5: (a) Token concatenation outperforms traditional conditioning in edit precision and object consistency; (b) Curation and advanced 3D models markedly boost training data quality and downstream edit capability.
Implications and Prospects
The parameter-efficient, full-attention, token-concatenation conditioning for native 3D editing offers a significant step toward production-grade, instruction-guided 3D asset manipulation. This paradigm, coupled with scalable data curation, opens pathways for generalized, robust 3D understanding and editing agents. The absence of auxiliary inputs (e.g., masks, sparse views) streamlines user interaction and unlocks potential for integration in asset pipelines, interactive design tools, and virtual simulation environments.
Theoretically, the token concatenation strategy provides an effective blueprint for multimodal, direct sequence-to-sequence conditioning, potentially extensible to higher-order transformations and generalized structure editing in 3D spatial domains.
Conclusion
"Native 3D Editing with Full Attention" introduces a rigorous framework for feed-forward, instruction-driven 3D editing in latent space, overcoming the core limitations of both optimization-based and 2D-lifting pipelines. Leveraging a high-fidelity, large-scale dataset and a novel parameter-efficient token concatenation mechanism, the method sets a new standard for edit accuracy, structural consistency, and semantic fidelity. The approach promises substantial impact in practical asset creation and establishes a foundation for future work in generalized, fully-attentive 3D content manipulation.