- The paper introduces a training-free method for precise 3D local asset editing using a two-stage latent inversion process and contextual feature replacement.
- The approach leverages a pretrained structured 3D diffusion model (TRELLIS) to blend edited and unedited regions, achieving high-fidelity reconstruction with superior metrics such as CD 0.012 and PSNR 41.68.
- The method generalizes to diverse 3D editing tasks and outperforms existing solutions in user studies, reducing processing time from minutes to seconds.
VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space
Introduction
VoxHammer introduces a training-free framework for precise and coherent local editing of 3D assets directly in native 3D latent space. The method leverages a pretrained structured 3D latent diffusion model (TRELLIS) and a two-stage process: (1) precise 3D inversion and (2) denoising-based editing with contextual feature replacement. This approach addresses the limitations of prior 3D editing pipelines, which either optimize 3D representations via Score Distillation Sampling (SDS) or edit multi-view images followed by 3D reconstruction, both suffering from inefficiency and poor preservation of unedited regions. VoxHammer achieves high-fidelity editing without retraining, enabling efficient synthesis of paired edited data and laying the groundwork for in-context 3D generation.
Methodology
Pipeline Overview
VoxHammer's pipeline begins with an input 3D model, a user-specified editing region, and a text prompt. The model first renders a view and uses off-the-shelf image diffusion models (e.g., FLUX) for inpainting. Subsequently, native 3D editing is performed in the latent space of the structured 3D diffusion model, conditioned on both the original 3D asset and the edited image.
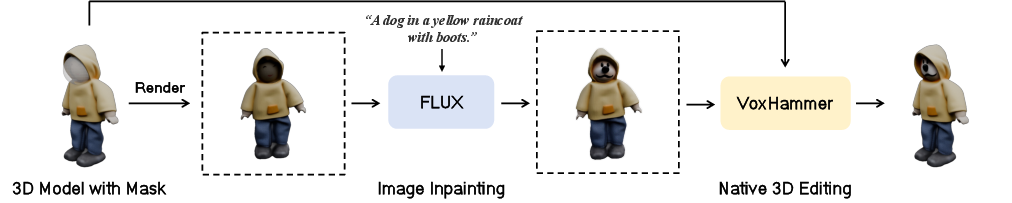
Figure 1: The pipeline integrates image inpainting and native 3D latent editing for precise local modifications.
Architecture and Inversion
The framework adopts TRELLIS as the base model, which operates in a sparse voxel-based latent space. TRELLIS employs a two-stage denoising process: the structure (ST) stage predicts coarse voxel occupancy, and the sparse-latent (SLAT) stage refines fine-grained geometry and texture. VoxHammer performs inversion in both stages, mapping the textured 3D asset to its terminal noise and caching latents and key-value (K/V) tokens at each timestep.
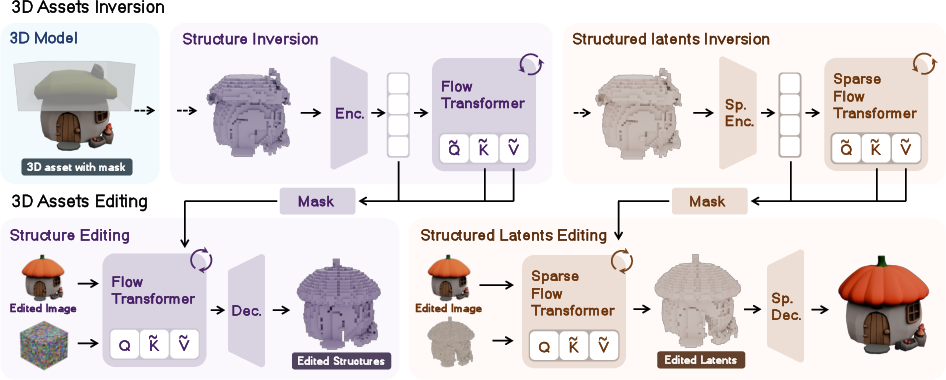
Figure 2: VoxHammer architecture with two-stage inversion and contextual feature replacement for precise editing.
Inversion is implemented using a Taylor-improved Euler scheme, inspired by RF-Solver, to minimize integration errors and ensure high-fidelity reconstruction. Classifier-free guidance (CFG) is applied only in late timesteps to stabilize inversion and enhance semantic sharpness.
Editing via Latent and Key-Value Replacement
During editing, denoising is initialized from the inverted noise. Latent replacement is performed using binary or soft masks to blend the edited and preserved regions. In the ST stage, latents are blended at each denoising step, while in the SLAT stage, features at unedited coordinates are replaced with their inverted counterparts. Key-value replacement in the attention mechanism further enforces feature-level consistency, preventing semantic leakage into preserved regions. All modifications are applied at inference time, without retraining.
Experimental Results
Quantitative and Qualitative Evaluation
VoxHammer is evaluated on Edit3D-Bench, a human-annotated dataset with labeled 3D editing regions. Metrics include Chamfer Distance (CD), masked PSNR, SSIM, LPIPS for unedited region preservation, FID and FVD for overall 3D quality, and DINO-I and CLIP-T for condition alignment.
VoxHammer achieves the best scores across all metrics, with CD of 0.012, PSNR of 41.68, SSIM of 0.994, LPIPS of 0.027, FID of 23.05, and DINO-I of 0.947. These results demonstrate superior preservation of geometry and texture in unedited regions and high overall quality.

Figure 3: Qualitative comparisons on Edit3D-Bench show VoxHammer's superior editing precision and coherence.
Ablation Studies
Ablation studies confirm the necessity of two-stage inversion and key-value replacement. Inversion in both ST and SLAT stages yields significant improvements in reconstruction fidelity (CD: 0.0055, PSNR: 39.70, SSIM: 0.987, LPIPS: 0.012). Disabling key-value replacement or reinitializing noise degrades preservation quality and introduces artifacts.

Figure 4: Ablation studies highlight the impact of key-value and latent replacement on editing fidelity.
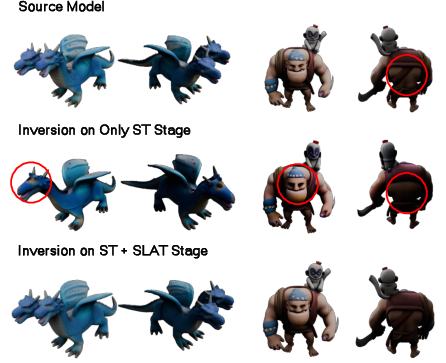
Figure 5: Inversion in both stages is critical for fine-grained geometry and texture reconstruction.
User Study
A user study with 30 participants shows a strong preference for VoxHammer over Instant3DiT and TRELLIS, with 70.3% favoring its text alignment and 81.2% its overall 3D quality.
Runtime Analysis
VoxHammer edits a 3D asset in approximately 133 seconds, outperforming optimization-based methods (e.g., Vox-E: 32 min) and competitive with multi-view editing approaches.
Generalization and Applications
VoxHammer generalizes to part-aware object editing, compositional 3D scene editing, and NeRF/3DGS asset editing. The method supports both text-conditioned and image-conditioned editing, with competitive performance in preserving unedited regions and maintaining overall quality.
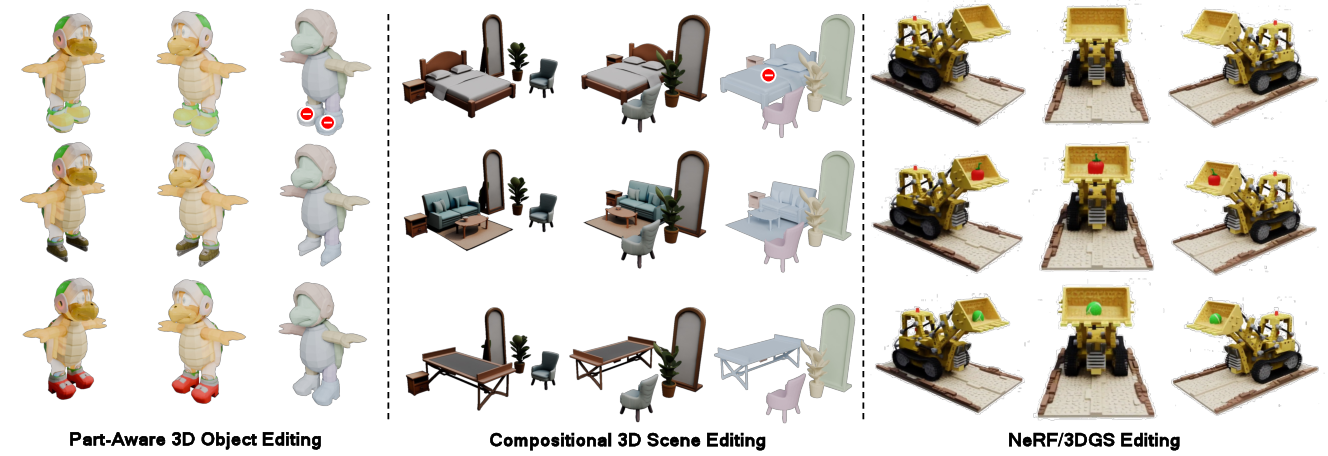
Figure 6: VoxHammer generalizes to part-aware 3D object, scene, and NeRF/3DGS editing.

Figure 7: Visualization results of text-conditioned 3D editing.
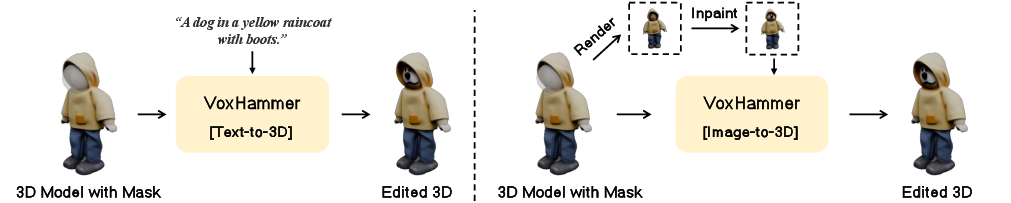
Figure 8: Pipeline for text-condition (left) and image-condition (right) 3D editing.

Figure 9: More visualization results of image-condition 3D editing.
Limitations
VoxHammer's text alignment is suboptimal due to limited captioned 3D datasets, and editing fidelity is bounded by the resolution of the TRELLIS backbone. The rendering phase in 3D encoding remains a bottleneck for interactive use.
Conclusion
VoxHammer establishes a training-free paradigm for precise and coherent 3D local editing by leveraging accurate inversion and contextual feature replacement in the latent space of a pretrained structured 3D diffusion model. The method achieves state-of-the-art consistency and quality, generalizes across asset types, and enables efficient synthesis of paired edited data. Future work should address text-conditioned guidance robustness, backbone resolution, and pipeline efficiency to further advance interactive and in-context 3D generation.

