- The paper introduces 3D-R1, a unified framework that leverages synthetic chain-of-thought data, reinforcement learning from human feedback, and dynamic view selection to boost 3D scene reasoning.
- Methodologies include parameter-efficient tuning using LoRA adapters on a multi-modal backbone, achieving state-of-the-art performance across tasks like dense captioning, QA, and visual grounding.
- Empirical results demonstrate significant improvements over prior models on benchmarks such as ScanRefer, Nr3D, and ScanQA, setting a new standard for 3D VLMs.
3D-R1: Enhancing Reasoning in 3D Vision-LLMs for Unified Scene Understanding
Introduction and Motivation
3D scene understanding is a critical capability for embodied AI, robotics, and mixed reality, requiring models to reason about complex spatial relationships, object configurations, and dynamic contexts. While large vision-LLMs (VLMs) have achieved strong results in 2D domains, their extension to 3D environments has been hampered by limited reasoning ability, poor generalization, and static viewpoint assumptions. The 3D-R1 framework addresses these limitations by integrating high-quality synthetic Chain-of-Thought (CoT) data, reinforcement learning from human feedback (RLHF) with multi-faceted reward functions, and a dynamic view selection strategy to enhance reasoning and generalization in 3D VLMs.
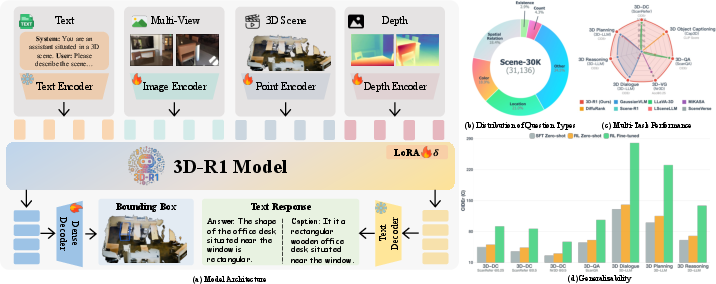
Figure 1: (a) 3D-R1 architecture processes text, multi-view images, 3D point clouds, and depth maps for unified 3D tasks; (b) Scene-30K question type distribution; (c) Multi-task performance; (d) Generalizability and reasoning.
Scene-30K: Synthetic Chain-of-Thought Data Engine
A central component of 3D-R1 is the Scene-30K dataset, a synthetic corpus of 30,000 high-quality CoT reasoning samples. The data engine operates by first generating concise scene descriptions from 3D point clouds using a pretrained 3D VLM. These descriptions, capturing object identities, relations, and spatial layouts, are then used to prompt Gemini 2.5 Pro for stepwise CoT reasoning on diverse 3D scene questions. The resulting samples are filtered for format adherence, multi-step logic, and semantic consistency using rule-based criteria and Levenshtein similarity.
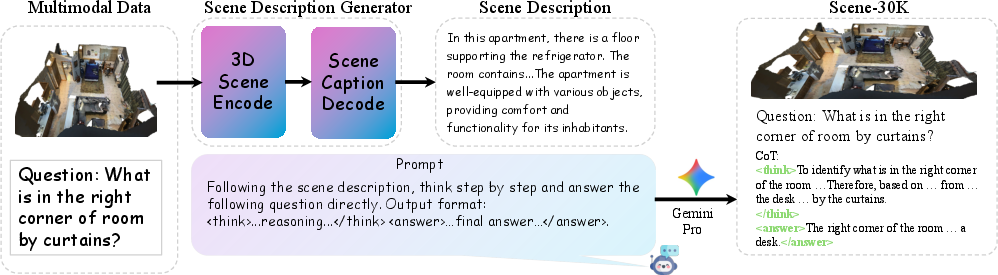
Figure 2: The CoT data engine generates scene descriptions from point clouds, then synthesizes CoT data using Gemini 2.5 Pro.
This dataset provides structured supervision for cold-start initialization, enabling the model to learn both the expected output format and the logic of multi-step spatial reasoning.
Model Architecture and Training Paradigm
3D-R1 employs a unified architecture that ingests text, multi-view images, 3D point clouds, and depth maps, formulating all 3D scene understanding tasks as autoregressive sequence prediction. The backbone is based on Qwen2.5-VL-7B-Instruct, with modality-specific encoders (SigLIP-2 for images, Depth-Anything v2 for depth, Point Transformer v3 for point clouds). All encoders are linearly projected and concatenated with text tokens for joint processing. Parameter-efficient fine-tuning is achieved via LoRA adapters in the last 8 transformer blocks, with only ~142M parameters updated.
Reinforcement Learning with Group Relative Policy Optimization
After supervised fine-tuning on Scene-30K, 3D-R1 is further optimized using Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm that samples multiple candidate responses per input and updates the policy based on relative reward advantages. Three reward functions are used:
- Format Reward: Enforces strict output structure (> …<answer>…</answer>).
- Perception Reward: Measures spatial grounding via IoU between predicted and ground-truth bounding boxes.
- Semantic Similarity Reward: Uses CLIP-based cosine similarity between predicted and reference answers.
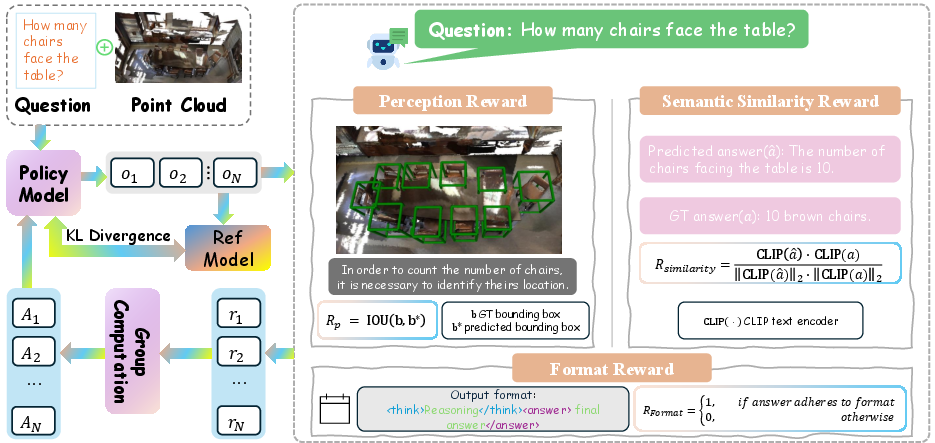
Figure 3: GRPO pipeline: the policy model generates multiple outputs, computes perception, semantic, and format rewards, and updates via KL-regularized policy optimization.
Ablation studies demonstrate that each reward contributes complementary improvements, with the combination yielding a significant increase in reasoning and grounding performance.
Dynamic View Selection
To address the limitations of static or fixed-viewpoint assumptions, 3D-R1 introduces a dynamic view selection module. For each 3D scene, a pool of candidate 2D views is rendered and scored using three metrics: text-to-3D relevance, image-to-3D coverage, and CLIP-based cross-modal similarity. Learnable weights (wt, wc, wclip) are used to adaptively fuse these scores, and the top-ranked views are selected for downstream processing.
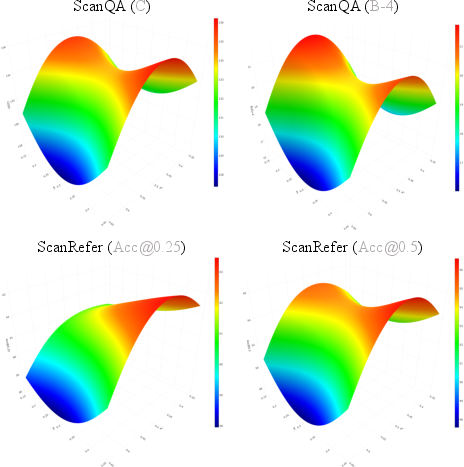
Figure 4: Performance surfaces under different dynamic view selection weight configurations, showing optimal performance for balanced text and visual weights.
Empirical results show that dynamic view selection outperforms all fixed-view baselines, with optimal performance achieved when text relevance is moderately weighted and visual cues are balanced.
Experimental Results
3D-R1 is evaluated across seven representative 3D scene understanding tasks: dense captioning, object captioning, question answering, visual grounding, dialogue, reasoning, and planning. The model consistently outperforms prior state-of-the-art methods on all major benchmarks, including ScanRefer, Nr3D, Cap3D, ScanQA, 3D-LLM, and SQA3D.
- 3D Scene Dense Captioning: 3D-R1 achieves 91.85 CIDEr on ScanRefer and 86.45 on Nr3D, surpassing all previous models.
- 3D Object Captioning: Achieves 4.32 quality score and 77.34 CLIP score on Cap3D, outperforming DiffuRank and other baselines.
- 3D Question Answering: 106.45 CIDEr and 51.23 ROUGE-L on ScanQA validation, with strong generalization to test sets.
- 3D Visual Grounding: 68.80 [email protected] on Nr3D and 65.85 on ScanRefer, exceeding all prior approaches.
- 3D Dialogue, Reasoning, Planning: State-of-the-art results across all metrics, with notable improvements in multi-turn and long-horizon tasks.
Qualitative results further illustrate the model's ability to generate contextually grounded, semantically rich, and spatially precise outputs across diverse 3D tasks.

Figure 5: Qualitative results for 3D scene dense captioning (3D-DC).

Figure 6: Qualitative results for 3D object captioning.

Figure 7: Qualitative results for 3D visual grounding (3D-VG).

Figure 8: Qualitative results for 3D question answering (3D-QA).

Figure 9: Qualitative results for 3D dialogue.

Figure 10: Qualitative results for 3D reasoning.

Figure 11: Qualitative results for 3D planning.
Implementation Considerations
- Data Synthesis: Scene-30K is generated using Gemini 2.5 Pro, with rule-based filtering for quality control.
- Parameter-Efficient Tuning: LoRA adapters enable efficient adaptation with minimal trainable parameters.
- RLHF Stability: Cold-start supervised fine-tuning is essential for stable RLHF; direct RL from scratch is unstable in 3D VLMs.
- Dynamic View Selection: Requires rendering and feature extraction for multiple candidate views per scene; computationally intensive but critical for generalization.
- Resource Requirements: Training conducted on 4×NVIDIA H20 GPUs; full fine-tuning is avoided for efficiency.
Limitations and Future Directions
Despite strong empirical results, several limitations remain:
- Scene-30K is synthetic and may not capture the full diversity of real-world human reasoning.
- GRPO-based RLHF operates at the response level and lacks temporally grounded feedback, limiting long-horizon embodied reasoning.
- Dynamic view selection is designed for static scenes and may not generalize to real-time interactive environments.
Future work should focus on integrating real-world embodied data, temporally grounded RLHF, and world modeling for predictive simulation and planning.
Conclusion
3D-R1 demonstrates that combining high-quality synthetic CoT supervision, multi-reward RLHF, and adaptive perception strategies yields substantial improvements in 3D scene understanding. The framework achieves strong generalization and reasoning across a wide range of 3D tasks, setting a new standard for unified 3D VLMs. The modular design, parameter-efficient tuning, and dynamic view selection provide a blueprint for future research in scalable, generalist 3D scene understanding systems.

