- The paper introduces a semi-explicit framework that integrates free-moving feature Gaussians to balance rendering fidelity and real-time performance.
- It employs a decoupled architecture with a transformer-based backbone and multi-space partitioned decoder for enhanced depth and color synthesis.
- Experimental results demonstrate significant gains in PSNR, SSIM, and depth accuracy while using a fraction of the Gaussians compared to prior methods.
Long-LRM++: A Semi-Explicit Framework for High-Resolution Feed-Forward Scene Reconstruction
Introduction and Motivation
Long-LRM++ addresses critical limitations in the feed-forward wide-coverage reconstruction domain, particularly the trade-off between rendering fidelity and real-time performance. Previous 3D Gaussian Splatting (GS) approaches enabled efficient and high-speed image-based reconstruction but suffered from blurriness and detail loss due to errors in direct color prediction for millions of explicit Gaussians. In contrast, implicit representations such as LaCT and LVSM achieve high fidelity but require complex decompression architectures per frame, rendering them impractical for real-time use. The paper poses two guiding questions: is the color-only splatting in explicit GS fundamentally limited in quality, and can model architectures maintain the strengths of implicit encodings while operating at feed-forward, real-time speeds? Long-LRM++ provides affirmative answers via a semi-explicit approach.

Figure 1: Long-LRM++ delivers real-time, high-resolution novel-view synthesis by reducing blurriness versus prior explicit methods, while maintaining speed.
Architecture and Methodology
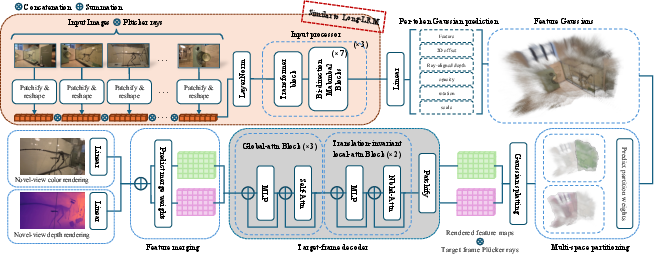
Long-LRM++ is architected around a semi-explicit paradigm in which each image token predicts a free-moving feature Gaussian with a learnable vector, relaxing constraints on spatial alignment and color association with scene surfaces. The model pipeline consists of three decoupled modules:
The decoder employs local-attention with relative positional encodings in early layers to address the positional entanglement of global-attention, followed by global-attention for contextual aggregation. View-dependent effects are encoded by incorporating Plücker rays into the feature space, and the partitioning mechanism (drawing from multi-space NeRFs) improves handling of complex phenomena such as mirror reflections.
Experimental Results
Long-LRM++ establishes new state-of-the-art performance on both wide-coverage color and depth novel-view synthesis.
Color Rendering (DL3DV):
On the DL3DV 140-scene benchmark, Long-LRM++ produces a PSNR of 27.3 (64 inputs), surpassing Long-LRM by a significant margin while maintaining real-time frame rates (14 FPS on a single A100 GPU). Notably, it achieves comparable PSNR and superior SSIM (0.869) versus LaCT, with a roughly 8× speed-up in rendering. Critically, Long-LRM++ achieves these results while using just a quarter of the Gaussians vs. Long-LRM.

Figure 3: Qualitative comparison on DL3DV—Long-LRM++ recovers fine details and faithful light interactions unattainable by prior feed-forward architectures.
Depth Rendering (ScanNetv2):
For combined color and depth view synthesis on ScanNetv2, Long-LRM++ yields a ΔPSNR of +4.6dB and reduces absolute depth error to 0.131, outperforming direct Gaussian depth regression in both accuracy and detail recovery.

Figure 4: On ScanNetv2, Long-LRM++ delivers high-quality depth and color renderings with a sparse set of free, unconstrained Gaussians.
Ablation and Analysis
Extensive ablations demonstrate the rationale for key hyperparameters. The K=16,F=32 setting for per-token Gaussian count and feature dimension optimizes the trade-off between spatial flexibility, expressivity, and memory footprint.
Translation-invariant local-attention in the decoder is shown to be vital for consistent object handling across the frame. The multi-space partitioning design yields measurable gains in PSNR, particularly in scenes with spatial discontinuities (e.g., reflections).
Auxiliary losses targeting depth gradients and normal consistency further enhance depth outputs with minor impact on color fidelity, affirming the value of multitask supervision for geometric quality.
Implications and Future Work
This work introduces a model class that robustly interpolates between explicit feature-level and implicit scene-level encodings. The resulting improvements in detail restoration and robustness against pose/attribute errors are especially salient for real-time 3D scene understanding and downstream AR/VR applications. By reducing the need for pixel-aligned Gaussians and instead delegating complex content to a feature-based learned decoder, Long-LRM++ highlights a scalable path towards efficient, high-fidelity scene inference.
- Practical Implications: The model's balance of quality and speed positions it as a candidate backbone for 3D semantic understanding, online mapping, and interactive graphics.
- Theoretical Implications: The success of semi-explicit representations invites further study in the interplay between feature field density, decoder design, and the trade-offs in partitioned vs. holistic scene inference.
- Future Directions: Enhancements may focus on further reducing computational bottlenecks in the decoder, adaptive selection of partition counts, or integration with physically based rendering priors for challenging materials and lighting.
Conclusion
Long-LRM++ (2512.10267) delivers a highly efficient, feed-forward 3D reconstruction framework that closes the fidelity gap with state-of-the-art implicit approaches while providing real-time scene synthesis. By decoupling explicit geometry from pixel-wise color prediction and introducing feature-based Gaussians with partitioned decoding, the architecture robustly addresses prior weaknesses in detail preservation and generalization. This paradigm provides a compelling template for future models targeting reconstruction at scale.