- The paper introduces a pose-free dual-branch architecture that decouples canonical avatar reconstruction from pose inputs, enabling robust animation.
- It employs pixel-aligned Gaussian primitives and a learnable template branch to inpaint occluded regions and capture high-fidelity texture and geometry from sparse data.
- Experimental evaluations on THuman2.0, XHuman, and HuGe100K show that NoPo-Avatar outperforms pose-dependent baselines under noisy conditions.
Introduction and Motivation
The reconstruction and animation of 3D human avatars with high fidelity from sparse 2D inputs is a central problem for AR/VR and telepresence systems. Conventional state-of-the-art approaches often require accurate camera and human pose information at test-time to facilitate correspondence matching and feature alignment. However, reliance on pose priors induces brittleness: test-time pose estimation is frequently noisy or imprecise, severely degrading rendering quality in uncontrolled environments, as evidenced by quantitative and qualitative metrics.
NoPo-Avatar introduces a paradigm shift—by dispensing with all pose requirements in the reconstruction stage, it achieves robust, high-quality avatar creation directly from images and binary masks. This design targets pose-agnostic canonicalization, using only the image data, and enables effective animation and novel view synthesis without being impacted by pose estimation errors.
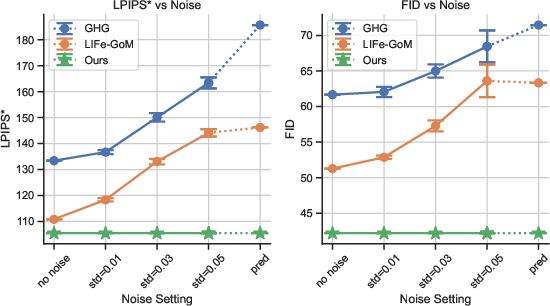
Figure 1: Rendering quality comparisons across varying levels of input-pose noise, showing NoPo-Avatar's insensitivity to pose inaccuracies.
Methodology
Architecture: Dual-Branch Canonical Gaussian Reconstruction
NoPo-Avatar's reconstruction module leverages a dual-branch encoder-decoder architecture (Figure 2):
- Template Branch: Builds a canonical T-pose representation using a learnable embedding consistent with the mean SMPL-X body. It inpaints occluded or unobserved regions, providing complete coverage even for sparse views.
- Image Branches: For each input image, pixel-aligned Gaussian primitives are predicted; these splatter representations encode precise texture, geometry, and opacity information for observed regions in canonical space.
Both branches employ vision transformer (ViT) encoders and a cross-attentive decoder stack to facilitate feature fusion and implicit alignment across multi-view inputs. The prediction heads deliver Gaussians parameterizing mean position, scale, rotation, opacity, spherical harmonics (for appearance), and linear blend skinning (LBS) weights tied to body bones.
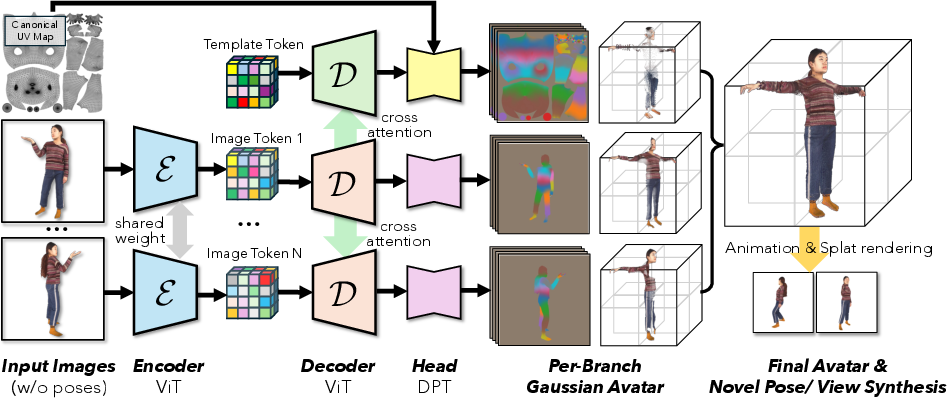
Figure 2: Dual-branch reconstruction module: image branches capture observed details, template branch enables inpainting; both fused in canonical space.
Articulation and Novel Pose Synthesis
Given arbitrary pose and shape specified in SMPL-X format, NoPo-Avatar warps the canonical Gaussian representation to the target pose via LBS. The predicted bone-wise weights are mapped to joint-wise assignments to comply with skeleton tree conventions, facilitating reliable articulation.
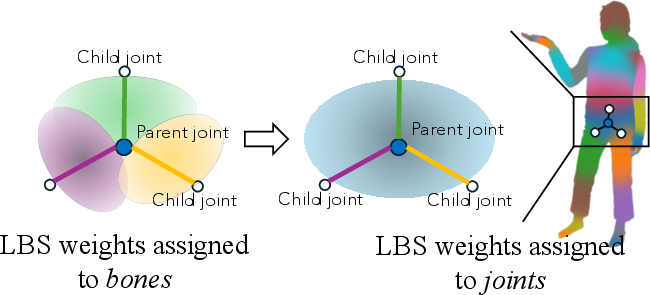
Figure 3: Visualization of the conversion from bone-based LBS weights to joint-based assignments for robust deformation.
Decoupling shape from the canonical representation is essential to mitigate scale ambiguity and ensure faithful thin structure recovery (e.g., hands). This process is highlighted in comparative reconstructions.

Figure 4: Shape-canonicalization decoupling avoids reconstruction failure of thin structures by anchoring to a fixed T-pose skeleton.
Novel view or pose rendering is executed via differentiable Gaussian splatting after articulation, with image-compliant projection for high appearance fidelity.
Experimental Evaluation
Benchmarks and Comparative Results
NoPo-Avatar is extensively benchmarked on THuman2.0, XHuman, and HuGe100K, with strong baselines such as GHG, LIFe-GoM, IDOL, and LHM. Two core test-time protocols are examined:
- Realistic (Predicted Pose Inputs): Competing models suffer severe performance loss under pose prediction noise.
- Lab (Ground-truth Pose Inputs): NoPo-Avatar matches or exceeds SOTA rendering quality, even without pose inputs.
Quantitative results show NoPo-Avatar consistently outperforms pose-dependent baselines on perceptual (LPIPS*, FID) and pixel-based (PSNR) metrics, especially under noisy or estimated poses.
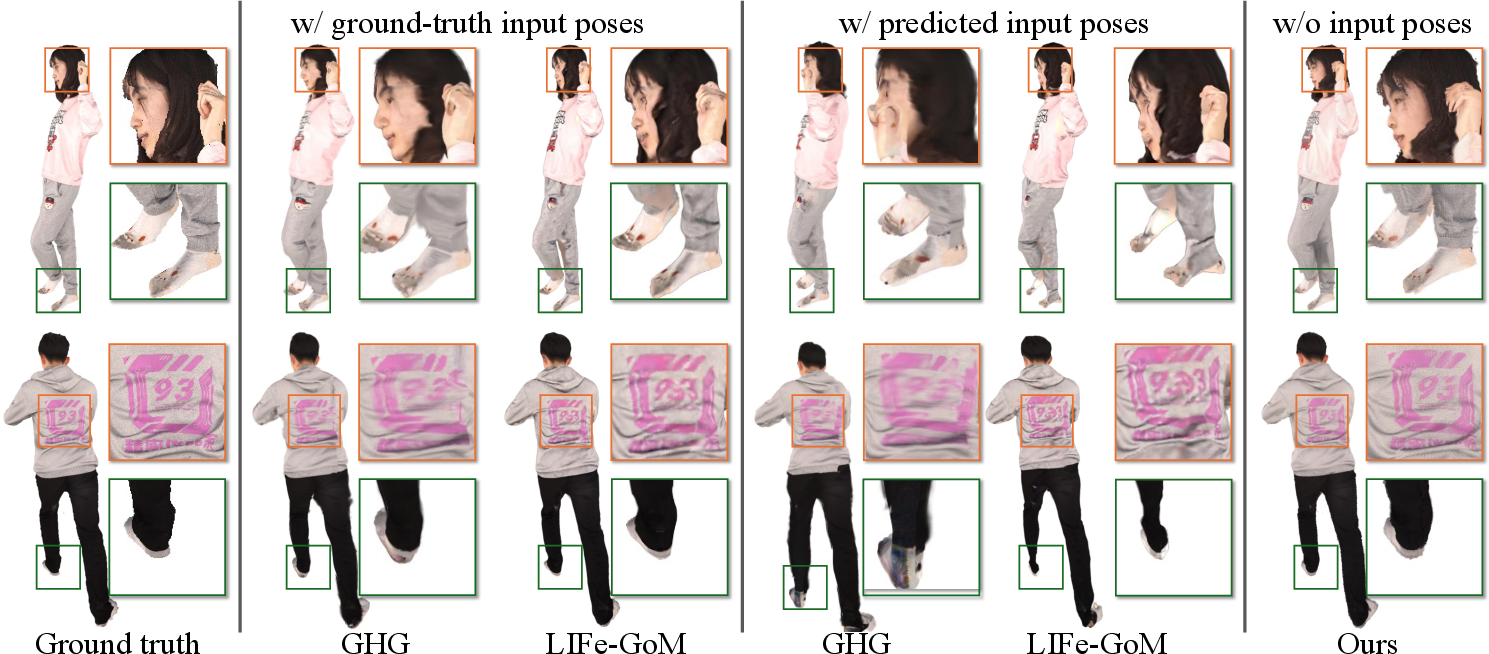
Figure 5: Novel view synthesis qualitatively on THuman2.0, showing NoPo-Avatar's resilience to pose errors in test-time reconstruction.
NoPo-Avatar scales gracefully with larger training sets, surpassing baselines in cross-domain and identity recovery tasks, a property not exhibited by methods with strong hand-crafted priors.
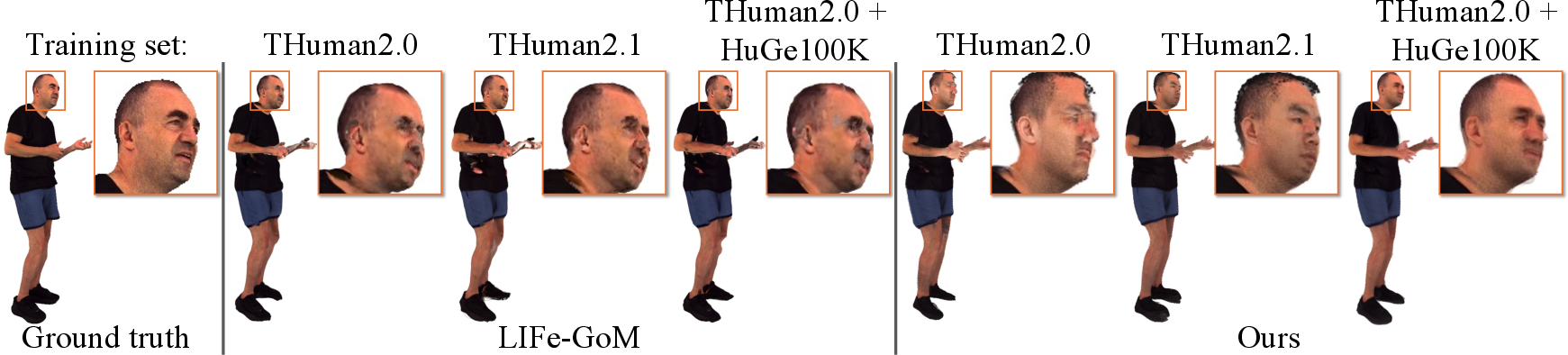
Figure 6: Cross-domain generalization and pose synthesis illustrate improved identity preservation and scaling trends with training set size.
Ablative studies rigorously validate the contributions of the template + image branch fusion and the crucial auxiliary losses for projection and LBS consistency. Disabling either negatively impacts inpainting, detail capture, or canonicalization.

Figure 7: Ablation: template-only misses fine details, image-only fails to inpaint; full model with auxiliary losses achieves optimal fidelity.
Robustness to Pose Noise
NoPo-Avatar's design removes sensitivity to test-time pose input noise. Even with severe Gaussian perturbations or inaccurate predicted poses, competing systems degrade sharply, while NoPo-Avatar retains performance.

Figure 8: LIFe-GoM's rendering deteriorates with pose noise; NoPo-Avatar maintains stable output across all noise levels.
Testing pose-dependent models with noisy training poses does not confer greater robustness, affirming the theoretical advantage of pose-free canonicalization for deployment.
Downstream Applications
Predicting pixel-aligned LBS weights and canonical coordinates enables zero-shot downstream tasks:
- Part Segmentation: Body part masks derived directly from LBS assignments in image branches.
- Pose Estimation: Optimization of pose parameters using pixel-3D correspondences and photometric alignment.
Limitations
NoPo-Avatar struggles with sharp inpainting when large unobserved regions coincide with the input set, and hand/facial detail recovery is imperfect—future work could adopt hybrid architectures with generative modules or dedicated predictors for these structures.
When trained with synthetic/multiview-inconsistent data (e.g., HuGe100K), semi-transparency or blurring emerges on boundaries, warranting higher-quality data curation for robust generalization.
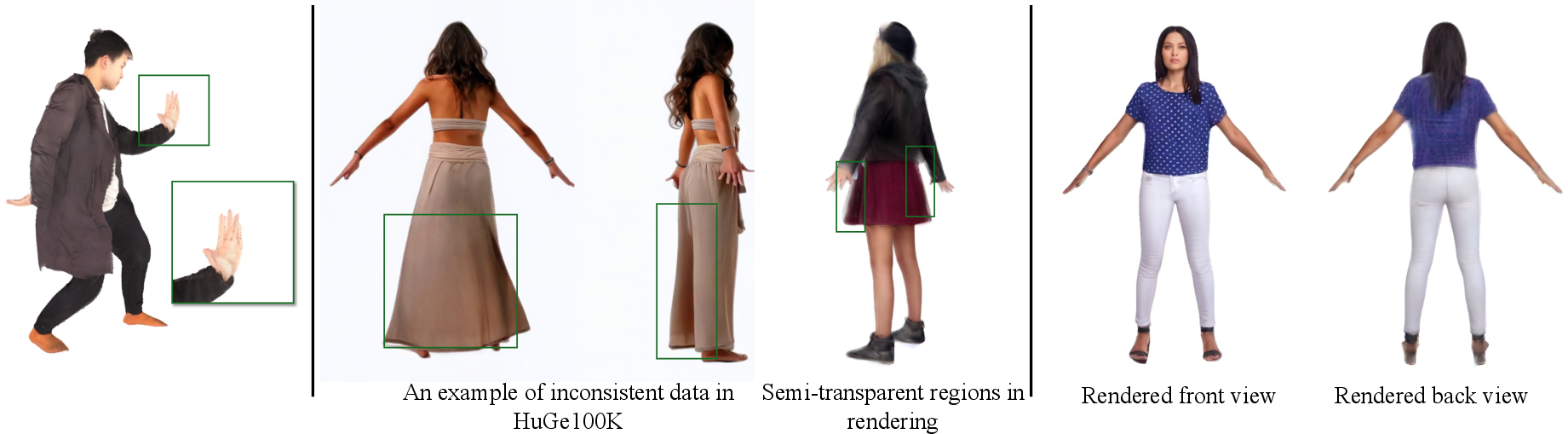
Figure 9: Examples of incomplete hand geometry, semi-transparent regions due to inconsistent training data, and blurry back-side inpainting.
Conclusion
NoPo-Avatar establishes a robust, pose-free framework for animatable avatar synthesis from sparse 2D inputs. The dual-branch architecture and canonical space design decouple the system from pose estimation bottlenecks, enhance generalization, and enable competitive fidelity on both novel view and pose tasks without reliance on ground-truth priors. The implications indicate strong potential for real-world AR/VR systems and foundation models where annotation of pose is infeasible. Future developments may incorporate adversarial/generative elements for improved sharpness in unobserved regions and specialized modules for fine parts modeling.