- The paper presents a staleness-aware proximal policy approximation that uses loglinear interpolation to replace expensive neural forward passes.
- It achieves a 22% speedup in training on GSM8K by reducing computation time from 10 seconds per step to 0.0012 seconds while maintaining stability.
- Empirical results reveal fewer clipped tokens and steadier importance weights, ensuring smoother updates and improved exploration in policy training.
A-3PO: Accelerating Asynchronous LLM Training with Staleness-aware Proximal Policy Approximation
Background and Motivation
The scaling of LLM post-training has motivated the adoption of asynchronous reinforcement learning (RL) protocols, decoupling data collection (rollouts) and policy updates. Standard Proximal Policy Optimization (PPO) enforces trust region constraints by referencing the same policy for both off-policy importance corrections and update limits. However, asynchronous RL induces staleness: the behavior policy generating rollouts lags behind the rapidly updated training policy. This leads to instability in conventional PPO, as the trust region anchor becomes an outdated policy. Decoupled loss frameworks, such as those in AReaL [fu2025areal], address staleness by introducing a proximal policy decoupled from the behavior policy, but require recomputation—a prohibitively expensive forward pass in the case of large autoregressive LLMs.
Methodology: Loglinear Staleness-aware Interpolation
The A-3PO algorithm proposes a computationally efficient loglinear interpolation framework for proximal policy approximation. The insight is that the proximal policy, whose purpose is to act as a trust region anchor, does not necessitate an expensive forward network evaluation. Instead, it can be interpolated in log-probability space between the stale behavior policy and the current training policy, using a staleness-dependent coefficient α:
logπprox=αlogπbehav+(1−α)logπθ
where α=1/s for staleness s (difference in update iteration between target and behavior policy).
This approach maintains numerical stability and leverages readily available log probability tensors, exploiting the practical interfaces provided by modern inference engines (e.g., SGLang, vLLM). Notably, for s=0, the method exactly recovers PPO, and for increasing staleness, the anchor is biased towards the current policy.
Computational Efficiency
The loglinear approximation yields a dramatic reduction in computational overhead for proximal policy evaluation. Specifically, it replaces a dedicated neural forward pass—often taking ∼10 seconds per step—with a negligible tensor arithmetic operation (∼0.0012 seconds). This directly translates to improved wall-clock training throughput.
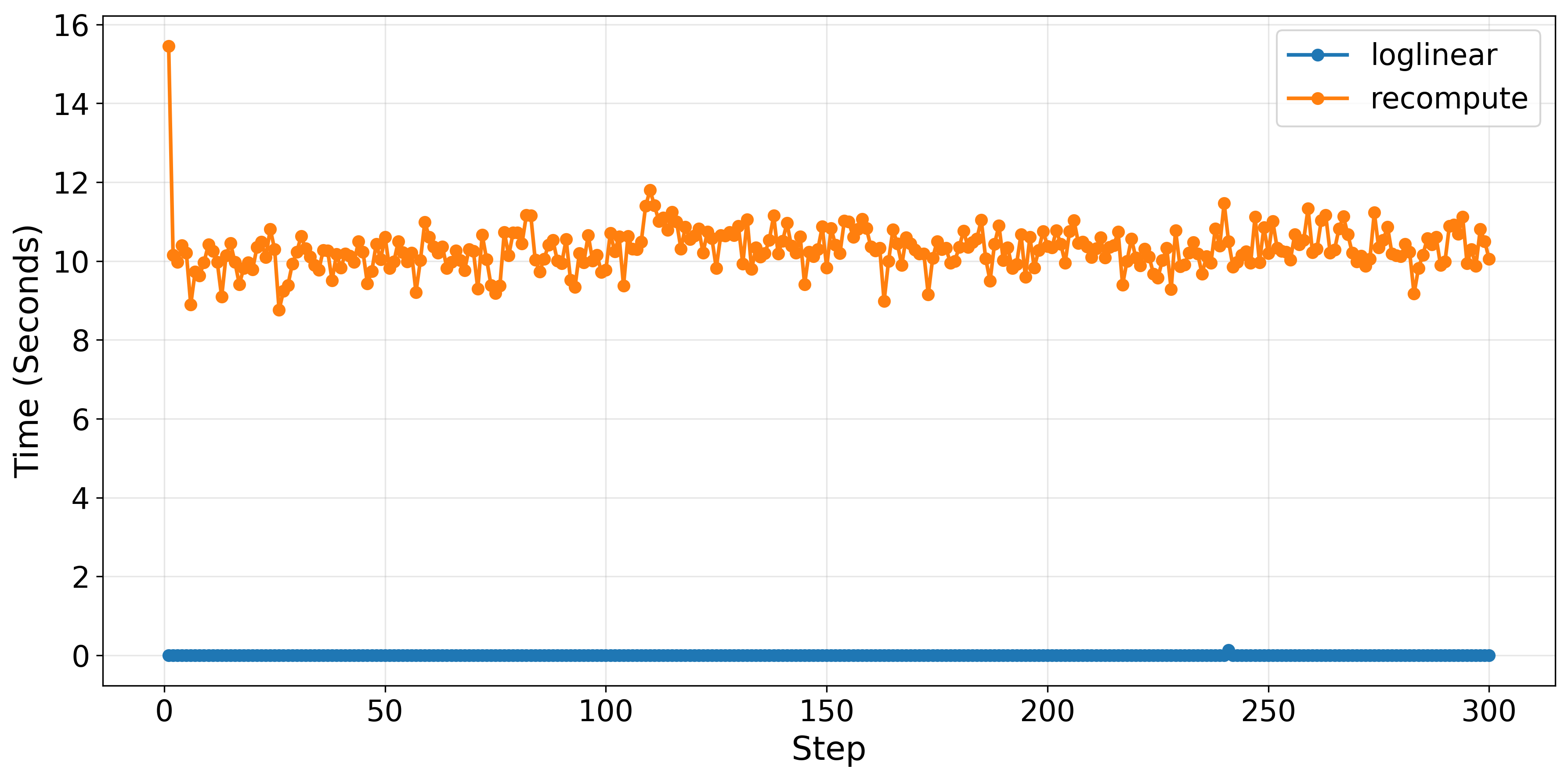
Figure 1: Loglinear interpolation eliminates proximal policy computation bottlenecks, achieving near-instantaneous evaluation compared to the recompute baseline's 10-second overhead per training step.
This efficiency gain is realized in practical training durations for LLM post-training pipelines. On GSM8K, using Qwen2.5-1.5B-Instruct, the loglinear method achieves a 22% end-to-end training speedup over the full recompute method (2.72 vs. 3.46 hours), with only 2% degradation in final performance.
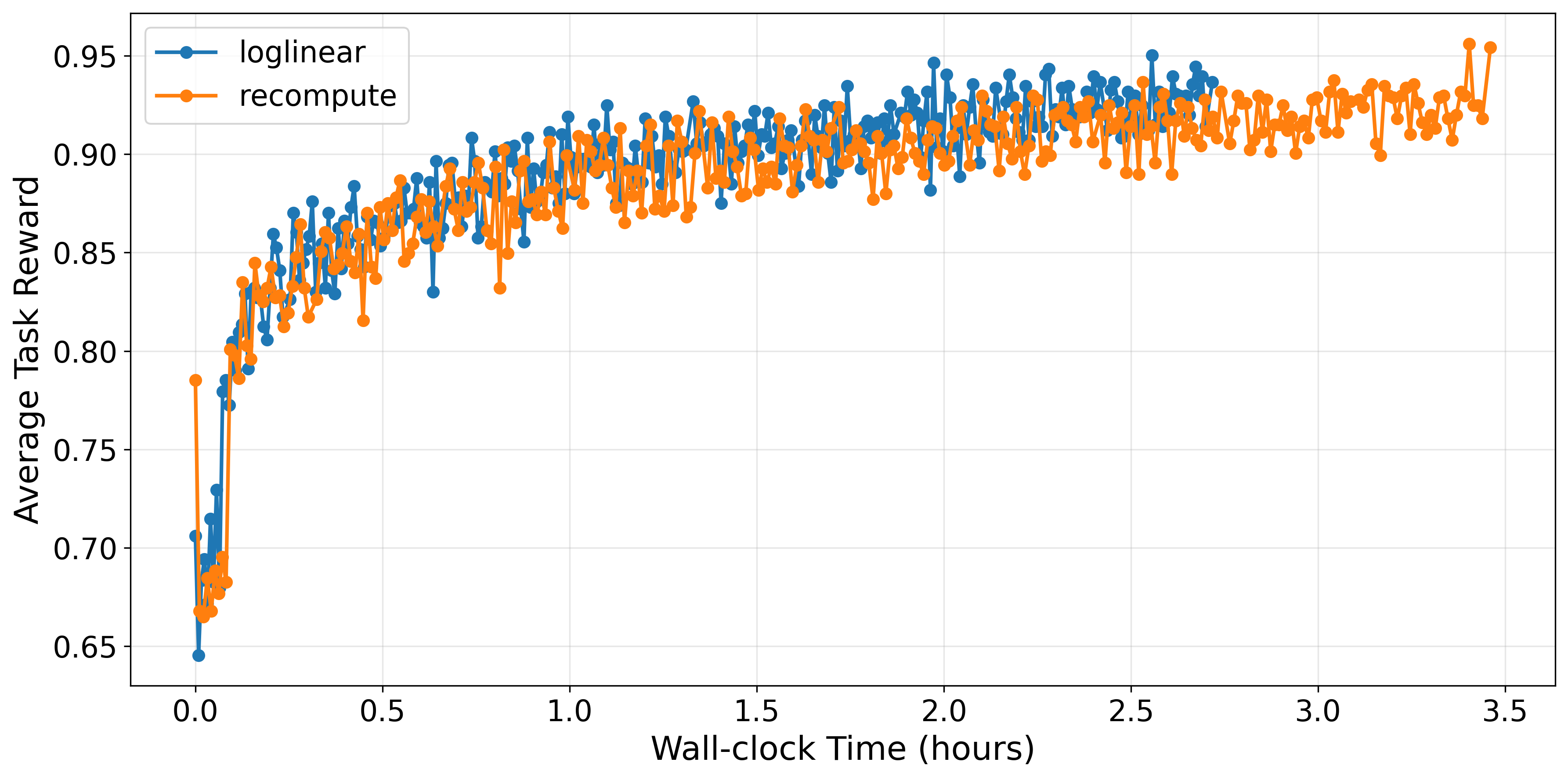
Figure 2: Training on GSM8K shows loglinear delivers 27% faster convergence without compromising final average reward.
Training Stability and Policy Properties
The loglinear proximal policy preserves the stabilizing effects of decoupled loss. Empirical results validate that entropy trajectories for both loglinear and recompute methods remain robust, with the loglinear anchor maintaining slightly higher entropy—indicative of greater exploration propensity.
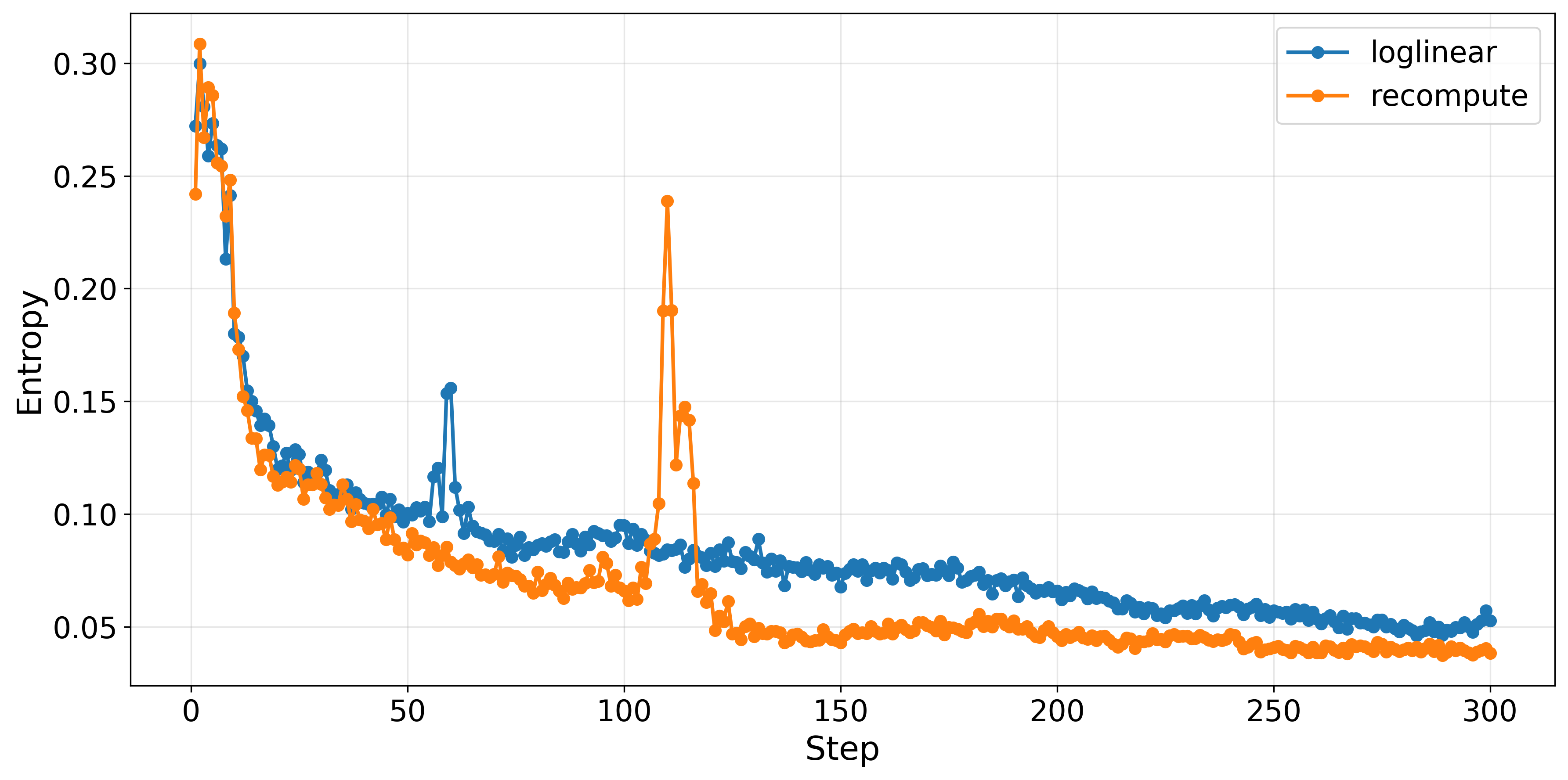
Figure 3: Policy entropy attenuates similarly for both methods throughout training; loglinear sustains higher entropy values beneficial for exploration.
Importantly, importance weights—used for off-policy correction—are less extreme in the loglinear paradigm, with lower maxima and higher minima, enhancing stability and mitigating high-gradient outliers.
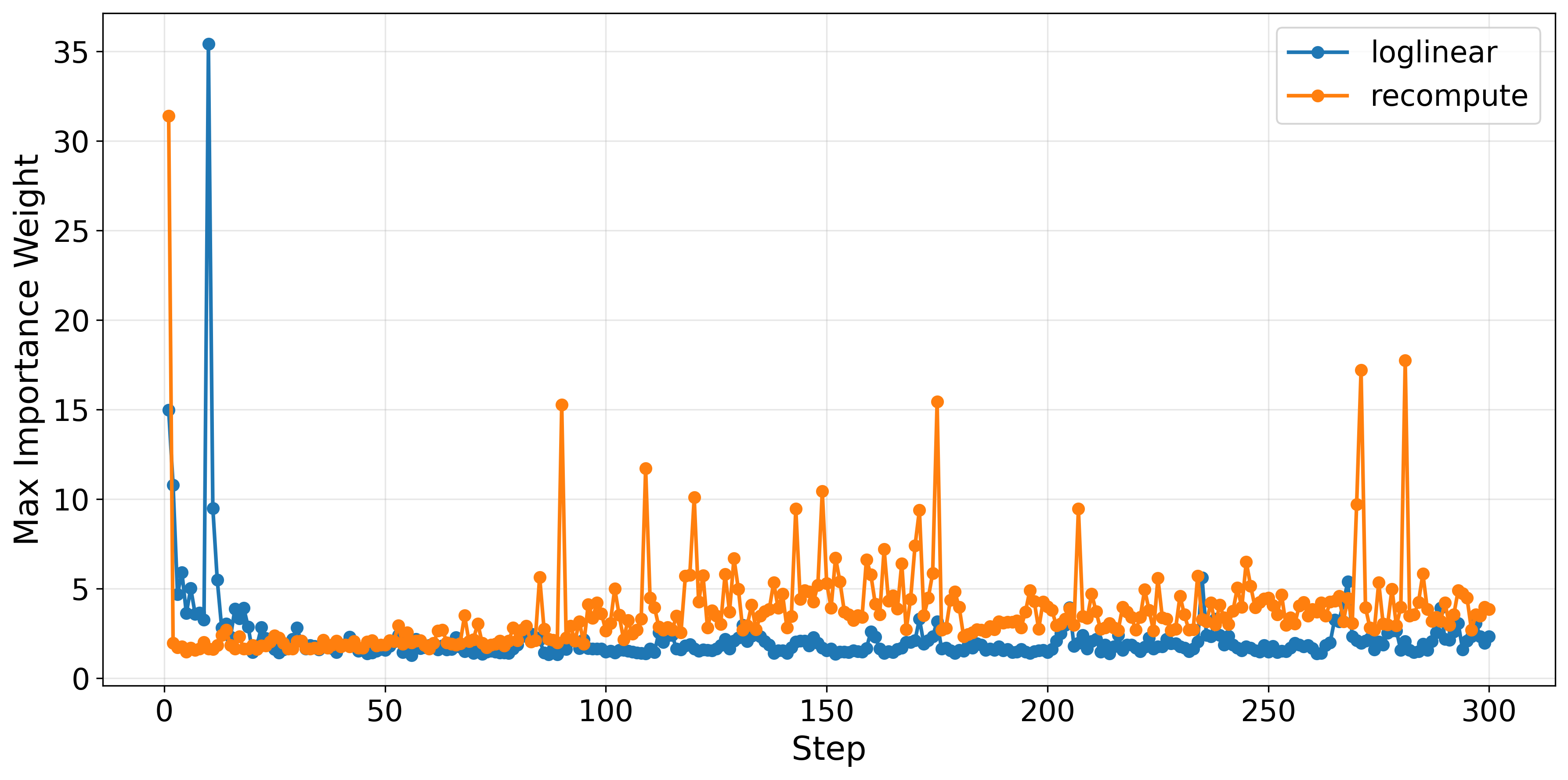
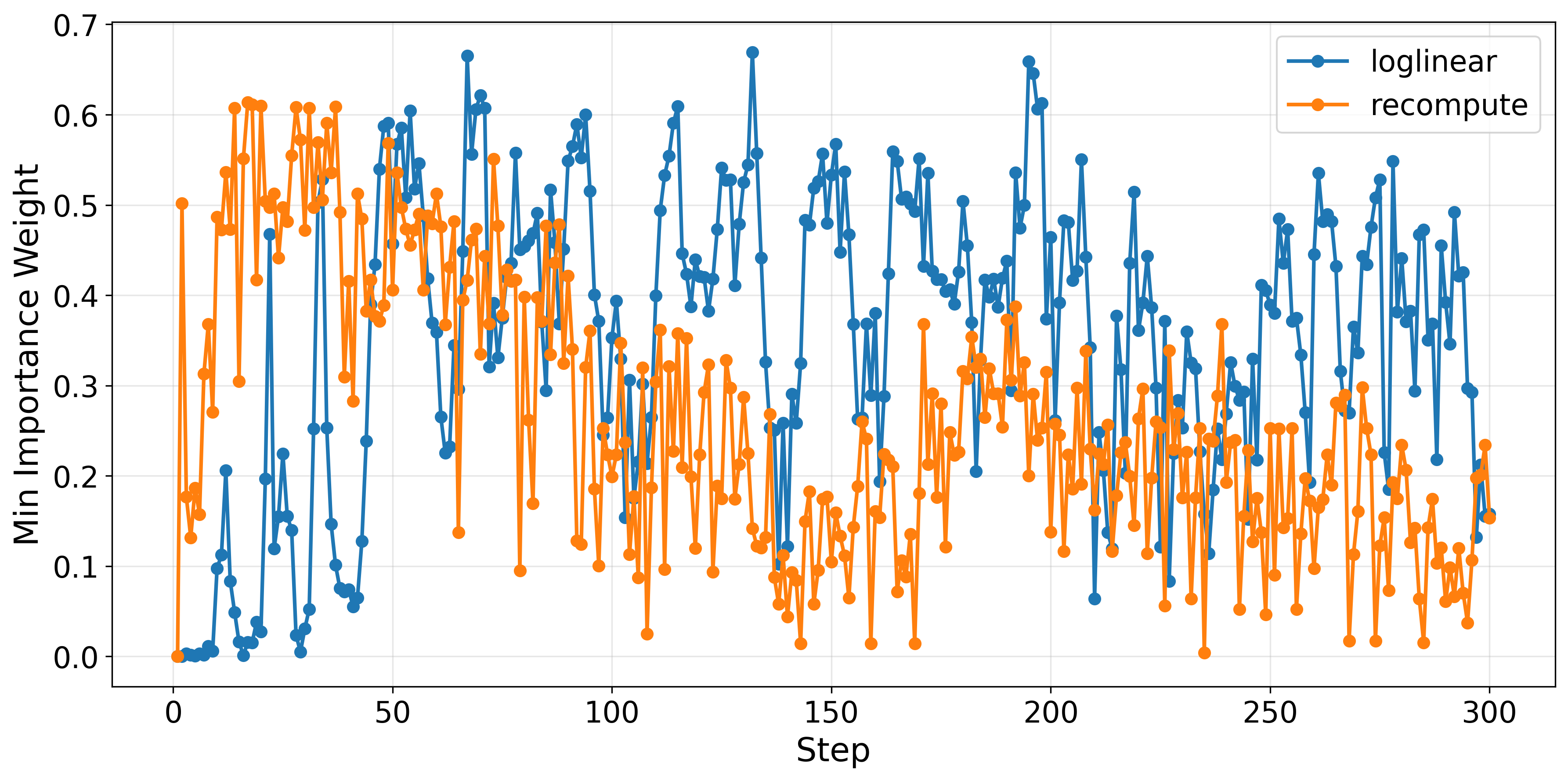
Figure 4: Loglinear proximal policy keeps importance weights well-behaved, reducing the risk of destabilization from extreme off-policy corrections.
Additionally, the loglinear approach results in 6× fewer clipped tokens per training step, meaning policy updates more reliably stay within trust region limits and require less aggressive clipping—enhancing sample efficiency.
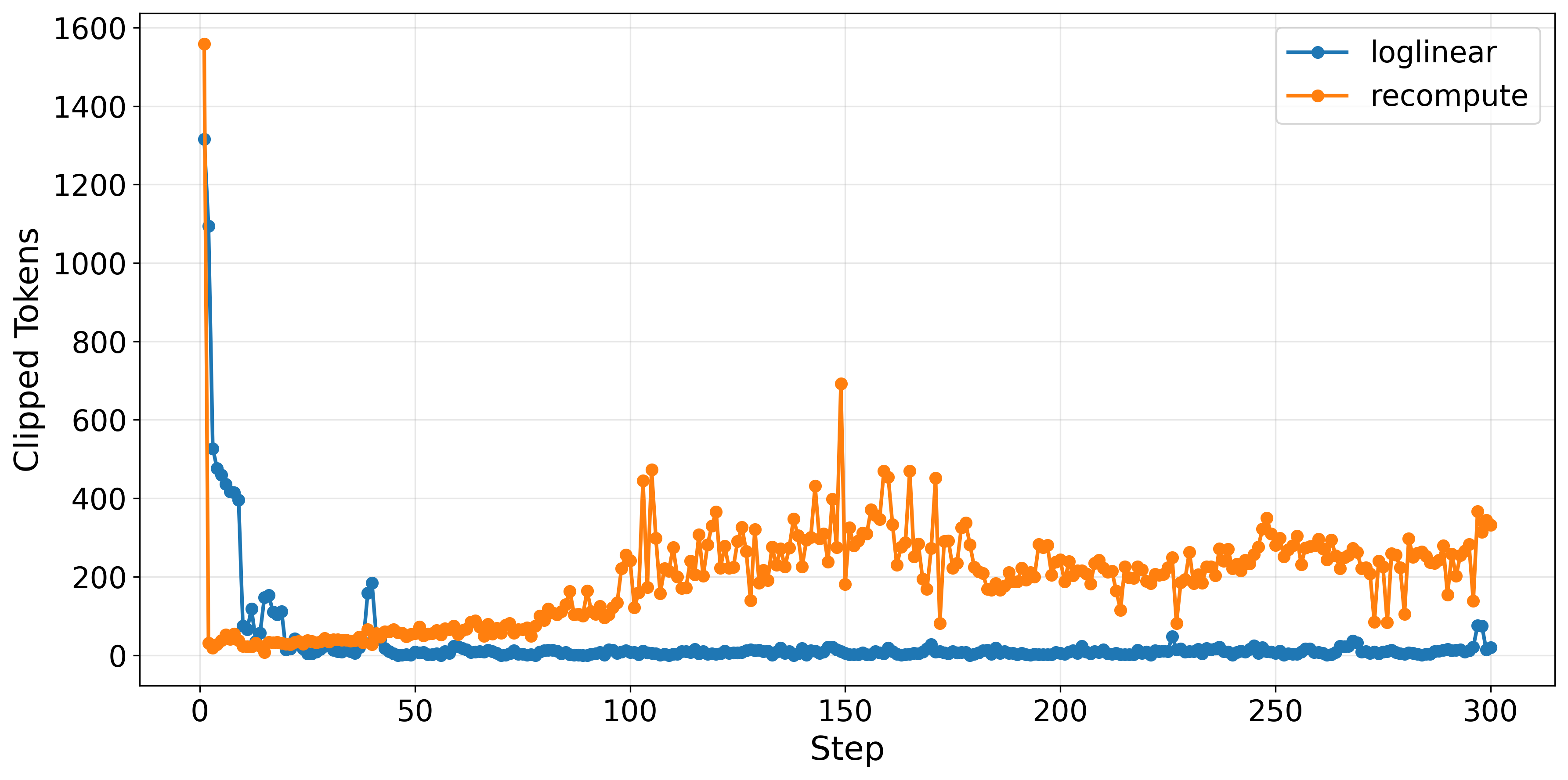
Figure 5: Clipped token analysis highlights that loglinear anchors induce fewer constraint violations, supporting smooth and stable optimization steps.
Practical and Theoretical Implications
A-3PO provides a computationally scalable mechanism for stabilizing asynchronous RL in large-scale LLM post-training, removing the major bottleneck associated with explicit proximal policy computation. The approach is fully compatible with any decoupled loss optimization protocol beyond PPO and is amenable to integration in distributed and parallel RL frameworks (c.f. [fu2025areal], [feng2025mindspeedrldistributeddataflow]). By reducing computational costs while maintaining stability, it enables efficient RLHF-style reasoning improvements for models with large parameter counts.
From a theoretical standpoint, the analysis challenges the necessity of explicit neural computation in trust region formation. The proven equivalence of interpolated log-probabilities to effective proximal policies under varying staleness regimes suggests broader applicability for approximate anchors in constrained optimization paradigms—potentially informing future advances in off-policy RL, variance reduction, and policy regularization.
As model scaling and algorithmic throughput demands escalate, staleness-aware, computation-avoiding approximations are expected to become integral to large-scale RL systems, both in language and non-language domains.
Conclusion
The A-3PO algorithm delivers an efficient and principled solution for proximal policy approximation in asynchronous RL for LLMs, leveraging staleness-aware loglinear interpolation to sidestep expensive forward passes. Empirical evaluation demonstrates its ability to retain task performance and stability while delivering substantial wall-clock speedup and improved sample efficiency. The method's generalizability and computational tractability position it as a valuable tool for next-generation RL-based LLM optimization pipelines and distributed training systems.