Stabilizing Reinforcement Learning with LLMs: Formulation and Practices
Abstract: This paper proposes a novel formulation for reinforcement learning (RL) with LLMs, explaining why and under what conditions the true sequence-level reward can be optimized via a surrogate token-level objective in policy gradient methods such as REINFORCE. Specifically, through a first-order approximation, we show that this surrogate becomes increasingly valid only when both the training-inference discrepancy and policy staleness are minimized. This insight provides a principled explanation for the crucial role of several widely adopted techniques in stabilizing RL training, including importance sampling correction, clipping, and particularly Routing Replay for Mixture-of-Experts (MoE) models. Through extensive experiments with a 30B MoE model totaling hundreds of thousands of GPU hours, we show that for on-policy training, the basic policy gradient algorithm with importance sampling correction achieves the highest training stability. When off-policy updates are introduced to accelerate convergence, combining clipping and Routing Replay becomes essential to mitigate the instability caused by policy staleness. Notably, once training is stabilized, prolonged optimization consistently yields comparable final performance regardless of cold-start initialization. We hope that the shared insights and the developed recipes for stable RL training will facilitate future research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A kid-friendly summary of “Stabilizing Reinforcement Learning with LLMs: Formulation and Practices”
What is this paper about?
This paper looks at how to safely and steadily train LLMs using reinforcement learning (RL). In RL, the model tries things and gets a “reward” for good answers. The problem: rewards are usually given for the whole answer (the full sentence or paragraph), but the model is trained by nudging the probability of each word it writes. The authors explain when and why this “word-by-word training” can still correctly improve “whole-answer rewards,” and they share practical tricks to make training stable—especially for a special kind of model called a Mixture-of-Experts (MoE).
What questions are the researchers trying to answer?
The paper focuses on three big questions, described in everyday terms:
- Is it okay to train an LLM word-by-word if the grade (reward) is based on the entire answer?
- What needs to be true for this word-by-word shortcut to work well?
- Which practical techniques keep RL training stable, especially for MoE models that “route” tokens to different expert parts of the model?
How did they approach the problem?
Think of an LLM writing an essay:
- The teacher gives a single grade for the whole essay (sequence-level reward).
- But the writing coach adjusts how likely the student is to use each word (token-level updates).
The paper shows that training on each word can be a good “first-order approximation,” which you can think of as a small-step shortcut that works if things don’t change too much.
Two things must be kept small for this shortcut to hold:
- Training–inference discrepancy: Imagine using two calculators—one during training and one during testing—that sometimes give slightly different results. If they disagree too much, training becomes shaky.
- Policy staleness: If you collect examples using an older version of the model and then train a much newer version on them, you’re teaching with stale data. The bigger the gap, the riskier the training.
To keep things fair, they use a tool called importance sampling. In simple terms, it gives “fairness weights” to each example so that data collected under slightly different conditions still teaches the right lesson. They also use clipping, a “speed limit” that stops the model from changing too much at once.
For Mixture-of-Experts (MoE) models (which are like teams of specialists where only a few experts are chosen for each word), the authors test “Routing Replay”—a way to fix which experts are used during training, so the training matches what happened when the text was generated. They try two versions:
- R2 (Vanilla Routing Replay): Reuse the experts chosen by the training system during rollout.
- R3 (Rollout Routing Replay): Reuse the experts chosen by the inference system during rollout.
Both aim to reduce mismatch and staleness, but they can also introduce a small “bias” because they force the model to stick with past routing choices instead of using the naturally chosen experts every time.
They validate all this with large-scale experiments:
- A big 30B-parameter MoE model
- Math reasoning tasks (like AIME and HMMT)
- Many training settings, including “on-policy” (train on data from the current model) and “off-policy” (reuse old data for multiple updates to speed up training)
- Extra diagnostics like entropy (how uncertain the model is) and KL divergence (how different the two “calculators” are)
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
- When training on fresh data from the current model (on-policy), the simplest approach works best:
- Basic policy gradient (REINFORCE) with importance sampling correction gave the most stable and best results.
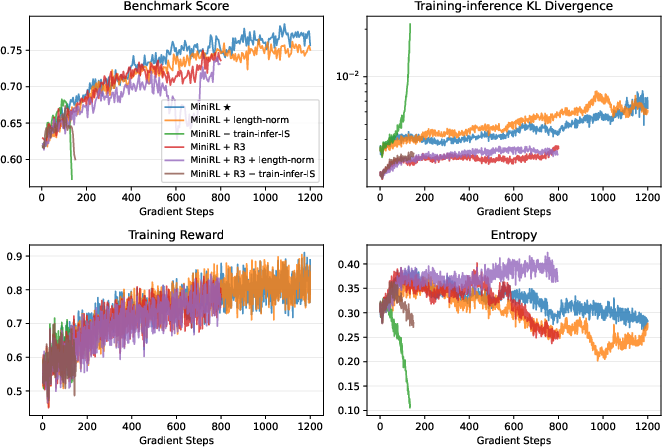
- If you skip the importance sampling correction, training can crash.
- Normalizing by sequence length (dividing by the number of tokens) sounded reasonable but actually hurt performance.
- For on-policy, R3 didn’t help and sometimes made things worse.
- When reusing old data to train faster (off-policy), two tools become essential:
- Clipping: a “speed limit” to prevent drastic updates.
- Routing Replay (R2 or R3): to reduce mismatch and keep the first-order shortcut valid.
- Which replay works better depends on “how off-policy” you are:
- With a small amount of off-policy updates, R2 tended to perform better.
- With a lot of off-policy updates, R3 tended to be more stable and better overall.
- Once training is stable, the starting point matters less:
- After long enough training, different initializations (different “cold starts”) ended up with similar final performance.
- This suggests it’s more important to make RL stable than to obsess over the starting data.
Why is this important for the future?
This work gives both a clear theory and a set of practical recipes for training LLMs with RL without crashes or weird behavior:
- Theory: It clarifies when word-by-word training can safely optimize whole-answer rewards—when you keep training–inference mismatch and staleness small.
- Practice: It offers concrete tips for stable training:
- Always use importance sampling correction for training–inference mismatch.
- Use clipping to limit overly aggressive updates.
- For MoE models, use Routing Replay:
- Prefer R2 when doing a small number of off-policy updates.
- Prefer R3 when doing many off-policy updates.
The big picture: if you stabilize RL training, you can reliably push LLMs to get better over time, and the exact choice of starting point matters less. That means future research can focus on better RL and scaling strategies rather than worrying too much about how the model was initialized.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, framed as concrete and actionable directions for future research:
- Absence of formal error bounds: quantify the approximation error between the token-level surrogate gradient and the true sequence-level gradient as a function of training–inference KL and policy staleness; derive sufficient conditions (thresholds) under which the first-order approximation is provably valid.
- No operational metric for “policy staleness”: define and measure staleness at sequence and token levels (e.g., per-token KL, ratio drift across minibatches, update lag) and connect it empirically/theoretically to stability; use these metrics to drive adaptive training (e.g., dynamic clipping, minibatch scheduling).
- Limited treatment of training–inference discrepancy: go beyond a global KL; measure and decompose sources (precision mismatches, kernel non-determinism, batching effects) into actionable components (e.g., “routing disagreement rate”, per-layer drift) and evaluate mitigation strategies.
- Unquantified bias from Routing Replay (R2/R3): analytically and empirically quantify the bias introduced by fixing routed experts; develop correction terms (e.g., reweighting by gating probabilities) or alternative replay schemes that reduce bias while preserving stability.
- No exploration of IS estimator variants: evaluate per-decision importance sampling, V-trace, clipped IS, and doubly robust estimators at token level (dense and MoE) under varying staleness/discrepancy; characterize bias–variance trade-offs and provide guidance for thresholding (currently set to 5 without analysis).
- Unclear generality beyond math binary rewards: test the formulation and recipes on non-binary, noisy, or learned reward models (RLHF, multi-aspect rewards), different domains (coding, reasoning, open-ended generation), and multilingual settings to assess robustness and transfer.
- Incomplete comparison to sequence-level optimization: directly compare token-level surrogate training to sequence-level objectives (e.g., GSPO, self-critical sequence training) with variance reduction (control variates) to identify regimes where sequence-level methods outperform.
- Heuristic hyperparameters without sensitivity study: systematically ablate and model the effects of reward normalization method, clipping thresholds (ε_high, ε_low), IS truncation level, generation length, and batch/mini-batch ratios; design adaptive tuning rules driven by discrepancy/staleness metrics.
- Synchronous-only experiments: evaluate the framework under asynchronous RL (multiple model versions generating a single response), replay buffers, and more aggressive off-policy pipelines; design principled corrections for increased staleness.
- Missing MoE routing diagnostics: measure routing agreement between training and inference engines (per-token expert overlap), gating probability drift, load balancing changes during RL, and their correlation with instability; use these signals to design gating temperature/noise regularizers or routing-stability constraints.
- No explicit regularization beyond clipping: study entropy regularization and KL constraints (to previous policies or reference models) as stabilizers; develop adaptive regularizers that respond to real-time staleness/discrepancy metrics.
- Implementation practicality of Routing Replay: quantify memory/time overhead of storing and replaying routed experts, especially for long sequences and large batches; propose efficient representations and caching strategies.
- Reproducibility and variance: report code, seeds, and run-to-run variance; perform statistical significance testing across multiple seeds to ensure observed stability/performance trends are robust.
- Adaptive off-policy scheduling: develop controllers that adjust global-to-mini-batch ratios and number of updates per rollout based on monitored staleness/discrepancy to keep the approximation valid and prevent collapse.
- Precision effects not isolated: systematically compare FP8 vs BF16 inference and matched training–inference precisions (and kernel choices) to isolate how numerical mismatch affects stability and the utility of R2/R3.
- Credit assignment without value models: explore token-weighting strategies (e.g., focusing on answer spans, step-wise rewards, reward shaping) that improve credit assignment while avoiding value models; compare to stabilized value-based methods under the same framework.
- Correct IS weights for MoE with routing changes: derive and test IS formulations that explicitly include gating probability ratios when routed experts differ (training vs inference, old vs new policy), and assess their practical variance.
- Long-term impact of Routing Replay on expert specialization: examine whether fixing routed experts induces expert underutilization or hampers specialization/diversification; track expert-level metrics over long training.
- Scaling laws and limits: characterize how stability and final performance scale with model size, number of experts, dataset size, and generation length; identify bottlenecks and diminishing returns in stabilized RL.
- Multi-stage/curriculum RL: test whether the first-order approximation remains valid under distribution shifts across stages; develop stage-aware stabilizers and switching criteria.
- Convergence guarantees: provide theoretical convergence analysis for MiniRL with IS correction and clipping under bounded discrepancy/staleness; identify failure modes or counterexamples.
- Robustness and safety: evaluate whether stabilized training (IS + clipping + routing replay) affects susceptibility to adversarial prompts, reward hacking, or mode collapse in broader settings; add robustness diagnostics.
- Broader evaluation suite: expand beyond 90 competition problems and 4,096 training prompts to diverse, larger-scale benchmarks; measure generalization, sample efficiency, and stability across datasets.
- Engine-level mitigation strategies: propose and benchmark inference/training engine changes (deterministic kernels, batch-invariant operations, precision harmonization) to systematically reduce training–inference discrepancy without algorithmic bias.
Glossary
- Advantage estimate: A variance-reduced estimate of the reward advantage used to weight updates per response. "First, we apply group-normalization \citep{grpo} to the raw rewards as the advantage estimate for each response : , which also lowers the variance of the raw rewards."
- Autoregressive LLM: A LLM that generates tokens sequentially, each conditioned on previous context. "We define an autoregressive LLM parameterized by as a policy ."
- Batch-invariant kernels: Deterministic compute kernels whose outputs do not depend on batch composition; often disabled to maximize inference throughput. "Even within a single engine, particularly the inference side, batch-invariant kernels \citep{he2025nondeterminism} are often disabled for maximizing throughput, so the same model input can still receive variant outputs."
- BF16 training: Training in bfloat16 precision, commonly used for efficiency and stability in large-model training. "We adopt the setting of FP8 inference and BF16 training, providing a stress test for algorithmic correctness where the inference precision is lower than the training and the trainingâinference discrepancy is large."
- CISPO: A specific RL objective with clipping and normalization variants; compared against the proposed MiniRL. "We compare the optimization objective of MiniRL against those of GRPO \citep{grpo} and CISPO \citep{minimax-m1}."
- Clipping: A mechanism that limits update magnitudes or ratios to prevent overly aggressive policy changes. "the clipping mechanism can restrain policy staleness by preventing aggressive policy updates;"
- Cold-start initialization: Initializing RL training from a supervised or distilled model state prior to RL fine-tuning. "Notably, once training is stabilized, prolonged optimization consistently yields comparable final performance regardless of cold-start initialization."
- Decoupled PPO: A PPO variant that uses a fixed proximal policy to decide clipping independently from the main objective. "We follow the decoupled PPO approach \citep{hilton2022batch} and use as the proximal policy to decide whether to clip the token based on the ratio of and "
- Entropy: A measure of uncertainty in the policy’s token distribution, monitored during training. "including the training-inference KL divergence and entropy reported in our later experiments (\S~\ref{sec:exp})."
- Expert routing: The mechanism in MoE models that selects which experts to activate for each token. "MoE models dynamically select and activate only a small subset of expert parameters via the expert routing mechanism."
- First-order approximation: An approximation that linearizes the target objective, enabling a token-level surrogate to optimize a sequence-level reward. "Specifically, through a first-order approximation, we show that this surrogate becomes increasingly valid only when both the trainingâinference discrepancy and policy staleness are minimized."
- FP8 inference: Inference performed in 8-bit floating point precision for higher throughput, potentially increasing discrepancies from training. "We adopt the setting of FP8 inference and BF16 training, providing a stress test for algorithmic correctness where the inference precision is lower than the training and the trainingâinference discrepancy is large."
- FSDP: Fully Sharded Data Parallel, a training engine for distributed large-model training. "Since the responses are typically not sampled in the training engine (e.g., Megatron and FSDP) but instead in the inference engine (e.g., SGLang and vLLM)"
- GRPO: A group-based RL optimization objective that applies length normalization and clipping. "However, mainstream RL algorithms, such as REINFORCE and GRPO, typically employ token-level optimization objectives."
- Group-normalization: Normalizing rewards within a group of responses to reduce variance and stabilize training. "First, we apply group-normalization \citep{grpo} to the raw rewards as the advantage estimate for each response ..."
- Importance sampling (IS): A reweighting technique to correct for sampling from a different policy or engine than the target policy. "we adopt the importance sampling (IS) trick to do a simple transformation:"
- Importance sampling correction: Applying IS weights in the objective or gradient to account for rollout-training discrepancies. "for on-policy training, the basic policy gradient algorithm with importance sampling correction achieves the highest training stability."
- KL divergence: A measure of difference between two probability distributions, here monitoring training–inference mismatch. "including the training-inference KL divergence and entropy reported in our later experiments (\S~\ref{sec:exp})."
- LLMs: High-capacity models trained on vast corpora, often optimized further with RL. "Reinforcement learning (RL) has become a key technical paradigm for enhancing LLMs' (LLMs) ability to tackle complex problem-solving tasks"
- Length normalization: Dividing objectives by sequence length; shown to bias the token-level objective relative to sequence-level goals. "We notice that existing RL algorithms, such as GRPO and CISPO, often employ length normalization in their optimization objectives"
- Megatron: A training engine/framework for large-scale transformer models. "Since the responses are typically not sampled in the training engine (e.g., Megatron and FSDP) but instead in the inference engine (e.g., SGLang and vLLM)"
- Mixture-of-Experts (MoE): Architectures that route tokens to subsets of expert networks to increase capacity efficiently. "When it comes to Mixture-of-Experts (MoE) models \citep{dpsk-r1,qwen3}, the conditions for the first-order approximation to hold become less straightforward."
- MiniRL: A minimalist baseline algorithm designed to align with the token-level surrogate objective and stabilize training. "The obtained minimalist baseline algorithm, which we call MiniRL, is as follows:"
- Off-policy updates: Multiple gradient updates using data sampled by an older or different policy, increasing staleness. "When off-policy updates are introduced to accelerate convergence, combining clipping and Routing Replay becomes essential to mitigate the instability caused by policy staleness."
- On-policy training: Training where the same policy both generates data and is updated from it (modulo engine discrepancies). "For on-policy training\footnote{ In this paper, we use the term on-policy to indicate that the rollout policy that samples responses is identical to the target policy to be optimized using these responses (omitting the trainingâinference discrepancy), while off-policy indicates that the two policies are different. }, the basic policy gradient algorithm with importance sampling correction yields the highest training stability;"
- Policy gradient: A class of RL methods that optimize policies via gradients of expected rewards. "This paper proposes a novel formulation for reinforcement learning (RL) with LLMs, explaining why and under what conditions the true sequence-level reward can be optimized via a surrogate token-level objective in policy gradient methods such as REINFORCE."
- Policy staleness: The discrepancy between the rollout policy that generated data and the current target policy being optimized. "Regarding policy stalenessâi.e., the discrepancy between the rollout policy that samples responses and the target policy to be optimizedâit usually arises from the trade-offs made to improve training efficiency and computational utilization."
- PPO: Proximal Policy Optimization, an RL algorithm that constrains updates via clipping and a proximal objective. "We do not consider the value-based setting (e.g., PPO, \citealt{ppo}), where policy optimization is steered by a value model..."
- Proximal policy: The reference (old) policy used by PPO-like methods to determine clipping thresholds for updates. "We follow the decoupled PPO approach \citep{hilton2022batch} and use as the proximal policy to decide whether to clip the token ..."
- REINFORCE: A classic Monte Carlo policy gradient algorithm using returns (or rewards) to weight log-prob gradients. "However, mainstream RL algorithms, such as REINFORCE and GRPO, typically employ token-level optimization objectives."
- Rollout policy: The policy that generates responses for training; may differ between engines or versions. "where denotes the rollout policy that samples responses."
- Rollout Routing Replay (R3): A routing replay variant that reuses inference-engine routing during training to reduce discrepancies and staleness. "Rollout Routing Replay (R3) \citep{r3} aims to reduce the impact of expert routing on the trainingâinference discrepancy by uniformly replaying, within the training engine, the routed experts determined by the rollout policy in the inference engine (i.e., )"
- Routing Replay: Techniques that fix expert routing during optimization in MoE models to stabilize training. "including importance sampling correction, clipping, and particularly Routing Replay for Mixture-of-Experts (MoE) models."
- SGLang: An inference engine used to sample responses for RL with LLMs. "responses are typically not sampled in the training engine (e.g., Megatron and FSDP) but instead in the inference engine (e.g., SGLang and vLLM)"
- Sequence-level IS weight: The importance sampling ratio at the whole-response level correcting for rollout vs target policy. "\underbrace{ \frac{ \pi_\theta ( y | x ) }{ \mu_{ \theta_\text{old} } ( y | x ) } }_\text{sequence-level IS weight} R(x, y)"
- Sequence-level reward: A scalar score assigned to an entire generated response rather than to individual tokens. "Due to the contextual nature of language, RL with LLMs usually employs sequence-level rewards, i.e., a scalar score assigned based on the complete model response."
- Surrogate token-level objective: A token-wise optimization objective used to approximate the sequence-level reward maximization. "The key insight is that, to optimize the expected sequence-level reward, we can employ a surrogate token-level objective as its first-order approximation."
- Token-level IS weight: The importance sampling ratio computed per token to correct training updates. "\underbrace{ \mathrm{sg} \left[ \frac{ \pi_\theta ( y_t | x, y_{<t} ) }{ \mu_{ \theta_\text{old} } ( y_t | x, y_{<t} ) } \right] }\text{token-level IS weight} R(x, y) \, \log \pi\theta ( y_t | x, y_{<t} )"
- Truncated Importance Sampling (TIS): A technique that caps IS weights to reduce variance and stabilize learning. "We additionally apply the Truncated Importance Sampling (TIS) trick \citep{yao2025offpolicy} to the token-level IS weight in MiniRL, with the truncation threshold set to 5."
- Trainingâinference discrepancy: Numerical differences between training and inference engines that can cause output and routing mismatches. "Regarding the trainingâinference discrepancyâi.e., the numerical differences between training and inference enginesâthe causes are usually complex and heavily tied to the underlying infrastructure."
- Training-inference KL divergence: A diagnostic metric measuring the divergence between rollout distributions from inference and training engines. "including the training-inference KL divergence and entropy reported in our later experiments (\S~\ref{sec:exp})."
- Value-based setting: An RL approach using a value function to score tokens (e.g., PPO), contrasted with sequence-reward-only methods. "We do not consider the value-based setting (e.g., PPO, \citealt{ppo}), where policy optimization is steered by a value model that assigns scalar scores to each token in a response ."
- vLLM: An inference engine optimized for LLM serving and generation. "responses are typically not sampled in the training engine (e.g., Megatron and FSDP) but instead in the inference engine (e.g., SGLang and vLLM)"
- Vanilla Routing Replay (R2): A routing replay variant that reuses training-engine rollout routing to reduce staleness during optimization. "Vanilla Routing Replay (R2) \citep{gspo} focuses on mitigating the impact of expert routing on policy staleness by replaying, during gradient updates, the routed experts determined by the rollout policy in the training engine (i.e., )"
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s formulations and training recipes; they target industry, academia, policy, and everyday product teams working with LLMs.
- Stable RL training recipe for LLM products using MiniRL with importance sampling (IS) correction
- Sector: software (LLM platforms, copilots), education (tutoring), finance (analysis assistants), healthcare (clinical reasoning support)
- Potential tools/products/workflows: a “MiniRL” module in RLHF/RLAIF pipelines that implements token-level IS weights, group-normalized advantages, and decoupled PPO clipping; default hyperparameters and monitoring hooks
- Assumptions/dependencies: sequence-level rewards available; access to both training and inference logits; sufficient compute; base model quality; reward quality and variance suitable for group normalization
- Off-policy RL training for Mixture-of-Experts (MoE) models with clipping plus Routing Replay
- Sector: software (large-scale model training), cloud ML platforms
- Potential tools/products/workflows: Routing Replay operators (R2 and R3) with a scheduler that picks R2 for low off-policiness and R3 for high off-policiness; response-batch splitting logic; expert-routing trace capture
- Assumptions/dependencies: inference engine can export routed experts; willingness to manage bias introduced by replay; careful tuning of clipping thresholds; adequate logging and storage for routing traces
- Training–inference consistency monitoring to prevent RL collapse
- Sector: MLOps across all industries
- Potential tools/products/workflows: dashboards tracking training–inference KL divergence and policy entropy; alerts when entropy drops or KL spikes; automated rollback/workflow pause
- Assumptions/dependencies: reliable collection of per-token probabilities from both engines; standardized metrics across teams; thresholds calibrated to task and model
- IS correction layer in existing RLHF/RLAIF pipelines
- Sector: software (model providers, open-source training stacks)
- Potential tools/products/workflows: an “IS Corrector” module that computes token-level ratios between training and inference policies, with truncated importance sampling (TIS)
- Assumptions/dependencies: access to token probabilities from both engines; consistent tokenization; TIS threshold selection (e.g., 5)
- Determinism-first inference configurations to reduce training–inference discrepancy
- Sector: infrastructure (inference engines, hardware vendors)
- Potential tools/products/workflows: configurable kernels that prioritize determinism (batch-invariant kernels on), reproducibility modes, “deterministic inference” flags in serving stacks
- Assumptions/dependencies: potential throughput trade-offs; vendor support for kernel options; alignment with production latency requirements
- Batch scheduling to minimize policy staleness in synchronous RL
- Sector: MLOps
- Potential tools/products/workflows: scheduling policies that limit the number of gradient updates per rollout batch; micro-batching strategies; adaptive off-policiness settings
- Assumptions/dependencies: synchronous RL framework; compute budget considerations; task-dependent staleness tolerance
- Migration guidance for GRPO/CISPO users
- Sector: software (teams currently using GRPO/CISPO)
- Potential tools/products/workflows: checklists to remove length normalization, add IS correction, enable clipping in token-level objectives; recipe cards with example code
- Assumptions/dependencies: ability to modify training objectives; acceptance of slight redesign of losses; validation on internal tasks
- MoE expert routing logging and replay for reproducibility
- Sector: software (MoE model training), academia (replicable experiments)
- Potential tools/products/workflows: expert routing trace capture pipelines; replay utilities to fix routed experts in training; APIs for inference→training trace transfer
- Assumptions/dependencies: inference engine supports exporting per-token expert choices; storage overhead for long sequences; privacy/security controls if routing traces contain sensitive context
- Reward normalization and clipping best practices
- Sector: software; academia (experiment baselines)
- Potential tools/products/workflows: reference implementation of group-normalized advantages and decoupled PPO clipping; task-aware clipping thresholds (εhigh≈0.27, εlow≈0.20 as starting points)
- Assumptions/dependencies: rewards are comparable across samples; normalization does not distort task signal; clipping criteria aligned with reward direction and ratio bounds
- Risk management in production RL updates
- Sector: policy/safety engineering; consumer apps (daily life)
- Potential tools/products/workflows: operational playbooks to pause training when entropy drops or KL spikes; canary rollouts; staged deployment of RL updates
- Assumptions/dependencies: clear stability criteria; observability in production; organizational readiness to halt training or revert models
Long-Term Applications
These applications require further research, scaling, and infrastructure development to fully realize the paper’s insights across sectors.
- Co-design of training and inference engines for low-discrepancy LLM pipelines
- Sector: infrastructure (engine developers, hardware vendors)
- Potential tools/products/workflows: unified numerical kernels and precision policies; cross-engine determinism standards; hardware-level support for consistent routing in MoE
- Assumptions/dependencies: vendor collaboration; acceptance of modest performance trade-offs; standardization efforts across ecosystem
- Adaptive, bias-aware Routing Replay strategies
- Sector: software research; academia
- Potential tools/products/workflows: dynamic replay policies that minimize bias while maintaining approximation validity; per-batch choice between R2 and R3 driven by metrics (KL, entropy, off-policiness)
- Assumptions/dependencies: reliable bias estimation; fast metric computation; task-specific heuristics or learned policies
- Staleness-aware schedulers for asynchronous RL
- Sector: MLOps; software platforms
- Potential tools/products/workflows: schedulers that limit policy version drift within a response; per-response version pinning; staleness budgets enforced by orchestration layers
- Assumptions/dependencies: orchestration changes to serving architecture; maintaining high throughput; telemetry resolution to tag responses with policy versions
- General-purpose stable RL frameworks beyond math reasoning and MoE
- Sector: academia; cross-domain industry (healthcare, finance, robotics, energy)
- Potential tools/products/workflows: task-agnostic RL with sequence-level rewards, robust to sparse/noisy feedback; extensions to multimodal policies; safe reward shaping methods
- Assumptions/dependencies: high-quality sequence-level rewards in each domain; domain-specific validation; safety and compliance requirements
- Certified RL training for safety-critical deployments
- Sector: healthcare, finance, energy, public sector
- Potential tools/products/workflows: audits and certifications for training stability (KL/entropy bounds); regulatory reporting of training regimes; incident response frameworks tied to stability metrics
- Assumptions/dependencies: regulator engagement; standard benchmarks for stability; reproducible training logs and traces
- Automatic off-policiness tuner
- Sector: software; MLOps
- Potential tools/products/workflows: an “OffPolicyTuner” that dynamically adjusts global batch size vs. mini-batch size and selects R2/R3 based on live metrics; autotuning of clipping thresholds
- Assumptions/dependencies: robust metric pipelines; policy selection heuristics; guardrails against oscillatory behavior
- Value-model alternatives or complements that preserve stability
- Sector: academia; software
- Potential tools/products/workflows: sequence-level reward estimation methods that avoid unreliable token-wise value models; semi-supervised reward learners; hybrid advantage estimators
- Assumptions/dependencies: labeled or weakly labeled datasets; careful validation to prevent reward hacking; scalability to long contexts
- Multi-agent and robotics integrations
- Sector: robotics; autonomous systems; gaming
- Potential tools/products/workflows: LLM planners trained with stable sequence-level RL; multi-agent coordination with staleness control; routing replay analogs for modular architectures
- Assumptions/dependencies: environment-level sequence rewards; safe exploration constraints; real-time inference consistency
- Low-compute stable RL recipes for smaller organizations
- Sector: startups; education; NGOs
- Potential tools/products/workflows: distilled versions of MiniRL with lightweight IS correction and routing replay for smaller models; community-curated hyperparameter sets
- Assumptions/dependencies: reduced model sizes; careful reward design; trade-offs in peak performance vs. stability
- Open-source “StableRL for LLMs” library and community standards
- Sector: software; academia; policy
- Potential tools/products/workflows: a reference library implementing MiniRL, IS correction, clipping, R2/R3, metric monitoring, and routing trace APIs; stability reporting standards for published models
- Assumptions/dependencies: broad adoption; governance for standards; contributions from engine developers to support determinism and routing exports
Collections
Sign up for free to add this paper to one or more collections.