Soft Adaptive Policy Optimization
Abstract: Reinforcement learning (RL) plays an increasingly important role in enhancing the reasoning capabilities of LLMs, yet stable and performant policy optimization remains challenging. Token-level importance ratios often exhibit high variance-a phenomenon exacerbated in Mixture-of-Experts models-leading to unstable updates. Existing group-based policy optimization methods, such as GSPO and GRPO, alleviate this problem via hard clipping, making it difficult to maintain both stability and effective learning. We propose Soft Adaptive Policy Optimization (SAPO), which replaces hard clipping with a smooth, temperature-controlled gate that adaptively attenuates off-policy updates while preserving useful learning signals. Compared with GSPO and GRPO, SAPO is both sequence-coherent and token-adaptive. Like GSPO, SAPO maintains sequence-level coherence, but its soft gating forms a continuous trust region that avoids the brittle hard clipping band used in GSPO. When a sequence contains a few highly off-policy tokens, GSPO suppresses all gradients for that sequence, whereas SAPO selectively down-weights only the offending tokens and preserves the learning signal from the near-on-policy ones, improving sample efficiency. Relative to GRPO, SAPO replaces hard token-level clipping with smooth, temperature-controlled scaling, enabling more informative and stable updates. Empirical results on mathematical reasoning benchmarks indicate that SAPO exhibits improved training stability and higher Pass@1 performance under comparable training budgets. Moreover, we employ SAPO to train the Qwen3-VL model series, demonstrating that SAPO yields consistent performance gains across diverse tasks and different model sizes. Overall, SAPO provides a more reliable, scalable, and effective optimization strategy for RL training of LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train LLMs using reinforcement learning (RL). The goal is to help LLMs reason better (for example, solve math problems, write code, or explain logic) while keeping training stable and effective. The new method is called Soft Adaptive Policy Optimization (SAPO). It replaces a common “hard clipping” trick with a smoother, smarter “soft gate” that keeps learning steady without throwing away useful signals.
What questions were they trying to answer?
In simple terms, the authors ask:
- How can we train LLMs with RL so they improve their reasoning, but don’t become unstable or get stuck?
- Can we avoid throwing away too much learning signal when the model makes unusual or risky changes?
- Can we design a method that keeps whole responses consistent while still reacting to individual words or tokens that go off-track?
How did they do it?
Here’s the basic idea of RL training for LLMs, explained with everyday language:
- Think of the model answering a question by writing a response one word at a time. Each word is a “token.”
- The training compares how the current model behaves with how the old model behaved. This comparison is called the “importance ratio”—basically, “how much did we change the probability of choosing this token?”
- If that ratio jumps around a lot (high variance), training can get unstable. This happens more in Mixture-of-Experts (MoE) models, where different “experts” handle different tokens, making changes uneven.
- Older methods like GRPO and GSPO use “hard clipping,” which is like a strict speed limit: if the change is too big, they instantly cut the update to zero. That keeps things safe, but often throws away useful learning, especially if just a few tokens are off.
SAPO changes the “hard limit” into a “soft dimmer.” Here’s how:
- Instead of cutting updates off suddenly, SAPO uses a smooth curve (a sigmoid function) to gently scale down the update when changes get too big. Imagine a dimmer switch that lowers the brightness, not an on/off light switch.
- This smooth scaling is controlled by a “temperature.” Higher temperature means faster damping. SAPO uses different temperatures for “positive” and “negative” updates:
- Positive updates (where the response was good) are damped gently.
- Negative updates (where the response was bad) are damped more strongly. Why? Because in a huge vocabulary, negative updates can accidentally raise the chance of many wrong tokens, which can destabilize training.
- SAPO is “sequence-coherent” and “token-adaptive”:
- Sequence-coherent: it respects the overall quality of the full answer (the whole sequence).
- Token-adaptive: if only a few words are off, it down-weights those specific words instead of throwing away the entire answer’s learning signal.
Compared with past methods:
- GRPO: Works per token but uses hard clipping—like a strict gate that shuts off updates outside a fixed range.
- GSPO: Works per sequence (the whole answer) with hard clipping—good for coherence but can throw away useful token-level information if just one token is extreme.
- SAPO: Uses a soft, temperature-controlled gate per token, but still lines up well with sequence-level goals. It keeps helpful signals and calms down risky ones.
What did they find and why does it matter?
The authors tested SAPO on math reasoning tasks and in training multimodal models (Qwen3-VL series, which handle text plus images). They found:
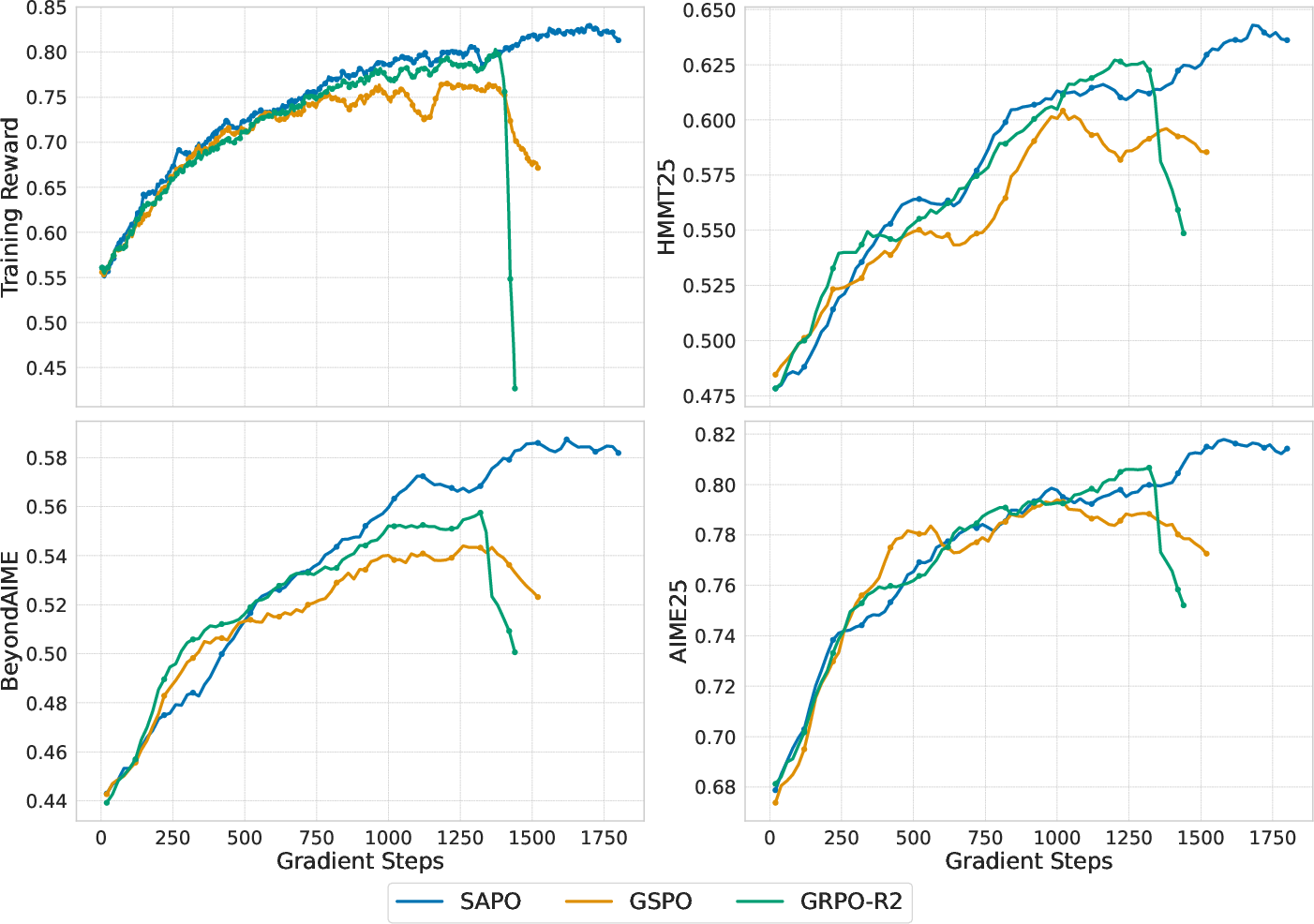
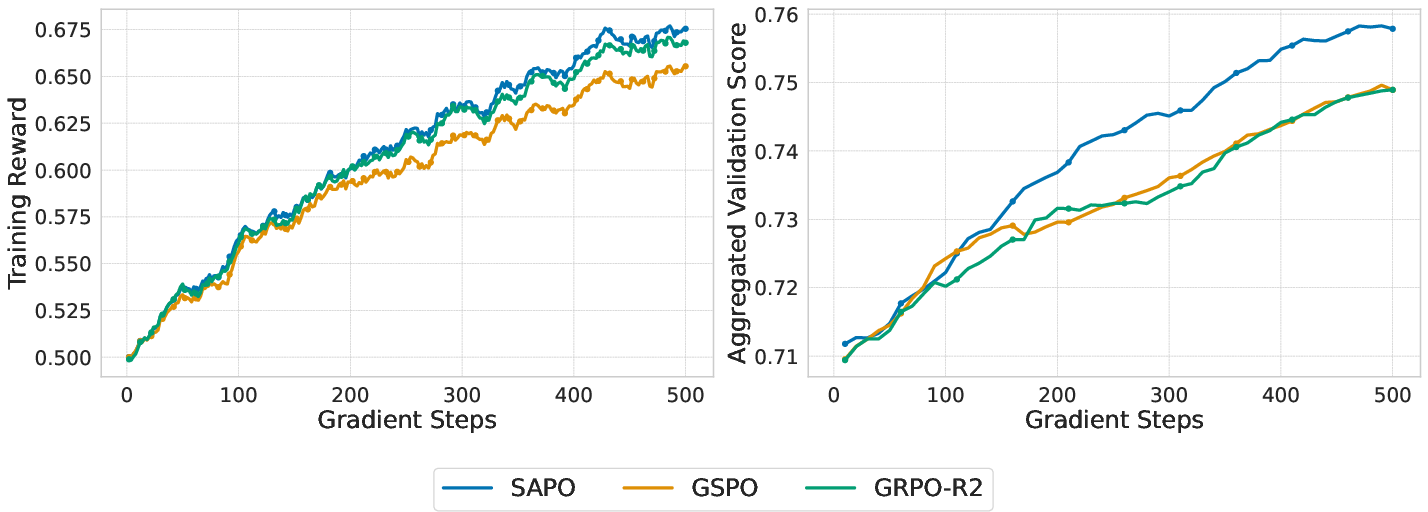
- Training is more stable: SAPO avoids early “training collapse” that can happen with hard clipping.
- Better performance: SAPO increases Pass@1 (the chance the model gets the right answer in one try) under similar training budgets.
- Works across sizes and architectures: SAPO improves models of different scales, including both dense models and MoE models.
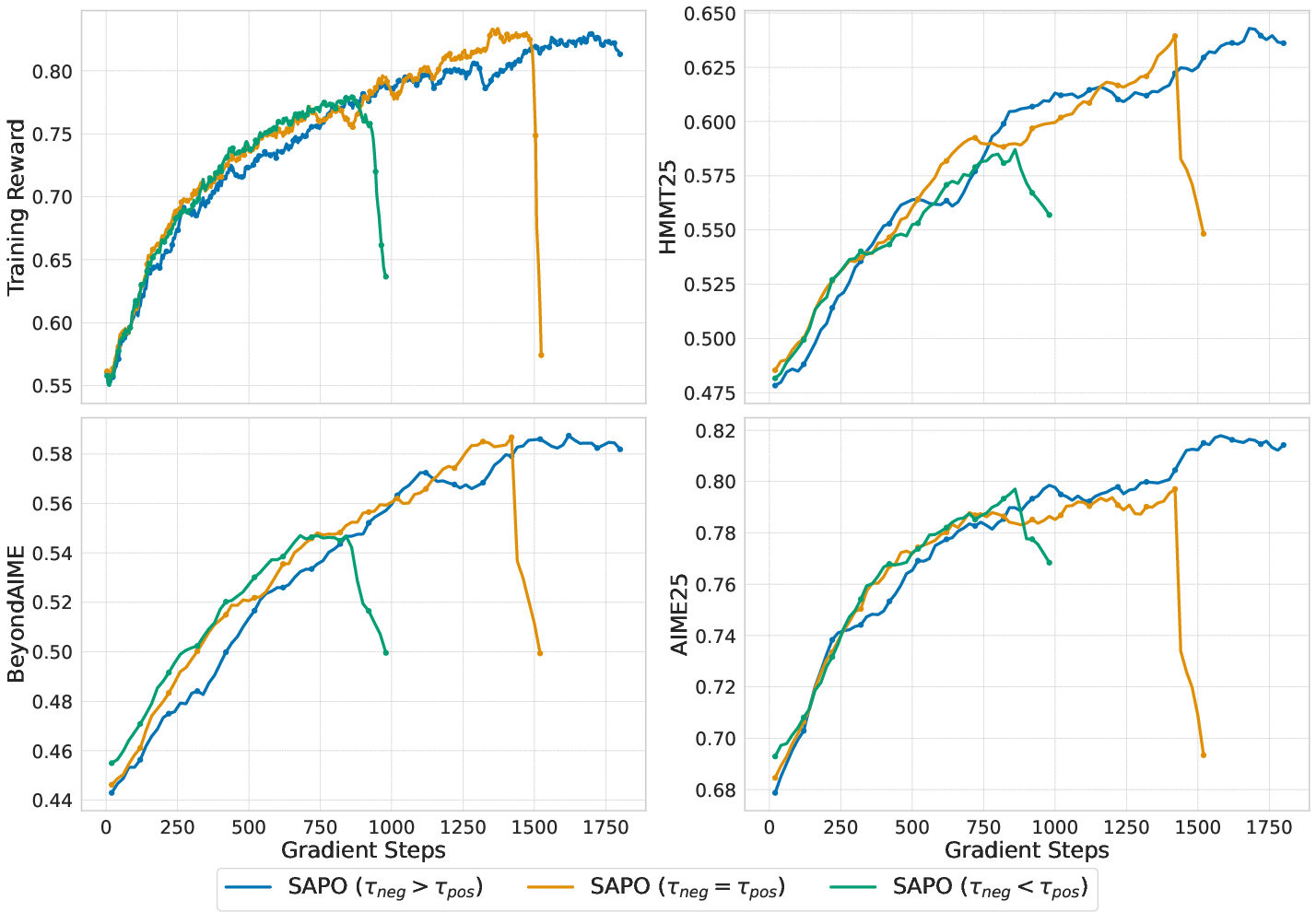
- Asymmetric temperatures help: Using a higher temperature for negative updates (i.e., damping negative updates more) makes training noticeably more stable.
Why this matters: In RL training for LLMs, keeping updates safe without killing learning is hard. SAPO’s smooth gate strikes a better balance—less noise, more useful signal—so models learn faster and more reliably.
Why this could be important going forward
- Stronger reasoning: If training stays stable, models can learn deeper, longer chains of thought for math, coding, and logic.
- Better sample efficiency: SAPO keeps useful parts of an answer even if a few words are off, so fewer training examples are wasted.
- Scalable and practical: Works on big models and across many tasks, which is essential in real-world training.
- Safer optimization: The soft gate acts like an adjustable “trust region” or safe zone, reducing both wild jumps and dead zones where learning stops.
In short, SAPO offers a smoother, smarter way to improve LLMs with RL. It helps models learn more from each training step while avoiding the brittle behavior caused by hard clipping. This could make the next generation of reasoning-focused LLMs more reliable and capable.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open problems left unresolved by the paper that future researchers could address.
- Provide formal convergence guarantees for SAPO (e.g., monotonic policy improvement, stability bounds) under off-policy updates and importance weighting, and characterize conditions on temperatures and ratio dispersion that ensure stable learning.
- Quantify the estimator bias introduced by soft-gated gradients relative to unbiased importance sampling (and hard clipping), and analyze its impact on sample efficiency and long-run performance.
- Develop an adaptive temperature schedule (per-token, per-sequence, or per-batch) that reacts to observed ratio distributions or log-ratio variance, rather than fixed , and evaluate its stability/performance trade-offs.
- Test alternative smooth gating kernels (e.g., tanh, logistic mixtures, rational functions) and centerings (e.g., around vs. around log-ratio or advantage magnitude) to determine if SAPO’s sigmoid is optimal for stability and learning signal retention.
- Extend the theoretical reduction from token-level SAPO to sequence-level gating beyond small-step and low-dispersion assumptions; quantify approximation error in regimes with high intra-sequence heterogeneity and its downstream effect on optimization.
- Characterize SAPO’s failure modes: when and why “eventual instability” occurs, how it relates to ratio tails, advantage distributions, sequence length, or MoE routing dynamics, and which safeguards (e.g., adaptive temperature, KL constraints) prolong stable training.
- Study SAPO’s interaction with common regularizers used in RLHF/RA (e.g., KL penalties to a reference policy, entropy bonuses, value baselines) and identify combinations that further reduce collapse while preserving gains.
- Measure the impact of SAPO on exploration–exploitation balance (e.g., response diversity, per-token entropy, coverage of solution space) and compare to hard clipping.
- Evaluate SAPO under learned (noisy) reward models and preference-based objectives, including robustness to reward misspecification and adversarial reward hacking, beyond deterministic pass/fail tasks.
- Investigate sensitivity to group size G and group-normalization choices (mean/std statistics, robust normalization, per-task normalization in multi-task training) and how these interact with soft gating.
- Provide rigorous sample-efficiency analyses (e.g., effective gradient contributions per batch, fraction of tokens/seqs attenuated, learning curves per unit compute) rather than qualitative claims.
- Compare SAPO with a broader set of baselines (e.g., PPO/TRPO-style trust-region methods, IMPALA/V-trace, AWR/AWAC, conservative policy gradients, soft clipping variants) under matched budgets and identical setups.
- Examine the effect of SAPO on MoE-specific behaviors (expert load balancing, router entropy, expert collapse/over-concentration, routing variance) and design router-aware gating if needed.
- Quantify how negative-token gradients drive instability in large vocabularies across architectures and vocab sizes; test scaling laws (instability vs. |V|) and evaluate targeted mitigations beyond temperature asymmetry.
- Explore advantage-aware gating (e.g., making depend on advantage magnitude, uncertainty estimates, or per-token variance) to selectively attenuate high-risk updates without over-damping informative ones.
- Analyze SAPO’s impact on catastrophic forgetting and general-domain capabilities (e.g., perplexity, factuality, helpfulness) during specialized RL training; measure any trade-offs or regressions.
- Provide robust multi-seed evaluations, confidence intervals, and statistical significance testing for reported gains to ensure claims about stability and performance are reproducible.
- Report detailed compute and memory overhead (throughput, latency, GPU utilization) introduced by soft gating and its scalability across model sizes, sequence lengths, and batch structures.
- Validate SAPO on diverse LLM families beyond Qwen (different pretraining corpora, tokenizers, routing schemes), including non-Chinese and multilingual models, to test generality.
- Assess SAPO on long-horizon interactive RL tasks (dialogue agents, tool-use, environment interaction) where credit assignment and off-policy drift differ from static sequence-level tasks.
- Investigate curriculum/scheduling strategies for temperatures and auxiliary regularizers over training phases (e.g., warm-up, stabilization, saturation) to counter late-stage instability.
- Examine robustness across tasks with imbalanced rewards or heterogeneous scales in multi-task settings; study per-task temperature tuning and normalization strategies for stable joint training.
- Provide ablations on sequence length and ratio dispersion (including synthetic constructions with controlled heterogeneity) to identify thresholds where token-level adaptivity significantly outperforms sequence-level gating.
- Analyze the interplay between SAPO and routing replay (GRPO-R2): whether SAPO can benefit from or replace replay mechanisms, and under what conditions replay remains necessary.
- Clarify and standardize reward design across benchmarks (especially non-math/multimodal tasks), including contamination checks, label noise characterization, and the exact evaluation protocol, to enhance reproducibility and comparability.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s method and empirical insights, with minimal adaptation to existing LLM RL pipelines.
- Soft-gated RL fine-tuning for reasoning-heavy LLMs (replacement for GRPO/GSPO)
- What: Integrate SAPO’s temperature-controlled soft gate into group-based policy optimization to stabilize updates and improve Pass@1 on math, coding, and multimodal tasks.
- Sectors: Software, education, finance (analyst assistants), healthcare (clinical decision support prototypes), robotics (planning assistants), research.
- Tools/Workflows:
- “SAPO optimizer” module in RLHF/RLAIF stacks (e.g., Hugging Face TRL/OpenRLHF/DeepSpeed), using
f_{i,t}(r)andw_{i,t}from the paper’s equations. - Hyperparameter preset: τ_pos ≈ 1.0, τ_neg ≥ τ_pos (e.g., 1.05), group-normalized sequence rewards, G≥4 sampled responses per query.
- Logging dashboards for ratio distributions r_{i,t}, sequence gate s_i, and instability flags (variance and collapse monitoring).
- Assumptions/Dependencies:
- Reward models or preference datasets exist for the target tasks; sufficient compute for group sampling.
- Small-step on-policy and low intra-sequence dispersion generally hold (empirically supported), especially in dense models.
- Access to behavior-policy logits and importance ratios; support for token-level weighting in training code.
- Stabilized Mixture-of-Experts (MoE) RL training without routing replay
- What: Use SAPO’s soft gate to attenuate high-variance token updates endemic to MoE routing, reducing training collapse and engineering overhead (no routing replay).
- Sectors: Software (LLM infrastructure), cloud AI platforms.
- Tools/Workflows:
- MoE-aware SAPO trainer with token-adaptive gates and sequence coherence; integrate asymmetric temperatures to damp negative-token gradients.
- Pipeline simplification by removing routing replay components.
- Assumptions/Dependencies:
- MoE checkpoints and routing remain compatible with token-level importance ratios; variance monitors included.
- τ_neg > τ_pos is tuned for the specific MoE architecture.
- Multi-task, multimodal RL training for production models (e.g., Qwen3-VL-like systems)
- What: Apply SAPO across mixed task batches (math, code, logical reasoning, vision-language) with fixed per-task sampling ratios to maintain reliable multi-task learning.
- Sectors: Software, education (tutors), enterprise support (document + chart understanding), creative tools (vision-language assistants).
- Tools/Workflows:
- Unified RL training loop with SAPO, large batch sizes split into mini-batches, per-task sampling controls; evaluation on benchmarks akin to AIME, LiveCodeBench, ZebraLogic, MathVision.
- Continuous trust region analytics for each modality/task.
- Assumptions/Dependencies:
- High-quality, task-specific reward functions; balanced sampling to avoid mode collapse.
- Sufficient GPU memory and throughput for multi-modal sequences and token-gate computation.
- Reduction in compute waste and operational risk during RL training
- What: Fewer unstable runs and collapses; improved sample efficiency by preserving gradients from near-on-policy tokens.
- Sectors: Energy/sustainability (compute efficiency), software operations (MLOps).
- Tools/Workflows:
- Training job governance: abort criteria based on SAPO gate diagnostics, energy dashboards tracking avoided reruns.
- Budget-aware scheduling with SAPO replacing hard clipping to reduce aborted training cycles.
- Assumptions/Dependencies:
- Existing MLOps observability to track ratio/gate metrics; cost-saving depends on baseline instability of GRPO/GSPO.
- Safer and more predictable optimization behavior for regulated applications
- What: Smoother trust regions and dampened negative-token updates reduce volatile policy shifts during training; improves auditability of changes.
- Sectors: Healthcare (clinical decision support research), finance (compliance-oriented assistants), legal tech.
- Tools/Workflows:
- Training change logs with ratio distributions, gate responses, and temperature schedules; pre-deployment validation pipelines using standardized stability criteria.
- Assumptions/Dependencies:
- Regulatory acceptance requires additional safeguards beyond optimization stability (e.g., comprehensive safety evaluations, domain-specific risk controls).
- SAPO is part of a broader safety-by-design training process.
- Academic evaluation and benchmarking of reasoning improvements
- What: Use SAPO to test hypotheses on stability-performance trade-offs and to replicate/extend improvements on math/coding benchmarks.
- Sectors: Academia, open-source community.
- Tools/Workflows:
- Reproducible training scripts with SAPO gates; ablations on τ_neg/τ_pos; sequence-level vs token-level behavior analyses.
- Assumptions/Dependencies:
- Availability of public datasets/benchmarks; sufficient compute to run controlled comparisons.
Long-Term Applications
The following applications are plausible extensions requiring further research, scaling, or development to verify feasibility and generalize beyond the presented scope.
- Automated temperature scheduling and gate learning
- What: Dynamic, context-aware τ schedules (per token/sequence/task) or learned gating functions to further reduce instability without manual tuning.
- Sectors: Software infrastructure, AutoML, academia.
- Tools/Workflows:
- Meta-learning modules to adjust τ_neg/τ_pos online based on risk signals; Bayesian or RL controllers for gate adaptation.
- Assumptions/Dependencies:
- Reliable online diagnostics, convergence proofs for adaptive gates, compatibility with large-scale distributed training.
- Generalization of soft trust regions to non-text RL (e.g., robotics, control)
- What: Adapt SAPO’s smooth clipping paradigm to continuous action spaces or hybrid policies (beyond tokenized actions), as a stability-enhancing alternative to hard clipping.
- Sectors: Robotics, autonomous systems, operations research.
- Tools/Workflows:
- SAPO-inspired gating for PPO/TRPO variants, with importance-ratio-based attenuation tuned to continuous actions.
- Assumptions/Dependencies:
- Theoretical and empirical validation in non-discrete action domains; careful design of ratio estimators and off-policy measures.
- Continual, privacy-preserving fine-tuning on devices and federated networks
- What: Use smoother updates to enable on-device or federated RL fine-tuning with reduced risk of destabilization in constrained environments.
- Sectors: Mobile, edge AI, privacy tech.
- Tools/Workflows:
- Federated SAPO training with local token-gate computation; aggregation with stability guarantees; privacy-preserving reward modeling.
- Assumptions/Dependencies:
- Efficient local computation of importance ratios; secure reward channels; federated optimization stability research.
- Safety certification frameworks leveraging smooth trust regions
- What: Formalize stability audits and certification criteria for RL training using soft gates, making model updates more predictable for high-stakes deployments.
- Sectors: Policy/regulatory, healthcare, finance, automotive.
- Tools/Workflows:
- Standardized training stability metrics (variance, collapse rates, gate response curves); audit trails for regulatory review.
- Assumptions/Dependencies:
- Multi-stakeholder standards development; alignment with domain-specific safety requirements and post-training evaluations.
- Reward design innovations paired with SAPO for complex reasoning
- What: Combine SAPO with richer process-based rewards (e.g., stepwise reasoning correctness, tool-use traces) to unlock further gains in long-chain tasks.
- Sectors: Education (interactive tutors), software (code agents), research.
- Tools/Workflows:
- Instrumented environments to score intermediate steps; tool-augmented RL with SAPO for better credit assignment.
- Assumptions/Dependencies:
- High-quality, scalable reward signals; robust evaluation pipelines to measure end-to-end improvements.
- Hallucination mitigation via targeted damping of negative-token gradients
- What: Explore whether SAPO’s asymmetric temperature scheme systematically reduces spurious token probabilities in long-form generation.
- Sectors: Consumer AI (assistants), enterprise search/summary, legal/medical drafting aids.
- Tools/Workflows:
- Long-form generation benchmarks with hallucination metrics; token-level error attribution and gate diagnostics.
- Assumptions/Dependencies:
- Empirical evidence across diverse domains; careful trade-offs to preserve exploration and diversity.
- Standardized, sector-specific SAPO training recipes
- What: Publish domain-adapted SAPO configurations (task sampling ratios, τ schedules, reward scalings) for healthcare, finance, education, and multimodal applications.
- Sectors: Healthcare, finance, education, media.
- Tools/Workflows:
- “SAPO Recipes” library with validated presets; integration guides for major training frameworks.
- Assumptions/Dependencies:
- Community validation, domain data availability, ongoing maintenance and benchmarking across evolving tasks.
Cross-cutting assumptions and dependencies
- Quality and availability of reward models/datasets remain a bottleneck; SAPO improves optimization stability but does not replace good reward design.
- The small-step on-policy (A1) and low intra-sequence dispersion (A2) assumptions hold frequently in practice (especially dense models), but may need monitoring and adaptation for MoE or highly heterogenous tasks.
- Token-level importance ratios and gate computations must be supported by training infrastructure; distributed training should preserve numerical stability in ratio and gate evaluation.
- SAPO reduces—but does not eliminate—the possibility of instability; monitoring, early stopping, and rollback remain essential operational practices.
Glossary
- Advantage: In policy-gradient RL, a signal indicating how much better or worse an action is than a baseline, used to scale updates. "Positive advantages increase the sampled tokenâs logit and decrease all unsampled logits; negative advantages do the opposite"
- Asymmetric temperature: Using different temperatures for positive vs. negative updates in a soft gate so negative-token gradients decay faster to improve stability. "To further enhance robustness in large vocabularies, SAPO employs asymmetric temperatures for positive and negative tokens"
- Autoregressive LLM: A model that predicts each token conditioned on all previous tokens in the sequence. "We model an autoregressive LLM parameterized by as a stochastic policy over token sequences."
- Behavior policy: The policy that generated the data used for learning, typically the previous (old) policy in off-policy updates. "samples a group of responses from the behavior policy $\pi_{\theta_\text{old}$,"
- Cold-start: Training a model starting from an initialization with little or no prior fine-tuning on the target objective. "We conduct experiments using a cold-start model fine-tuned from Qwen3-30B-A3B-Base"
- Geometric mean: The multiplicative average; used to aggregate token-level ratios into a length-normalized sequence-level ratio. "We further define the length-normalized sequence-level ratio as the geometric mean of token ratios:"
- Group-based policy optimization: An RL paradigm where multiple responses are sampled per query, rewards are normalized within the group, and updates use importance ratios. "group-based policy optimization has emerged as a practical recipe: multiple responses are sampled per query, sequence-level rewards are normalized within the group, and policy updates are weighted by importance ratios"
- Group Relative Policy Optimization (GRPO): A group-based policy optimization method that applies hard token-level clipping of importance ratios. "GRPO~\citep{grpo} samples a group of responses from the behavior policy $\pi_{\theta_\text{old}$, computes their rewards , and maximizes the following token-level objective:"
- Group Sequence Policy Optimization (GSPO): A group-based method that applies clipping at the sequence level with length normalization to reduce variance. "GSPO applies clipping at the sequence level rather than per token."
- Group-normalized advantage: An advantage estimate normalized within a sampled group, typically shared across tokens of a response. "and is the group-normalized advantage (shared across tokens within a response)."
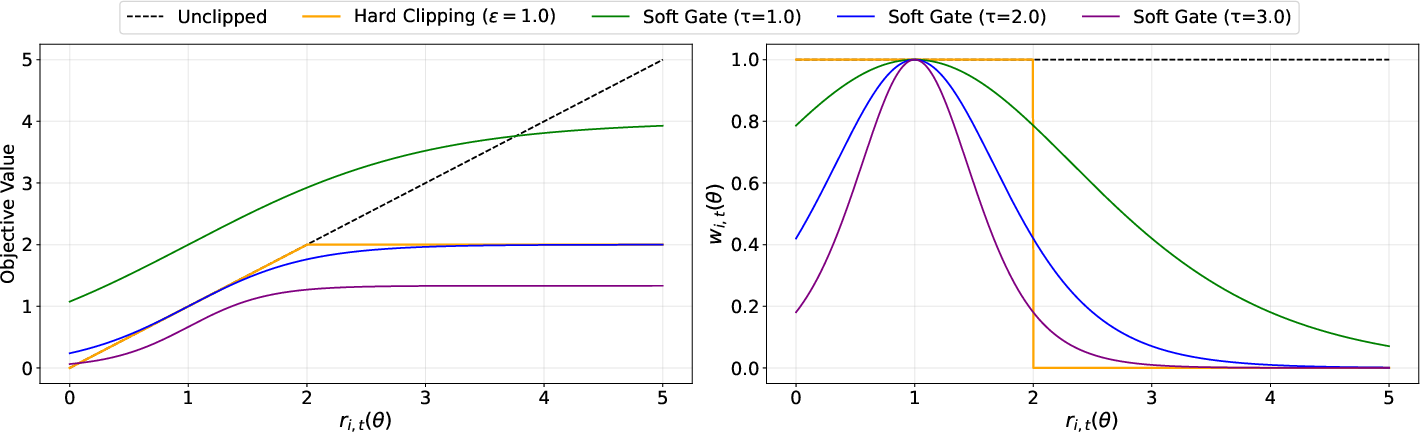
- Hard clipping: A discontinuous truncation that caps importance ratios within a fixed band, zeroing gradients outside it. "Hard clipping, as used in GRPO \citep{grpo}, constrains large deviations by zeroing gradients outside a fixed band."
- Importance ratio: The ratio between current and behavior policy probabilities for an action (token), used for off-policy correction. "Token-level importance ratios often exhibit high varianceâa phenomenon exacerbated in Mixture-of-Experts modelsâleading to unstable updates."
- Length normalization: Adjusting sequence-level quantities by sequence length to stabilize scales and reduce variance. "The length normalization in reduces variance and places it on a consistent numerical scale across responses."
- Logit: The pre-softmax score for a token; differences in logits determine output probabilities. "let denote the logits (with vocabulary size )"
- Mixture-of-Experts (MoE): An architecture that routes tokens to specialized experts, often increasing variance across tokens. "especially in Mixture-of-Experts (MoE) models where routing heterogeneity and long responses can amplify deviations across tokens."
- Off-policy: Learning from data generated by a different policy than the one currently being optimized. "adaptively attenuates off-policy updates while preserving useful learning signals."
- On-policy: Learning from data generated by the current policy; often corresponds to importance ratios near 1. "centered at the on-policy point."
- Pass@1: An evaluation metric measuring the success rate of the first sampled answer. "higher Pass@1 performance under comparable training budgets."
- Policy gradient: A family of RL methods that optimize expected returns by following gradients of log-policy terms weighted by returns or advantages. "Soft Adaptive Policy Optimization (SAPO) is a smooth and adaptive policy-gradient method for RL fine-tuning"
- Routing heterogeneity: Variability introduced by MoE routing decisions that can increase token-level ratio dispersion. "where routing heterogeneity and long responses can amplify deviations across tokens."
- Routing replay: A stabilization technique for MoE training that reuses or controls routing decisions during learning. "GRPO-R2 (i.e., GRPO equipped with routing replay)"
- Sequence-level coherence: Alignment of optimization with sequence-level signals so updates reflect the overall sequence reward. "Like GSPO, SAPO maintains sequence-level coherence"
- Sigmoid: The logistic function mapping reals to (0,1), used here to define a smooth gate over ratios. " is the sigmoid function."
- Soft gate: A smooth weighting function applied to importance ratios to attenuate updates without discontinuities. "replaces hard clipping with a temperature-controlled soft gate"
- Softmax: A normalization function that converts logits into a probability distribution over the vocabulary. "compute output probabilities via a softmax operation, i.e., ."
- Stop gradient: An operation that blocks gradient flow through a quantity during backpropagation. "where denotes the stop gradient operation."
- Surrogate objective: A proxy objective used for stable optimization of the true objective, common in clipped or gated policy methods. "The left panel shows the surrogate objective value;"
- Temperature: A hyperparameter controlling the sharpness or decay rate of a soft gating function; higher values cause faster attenuation. "Using a higher temperature for negative tokens ($\tau_{\text{neg} > \tau_{\text{pos}$) leads to the most stable training dynamics"
- Token-level adaptivity: The capability to modulate update weights per token rather than uniformly across the sequence. "Compared with GSPO~\citep{gspo} and GRPO~\citep{grpo}, SAPO provides both sequence-level coherence and token-level adaptivity:"
- Trust region: A region around on-policy behavior within which updates are trusted; enforced softly or continuously to stabilize learning. "This implements a continuous trust region:"
Collections
Sign up for free to add this paper to one or more collections.