DreamOmni2: Multimodal Instruction-based Editing and Generation
Abstract: Recent advancements in instruction-based image editing and subject-driven generation have garnered significant attention, yet both tasks still face limitations in meeting practical user needs. Instruction-based editing relies solely on language instructions, which often fail to capture specific editing details, making reference images necessary. Meanwhile, subject-driven generation is limited to combining concrete objects or people, overlooking broader, abstract concepts. To address these challenges, we propose two novel tasks: multimodal instruction-based editing and generation. These tasks support both text and image instructions and extend the scope to include both concrete and abstract concepts, greatly enhancing their practical applications. We introduce DreamOmni2, tackling two primary challenges: data creation and model framework design. Our data synthesis pipeline consists of three steps: (1) using a feature mixing method to create extraction data for both abstract and concrete concepts, (2) generating multimodal instruction-based editing training data using the editing and extraction models, and (3) further applying the extraction model to create training data for multimodal instruction-based editing. For the framework, to handle multi-image input, we propose an index encoding and position encoding shift scheme, which helps the model distinguish images and avoid pixel confusion. Additionally, we introduce joint training with the VLM and our generation/editing model to better process complex instructions. In addition, we have proposed comprehensive benchmarks for these two new tasks to drive their development. Experiments show that DreamOmni2 has achieved impressive results. Models and codes will be released.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
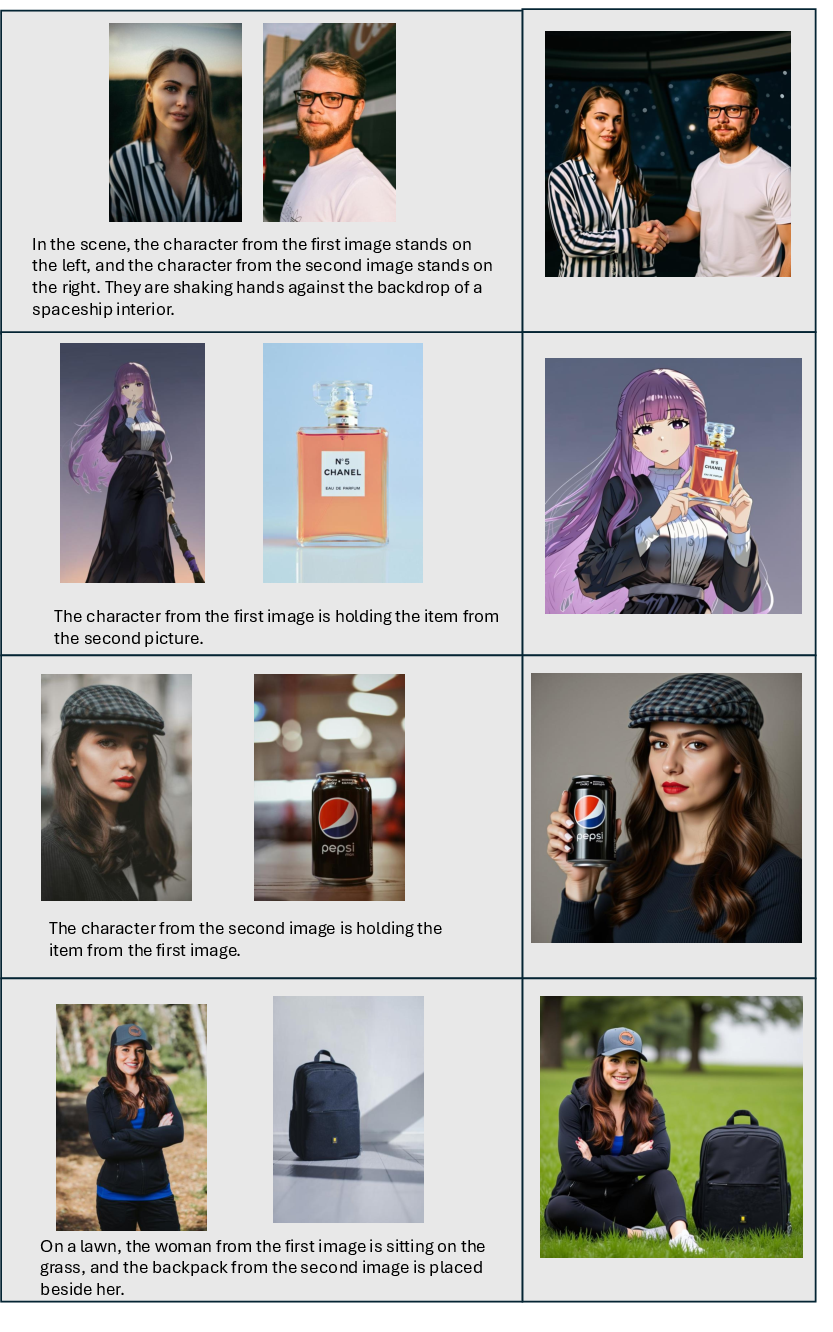
This paper introduces DreamOmni2, a smarter image tool that can both edit and create pictures by following instructions that include text and example images. Unlike many older tools that only handle simple text prompts or focus on specific objects, DreamOmni2 can follow “multimodal” instructions—meaning it understands both words and pictures—and it can match not just concrete things (like “a red car”) but also abstract qualities (like “the shiny texture,” “a watercolor style,” “curly hairstyle,” or “relaxed pose”).
What questions are they trying to answer?
The authors focus on two big questions:
- How can we edit an image using instructions that include both text and reference images, so the result matches very specific details that are hard to describe with words alone?
- How can we generate a brand-new image that copies concrete objects (like a specific dog) or abstract attributes (like fabric texture or art style) from one or more reference images?
In short: How do we build a single, easy-to-use system that can understand complex, real-world instructions and use multiple pictures as precise guidance?
How did they do it?
To make this work, the authors tackled two main challenges: building good training data and designing a model that can handle multiple images without getting confused.
A. Creating training data in three stages
They built a synthetic (computer-made) dataset because real data for these tasks is rare. Here’s the three-step plan:
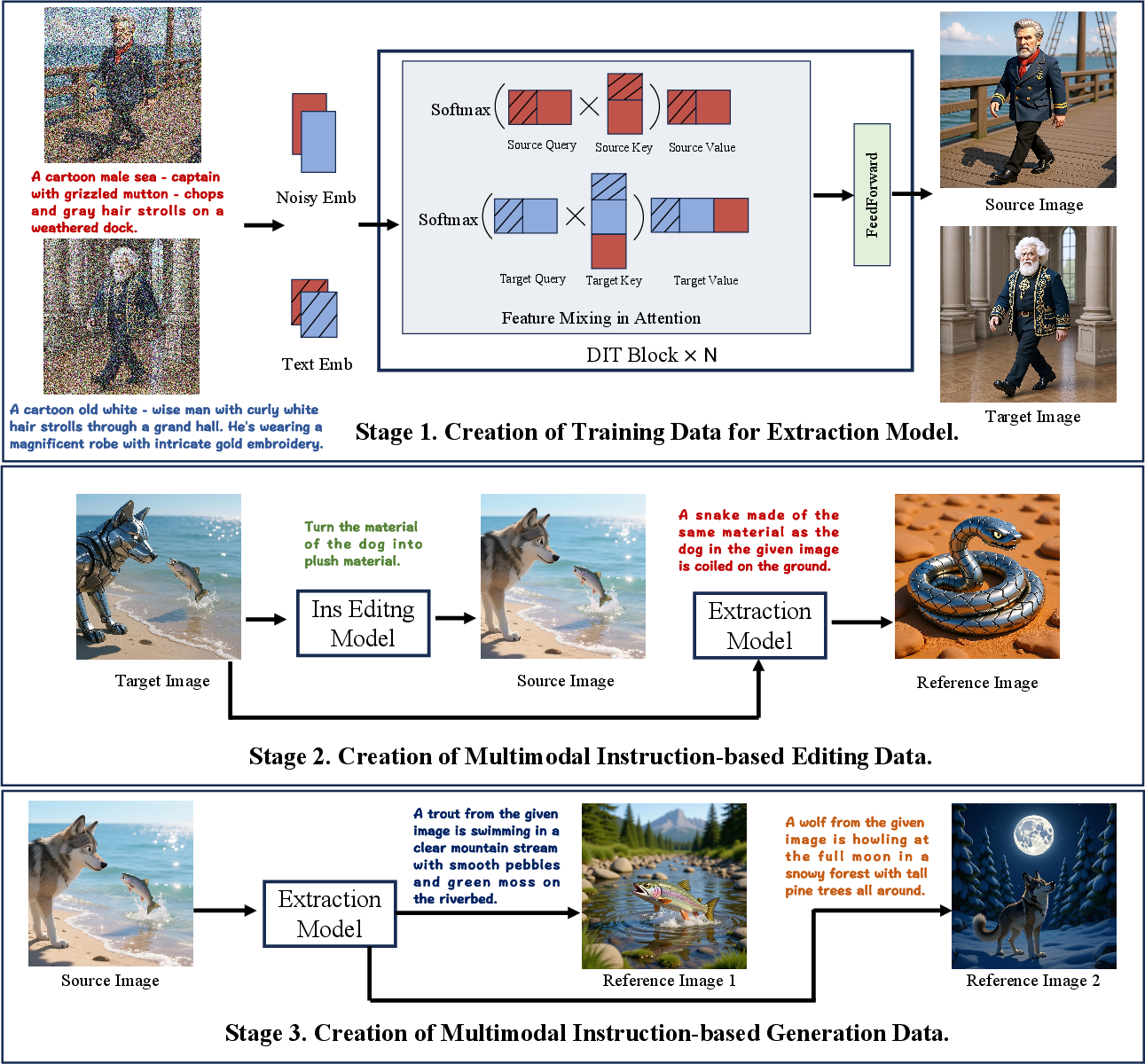
- Stage 1: Feature mixing to make paired images
- Think of a “feature” as the AI’s invisible description of what it sees or imagines (like a recipe for the image). The authors “mix” some of these hidden features between two image branches, so the model generates two related images: different scenes, but sharing the same object or abstract attribute (for example, both images have the same marble texture or the same character).
- This produces clean, high-quality pairs without weird seams or blended edges.
- Stage 2: Build “edit” training examples
- They train an “extraction model” that learns to pull out a chosen object or attribute from an image and produce reference images for it.
- Then they create editing tasks: they pick a target image, generate or extract reference images that capture the thing to be edited (object or attribute), and make a “source image” by editing the target so it’s different. This gives them a training set of: source image + instruction + reference images → target image.
- Stage 3: Build “generation” training examples
- Using the same extraction model, they create multiple reference images from the source image’s keywords. Now the task is: multiple reference images + instruction → generate the target image (no source image to preserve).
B. A model that understands multiple images without mixing them up
When a model sees many images at once, it can confuse which pixels belong to which picture (a “copy-and-paste” mess). DreamOmni2 adds two simple ideas:
- Index encoding: Give each input image a clear “name tag” (like “Image 1,” “Image 2”). This helps the model follow instructions such as “Use the pattern from Image 2.”
- Position encoding shift: Imagine laying photos on a table. If their coordinates overlap in the model’s mind, it might blur them together. Shifting the “position map” for each image prevents overlap, so the model keeps them separate.
C. Teaching the system to understand messy, real-world instructions
People don’t always write clean, simple prompts. So the authors train a vision-LLM (VLM) alongside their image model. The VLM reads the user’s complex or messy instruction and rewrites it into a clean, structured form the image model understands. This “joint training” helps a lot with practical usage.
They also use a lightweight training trick called LoRA (you can think of it as a small add-on that fine-tunes the big model without retraining everything), so the system can keep its original abilities and only “switch on” the new skills when reference images are provided.
What did they find?
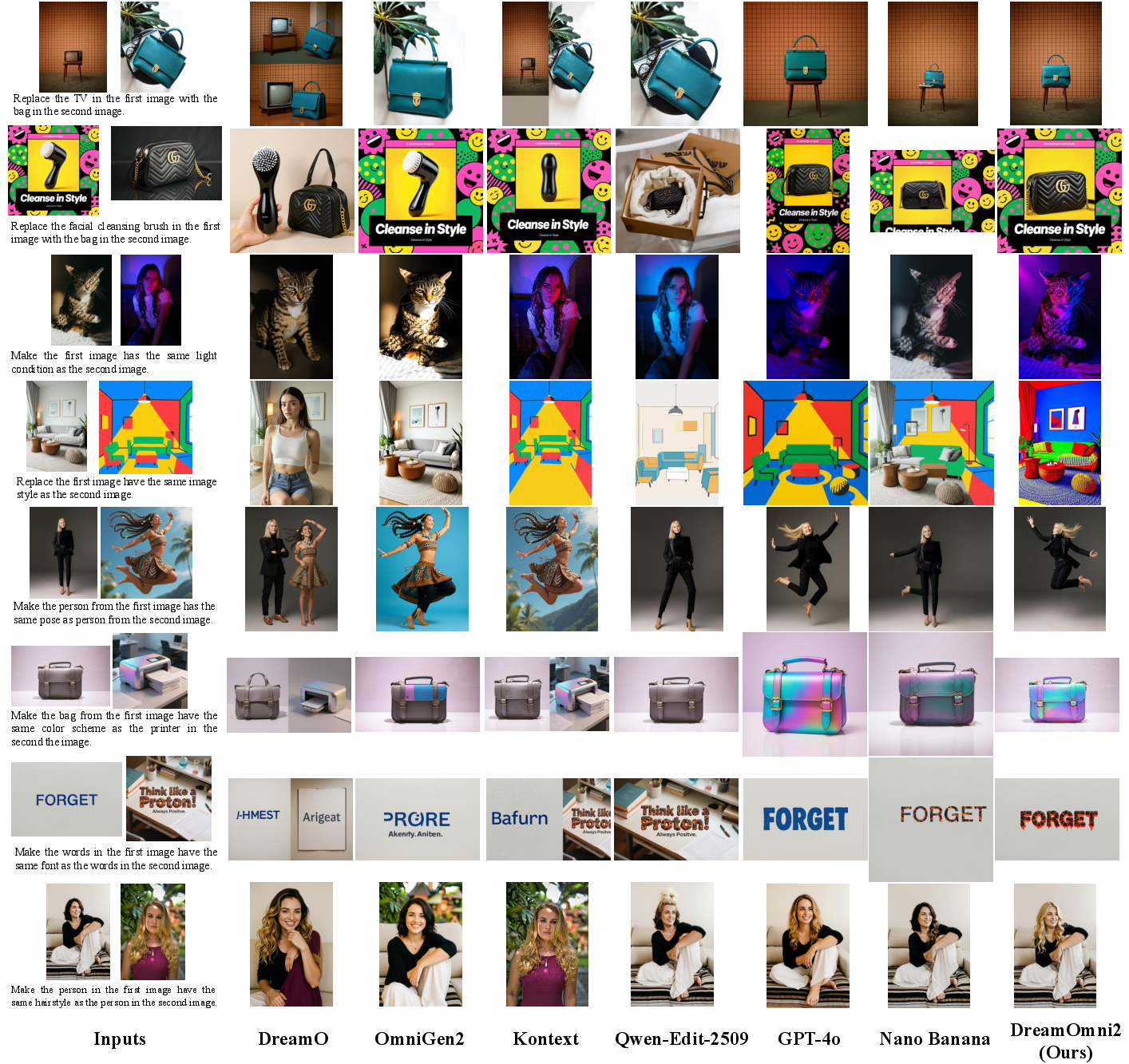
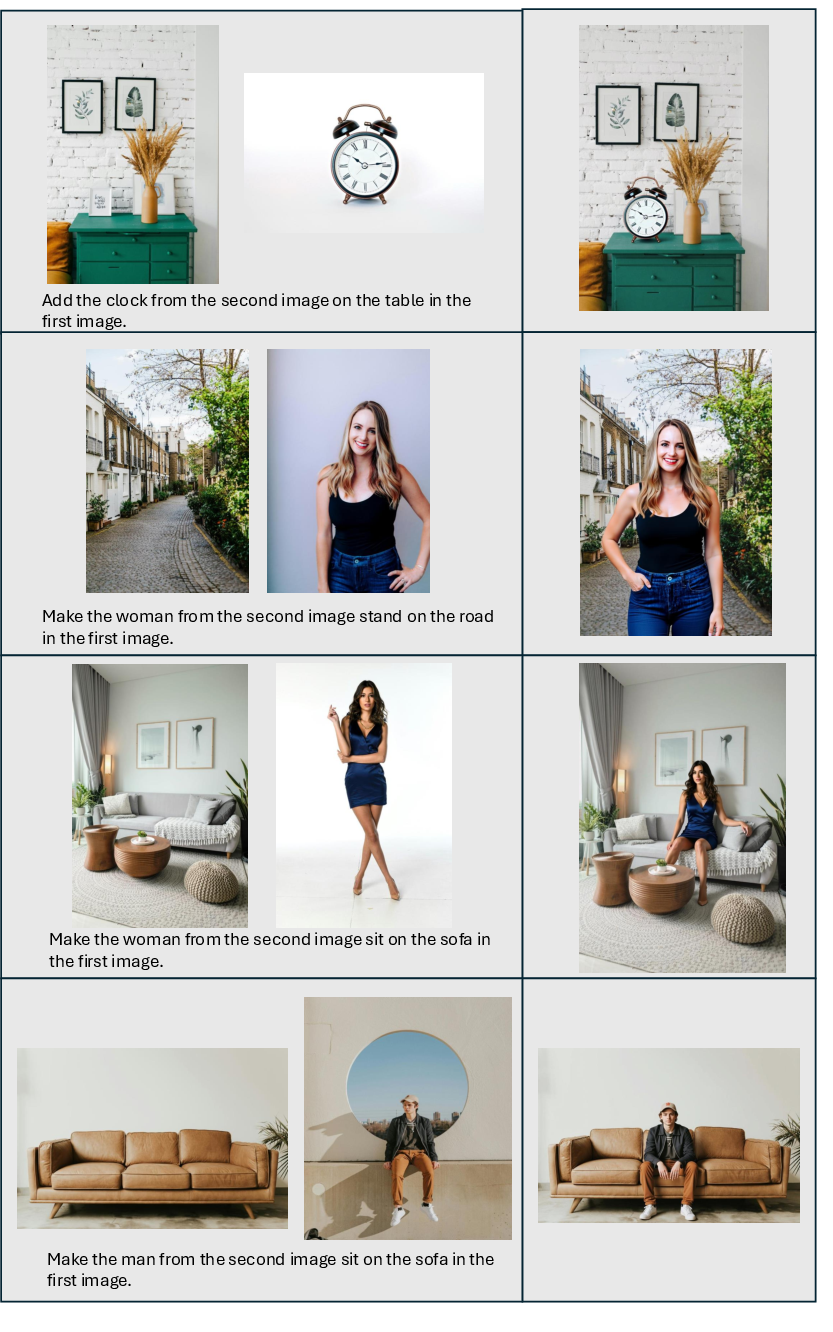
- DreamOmni2 edits images more accurately than other open-source systems and is competitive with some commercial ones, especially when the task involves copying abstract qualities (like texture, style, pose) from reference images.
- It also generates new images that better follow both the instructions and the provided references, for both concrete objects and abstract attributes.
- The new “index encoding + position shift” trick reduces pixel confusion and improves multi-image handling.
- Joint training with the VLM makes the system much better at understanding complex instructions people actually write.
- They created a new benchmark (a standardized test) with real images that checks both multimodal editing and generation across concrete and abstract concepts—something prior benchmarks didn’t fully cover.
Why it matters: In tests judged by humans and AI evaluators, DreamOmni2 scored higher than many alternatives, showing it’s better at following multimodal instructions accurately and consistently.
Why does this matter?
- More precise control: Users can say “Make this bag have the same pattern as this dress” and show the dress image, instead of trying to describe the pattern in words.
- Works with abstract ideas: It doesn’t just copy objects—it can match textures, materials, styles, poses, and other “hard-to-describe” qualities.
- Practical for real users: Combining text and images in instructions is how people naturally communicate. The VLM bridge also helps when instructions are messy.
- A step toward smarter creative tools: Designers, artists, and everyday users can do complex edits and creations within one unified system, without juggling many separate tools.
In short, DreamOmni2 pushes image AI beyond simple text prompts and single-subject copying. It enables accurate, flexible editing and generation guided by both words and multiple reference images—including abstract looks and styles—making image creation more natural, powerful, and reliable.
Knowledge Gaps
Below is a concise, actionable list of the main knowledge gaps, limitations, and open questions left unresolved by the paper:
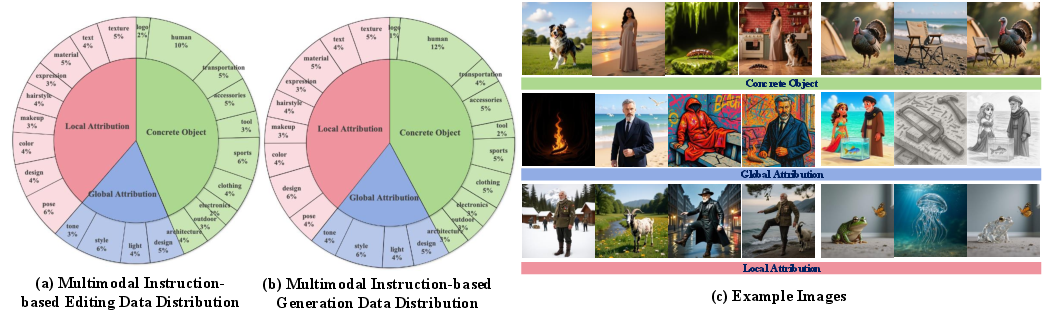
- Lack of a clear taxonomy and operational definition of “abstract attributes” (e.g., texture, style, posture) and how they are annotated or verified; no standardized ontology to support consistent data creation and evaluation.
- Heavy reliance on LLM/VLM heuristics (for keyword extraction, prompt synthesis, and auto-evaluation) introduces label noise and circularity; no audit of prompt quality, bias, or error propagation across stages.
- The synthetic data pipeline dominates training (feature mixing → extraction model → editing/generation data), but the distributional gap to real-world images and instructions is unquantified; no systematic study of how performance scales with real vs synthetic data ratios.
- Feature mixing scheme is under-specified: no ablation on where/how much to mix (layers, heads, tokens), how mixing affects disentanglement, or whether mixing induces spurious correlations (e.g., background/style leakage).
- No theoretical or empirical analysis of what the feature mixing mechanism learns (e.g., causal vs correlational transfer of attributes); absence of diagnostics for attribute disentanglement or controllability.
- The extraction model’s claimed advantages (handling abstract attributes and occlusions) are not rigorously validated with targeted stress tests (severe occlusion, clutter, domain shift, fine-grained materials).
- Index encoding and position-encoding shift solutions lack formalism and scalability analysis: no study of permutation invariance/sensitivity to reference order, variable image resolutions/aspect ratios, or robustness with many references (e.g., >5).
- The model requires separate LoRAs for generation vs editing and manual mode selection; no unified gating or automatic intent disambiguation, and no analysis of failure cases when users provide ambiguous instructions.
- No mechanism for user-controllable reference weighting, conflict resolution among multiple references, or explicit strength/region control over attribute transfer.
- Localization remains underspecified: no integration with masks or spatial constraints to restrict edits; unclear how precisely the model can target small regions without collateral changes.
- Limited benchmark scale (205 editing, 114 generation cases) and incomplete reporting of category/attribute balance, demographic diversity, or domain coverage; no inter-rater agreement, reproducibility protocol, or confidence intervals in human evaluations.
- Evaluation metrics rely mainly on VLM “success ratios” and ad-hoc human judgments; absent standardized metrics for abstract-attribute alignment, identity/structure preservation, and photorealism (e.g., retrieval-based alignment, identity similarity, region consistency).
- Baseline fairness is unclear: some baselines lack native multi-image support; parameter counts, training data scale, and adaptation details are not matched or controlled.
- Generalization to out-of-distribution settings is untested: non-photorealistic references (sketches, diagrams), extreme lighting, compression, low-resolution, or noisy references.
- Robustness to instruction variability is only partially addressed via a 7B VLM fine-tune; no evaluation on multilingual instructions, code-switching, adversarial/contradictory prompts, or long-horizon compositional instructions.
- Computational and memory costs for multi-reference inference are not reported; no latency/throughput benchmarks or memory footprint analysis at different resolutions and reference counts.
- Maximum supported resolution and fidelity limits are unspecified; no analysis of high-resolution consistency, fine detail preservation, or texture fidelity under heavy edits.
- Failure mode analysis is missing: no taxonomy of typical errors (unintended edits, attribute drift, identity loss, copy artifacts) or conditions that trigger them.
- No study of data and model bias: demographic fairness, style/region bias, and content diversity of real images are not characterized; lacking fairness metrics or bias mitigation.
- Potential IP, privacy, and safety issues are unaddressed: style appropriation, identity misuse, brand/logo replication, and harmful/misleading edits without guardrails, filters, or watermarking.
- Reproducibility details are incomplete: “will be released” for code/models/benchmark; licenses of real images, generation seeds, and full data synthesis scripts are not provided.
- Security and memorization risks are not analyzed: potential for training data leakage/inversion or reproduction of copyrighted content via references.
- No comparison to alternative multi-reference fusion strategies (e.g., learned adapters, gating, routing, key–value caching) or explicit compositional modules for combining disparate attributes.
- Disentanglement remains emergent and weakly supervised; open question on incorporating structured supervision (attribute tags, masks, 3D priors) or causal interventions to improve compositional control.
- Extension to video or 3D remains unexplored: temporal consistency for edits/generation, multi-frame references, and motion/pose attribute transfer across time.
- Sensitivity to the number and quality of references is unquantified; no curve showing gains vs. added references or robustness to redundant/conflicting references.
- Ordering and naming of references (“image 1/2/3”) is brittle; no user-facing alignment checks or automatic reconciliation when instruction–reference indices mismatch.
- Portability beyond the chosen base model (Flux Kontext) is untested; unclear how the method transfers to other DiT backbones or non-DiT diffusion models.
- Statistical significance of reported improvements is not provided; no multiple-run variance, bootstrap CIs, or hypothesis testing on success rates.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, based on DreamOmni2’s multimodal instruction-based editing/generation, feature-mixing data pipeline, index/position encoding for multi-image inputs, and joint training with a VLM for instruction normalization.
- Reference-aware image editor for creative teams (software, media/advertising)
- Use case: Apply textures, materials, color palettes, lighting styles, or posing from multiple reference images to a campaign asset while following a natural-language brief.
- Tools/products/workflows: “ReferenceBoard-to-Edit” plugin/API for Photoshop/Figma; multi-image upload with index-aware references (e.g., “use Image 2’s color grading”).
- Assumptions/dependencies: Availability of a fine-tuned LoRA on Kontext; GPUs for inference; content licensing for reference images; basic prompt sanitation via VLM.
- E-commerce product imagery at scale (retail/fashion)
- Use case: Batch-edit product photos to match brand materials, patterns, or textures from a style library; generate new product hero shots with consistent abstract attributes (finish, material sheen, backdrop style).
- Tools/products/workflows: Automated “Pattern/Style Transfer” pipeline; DAM integration; SKU-based workflows with multi-reference style boards.
- Assumptions/dependencies: QA for color/texture fidelity; brand compliance checks; image rights management.
- Fashion design ideation and mood-board synthesis (fashion/design)
- Use case: Convert multiple inspiration images (fabric swatch, silhouette, trim) plus text brief into candidate renders; edit garments to test alternate materials/patterns.
- Tools/products/workflows: “Multimodal Ideation Co-pilot” that extracts and recombines abstract attributes; on-demand variant generator.
- Assumptions/dependencies: Designer sign-off; consistent lighting/pose control; trusted data provenance.
- Interior/architecture concept visualization (AEC)
- Use case: Generate or edit room renders guided by reference materials (wood grain, stone finish, lighting mood) and textual constraints.
- Tools/products/workflows: Material/style banks feeding the generator; index-encoded references for “Image 1 = flooring, Image 2 = lighting.”
- Assumptions/dependencies: Material realism thresholds; calibration to typical camera/lens setups for client expectations.
- Brand asset consistency enforcement (marketing/comms, finance)
- Use case: Enforce brand palettes, textures, and visual motifs across assets via multimodal references; flag deviations during editing.
- Tools/products/workflows: “Brand-Guard” preflight that uses the extraction model to detect and reapply brand attributes; VLM normalizes messy briefs.
- Assumptions/dependencies: Up-to-date brand libraries; model guardrails; audit trails.
- Social media “remix with references” features (consumer apps)
- Use case: Users edit posts using multiple references (friend’s backdrop, influencer’s color grade, specific hairstyle) with casual instructions.
- Tools/products/workflows: Mobile app feature with index-aware multi-image input; on-device prompt normalization via a lightweight VLM.
- Assumptions/dependencies: Content moderation; resource-constrained inference; user consent on reference use.
- VFX and post-production look dev (film/TV)
- Use case: Rapidly prototype scene looks by referencing multiple plates, LUTs, and texture studies; perform consistent attribute edits across shots.
- Tools/products/workflows: Pipeline nodes that apply abstract attributes from look-book images; batch scene-level consistency checks.
- Assumptions/dependencies: Integration into Nuke/Resolve workflows; quality gates; license compliance.
- Synthetic data augmentation for CV tasks (academia/industry R&D)
- Use case: Generate labeled image sets controlling abstract attributes (texture/material/lighting) and concrete objects for robustness testing.
- Tools/products/workflows: Feature-mixing pipeline to create paired data; attribute-aware sampling; benchmark evaluation (DreamOmni2).
- Assumptions/dependencies: Domain gap management; dataset documentation; consistency of attribute labels.
- Instruction normalizer microservice (software/MLOps)
- Use case: Convert messy user prompts into structured directives for editing/generation (joint training with VLM improves real-world usability).
- Tools/products/workflows: “Instruction-to-Plan” API that outputs the predefined format consumed by the generator/editor.
- Assumptions/dependencies: VLM availability (e.g., Qwen2.5-VL 7B fine-tuned); latency budgets; multilingual coverage if needed.
- Multi-image-aware API for existing generators (software)
- Use case: Retrofit current diffusion-transformer systems with index encoding and position encoding shifts to support multiple references without pixel confusion.
- Tools/products/workflows: Open-source module implementing index channels + positional shifts; SDK for integration.
- Assumptions/dependencies: Access to model internals; adequate memory; thorough regression tests.
- Benchmarking and procurement evaluation (academia/enterprise)
- Use case: Use DreamOmni2’s real-image benchmark to compare vendors on multi-reference editing/generation, including abstract attributes.
- Tools/products/workflows: Standardized evaluation harness; human + VLM scoring; decision dashboards.
- Assumptions/dependencies: Release of benchmark; license clarity; established acceptance criteria.
- Creative A/B testing and variant exploration (marketing, product design)
- Use case: Rapidly generate attribute-controlled variants (lighting/texture/layout) to test engagement or conversion.
- Tools/products/workflows: Variant factory with attribute toggles; analytics loop; VLM-guided prompt templates.
- Assumptions/dependencies: Experiment design; content safety filters; legal review for references.
- Education and training materials (education)
- Use case: Generate visual teaching aids showing controlled changes in abstract attributes (e.g., how posture or lighting affects perception); guided edits from example images.
- Tools/products/workflows: Lesson kits; classroom prompt templates; student-safe content filters.
- Assumptions/dependencies: Age-appropriate use; institutional policies; open educational resource licensing.
Long-Term Applications
These opportunities require further research, scaling, domain adaptation, or policy frameworks before broad deployment.
- Virtual try-on and personalized fit visualization (fashion/retail)
- Use case: End-to-end try-on that transfers garment attributes (fabric drape, pattern, texture) to user photos across diverse poses/occlusions.
- Dependencies: Robust human/body modeling; 3D/physics-aware attribute transfer; privacy/consent; evaluation for bias and fit realism.
- Video-level multimodal editing/generation (media, social, education)
- Use case: Apply multi-reference abstract attributes consistently across frames (style, lighting, motion cues).
- Dependencies: Temporal consistency models; compute optimization; motion-aware position encoding; content provenance tracking.
- Robotics/simulation asset generation (robotics, manufacturing)
- Use case: Generate materials/textures and environments with controllable abstract attributes for sim-to-real transfer and vision policy training.
- Dependencies: Physics-consistent rendering; domain randomization strategies; attribute-grounded labels; validation against real-world sensors.
- Healthcare imaging augmentation (healthcare, academia)
- Use case: Privacy-preserving synthetic images for training and education, with controlled attributes (noise, contrast, anatomical poses).
- Dependencies: Clinical validation; regulatory compliance (HIPAA/GDPR); bias mitigation; rigorous dataset governance.
- Enterprise creative copilots integrated with PIM/DAM (software/enterprise IT)
- Use case: From product metadata and brand reference boards, auto-generate/edit assets across channels while maintaining abstract brand attributes.
- Dependencies: System integration (CMS, DAM, PIM); workflow orchestration; auditability; human-in-the-loop guardrails.
- Cross-lingual, domain-robust instruction understanding (software, education)
- Use case: Seamless prompt normalization across languages and professional jargon for attribute-specific edits.
- Dependencies: VLM fine-tuning at scale; domain adapters; continuous evaluation and feedback loops.
- Visual attribute knowledge graphs for search/recommendation (software, e-commerce)
- Use case: Use the extraction model to build structured attribute graphs (materials, styles, lighting) to power retrieval and recommendations.
- Dependencies: Reliable attribute extraction; schema design; data quality monitoring; privacy-preserving pipelines.
- On-device and real-time mobile editing (consumer apps)
- Use case: Multi-reference edits on smartphones with low latency.
- Dependencies: Model compression/quantization; hardware acceleration; energy constraints; safety filters on-device.
- Standards and policy for multi-reference generative editing (policy, industry consortia)
- Use case: Establish guidelines on provenance, consent for reference usage, watermarking, and audit trails for multi-reference edits.
- Dependencies: Cross-industry collaboration; regulatory alignment; interoperable watermarking; disclosure norms.
- Content authenticity and IP compliance tooling (legal/compliance)
- Use case: Automated detection of reference-derived attributes with provenance logging; compliance checks before publication.
- Dependencies: Robust attribution tracing; standardized metadata; alignment with evolving IP law.
- Multimodal curriculum learning and benchmarks beyond images (academia)
- Use case: Extend the DreamOmni2 paradigm to audio/3D/AR with abstract attribute controls (timbre, material response, interaction behaviors).
- Dependencies: New datasets; cross-modal encodings; community benchmarks; shared evaluation protocols.
- Safety, bias, and fairness evaluation suites for abstract attributes (academia/policy)
- Use case: Measure and mitigate harms arising from attribute transfer (e.g., skin tone, cultural motifs) in generative edits.
- Dependencies: Diverse, representative benchmarks; sociotechnical review; stakeholder engagement; red-teaming processes.
- Creative supply chain optimization (media/advertising/finance)
- Use case: Model-driven forecasting of asset needs and automated generation of variants constrained by reference boards and performance data.
- Dependencies: Data integration (analytics, CRM); governance of automated content; ROI measurement frameworks.
- Energy-efficient training/inference for multimodal editing (energy/compute)
- Use case: Reduce A100-hours and carbon footprint while maintaining performance through LoRA strategies, distillation, and sparse adapters.
- Dependencies: Research on green ML tooling; hardware/software co-design; standardized reporting of energy metrics.
Glossary
- abstract attribution: An image property that is not a concrete object, such as texture, material, posture, hairstyle, or style. Example: "including various abstract attributions and concrete objects."
- AGI: Artificial General Intelligence; a broad goal of building systems with general reasoning and understanding. Example: "they contribute to the exploration of AGI and world models"
- diptych method: A data synthesis technique that forms paired images by placing two images side-by-side within one canvas. Example: "Compared to the previous diptych method~\citep{UNO} for generating image pairs, our scheme achieves a higher success rate"
- DiT (Diffusion Transformer): A diffusion-based generative model that uses Transformer architectures. Example: "and feeding them into the DIT model."
- dual-branch structure: A network architecture with two parallel paths that simultaneously produce multiple outputs. Example: "where a dual-branch structure is employed to simultaneously generate both the source image and the target image as follows:"
- extraction model: A model trained to isolate objects or attributes from an image and produce reference images or guided outputs. Example: "we train a generation-editing model as an extraction model."
- feature mixing scheme: A training/data-generation approach that mixes features (e.g., attention features) across branches or batches to create paired data. Example: "we propose a feature mixing scheme to exchange attention features between two batches"
- index encoding: An additional encoding that marks the identity (index) of each input image so the model can distinguish multiple references. Example: "we propose an index encoding and position encoding shift scheme."
- inpainting: An image-editing technique that fills in or replaces regions of an image. Example: "using inpainting methods"
- instruction-based editing: Editing an image guided directly by natural-language instructions. Example: "Instruction-based Editing refers to modifying an image based on a user's language instruction"
- joint training: Training two components (e.g., a VLM and a generation/editing model) together to improve end-to-end performance. Example: "we introduce joint training with the VLM and our generation/editing model to better process complex instructions."
- LLM: LLM; a model trained on large text corpora to understand and generate language. Example: "we randomly select diverse element keywords (e.g., objects or attributes) and use an LLM to compose a prompt"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique for large models. Example: "We then train the editing and generation models using LoRA on Flux Kontext"
- multimodal instruction-based editing: Editing guided by both text instructions and one or more reference images. Example: "we create multimodal instruction-based editing data."
- multimodal instruction-based generation: Image generation guided by text plus multiple reference images capturing objects or attributes. Example: "we create multimodal instruction-based generation data."
- occluded objects: Objects that are partially hidden by other elements in an image. Example: "it can handle abstract concepts, occluded objects, and generate more diverse reference images."
- position encoding shift: Offsetting position encodings for later inputs to prevent confusion or overlap between multiple image references. Example: "Position encoding is shifted based on previous inputs, preventing pixel confusion"
- positional encoding: A representation that encodes spatial or sequence position information for model inputs. Example: "positional encoding alone cannot accurately distinguish the index of reference images."
- segmentation detection models: Systems that detect and/or segment objects to create masks or references for generation/editing. Example: "relies on segmentation detection models to create reference images."
- subject-driven generation: Generating images that faithfully preserve a given subject’s identity or defining characteristics. Example: "Subject-driven Generation has been extensively studied."
- T2I: Text-to-Image; models or pipelines that synthesize images from text prompts. Example: "We use a text-to-image (T2I) model to generate a target image"
- textual inversion: A technique that learns a token embedding from a few images to personalize a text-to-image model. Example: "Methods like Dreambooth~\citep{dreambooth} and textual inversion~\citep{textual-inversion} fine-tune models on multiple images of the same subject"
- token concatenation: Joining token sequences along the length dimension before feeding them to a model. Example: "[;] indicates token (or called length) dimension concatenation."
- unified generation and editing model: A single model capable of both creating new images and editing existing ones. Example: "The unified generation and editing base model~\citep{kontext} can only process a single input image."
- visual tokens: Tokenized embeddings of images used alongside text tokens in transformer-based generative models. Example: "encoding reference images as visual tokens, concatenating them with text and noise tokens"
- VLM: Vision-LLM; a model jointly trained on visual and textual data to interpret and generate multimodal content. Example: "A VLM pre-trained on large-scale corpora can better understand these complex intentions"
Collections
Sign up for free to add this paper to one or more collections.

