- The paper introduces a novel framework integrating MLLM-driven cross-modal reasoning and adaptive multi-reference conditioning to ensure subject-consistent video generation.
- It employs a unified conditioning pipeline combining MLLM, T5, VAE, and CLIP features to achieve superior identity preservation and temporal coherence.
- Quantitative evaluations on OpenS2V benchmarks demonstrate state-of-the-art performance in subject fidelity, naturalness, and semantic alignment.
BindWeave: Subject-Consistent Video Generation via Cross-Modal Integration
Subject-consistent video generation (S2V) aims to synthesize videos in which one or more user-specified subjects maintain high-fidelity identity and appearance throughout dynamic sequences, guided by textual prompts. Existing video diffusion models, including DiT-based architectures, have achieved notable progress in visual quality and temporal coherence, but they exhibit limited controllability over subject identity, spatial relationships, and complex multi-entity interactions. Prior approaches typically employ shallow fusion strategies—separate encoders for text and images followed by post-hoc feature fusion—which are insufficient for parsing and binding intricate cross-modal semantics, resulting in identity drift, attribute blending, and action misplacement.
BindWeave Framework Overview
BindWeave introduces a unified framework for S2V that leverages deep cross-modal reasoning to bind prompt semantics to concrete visual subjects. The core innovation is the integration of a pretrained Multimodal LLM (MLLM) as an intelligent instruction parser, which grounds entities and disentangles roles, attributes, and interactions from both text and reference images. The resulting subject-aware hidden states condition a Diffusion Transformer (DiT) via cross-attention and lightweight adapters, guiding identity-faithful, relation-consistent, and temporally coherent video generation.
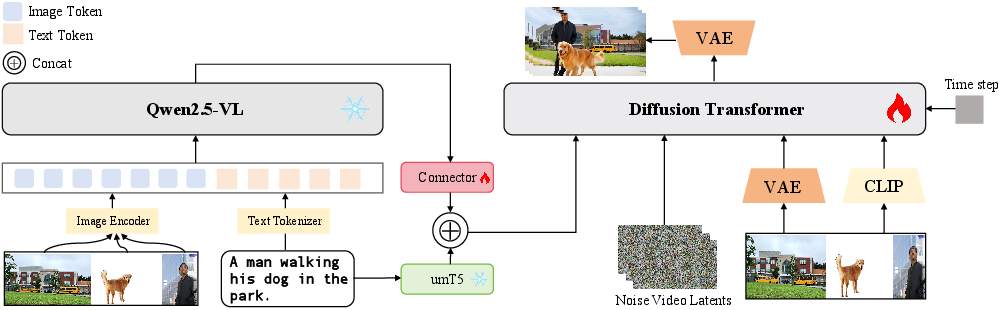
Figure 1: BindWeave architecture: MLLM parses prompt and references, producing subject-aware signals that condition the DiT for subject-consistent video synthesis.
Cross-Modal Reasoning and Conditioning
Multimodal Instruction Planning
Given a text prompt T and K reference images {Ik}, BindWeave constructs a unified multimodal sequence by interleaving the prompt with image placeholders. The MLLM processes this sequence and the actual images, generating hidden states Hmllm that encode high-level reasoning about subject identities, attributes, and interactions. These states are projected via a trainable connector to align with the DiT conditioning space, forming cmllm. In parallel, the prompt is encoded by a T5 encoder to produce ctext. The final relational conditioning signal cjoint is the concatenation of cmllm and ctext, providing both deep cross-modal and precise linguistic grounding.
Multi-Reference Appearance Conditioning
To preserve fine-grained appearance, BindWeave employs an adaptive multi-reference conditioning strategy. Reference images are encoded into VAE features cvae, which are injected into the video latent space by padding the temporal axis and concatenating binary masks to emphasize subject regions.
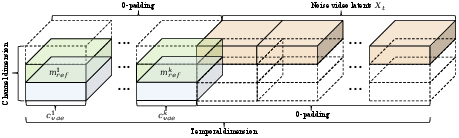
Figure 2: Adaptive multi-reference conditioning: VAE features and masks are injected into padded temporal slots to anchor subject appearance.
Collective Conditioning in DiT
The DiT generator is conditioned at two levels: (1) input-level, where video latents are concatenated with VAE features and masks; (2) cross-attention, where cjoint (MLLM+T5) and CLIP features cclip (from reference images) are projected to keys/values for attention. This structured integration ensures that the diffusion process is guided by high-level relational reasoning, semantic identity, and low-level appearance details.
Training and Inference Protocols
BindWeave is trained on a curated subset of the OpenS2V-5M dataset, using a two-stage curriculum: initial stabilization on a high-quality core subset, followed by large-scale training. The model is optimized to predict the ground truth velocity in the rectified flow framework, with MSE loss between the output and target velocity. Training utilizes 512 xPUs, batch size 512, and AdamW optimizer. During inference, BindWeave flexibly accepts 1–4 reference images and a prompt, with generation performed over 50 rectified flow steps and Classifier-Free Guidance (CFG) scale ω=5.
Quantitative and Qualitative Evaluation
BindWeave is evaluated on the OpenS2V-Eval benchmark, which assesses subject consistency (NexusScore), naturalness (NaturalScore), text-video relevance (GmeScore), and other metrics. BindWeave achieves the highest Total Score (57.61%), with a notably strong NexusScore (46.84%), outperforming all open-source and commercial baselines. The ablation study demonstrates that concatenating MLLM and T5 signals yields superior results compared to T5-only conditioning, especially in scale grounding, action-object execution, and temporal/textual coherence.

Figure 3: Qualitative comparison: BindWeave surpasses baselines in subject fidelity, naturalness, and semantic alignment.

Figure 4: BindWeave avoids implausible phenomena and maintains strong subject consistency compared to other methods.

Figure 5: MLLM+T5 conditioning yields better scale grounding and action-object execution than T5-only.
Robustness to Prompt-Reference Ambiguity and Copy-Paste Artifacts
BindWeave demonstrates robustness in scenarios with prompt-reference ambiguity (e.g., prompt: "a man", reference: baby), faithfully preserving the reference subject's appearance, unlike baselines that default to the prompt semantics.

Figure 6: BindWeave preserves reference appearance under prompt-reference ambiguity, outperforming baselines.
In simple prompts, BindWeave avoids copy-paste artifacts, generating temporally dynamic and natural motion, whereas baselines often produce static subjects.

Figure 7: BindWeave maintains subject dynamics and avoids copy-paste artifacts in subject-to-video generation.
Generalization to Multi-Subject and Complex Scenes
BindWeave generalizes to multi-subject scenarios, maintaining consistent identity and appearance for each subject, preserving spatial layout, and producing coordinated, realistic interactions.

Figure 8: BindWeave generates high-fidelity, subject-consistent videos from single reference images.

Figure 9: BindWeave maintains strong subject consistency across multiple references in complex scenes.
Implications and Future Directions
BindWeave's explicit cross-modal integration via MLLM-driven reasoning and collective conditioning sets a new standard for controllability and consistency in S2V. The demonstrated robustness to prompt-reference conflicts and avoidance of copy-paste artifacts highlight the importance of deep semantic binding in generative video models. The framework is extensible to broader multimodal generation tasks, including personalized content creation, brand marketing, and virtual try-on. Future research may explore scaling MLLM reasoning, more granular spatial-temporal control, and integration with real-time editing interfaces.
Conclusion
BindWeave presents a comprehensive solution for subject-consistent video generation, achieving state-of-the-art performance through deep cross-modal integration and collective conditioning. The approach advances controllability, consistency, and realism in video synthesis, with strong empirical results and robust generalization across diverse scenarios. BindWeave provides a foundation for future developments in multimodal generative modeling and practical deployment in customized video applications.

